点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-30-新发布【1T 万亿】参数量大模型!Kimi‑K2开源大模型解读与实践,持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年07月21日更新到: Java-77 深入浅出 RPC Dubbo 负载均衡全解析:策略、配置与自定义实现实战 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
章节内容
上节我们完成了如下的内容:
- Redis高可用 CAP-AP
- Redis主从模式
- Redis一主一从 一主多从
- Redis哨兵模式
- Redis哨兵模式 docker-compose测试
终于!我们更新完了Redis!现在我们开始更新Kafka。
Kafka介绍
起源与发展
Kafka最初是由LinkedIn公司于2010年开发的分布式消息系统。当时LinkedIn需要处理大量的活动流数据(如页面浏览、用户行为等),现有的消息系统无法满足其高吞吐量和低延迟的需求。2010年11月,LinkedIn将Kafka贡献给Apache软件基金会,2011年7月成为Apache顶级开源项目。
核心特性
Kafka是一个分布式、分区化、多副本的发布-订阅消息系统,具有以下特点:
- 分布式架构:采用主从结构,支持水平扩展
- 分区机制:将消息分散存储在不同节点上
- 多副本设计:通过ISR机制保证数据可靠性
- 基于Zookeeper:用于集群管理、元数据存储和协调
典型应用场景
- 日志收集 :常用于收集Nginx访问日志、应用日志等
- 示例:电商网站使用Kafka收集用户行为日志进行分析
- 消息服务 :作为企业级消息中间件
- 示例:订单系统与库存系统间的异步通信
- 流式处理:支持实时数据分析
- 事件溯源:记录系统状态变更历史
设计目标与技术实现
-
高效持久化:
- 时间复杂度O(1):通过分段日志和索引文件实现
- 存储优化:采用顺序I/O,避免随机读写
- 示例:处理TB级数据时仍保持毫秒级访问延迟
-
高吞吐量:
- 基准测试:单机可达每秒100K+消息处理
- 优化手段:零拷贝技术、批量发送、压缩传输
