将单头注意力扩展到多头注意力
在多个头的基础上扩展之前实现的 CausalAttention 类。这被称为多头注意力机制(Multi-head Attention)。
"多头"这一术语指的是将注意力机制分为多个"头",每个头独立运作。在这种情况下,单个因果注意力模块可以被视为单头注意力,其中只有一组注意力权重顺序处理输入。
因果注意力扩展到多头注意力。
第一小节将直观地通过堆叠多个 CausalAttention 模块来构建 Multi-head Attention 模块,用于示例说明。
第二小节将以更复杂但计算上更高效的方式实现相同的多头注意力模块。
堆叠多个 Single-head Attention 层
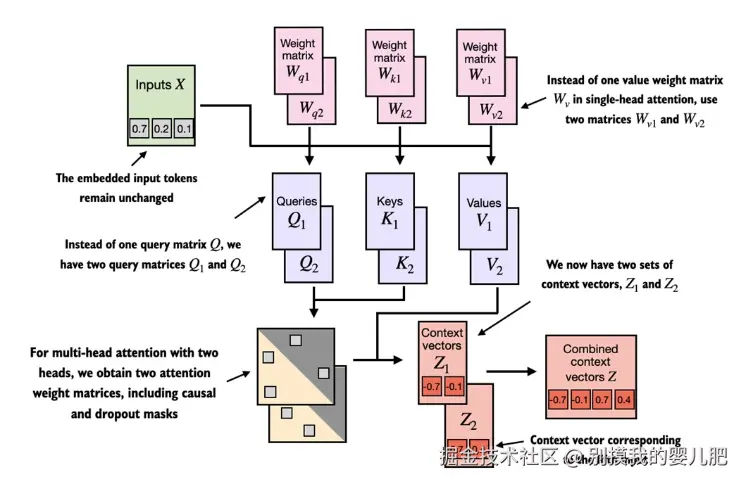 这张图中的多头注意力模块由两个单头注意力模块堆叠在一起。因此,在一个具有两个头的多头注意力模块中,我们不再使用单个矩阵 Wv 来计算值矩阵,而是使用两个值权重矩阵:Wv1 和 Wv2 。同样地,Wq 和 Wk 也各自有两组权重矩阵。我们得到两组上下文向量 Z1 和 Z2 ,然后将它们组合成一个上下文向量矩阵 Z 。
这张图中的多头注意力模块由两个单头注意力模块堆叠在一起。因此,在一个具有两个头的多头注意力模块中,我们不再使用单个矩阵 Wv 来计算值矩阵,而是使用两个值权重矩阵:Wv1 和 Wv2 。同样地,Wq 和 Wk 也各自有两组权重矩阵。我们得到两组上下文向量 Z1 和 Z2 ,然后将它们组合成一个上下文向量矩阵 Z 。
在实际操作中,实现多头注意力机制需要创建多个自注意力机制的实例,其中每个实例都有自己的权重,然后合并这些示例的输出。尽管使用多个自注意力机制实例计算量很大,但这对于像 Transformer 基础的大语言模型所需的复杂模式识别至关重要。
多头注意力的主要思想是通过不同的、学习到的线性投影,多次(并行地)运行注意力机制------------即将输入数据(如注意力机制中的查询、键和值向量)与权重矩阵相乘。
实现 MultiHeadAttentionWrapper 类
python
from torch import nn
class MultiHeadAttentionWrapper(nn.Module):
def __init__(self, d_in, d_out, context_length,
dropout, num_heads, qkv_bias=False):
super().__init__()
self.heads = nn.ModuleList(
[CausalAttention(d_in, d_out, context_length, dropout, qkv_bias)
for _ in range(num_heads)]
)
def forward(self, x):
return torch.cat([head(x) for head in self.heads], dim=-1)如果我们使用这个 MultiHeadAttentionWrapper 类并通过 num_heads=2 设置两个注意力头,且将 CausalAttention 的输出维度设置为2(d_out=2),这将导致一个四维的上下文向量 (d_out*num_heads=4)。
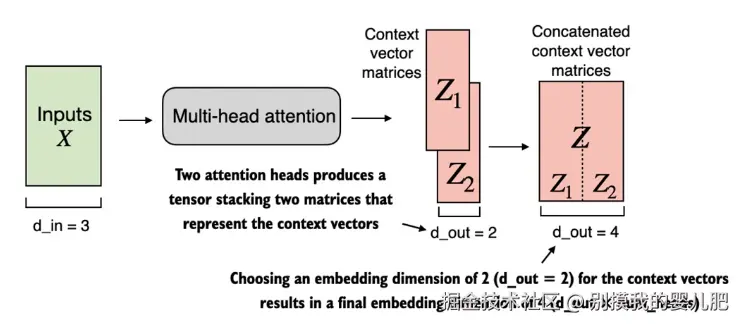 使用 MultiHeadAttentionWrapper ,指定了注意力头的数量(num_heads)。如果我们设置 num_heads=2,如图所示,我们将得到一个包含两组上下文向量矩阵的张量。在每个上下文向量矩阵中,行表示对应于 Token 的上下文向量,列对应于通过 d_out=2 指定的嵌入维度。我们沿列维度连接这些上下文向量矩阵。由于我们有 2 个注意力头和嵌入维度为 2,最终的嵌入维度为 2 × 2 = 4。
使用 MultiHeadAttentionWrapper ,指定了注意力头的数量(num_heads)。如果我们设置 num_heads=2,如图所示,我们将得到一个包含两组上下文向量矩阵的张量。在每个上下文向量矩阵中,行表示对应于 Token 的上下文向量,列对应于通过 d_out=2 指定的嵌入维度。我们沿列维度连接这些上下文向量矩阵。由于我们有 2 个注意力头和嵌入维度为 2,最终的嵌入维度为 2 × 2 = 4。
ini
torch.manual_seed(123)
context_length = batch.shape[1] # This is the number of tokens
d_in, d_out = 3, 2
mha = MultiHeadAttentionWrapper(d_in, d_out, context_length, 0.0, num_heads=2)
context_vecs = mha(batch)
print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)
#结果
tensor([[[-0.4519, 0.2216, 0.4772, 0.1063],
[-0.5874, 0.0058, 0.5891, 0.3257],
