1 简介
GPT-SoVITS是一种语音合成模型,于2024年2月18日发布,它基于深度学习的语音合成框架,通过整合GPT(Generative Pre-trained Transformer)的自然语言理解能力与SoVITS(Soft Voice Isolation and Timbre Synthesis)的声纹特征建模技术,实现了「文本 -- 语音」的高保真映射与个性化声音克隆。其核心优势在于:
多模态融合 :支持文本、声纹、情感标签等多维度输入,生成兼具语义理解与情感表达的自然语音;
低资源适配 :通过少量样本即可完成声线迁移,降低专业配音的门槛;
场景化定制:可针对短视频创作、智能客服、有声书制作等场景优化韵律与音色,满足工业化部署需求。
1.1 安装
1. 下载
首先,从github上下载项目:
git clone https://github.com/RVC-Boss/GPT-SoVITS2. 自动安装
然后根据系统版本进行相应安装,如windows可以用如下命令进行安装:
conda create -n GPTSoVits python=3.10
conda activate GPTSoVits
pwsh -F install.ps1 --Device CU128 --Source HF-Mirror --DownloadUVR5其中CU128对应CUDA 12.8,这里可以根据自己环境配置CPU还是CUDA其他版本,HF-Mirror表示从清华镜像加速下载,--DownloadUVR5表明额外下载一个音源分离工具(可选)。
在执行该命令进行安装时,命令行提示找不到pwsh命令,这是因为:pwsh是PowerShell 7.x(即PowerShell Core)的命令行启动命令,不是旧版Windows自带的PowerShell 5.x(用powershell.exe启动)。这里需要执行以下命令安装最新版PowerShell 7:
winget install --id Microsoft.Powershell --source winget安装PowerShell 7(pwsh) 后,打开的PowerShell终端中Conda环境没有前缀提示了,比如不再显示:
(base) PS C:\Users\you>而是变成:
PS C:\Users\you>这是因为Conda的环境激活脚本默认只对PowerShell 5.x做了配置,而你现在用的是PowerShell 7(pwsh),它需要你手动初始化一下Conda环境支持。执行命令:
