我用夸克网盘给你分享了「鸢尾花分类数据集」,链接:https://pan.quark.cn/s/b71fea1ab57a
鸢尾花数据集(Iris dataset)也被称为费舍尔鸢尾花数据集(Fisher's Iris data set),是一类多重变量分析的数据集,在统计学和机器学习领域具有重要地位,以下是它的一些历史背景信息:
首次收集
该数据集由英国统计学家、遗传学家罗纳德·艾尔默·费舍尔(Ronald Aylmer Fisher)在 1936 年发表的论文《The use of multiple measurements in taxonomic problems》中引入,被用于展示线性判别分析这种分类方法。不过,数据本身并不是费舍尔收集的,而是由美国植物学家埃德加·安德森(Edgar Anderson)收集整理的。安德森在加拿大加斯帕半岛上对三种鸢尾花(山鸢尾 Iris setosa、变色鸢尾 Iris versicolor 和维吉尼亚鸢尾 Iris virginica)进行了详细的测量,每种鸢尾花各选取了 50 个样本,测量了它们的萼片长度、萼片宽度、花瓣长度和花瓣宽度这四个特征。
数据特点与意义
- 数据规模恰当:整个数据集共 150 个样本,数据量既不过于庞大使得处理复杂,也不过于微小而无法体现模式,非常适合作为初学者入门和算法验证的基础数据集。
- sepal_length:萼片长度,数值类型。
sepal_width:萼片宽度,数值类型。
petal_length:花瓣长度,数值类型。
petal_width:花瓣宽度,数值类型。
species:鸢尾花的种类,文本类型。 - 特征典型:所选取的四个特征能很好地反映不同鸢尾花种类之间的差异,便于开展分类和聚类等各种数据分析任务。
- 开启先河:它是最早被广泛使用的用于分类问题的数据集之一,为后续大量分类算法的研究和发展提供了标准的测试平台。许多新提出的分类算法都会先在鸢尾花数据集上进行性能验证,以初步评估算法的有效性和优越性。
广泛应用
随着机器学习和数据科学的发展,鸢尾花数据集的应用范围越来越广泛,不仅在学术研究中频繁出现,也被用于教学,帮助学生理解分类算法、数据预处理、模型评估等基本概念和技术。此外,它还常被作为新的数据分析工具和编程语言的示例数据集,用以展示这些工具和语言在数据处理和建模方面的能力。
