一**.**高可用集群
1.1****集群类型
LB:Load Balance 负载均衡
LVS/HAProxy/nginx(http/upstream, stream/upstream)
HA:High Availability 高可用集群
数据库、Redis
SPoF: Single Point of Failure,解决单点故障
HPC:High Performance Computing 高性能集群
1.2****系统可用性
SLA:Service-Level Agreement 服务等级协议(提供服务的企业与客户之间就服务的品质、水准、性能
等方面所达成的双方共同认可的协议或契约)
A = MTBF / (MTBF+MTTR)
指标 :99.9%, 99.99%, 99.999%,99.9999%
1.3****系统故障
硬件故障:设计缺陷、wear out(损耗)、非人为不可抗拒因素
软件故障:设计缺陷 bug
1.4****实现高可用
提升系统高用性的解决方案:降低MTTR- Mean Time To Repair(平均故障时间)
解决方案:建立冗余机制
active/passive 主/备
active/active 双主
active --> HEARTBEAT --> passive
active <--> HEARTBEAT <--> active
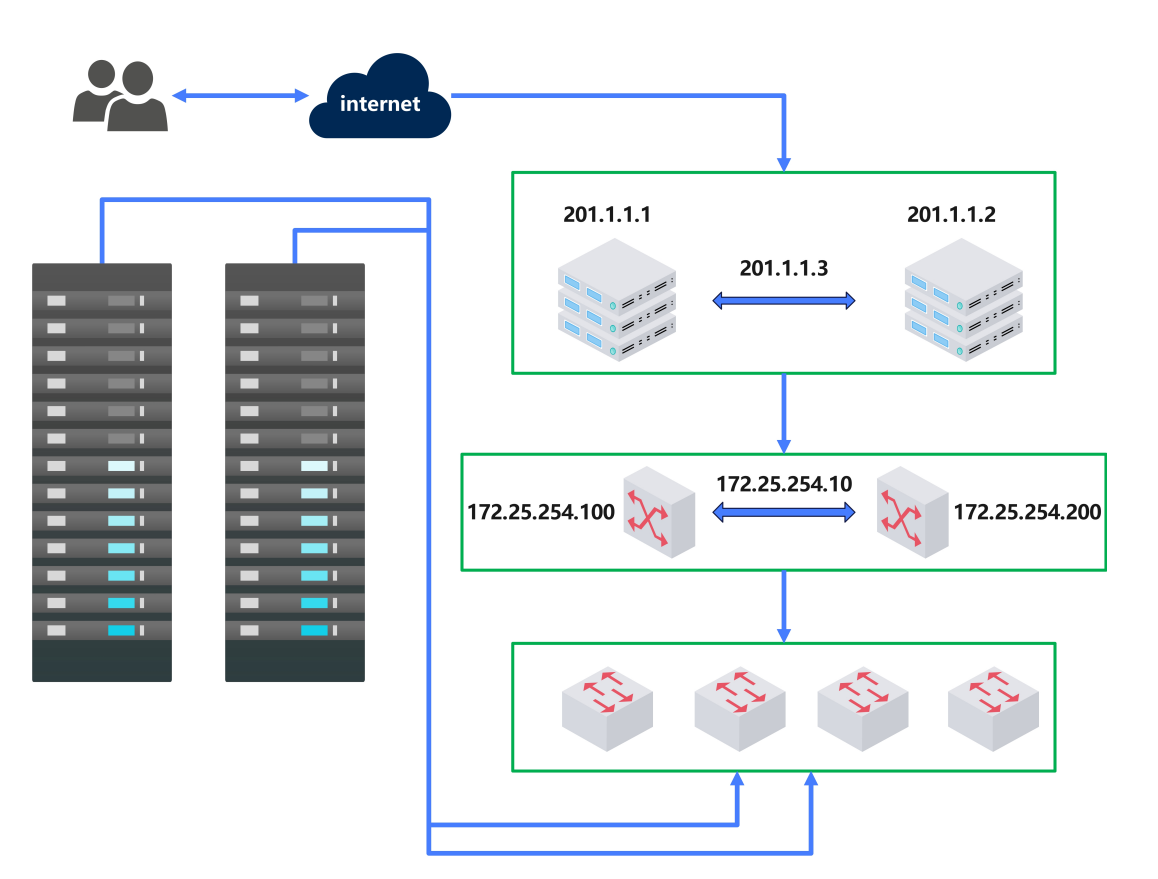
1.5.VRRP**:**Virtual Router Redundancy Protocol
虚拟路由冗余协议,解决静态网关单点风险
物理层:路由器、三层交换机
软件层:keepalived
'
1.5.1 VRRP****相关术语
虚拟路由器:Virtual Router
虚拟路由器标识:VRID(0-255),唯一标识虚拟路由器
VIP:Virtual IP
VMAC:Virutal MAC (00-00-5e-00-01-VRID)
物理路由器:
master:主设备
backup:备用设备
priority:优先级
1.5.2 VRRP****相关技术
通告:心跳,优先级等;周期性
工作方式:抢占式,非抢占式
安全认证:
无认证
简单字符认证:预共享密钥
MD5
工作模式:
主/备:单虚拟路由器
主/主:主/备(虚拟路由器1),备/主(虚拟路由器2)
二**.Keepalived****部署**
2.1 keepalived****简介
vrrp 协议的软件实现,原生设计目的为了高可用 ipvs服务
功能:
基于vrrp协议完成地址流动
为vip地址所在的节点生成ipvs规则(在配置文件中预先定义)
为ipvs集群的各RS做健康状态检测
基于脚本调用接口完成脚本中定义的功能,进而影响集群事务,以此支持nginx、haproxy等服务

2.2 Keepalived****架构
官方文档:
http://keepalived.org/documentation.html、
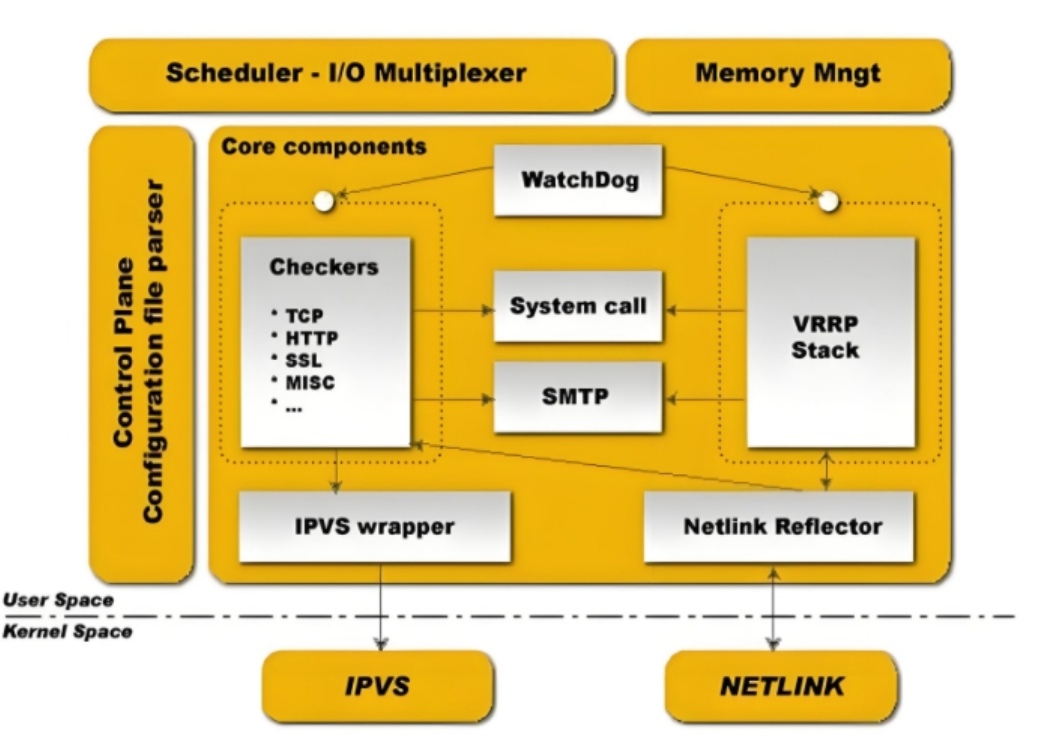
用户空间核心组件:
vrrp stack:VIP消息通告
checkers:监测real server
system call:实现 vrrp 协议状态转换时调用脚本的功能
SMTP:邮件组件
IPVS wrapper:生成IPVS规则
Netlink Reflector:网络接口
WatchDog:监控进程
控制组件:提供keepalived.conf 的解析器,完成Keepalived配置
IO复用器:针对网络目的而优化的自己的线程抽象
内存管理组件:为某些通用的内存管理功能(例如分配,重新分配,发布等)提供访问权限
2.3 Keepalived****环境准备
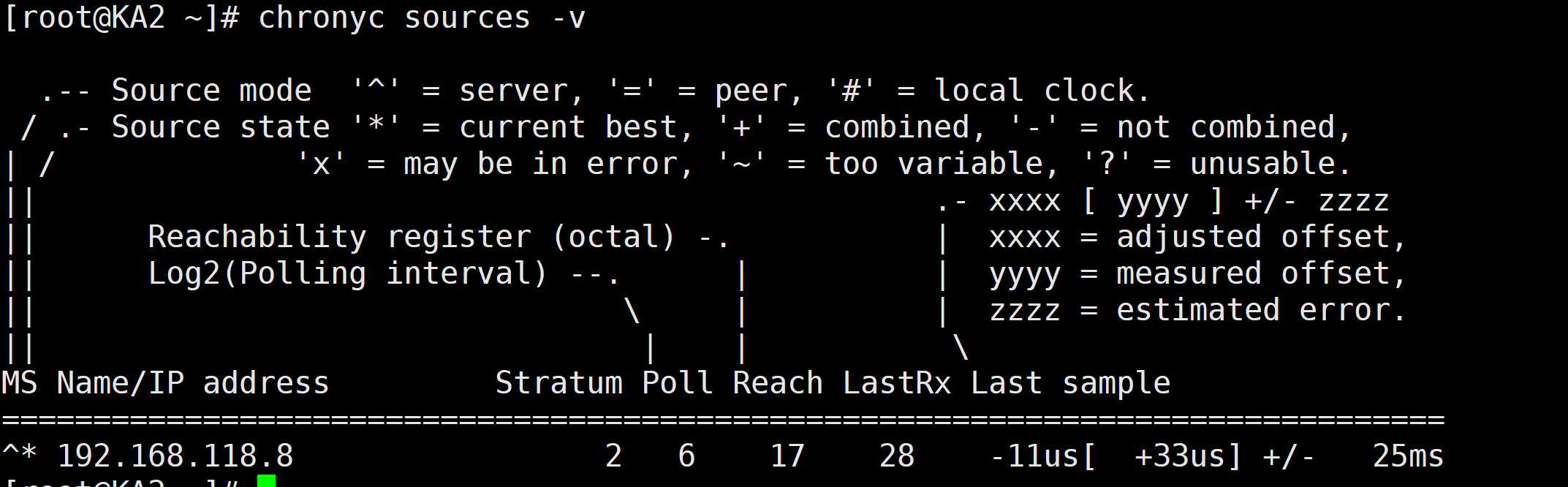
各节点时间必须同步:ntp, chrony
关闭防火墙及SELinux
各节点之间可通过主机名互相通信:非必须
建议使用/etc/hosts文件实现:非必须
各节点之间的root用户可以基于密钥认证的ssh服务完成互相通信:非必须
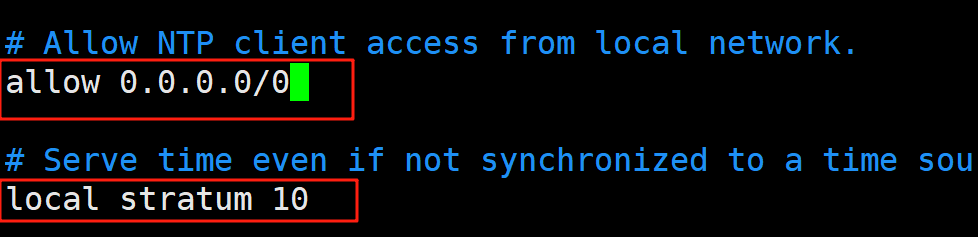
在ka1
vim /etc/chrony.conf

在ka2上
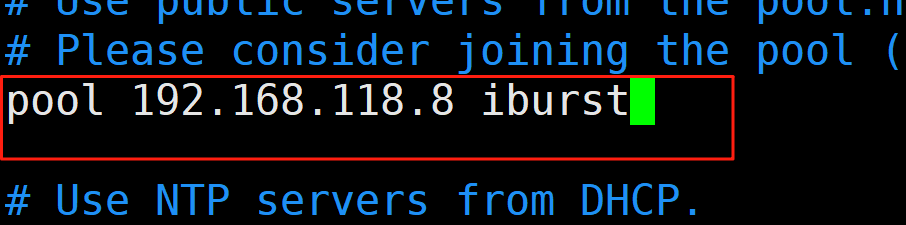
时间同步
2.4 Keepalived****相关文件
软件包名:keepalived
主程序文件:/usr/sbin/keepalived
主配置文件:/etc/keepalived/keepalived.conf
配置文件示例:/usr/share/doc/keepalived/
Unit File:/lib/systemd/system/keepalived.service
Unit File的环境配置文件:/etc/sysconfig/keepalived

