一、Kimi - Audio 简介
Kimi - Audio 是一个开源的音频基础模型,在音频理解、生成和对话等方面表现出色。其设计旨在作为一个通用的音频基础模型,能够在单一统一的框架内处理各种音频处理任务,如语音识别(ASR)、音频问答(AQA)、音频描述(AAC)、语音情感识别(SER)、声音事件 / 场景分类(SEC/ASC)以及端到端的语音对话等。并且在众多音频基准测试中取得了前沿的成果。
二、技术特点
-
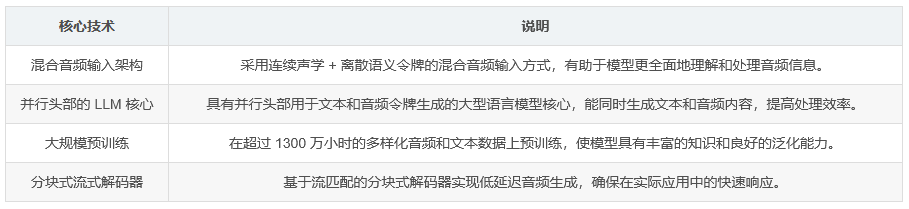
大规模预训练 :在超过 1300 万小时的多样化音频数据(包括语音、音乐、声音)和文本数据上进行了预训练,这使得模型具有广泛的知识基础和强大的泛化能力。
-
新颖的架构 :采用混合音频输入(连续声学 + 离散语义令牌)以及具有并行头部用于文本和音频令牌生成的大型语言模型(LLM)核心,这种架构设计有助于模型更好地理解和生成音频内容。
-
高效的推理 :具备基于流匹配的分块式流式解码器,可实现低延迟的音频生成,从而在实际应用中能够快速响应用户需求。
三、使用方法
-
环境搭建 :推荐通过构建 Docker 镜像来运行推理。可以使用命令
git clone https://github.com/MoonshotAI/Kimi-Audio克隆代码并构建镜像,也可以使用预构建的镜像docker pull moonshotai/kimi-audio:v0.1,或者安装相关依赖pip install -r requirements.txt。 -
模型加载与推理 :首先需要从 Hugging Face Hub 加载模型,确保已登录(如果是私有仓库的话)。然后定义采样参数,包括音频和文本的温度、top_k 值、重复惩罚等。接着通过调用模型的生成方法,可以实现音频到文本(如语音识别)以及音频到音频 / 文本对话等功能。
四、总结
Kimi - Audio 作为一个功能强大的通用音频基础模型,凭借其出色的技术特点和方便的使用方式,在音频处理领域具有广阔的应用前景。
核心技术表格如下: