实时查看日志数据有助于确定应用程序的管理方式和基础设施的扩展方式。为了确定并解决最终用户遇到的问题,我们往往需要获取来自多个来源(如CDN、安全系统、服务器端等)的日志,然而这可能导致复杂的基础设施设置,会产生不同级别的可见性需求,并且由于数据量大,往往还会产生较高的数据出口成本。

如您所在的企业也在考虑采购云服务或进行云迁移,
点击链接了解Akamai Linode解决方案,现在申请试用可得高达500美元专属额度
为了实现高效、可预测且具有成本效益的可观察性工作流,一种方法是实施基于云的多路复用解决方案,在将日志数据发送到相关DevOps团队之前,先进行数据摄取和解析。结合Akamai的DataStream边缘日志报告,多路复用可以帮助企业管理日志的传输方式和位置,提升数据安全性,并降低整体成本。
本文概括介绍了可观察性工作流中的业务挑战、集成和迁移的关键要点,并展示了使用Linode Kubernetes Engine(LKE)运行Elastic Stack(ELK)和Vector的多路复用参考架构。
DataStream和多路复用工作流
以下是在可观察性工作流中使用多路复用与DataStream的大致步骤:
- 运行DataStream的边缘服务器接收客户端请求。
- DataStream将日志数据作为单一流输出到运行多路复用软件解决方案的LKE集群,该解决方案由ELK栈和Vector组成。
- ELK和Vector摄取日志数据,对日志进行分析、解析,并输出到用户定义的对象存储端点。
- 区域对象存储桶用于存储已解析的日志数据。
应对不同挑战
· 跨团队管理可观察性需求
使用多路复用将日志数据发送给需要的团队。
许多企业(尤其是大型企业)往往需要将特定日志数据发送给多个地理区域的特定团队。然而,并不是每个地区的每个团队都需要(或应该拥有)每一条数据来达到所需的可见性水平。处理未经筛选、未经解析的日志数据不仅耗时易出错,而且也会造成不必要的安全风险。
将多路复用方法引入可观察性工作流,可确保相关DevOps团队只获取他们所需的数据。这不仅提高了数据安全性,还能提升效率并降低整体日志存储成本。
· 海量数据
通过避免传输不必要的数据来降低成本。