- 示例:在普通服务器(16核,32G)上可达10万+/秒的消息吞吐
-
分区与顺序保证:
- 分区策略:支持Hash、Range等分区算法
- 顺序性:同一分区内消息严格有序
- 示例:电商订单状态变更需要严格有序处理
-
多处理模式支持:
- 实时处理:通过Kafka Streams实现
- 离线处理:与Hadoop/Spark集成
- 示例:实时风控系统+离线用户画像分析
-
水平扩展能力:
- 动态扩容:支持在线添加节点
- 无停机扩展:通过分区重平衡实现
- 示例:双11期间临时扩容应对流量高峰
架构优势
- 解耦生产消费系统
- 削峰填谷应对流量波动
- 高容错性和可靠性
- 支持多种语言客户端

生产消费图
消息模式详解
消息传递模式
主流的消息传递主要分为两种基本模式:
-
点对点(Queue)模式:
- 特点:每条消息只能被一个消费者处理
- 示例:银行转账系统,订单处理系统
- 工作方式:生产者发送消息到队列,消费者从队列获取消息处理后确认
-
发布-订阅(Topic)模式:
- Kafka采用这种模式
- 特点:一条消息可以被多个订阅者接收
- 示例:新闻推送系统,股票行情系统
- 工作方式:生产者发布消息到主题,多个消费者可以订阅同一主题接收消息
消息获取机制
对于消息中间件,消息获取可分为两种方式:
-
推(Push)模式:
- 服务器主动将消息推送给消费者
- 优点:实时性好
- 缺点:可能导致消费者过载
- 典型系统:RabbitMQ
-
拉(Pull)模式:
- Kafka采用这种模式
- 消费者主动从服务器拉取消息
- 优点:消费者可以控制消费节奏
- 缺点:可能产生延迟
- 实现推送:可以通过消费者定时轮询的方式模拟推送效果
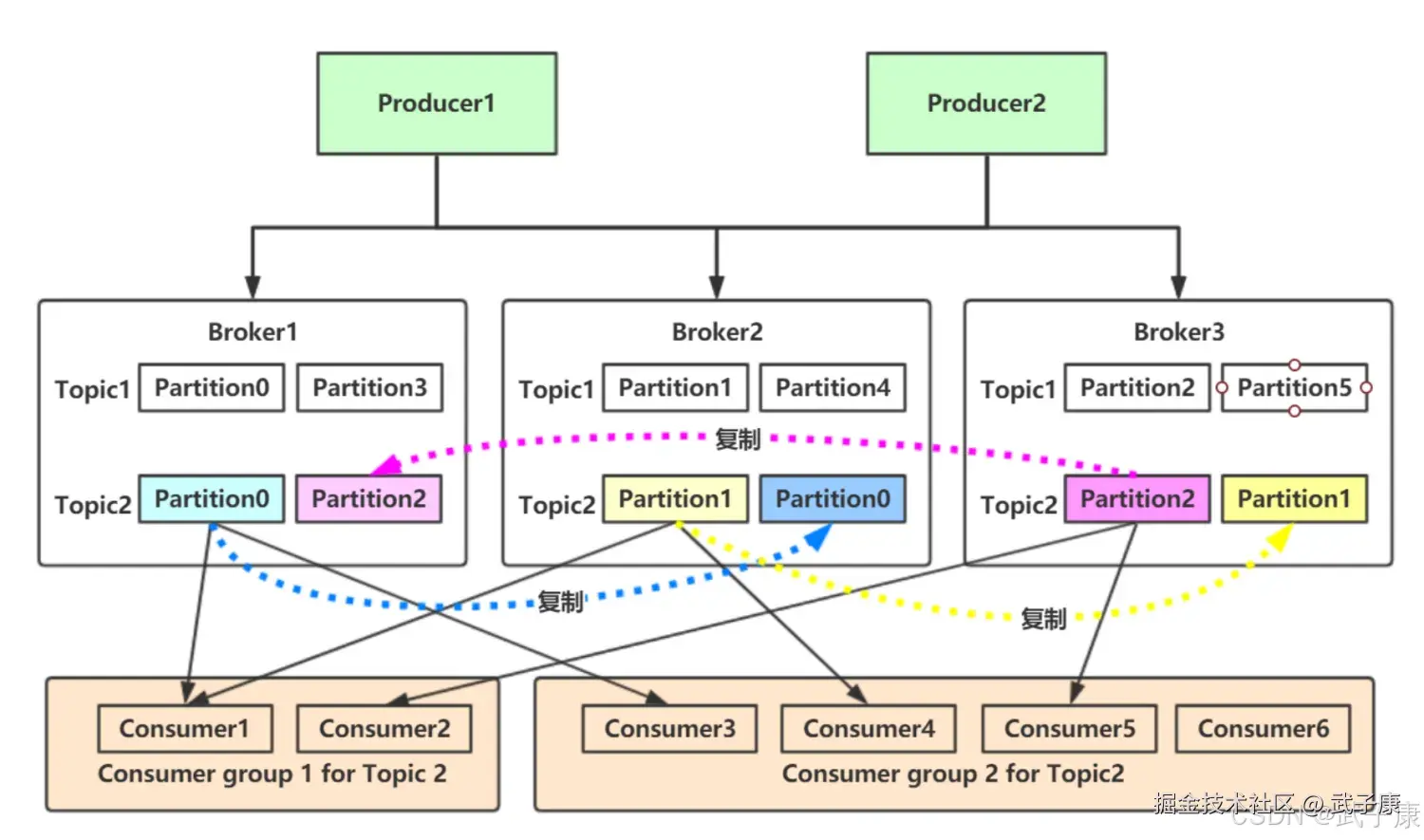
Kafka集群架构
Kafka的分布式架构设计:
-
服务器部署:
- 可以部署在多个服务器上形成集群
- 支持跨多个数据中心部署,提高容灾能力
- 典型部署:至少3-5个broker节点组成集群
-
主题(Topic)管理:
- 数据按主题分类存储
- 一个主题可以划分为多个分区(Partition)
- 分区可以设置多个副本(Replica),通常为2-3个
- 示例:一个订单主题可分为16个分区,每个分区有2个副本
消息记录结构
Kafka中的消息记录包含以下要素:
-
键(Key):
- 可选字段
- 用于决定消息写入哪个分区
- 示例:用户ID可作为key保证同一用户的消息顺序
-
值(Value):
- 实际的消息内容
- 可以是任意格式的数据
- 通常为JSON、Avro或Protobuf格式
-
时间戳(Timestamp):
- 记录消息创建时间或写入时间
- 可用于消息排序和过期处理
- 示例:事件时间戳可用于流处理的时间窗口计算
-
其他元数据:
- 偏移量(Offset):消息在分区中的唯一标识
- 头信息(Headers):可携带额外的元数据
核心API
- ProducerAPI:允许应用程序记录流发布到一个或者多个Kafka主题
- ConsumerAPI:允许应用程序订阅一个或多个主题并处理并生成记录流
- StreamAPI:允许应用程序充当流处理器,使用一个或多个主题的输入流,并生成一个或者多个输出流。从而有效的将输入流转换为输出流。
- ConnectorAPI:允许构建和运行将Kafka主题连接到现有应用程序或数据系统的可重用生产者或使用者
Kafka优势详解
高吞吐能力
Kafka在设计上采用了一系列优化措施来实现极高的消息吞吐量:
- 高效的消息批处理机制,可将多个小消息批量发送,减少网络开销
- 顺序磁盘I/O写入方式,充分利用磁盘顺序读写的高性能特性
- 零拷贝技术(Zero-Copy),减少数据在内核空间和用户空间的拷贝次数
- 分区并行处理架构,单机每秒可处理几十万到上百万条消息
- 即使存储TB级别的消息数据,系统仍能保持稳定运行,不会因数据量增大而显著降低性能
高性能表现
Kafka具有出色的性能表现:
- 单个Kafka节点可同时支持上千个客户端连接
- 采用高效的网络通信协议,最大化利用带宽资源
- 完善的负载均衡机制,确保各节点负载均衡
- 系统设计保证零停机时间,支持7×24小时不间断运行
- 数据多重保护机制,确保零数据丢失
- 消息处理延迟低,通常在毫秒级别
持久化数据存储
Kafka提供可靠的数据持久化方案:
- 所有消息默认持久化到磁盘,而不仅仅是内存
- 可配置的保留策略(按时间或大小)
- 通过副本机制(Replication)防止数据丢失
- 支持多副本配置(通常3副本)
- 自动处理副本同步和故障转移
- 数据压缩支持(支持gzip、snappy、lz4等多种压缩算法)
