摘要
随着 AI Agent的发展,人们期待其在科学发现中发挥关键作用。本文提出 X-Master,一种工具增强型通用推理Agent(tool-augmented reasoning agent) ,通过将 Python 代码作为与外部环境交互的语言,实现对计算库、网络搜索等工具的调用。为进一步增强推理能力,本文构建了一个分散--堆叠式代理工作流 X-Masters,实现解答过程的多阶段协作与优化。系统在 Humanity's Last Exam(HLE)上首次突破 30% 得分,超过 OpenAI 与 Google DeepMind 的闭源系统,展示出开源代理系统在科学智能领域的领先潜力。
- 论文标题:SciMaster: Towards General-Purpose Scientific AI Agents, Part I. X-Master as Foundation: Can We Lead on Humanity's Last Exam?
- 论文链接:arxiv.org/abs/2507.05...
1 引言
"人类最后考试(Humanity's Last Exam, HLE)" 是一个由全球近 1000 位领域专家共同打造的评估基准,涵盖来自超过 500 个机构的多学科知识前沿任务。它被视为 AI 系统在应对科学性、高复杂度、跨领域问题方面的终极挑战,其中的问题都非常复杂,例如下图展示了其中的几个样例:

目前,尽管 OpenAI 和 Google DeepMind 等闭源系统在 HLE 上分别取得一定的成绩,但这类系统的封闭性严重限制了社区理解、复现与创新的能力。
为应对这一挑战,本文提出一个无需微调、基于推理时增强的开源Agent系统 X-Master,旨在通过结构性地引导开源模型完成复杂科学任务。X-Master 将 Python 代码作为与外部环境交互的语言,调用包括网页搜索、科学论文解析等工具,在推理过程中主动获取和验证信息。
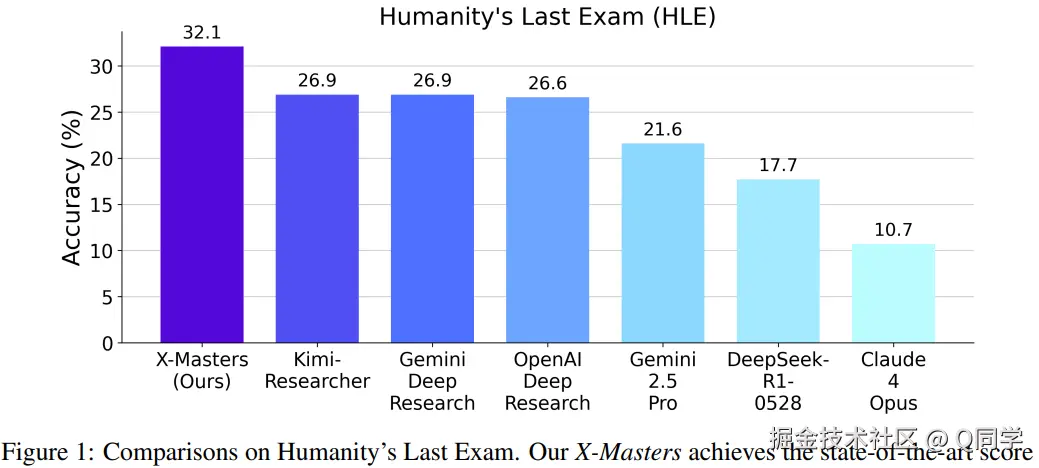