日志数据对于有效的可观察性工作流至关重要。然而,日志数据庞大、数量众多且持续不断;大量日志数据必须传输到某个地方,如果在到达目的地之前没有正确解析,就可能造成不必要的存储和数据出口成本。
多路复用可提前整理数据并使用数据"标识符"(如日志特定元数据)将已解析日志定向到指定的目的地,从而降低这些成本。这样,不仅日志能被发送给正确的团队,还确保了非必要数据不会首先被发送,从而减少了整体日志存储量。
· 在分布式架构中维持可观察性
确保不同类型日志在需要的地方进行分发。
分布式架构是高可用性、高流量应用的标配。随着分布式架构的实施,往往会涉及多地区、多VPC、多微服务以及与每个组件相关的日志。除了大量数据外,这还可能导致复杂的监控和可见性需求,这些需求可能因地区而异。
将基于云的多路复用与DataStream边缘日志记录相结合,可精确控制CDN、安全系统、服务器端和其他日志如何在多区域基础设施中处理和分发。
· 集成和迁移工作
本文涉及的多路复用解决方案不需要迁移任何与应用程序相关的软件或数据。该解决方案是一种与位置无关的,基于云的管道,位于企业的边缘交付基础设施和日志存储端点(如Amazon S3兼容的桶、Google Cloud Storage等)之间。
通过以下示例,大家可以通过将云端多路复用架构指向Akamai的对象存储(而非第三方对象存储解决方案),借此降低整体数据出口成本。
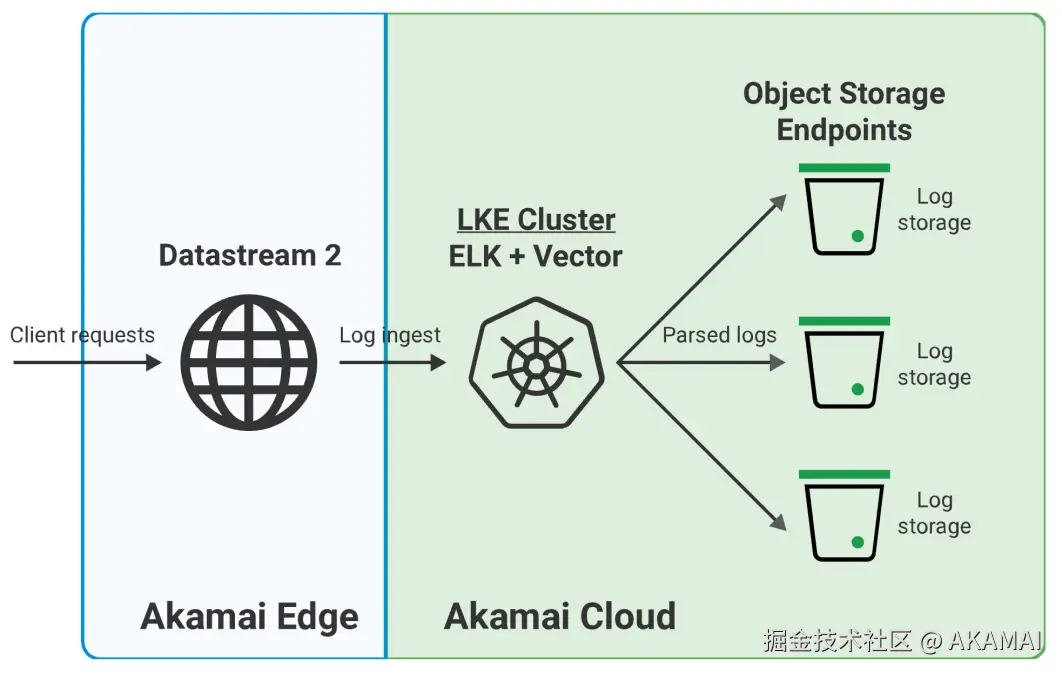
多路复用DataStream设计示意图
下图使用单区域、可扩展的LKE集群运行ELK和Vector,从DataStream摄取并解析单一日志流。解析后的日志被发送到由对象存储桶组成的区域日志处理基础设施,并在那里进行处理和存储:
- 发出请求。最终用户提交应用请求。
- 边缘服务器接收请求。请求被Akamai的边缘基础设施接收,该基础设施运行了DataStream。如果该请求在边缘未缓存,最终用户请求的HTTP数据将被转发到运行用户请求信息的区域SaaS集群。
HTTP数据:HTTP数据传输不受影响,也与基于云的多路复用日志解析解决方案无关。 - 日志发送到云基础设施进行多路复用。DataStream根据最终用户的请求捕获并传输日志信息。日志不是直接发送到区域日志处理基础设施,而是以单一流的形式发送到Akamai Cloud上的单区域LKE集群。
