剧情简介
接下来,你将开始参与服务端性能测试。此时,你已经开始参与偏有难度的专项测试工作,需要自主学习、总结新知识了。比如服务器性能测试常见的测试指标及相关术语,QPS、TPS、慢查询、GC、内存泄漏、服务崩溃、微服务架构、k8s等等。
测试目的
- 评估承载能力:确定服务器在不同场景下能够稳定支撑预定玩家数量,为游戏的运营规模提供参考。
- 发现性能瓶颈:找出服务器在高并发情况下的性能瓶颈,如 CPU、内存、IO、网络带宽等方面的问题,以便进行针对性优化。
- 验证系统稳定性:检验服务器在长时间高负载运行下的稳定性,确保不会出现崩溃、卡顿等问题,保障玩家的游戏体验。
- 评估服务器配置最优方案:通过不同梯度的压力配置,可找出服务器配置最优选择,帮助节约服务器及网络资源开销。
测试标准
常见的测试标准,可根据实际游戏类型及项目情况补充,如:
- 各压力场景下CPU使用率<70%,内存无明显内存泄漏、溢出表现,磁盘IO<30%;
- 针对单服单场景测试,必须满足运营标准容量下,各事务90%响应时间<1s,各事务成功率99.9%;
- 稳定性测试(服务器进程不重启),运行24小时以上,无内存泄漏,各事务成功率99.9%。
测试流程
- 基线确定
- 场景设计
- 场景评审
- 环境及工具准备
- 环境及工具验证
- 执行测试
- 数据整理及分析
- 测试报告
- 持续优化
1、基准确定
一般分2种情况,未上线 和 已上线(包括删档测试),同时包括场景人数分布及TPS预估。
未上线
未上线的项目,测试基准以产品、运营及研发同事确认预期目标,以设计目标及运营目标为基准。
如:单服注册用户数5W,同时在线1W。A场景100人,TPS预估50;B场景50人,TPS预估20。TPS预估时也可按人数1比1,如50人TPS默认50,或根据场景放大,如50人TPS放大1倍,则TPS=100
(未上线项目完成常规测试,一般还会有额外的梯度压测,比如:5000/1000、10000/3000、20000/5000,通过不同的梯度验证服务器的性能情况)
已上线
需运营同事从线上所有服务器找出峰值数据:注册人数/同时在线人数最多的,并从中找出参考段数据(找同时在线人数最高点,一般需取前后一段时间范围,根据真实用户数据计算场景人数分布及TPS)
参考点一般如:
1、开服时长,比如7天内、7天后的综合场景数据(考虑功能开启对人数的影响);
2、峰值人数,参考场景内同时在线人数最高点。
2、场景设计
单场景
一般情况下在研发阶段中后期,需要针对核心功能进行单场景测试+综合场景测试,或发布后有大的新增功能。
(如:登录、跨服战斗、聊天、抽奖、活动、充值等核心功能,场景需要关注相关协议。)
综合场景
在游戏进入后期及发布后,需要进行综合场景测试,一般用于常规压测+稳定性测试。
(真实场景如:如同时在线10000人,5000人在战斗,1000人在聊天,100人在抽奖,50人在充值...)
