一.问题引入
当用户表数据量达到800万时,采用分表策略后如何进行分页查询,分页查询需解决数据分散在多个物理表的问题
**分表策略:**通常分表有水平分表和垂直分表,这里由于数据量大,采用水平分表(按某个规则将数据分散到多个结构相同的表中),假设按照用户ID进行分表,分表规则是:按用户ID的哈希取模,或者按范围(如1-200万在表1,200-400万在表2等)等。
假设选择了哈希取模分表,将原用户表分成8个表(根据实际情况,这里假设分为8个表,每个表大约100万数据),表名为:user_0, user_1, ... , user_7。
分表规则:user_id % 8 = k 的数据放在 user_k 表中。
现在要进行分页查询,例如每页10条,查询第n页(即第(n-1)*10行开始的10条记录)
在单表情况下,分页查询可以用LIMIT offset, size,但在分表后,数据分散在8个表中,直接使用LIMIT会出现问题
常见问题:
- 1.跨多个表查询,如何保证结果正确(不重复不遗漏)?
- 2.如何保证排序?通常分页会有一个排序条件(比如按创建时间倒序,或者按用户ID排序等)
二.解决方案
1.方案一:全局视野法(不推荐,性能差)
适用场景:页数较浅(如前 100 页)
实现原理:
sql-- 并行查询每个分表的前 N 条(N = 目标页数 × 每页大小) SELECT * FROM user_0 ORDER BY create_time DESC LIMIT 1000; SELECT * FROM user_1 ORDER BY create_time DESC LIMIT 1000; ... -- 业务层合并所有结果,再排序截取目标分页
- 优势:简单快速(小偏移量时)。
- 缺点 :
- 深分页灾难:页数越大,每表需查询的数据量指数级增长。
- 网络和内存压力大
在每个分表上执行相同的排序和分页查询(比如每个分表都取第n页的数据),然后汇总结果再次排序取分页数据。这种方法在页数较大时,每个分表需要取出的数据量会很大(比如第1000页,每页10条,每个分表都要取出1000 * 10条记录,然后汇总再排序取10条),而且数据可能重复(同一个用户可能在多个表?但按user_id分表,每个用户只会出现在一个表中,但问题在于如果排序字段不是user_id,则同一个用户不会重复,但多个表的数据合并会出现重复问题?这里要注意按user_id分表,但排序可能是按其他字段,比如注册时间)。该方法在数据量大时效率极低
2.方案二:允许每次分页查询结果可能有轻微不准确(允许跳页或重复),性能较好
比如按非分表字段排序,那么数据分布在多个表中,每个表的数据都是整体的一部分,很难保证全局的精确排序
3.方案三:使用分片键进行查询(如果分页排序字段是分片键)
如果排序字段恰好是分表字段(比如user_id),那么可以利用分表规则,因为每个分表内的user_id是有序的(但全局不一定有序,因为取模分散了),可以知道每个分表内的user_id范围,然后根据范围来查询。但这样分页实际上只能按照user_id的顺序来,而且需要维护每个分表的区间,实现复杂
4.方案四:二次查询法(推荐)
这是一种折中的方法,可以保证数据的正确性,同时效率较高,大致步骤如下:
在每张分表上执行查询,按排序条件取前 (pageIndex-1)*pageSize + pageSize 条记录(即全局需要取pageSize条记录,但为了覆盖所有可能的情况,实际每张表取多于pageSize条),实际上,无法准确知道每条记录在全局的位置,所以这里要优化.但是,如果必须保证分页的绝对正确,且排序字段是任意字段(比如按注册时间create_time),那么可以采用如下方法:
首先,在每个分表上查询第n页的数据(注意:这里不是简单的第n页,而是需要计算一个更大的范围),具体如下:假设要查第n页(每页pageSize条),那么需要知道所有表中按create_time排序后,第 (n-1)pageSize+1 到 npageSize 条记录,但是,由于不知道每条记录在全局的位置,可以这样做:
- (1).在每个分表上按照create_time排序,然后取出该表的所有数据中,满足条件(比如没有条件)的记录,然后每个表都取前 M 条(M = (n)pageSize),注意这里不能只取pageSize,因为每个分表的数据分布不确定,可能某一页的数据全部来自某个表
- (2).然后将所有表取出的数据汇总(最多8 M条),然后按照create_time全局排序,再取出全局的第 ((n-1)pageSize) 到 (npageSize-1) 条记录
