1、什么是Embedding?
Embedding(嵌入)是指把文本(也可能包括图像、视频等其他模态数据)转成能表达语义信息的浮点数向量,向量之间的数学距离可以反映对应文本之间的语义相关性。
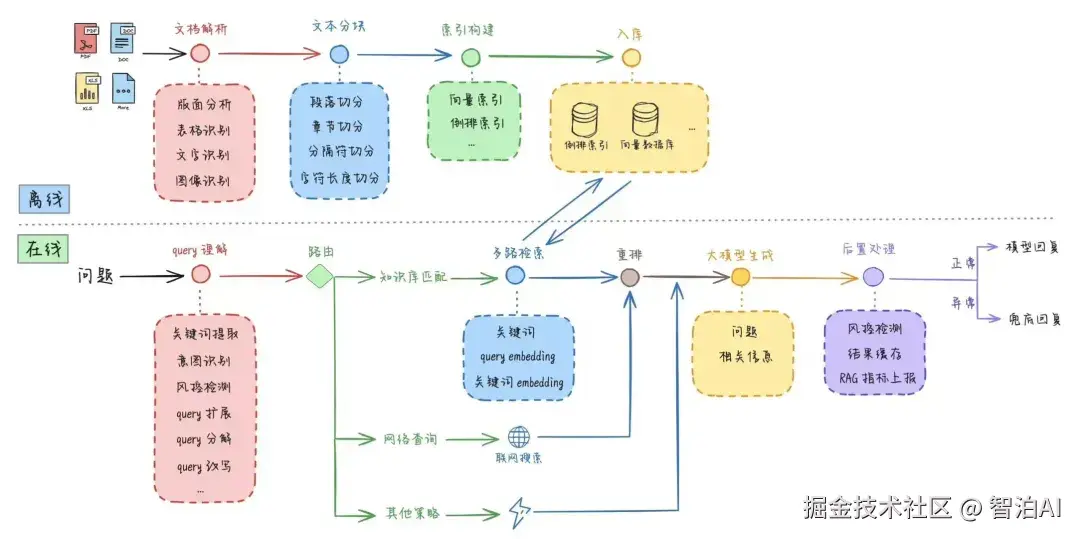
2、从文本到Embedding的流程
Embedding的生成方式,主要分两种情况:
1)大模型推理中的Embedding(Token级)
文本先通过分词器拆分成最小语言单位token,例如:"unbelievable"→"un","believ","able"
接着查询词表,将每个token被映射成一个数字编号,比如:"un"→1087。
根据编号查询Embedding矩阵,快速取出对应的浮点数向量,例如:"un"→0.24,-0.31,0.88,..., 0.05。
生成Token级的Embedding,是大模型理解输入文本的第一步。

2)独立使用的Embedding(句子/文档级)
如果需要表示一整句或一段文本(比如在RAG中检索),就不能只查表了。
常见做法是:将文本输入到一个专门训练好的Embedding模型(如 Sentence-BERT、M3E),通过推理生成一个完整的句子或文档级向量。
这种Embedding包含了更丰富的上下文信息,适合检索、相似性判断等场景。
3、Embedding的本质:语义可被数字表示
在模型训练中,发现文本的语义可以被"压缩"成一组数字向量,且向量之间的距离和方向,能自然反映文本间的语义关系。
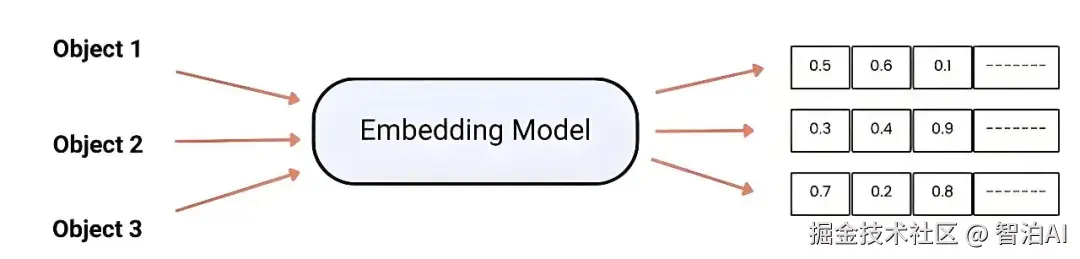