conda init powershell成功后它会提示你重启shell,重启后shell恢复前缀提示。
3. 手动安装
不知道是兼容性还是什么原因,pwsh -F install.ps1 --Device CU128 --Source HF-Mirror --DownloadUVR5命令执行过程中也会出现各种问题,不再调用这个脚本进行安装,而是一步步手动进行安装,首先安装必要依赖(省略conda环境创建及激活):
conda install ffmpeg cmake
torch torchaudio --index-url "https://download.pytorch.org/whl/cu128"
pip install -r extra-req.txt --no-deps
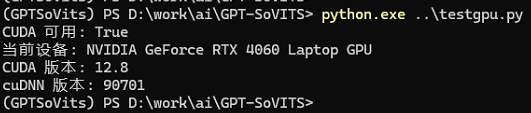
pip install -r requirements.txt安装完成后,可以用以下python文件检查torch是否支持显卡:
import torch
print("CUDA 可用:", torch.cuda.is_available())
print("当前设备:", torch.cuda.get_device_name(0))
print("CUDA 版本:", torch.version.cuda)
print("cuDNN 版本:", torch.backends.cudnn.version())结果显示如下:
根据实际网络情况选择下载源,下载5个文件:
"HF" {
Write-Info "Download Model From HuggingFace"
$PretrainedURL = "https://huggingface.co/XXXXRT/GPT-SoVITS-Pretrained/resolve/main/pretrained_models.zip"
$G2PWURL = "https://huggingface.co/XXXXRT/GPT-SoVITS-Pretrained/resolve/main/G2PWModel.zip"
$UVR5URL = "https://huggingface.co/XXXXRT/GPT-SoVITS-Pretrained/resolve/main/uvr5_weights.zip"