注意:RHEL7中可能会遇到一下bug,RHEL9中无此问题
解决办法:
systemctl restart keepalived #新配置可能无法生效
systemctl stop keepalived;systemctl start keepalived #无法停止进程,需要 kill 停
止
2.5 Keepalived****安装
安装****keepalived
ka1和ka2安装keepalived
dnf install keepalived -y
2.6 KeepAlived****配置说明
2.6.1****配置文件组成部分
配置文件:/etc/keepalived/keepalived.conf
配置文件组成
GLOBAL CONFIGURATION
Global definitions: 定义邮件配置,route_id,vrrp配置,多播地址等
VRRP CONFIGURATION
VRRP instance(s):
定义每个vrrp虚拟路由器
LVS CONFIGURATION
Virtual server group(s)
Virtual server(s):
LVS集群的VS和RS
2.6.2****配置语法说明
帮助
man keepalived.conf
1.全局配置
启动keepalived服务

ka2和ka1大体一样,不一样的下方图片标了出来。
 启动keepalived
启动keepalived

2.配置虚拟路由器
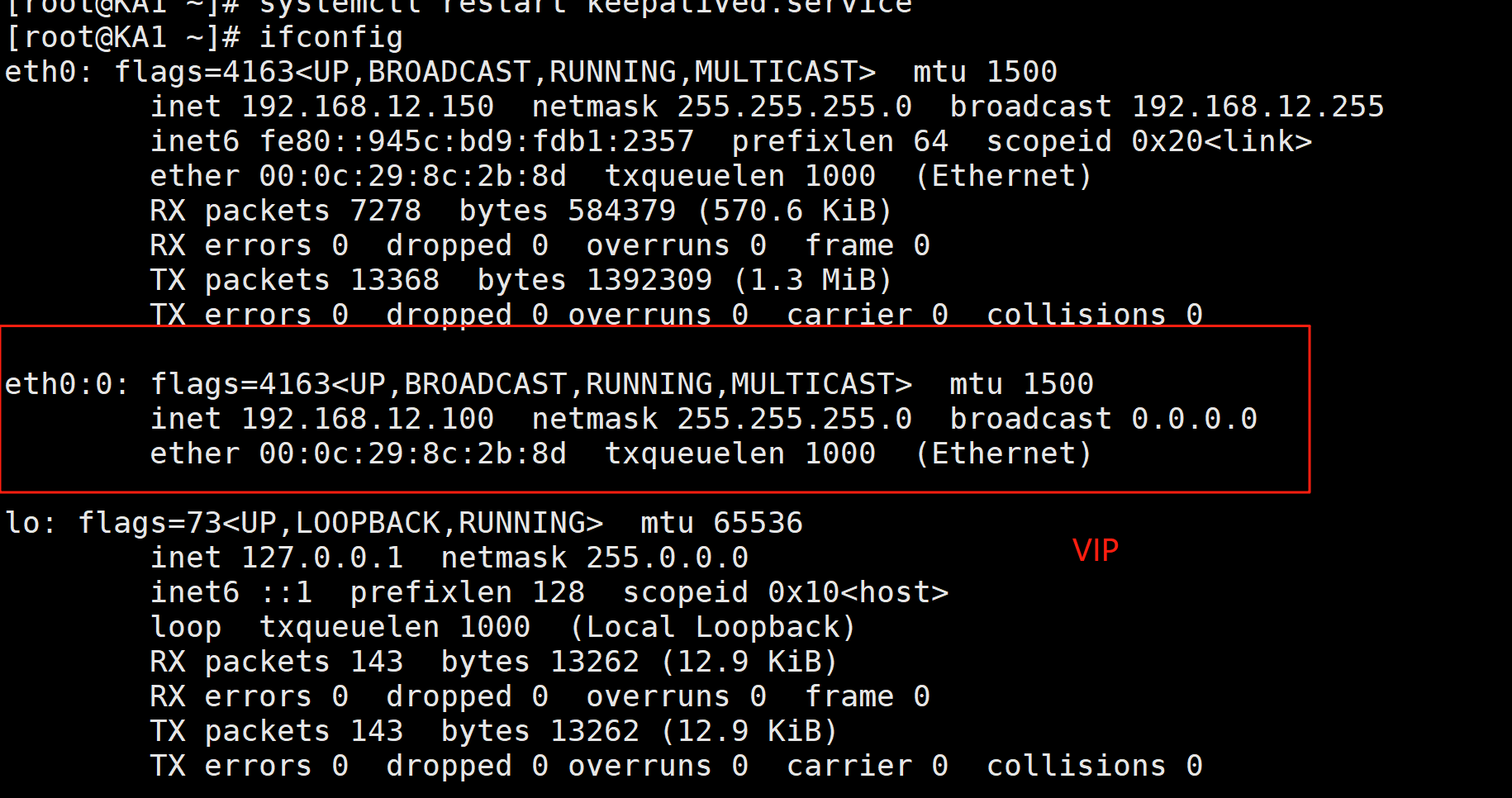

3.启用keepalived日志功能
cat /var/log.messages
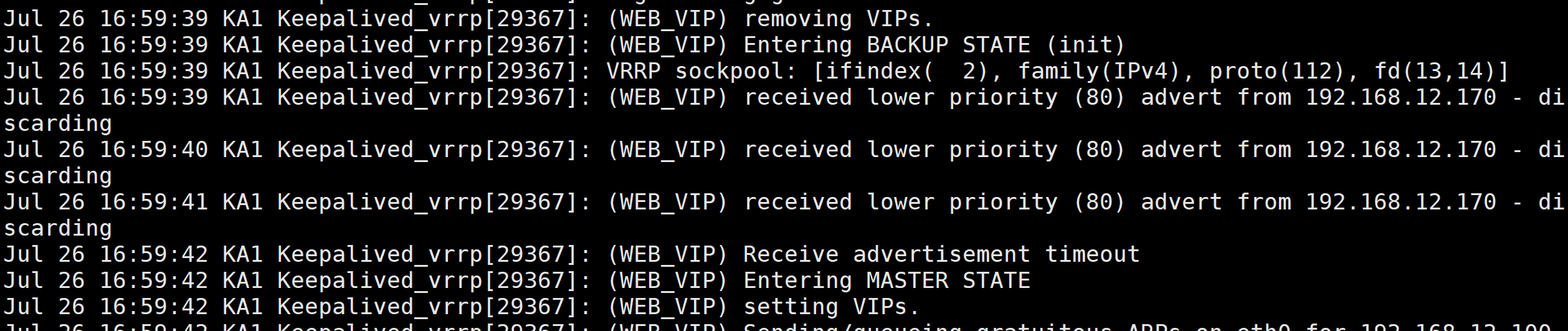
root@KA1 \~# vi /etc/sysconfig/keepalived
启用日志功能

