引言
本文继续研究 LLaMA-Factory,内容侧重于日志监控和模型量化分享。
更好的训练日志监控
LLaMA-Factory 的 Webui** 仅生成训练损失的曲线图,如需查看更详细训练情况监控信息,可使用 SwanLab**、TensorBoard、Wandb。
其中,SwanLab 是国内平台,访问速度更快,且同时支持云端/离线使用,自然作为首选。
SwanLab 官网:swanlab.cn
要使用SwanLab,需要在其官网注册账号,并获取API key。
之后运行
swanlab login在弹出此内容后,输出api key信息。
vbnet
swanlab: Logging into swanlab cloud.
swanlab: You can find your API key at: https://swanlab.cn/settings
swanlab: Paste an API key from your profile and hit enter, or press 'CTRL-C' to quit:完成配置后,在 webui 界面中,勾选启用 SwanLab,设置为云端存储,开始训练后,会自动生成 SwanLab 项目访问地址。
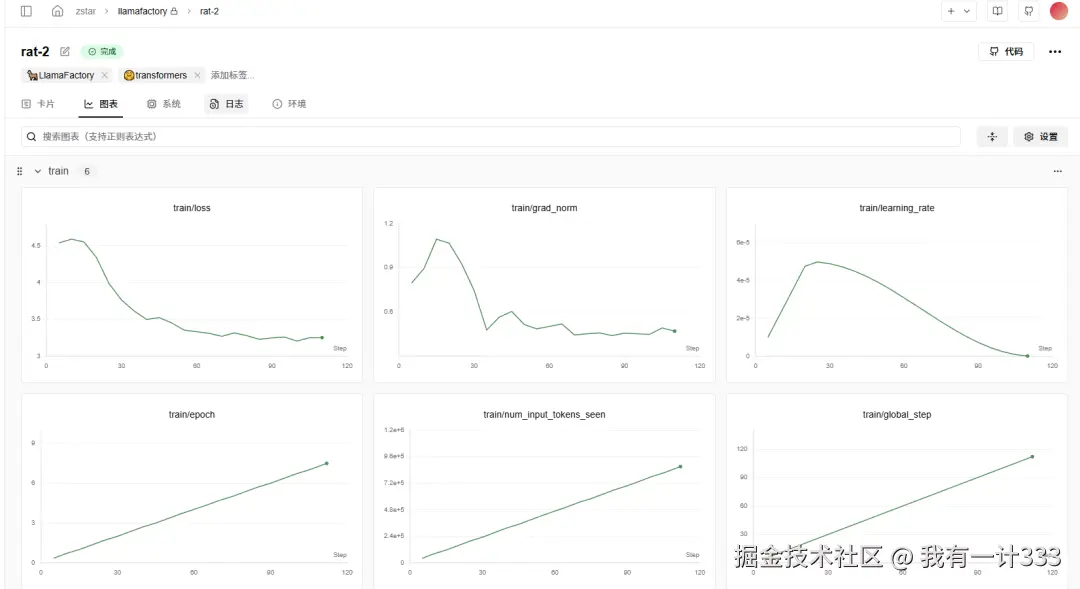
训练完成后,可以查看各参数的曲线变化图。
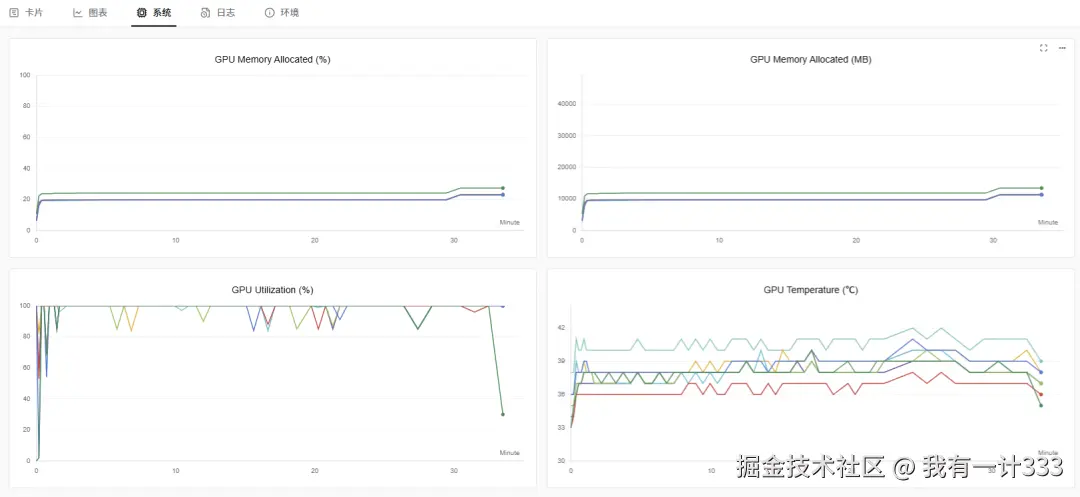
以及训练过程中 GPU 显存占用、利用率、温度等信息。
导出模型量化
导出量化模型
上文提到,通过llama.cpp可以将 LLaMA-Factory 训练完成的模型转换成 gguf 格式,命令如下:
bash
python convert_hf_to_gguf.py /home/zxy/code/LLaMA-Factory/output_model实际上,该命令可通过outtype参数来控制导出模型的精度,有以下选项:f32、f16、bf16、q8_0、tq1_0、tq2_0、tq2_0、auto。
比如,通过以下命令,将模型转换成 8 位量化的版本。
bash
python convert_hf_to_gguf.py /home/zxy/code/LLaMA-Factory/output_model --outtype q8_0量化四位模型
然而,ollama上的模型基本上都是 int4 精度,通过上面的方式无法直接转换成该精度,需要用编译完的llama.cpp再进行量化。
具体方法如下:
1.下载必要依赖
sudo apt install cmake
sudo apt install libopenblas-dev
sudo apt install libcurl4-openssl-dev curl2.cmake编译
ini
cmake -B build -DGGML_BLAS=ON -DGGML_BLAS_VENDOR=OpenBLAS -DLLAMA_CURL=ON
cmake --build build --config Release -j$(nproc)3.进行量化
bash
./build/bin/llama-quantize /home/zxy/code/LLaMA-Factory/output_model/Output_Model-33B-F16.gguf /home/zxy/code/LLaMA-Factory/output_model/Output_Model-33B-q4_k_m.gguf Q4_K_M这里面的Q4_K_M是指使用"k-quant"量化方法和"Medium"中等混合精度策略,兼顾速度与质量。