-
场景人数比例
场景人数 = 当前场景(moduleId)的所有请求数之和
场景比例 = 当前场景(moduleId)的所有请求数之和 % 所有请求数之和
如果是在已有版本上新增功能,需重新折算,如:
场景使用人数 = 线上/历史数据 ± 预估值
场景折算比例 = 当前场景比例 %(100% + 新功能%总和)
即如果增加新功能A、B,预计A功能使用约5%,B使用约10%,原场景A使用比例10%,则
折算后比例 = (10%) %(100%+ 5%+10%)
-
放大倍数
一般情况下还会根据情况额外放大TPS倍数(或预期测试完成,梯度加压测试时),以确保系统能稳定支撑预期设定目标。
放大倍数 = 1.5
(如固定倍数1.5,可根据项目及场景调整,如抽奖,同时50人,TPS预估20,放大倍数后TPS=30,压测机器人该场景就需按TPS30实现)
场景TPS = 预估TPS * 放大倍数
3、场景评审
评审
整理好场景数据后,发起会议(通知相关人员)参与性能测试场景评审。
场景最终效果参考,如:
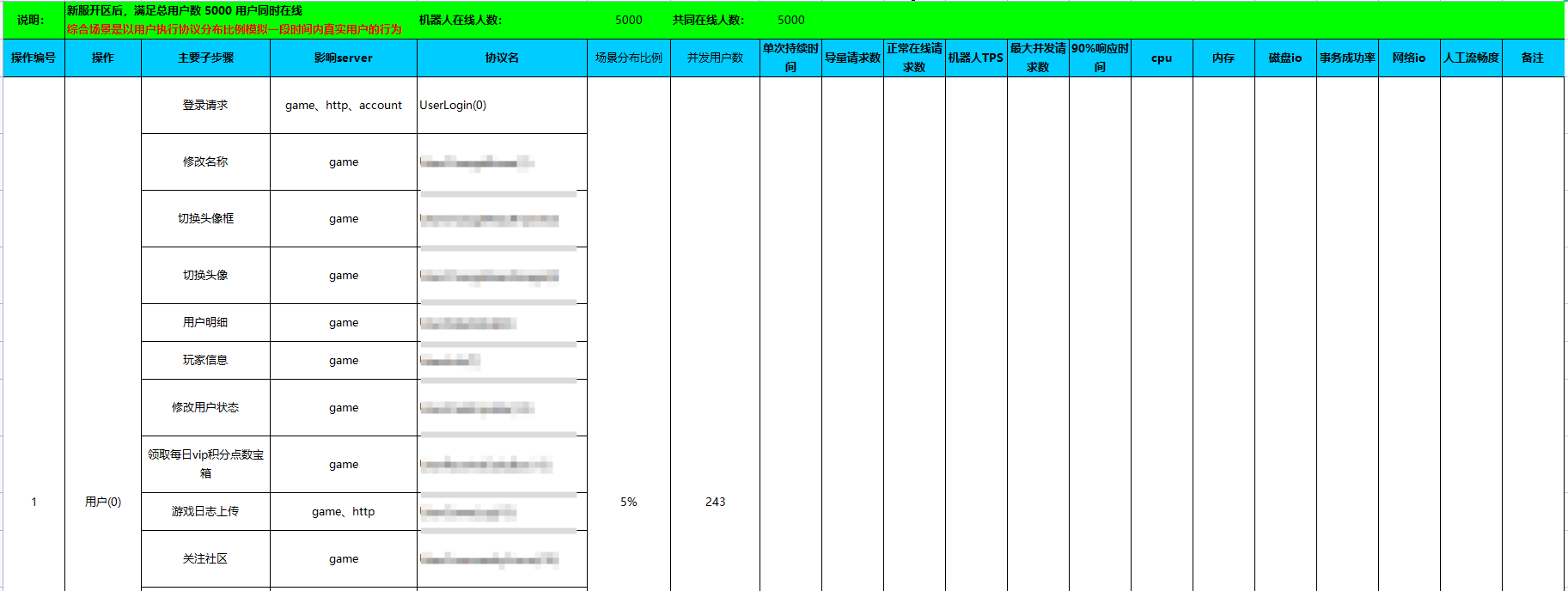
信息同步
同步信息,并开始后续准备
4、压测准备
环境准备
场景评审通过后,向运维申请测试服务器资源、网络资源等。根据游戏服务部署方案进行,如rancher多集群部署,N个登录服、N个战斗服、N个聊天服、N个游戏服、N个充值服。
监控服务及权限
游戏服务及压测服务都有监控及后台管理,需要提前申请好相关资源及权限,一般需向安全团队、运维及项目组申请相关权限。比如常用的监控及后台工具,如:rancher、grafana、skywalking、堡垒机权限、项目运营统计后台等等。
压测工具开发
压测机器人,一般由服务端开发,也有少部分是客户端开发或QA开发。考虑复杂度、保密性,一般由测试人员提出工具需求,服务端同事实现。
经过场景评审,需配合服务端同事持续对接机器人方案,比如场景需求:场景内协议触发频率及比例,工具需求如:配置控制协议触发频率、时间控制、启动方式等等。
5、环境验证
服务器验证
当运维配置完成测试服务器后,进入服务集群管理,验证服务是否按预期部署,比如检查rancher及linux服务器上的服务进程,机器配置等。(游戏相关服务、压测机器人服务分别部署和运行在独立的服务器上。)
压测机器人验证