root@KA1 \~# vim /etc/rsyslog.conf

测试:cat /var/log/keepalived.log
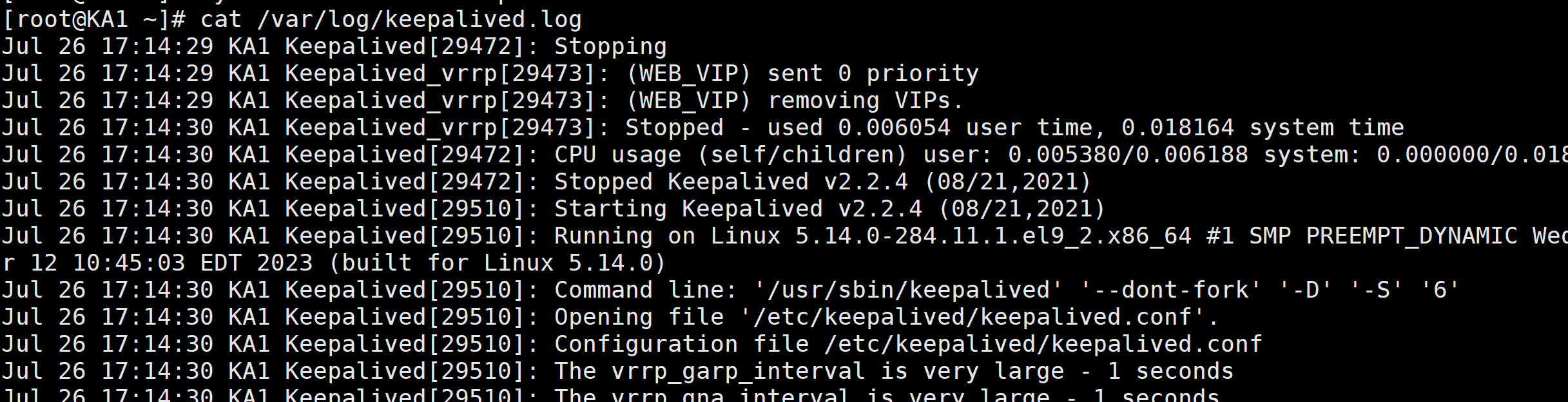
4.实现独立子配置文件
当生产环境复杂时, /etc/keepalived/keepalived.conf 文件中内容过多,不易管理
将不同集群的配置,比如:不同集群的VIP配置放在独立的子配置文件中利用include 指令可以实现包含子配置文件
格式:
include /path/file
vim /etc/keepalived/keepalived.conf
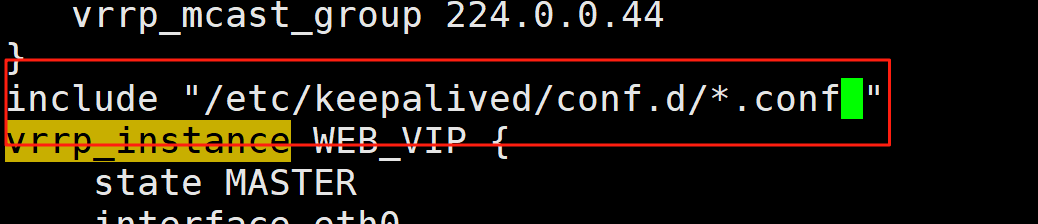
复制对话1
root@KA1 \~# mkdir /etc/keepalived/conf.d -p
root@KA1 \~# sudo vim /etc/keepalived/conf.d/webvip.conf
这样就完成了独立子配置文件。
三**.Keepalived****企业应用示例**
3.1实现master/slave的Keepalived****单主架构
3.1.1 MASTER****配置
前面已经做过,这个就不细写了。
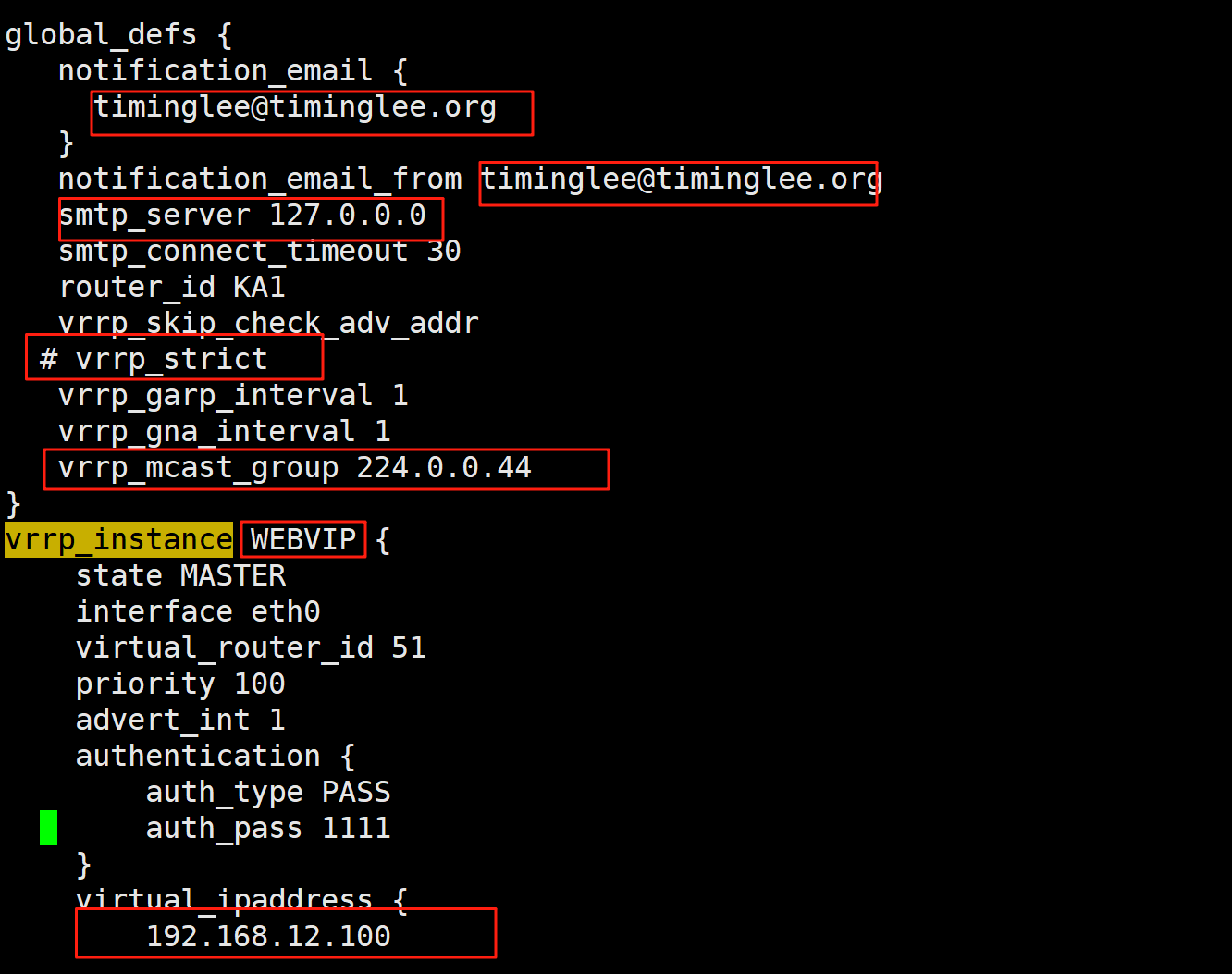
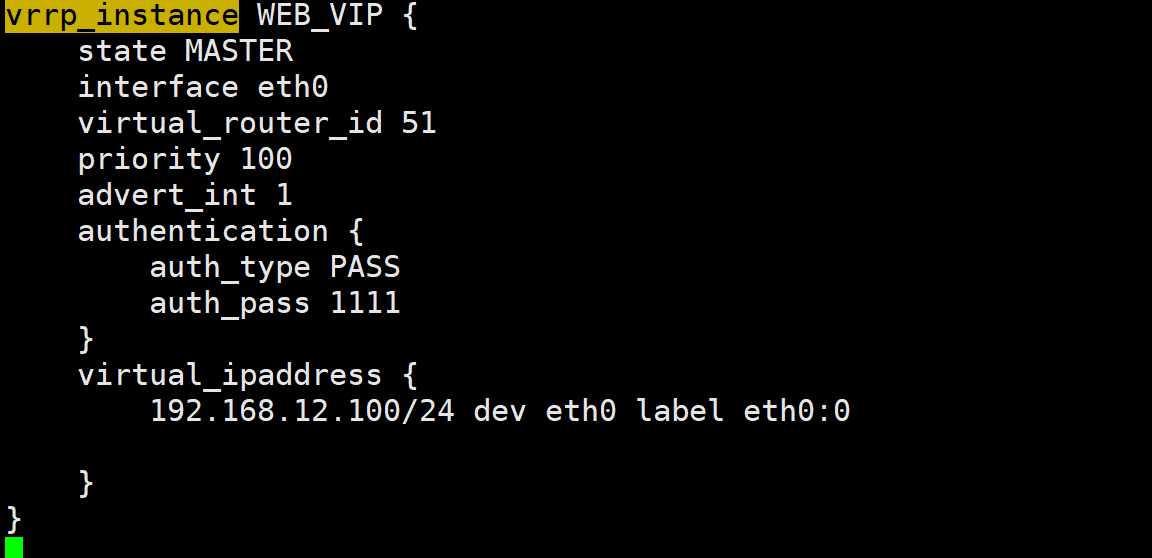
root@KA1 \~# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
594233887@qq.com3.1.2 BACKUP配置
}
notification_email_from keepalived@KA1.timinglee.org
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id KA1.timinglee.org
vrrp_skip_check_adv_addr
#vrrp_strict #添加此选项无法访问vip,可以用nft list ruleset查看
vrrp_garp_interval 1
vrrp_gna_interval 1
vrrp_mcast_group4 224.0.0.18
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 20
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.25.254.100/24 dev eth0 label eth0:0
}
}
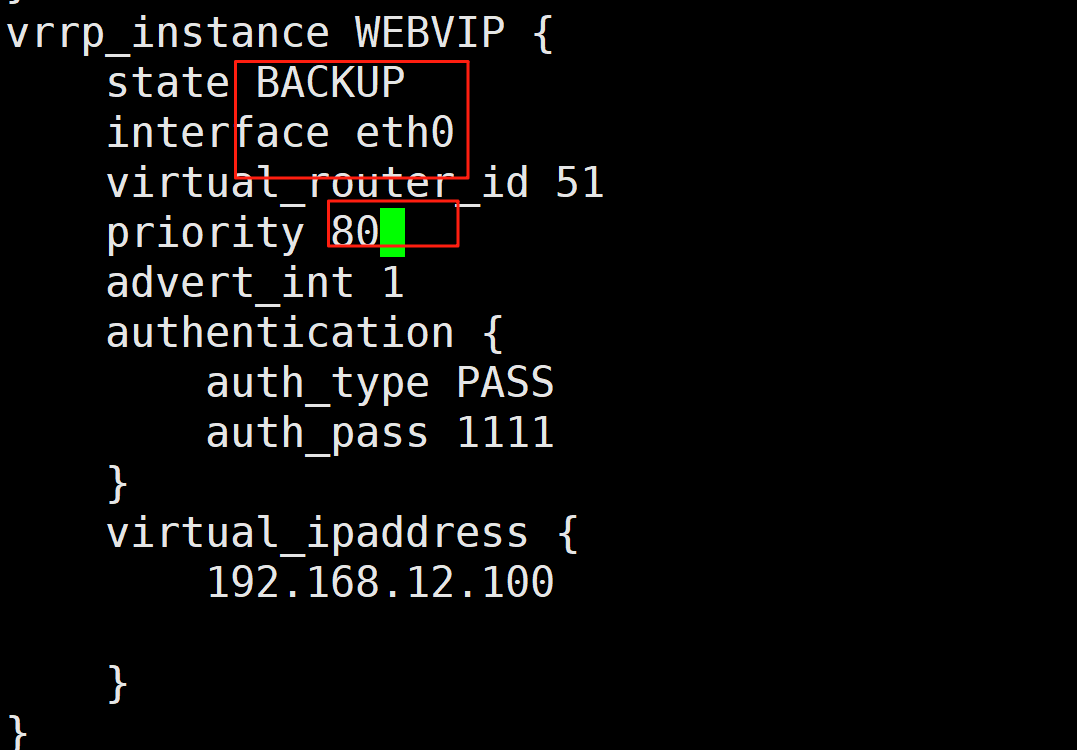
#配置文件和master基本一致,只需修改三行
root@KA2 \~# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
}
notification_email_from keepalived@timinglee.org
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id KA2.timinglee.org
vrrp_skip_check_adv_addr
#vrrp_strict
vrrp_garp_interval 1
vrrp_gna_interval 1
vrrp_mcast_group4 224.0.0.18
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 20 #相同id管理同一个虚拟路由
priority 80 #低优先级
advert_int 1
抓包观察
tcpdump -i eth0 -nn host 224.0.0.18
3.2****抢占模式和非抢占模式
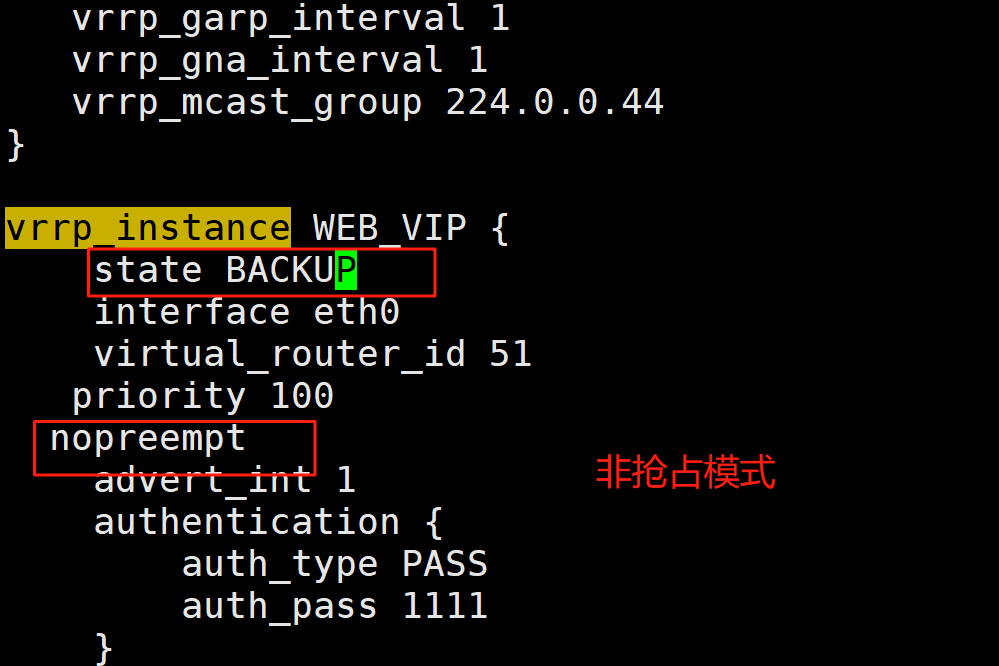
3.2.1非抢占模式nopreempt
默认为抢占模式preempt,即当高优先级的主机恢复在线后,会抢占低先级的主机的master角色, 这样会使vip在KA主机中来回漂移,造成网络抖动,
建议设置为非抢占模式 nopreempt ,即高优先级主机恢复后,并不会抢占低优先级主机的master角色非抢占模块下,如果原主机down机, VIP迁移至的新主机, 后续也发生down时,仍会将VIP迁移回原主机
注意:要关闭 VIP抢占,必须将各 keepalived 服务器state配置为BACKUP
ka1和ka2上:

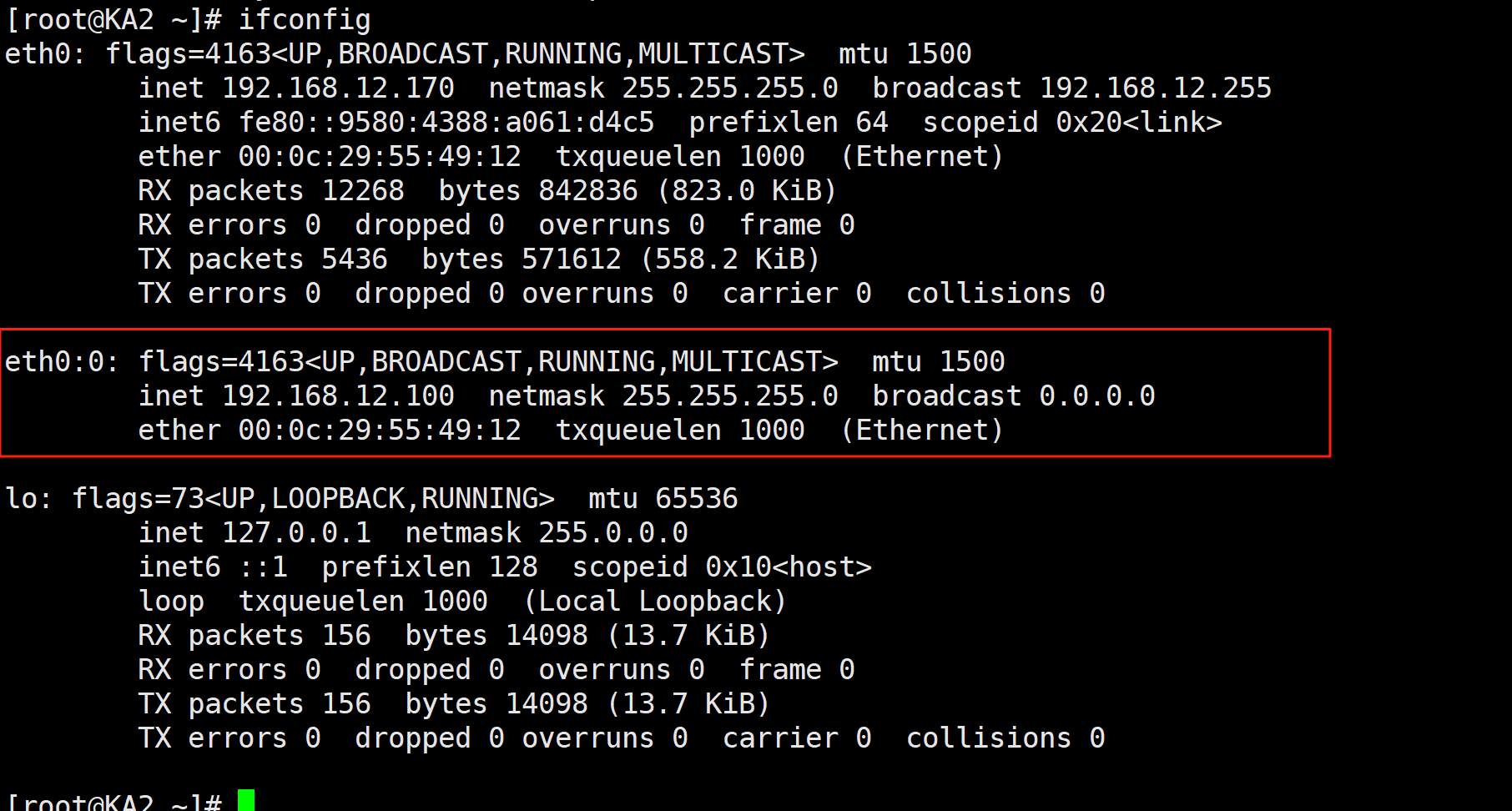
3.2.2抢占延迟模式preempt_delay
抢占延迟模式,即优先级高的主机恢复后,不会立即抢回VIP,而是延迟一段时间(默认300s)再抢回VIP
preempt_delay # #指定抢占延迟时间为#s,默认延迟300s
注意:需要各keepalived服务器state为BACKUP,并且不要启用 vrrp_strict
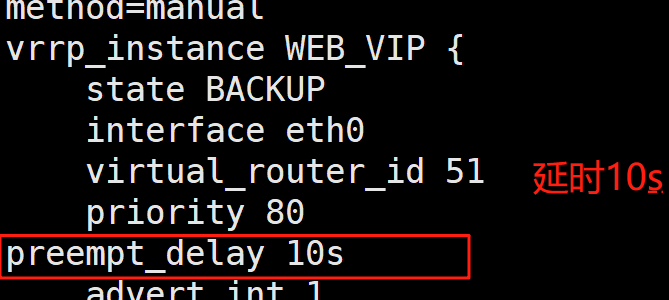
关掉并迅速启动服务
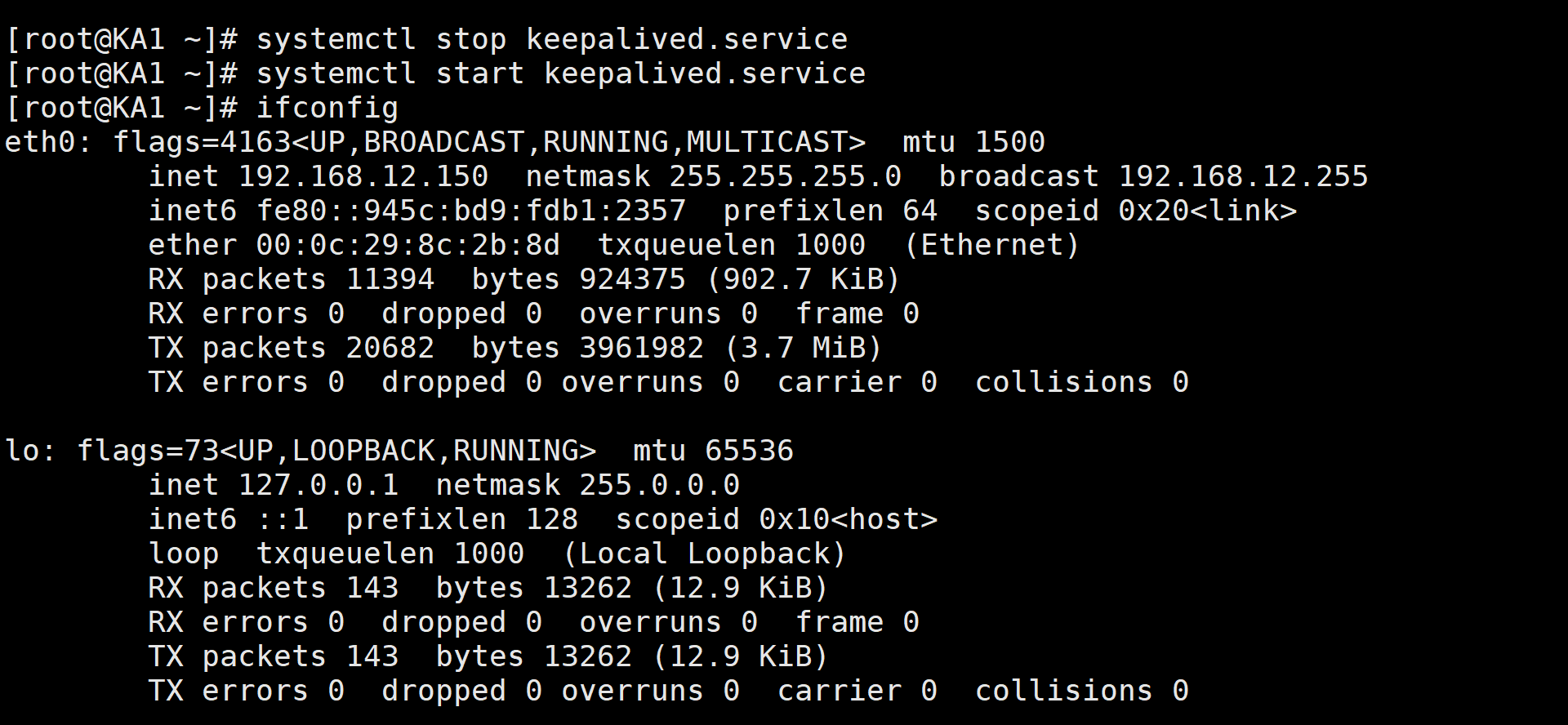
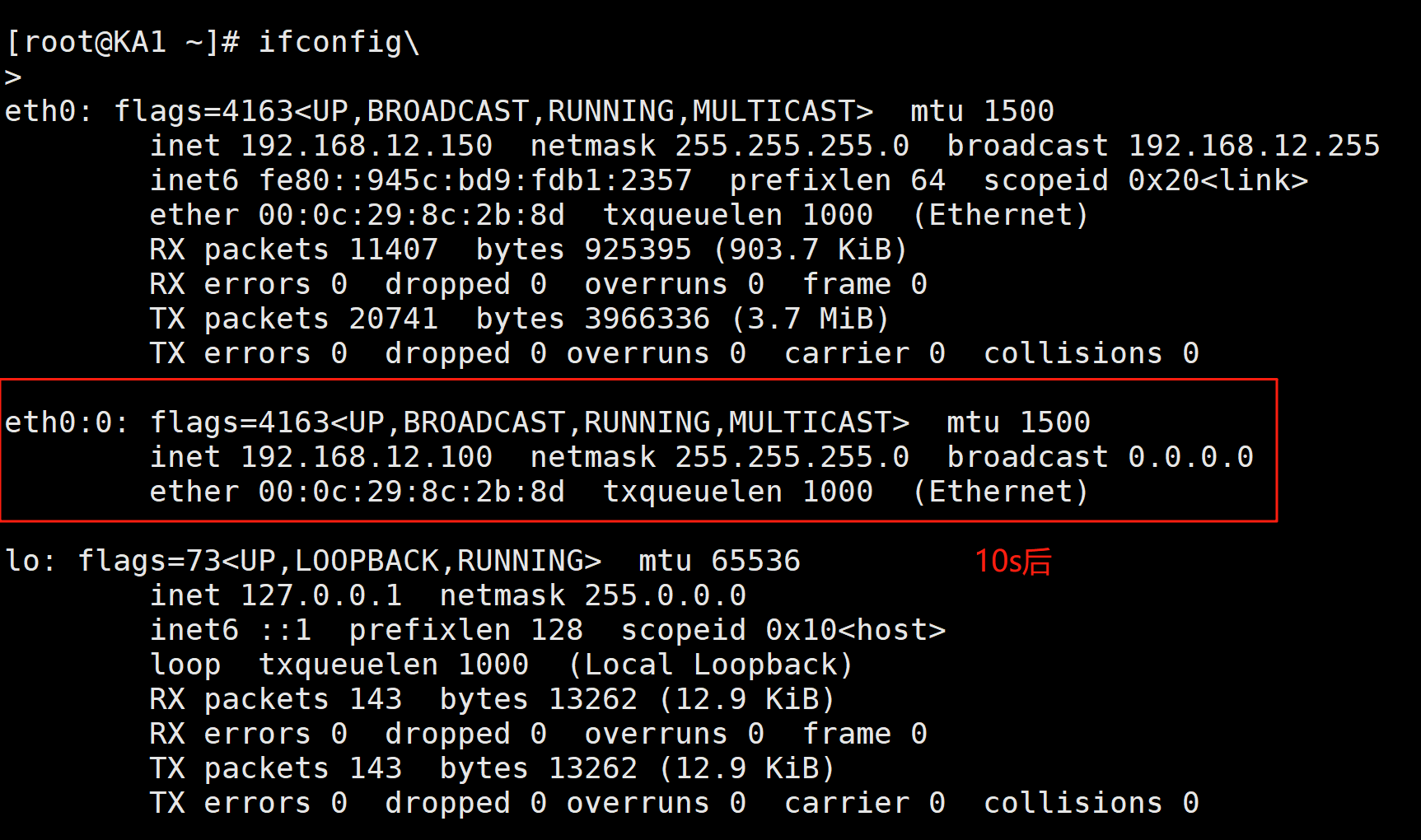
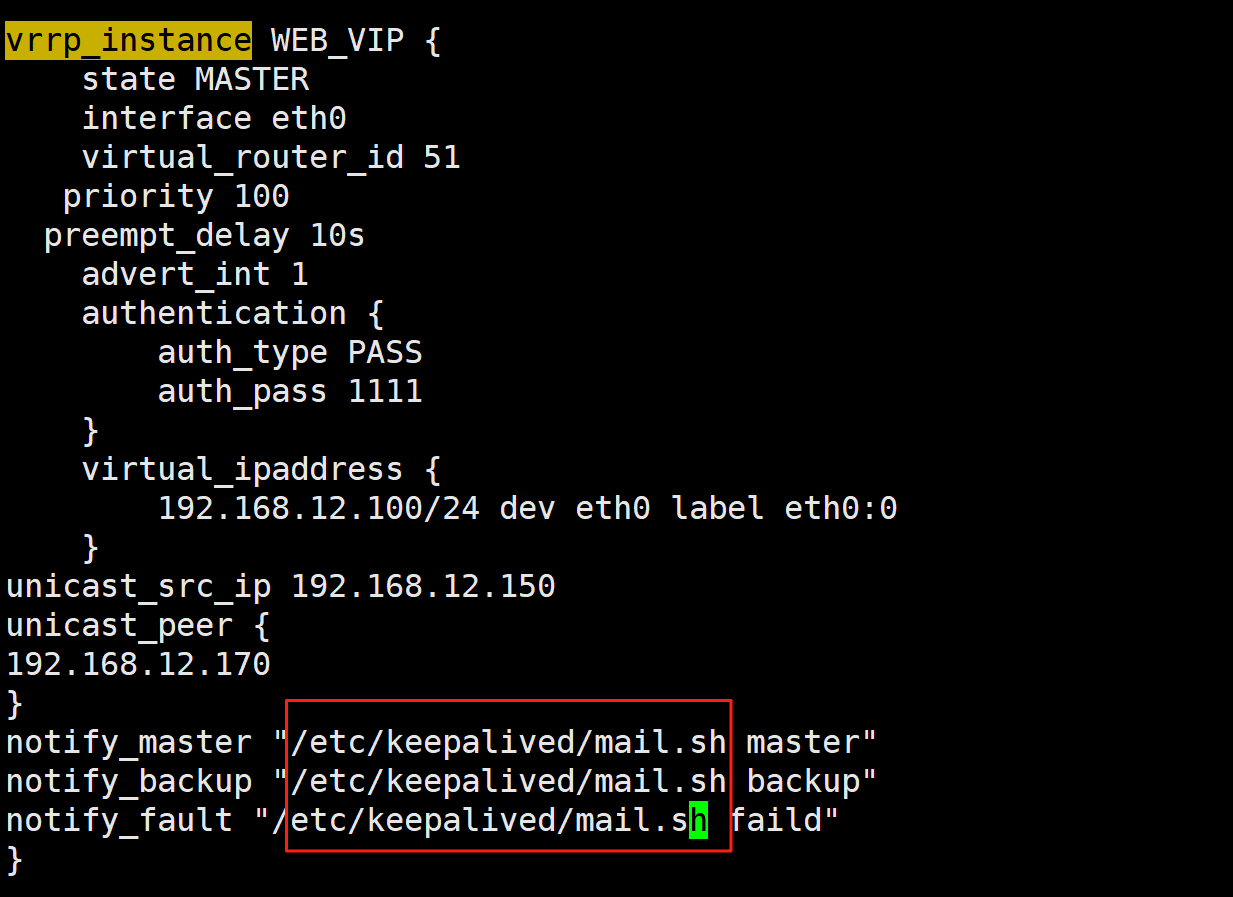
3.3 VIP****单播配置
默认keepalived主机之间利用多播相互通告消息,会造成网络拥塞,可以替换成单播,减少网络流量
注意:启用 vrrp_strict 时,不能启用单播
ka1和2都按照这个原理配置
root@KA2 \~# vi /etc/keepalived/keepalived.conf
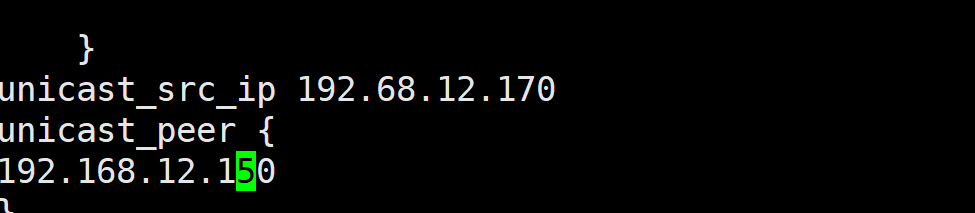
测试:
ka1

