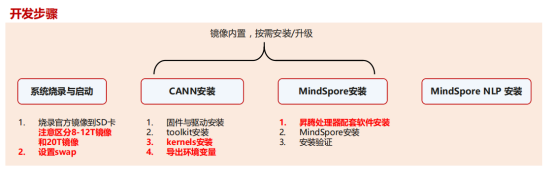
Deepseek-r1-distill-qwen-1.5b介绍
Deepseek-v3和r1的版本通过8张141张nvidia h200 gpu进行训练,训练和运行成本高,为节约成本,deepseek推出蒸馏板模型,基于r1版本的模型生成的高质量推理数据,在小模型上进行监督微调(sft,无强化学习或者偏好对齐训练阶段),具体过程如下:
- 选用 Llama 3.1/3.3 和 Qwen 2.5 的 6 个开源模型
- 用 R1 生成 80 万条高质量推理数据
- 基于这些数据进行监督微调(SFT,无 RL 阶段)
DeepSeek-R1-Distill-Qwen-1.5B在香橙派上的开发与适配
其中由于香橙派的板有8-12T和20T不同的算力版本,因此价格也是不同的,部署及开发人员根据自身的情况选择合适的板子进行开发。
详细的配置教学可以扫下面的二维码;

香橙派板子调试前的环境准备工作
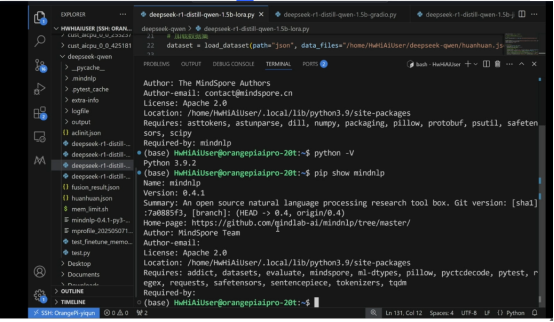
版本查看:
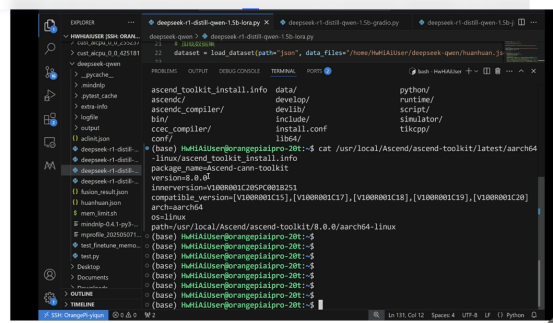
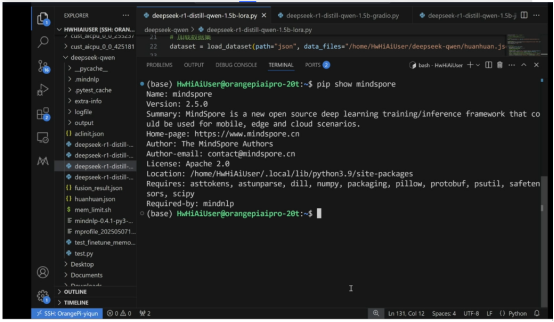
香橙派板子的Mindspore版本查看:
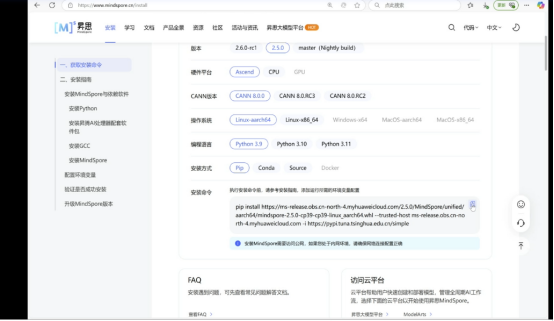
通过mindspore官网的命令来升级
Mindnlp版本:
香橙派板子模型及网络调试(查看当前板子是否能够支持模型的运行)
模型调试命令如下:
MindSpore NLP套件中有针对模型的ut测试,可通过pytest来测试模型在香橙派的训练和推理,并进行问题定位和调试
设置环境变量:
export RUN_SLOW=True
执行命令:
Pytest -v -s tests/transformers/models/qwen2/test_modeling_qwen2.py
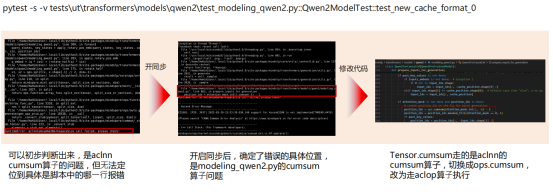
由于MindSpore动态图下框架存在多线程异步⾏为,所以会出现python调⽤栈不准确的场景,为了精准定位在test_modeling_qwen2.py脚本中import mindspore之后的位置,加入如下代码,重新跑pytest,查看具体的报错位置并根据报错信息修改 :
mindspore.set_context(pynative_synchronize=True)
对香橙派板子调试模型时报错的一些处理案例
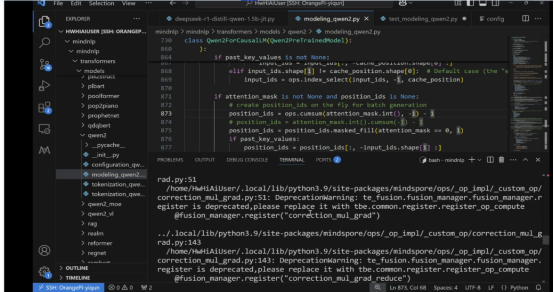
针对算子缺失的处理方式及在实际工程文件中修改对应代码
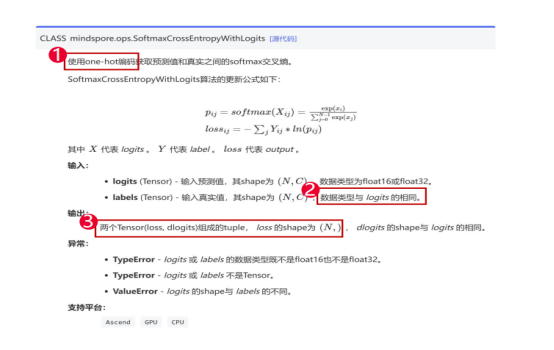
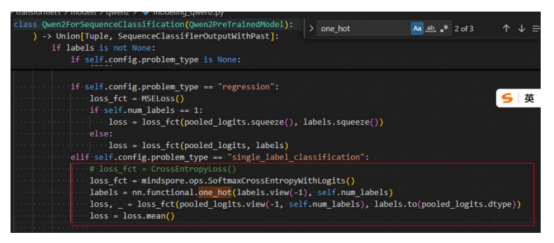
针对损失函数报错的处理方式

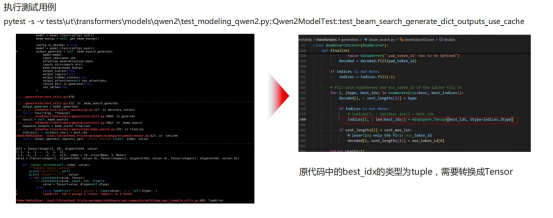
针对香橙派上Tensor索引/切片报错的处理方式
学习心得:
- 对于香橙派上面训练和运行的deepseek蒸馏版本模型的方式有初步的了解。
- 对香橙派板子调试前的部署流程有初步认识。
- 对香橙派板子上面部署及测试mindspore有初步了解,及对部分异常及错误处理有明确认识。