GenEnv:让AI智能体像人一样在"游戏"中成长
GenEnv框架通过在LLM智能体与可扩展的生成式环境模拟器之间建立难度对齐的协同进化博弈,实现了数据效率的显著提升。该框架将智能体训练视为一个两玩家课程游戏,通过动态调整任务难度来最大化学习信号,使7B参数模型在多个基准测试中性能提升高达40.3%。
论文标题: GenEnv: Difficulty-Aligned Co-Evolution Between LLM Agents and Environment Simulators
来源: arXiv:2512.19682v2 + https://arxiv.org/abs/2512.19682
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 AI极客熊 」 即刻免费解锁
文章核心
研究背景:AI智能体训练的瓶颈与机遇
当前大型语言模型(LLM)智能体的训练面临严峻挑战:真实世界交互数据成本高昂且具有静态局限性。传统方法依赖于收集大量专家演示数据,这些静态数据集无法捕捉智能体在开放环境中可能遇到的广泛变化。尽管合成数据生成技术有所进展,但这些方法通常产生大量但最终静态的内容,无法适应智能体不断变化的需求。这种静态数据的局限性成为训练高效、适应性强的智能体的主要瓶颈。
研究问题:传统方法的三大缺陷
- 数据成本高昂:真实世界交互需要大量资源投入,且难以并行化
- 静态数据局限:预收集的数据集无法适应智能体能力的动态提升
- 缺乏自适应课程:传统方法难以生成与智能体当前能力匹配的任务难度
主要贡献:三重创新突破
- 数据演化范式:提出协同进化框架,使训练数据分布动态适应智能体的学习进度,打破对静态语料的依赖
- 难度对齐模拟:引入α-课程奖励机制,确保任务难度与智能体当前能力保持同步
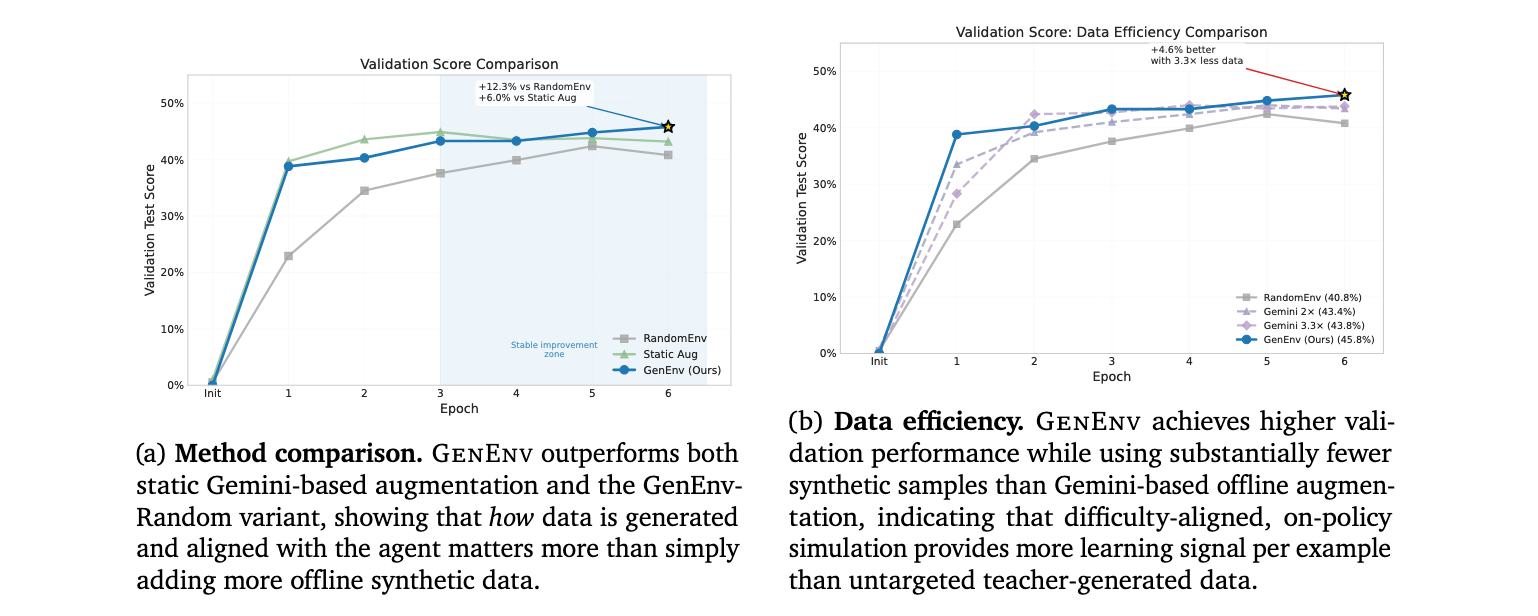
- 数据效率提升:在基准测试中,GenEnv在使用3.3倍更少合成数据的情况下,性能超越Gemini 2.5 Pro-based离线数据增强


方法论精要
GenEnv框架的核心理念是将智能体训练视为一个两玩家课程游戏,而非单玩家优化问题。该框架维护两个策略:智能体策略 \\pi_{agent} (学生)和环境策略 (学生)和环境策略 (学生)和环境策略 \\pi_{env} (老师)。与标准强化学习中环境固定不同,GenEnv使两者能够协同进化。
