一、Scikit-learn 核心定位
是什么 :Python 最主流的机器学习库 ,涵盖从数据预处理到模型评估的全流程。
为什么测试工程师必学:
-
✅ 80% 的测试机器学习问题可用它解决
-
✅ 无需深厚数学基础,API 设计极简
-
✅ 与 Pandas/Numpy 无缝集成,完美处理测试数据
二、Scikit-learn 核心模块图解
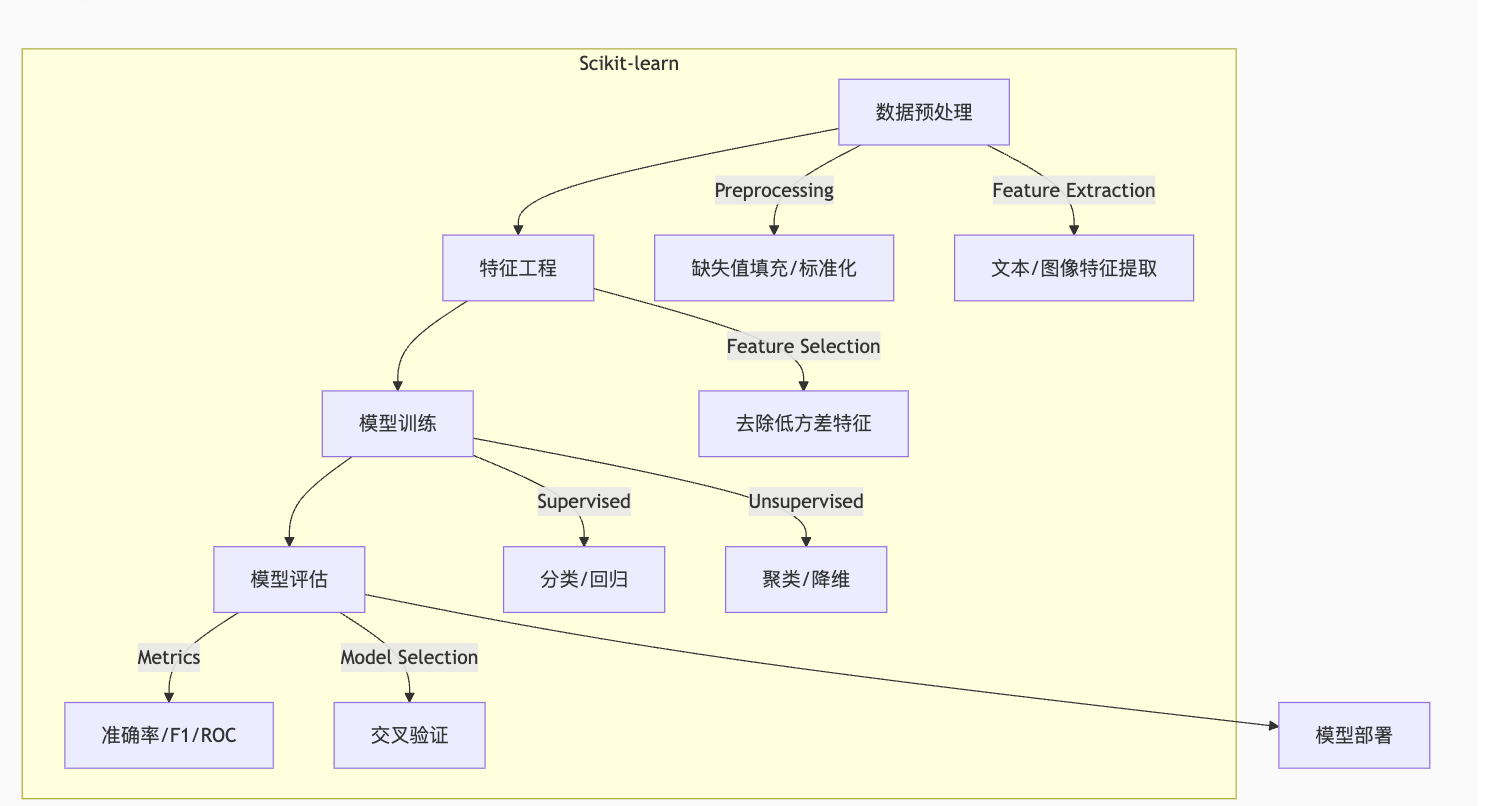
三、测试工程师必掌握的 6 大核心功能
1. 数据预处理:清洗混乱的测试数据
测试痛点:测试日志缺失值、环境配置数值差异大
python
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import MinMaxScaler
# 处理测试执行时间的缺失值(用中位数填充)
imputer = SimpleImputer(strategy='median')
test_data['execution_time'] = imputer.fit_transform(test_data[['execution_time']])
# 将环境配置参数归一化(如内存:4GB/16GB → 0.25/1.0)
scaler = MinMaxScaler()
test_data[['cpu_cores', 'memory_gb']] = scaler.fit_transform(test_data[['cpu_cores', 'memory_gb']])2. 文本特征提取:分析缺陷报告
测试场景:自动分类缺陷报告(崩溃/性能/UI)
python
from sklearn.feature_extraction.text import TfidfVectorizer
# 将缺陷描述转为数值特征
bug_descriptions = ["UI按钮点击无响应", "API响应超时5s", "APP启动时崩溃"]
vectorizer = TfidfVectorizer(max_features=1000) # 提取最重要的1000个词
X_text = vectorizer.fit_transform(bug_descriptions)
# 输出:<3x1000 sparse matrix> 可用于训练分类模型3. 分类模型:预测测试用例失败概率
测试场景:优先执行高失败风险的测试用例
python
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# 特征:测试用例复杂度 + 历史失败率 + 关联代码变更次数
X = test_cases[['complexity', 'historical_fail_rate', 'code_changes']]
y = test_cases['failed'] # 标签:0=通过, 1=失败
# 拆分数据集(测试集永远隔离!)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练随机森林
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
# 预测新测试用例失败概率
new_case = [[5, 0.3, 8]] # 复杂度=5, 失败率=30%, 变更次数=8
fail_prob = model.predict_proba(new_case)[0][1] # 输出:0.87 (87%概率失败)4. 聚类分析:自动归档相似缺陷报告
测试场景:减少重复缺陷报告处理时间
python
from sklearn.cluster import KMeans
from sklearn.feature_extraction.text import TfidfVectorizer
# 1. 提取文本特征
vectorizer = TfidfVectorizer(stop_words='english')
X = vectorizer.fit_transform(bug_reports['description'])