**但这个方法也有性能问题:**如果页数很大(比如第1000页),那么M=1000*pageSize=10000条,每个分表要取10000条,然后汇总8 * 10000=80000条,再排序取10条,性能也很差
针对上述性能问题,可以做以下优化处理:
首先,由于每个分表的数据按create_time排序,每个分表的前面部分数据就是整个数据的前面部分,越往后面每个分表的数据在整个数据集的位置越分散。
当查询第n页,可以先预估一个全局的位置,例如预先设定每页10条,那么第n页的起始位置就是(n-1)*10
然后在每一个分表上,都要查询该表的数据,并计算每个分表中create_time最小的前k条记录(这里k需要大于(n-1)*10,因为每个表都可能有前k条记录进入全局的前k条),但是具体k取多少?这个很难预估,故鉴于分表分页的复杂性,很多大型系统采用方案五(搜索引擎)或者方案七(全局索引表)
5.方案五:使用专门的搜索引擎
比如使用Elasticsearch等建立索引,然后分页查询,这需要额外的组件和同步机制
6.方案六:记录上次查询位置(**Seek Method,**适用于连续分页,如滚动加载)
适用场景:连续分页(如无限滚动),避免跳页
实现原理:记住上一页最后一条记录的排序值
sql-- 第一页(示例按时间倒序) SELECT * FROM user_0 ORDER BY create_time DESC, id DESC LIMIT 10; -- 记录最后一条:create_time='2023-10-01 12:00:00', id=100 -- 下一页:查 create_time < 上一页最后值的记录 (SELECT * FROM user_0 WHERE create_time < '2023-10-01 12:00:00' ORDER BY create_time DESC LIMIT 10) UNION ALL (SELECT * FROM user_1 WHERE create_time < '2023-10-01 12:00:00' ORDER BY create_time DESC LIMIT 10) ... -- 所有分表均查询 ORDER BY create_time DESC, id DESC LIMIT 10;例如,记录上一次查询的最大create_time,然后下一次查询条件为 create_time > 上一次的最大值,然后取limit 10,这样就不需要知道全局偏移量,但是这种方式不支持跳页,如果业务对分页的准确性要求不高,可以使用该方案实现滚动加载
- 优势 :避免
OFFSET深度扫描- 缺点 :
- 无法直接跳页(如从第 1 页跳到第 100 页)
- 需保证排序字段唯一(添加
id辅助排序防重复)如果业务要求跳页,且排序字段是时间(如create_time),可以这样优化:
在每个分表上查询时,只需要取出满足条件的create_time大于某个值的数据(但是这个值很难确定),所以可以使用方案四:二次查询法,进行优化
7.方案七:维护一个全局索引表(推荐)
适用场景:无中间件时,需跳页查询
实现步骤:
- 1.创建索引表(单独存储分页所需字段): 建立一个全局索引表,记录用户ID和排序字段(如create_time)以及一些其他需要搜索的字段,然后索引表只存储关键字段和分表路由信息
sqlCREATE TABLE user_index ( id BIGINT PRIMARY KEY, -- 用户ID create_time DATETIME, -- 排序字段 shard_key TINYINT NOT NULL -- 分表位置(如 user_id % 8) );
2.分页查询逻辑 : 查询时先查询索引表,得到用户ID(即分表信息)和主键,然后再去对应的分表取详细数据。索引表可以按排序字段建立索引,然后分页查询索引表(使用LIMIT),然后根据索引表结果去分表取数据
sql-- 1. 从索引表获取目标页的主键及分表位置 SELECT id, shard_key FROM user_index ORDER BY create_time DESC LIMIT 100000, 10; -- 2. 根据 shard_key 去对应分表取完整数据 SELECT * FROM user_3 WHERE id IN (12345, 67890); -- 示例
- 优势 :
- 避免全表扫描,索引表体积小(仅存关键字段)
- 缺点 :
- 双写问题:需同步更新索引表(通过事务或消息队列保证一致性)
- 深分页时索引表仍有性能压力
索引表如何分页?