机器人的实现其实就是无界面的程序,模拟用户端并触发各功能协议,但其中各类协议涉及到前置条件等复杂过程,且需考虑真实场景情况,需要通过多轮测试验证机器人的准确性及稳定性。
一般需要通过多轮测试验证机器人和配置符合测试预期,检查一般包括:
-
测试协议是否齐全
-
协议响应是否有超1s
-
TPS是否达预期
-
协议和场景预期是否匹配,发多、发少了
建议方案:
1、整合功能协议:线上协议 + 新增功能协议;
2、运行机器人程序,运行一段时间,查看后台流量数据统计,遍历检查所有功能协议是否正常触发,同时计算各场景协议占比及TPS,验证是否符合场景分布和TPS预期,同时参考线上真实数据比例(比如线上A功能某协议1h内只发送100次,实际机器人发了10000次);也需要检查各协议的请求、平均响应时长、最大响应时长等;
3、根据计算结果,记录缺失和数据异常情况,和机器人研发同事对接测试结果,调整或优化机器人工具;
4、重复上述过程,直到数据符合预期。
监控工具验证
运行压测机器人后,需要确保各类监控工具正常,比如服务监控(rancher、grafana、skywalking)、管理后台数据监控(协议相关、机器人数量等)。
6、执行测试
运行机器人服务
根据机器人工具的使用规则,把机器人工具部署到压测服务器上,完成服务器连接及相关配置,设定运行时长等,就可以执行工具,同时定时监控即可,直至达到预期测试时长。
比如有配置项配置(也可能没有,全AI自动逻辑),如:
shell
# 机器人数量
numOfRobot=50
# 机器人id头,测试时会用这个头信息拼接一个index,以确认一个机器人uid
flagOfRobot=cb1
#消息一条条地发(就是要等着一条回来后,再发下一条)
isSendStepByStep=true
# 轮询(秒)
deltaTime=0.05
# 轮询Run(秒)
runDeltaTime=0.1
shortRunDeltaTime=1
longRunDeltaTime=5
# 测试开始时间
begainTime=2023-10-20 02:00:00
#登陆完成后,开始后续测试的时间点
begainTestAfterLogin=2023-10-20 02:30:00
# 测试结束时间
endTime=2023-10-20 03:35:00