在此基础上,本文进一步构建一个分散--堆叠式代理工作流 X-Masters,使Agent在多个解法之间并行探索并逐步优化,显著提升了推理广度与深度。该系统最终在 HLE 上取得了32.1%的领先成绩,成为首个突破 30% 阈值的系统,且完整开源。
2 方法
2.1 工具增强型推理代理:X-Master
基于开源模型(如 DeepSeek-R1),通过代码调用工具获取实时信息;推理过程为多轮:生成 <code> 片段 → 工具调用 → 获取结果 <execution_results> → 继续推理;实现方式无需训练,只通过上下文控制代理行为。
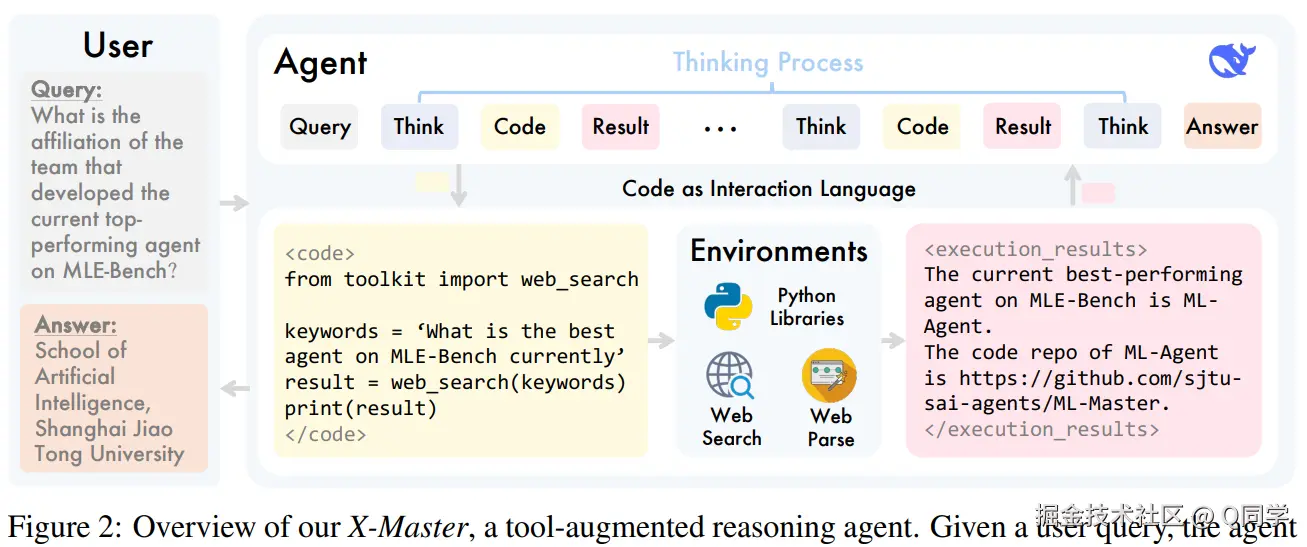
2.2 代码即交互语言
使用 Python 代码作为与外部环境交互的统一接口,具备三大优势:
- 通用性(可调用任意功能)、
- 准确性(结构表达意图)、
- 兼容性(复用成熟生态);
其中,工具种类包括内建库(如 NumPy)、网页搜索、PDF/HTML 解析等。
2.3 无需再训练的代理行为诱导机制
尽管一些开源大模型在推理能力上表现出色,但是这些模型没有针对性的工具调用训练,导致在工具调用能力上性能不佳,例如Deepseek-R1。为了克服这种困难,本文为非代理型模型(如 DeepSeek-R1)设计"初始引导"(Initial Reasoning Guidance),具体做法如下:
- 在
<think>标签内添加以第一人称自述的提示(例如"我会使用工具并以 标签包裹"); - 声明所有的工具都使用python实现调用
(1) 'I can answer this query effectively by leveraging access to external environments.' (2) 'Every time I determine the need for interaction with external tools, I will generate Python code enclosed between ` and ` tags.