其它量化方案还包括:
| 量化类型 | 位数 | 模型大小(7B) | PPL增加 | 适用场景 |
|---|---|---|---|---|
| Q2_K | 2 | 2.67GB | +100% | 极端显存受限 |
| Q3_K_M | 3 | 3.06GB | +37.4% | 低显存设备 |
| Q4_K_S | 4 | 3.56GB | +17.6% | 显存与性能平衡 |
| Q4_K_M | 4 | 4.08GB | +8.2% | 推荐通用场景 |
| Q5_K_M | 5 | 4.78GB | +6.36% | 高精度需求 |
| Q6_K | 6 | 5.53GB | +0.1% | 接近原始精度 |
| Q8_0 | 8 | 7.16GB | 几乎无损 | 研究调试 |
查看量化完的模型体积,会有明显的减小。
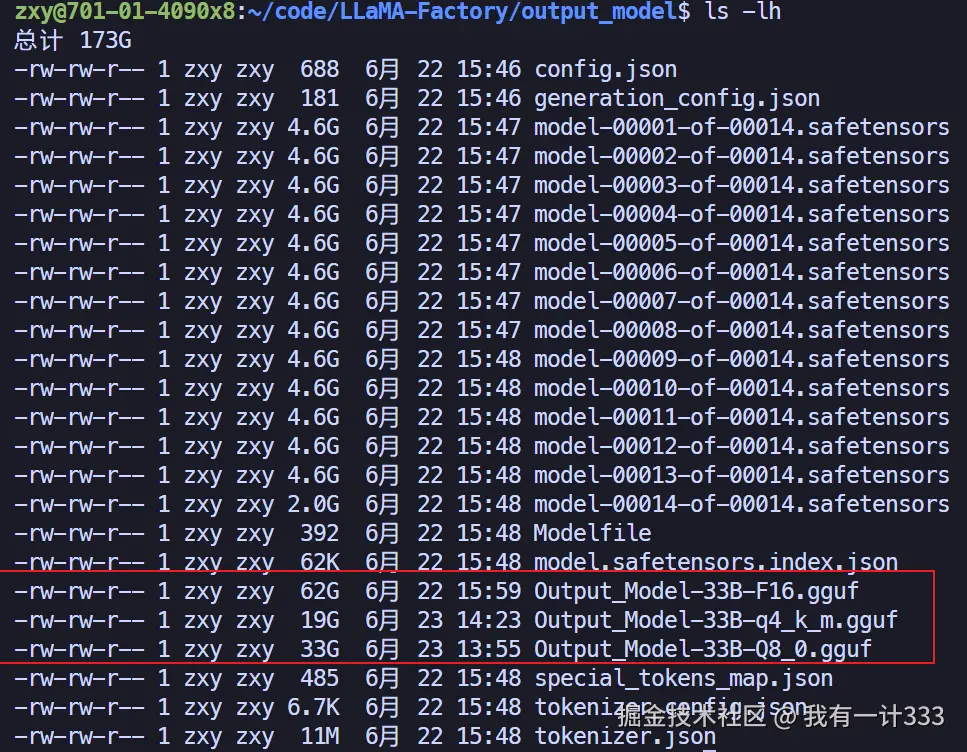
模型上传分享
下面介绍如何将模型上传到 modelscope 或 ollama 平台上供他人下载。
modelscope 平台上传模型
首先在 modelscope 平台上注册账号,复制token信息。
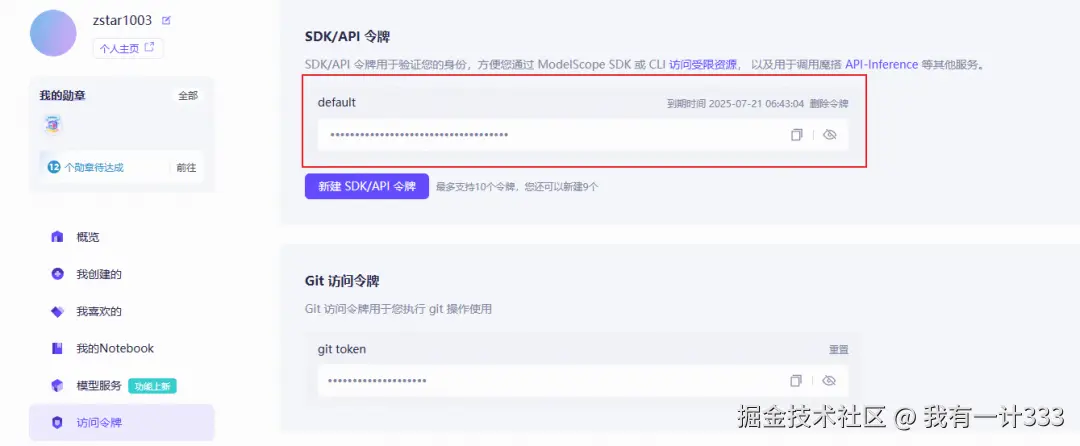
运行如下命令,添加刚刚复制的token
css
modelscope login --token 复制的token将model-q4_k_m.gguf这个模型上传到zstar1003/model_test这个仓库。
bash