# 机器人取得账号排队间隔毫秒(http)
accountHttpIntervalMs=1000
# 联盟创建最大数量
allianceNum=1
#邮件接收人id
mailReceiveId=
#聊天发送频率(毫秒)
chatSendInterval=5000
#布阵战斗频率(毫秒)
formationInterval=8000
#大地图搜索怪物等级
mapSearchLevel=1
#统计单独的接口 module-cmd,例:Building-0
debugCmd=
#关闭日志 false/true
closeLog=true
#登录后,发送gm指令(注意用`号分隔多条指令)。 例:!building_10`!buildings
gmcmds=!add_2|8888|55555555`!building_10
#只运行只指定模块 Activity|Alliance|AllianceBuild|Army|Battle|Build|CastleGame|Chapter|Chat|Com|DarkMap|Guide|Hero|Mail|Map|MapBattle|Market|Push|Radar|Rally|Refit|Station|Task|Tech|Travel|TreatArmy|User|WorkRoom
onlyRunModuls=Build|Com|Push|Chat
#全服玩家攻击一个玩家 false/true, 目前的处理是默认取得一个机器人为目标,其它机器人攻击它。注意要把机器人的保护状态去掉
allUsersAttackOneUser=false
allUsersAttackOneUserTime=2023-03-21 16:05:00
#是否生效指令发送的速率 true/false
enableCmdSendSpeedOffset=true
#发送cmd的速率的offset,要enableCmdSendSpeedOffset为true才生效
cmdSendSpeedOffset=3
#队列只处理王座战
onlyAttackWander=false
#参加王座战的人数
numOfAttackWander=10
############################################
# 网关地址
gateWay=http://k8s-stress-nlbinter-1cd433ba76-539afd0e19e51231.elb.us-west-2.amazonaws.com:23001
# 服务器ip地址
ip=k8s-stress-nlbinter-1cd433ba76-539afd0e19e51231.elb.us-west-2.amazonaws.com
# 服务器端口
port=18181
#最大线程数量
threadCount=16运行机器人程序,每种机器人运行方式可能不一样,根据实际情况执行即可,
shell
# 1、进入机器人目录
cd testRobot/
# 2、启动机器人程序,此时需要指定使用的配置文件,
# 默认 total_cfg_common_50_create 是创建用户时的配置, total_cfg_common_50是测试时使用的配置
# 比如创建用户
nohup ./testRobot -initCfg /data/testRobot/total_cfg_common_50_create/common_test_create_bot.json &
# 执行综合场景测试及稳定性测试
nohup ./testRobot -initCfg /data/testRobot/total_cfg_common_50/common_test_release.json &
# 等到配置的开始时间,查看进程是否起来
netstat -anp|grep pid
# 机器人进程起太多,会导致进程无法正常运行,需要手动杀进程
kill -9 $(pidof testRobot)
# top查看当前进程, 1查看各cpu详情
top
1
# 等到配置的开始时间,查看进程是否起来
netstat -anp|grep pid
# 查看错误日志,nohup.out
cat nohup.out如果需要单机多进程起机器人,可以多放2个目录,在各自目录下分别起testRobot即可,注意路径。
shell
脚本多进程启动,一般需要稳定性测试时使用,其他时候单独起即可
```shell
# 查看启动nohub的进程,并获取进程号
pid1=`ps -ef | grep "/data/testRobot/testRobot" | grep -v grep | awk '{print $2}'`
pid2=`ps -ef | grep "/data/testRobot2/testRobot" | grep -v grep | awk '{print $2}'`
# 打印进程
echo $pid1 $pid2
# 杀死进程
kill -9 $pid1 $pid2
# 重启进程
nohup /data/testRobot/testRobot -initCfg /data/testRobot/init.json > testRobot1.log 2>&1 &
sleep 30
nohup /data/testRobot2/testRobot/testRobot -initCfg /data/testRobot2/testRobot/init.json > testRobot2.log 2>&1 &
# 重启后查看进程
ps -ef | grep "/data/testRobot/testRobot" | grep -v grep > /data/status.txt
ps -ef | grep "/data/testRobot2/testRobot" | grep -v grep >> /data/status.txt
# 打印重启时间
echo "restart time:" >> /data/status.txt
echo `date` >> /data/status.txt监控跟踪
-
服务管理后台
进入零信任平台,游戏服务管理后台,查看机器人数量、TPS、流量数据是否正常
注意时区,utc查询时间需UTC时间,即系统当前时间-8小时
只能查整点数据。非整点如果点清理数据就没了,注意测试时间段。测试的时候,为了随时可以测,可以在开始测试前清理数据,到达预定时间后,复制出本次数据,提高效率。
-
SkyWalking
-
查看 JVM
CPU、内存、GC情况,一般是压测x服,根据测试配置选择
点击服务器之后,选择instance,点击下方的实例,查看压测服的性能监控
-
查看 数据库
-
-
Rancher:
一般在测试完成后,通过rancher、grafana查看服务器数据。
7、数据整理及分析
测试数据输出后,整合结果,根据各场景数据计算并分析结果,参考结果文档:
计算TPS
计算方式:场景协议请求总数 / 协议请求时长s(请求结束-请求开始)