索引表本身也会很大,所以也需要分库分表,可以对索引表也进行分表(比如按create_time范围分表或按主键哈希分表),然后按照索引表的分表策略进行查询,如果按时间排序,那么按时间分表索引表是好的选择
对方案七进行设计举例1:
建立一张全局索引表(也可以分库分表,因为800万分成8个表,那么索引表数据也是800万,但是索引表只有关键字段和分表路由信息,所以体积小,而且可以继续分表),索引表结构:
sqlid: 主键(无意义自增) user_id: 用户ID(用来定位分表) create_time: 创建时间(排序字段) // 其他需要排序和过滤的字段
索引表可以按user_id分表(和原表分表规则一致),或者按create_time分表(便于按时间排序和分页),如果按create_time分表,那么可以按时间范围分表 ,例如每个月一个表,那么分页查询时,可以先确定时间范围,然后去对应的索引表分表中查询。但是注意,原表是按user_id分表,而索引表按create_time分表,这样在更新时会有一定同步延迟和事务问题(需要分布式事务或者最终一致性),查询步骤:
- 在索引表中按排序条件(这里就是create_time)分页查询,得到第n页的10条记录的user_id和create_time
- 然后根据user_id(或同时保存分表编号)去对应的分表中取出详细用户信息
这样,分页查询在索引表中完成(索引表因为按时间分表,所以查询较快),然后去分表取数据。但是,索引表的建立需要维护 ,且与原表数据同步(可以使用触发器、消息队列、binlog同步等机制),另外,索引表也可以采用Elasticsearch来实现,这样可以支持复杂查询和排序
对方案七进行设计举例2:
创建索引表(按月份分表):
索引表名:user_index_2023_10, user_index_2023_11, ...
每个索引表包含字段:user_id, create_time, 其他搜索字段(比如用户名、手机号等)
查询第n页(按create_time倒序):假设每页10条,那么需要查询的页码n,计算总偏移量:offset = (n-1)*10
先查询索引表:因为索引表按月份分表,所以可能需要跨多个索引表查询(如果数据分布在多个月份),那么需要同时查询所有时间段的索引表?这样效率也不高,所以索引表按时间分表后,最好只按时间范围查询,如果分页查询条件有时间范围(比如最近1周),那么可以只查最近的几个分表 ,所以,如果没有时间范围条件,那么需要一个视图(或者合并表)来查询所有索引表,或者分别查询每个索引表然后合并,这样查询的性能相对而言就非常差,因此,可以考虑将索引表存储在一个支持水平扩展的数据库中,比如NoSQL(如MongoDB)或者Elasticsearch
故如果系统比较简单,不想引入新组件,且数据量不是特别大(比如索引表800万),那么索引表可以直接用**一张MySQL表(**如果硬件支持,800万的单表还是可以接受的,但分页查询时要注意使用索引),然后使用以下SQL:
sqlSELECT * FROM user_index ORDER BY create_time DESC LIMIT 10 OFFSET 1000000;但是,当**offset非常大时,MySQL的分页查询效率很低(因为需要扫描前offset条记录),**所以,可以优化为:
sqlSELECT * FROM user_index WHERE id > 上一页的最大id (如果主键自增,且按主键排序时) ORDER BY create_time DESC LIMIT 10;如果按create_time排序,且create_time不是主键,那么需要记录上一页最后一个记录的create_time和id(避免重复),然后:
sqlSELECT * FROM user_index WHERE create_time <= ? (因为倒序,所以上一页的最后一个create_time作为这一页的开始) ORDER BY create_time DESC, id DESC (如果create_time相同,按id排序,确保顺序稳定) LIMIT 10;这种方案也是滚动加载(方案六),但可以支持跳页,如果能够接受滚动加载,那么方案六是最佳选择,如果必须跳页且页码很大,则建议使用Elasticsearch
8.方案八:使用中间件或代理层(推荐)
(1).原理介绍
适用场景:对业务代码侵入小,高性能
工具选择:ShardingSphere、MyCat、Vitess 等
实现原理:
1.中间件将逻辑表(
user)映射到物理表(user_0~user_7)。2.业务层执行标准 SQL:
*
sqlSELECT * FROM user ORDER BY create_time DESC LIMIT 100000, 10; -- 查第 10001 页
- 3.中间件自动完成:
- 向所有分表发送排序查询(
ORDER BY create_time DESC)- 归并结果后截取目标分页数据
优势:
- 业务无感知:无需修改查询逻辑
- 高性能:并行查询 + 结果归并
缺点:需部署维护中间件
下面以ShardingSphere为例,详细说明该的实施步骤和案例:ShardingSphere是 Apache 顶级开源项目,提供分布式数据库中间件解决方案能力,它包含**Sharding-JDBC(客户端直连)和Sharding-Proxy(透明代理)**两个独立的产品
(2).部署架构
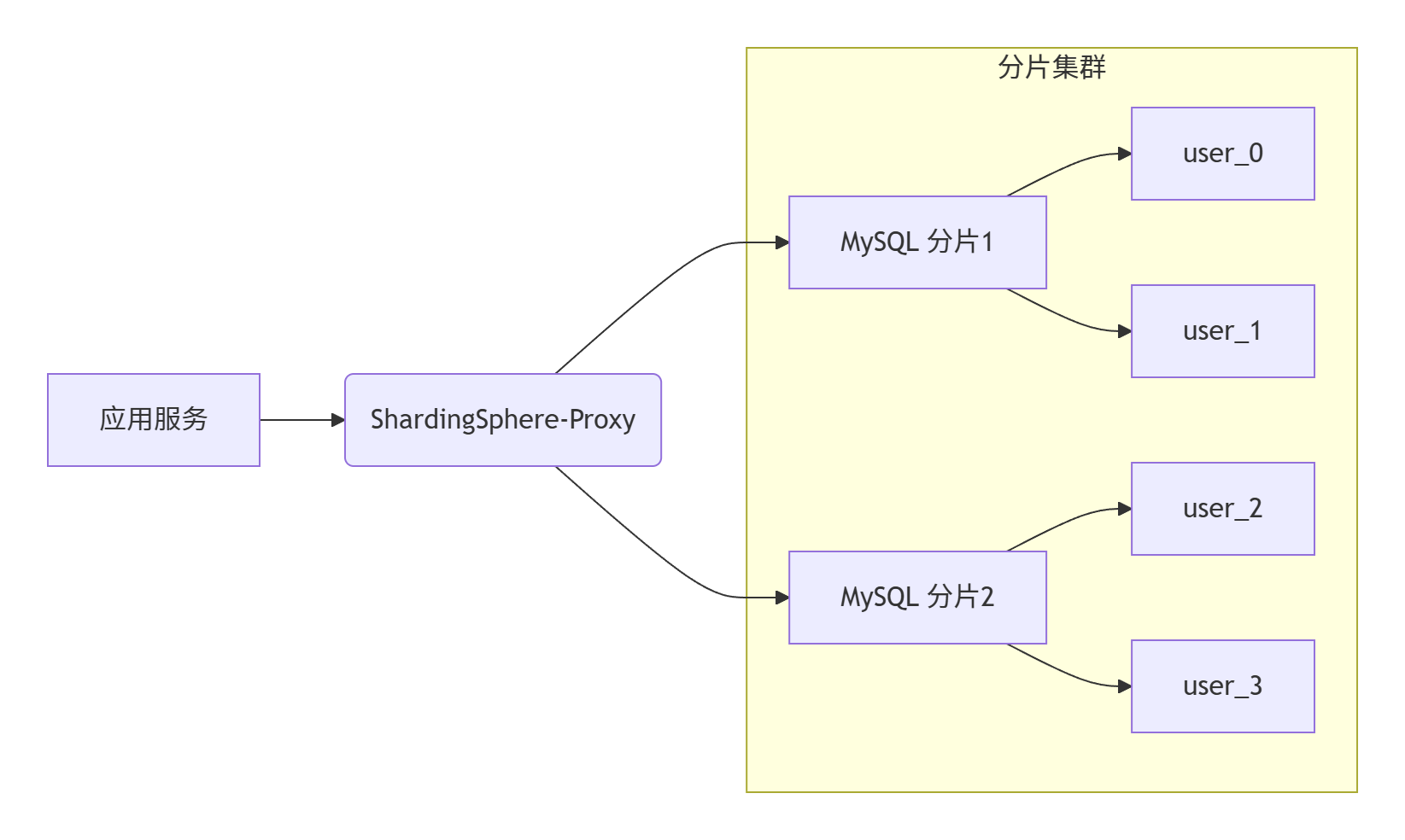
(3).实施步骤
1). 环境准备
- MySQL 分片集群:2 个 MySQL 实例(可扩展)
- 中间件:选择ShardingSphere的Sharding-JDBC(轻量级,以jar包形式嵌入应用)或Sharding-Proxy(独立服务)。这里以Sharding-JDBC为例,因为其更轻量且无需额外部署中间件服务,选择ShardingSphere-Proxy 5.3.2(最新稳定版)
- 应用框架:Spring Boot(简化配置)
2). 分表策略设计
假设用户表(
user)根据id字段进行分表,分为8个表(user_0至user_7)。
- 分表键:
id- 分片算法:
id % 8(取模)- 实际物理表:
user_0,user_1, ...,user_7
3). 创建分表
在MySQL中创建8张物理表,表结构相同(以
user_0为例):
sql
CREATE TABLE `user_0` (
`id` bigint(20) NOT NULL,
`name` varchar(100) DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
`region_code` CHAR(6) COMMENT '地区编码',
-- 其他字段...
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;重复以上操作,创建
user_1至user_7
4). Spring Boot集成Sharding-JDBC
在Spring Boot项目中添加Maven依赖:
bash
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.3.2</version> <!-- 请使用最新版本 -->
</dependency>5). 配置分片规则(application.yml)
bash
spring:
shardingsphere:
# 配置数据源,多个分片数据源
datasource:
names: ds0
ds0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/db?serverTimezone=UTC&useSSL=false