比如:
"猫"和"狗"对应向量的数学距离很近,代表它们语义接近(都是动物)
"房子"和"你好"对应向量的数学距离很远,表示它们语义无关
模型甚至可以学到:king-man+woman≈queen 这样的语义数学关系
这些规律并非人为设定,而是模型通过海量数据自动学习到的。
4、Embedding的应用场景
Embedding不仅用于大模型推理时将输入文本编码为语义向量,也广泛应用于实际场景,例如:
检索增强生成(RAG) :将文档或知识内容转化为向量存储,推理时通过向量检索相关片段,扩展模型上下文,提升回答准确性。
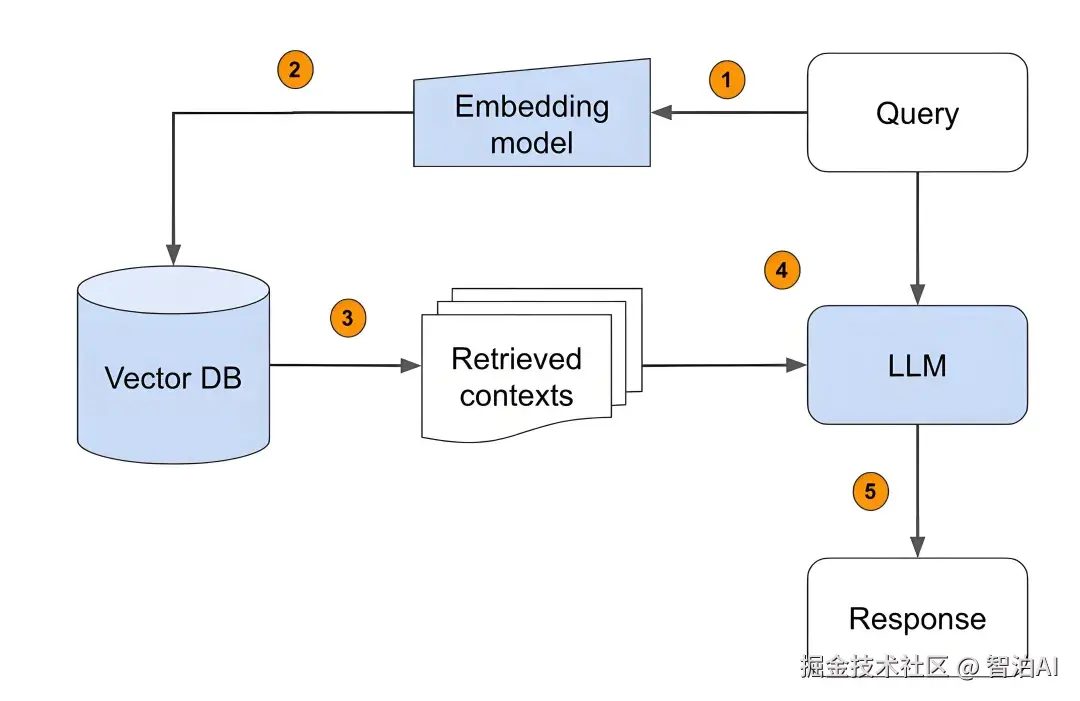
相似性判断:比较文本向量的距离或角度,判断语义一致性或检测重复内容。
文本聚类与分析:将文本编码为向量后进行聚类,挖掘内容结构和主题分布,如K-means聚类。
5、常见问题答疑
Q:Token 和 Embedding 是一回事吗?
A:不是。Token是编号(离散的ID),Embedding是承载语义的连续向量,二者功能完全不同。
Q:Embedding 是模型训练出来的吗?
A:是的。Embedding 向量是模型通过海量语料学习到的语义表示,而不是手动设定或硬编码的。
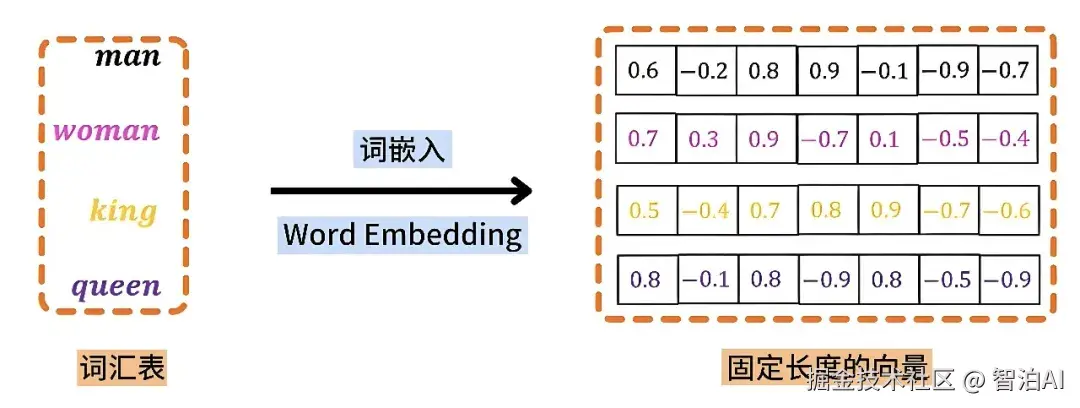
Q:Embedding 向量长度固定吗?为什么?
A:在同一个模型中,所有Embedding向量的长度是固定的(例如:512维、768维),这样可以统一模型内部的计算结构,方便批量处理和矩阵运算。不同模型之间的向量长度则可能不同。