$NLTKURL = "https://huggingface.co/XXXXRT/GPT-SoVITS-Pretrained/resolve/main/nltk_data.zip"
$OpenJTalkURL = "https://huggingface.co/XXXXRT/GPT-SoVITS-Pretrained/resolve/main/open_jtalk_dic_utf_8-1.11.tar.gz"
}
"HF-Mirror" {
Write-Info "Download Model From HuggingFace-Mirror"
$PretrainedURL = "https://hf-mirror.com/XXXXRT/GPT-SoVITS-Pretrained/resolve/main/pretrained_models.zip"
$G2PWURL = "https://hf-mirror.com/XXXXRT/GPT-SoVITS-Pretrained/resolve/main/G2PWModel.zip"
$UVR5URL = "https://hf-mirror.com/XXXXRT/GPT-SoVITS-Pretrained/resolve/main/uvr5_weights.zip"
$NLTKURL = "https://hf-mirror.com/XXXXRT/GPT-SoVITS-Pretrained/resolve/main/nltk_data.zip"
$OpenJTalkURL = "https://hf-mirror.com/XXXXRT/GPT-SoVITS-Pretrained/resolve/main/open_jtalk_dic_utf_8-1.11.tar.gz"
}
"ModelScope" {
Write-Info "Download Model From ModelScope"
$PretrainedURL = "https://www.modelscope.cn/models/XXXXRT/GPT-SoVITS-Pretrained/resolve/master/pretrained_models.zip"
$G2PWURL = "https://www.modelscope.cn/models/XXXXRT/GPT-SoVITS-Pretrained/resolve/master/G2PWModel.zip"