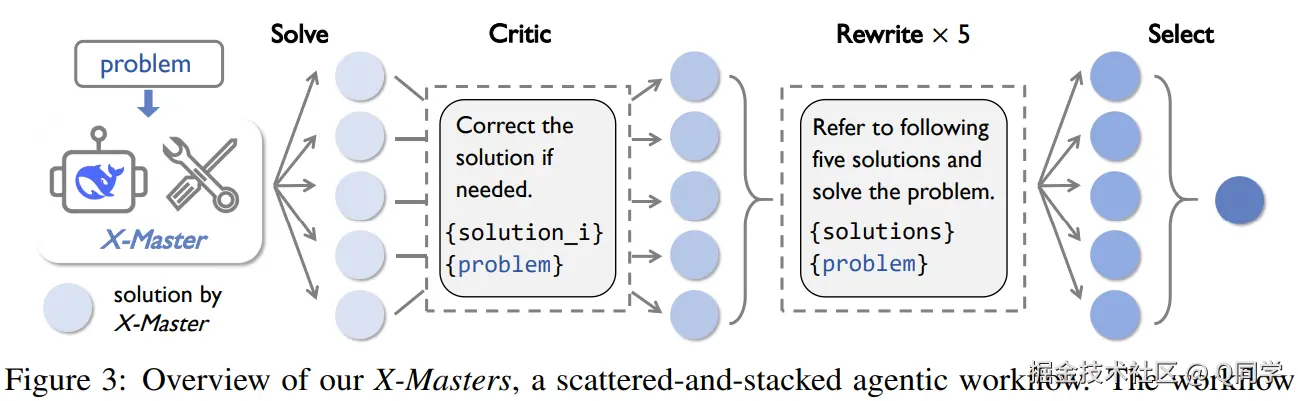
2.4 分散--堆叠式工作流:X-Masters
经过以上步骤改进的X-Master已基本具备了工具调用能力,作者接下来进行测试时扩展(Test-time Scaling),主要实现方式包括(深度和广度):
- Solver:并行生成 5 个工具增强解答;
- Critic:分别评估每个答案并提出修正;
- Rewriter:融合所有解答信息,生成新一轮改写;
- Selector:从重写答案中选出最终输出。
该结构兼顾解法多样性(广度)与答案精度(深度),形成结构化思维流程。
3 实验
3.1 数据集
- 主测试集:Humanity's Last Exam(HLE)文本子集,共 2,518 道题目;
- 评测模型:采用 o3-mini 作为裁判,评估系统输出的正确性;
- 生物医学扩展:包括 HLE 生物类目(222 题)与 TRQA-lit 数据集(172 道生物研究多选题)。
3.2 实验结果
在 HLE 上刷新 SOTA
X-Masters 为首个在 HLE 上突破 30% 的系统;显著超过现有闭源系统,验证该系统的工作流效果。

生物领域表现领先
- HLE 生物子集:X-Masters 准确率 27.6%,优于 STELLA(~26%)、Biomni(17.3%);
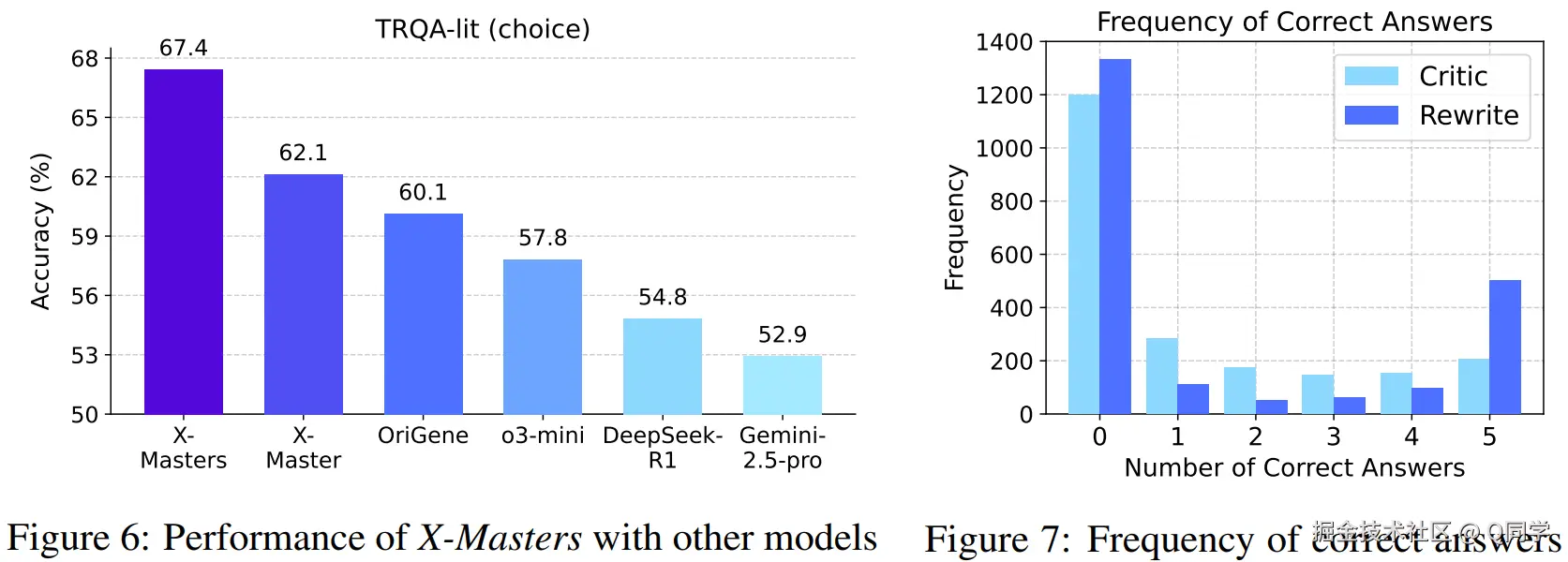
- TRQA-lit:
- 单独 X-Master:62.1%