modelscope upload zstar1003/model_test /home/zxy/code/LLaMA-Factory/output_model/Output_Model-33B-q4_k_m.gguf model-q4_k_m.gguf --repo-type model --commit-message "upload model"上传完之后,就可以在仓库中看到该模型。
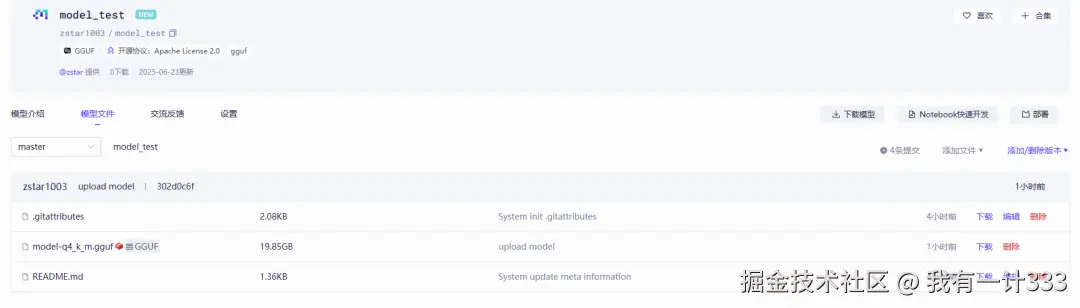
ollama 平台上传模型
首先在 ollama 平台上注册账号。
执行以下命令,生成密钥:
javascript
ssh-keygen -t ed25519 -f ~/.ollama/id_ed25519 -C "ollama账号的邮箱地址"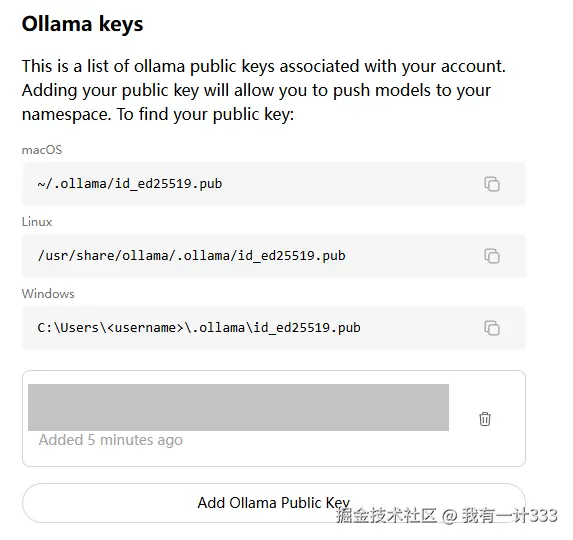
不同操作系统的公钥放在不同位置,参考上图找到公钥内容并直接添加。
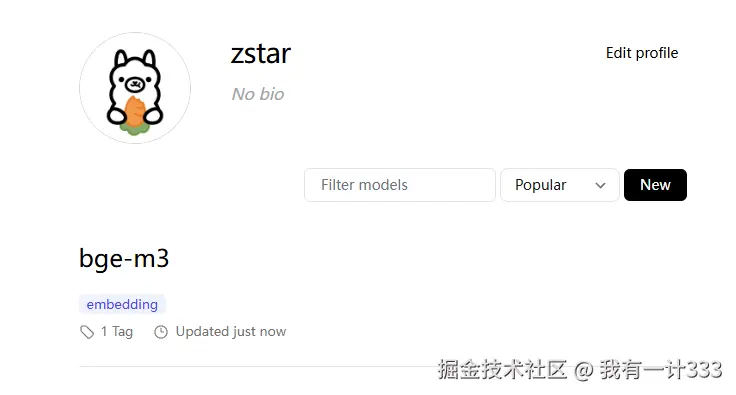
添加完成后,以上传本地的bge-m3模型为例,执行以下命令。
bash
ollama cp bge-m3:latest zstar/bge-m3
ollama push zstar/bge-m3执行完成后,可在个人仓库中看到上传的模型文件。
往期内容推荐
大模型微调相关:
1.【大模型微调】1.LLaMA-Factory简介和基本使用流程
2.【大模型微调】2.微调方法详解与模型显存占用实测3.【大模型微调】3.通过Easy Dataset构建自己的微调数据集4.【大模型微调】4.模型评估标准及操作流程5.【大模型微调】5.调参经验总结与显存占用因素探究6.【大模型微调】6.模型微调实测与格式转换导出