$UVR5URL = "https://www.modelscope.cn/models/XXXXRT/GPT-SoVITS-Pretrained/resolve/master/uvr5_weights.zip"
$NLTKURL = "https://www.modelscope.cn/models/XXXXRT/GPT-SoVITS-Pretrained/resolve/master/nltk_data.zip"
$OpenJTalkURL = "https://www.modelscope.cn/models/XXXXRT/GPT-SoVITS-Pretrained/resolve/master/open_jtalk_dic_utf_8-1.11.tar.gz"
}之后将前三个压缩包pretrained_models.zip、G2PWModel.zip、uvr5_weights.zip分别解压到当前目录下的:GPT_SoVITS、GPT_SoVITS/text、tools/uvr5目录下,再将nltk_data.zip解压到当前目录,最后将open_jtalk_dic_utf_8-1.11.tar.gz压缩包解压到env的python环境site-packages库目录下,可参考如下内容进行操作:

1.2 音频预处理
以下几个小结内容主要转载了文章最后参考1内容,运行以下命令,启动GUI:
python webui.py zh_CN用浏览器登陆http://localhost:9874,进入后台Web主界面,如下所示:
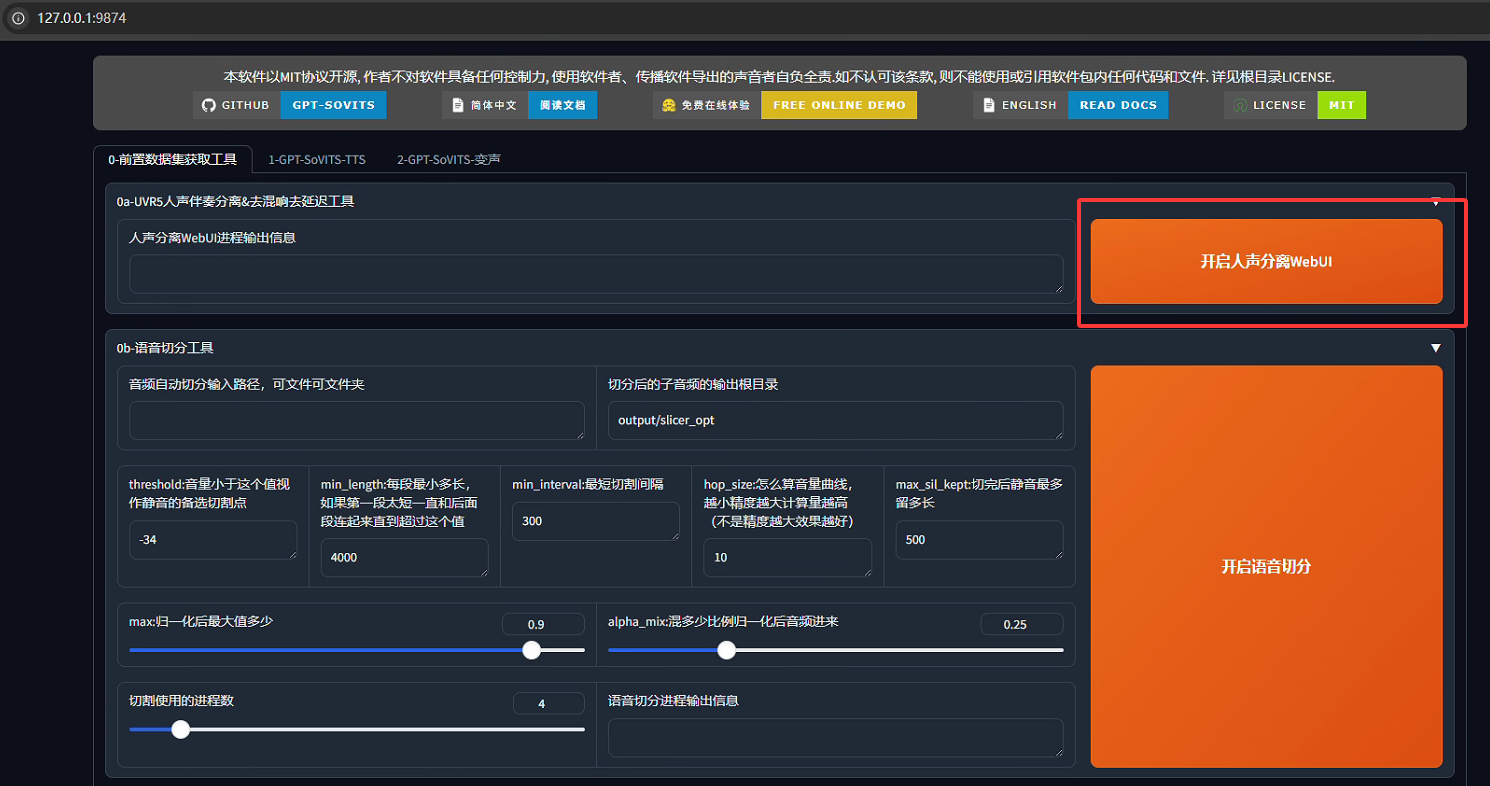
1. 人声分离
我们收集到的数据不一定是纯粹的语音,需要进一步的提取人声,例如去除伴奏,去除混响(可以理解为回音)等,在主界面中单击"开启人声分离WebUI",浏览器会打开UVR5的webui,如果没有跳转就在游览器输入http://localhost:9873进行访问即可。
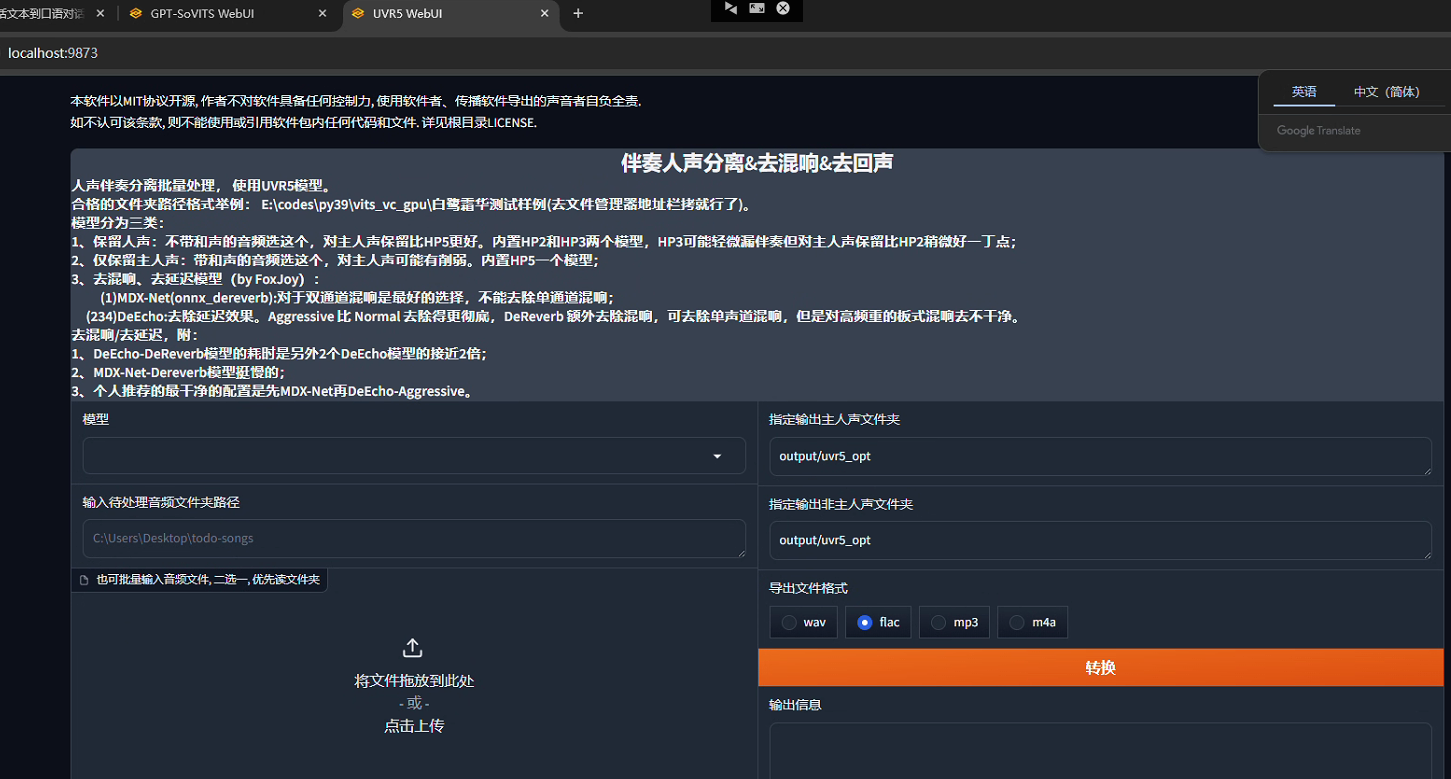
在该webui主界面最上面已经介绍了其主要功能,下方左侧,首先需要选择使用的"模型",然后需要"输入待处理音频文件夹路径"或者"批量输入音频文件",这两种方式二选一,如果文件夹路径不为空则优先读文件夹。右侧指定输出人声及非人声文件夹路径,导出文件格式部分有4种格式文件可选,这里选择未压缩格式wav,最后单击"转换"即可。