数据分析与预测示例
python
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report
#显示中文
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 加载数据集
data = pd.read_csv('iris.csv')
print('数据基本信息:')
data.info()
# 查看数据集行数和列数
rows, columns = data.shape
if rows < 100 and columns < 20:
# 短表数据(行数少于100且列数少于20)查看全量数据信息
print('数据全部内容信息:')
print(data.to_csv(sep='\t', na_rep='nan'))
else:
# 长表数据查看数据前几行信息
print('数据前几行内容信息:')
print(data.head().to_csv(sep='\t', na_rep='nan'))
# 设置图片清晰度
plt.rcParams['figure.dpi'] = 300
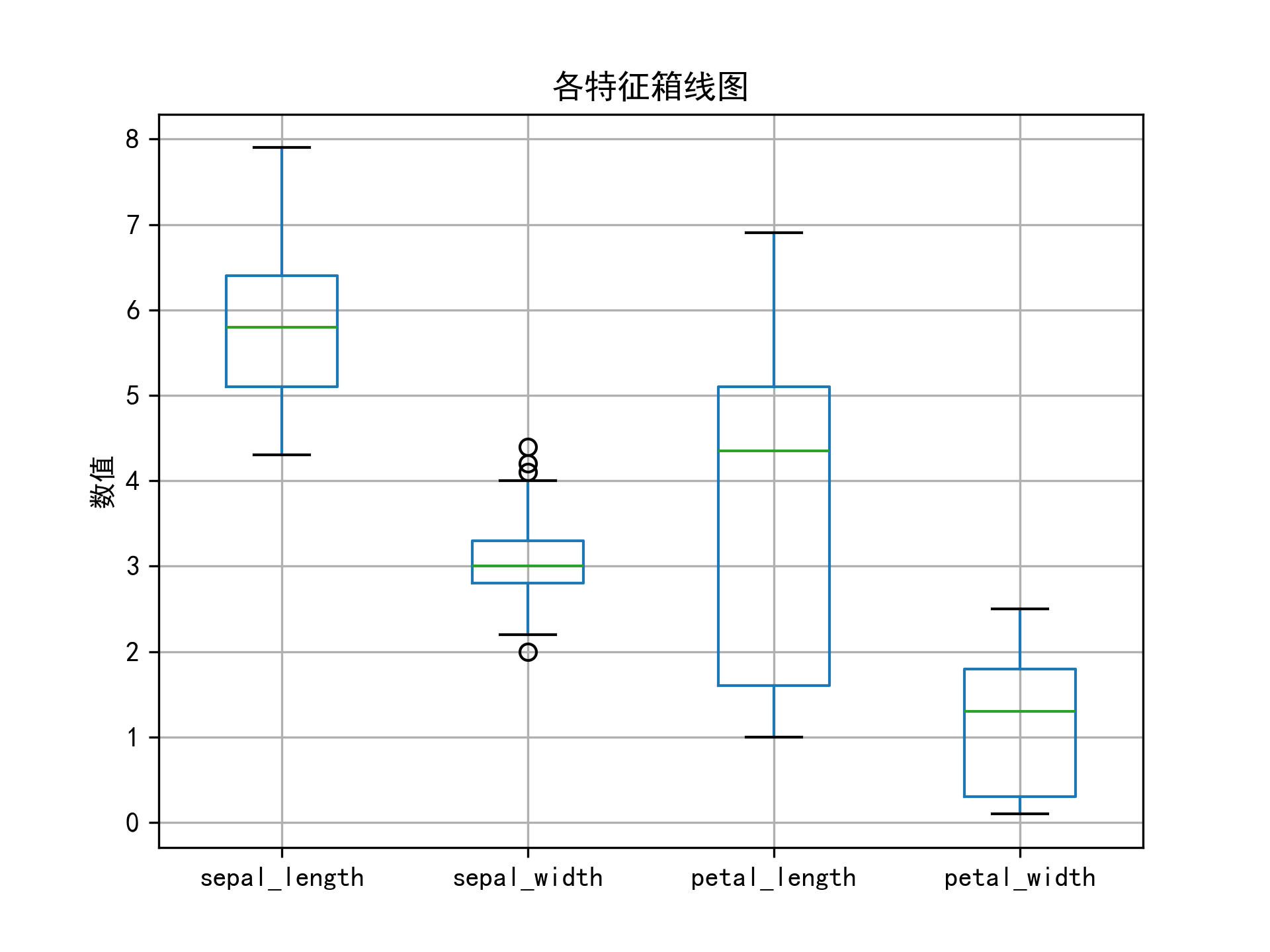
# 绘制各特征的箱线图
data.iloc[:, :-1].boxplot()
plt.title('各特征箱线图')
plt.ylabel('数值')
plt.show()
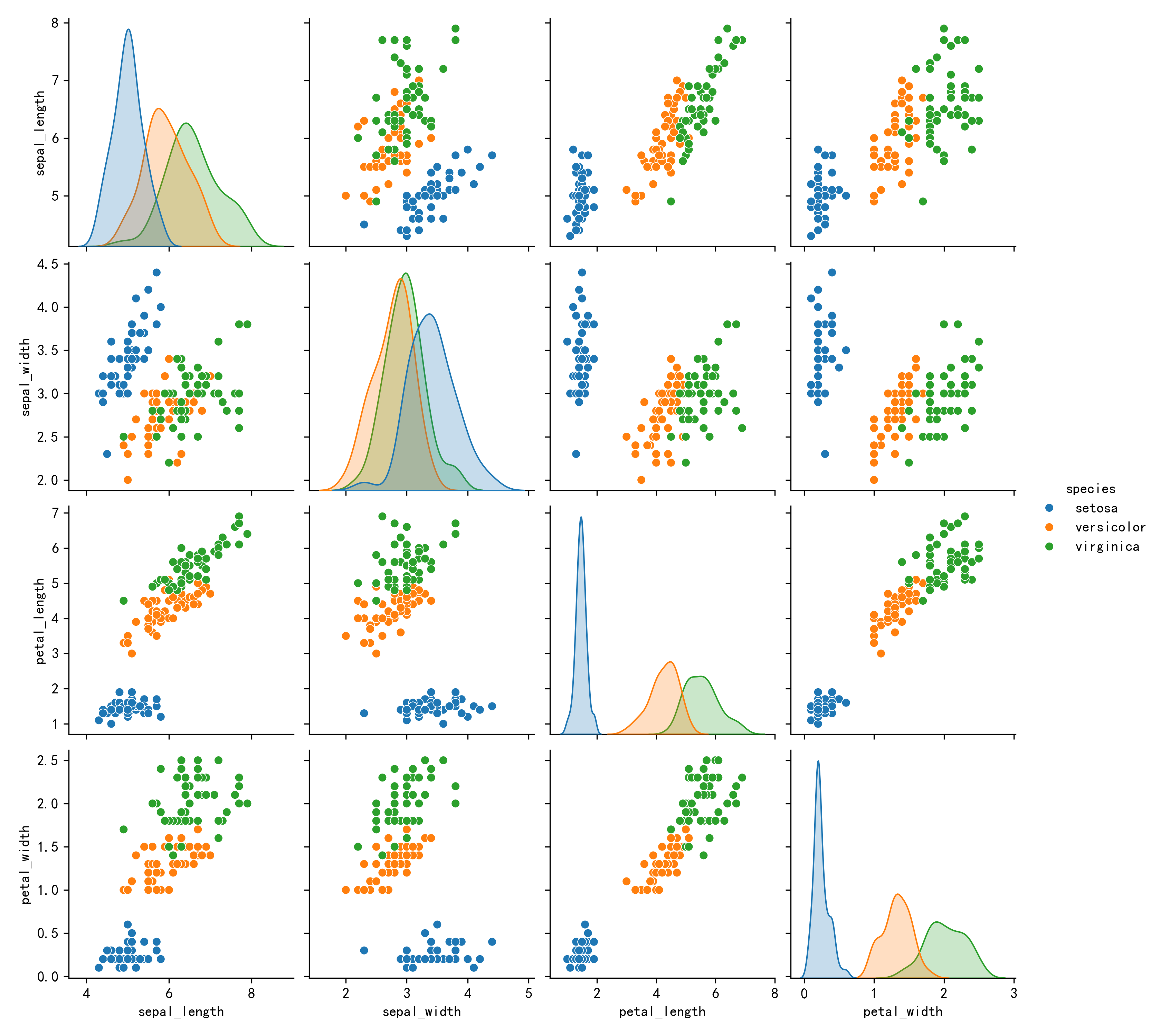
# 绘制特征间的散点图矩阵
sns.pairplot(data, hue='species')
plt.show()
# 准备特征和目标变量
X = data.drop('species', axis=1)
y = data['species']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 构建决策树分类模型
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