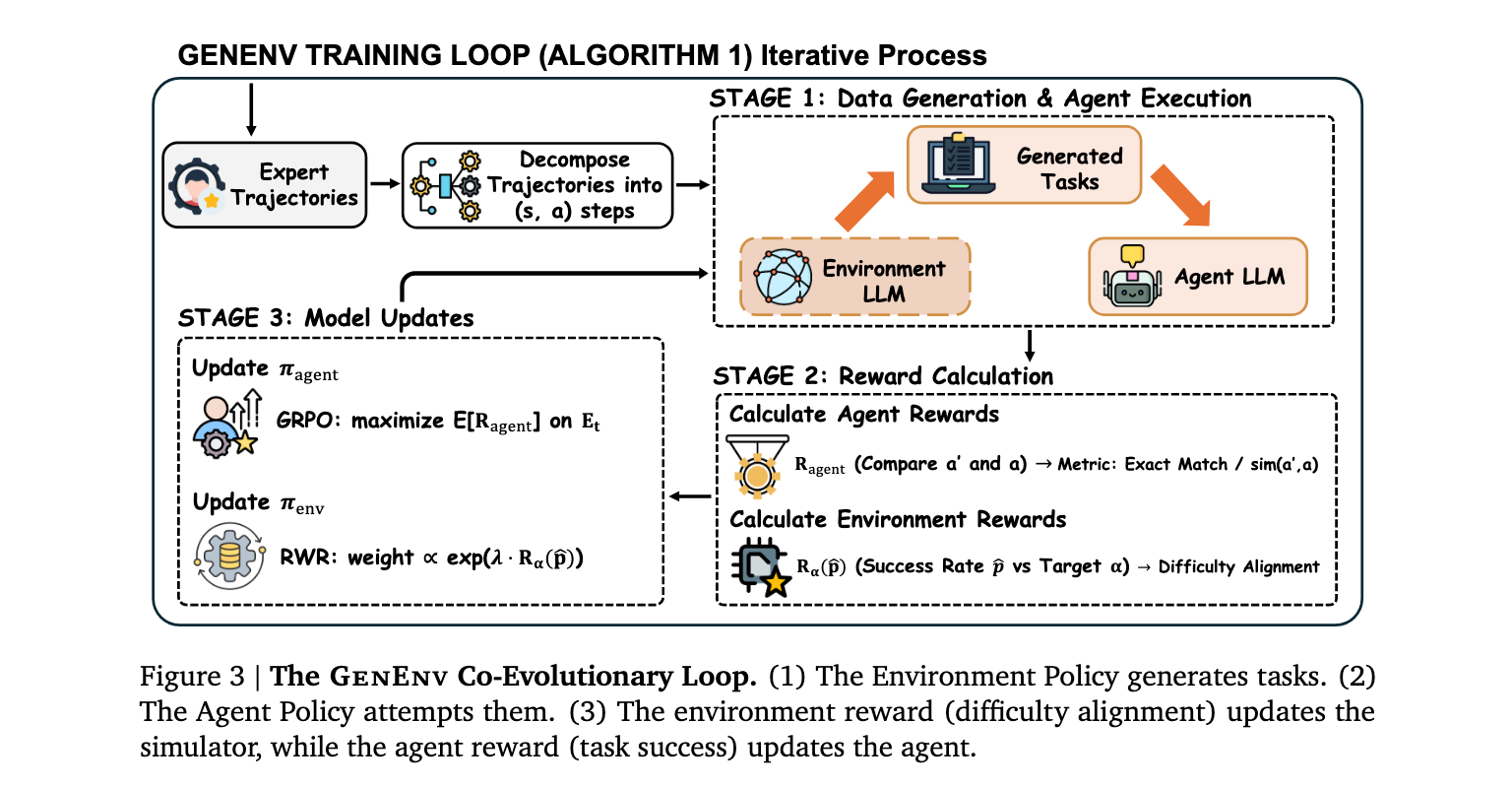
数据演化范式:从静态语料到自适应模拟
标准训练在静态分布 D_{static} 上最小化损失 上最小化损失 上最小化损失 L(\\theta) ,而 G e n E n v 实现数据演化范式。训练数据 ,而GenEnv实现数据演化范式。训练数据 ,而GenEnv实现数据演化范式。训练数据 D_t 由 由 由 \\pi_{env} 在智能体历史性能条件下实时生成。这种反馈循环中,模拟器的目标不是击败智能体,而是找到其"突破点"以促进学习。
奖励机制设计:双目标优化
GenEnv采用双重奖励机制设计,分别优化智能体和环境策略:
智能体任务奖励(R_agent) :
对于结构化动作空间(如可执行的API调用),采用精确匹配:
R_{agent}(a', a) = \\mathbb{I}(a' = a) \\cdot \\mathbb{I}(a \\in A_{struct}) + sim(a', a) \\cdot \\mathbb{I}(a \\notin A_{struct})