根据后台导出的统计数据进行计算,这里要注意时间段,有些场景只在某些时间段触发,所以不能用所有的测试时间段计算,只能用该场景相关协议的最早、最晚时间。如果还要细分,还得精确到每个协议上,但一般不会,除非占比非常大的情况。
统计数据参考,如:
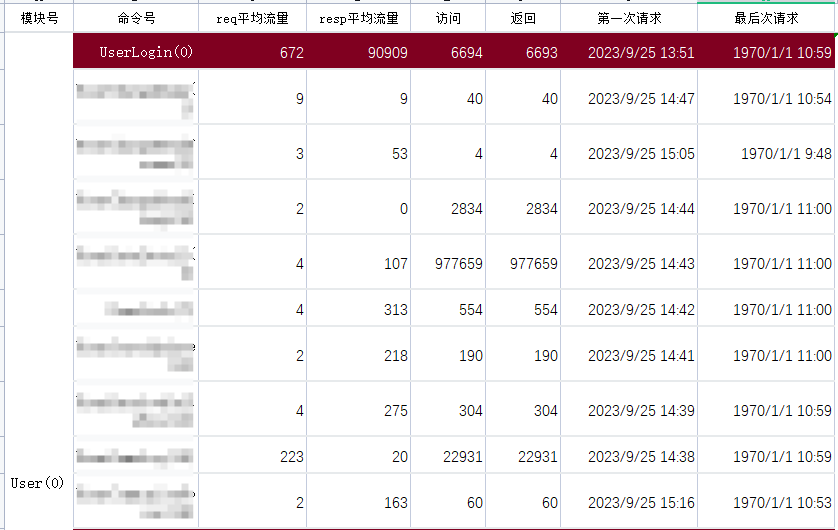
计算CPU、内存(rancher/ Grafana)
如图:
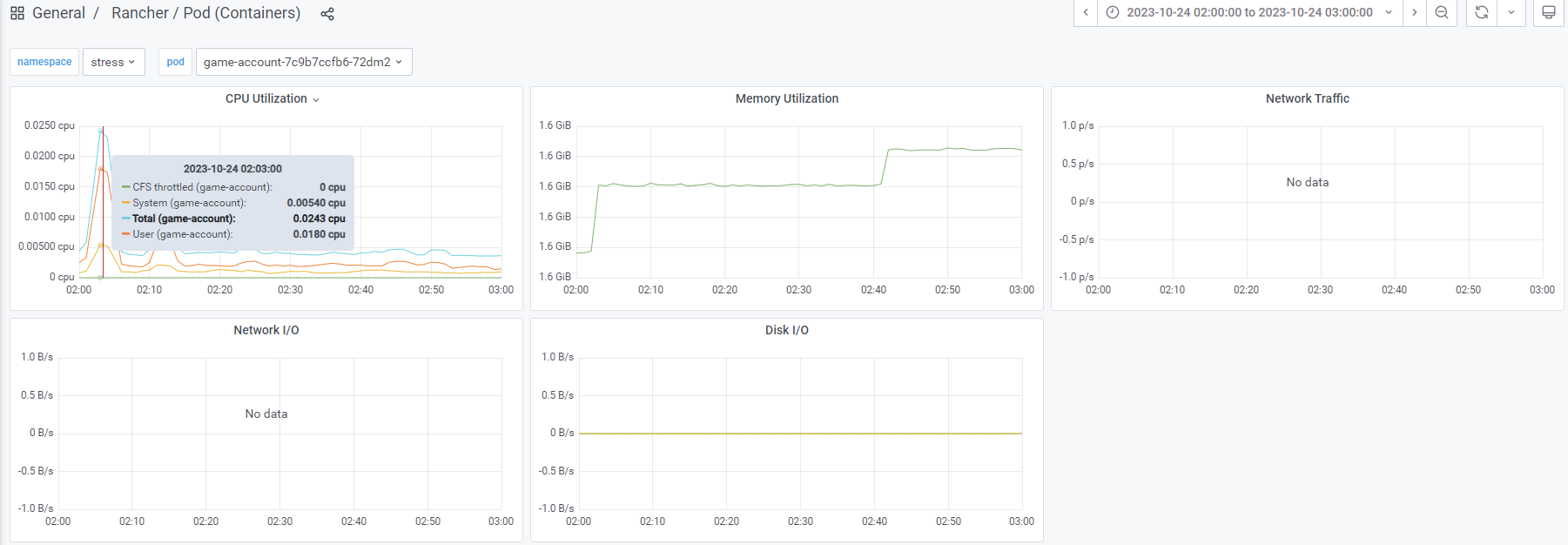
选取规则,从当前服务选取最高pod,再在最高pod内选取最高点和稳定范围点
计算规则:
CPU峰值:选CPU最高点 / 核心数, 如:占了0.5个CPU,服务器8核, 计算结果= 0.4 / 8 * 100% = 5%
CPU均值:计算公式相同,选取范围从最高的一段稳定范围内随机选取1个点即可。
MEM内存:直接取最高点即可。
磁盘IO、流量IO(grafana)
如图:
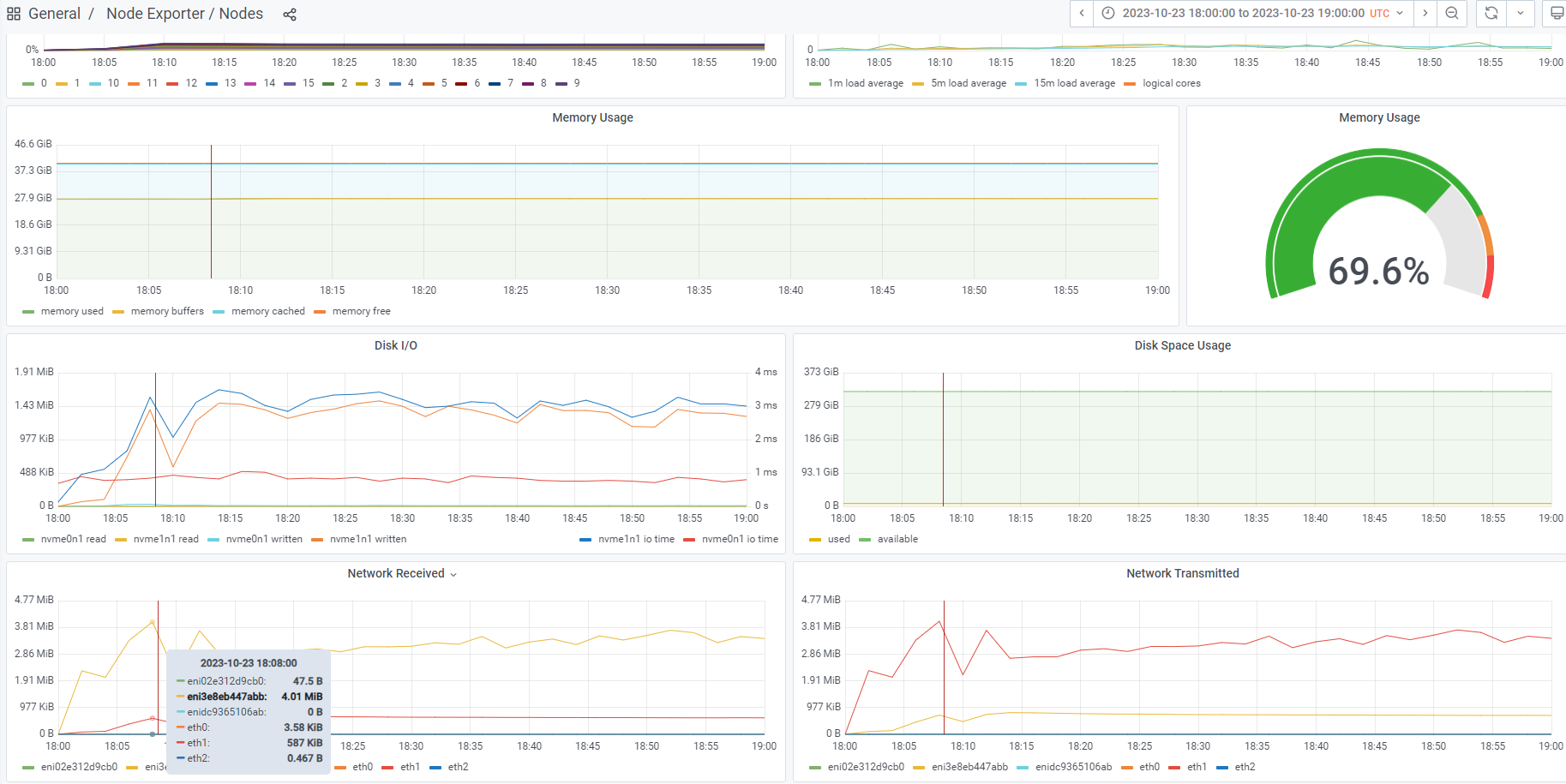
Grafana内点击General,点击Exporter/Nodes
选取对应服务器的 ip,在Pods/找到对应的服务,看Node ip
选取规则:选取最高点
计算方式:所有written相加,注意单位并转换
网络流量(grafana)
特别是海外游戏,流量是要钱的,这种情况需要特别针对流量进行优化。
选取规则:选取最高点,分为recieve和trans
计算方式:所有相加,注意单位并转换
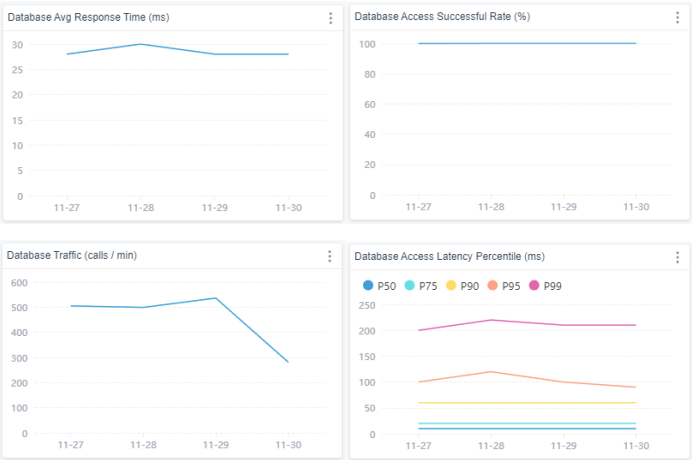
DataBase
数据库方面,关注内容:
- 平均响应时长
- 成功率
- 慢查询

JVM情况(Java后端时)(SkyWalking )
如图:
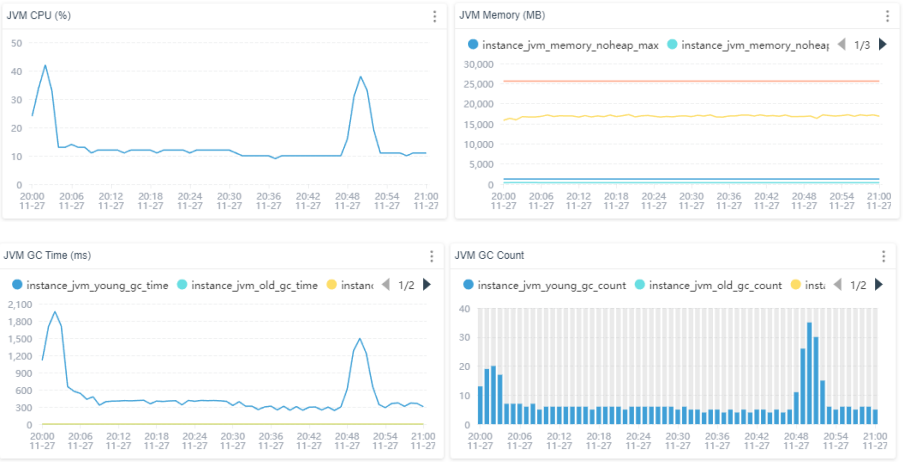
关注内容(不超过研发给的上限即可):
- CPU(一般是70%)
- Memory(比如40G内存,一般不超30GB,持续增长要看服务器的处理方式)
- GC次数(oldGC一般在运行前会触发,中途触发或者次数较多可能有异常)
事务成功率
计算规则:响应总数 / 请求总数 * 100%
(如触发了1000000次请求,响应了999999,事务成功率≈99.99%)
90%响应时间