分布式与可扩展性
Kafka是真正的分布式系统:
- 采用无中心架构,所有节点对等
- 支持水平扩展,可轻松添加新节点
- Producer和Consumer都可以分布式部署
- Producer可自动发现集群节点
- Consumer支持分组消费
- 扩展过程无需停机,不影响线上服务
- 自动负载均衡,新节点加入后自动分担负载
容错与可靠性
Kafka具备完善的容错机制:
- 分布式架构天然具备容错能力
- 分区(Partition)机制将数据分散存储
- 多副本(Replica)保证数据可靠性
- 自动故障检测和恢复机制
- 支持ISR(In-Sync Replica)机制保证数据一致性
- 完善的监控和告警系统
客户端状态管理
Kafka的消费状态管理特点:
- 消费状态由Consumer自行维护(通过offset)
- 支持手动和自动提交offset
- Consumer故障时可自动重新平衡
- 支持从指定offset重新消费
- Consumer增加或减少时自动重新分配分区
场景支持
Kafka支持多样化的应用场景:
- 在线(Online)场景:
- 实时数据处理
- 即时消息推送
- 实时监控告警
- 离线(Offline)场景:
- 大数据分析
- 数据仓库ETL
- 日志归档
- 混合场景:
- 实时+批处理混合架构
- 流批一体处理
多语言支持
Kafka提供丰富的客户端支持:
- 官方支持的客户端语言:Java、Scala
- 社区维护的客户端:Python、Go、C/C++、Node.js、Ruby等
- REST Proxy支持其他语言通过HTTP接入
- 完善的API文档和示例代码
- 各语言客户端功能基本一致
应用场景
- 日志收集:可以用Kakfa进行日志的收集
- 消息系统:解耦生产者和消费者
- 用户活动跟踪:用户行为被记录到Kafka中,消费者取到之后对用户的数据进行分析处理
- 运营指标:记录运营监控数据、报警和报告
- 流式处理:比如SparkStream、Storm
基本架构
消息和批次
消息结构
Kafka的数据单元称为消息(message),可以类比为数据库中的一行记录或数据条目。每条消息由以下几部分组成:
- 消息体:实际要传输的数据内容,以字节数组形式存储
- 键值 :可选字段,也是一个字节数组,通常用于:
- 消息路由(决定写入哪个分区)
- 日志压缩(相同key的消息会被覆盖)
- 业务标识(如用户ID、订单号等)
- 元数据:包括时间戳、消息头(headers)等辅助信息
批次处理机制
- **批次(batch)**是指属于同一主题(topic)和分区(partition)的一组消息集合
- 批量处理的好处:
- 显著减少网络I/O开销(一次传输多条消息)
- 提高吞吐量(单位时间内处理更多消息)
- 降低服务端处理压力
- 批次大小的权衡:
- 较大的批次:提高吞吐但增加延迟
- 较小的批次:降低延迟但增加网络开销
- 典型配置:16KB~1MB(根据业务场景调整)
消息模式
模式选型对比
| 格式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| JSON | 易读性好,广泛支持 | 冗余度高,无类型检查 | 简单系统,调试阶段 |
| XML | 结构化强,支持命名空间 | 冗余度最高,解析开销大 | 传统企业系统 |
| Protocol Buffers | 高效二进制编码 | 需要预编译,模式演进受限 | Google生态,性能敏感场景 |
| Apache Avro | 紧凑二进制,模式演进灵活 | 需要模式注册表 | 大数据生态,Kafka最佳实践 |
Apache Avro详解
Avro成为Kafka推荐的消息格式主要因为:
- 紧凑存储:二进制编码比文本格式节省50%以上空间
- 模式演进 :支持向后/向前兼容的字段变更
- 可添加新字段(需设默认值)
- 可删除字段(需确保无消费者依赖)
- 可修改字段类型(需兼容)
- 运行时绑定:不需要生成代码即可读写数据
- 模式注册表 :集中管理所有消息格式定义
- 生产者和消费者通过ID获取模式
- 确保上下游数据格式一致
数据格式一致性的重要性
在Kafka生态中保持统一的消息格式可以:
- 解耦生产消费:生产者升级模式不影响现有消费者
- 简化系统集成:不同团队使用相同数据表示
- 保证数据处理正确性:避免因格式错误导致的数据丢失
- 实现跨语言交互:各种编程语言通过标准格式交换数据
实际案例:某电商平台使用Avro定义订单消息,包含:
avro
{
"type": "record",
"name": "Order",