其中sim(a', a) ∈ 0, 1是任务相关的相似度度量。
环境难度对齐奖励(R_env) :
核心创新在于难度对齐奖励机制,目标是将成功率控制在目标α ∈ (0, 1)附近(本文使用α = 0.5):
R_{env}(\\hat{p}) = \\exp\\left(-\\beta(\\hat{p} - \\alpha)\^2\\right)
其中 \\hat{p} 是经验成功率,β > 0控制奖励形状。这种bell-shaped奖励在智能体表现与目标成功率匹配时达到峰值,避免生成过于简单或困难的任务。
数据结构与新训练数据生成
GenEnv维护两个在线增长的数据集:
- 智能体训练池 D_{train} :存储从 :存储从 :存储从 E_t 中提取的有效交互轨迹
- 环境SFT池 D_{env} :存储用于训练 :存储用于训练 :存储用于训练 \\pi_{env} 的环境生成记录
这种设计确保新数据作为交互副产品产生,并明确聚合到后续更新的训练池中。
两玩家课程强化学习:优化循环
玩家1更新(智能体):通过Group Relative Policy Optimization (GRPO)最大化 \\mathbb{E}\[R_{agent}\] 。
玩家2更新(环境):通过奖励加权回归(RWR)最大化 \\mathbb{E}\[R_{env}\] ,通过加权 S F T 集微调 ,通过加权SFT集微调 ,通过加权SFT集微调 \\pi_{env} 。
算法1展示了完整的协同进化循环过程,包括在线生成与交互、双目标更新和数据聚合三个阶段。

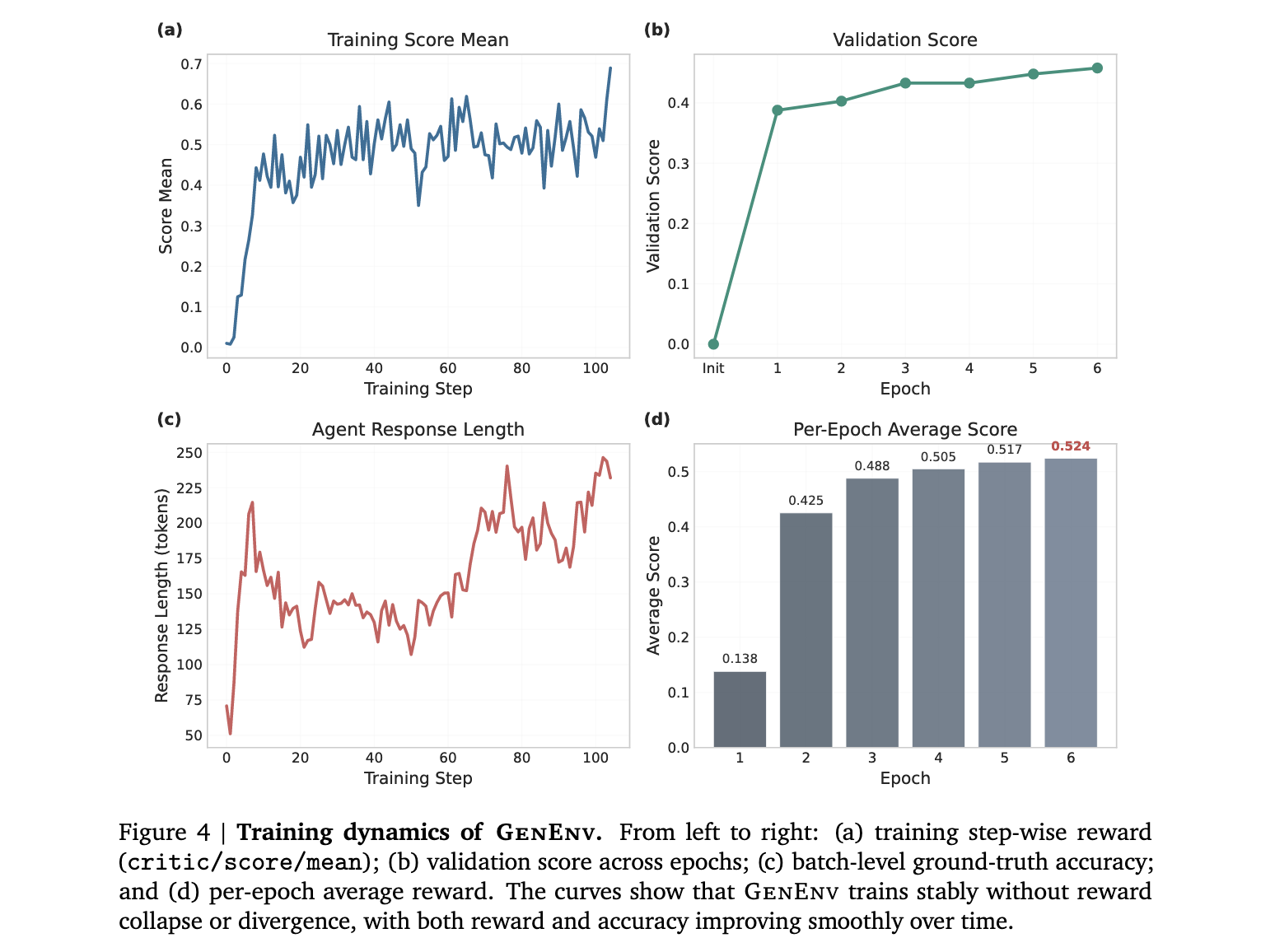
实验洞察
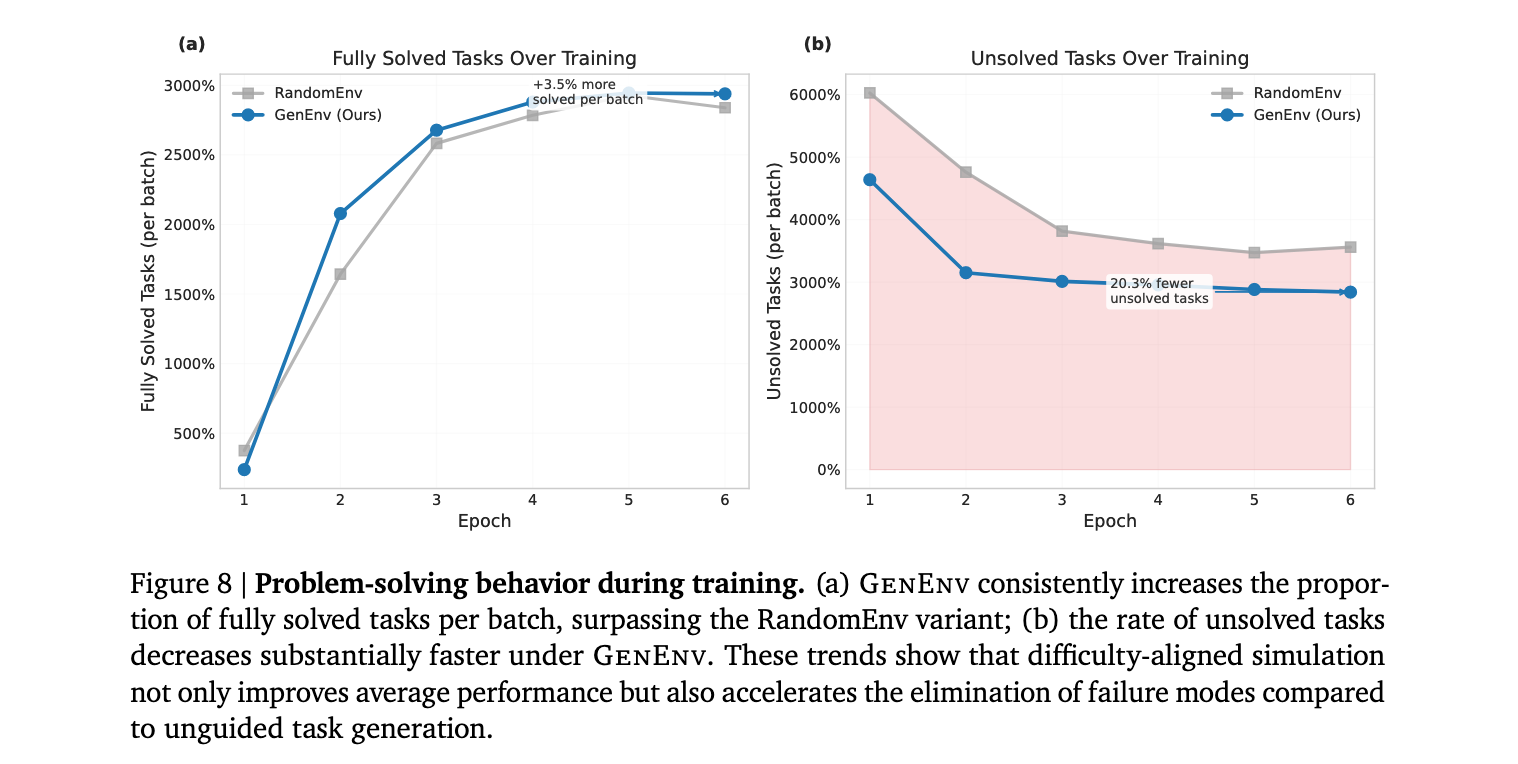
GenEnv在五个基准测试上进行了评估,包括API-Bank、ALFWorld、BFCL、Bamboogle和TravelPlanner。实验结果表明,GenEnv在所有基准测试中显著优于强基线,7B模型性能提升高达+40.3%。

性能提升验证