计算规则:按单场景算时,各区间段的响应总数累加之和 / 90% >= 响应总数时,此时对应的最后区间段就是90%响应时间
(就是计算依次累加区间的请求数计算,直至总数>=90%,比如1ms、5ms、50ms、100ms累加后符合,则90%响应时间=100ms)

体验流畅度
在执行测试的同时,也需要真人体验,通过测试包进入压测服正常游戏,体验各个功能。根据场景记录体验情况,如有卡顿或响应慢等异常情况,则记录体验问题
8、测试报告
报告内容,参考如:
-
固定title

-
测试结论
- 测试需求
注册用户xx,同时在线xx,服务端性能表现符合预期要求,无异常情况。 - 测试风险
本轮测试的情况介绍,一般包括场景介绍、场景结果分析、问题列表
- 测试需求
-
测试详情
-
场景1
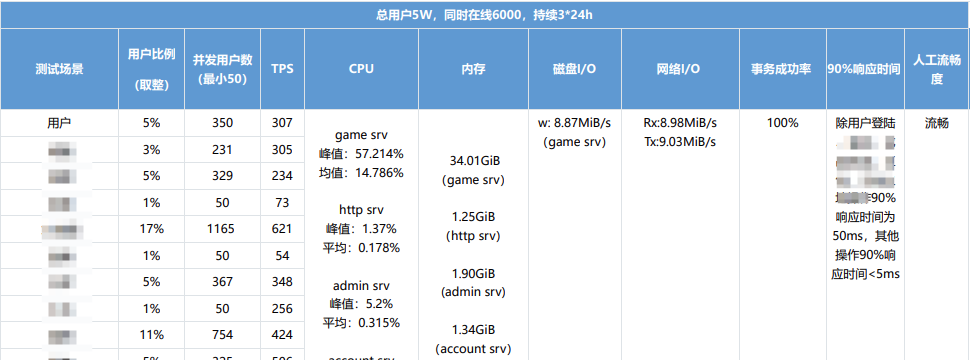
数据截图及数据说明,参考上述内容,包含CPU、内存、JVM(如有)、DB等
场景数据统计后结果,如:
-
场景2
同场景1分析及统计数据
-
日志增量(接了监控的,如欧若拉)

-
-
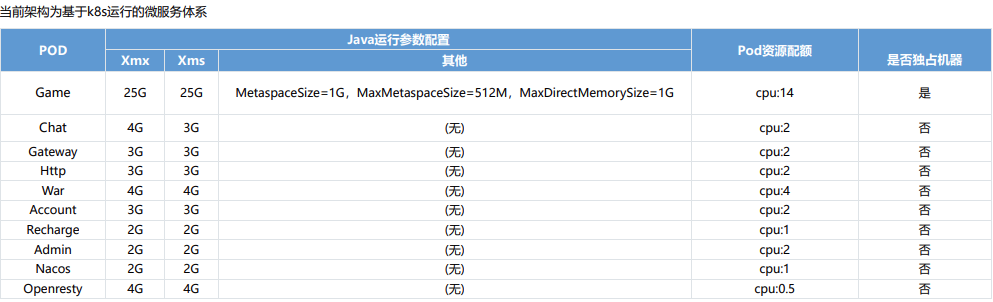
服务器配置说明
-
性能标准
各压力场景下CPU使用率低于70%,内存无明显内存泄漏、内存溢出现象,磁盘IO低于30%。
针对单服的综合场景的测试,必须满足运营标准容量下,各事务90%响应时间<1秒,各事务成功率>99.9%。
稳定性测试(服务进程不重启情况下,持续请求)运行10小时以上,无内存泄漏,各事务成功率>99.9%。
9、持续优化
服务器性能测试是一项复杂、琐碎、反复的团队工作,需要足够的耐心和团队协作精神。测试过程中需要根据项目情况,实际的业务场景,动态调整测试的策略,和产品、研发等同事保持有效的沟通方式,保证测试过程中工作正常开展完成。
多和产品、研发同事沟通压测需求及场景,学习了解压测机器人实现方案,不断总结优化场景设计、机器人实现方案;持续学习,不同的项目,不同的技术栈,都会遇到不一样的问题和挑战,只有保持空杯心态,不断学习,才能不断丰富经验,持续提升测试能力;
把遇到的问题和经验记录下来,把模板格式不断优化,参考标准随技术变革不断更新。(更新模板文件及标准);
规范化存储各版本报告,形成纵向对比,记录版本性能数据变化。(固定目录规范化存储)