
1. 我们要做什么?
我们要做一件"魔术"一样的事情:把一份份"看不懂"的文档,变成电脑能理解、能提问、能回答的格式。我们会教电脑怎么"读文件""找重点""分段落"。
就像我们把一本厚厚的书,按小故事一个个剪下来,这样以后看、问、找都方便!
2. 我们需要的工具(环境准备)
就像做蛋糕前要准备面粉、鸡蛋,我们也要先装好工具!
先装 Python(电脑必须装过 Python 才能继续)
接下来打开你的终端或命令行,依次输入这些命令:
bash
# 创建虚拟环境(可选)
python -m venv env
source env/bin/activate # Windows上是 env\Scripts\activate
# 安装我们需要的工具包
pip install langchain
pip install unstructured
pip install beautifulsoup4
pip install pymupdf
pip install openpyxl
pip install python-docx
pip install python-pptx
pip install modelscope3. 让我们教电脑认识"文档"
电脑不像人,不认识 Word、PDF 这些文件,它只懂"文本"和"结构"这两样东西。
我们要先教它一个"概念"------Document(文档对象)。
ini
from langchain.schema import Document
doc = Document(
page_content="我是正文内容",
metadata={"source": "我的文件路径.pdf"}
)
print(doc.page_content) # 打印正文
print(doc.metadata) # 打印元数据(比如文件名、页数)这就像我们告诉电脑:"这是第几页的内容,它是来自哪里,它的原话是这些。"

4. 解析 HTML 网页
有两种方法:
- 方法一:网页链接直接读(推荐)
- 方法二:本地 HTML 文件
ini
from langchain_community.document_loaders import WebBaseLoader,BSHTMLLoader
# 方法一:从网址抓网页内容
loader = WebBaseLoader(
"https://flask.palletsprojects.com/en/stable/tutorial/layout/")
docs = loader.load()
for doc in docs:
print(doc.page_content,doc.metadata)
# 方法二:读取本地html文件
loader = BSHTMLLoader("student-grades.html")
docs = loader.load()
for doc in docs:
print(doc.page_content,doc.metadata)我们可以用 BeautifulSoup 自己抓代码块:
ini
from bs4 import BeautifulSoup
with open("student-grades.html", "r", encoding="utf-8") as f:
html = f.read()
soup = BeautifulSoup(html, "html.parser")
code_blocks = soup.find_all("td", class_="py-3 px-4")
for block in code_blocks:
print(block.get_text())5. 解析 PDF 文件
PDF 是最常见的办公文档。我们用两个方法来解析它。
方法一:简单读取文字内容
ini
from langchain.document_loaders import PyMuPDFLoader
loader = PyMuPDFLoader("analysisReport.pdf")
docs = loader.load()
for doc in docs:
print(doc.page_content)方法二:高级自定义------提取表格
安装依赖
pip install pymupdf pandas openpyxl
ini
import fitz # PyMuPDF
import pandas as pd
# 打开PDF文件
doc = fitz.open("analysisReport.pdf")
# 创建一个ExcelWriter对象,用于写入多个工作表
with pd.ExcelWriter("output_tables.xlsx", engine="openpyxl") as writer:
page_num = 0
for page in doc.pages():
page_num += 1
tables = page.find_tables()
for table_index, table in enumerate(tables, start=1):
df = table.to_pandas()
print(df)
# 写入Excel,每个表格作为一个sheet,命名方式为 Page_1_Table_1 等
sheet_name = f"Page_{page_num}_Table_{table_index}"
df.to_excel(writer, sheet_name=sheet_name, index=False)
print(f"已写入:{sheet_name}")6. Word、PPT、Excel 怎么解析?
Word
python
from docx import Document as DocxDocument
doc = DocxDocument("analysisReport.docx")
print("文本段落:")
for para in doc.paragraphs:
print(para.text)
print("表格:")
for table in doc.tables:
for row in table.rows:
print([cell.text for cell in row.cells])PPT
python
import os
import uuid
from pptx import Presentation
ppt = Presentation("demo.pptx")
# Create a directory to save images if it doesn't exist
output_dir = "ppt_images"
os.makedirs(output_dir, exist_ok=True)
for slide_id, slide in enumerate(ppt.slides):
print(f"\n--- 第{slide_id+1}页 ---")
for shape in slide.shapes:
if shape.has_text_frame:
print("[Text]", shape.text)
elif shape.shape_type == 13: # picture
print("[Image] 有图片,保存")
try:
# Get the image
image = shape.image
# Generate a unique filename using UUID
unique_id = uuid.uuid4()
image_filename = os.path.join(output_dir, f"slide_{slide_id + 1}_image_{unique_id}.{image.ext}")
# Save the image
with open(image_filename, 'wb') as img_file:
img_file.write(image.blob)
print(f"[Image] Saved: {image_filename}")
except Exception as e:
print(f"Error saving image: {e}")
elif shape.has_table:
print("[Table]")
for row in shape.table.rows:
print([cell.text for cell in row.cells])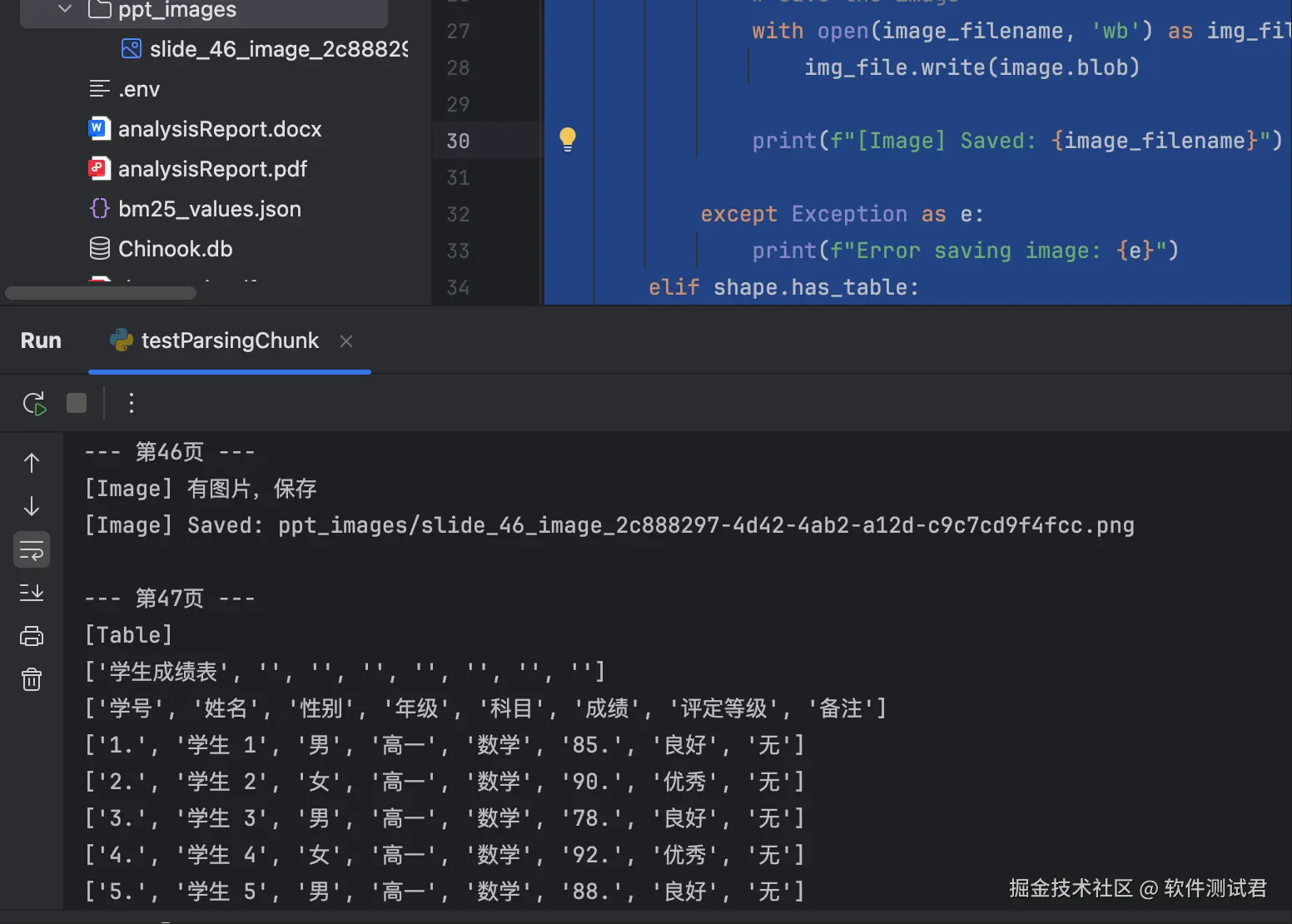
Excel
python
from openpyxl import load_workbook
wb = load_workbook("fake.xlsx")
sheet = wb.active
print("按行打印单元格:")
for row in sheet.iter_rows():
print([cell.value for cell in row])
print("合并单元格:")
for merged_range in sheet.merged_cells.ranges:
print("合并: ", merged_range)
7. 把文档"切"成小段落(分块)
方法一:递归文本分块(最常用)
ini
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=128,
chunk_overlap=30,
separators=["\n", "。", "!", "?"]
)
docs_split = text_splitter.split_documents(docs)
for i, doc in enumerate(docs_split[:3]):
print(f"第{i+1}块:\n{doc.page_content}\n")方法二:语义分块(智能一点)
ini
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.text_splitter import SemanticChunker
embedding = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh")
chunker = SemanticChunker(embedding)
docs_split = chunker.split_documents(docs)方法三:模型分块(阿里的模型)
ini
from modelscope.pipelines import pipeline
splitter = pipeline(
task="text-segmentation",
model="damo/nlp_corom_sentence-segmentation_chinese-base"
)
result = splitter("这是第一句话。这是第二句话。这是第三句话。")
print(result)8. 总结一下!
| 工具名 | 用途 | 安装命令 |
|---|---|---|
| langchain | 框架,封装 document | pip install langchain |
| unstructured | 自动识别多种文档 | pip install unstructured |
| PyMuPDF | 解析 PDF | pip install pymupdf |
| beautifulsoup4 | HTML解析 | pip install beautifulsoup4 |
| python-docx | Word处理 | pip install python-docx |
| python-pptx | PPT处理 | pip install python-pptx |
| openpyxl | Excel处理 | pip install openpyxl |
| modelscope | 使用 AI 模型 | pip install modelscope |
📌 小提示:
- 多试几种 loader,理解它们的区别。
- 文档结构不同,处理策略也要灵活。
- 分块大小、重叠设置,可以根据句子长度分布来定。