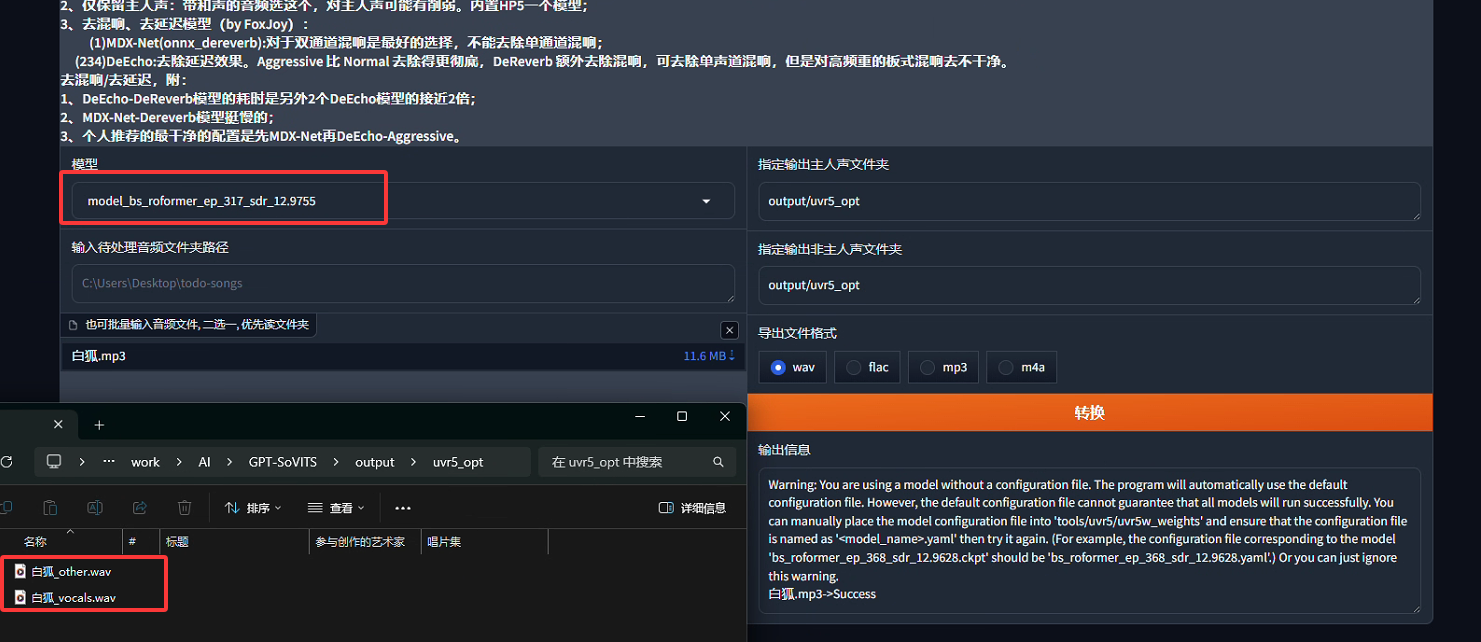
接下来要举一个实例l说明如何纯净的人声,该实例需过三遍模型,分别是提取人(去除伴奏),去除混响,去除第二次混响。
第一遍:提取人声,选择模型model_bs_roformer_ep_317_sdr_12.9755,该模型的用途是提取人声,我们的音频中可能会混有bgm,杂音等等,我们需要用这个模型来提取我们需要的纯粹的人声。运行过程中,在输出信息框有一个告警提示信息,非致命可忽略。这时在output\uvr5_opt目录可以看到两种文件,一种文件名会带_other,是分离出来的伴奏音乐或者杂音,另一种文件名会带_vocals,是分离出来的纯人声,正是我们需要的。将_other删除,并在项目根目录下创建wav\proc1文件夹,将_vocals.wav文件剪切到该文件夹。
第二遍:去除混响,选择模型onnx_dereverb_By_FoxJoy,混响可以理解为录音时的回音,去除混响可以理解成降噪,去除混响后的音频文件会是更加纯净的人声,有助于模型训练学习。以下产生了第二遍的结果,可以看到带有_main名字的文件名和_other的文件名,同样的,把带_other的文件全部删掉,那是不需要的混响音。然后再建一个新的文件夹wav\proc2,将uvr5_opt文件夹下_main文件移过去,为第三次提纯做准备。
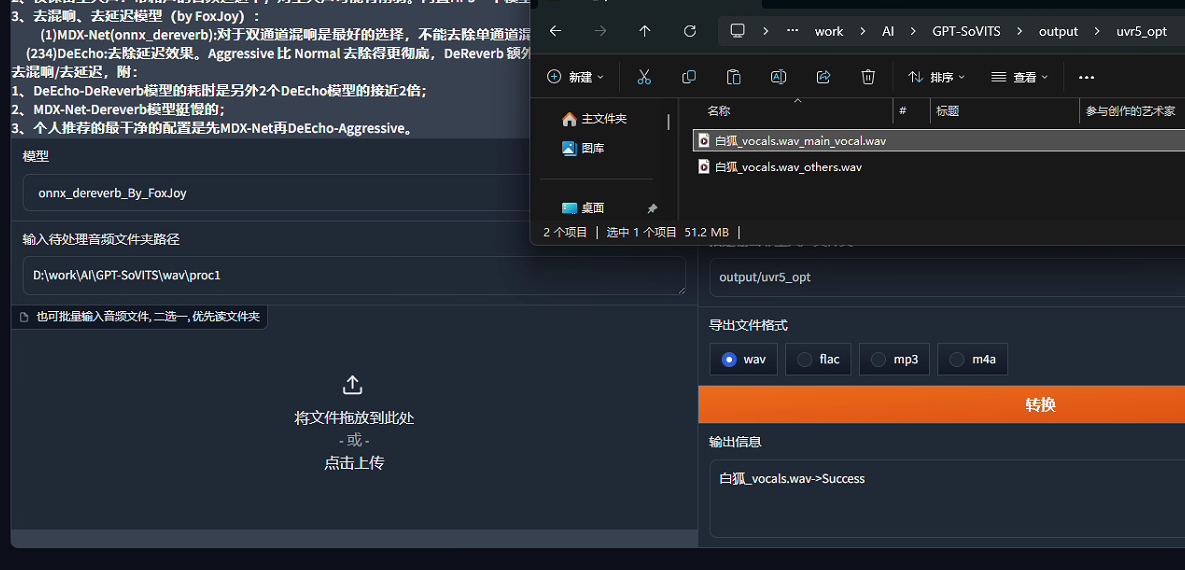
第三遍:去除混响,选择模型VR-DeEchoAggressive,操作都大差不差,这是第三次提纯,同样是去除混响。继续等待完成即可,完成后,会有文件名带有instrument_的音频文件,还有vocal_的音频文件,instrument_的音频文件为提纯后的杂音,删除即可。然后全部转移到新文件夹wav\proc3。
到这一步人声提取就完成了,我们得到了去除杂音和混响的干人声,可以关闭人声分离webui了,防止自己搞不清工具界面和节省显存。
2. 语音切分
首先先要理解为什么要切割音频:
显存限制:TTS模型通常以固定长度的音频片段为输入,长音频直接训练会导致显存溢出(OOM)。切割后,每段音频长度适配模型输入(例如3~10秒)
数据标准化:避免一句话包含过多静音或杂音,提升训练效率和质量。便于文本与音频的严格对齐(强制对齐工具对短句效果更好)