ka2

抢占模式:ka1停止ka2就进行,ka2停止就回到ka1这边,那边优先级高先从那边开始,电脑卡顿,就不展示了。
3.4 Keepalived****通知脚本配置
当keepalived的状态变化时,可以自动触发脚本的执行,比如:发邮件通知用户
默认以用户keepalived_script身份执行脚本
如果此用户不存在,以root执行脚本可以用下面指令指定脚本执行用户的身份
global_defs {
......
script_user <USER>
......
}
3.4.1****通知脚本类型
当前节点成为主节点时触发的脚本
notify_master <STRING>|<QUOTED-STRING>
当前节点转为备节点时触发的脚本
notify_backup <STRING>|<QUOTED-STRING>
当前节点转为"失败"状态时触发的脚本
notify_fault <STRING>|<QUOTED-STRING>
3.4.2****脚本的调用方法
在 vrrp_instance VI_1 语句块的末尾加下面行
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
3.4.3 创建通知脚本
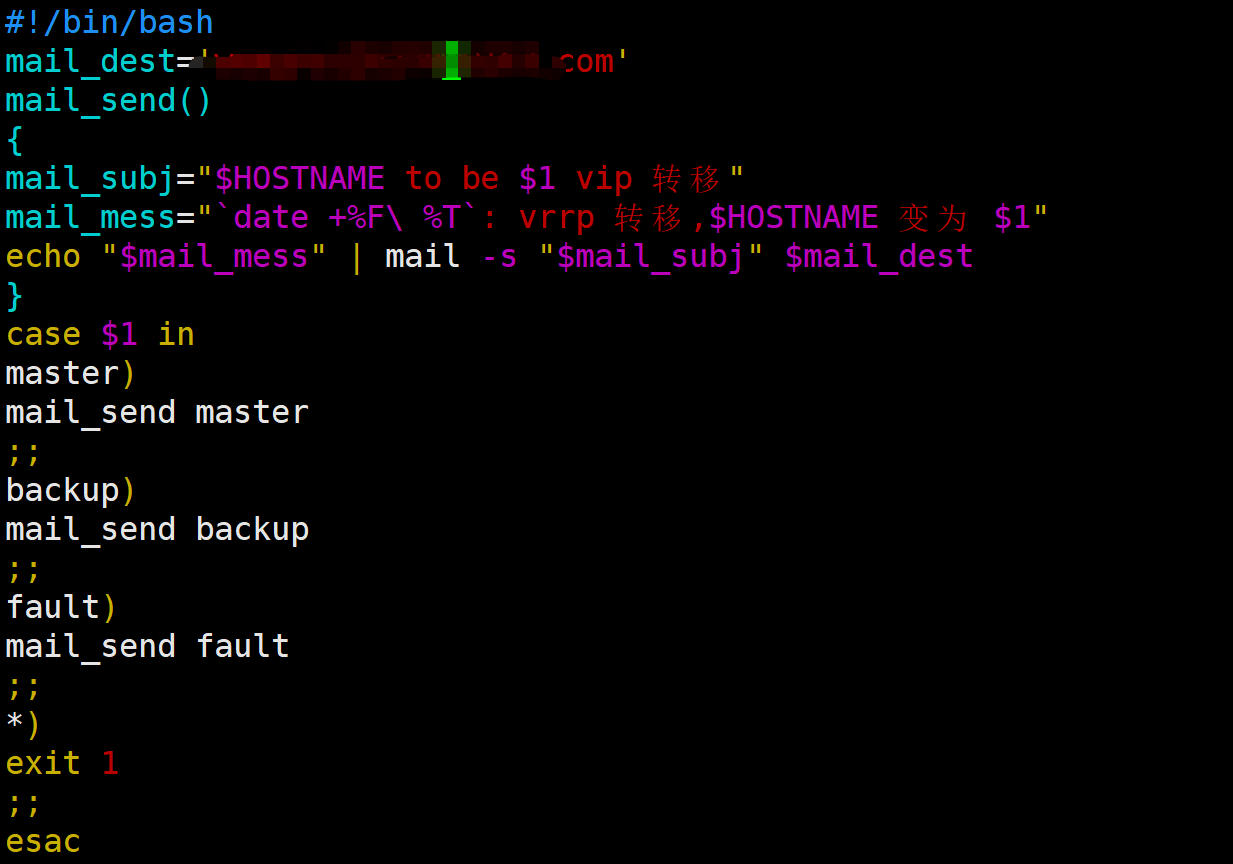
root@KA1 \~# vim /etc/keepalived/mail.sh
#!/bin/bash
mail_dest='594233887@qq.com'
mail_send()
{
mail_subj="HOSTNAME to be 1 vip 转移"
mail_mess="`date +%F\ %T`: vrrp 转移,HOSTNAME 变为 1"
echo "mail_mess" \| mail -s "mail_subj" mail_dest
}
case 1 in
master)
mail_send master
;;
backup)
mail_send backup
;;
fault)
mail_send fault
;;
*)
exit 1
;;
esac
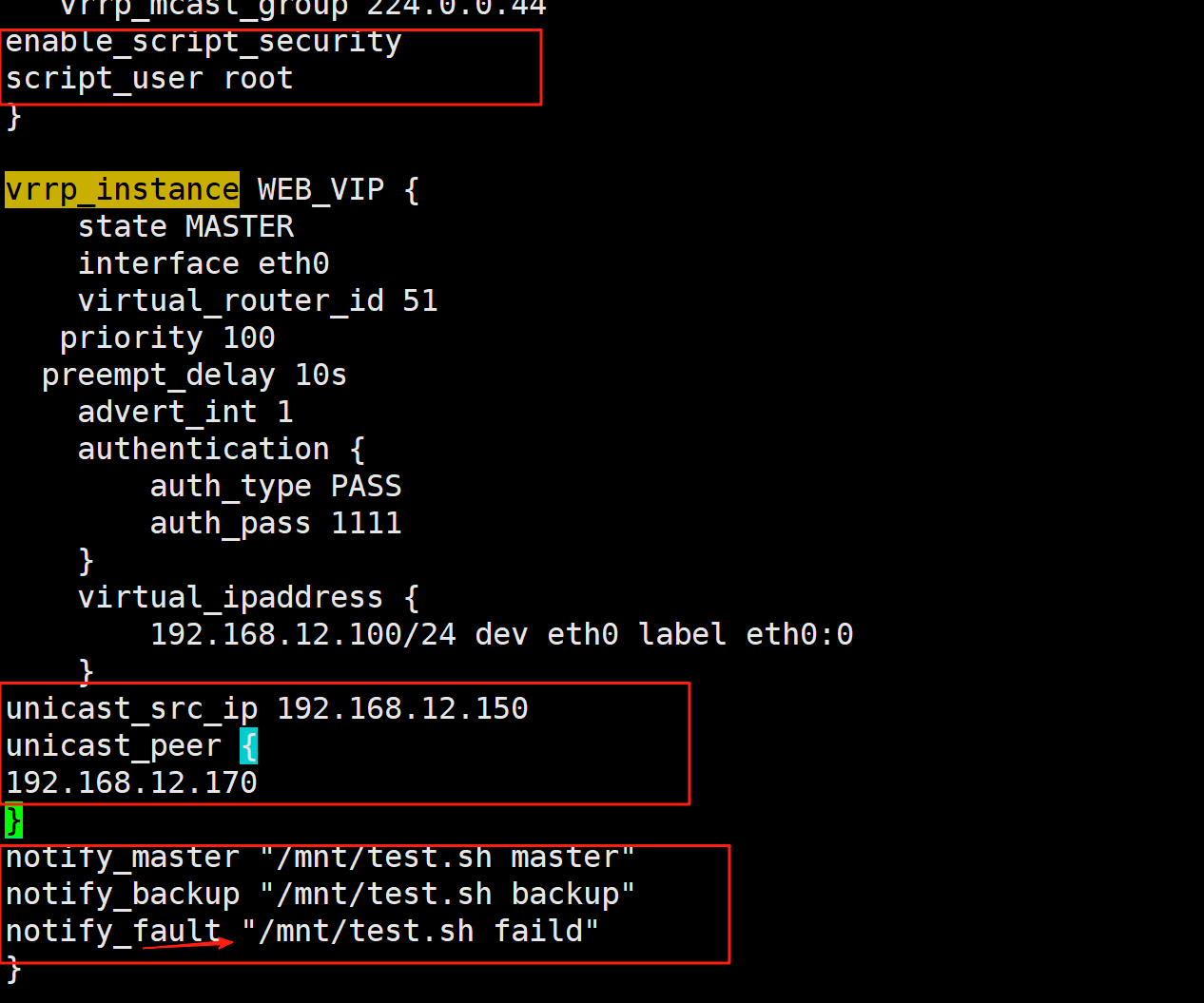
#!/bin/bash
rm -fr /mnt/{master,backup,faild}
case $1 in
master)
echo master > /mnt/master
;;
backup)
echo backup > /mnt/backup
;;
faild)
echo faild > /mnt/faild
esac
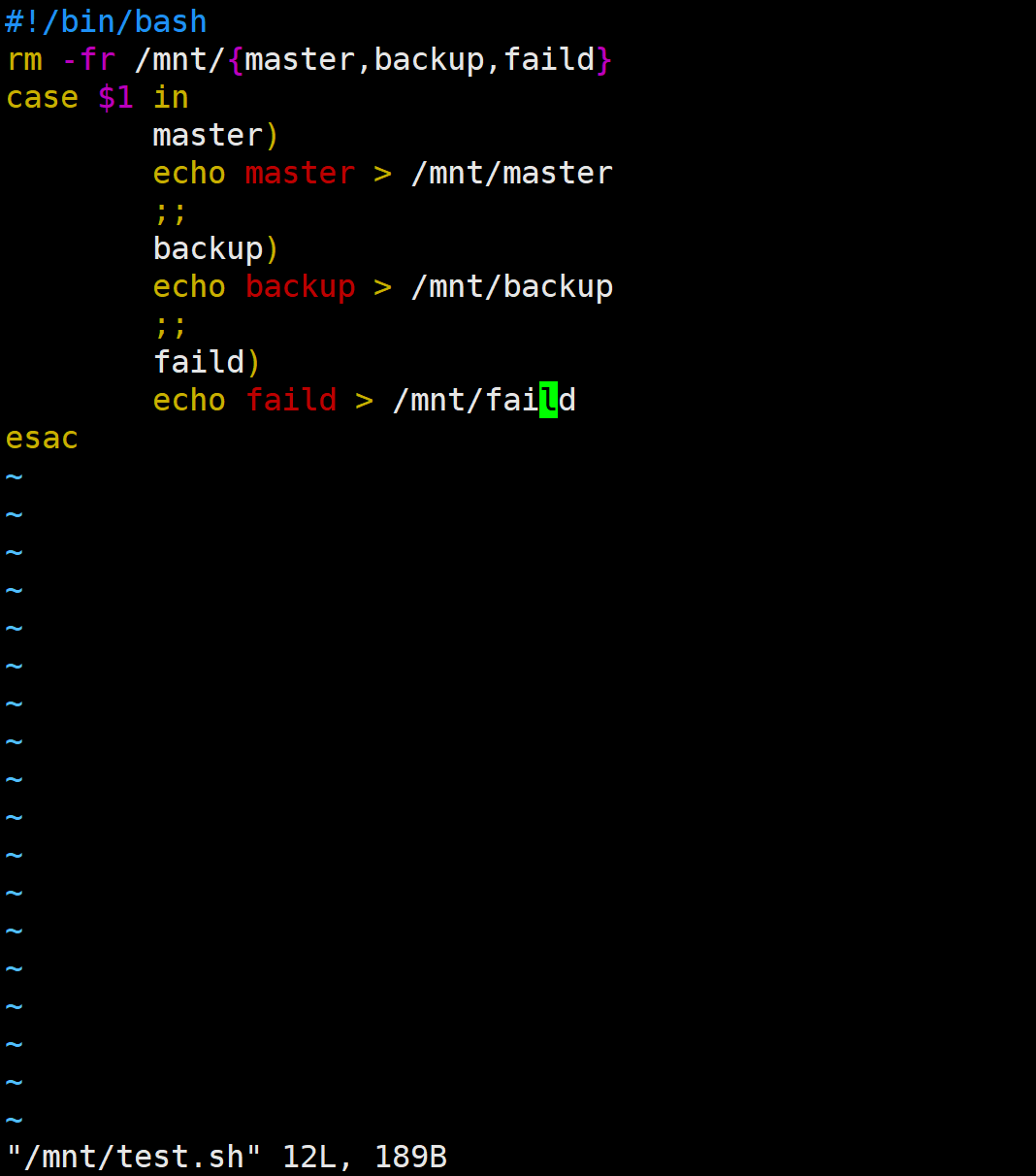
/mnt/test.sh 必须存在且 可执行,否则 Keepalived 会不断报警。
sudo chmod +x /mnt/test.sh测试:
3.4.4****邮件配置
安装邮件发送工具
root@KA1 \~# dnf install s-nail sendmail -y
root@KA1 \~# systemctl enable --now sendmail.service