# 2. 聚类相似缺陷(假设分5类)
kmeans = KMeans(n_clusters=5, random_state=42)
clusters = kmeans.fit_predict(X)
# 3. 结果分析
bug_reports['cluster'] = clusters
print(bug_reports.groupby('cluster')['description'].count()) # 查看每类缺陷数量5. 回归模型:预测测试执行时间
测试场景:优化测试资源调度
python
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_absolute_error
# 特征:测试步骤数 + 涉及服务数 + 数据量大小
X = tests[['step_count', 'services_involved', 'data_size_mb']]
y = tests['execution_time_sec']
# 训练回归模型
model = Ridge(alpha=1.0)
model.fit(X_train, y_train)
# 评估模型
y_pred = model.predict(X_test)
mae = mean_absolute_error(y_test, y_pred) # 平均绝对误差:12.3秒6. 模型评估:验证测试效果
测试工程师必须掌握的评估技术:
python
from sklearn.metrics import classification_report, confusion_matrix
# 分类模型评估
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred))
print("混淆矩阵:\n", confusion_matrix(y_test, y_pred))
# 输出示例:
precision recall f1-score support
0 0.92 0.95 0.93 120 # 通过类
1 0.88 0.82 0.85 60 # 失败类
accuracy 0.91 180四、Scikit-learn 在测试中的典型应用场景
| 测试领域 | 问题类型 | 推荐算法 | 应用效果 |
|---|---|---|---|
| 缺陷优先级分类 | 文本分类 | SGDClassifier (TF-IDF) |
自动区分 P0/P1/P2 缺陷 |
| 测试失败根因分析 | 多分类问题 | RandomForest |
识别失败原因:环境/数据/代码缺陷 |
| 性能瓶颈预测 | 回归分析 | GradientBoostingRegressor |
提前发现接口响应时间劣化 |
| 测试用例去冗余 | 聚类 | DBSCAN |
合并高度相似的测试用例 |
| 视觉测试差异检测 | 图像特征 + 分类 | PCA + SVM |
识别UI细微差异 |
五、实操举例说明
# 场景:自动分类缺陷报告
from sklearn.cluster import KMeans
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
# 1. 提取文本特征
vectorizer = TfidfVectorizer(stop_words='english')
bug_reports = {
'description': ['登录页无响应', '无法提交表单', '密码重置失败', '登录超时', '验证码不显示','按钮无法点击','按钮点击无反应','字符取值错误'],
'cluster': []
}
X = vectorizer.fit_transform(bug_reports['description'])
# 2. 聚类相似缺陷(假设分5类)
kmeans = KMeans(n_clusters=5, random_state=42)
clusters = kmeans.fit_predict(X)