音量均衡:切割前统一音量(如-9dB到-6dB)可防止部分片段过响或过轻,影响声学模型稳定性
一段完美的音频应该是没有任何噪音杂音混响等,音量统一在-9dB到-6dB之间。配置部分只有min_interval参数按照参考文章1中的建议改为100,其他值都保留默认值,之后点击开始语音切分:
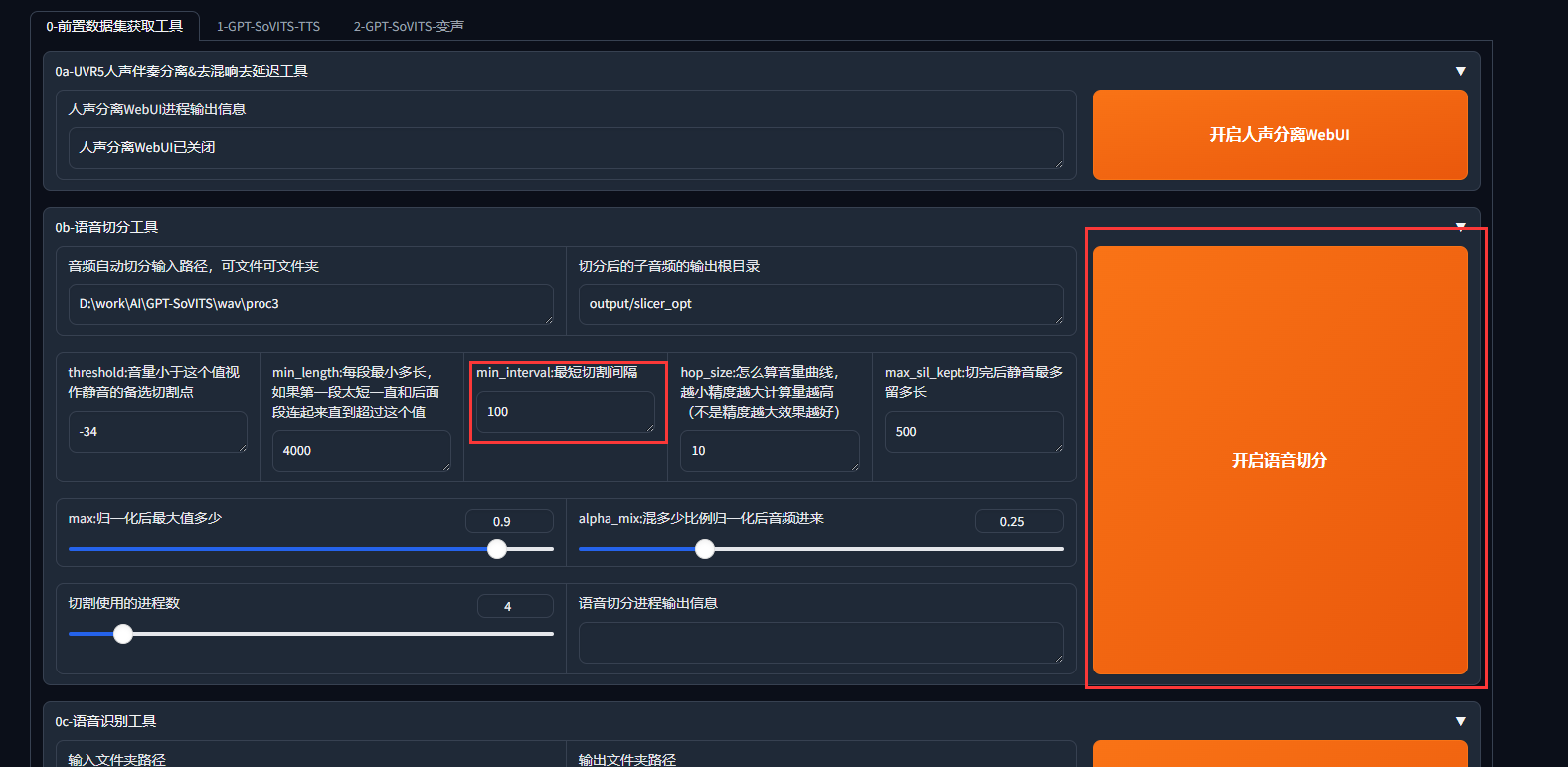
输出信息中显示"语音切分已完成"后,进入输出路径进行查看:
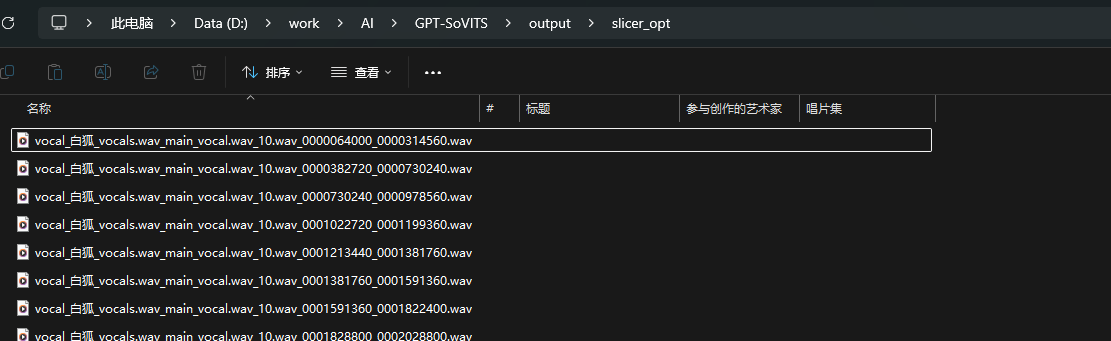
音频文件音质正常,长度在5s左右,则语音切分完毕。
3. 语音识别
这一步也可以称为ai标注,为什么要做标注,因为训练的时候是根据你的音频文件还有你的文本文件来进行训练的,相当于你需要叫模型,这一个字是这样读的(然后给出你的文本和音频),这个语音识别只是一个辅助工具,帮你大概的识别出人物所讲出的句子,
你文本的句子准确度越高,训练出来的模型质量也会越好。之后保持默认配置,直接"开启语音识别":
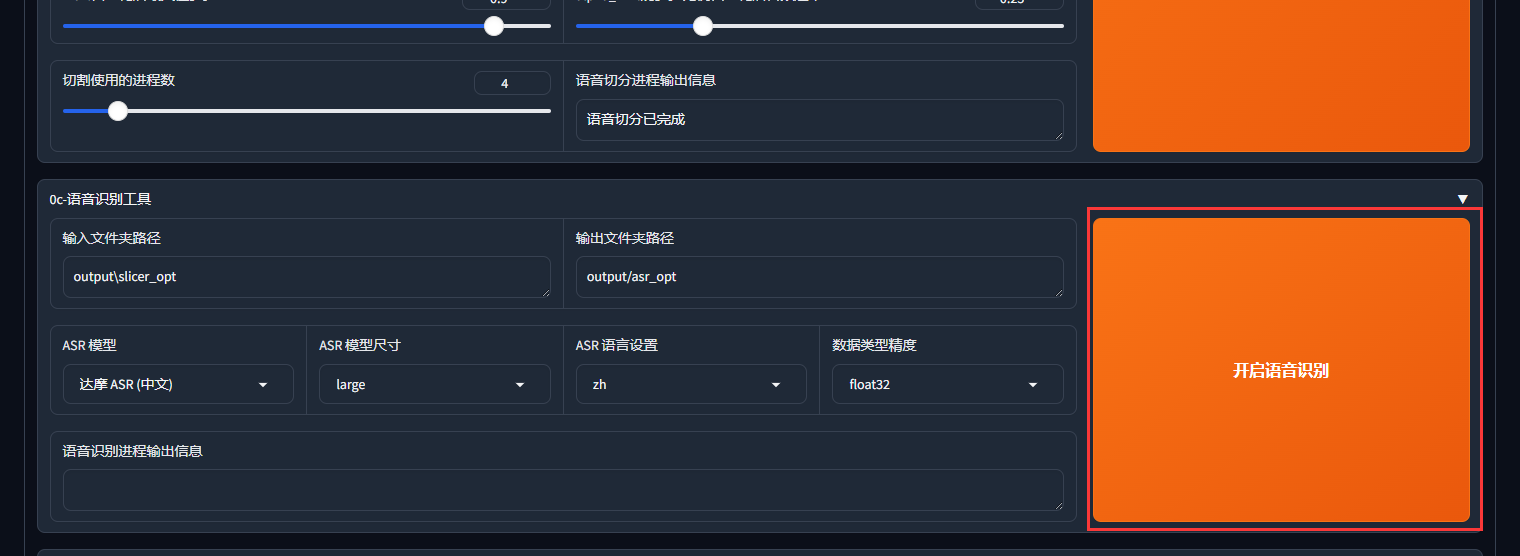
第一次执行这一步时会下载一些模型文件时间较长,请耐心等待,最终会生成语音识别文本文件:

到这一步,我们就有了ai出来的文本和处理好的音频素材了。
4. 音频标注
上一步语音识别只是一个大概,是ai出来的文本,还需要手动来校准,单击"开启音频标注WebUI":
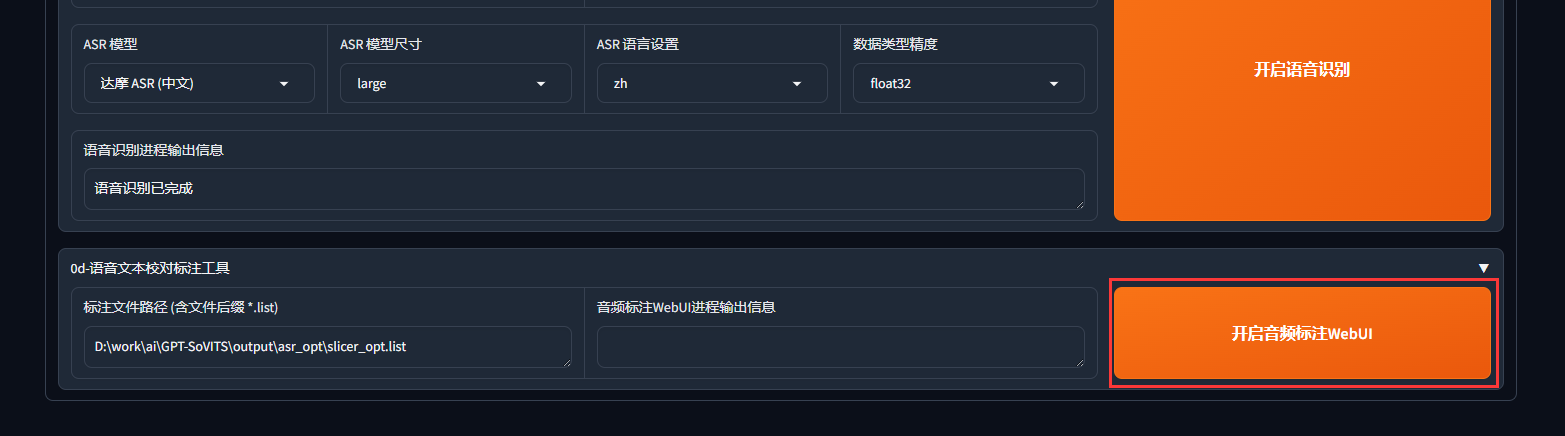
稍作等待后,就会出现新的音频标注webui界面,会自动跳转游览器,如果没有跳转,在浏览器中输入http://localhost:9871/即可,这一步就是在教模型这个字要怎么念的其中一个过程,每校对完一页就点击submit text提交文本,否则你翻到下一页的话,文本是不会保存的。
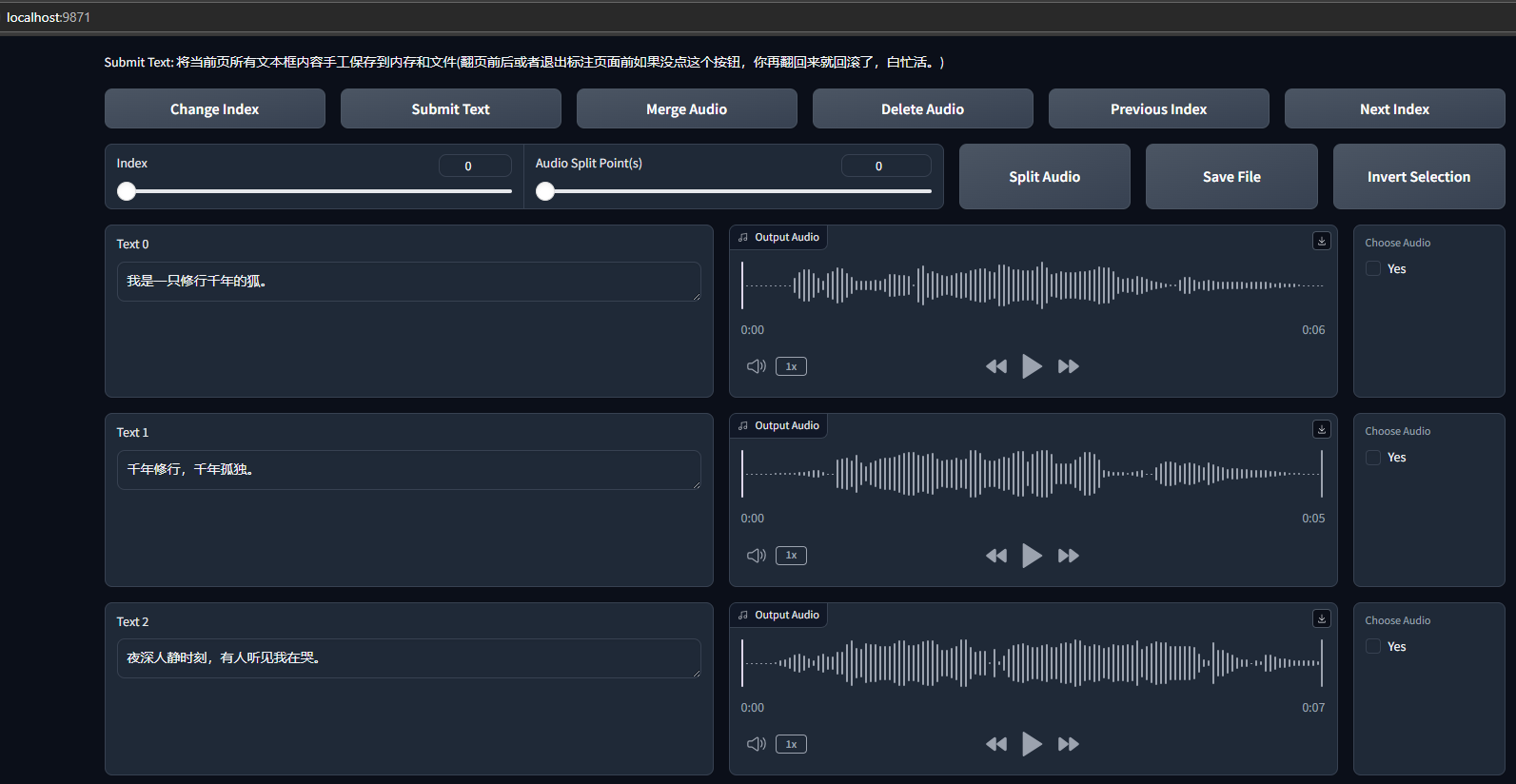
这一步需要相当的耐心,你的语料越大,需要校对的文本也就越多,文本修正的越好,你训练出来的模型质量也会越好。但你如果太懒或者语料实在太多搞不过来也可以省略这一步,追求完美的可以完成这一步,还是那句话,你数据处理的越好,训练出来的模型效果也会越好(追求完美的话),全部处理完后,数据就处理完毕了,接下来就是微调和训练我们的模型了。
1.3 模型微调训练