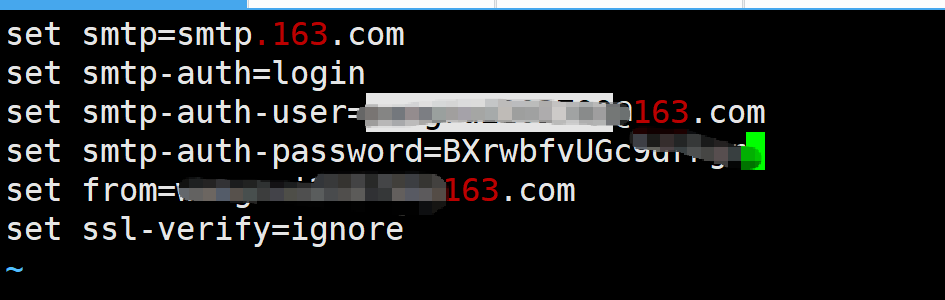
root@KA1 \~# echo hello | mailx -s test xxxxx@163.com


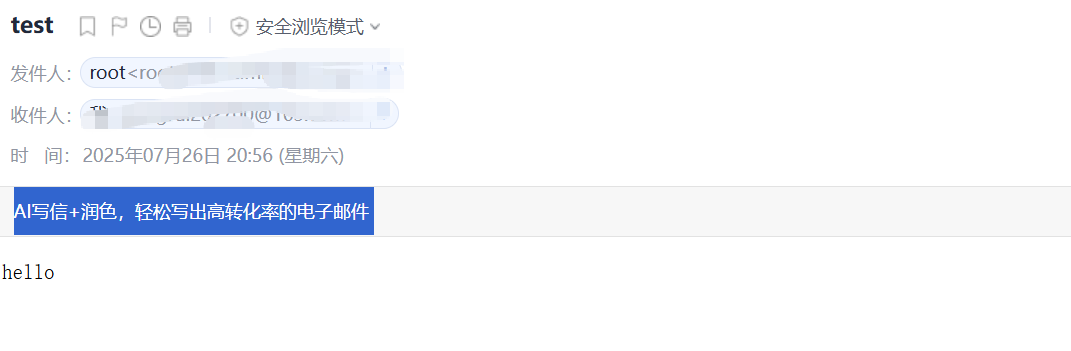

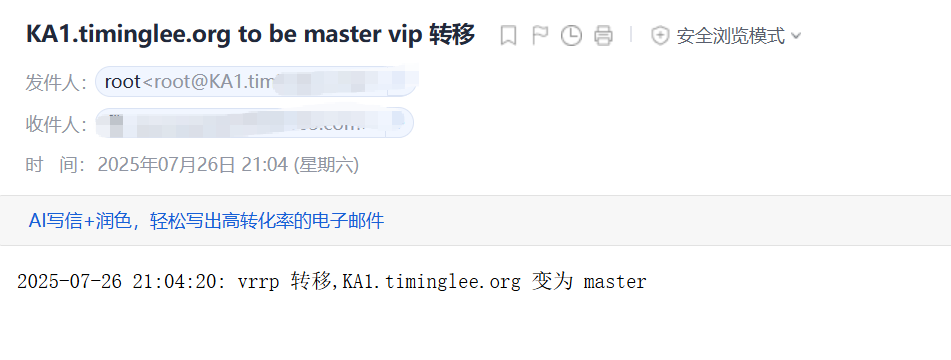
3.4.5实战案例:实现Keepalived****状态切换的通知脚本
编写脚本:
#!/bin/bash
mail_dest='xxxx@163.com'
mail_send()
{
mail_subj="HOSTNAME to be 1 vip 转移"
mail_mess="`date +%F\ %T`: vrrp 转移,HOSTNAME 变为 1"
echo "mail_mess" \| mail -s "mail_subj" $mail_dest
}
case $1 in
master)
mail_send master
;;
backup)
mail_send backup
;;
fault)
mail_send fault
;;
*)
exit 1
;;
esac
~
root@KA1 \~# vim /etc/keepalived/keepalived.conf
root@KA1 \~# systemctl restart keepalived.service
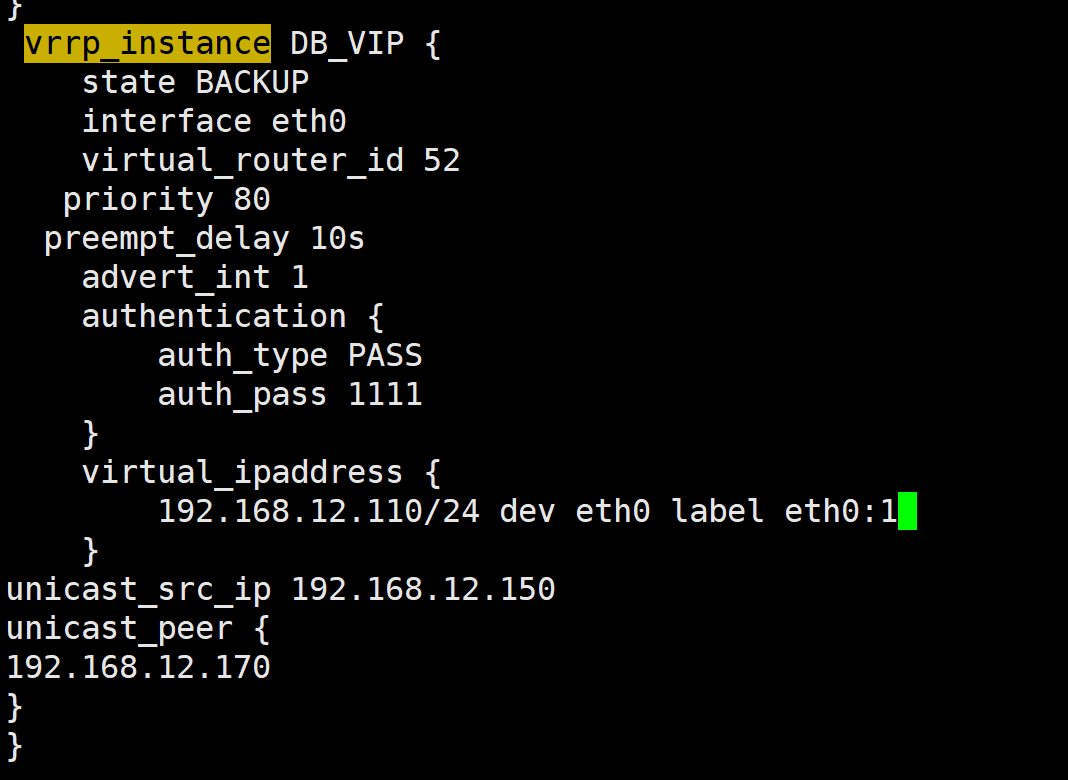
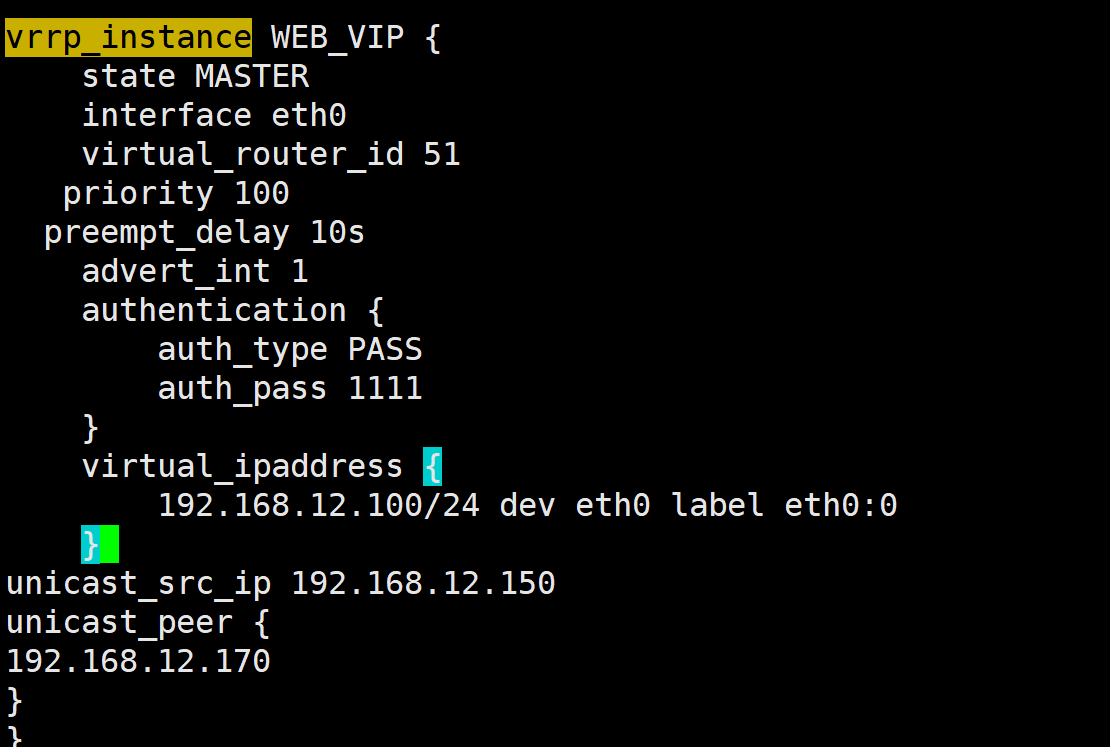
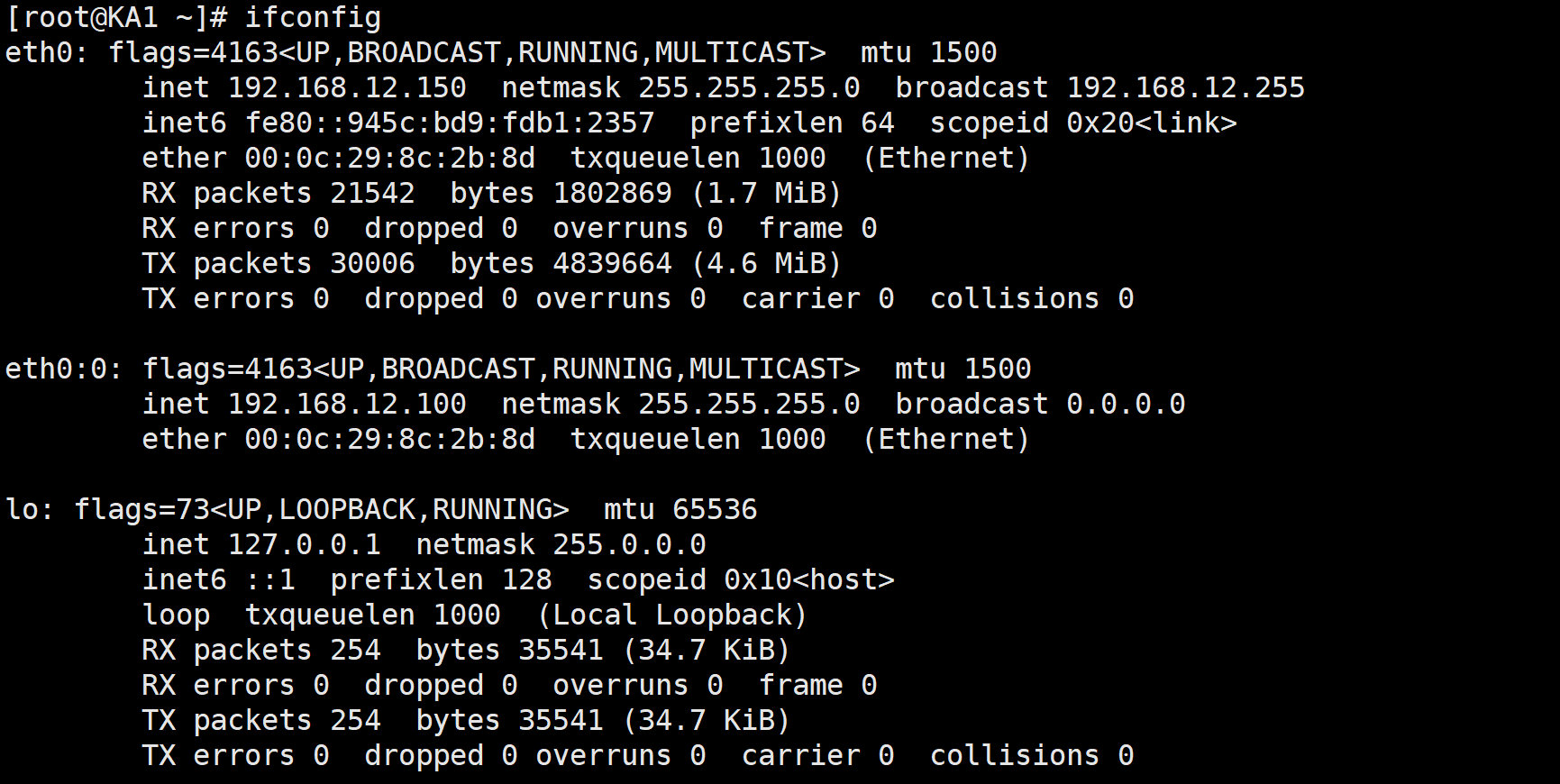
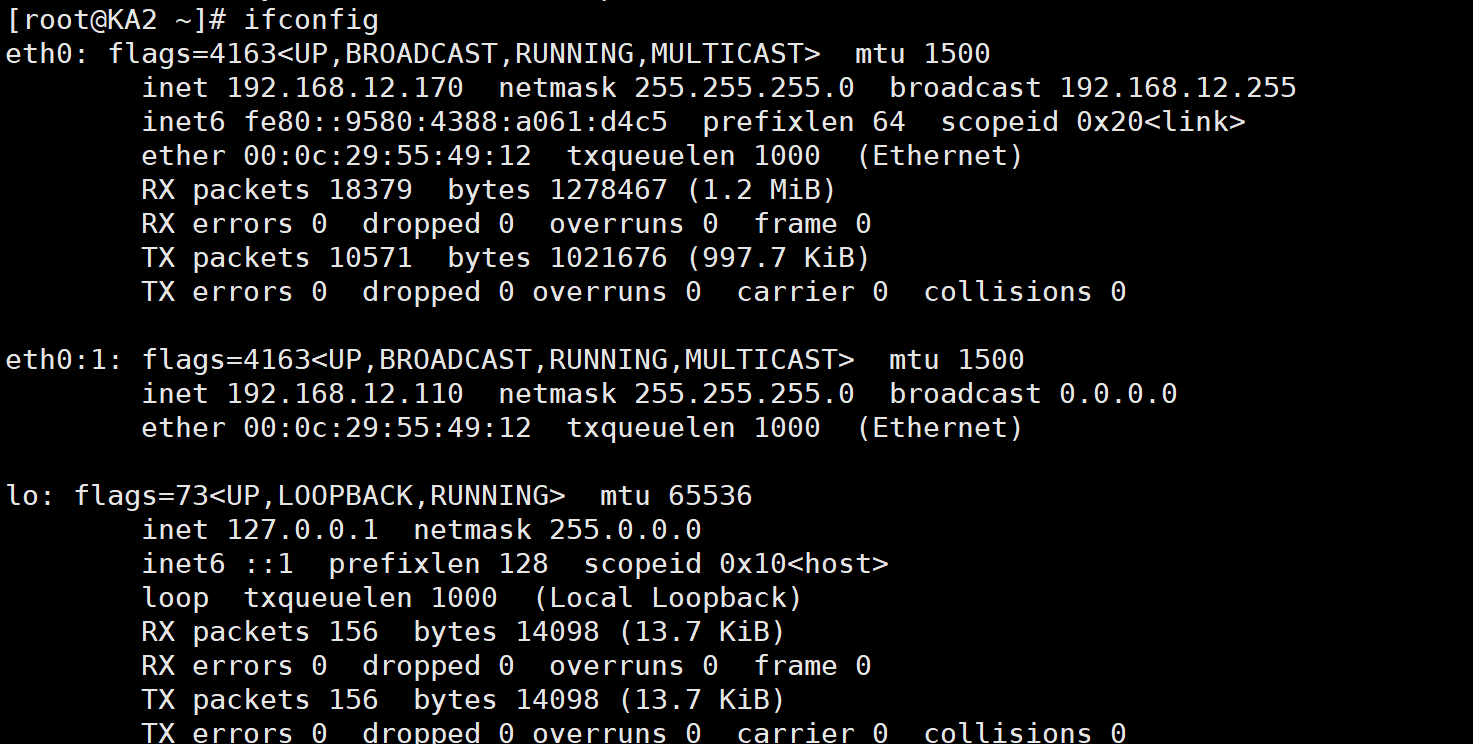
3.5实现master/master的Keepalived****双主架构
master/slave的单主架构,同一时间只有一个Keepalived对外提供服务,此主机繁忙,而另一台主机却很空闲,利用率低下,可以使用master/master的双主架构,解决此问题。
master/master 的双主架构:
即将两个或以上VIP分别运行在不同的keepalived服务器,以实现服务器并行提供web访问的目的,提服务器资源利用率
两个虚拟路由设定
ka1 ka2与ka1的两个相反
3.6实现IPVS****的高可用性
3.6.1 IPVS****相关配置
**1.**虚拟服务器配置结构
virtual_server IP port {
...
real_server {
...
}
real_server {
...
}
...
}
2.virtual server**(虚拟服务器)的定义格式**
virtual_server IP port #定义虚拟主机IP地址及其端口
virtual_server fwmark int #ipvs的防火墙打标,实现基于防火墙的负载均衡集群
virtual_server group string #使用虚拟服务器组
**3.**虚拟服务器配置
virtual_server IP port { #VIP和PORT
delay_loop <INT> #检查后端服务器的时间间隔
lb_algo rr|wrr|lc|wlc|lblc|sh|dh #定义调度方法
lb_kind NAT|DR|TUN #集群的类型,注意要大写
persistence_timeout <INT> #持久连接时长
protocol TCP|UDP|SCTP #指定服务协议,一般为TCP
sorry_server <IPADDR> <PORT> #所有RS故障时,备用服务器地址
real_server <IPADDR> <PORT> { #RS的IP和PORT
weight <INT> #RS权重
notify_up <STRING>|<QUOTED-STRING> #RS上线通知脚本
notify_down <STRING>|<QUOTED-STRING> #RS下线通知脚本
HTTP_GET|SSL_GET|TCP_CHECK|SMTP_CHECK|MISC_CHECK { ... } #定义当前主机健康状
态检测方法
}
}
注意:括号必须分行写,两个括号写在同一行,如: }} 会出错
**4.**应用层监测
应用层检测:HTTP_GET|SSL_GET
HTTP_GET|SSL_GET {
url {
path <URL_PATH> #定义要监控的URL
status_code <INT> #判断上述检测机制为健康状态的响应码,一般为 200
}
connect_timeout <INTEGER> #客户端请求的超时时长, 相当于haproxy的timeout server
nb_get_retry <INT> #重试次数
delay_before_retry <INT> #重试之前的延迟时长
connect_ip <IP ADDRESS> #向当前RS哪个IP地址发起健康状态检测请求
connect_port <PORT> #向当前RS的哪个PORT发起健康状态检测请求
bindto <IP ADDRESS> #向当前RS发出健康状态检测请求时使用的源地址
bind_port <PORT> #向当前RS发出健康状态检测请求时使用的源端口
}
5.TCP****监测
传输层检测:TCP_CHECK
TCP_CHECK {
connect_ip <IP ADDRESS> #向当前RS的哪个IP地址发起健康状态检测请求
connect_port <PORT> #向当前RS的哪个PORT发起健康状态检测请求
bindto <IP ADDRESS> #发出健康状态检测请求时使用的源地址
bind_port <PORT> #发出健康状态检测请求时使用的源端口
connect_timeout <INTEGER> #客户端请求的超时时长
#等于haproxy的timeout server
}
3.6.2****实战案例
准备web服务器并使用脚本绑定VIP至web服务器lo网卡
rs1和rs2安装
