一、JDK 1.7:分段锁(Segment Locking)
核心思想
-
数据分片 :将整个哈希表拆分为多个
Segment(默认16个),每个Segment独立加锁,不同Segment的读写可并行。 -
锁粒度 :每个
Segment继承ReentrantLock,仅操作同一Segment的线程竞争锁。
线程安全实现
-
写操作(put):
-
根据Key的Hash值定位到
Segment。 -
获取该
Segment的锁(lock())。 -
在
HashEntry链表内执行插入/更新。 -
释放锁(
unlock())。
-
-
读操作(get):
- 无需加锁,依赖
volatile修饰的HashEntry.value保证可见性。
- 无需加锁,依赖

缺陷
-
锁粒度较粗 :单个
Segment包含多个桶,高并发时仍可能竞争。 -
扩容效率低 :仅
Segment内部的HashEntry数组可扩容,全局扩容需逐个Segment处理。
二、JDK 1.8:CAS + synchronized + 红黑树
核心优化
-
取消分段锁 :使用全局
Node[] table,锁粒度细化到单个桶的头节点。 -
数据结构升级:链表长度≥8且数组长度≥64时,链表转为红黑树(查询时间复杂度O(n)→O(log n))。
-
并发控制 :
CAS(无锁化) +synchronized(悲观锁)组合。
线程安全实现
-
初始化与插入:
-
空桶 :通过
CAS添加头节点(无锁)。 -
非空桶 :用
synchronized锁定头节点,遍历链表/红黑树执行操作。
-
-
读操作 :
无锁,依赖
Node.val的volatile可见性。
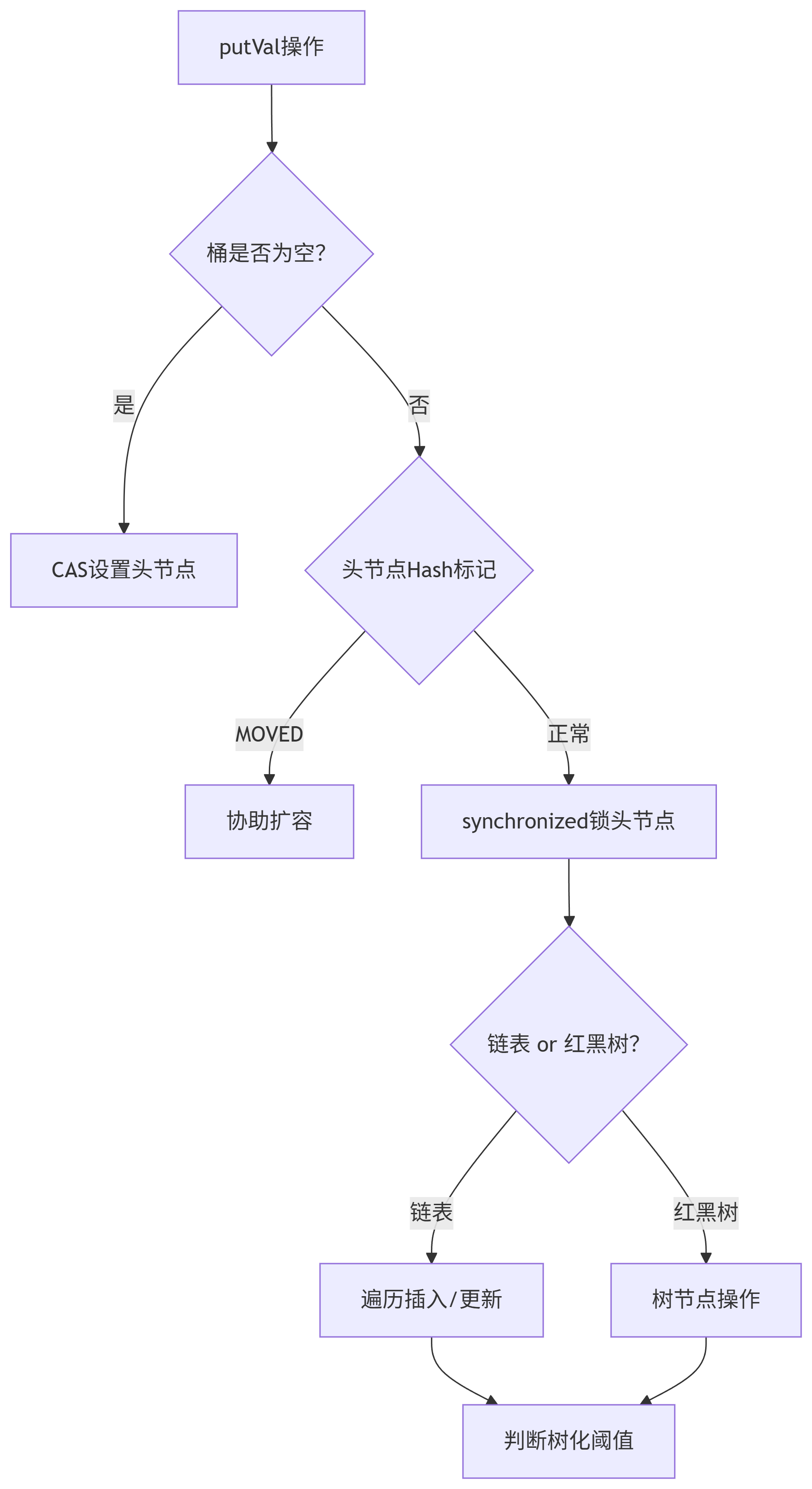
关键改进
-
性能提升:
-
锁竞争概率↓:从16段→数万桶独立锁。
-
无锁读:
volatile变量 +CAS减少阻塞。
-
-
扩容优化 :
支持多线程协同扩容(
ForwardingNode标记迁移状态),避免单点瓶颈。
三、JDK 1.7 vs 1.8 对比总结
| 维度 | JDK 1.7 | JDK 1.8 |
|---|---|---|
| 锁机制 | 分段锁(ReentrantLock) |
CAS + synchronized(桶级锁) |
| 数据结构 | 数组+链表 | 数组+链表/红黑树 |
| 锁粒度 | 段级(默认16锁) | 桶级(数万锁) |
| 并发性能 | 中等(段间并行) | 高(桶间并行 + 无锁读) |
| 扩容 | 单Segment独立扩容 | 多线程协同扩容 |
四、总结
Q:ConcurrentHashMap如何保证线程安全?JDK 1.8做了哪些优化?
A:
JDK 1.7 采用分段锁:
将哈希表拆分为多个
Segment(默认16个),每个Segment独立加锁。写操作需获取目标
Segment的ReentrantLock,不同Segment的读写可并行。缺陷:锁粒度较粗,高并发场景性能受限。
JDK 1.8 优化为桶级锁:
取消
Segment,使用Node[] table+链表/红黑树。线程安全通过:
CAS:初始化数组、插入空桶等无锁操作;
synchronized:锁定非空桶的头节点执行写操作;
volatile:保证Node.val的可见性(读操作无锁)。优化点:
锁粒度细化至单个桶,并发度↑;
链表长度≥8且数组≥64时转红黑树,查询效率↑(O(n)→O(log n));
多线程协同扩容,避免阻塞。