从主页面切换到子页面,大多数参数和路径动不用改:
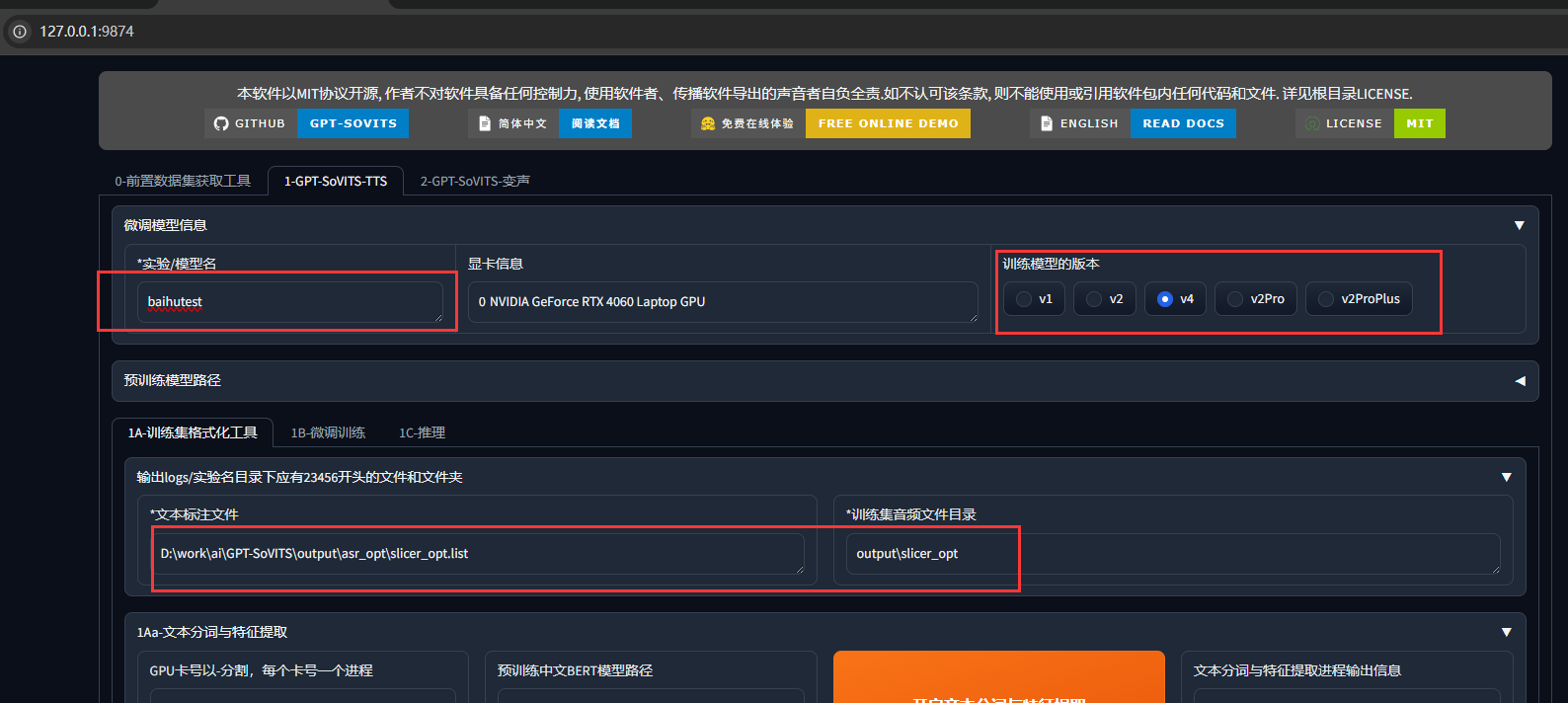
1. 训练集格式化
这一阶段的目标是将原始音频和文本数据转化为模型可训练的格式化数据
|---------------|-----------------------|
| 步骤 | 核心功能 |
| 1Aa-文本分词与特征提取 | 文本→分词+语义特征 |
| 1Ab-语音自监督特征提取 | 音频→HuBERT声学特征 |
| 1Ac-语义Token提取 | 音频→SoVITS专属的离散语义Token |
之后内容也无需做特别改动,保持默认就行:
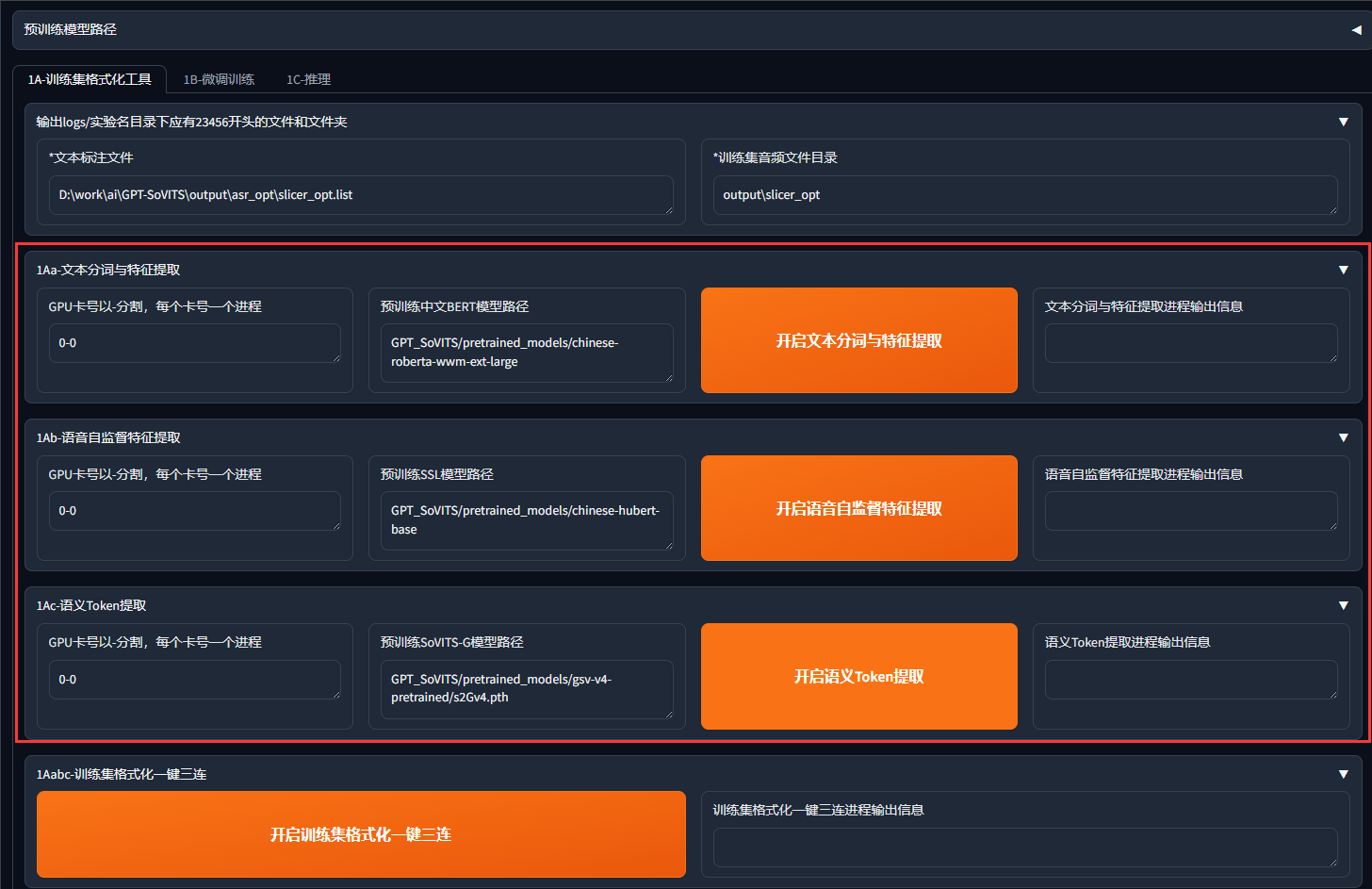
直接单击"开启训练集格式化一键三连"即可,完成后logs里产生格式化的训练集:
2. 微调模型
按以下配置,点击"开始SoVITS训练"后开始等待:
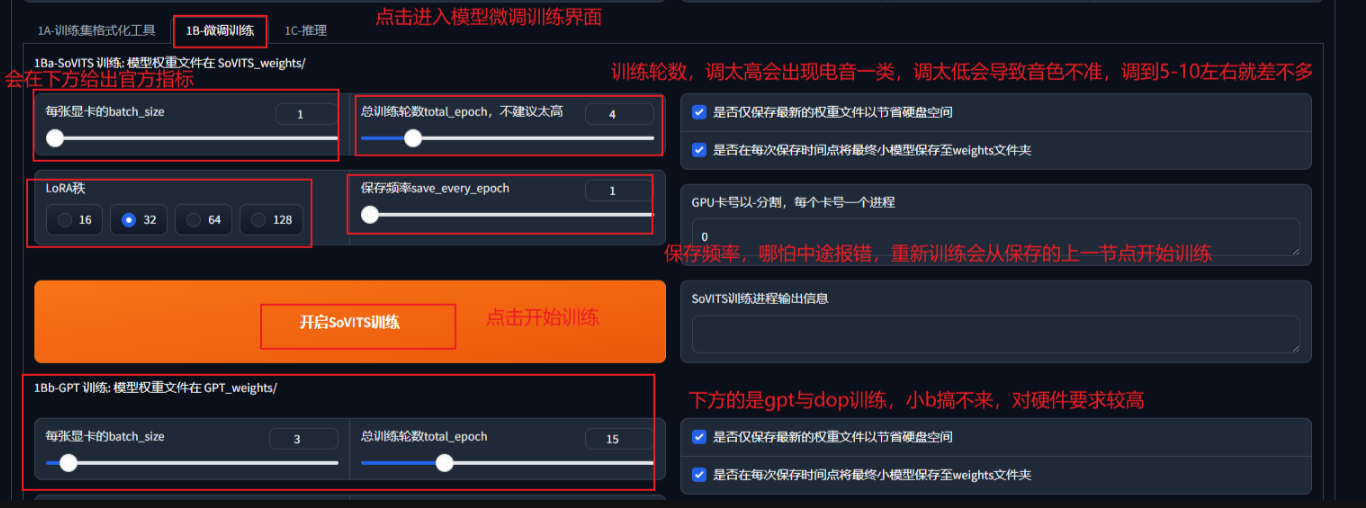
batch_size在合理的范围内越高,训练模型的速度就越快,下面给出一张官方的指标:

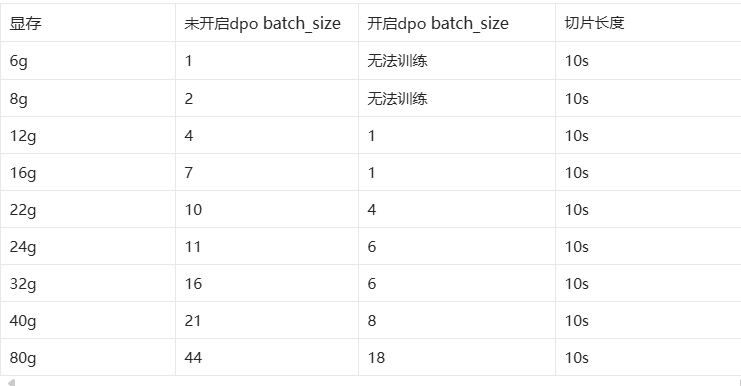
除了SoVITS训练,还有GPT训练,GPT训练可以开启dpo模式
GPT的dpo模式可以大幅提升模型的效果,但是小b硬件不允许,所以在本教程不做演示
(等我成为高手了把你们都吊起来打.jpg)
下面放出官方的指标进行参考
训练耗费时间也较长,最后当控制台输出:
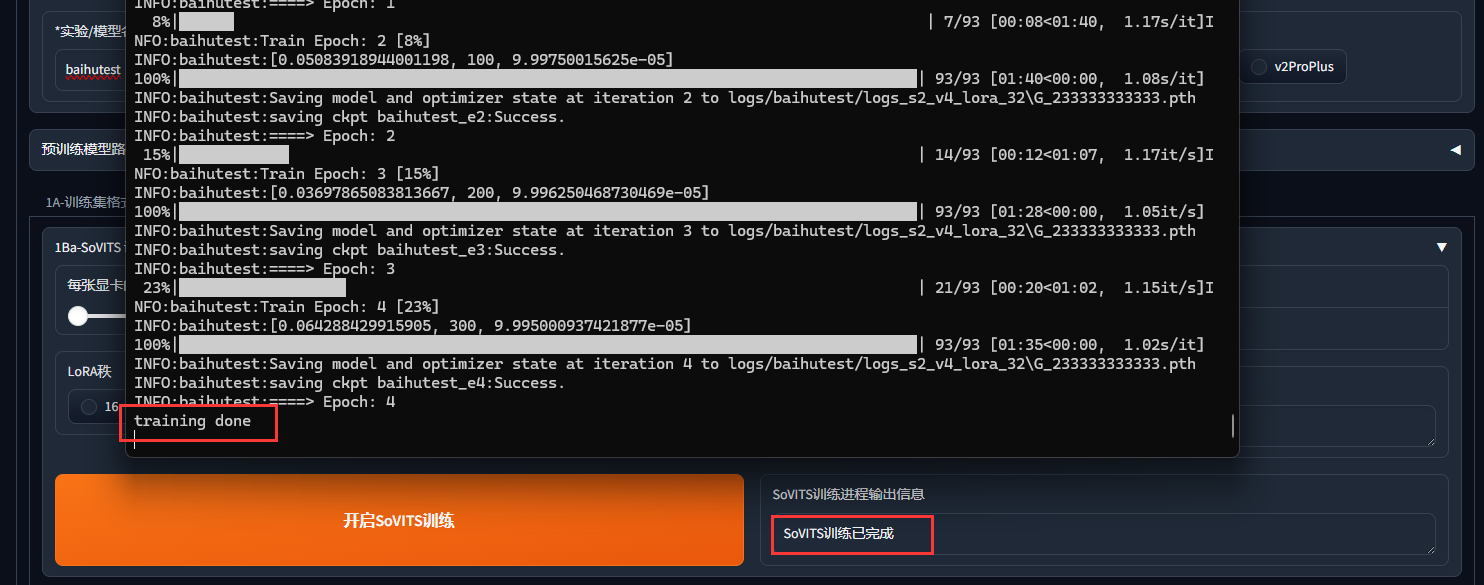
就证明模型已经训练好了。最终训练好的模型保存在以下路径:
1.4 开启TTS推理
这一步就可以验证你的模型效果了
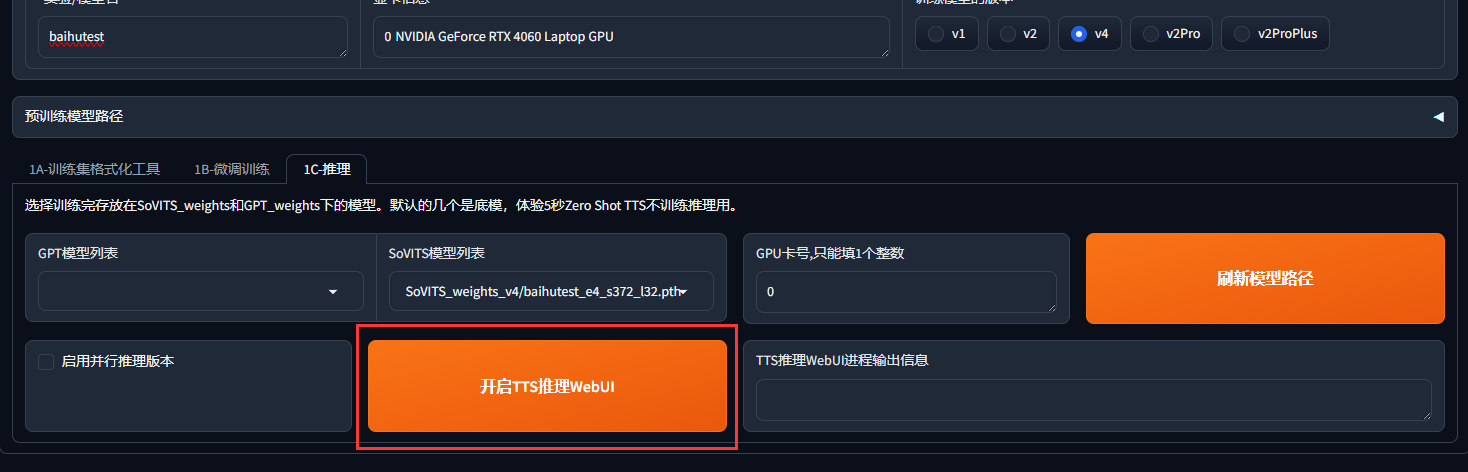
等待一会游览器会自动跳转,如果没有自动跳转的话在游览器访问http://localhost:9872/即可,随即进入TTSwebui界面:
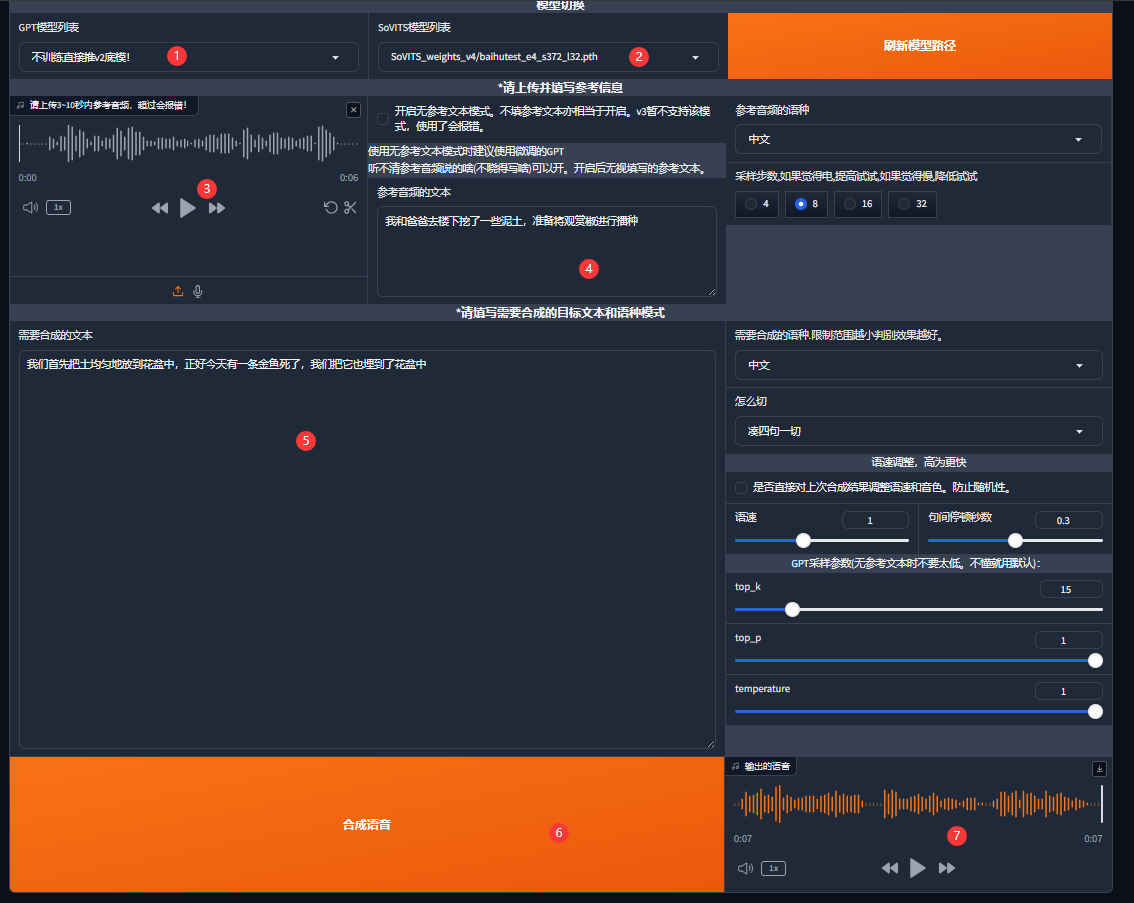
第1部分中随便选一个存在的GPT模型,第2部分选择我们刚刚训练的模型,第3部分选择要克隆的音频文件,第4部分是该音频语音的文本内容,第5部分输入要进行克隆的文本内容,第6进行语音合成,第7部分产生第5部分文本内容的克隆声音。不清楚的部分都可以保持默认配置。