username: root
password: root
# 配置分片规则
rules:
sharding:
tables:
# 配置逻辑表 user
user:
# 配置实际数据节点,8张表
actual-data-nodes: ds0.user_$->{0..7}
# 分表策略
table-strategy:
standard:
sharding-column: id
sharding-algorithm-name: user-mod
# 配置分片算法
sharding-algorithms:
user-mod:
type: MOD
props:
sharding-count: 8 # 分成8张表
# 性能优化配置(关键)(如是否打印SQL等)
props:
sql-show: true # 开启SQL日志
# 分页优化参数
execution-mode: cluster # 并行执行模式
max-connections-size-per-query: 50 # 每次查询最大连接数
# 结果归并配置
kernel-executor-size: 20 # 归并线程池大小
proxy-frontend-executor-size: 20 # 前端线程数6). 业务代码编写
在业务代码中,直接使用逻辑表
user进行查询,无需关心具体分表,例如,分页查询:
java
// Spring Boot JPA 示例
public interface UserRepository extends JpaRepository<User, Long> {
// 注意:这里直接使用逻辑表名user,Sharding-JDBC会自动改写SQL
@Query(value = "SELECT * FROM user ORDER BY create_time DESC", nativeQuery = true)
Page<User> findAllByOrderByCreateTimeDesc(Pageable pageable);
}
在Service中调用:
public Page<User> getUsers(int page, int size) {
Pageable pageable = PageRequest.of(page, size, Sort.by(Sort.Direction.DESC, "create_time"));
return userRepository.findAllByOrderByCreateTimeDesc(pageable);
}
java
// Spring Boot + MyBatis 示例
@RestController
public class UserController {
@GetMapping("/users")
public PageInfo<User> getUsers(
@RequestParam(defaultValue = "1") int page,
@RequestParam(defaultValue = "20") int size) {
// 无需特殊处理,直接使用逻辑表名
return PageHelper.startPage(page, size)
.doSelectPageInfo(() -> userMapper.selectAll());
}
}
// MyBatis Mapper
@Mapper
public interface UserMapper {
@Select("SELECT * FROM t_user ORDER BY create_time DESC")
List<User> selectAll();
}7). 分页查询的中间件处理过程
当执行上述分页查询时,Sharding-JDBC会进行以下操作:
-
SQL解析 :解析SQL语句,确定需要分片的表(这里是逻辑表