[-0.6300, -0.0632, 0.6202, 0.3860],
[-0.5675, -0.0843, 0.5478, 0.3589],
[-0.5526, -0.0981, 0.5321, 0.3428],
[-0.5299, -0.1081, 0.5077, 0.3493]],
[[-0.4519, 0.2216, 0.4772, 0.1063],
[-0.5874, 0.0058, 0.5891, 0.3257],
[-0.6300, -0.0632, 0.6202, 0.3860],
[-0.5675, -0.0843, 0.5478, 0.3589],
[-0.5526, -0.0981, 0.5321, 0.3428],
[-0.5299, -0.1081, 0.5077, 0.3493]]], grad_fn=<CatBackward0>)
context_vecs.shape: torch.Size([2, 6, 4])第一个维度的上下文向量张量为 2,因为我们有两个输入文本(输入文本是复制的,这就是为什么这些上下文向量对于它们来说完全相同)。第二维度指的是每个输入中的 6 个 Token。第三维度指的是每个 Token 的四维嵌入。
通过权重分割实现多头注意力
前一节中,我们创建了一个 MultiHeadAttentionWrapper 来通过堆叠多个 Single-head Attention 模块实现多头注意力。这是通过实例化并组合几个 CausalAttention 对象完成的。
在 MultiHeadAttentionWrapper 中,通过创建一系列 CausalAttention 对象(self.heads)来实现多个头,每个头代表一个单独的注意力头。 CausalAttention 类独立执行注意力机制,每个头的结果被连接起来。相比之下,下面的 MultiHeadAttention 类将多头功能集成在一个类中。它通过重塑投影的查询、键和值张量将输入分割成多个头,然后在计算注意力后组合这些头的结果。
一个高效的 MultiHeadAttention 类
python
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out,
context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert d_out % num_heads == 0, "d_out must be divisible by num_heads"
self.d_out = d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads #A
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.out_proj = nn.Linear(d_out, d_out) #B
self.dropout = nn.Dropout(dropout)
self.register_buffer('mask', torch.triu(torch.ones(context_length, context_length), diagonal=1))
def forward(self, x):
b, num_tokens, d_in = x.shape
keys = self.W_key(x) #C
queries = self.W_query(x) #C
values = self.W_value(x) #C
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim) #D
values = values.view(b, num_tokens, self.num_heads, self.head_dim) #
queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
keys = keys.transpose(1, 2) #E
queries = queries.transpose(1, 2) #E
values = values.transpose(1, 2) #E
attn_scores = queries @ keys.transpose(2, 3) #F
mask_bool = self.mask.bool()[:num_tokens, :num_tokens] #G
attn_scores.masked_fill_(mask_bool, -torch.inf) #H
attn_weights = torch.softmax(
attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
context_vec = (attn_weights @ values).transpose(1, 2) #I
#J
context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)
context_vec = self.out_proj(context_vec) #K