在API-Bank测试中,GenEnv训练的7B模型达到了79.1%的成功率,相比基础模型的61.6%有了显著提升。在ALFWorld这个具体环境交互测试中,GenEnv展现了最为惊人的提升效果,基础模型的成功率仅为14.2%,而GenEnv训练的模型达到了54.5%,提升幅度超过40个百分点。
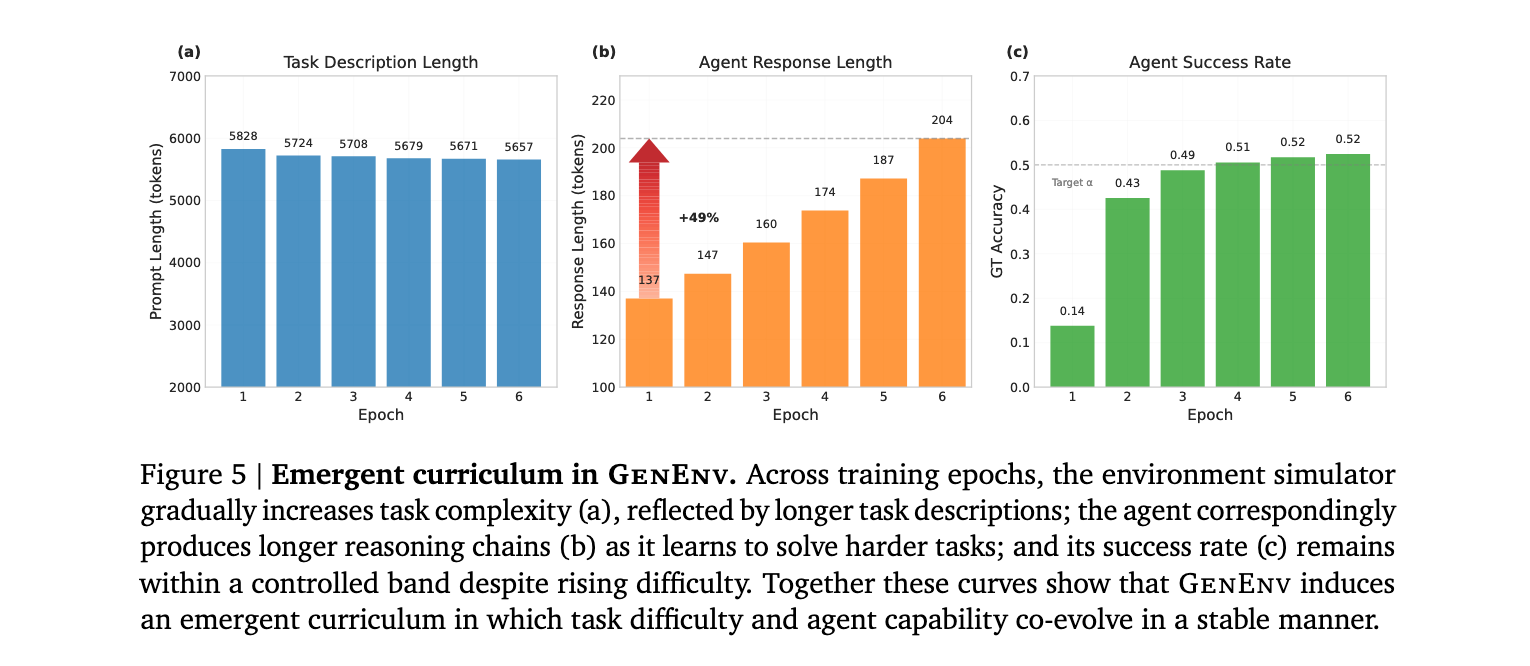
课程演进机制
通过分析训练动态,研究发现智能体响应长度从137个token增长到204个token(增幅49%),同时环境生成的任务描述长度也相应增加,表明系统成功实现了难度递增的课程设计。更重要的是,智能体的成功率保持在目标带宽内,证明了难度校准机制的有效性。
数据效率优势
GenEnv在数据效率方面表现出色。与Gemini 2.5 Pro-based离线数据增强相比,GenEnv在使用3.3倍更少合成数据的情况下实现了更好的性能。这验证了目标化、难度对齐的模拟生成在数据效率方面的优越性,而非简单地增加合成数据量。
理论验证
研究团队通过理论分析证明了α-Curriculum奖励机制的统计一致性,表明即使环境模拟器只能观察到有限次数的智能体尝试,它依然能够可靠地判断哪种任务类型更接近目标难度。这种理论保证解释了为什么GenEnv在实际应用中表现如此出色。