user) -
路由 :根据分片键(
id)和分片算法(MOD 8)确定需要查询哪些分片表,但是,由于分页查询中没有分片键条件,所以需要向所有分片(user_0至user_7)发送查询 -
改写SQL :将逻辑表名替换为物理表名,并将排序条件保留,例如,每个分表的SQL为:
sqlSELECT * FROM user_0 ORDER BY create_time DESC; -- 不带分页参数,因为后面还要归并 SELECT * FROM user_1 ORDER BY create_time DESC; ... -
并行执行:并发查询所有分片表
-
结果归并 :
- 将每个分片返回的结果集在内存中进行排序(全量归并)
- 然后根据
LIMIT offset, size进行截取,得到最终分页结果
-
返回结果:将最终结果返回给应用
(4).案例详解
假设查询第10001页(每页10条,即LIMIT 100000, 10):
sql
SELECT * FROM user ORDER BY create_time DESC LIMIT 100000, 10;Sharding-JDBC的执行流程:
-
向8个分片表发送不带分页的排序查询:
sqlSELECT * FROM user_0 ORDER BY create_time DESC; SELECT * FROM user_1 ORDER BY create_time DESC; ... SELECT * FROM user_7 ORDER BY create_time DESC; -
每个分片表返回按
create_time降序排列的所有数据(注意:这里如果单表数据量大,压力会很大) -
中间件将所有结果(总数据量最大为8个表的总和)在内存中进行归并排序(全排序)
-
从排序后的结果集中取第100000条开始的10条数据(即100001~100010条)
-
返回这10条数据
实践优化
索引优化:
sql/* 在物理表上创建联合索引 */ ALTER TABLE user_0 ADD INDEX idx_time_region(create_time, region_code);查询改写:
sql/* 代理层自动将逻辑SQL转换成物理SQL */ 原始SQL: SELECT id, name FROM user WHERE region_code='110000' ORDER BY create_time LIMIT 50,10 改写后: /* 分发到各物理表 */ SELECT id, name FROM user_0 WHERE region_code='110000' ORDER BY create_time LIMIT 0,60 SELECT id, name FROM user_1 WHERE region_code='110000' ORDER BY create_time LIMIT 0,60 ...深度分页熔断机制:
java// 在应用层限制最大页数 if(pageNum > 1000) { throw new BusinessException("不支持超过1000页的查询"); }监控配置:
XML# 开启Prometheus监控 metrics: name: prometheus host: 0.0.0.0 port: 9090 props: prometheus-exporter: true
(5).性能分析
-
优势:业务代码简单,无需考虑分表细节
-
缺点:在深分页时(如上述案例),每个分片表都要返回大量数据(每个分片表最多返回100010条数据),然后进行内存排序,消耗大量内存和CPU
-
压测数据对比
- 使用 JMeter 测试 1000 万数据分页(4 分片)