2 和IndexTTS比较
在2025年的现状下,GPT-SoVITS 和index-tts都是语音合成技术中的强者,但它们定位不同,适用场景也有差异。下面是一个直接对比,帮助你判断哪种方案生成效果更好,取决于你的需求。

2.1 背景介绍
1. GPT-SoVITS
特点
-
是SoVITS(基于 VITS 的语音合成)和GPT分词、语言建模能力的结合体。
-
使用某个"音色克隆"的语音模型(通常是基于 VITS)+ 语义编码器(如 HuBERT/GPT),实现拟人化 TTS。
-
支持换声、语气、风格迁移,甚至跨语言说话。
-
通常配合 RVC 音色模型(如RVC v2/v3)使用。
优势
-
支持音色克隆:训练十几秒音频就能拟声。
-
语音自然,停顿、语调模拟人类非常像。
-
可以"演戏"式表达,比如愤怒、哭泣、兴奋。
缺点
-
对输入文本"精准朗读"能力差一些,容易漏词、错词。
-
推理时间可能比 index-tts 慢,尤其在低配置机器。
-
有时候会出现"滑词"、"语义混乱"等现象。
2. index-tts
特点
少样本克隆:支持通过少量语音样本(如几秒到几十秒)快速克隆目标音色,保留说话人的语音特征(如音调、语速、口音)。
音色 - 情感解耦:采用分离建模机制,可将 "音色" 与 "情感" 独立控制,例如用 A 的音色合成 B 的情感语气,提升克隆的灵活性。
跨场景适应性:克隆的语音在不同文本内容(如新闻、对话、旁白)中保持一致性,减少因文本风格变化导致的音色偏移。
优势
对文本的朗读更稳定,停顿、标点处理准确。
支持多语种,语音平稳、不卡顿。
精准发音处理:采用 "字符 - 拼音混合建模",有效解决中文多音字、生僻字、方言词汇的发音问题,提升合成准确性。
韵律适配中文特性:针对中文声调(阴平、阳平、上声、去声)和语流音变(如轻声、儿化)优化模型,使合成语音更符合中文表达习惯。
缺点
生成声音稍微"机器人"一点,没有 GPT-SoVITS 拟人的自然。
很难做精确的音色模仿。
情感语调弱,无法生成演讲式、激动等语音风格。
2.2 各自用途

2.3 技术结合
你可以用 index-tts 生成结构清晰的语音,然后 用 GPT-SoVITS 对其风格转换。即:
- 用index-tts合成基础语音(保证发音准确);
2 喂给 GPT-SoVITS 进行风格"拟人化"迁移;
- 得到最自然、最清晰、最像人的音频。
这种做法在AI虚拟主播、AI歌手中非常流行。