"fields": [
{"name": "orderId", "type": "string"},
{"name": "userId", "type": "string"},
{"name": "items", "type": {"type": "array", "items": {
"type": "record",
"name": "Item",
"fields": [
{"name": "sku", "type": "string"},
{"name": "quantity", "type": "int"}
]
}}},
{"name": "createTime", "type": "long"}
]
}主题和分区
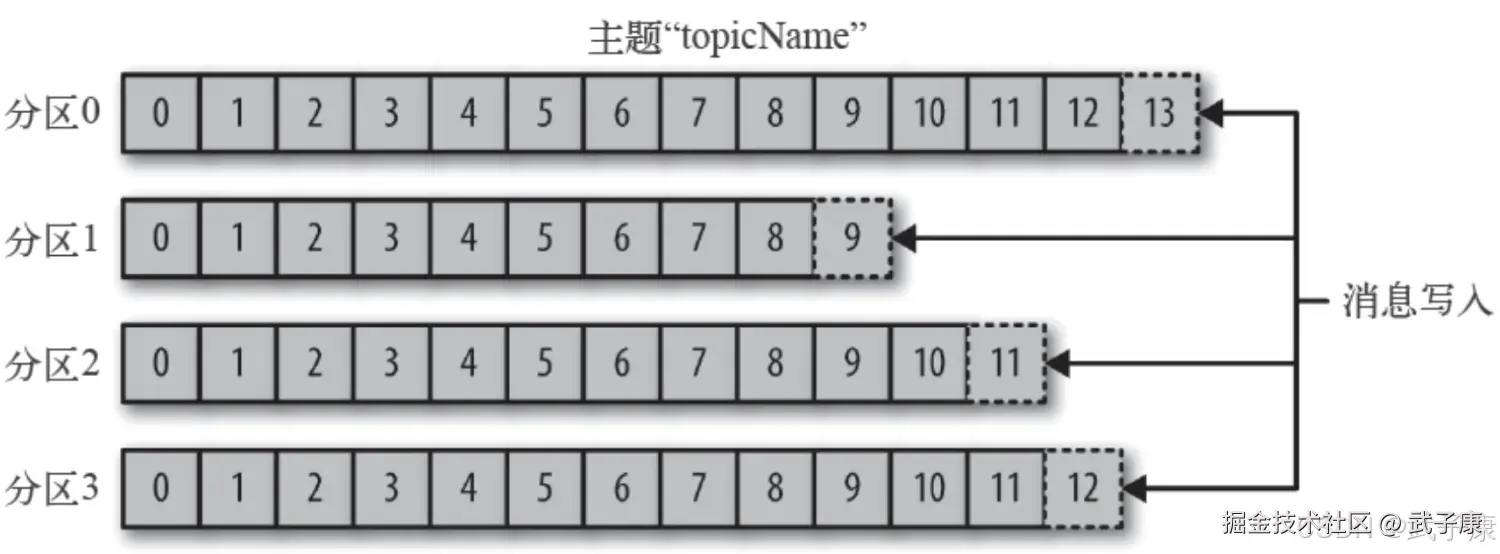
Kafka的消息通过主题进行分类,主题可比数据库表或者文件系统里的文件夹。主题可以被分为若干区域,一个主题通过分区分布于Kafka集群中,提供了横向扩展的能力。
生产和消费者
生产者创建消息,消费者消费消息。 生产者在默认的情况下会把消息均衡的发布到主题的所有分区上:
- 直接指定消息的分区
- 根据消息的key散列取模得出分区
- 轮询指定分区
消费者通过偏移量来区分已经读过的消息,从而消费消息。 消费者是消费组的一部分,消费组保证每个分区只有一个消费者使用,避免重复消费。
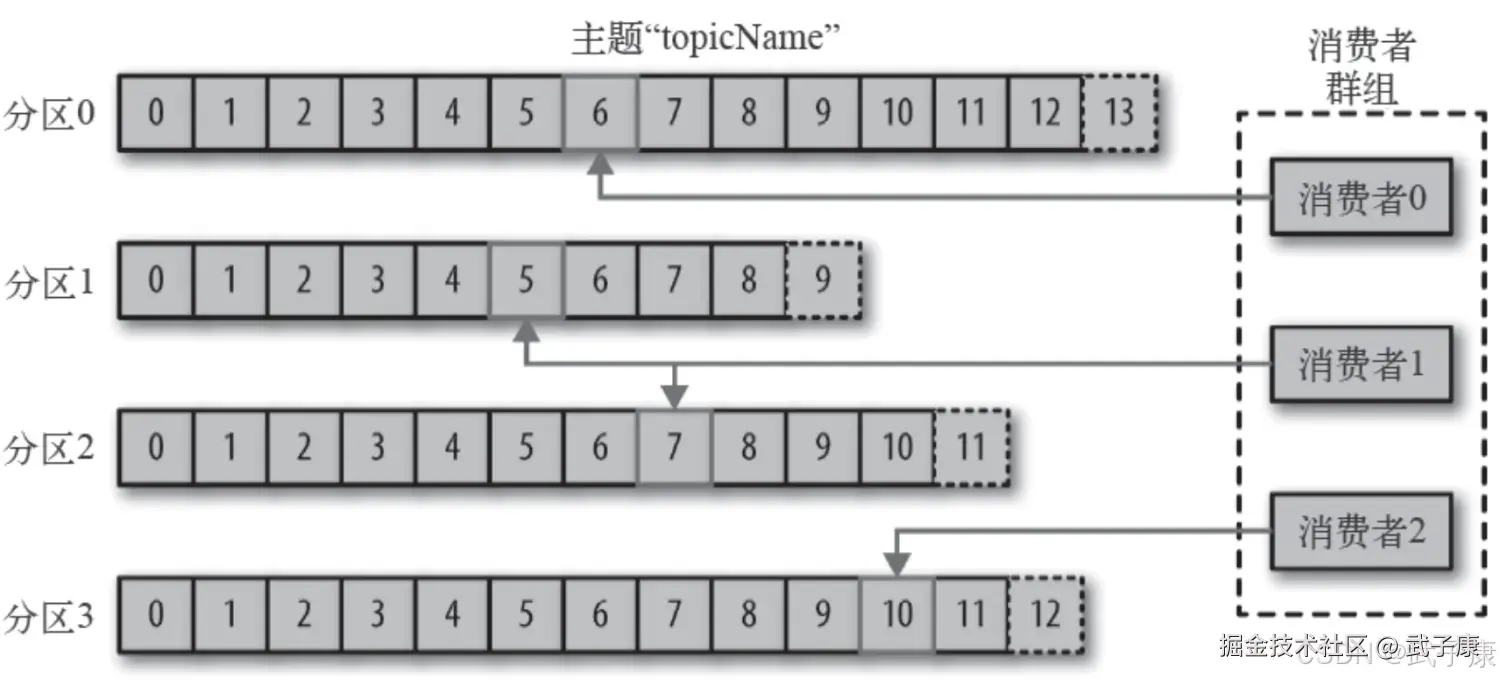
Broker 和 集群
一个独立的Kafka服务器成为Broker,Broker接受来自生产者的消息,为消息设置偏移量,并提交到磁盘进行保存。 Broker为消费者提供服务,对读取分区的请求做出响应,返回已提交到磁盘上的消息。 单个Broker可以轻松处理数千个分区以及每秒百万的消息量。
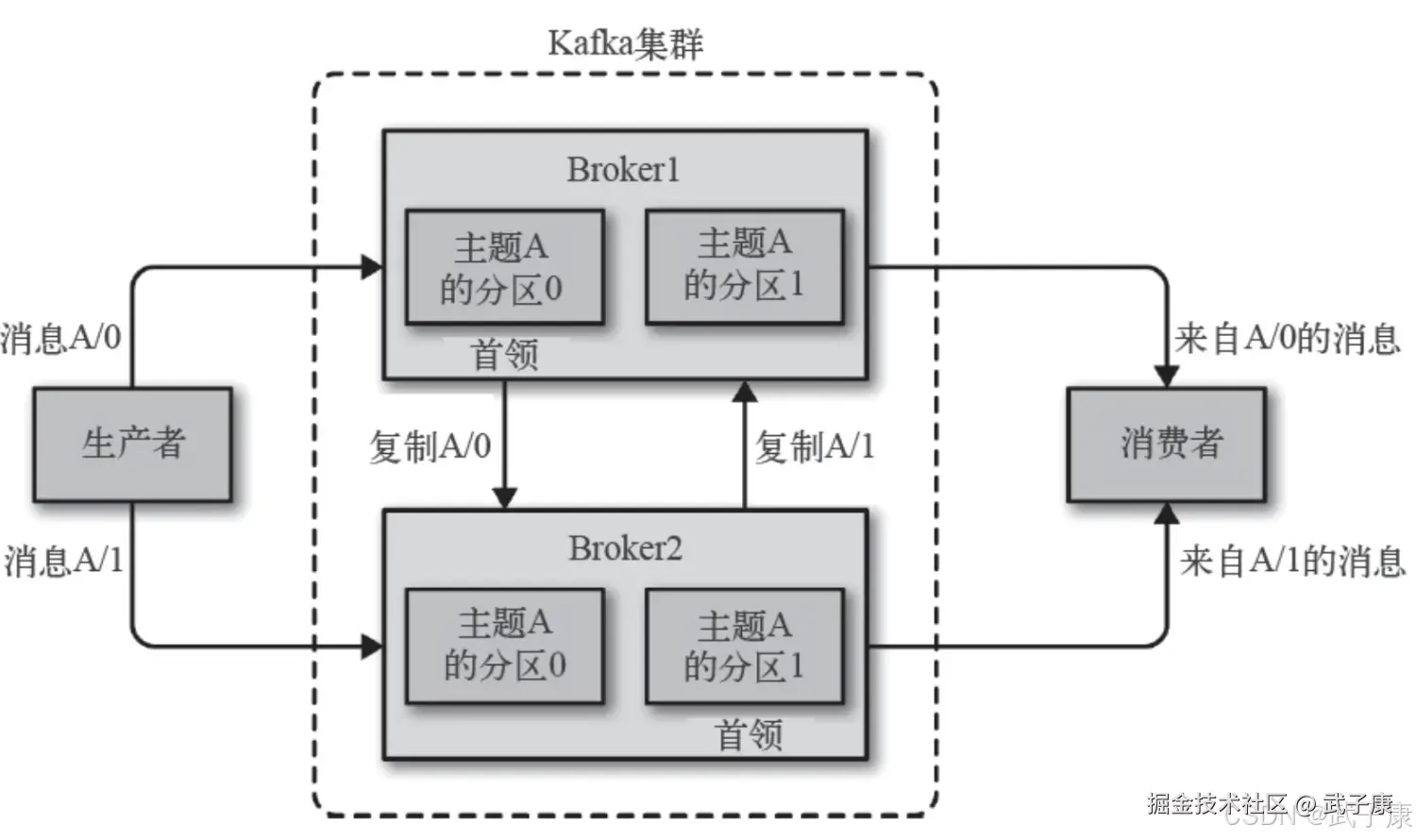
每一个集群都有一个Broker是集群控制器(自动从集群的活跃成员中选举出来) 控制器负责管理工作:
- 将分区分配给Broker
- 监控Broker
集群中一个分区属于一个Broker,该Broker称为分区首领。
- 一个分区可以分配给多个Broker,此时会发生分区复制。
- 分区的复制提高了消息冗余、高可用。
- 副本分区不负责处理消息的读写。