- 完整工作流 X-Masters:67.4%
- 超越集成 500 工具的 OriGene,凸显架构高效性。
3.3 实验分析
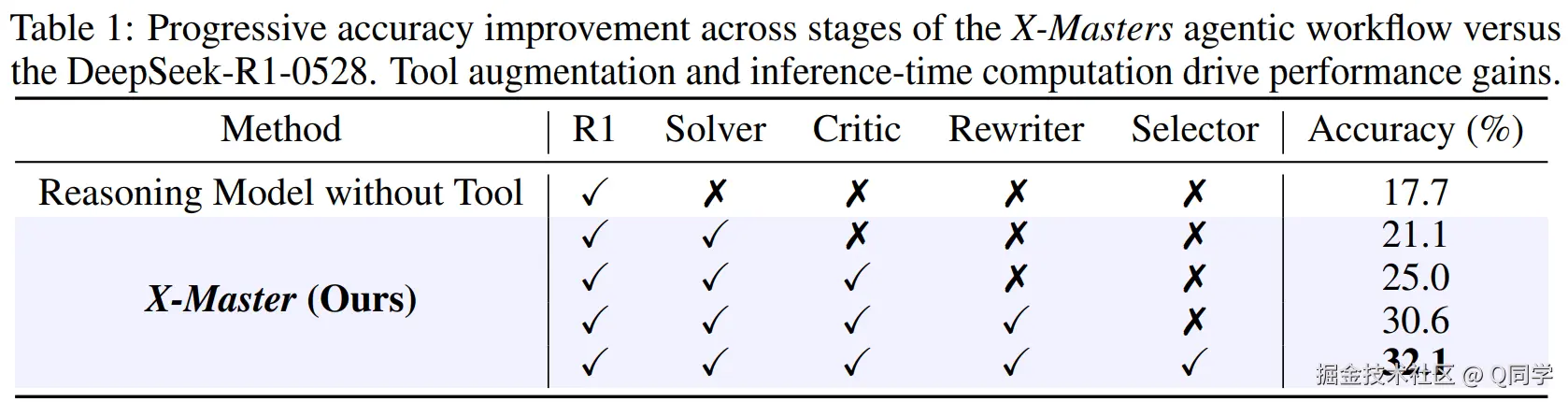
如表1所示,工具增强与测试时扩展带来性能增益:
- 基础模型(无工具):17.7%
- 工具支持(Solver):21.1%
- Critic 与 Rewriter:30.6%
- Selector 选择:32.1%
如图7所示,重写阶段有效提升正确答案数量:应用重写后,5 个解中至少 3 个正确的频率显著提高;帮助 Selector 更容易选出最佳答案。
消融实验验证堆叠与分散重要性:
| 设定 | 准确率 |
|---|---|
| 无分散 | 25.5% |
| 无堆叠(无重写与选择) | 25.0% |
| 全流程(分散+堆叠) | 32.1% |
3.4 案例分析

4 总结
本文提出了构建通用科学智能体的基础架构 X-Master,并通过 X-Masters 工作流展现出推理时增强策略的强大能力。该系统具备:1)多轮、可执行的推理能力;2)工具增强、上下文可控的行为设计;3)可部署于开源模型之上,无需额外训练。在 Humanity's Last Exam 与生物医学任务中均实现 SOTA 结果,验证了其科学研究智能体方向的可行性与领先性。
未来工作包括:
- 构建端到端训练代理,内化推理--工具使用流程;
- 设计更丰富的科学工具与任务(如文献阅读、实验规划等);
- 推进开源智能体系统在科研中的实用部署。