root@KA2 \~# dnf install ipvsadm-1.31-6.el9.x86_64 -y
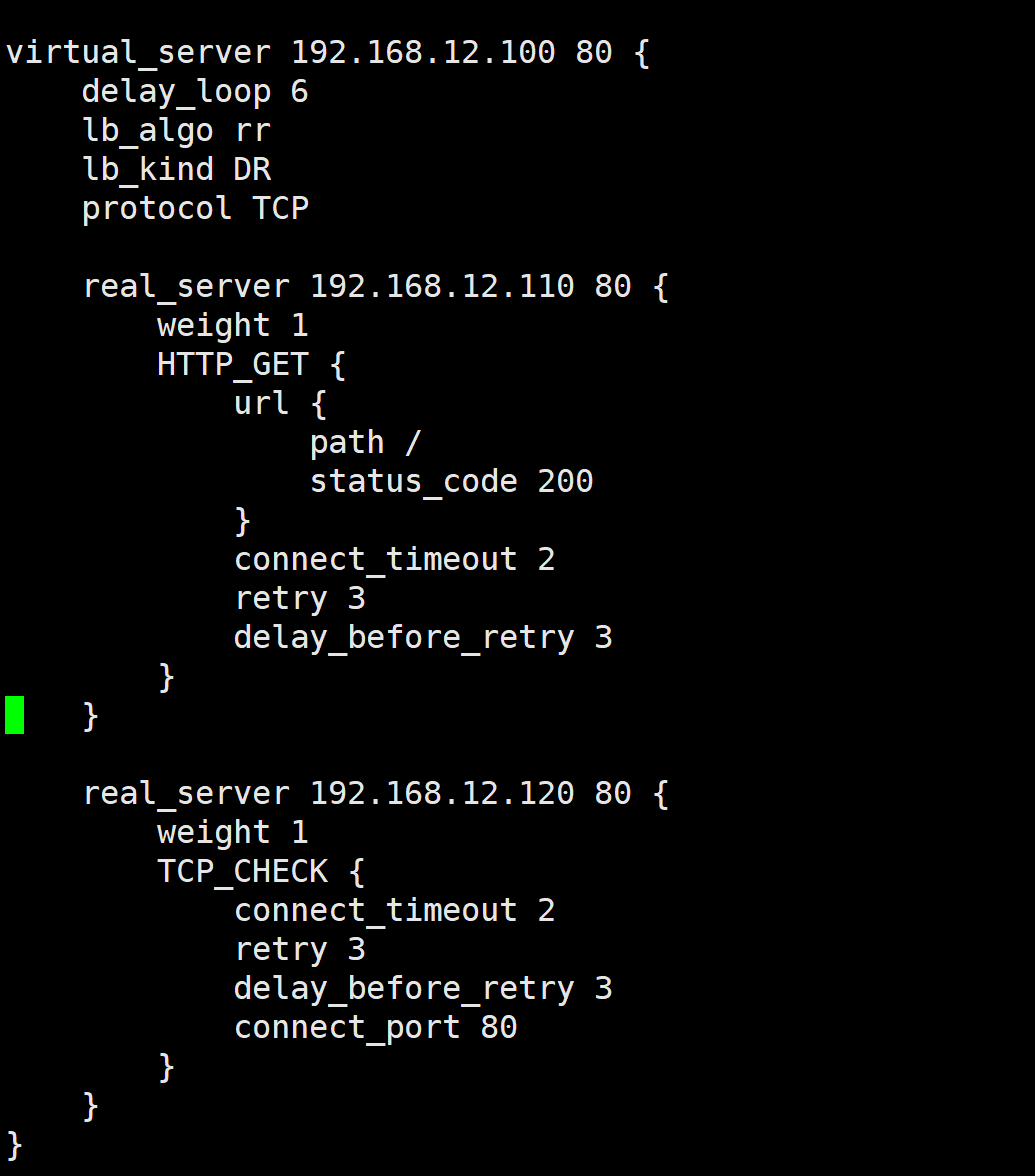
ka1和2上配置
virtual_server 192.168.12.100 80 {
delay_loop 6
lb_algo rr
lb_kind DR
protocol TCP
real_server 192.168.12.110 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 2
retry 3
delay_before_retry 3
}
}
real_server 192.168.12.120 80 {
weight 1
TCP_CHECK {
connect_timeout 2
retry 3
delay_before_retry 3
connect_port 80
}
}
}
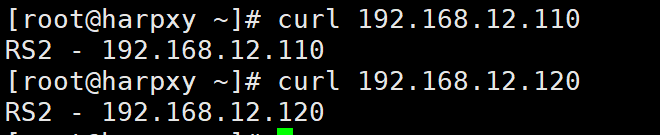
for i in {1..6}; do curl 192.168.12.100; done
RS2 - 192.168.12.110
RS2 - 192.168.12.120
RS2 - 192.168.12.110
RS2 - 192.168.12.120
RS2 - 192.168.12.110
RS2 - 192.168.12.120
ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.12.100:80 wrr
-> 192.168.12.110:80 Route 1 0 6
-> 192.168.12.120:80 Route 1 0 6
以上就是ipvs的高可用!
3.7实现其它应用的高可用性VRRP Script
3.7.1 VRRP Script****配置
分两步实现:
定义脚本
vrrp_script:自定义资源监控脚本,vrrp实例根据脚本返回值,公共定义,可被多个实例调用,定
义在vrrp实例之外的独立配置块,一般放在global_defs设置块之后。
通常此脚本用于监控指定应用的状态。一旦发现应用的状态异常,则触发对MASTER节点的权重减至低于SLAVE节点,从而实现 VIP 切换到 SLAVE 节点
vrrp_script <SCRIPT_NAME> {
script <STRING>|<QUOTED-STRING> #此脚本返回值为非0时,会触发下面OPTIONS执行
OPTIONS
}
调用脚本
track_script:调用vrrp_script定义的脚本去监控资源,定义在VRRP实例之内,调用事先定义的
vrrp_script
track_script {
SCRIPT_NAME_1
SCRIPT_NAME_2
}
1.定义VRRP script
vrrp_script <SCRIPT_NAME> { #定义一个检测脚本,在global_defs 之外配置
script <STRING>|<QUOTED-STRING> #shell命令或脚本路径
interval <INTEGER> #间隔时间,单位为秒,默认1秒
timeout <INTEGER> #超时时间
weight <INTEGER:-254..254> #默认为0,如果设置此值为负数,
#当上面脚本返回值为非0时
#会将此值与本节点权重相加可以降低本节点权重,
#即表示fall.
#如果是正数,当脚本返回值为0,
#会将此值与本节点权重相加可以提高本节点权重
#即表示 rise.通常使用负值
fall <INTEGER> #执行脚本连续几次都失败,则转换为失败,建议设为2以上
rise <INTEGER> #执行脚本连续几次都成功,把服务器从失败标记为成功
user USERNAME GROUPNAME #执行监测脚本的用户或组
init_fail #设置默认标记为失败状态,监测成功之后再转换为成功状态
}
2.调用VRRP script
vrrp_instance test {
... ...
track_script {
check_down
}
}
3.7.2****实战案例:利用脚本实现主从角色切换
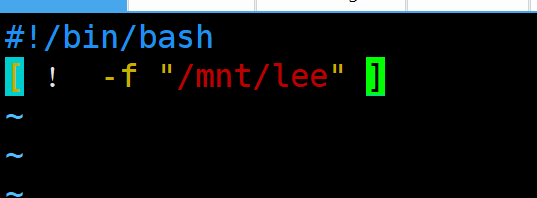
vim /mnt/check_lee.sh
#!/bin/bash
! -f "/mnt/lee"
chmod +x /mnt/check_lee.sh
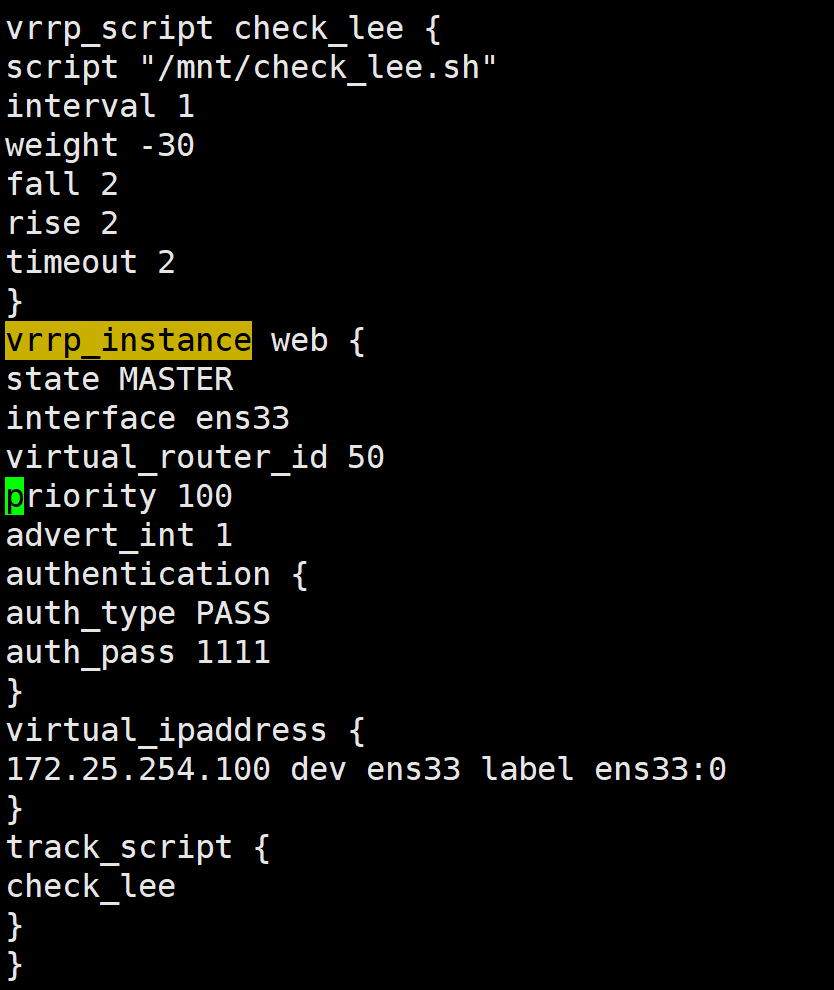
vim /etc/keepalived/keepalived.conf
脚本:
vrrp_script check_lee {
script "/mnt/check_lee.sh"
interval 1
weight -30
fall 2
rise 2
timeout 2
}
vrrp_instance web {
state MASTER
interface ens33
virtual_router_id 50
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.25.254.100 dev ens33 label ens33:0
}
track_script {
check_lee
}
}
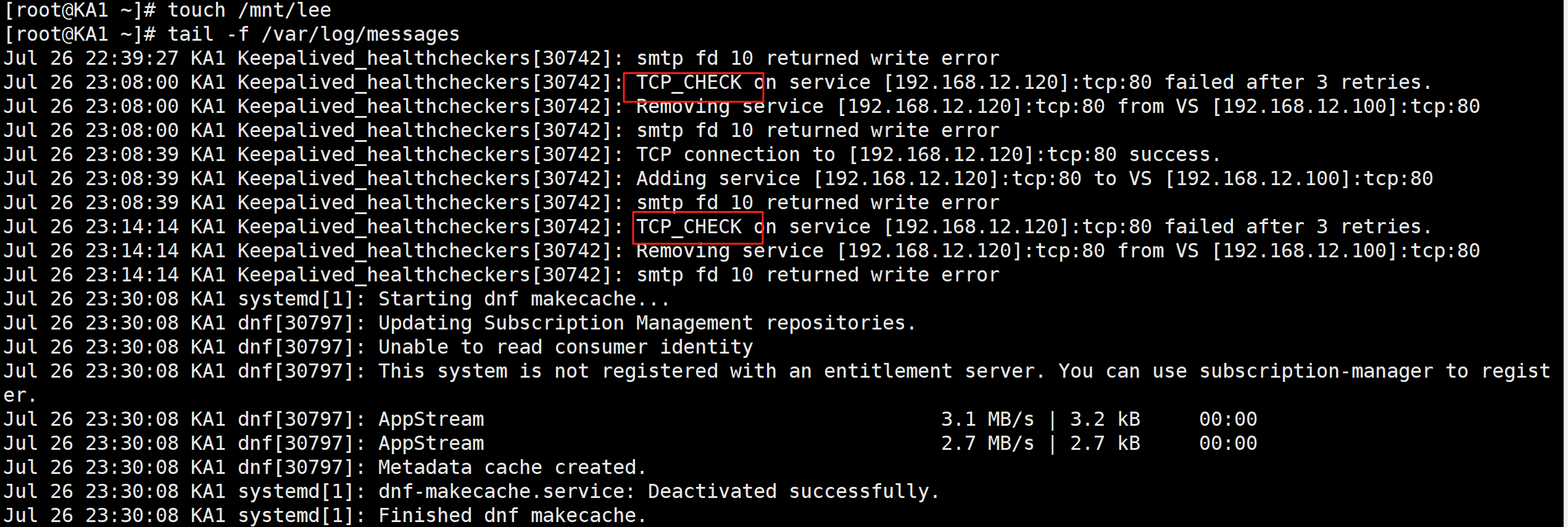
touch /mnt/lee
tail -f /var/log/messages
3.7.3实战案例:实现HAProxy****高可用
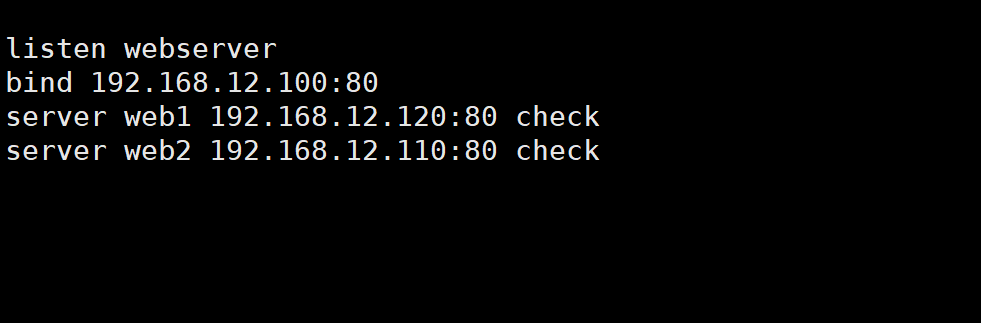
在ka1和ka2先实现haproxy的配置
listen webserver
bind 192.168.12.100:80
server web1 192.168.12.120:80 check
server web2 192.168.12.110:80 check
在两个ka1和ka2两个节点启用内核参数
vim /etc/sysctl.conf
net.ipv4.ip_nonlocal_bind = 1