- 日志被解析和分发。运行ELK和Vector多路复用解决方案的LKE集群摄取、处理、排序并将解析后的日志传输到区域本地日志处理基础设施。
- 区域桶接收并存储解析后的日志。由对象存储桶和软件组成的本地日志处理基础设施,会根据解析过程中提供的数据标识符摄取并存储解析后的日志。这些桶位于与运行最终用户查询应用程序SaaS集群相同的区域。
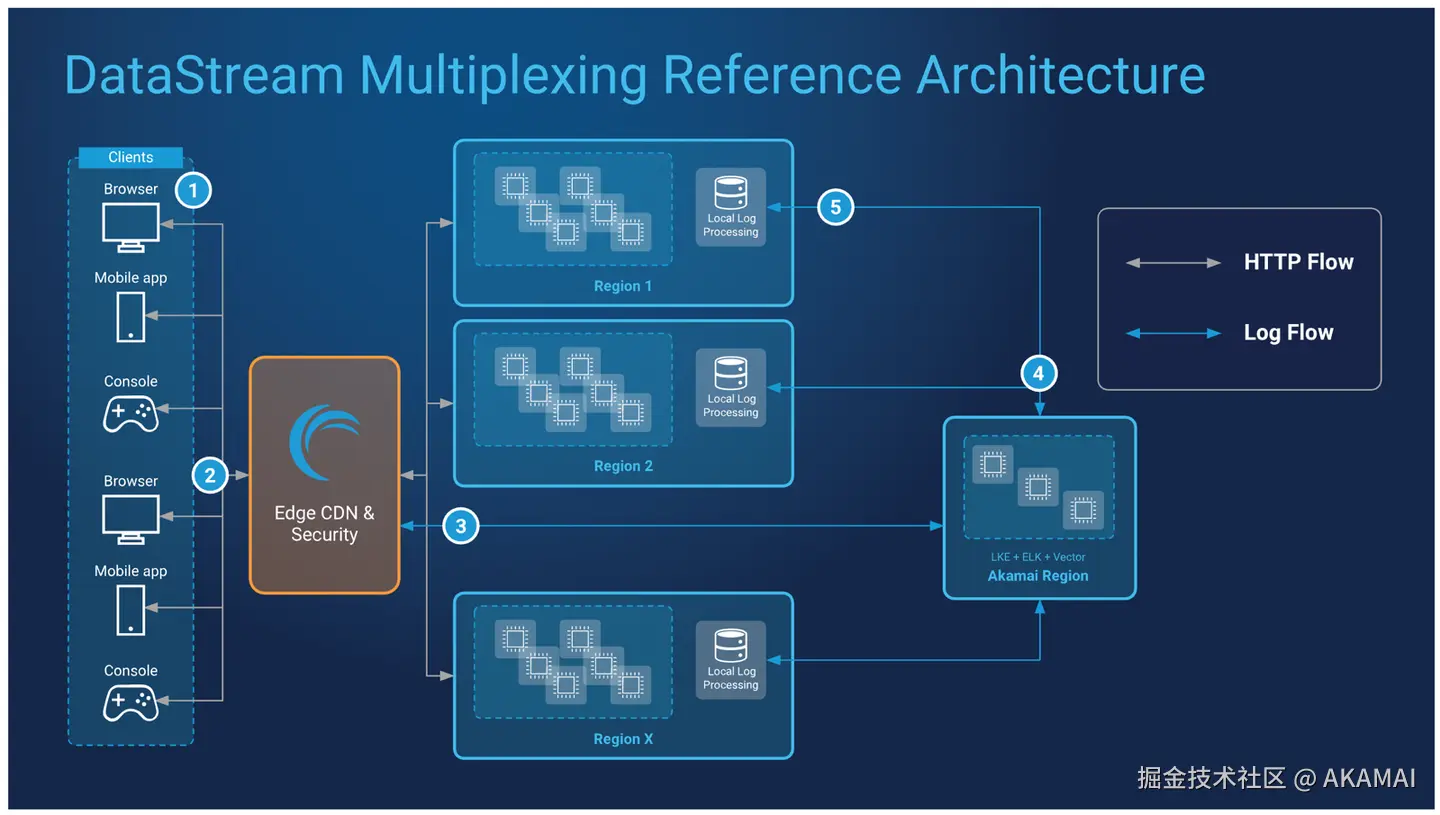
系统和组件
- 边缘CDN和安全性:Akamai的边缘基础设施,接收并路由最终用户的请求和数据。
- DataStream:Akamai的边缘原生日志报告服务,是此场景中使用的边缘解决方案之一。DataStream通过捕获性能和安全日志并将这些数据流传输到用户定义的目标,提供对流量交付的可见性。
- SaaS集群:跨多个区域的节点集群,运行应用程序后端。
- 本地日志处理:用于摄取LKE集群输出的日志数据的对象存储桶和软件,该LKE集群运行日志多路复用解决方案。与应用程序的SaaS集群位于相同的区域。
可选的其他区域处理软件包括本地ELK栈或TrafficPeak。 - LKE:Linode Kubernetes Engine是Akamai云计算的托管Kubernetes平台。Kubernetes集群可以通过Cloud Manager、Linode CLI或Linode API快速高效地部署。
- ELK:由Elasticsearch、Kibana和Logstash组成的软件栈。ELK栈能够可靠且安全地从任何来源、任何格式的数据中获取数据,然后进行搜索、分析和可视化。
- Vector:数据解析软件,用于收集、转换和路由输入/输出数据,包括日志信息。
通过上述解决方案,我们即可在Akamai云计算平台上实施基于云的多路复用可观察性解决方案,确保在将日志数据发送到相关团队之前,先进行必要的数据摄取和解析。在Akamai DataStream边缘日志和多路复用能力的帮助下,企业将能更好地管理日志传输方式和位置,在提升数据安全性的同时大幅降低数据存储和出口成本。
如您所在的企业也在考虑采购云服务或进行云迁移,
点击链接了解Akamai Linode解决方案,现在申请试用可得高达500美元专属额度