# 3. 结果分析
bug_reports['cluster'] = clusters
df = pd.DataFrame(bug_reports)
# 按聚类分组后,打印每个聚类的具体描述
for cluster_id, group in df.groupby('cluster'):
print(f"聚类 {cluster_id} 包含的缺陷:")
for desc in group['description']:
print(f"- {desc}")
print("---")-
vectorizer = TfidfVectorizer(stop_words='english')
-
作用是创建一个TF-IDF 文本特征提取器,用于将文本数据转换为数值特征向量。
-
TfidfVectorizer:这是 scikit-learn 库中用于实现 TF-IDF算法的工具类,它能把人类可读的文本翻译成机器学习算法能理解的数字向量,同时还会自动忽略无意义的常用词,让翻译结果更精准。
- TF(词频):衡量一个词在某篇文档中出现的频率,出现次数越多,权重越高。
- IDF(逆文档频率) :衡量一个词在所有文档中的普遍重要性,在越少文档中出现的词(越独特),权重越高。
两者结合可以将文本转换为能体现词语重要性的数值向量。
-
stop_words='english' :这是一个参数设置,表示在处理文本时会自动过滤掉英文停用词 (如 "the"、"and"、"is" 等)。
这些词在英文中出现频率极高,但通常不携带实际语义,过滤后可以减少噪音,让特征更聚焦于有意义的词汇。
-
-
vectorizer.fit_transform(bug_reports'description')
-
将文本数据转换为机器学习算法可处理的数值特征矩阵,是文本特征提取的核心步骤。它完成了两个关键操作:
-
拟合(fit) :让
vectorizer(TF-IDF 提取器)"学习" 文本数据的特征,包括:- 分析所有文本中的词汇,构建一个词汇表(比如将 "登录""响应""表单" 等词映射为唯一的索引)。
- 计算每个词的 IDF(逆文档频率)值,评估其在整个文本集合中的重要性。
-
转换(transform):将原始文本数据转换为 TF-IDF 数值矩阵:
- 矩阵
X的每一行对应一个文本(如一条缺陷报告)。 - 每一列对应词汇表中的一个词。
- 矩阵中的数值是该词在对应文本中的 TF-IDF 分数(综合了词频和重要性的权重)。
- 矩阵
-
-
-
KMeans
- 是一种经典的无监督聚类算法,全称为 K - 均值聚类(K-Means Clustering)。它的核心作用是:将一堆没有标签的数据,自动划分成 K 个不同的组别(聚类),使得同一组内的数据相似度高,不同组的数据相似度低。
-
kmeans = KMeans(n_clusters=5, random_state=42)
random_state=42是为了保证代码运行结果的可重复性 而设置的参数。相当于给随机过程设定了一个 "种子值"(这里的种子是 42)。无论你运行多少次代码,只要random_state保持不变,算法中涉及的随机操作都会产生相同的结果。- 以 KMeans 为例,它在初始阶段会随机选择 K 个聚类中心 ,这个随机选择会影响最终的聚类结果 ------ 即使是同一组数据,不同的初始中心可能会得到略有差异的聚类结果。
- 为什么是42 ?这是编程领域的一个 "梗"(源自《银河系搭车客指南》中 "生命、宇宙及一切的终极答案是 42")。实际使用中,你可以换成任何整数(如 0、100 等),只要保持固定,就能保证结果可重复。
-
clusters = kmeans.fit_predict(X)
- 对特征矩阵 X 执行 KMeans 聚类,并返回每个样本所属的聚类标签。
-
df = pd.DataFrame(bug_reports)
- 将字典格式的
bug_reports转换为 pandas 数据框(DataFrame),方便进行数据处理和分析。
- 将字典格式的