sysctl -p


在ka1中编写检测脚本
vim /etc/keepalived/scripts/haproxy.sh
#!/bin/bash
killall -0 haproxy
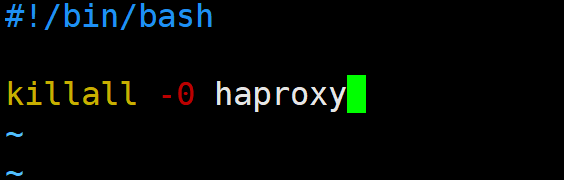
chmod +X /etc/keepalived/scripts/haproxy.sh

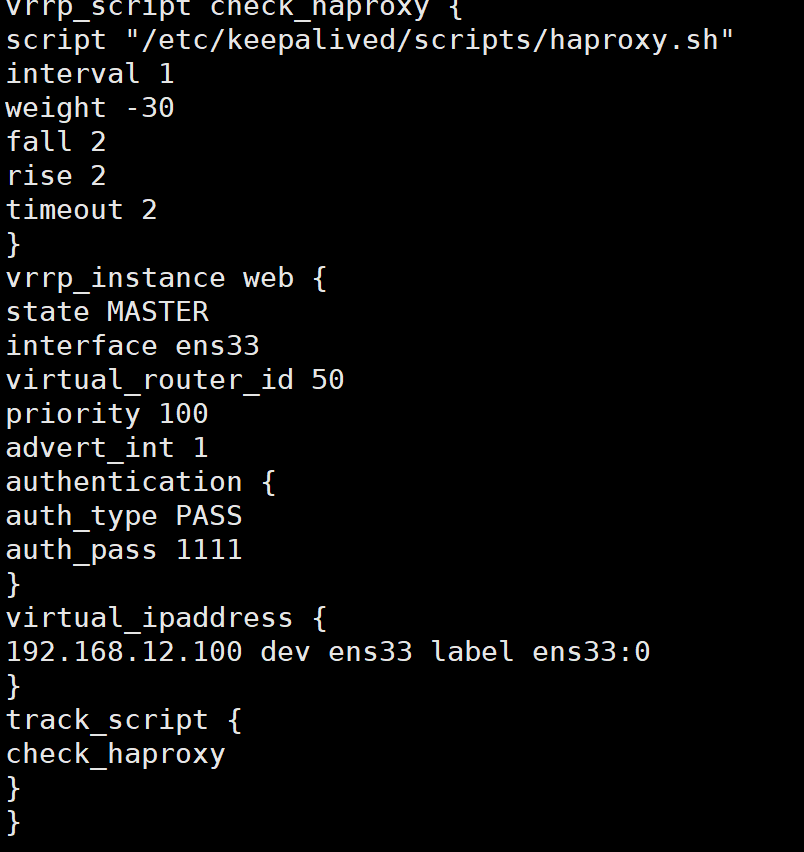
在ka1中配置keepalived
#cat /etc/keepalived/keepalived.conf
vrrp_script check_haproxy {
script "/etc/keepalived/scripts/haproxy.sh"
interval 1
weight -30
fall 2
rise 2
timeout 2
}
vrrp_instance web {
state MASTER
interface ens33
virtual_router_id 50
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.12.100 dev ens33 label ens33:0
}
track_script {
check_haproxy
}
}
测试
systemctl stop haproxy.service

成功!
以上就是对高可用集群KEEPALIVED的详细部署!!
四.注意事项
Keepalived 高可用集群在生产落地时,有 8 条「踩坑率最高」的注意事项,务必提前规避:
| 关键项 | 正确做法 / 避坑指南 |
|---|---|
| VRRP 通信方式 | 云环境或组播受限制时,统一使用单播 (unicast_src_ip + unicast_peer),可减少 90 % 脑裂事故 。 |
| virtual_router_id | 同一二层网络内必须唯一(0-255),不同集群不能重复,否则 Keepalived 会异常退出 。 |
| 抢占模式 | 为避免 MASTER 恢复后频繁漂移,主备均设为 BACKUP + 加 nopreempt ;如需延迟抢占,再配 preempt_delay N 。 |
| ARP 参数 | 必须显式添加 garp_master_delay 1 与 garp_master_refresh 5,防止切换后 ARP 不更新导致 VIP 不通 。 |
| vrrp_strict | 如果启用,会强制检查校验和并自动加 iptables 规则,极易把 VIP 封掉,建议删除或注释掉 。 |
| advert_int | 默认 1 秒;云网络抖动场景可调大到 3-5 秒,牺牲收敛速度换取稳定性,避免频繁主备倒换 。 |
| track_script / track_interface | 业务探测脚本 interval 设置过小会超时误判,建议 ≥5 s;接口 down 事件也要跟踪,防止"假存活" 。 |
| VIP 数量与网卡 | 单网卡 VIP ≤5 个;如需更多,在 global_defs 加 vrrp_garp_master_repeat 1,避免 GARP 风暴 。 |
以上就是高可用集群KEEPALIVED的详细部署!