return context_vec从宏观层面上看,在之前的 MultiHeadAttentionWrapper 中,我们堆叠了多个 Single-head Attention 层,然后将它们组合成一个 MultiHeadAttention 层。MultiHeadAttention 类采取了一种集成的方法。它从一个 Multi-head Attention 层开始,然后在内部将这个层分割成单独的注意力头,如图所示。
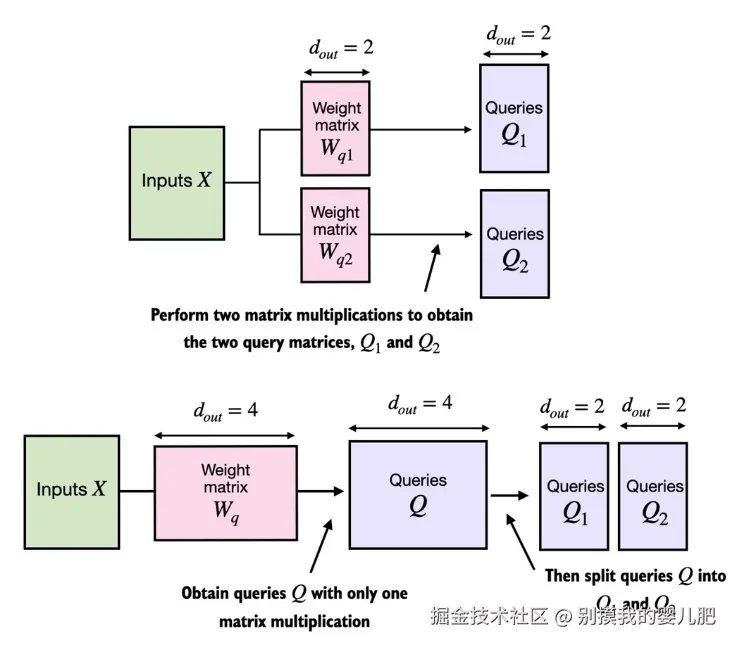 在带有两个注意力头的 MultiHeadAttentionWrapper 类中,我们初始化了两个权重矩阵 Wq1 和 Wq2,并计算了两个查询矩阵 Q1 和 Q2,如图顶部所示。在 MultiHeadAttention 类中,我们初始化一个更大的权重矩阵 Wq,只执行一次与输入的矩阵乘法以获得查询矩阵 Q,然后将查询矩阵分割成 Q1 和 Q2,如图底部所示。我们对键和值做同样的处理,为了减少视觉混乱,这部分处理没有显示出来。
在带有两个注意力头的 MultiHeadAttentionWrapper 类中,我们初始化了两个权重矩阵 Wq1 和 Wq2,并计算了两个查询矩阵 Q1 和 Q2,如图顶部所示。在 MultiHeadAttention 类中,我们初始化一个更大的权重矩阵 Wq,只执行一次与输入的矩阵乘法以获得查询矩阵 Q,然后将查询矩阵分割成 Q1 和 Q2,如图底部所示。我们对键和值做同样的处理,为了减少视觉混乱,这部分处理没有显示出来。
查询、键和值张量的分割是通过使用 PyTorch 的 .view 和 .transpose 方法进行张量重塑和转置操作来实现的。输入首先通过线性层转换(针对查询、键和值),然后被重塑来表示多个头。
关键操作是将 d_out 维度分割为 num_heads 和 head_dim,其中 head_dim = d_out / num_heads。这种分割随后通过 .view 方法实现:将维度为 (b, num_tokens, d_out) 的张量重塑为维度 (b, num_tokens, num_heads, head_dim)。
随后,张量被转置,使得多头维度(num_heads)排在序列长度维度(num_tokens)之前,形成 (b, num_heads, num_tokens, head_dim) 的结构。这种转置对于正确匹配不同头的查询、键和值,以及高效进行批量矩阵乘法至关重要。
MultiHeadAttention 类可以像我们之前实现的 SelfAttention 和 CausalAttention 类一样使用:
ini
torch.manual_seed(123)
batch_size, context_length, d_in = batch.shape
d_out = 2
mha = MultiHeadAttention(d_in, d_out, context_length, 0.0, num_heads=2)
context_vecs = mha(batch)
print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)
#结果
tensor([[[0.3190, 0.4858],
[0.2943, 0.3897],
[0.2856, 0.3593],
[0.2693, 0.3873],
[0.2639, 0.3928],
[0.2575, 0.4028]],
[[0.3190, 0.4858],
[0.2943, 0.3897],
[0.2856, 0.3593],
[0.2693, 0.3873],
[0.2639, 0.3928],
[0.2575, 0.4028]]], grad_fn=<ViewBackward0>)
context_vecs.shape: torch.Size([2, 6, 2])总结
- 注意力(Attention)机制将输入元素转换为增强的上下文向量表示,这些表示融合了所有输入的信息。
- 自注意力(Self Attention)机制通过对输入的加权求和来计算上下文向量表示。
- 在简化的注意力机制中,注意力权重通过点积计算得出。
- 点积是将两个向量的相应元素相乘然后求和的简洁方式。
- 虽然不是绝对必要,但矩阵乘法通过替代嵌套的 for 循环,帮助我们更高效、紧凑地实施计算。
- 用于大语言模型的自注意力机制,也称为缩放点积注意力,其中包含了可训练的权重矩阵来计算输入的中间转换向量:查询、值和键。
- 在处理从左到右阅读和生成文本的大语言模型时,我们添加因果注意力遮蔽(CausalAttention Mask)以防止大语言模型访问后续的 Token 。
- 除了使用因果注意力遮蔽将注意力权重归零外,我们还可以添加 Dropout 遮蔽来减少大语言模型中的过拟合问题。
- 基于 Transformer 的大语言模型中的注意力模块涉及多个因果注意力(CausalAttention)实例,这称为多头注意力(MultiHeadAttention)。
- 我们可以通过堆叠多个 CausalAttention 模块来创建一个 MultiHeadAttention 模块。
- 创建 MultiHeadAttention 模块的更有效方式涉及到批量矩阵乘法。