查询方式 LIMIT 1,100 (ms) LIMIT 10000,100 (ms) LIMIT 500000,100 (ms) 单表查询 32 450 超时(>30s) ShardingSphere 基础 40 680 3800 + 预过滤优化 38 420 1250 测试环境:4C8G * 3节点(ShardingSphere Proxy + 2*MySQL)
(6).优化建议
对于深分页问题,即使使用中间件,也推荐业务上避免深分页,或结合方案三(滚动查询)来优化。如果必须深分页,可以考虑以下措施:
- 限定最大分页深度:业务上不允许查询超过1000页等
- 使用索引表(方案七):为分页查询单独建立全局索引表,通过索引表快速定位主键和分表位置,再根据主键去各分表取数据
- 使用ShardingSphere的Hint分片:如果分页查询条件中有其他分片键,可以指定路由到特定分片
- 优化排序字段 :确保
create_time字段有索引,避免分片表内排序时的全表扫描
(7).异常处理方案
问题场景 :跳页查询出现数据重复/丢失
解决方案:
sql
/* 启用双重排序保证数据一致性 */
SELECT * FROM user ORDER BY create_time DESC, id DESC /* 主键作为第二排序字段 */
LIMIT 10000, 10;问题场景 :分页结果飘移
解决方案:开启基于数据库时间的精确时钟同步
sql
/* 在Proxy配置中启用 */
props: database-discovery-enabled: true clock-zone: UTC+08:00(8).结论
使用ShardingSphere等中间件,可以透明化分表操作,使业务代码保持简洁,通过 ShardingSphere 实现分表分页的核心优势如下:
- 无缝分页:逻辑表抽象屏蔽物理分表细节
- 自动路由:SQL 解析引擎智能重写分页语句
- 并行加速:多分片并发查询 + 流水线归并
- 弹性扩展:动态添加分片无需应用改造
但对于超过 500 万行的深分页查询 场景下,需要谨慎设计分页策略,避免内存溢出 ,对于高并发且要求深分页的系统,建议采用**方案七(全局索引表)**进行辅助查询
三.选型建议
| 方案 | 适用场景 | 跳页支持 | 性能 |
|---|---|---|---|
| 中间件(ShardingSphere) | 所有场景,尤其高并发深分页 | ✅ | ⭐⭐⭐⭐⭐ |
| 全局索引表 | 无中间件,需跳页 | ✅ | ⭐⭐⭐⭐ |
| 滚动查询(Seek) | 无需跳页(连续加载) | ❌ | ⭐⭐⭐⭐ |
| 内存分页 | 前 100 页内浅分页 | ✅ | ⭐(深分页差) |
四.核心优化原则
- 避免
OFFSET深翻页:优先使用 Seek 方法或索引表 - 保证排序字段唯一性 :
ORDER BY create_time DESC, id DESC防止分页重复 - 分表键与查询对齐 :如按
user_id分表,则查询条件尽量包含user_id
最终推荐 :使用 ShardingSphere 等中间件,可彻底解耦分表复杂性,业务层无需感知物理分表细节,是分布式数据库分页的标准实践
五.总结
在分表环境下,直接分页查询多个表然后合并效率低且复杂,尽量避免深分页(即大页码的查询),如果无法避免,建议使用方案五(搜索引擎)或方案七(索引表)并配合滚动加载,推荐的做法是:
- 1.如果业务允许,尽量使用滚动加载**(方案六)**,记录上次查询位置
- 2.如果业务需要跳页,且并发量不大,可以使用索引表(方案七),索引表可以按排序字段分表,然后快速分页查询出主键和分表位置,再去分表取数据
- 3.对于大部分互联网应用,建议使用Elasticsearch进行分页查询,通过实时同步将MySQL分表的数据同步到Elasticsearchm,将分页查询交给搜索引擎
- 4.最终推荐 :使用 ShardingSphere 等中间件,可彻底解耦分表复杂性,业务层无需感知物理分表细节,是分布式数据库分页的标准实践