print('模型准确率:', accuracy)
print('分类报告:')
print(report)结果输出:
数据基本信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal_length 150 non-null float64
1 sepal_width 150 non-null float64
2 petal_length 150 non-null float64
3 petal_width 150 non-null float64
4 species 150 non-null object
dtypes: float64(4), object(1)
memory usage: 6.0+ KB
数据前几行内容信息:
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosa
模型准确率: 1.0
分类报告:
precision recall f1-score support
setosa 1.00 1.00 1.00 19
versicolor 1.00 1.00 1.00 13
virginica 1.00 1.00 1.00 13
accuracy 1.00 45
macro avg 1.00 1.00 1.00 45
weighted avg 1.00 1.00 1.00 45
Process finished with exit code 0使用决策树分类模型对鸢尾花种类进行预测,得到以下结果:
模型准确率:模型准确率达到 1.0,这意味着在测试集上,模型的预测完全正确,没有出现任何错误分类的情况。
分类报告:对于每个类别(setosa、versicolor、virginica),精确率(precision)、召回率(recall)和 f1 分数(f1-score)均为 1.0。这表明模型在各个类别上的表现都非常出色,能够准确地识别出每一种鸢尾花的类别。
不过,模型准确率为 1.0 可能暗示数据相对简单或者测试集规模较小,导致模型过度拟合测试数据。
为了更准确地评估模型的泛化能力,可以考虑增加测试集的比例、使用交叉验证等方法进一步验证模型性能。