LangChain 模块和体系
LangChain 是一个用于开发由大型语言模型(LLMs)驱动的应用程序的框架。
官方文档:python.langchain.com/docs/introd...
LangChain 简化了LLM应用程序生命周期的每个阶段:
- 开发 :使用 LangChain 的开源组件和第三方集成构建您的应用程序。使用LangGraph构建具有一流流媒体和人机交互支持的状态代理。
- 生产部署 :使用LangSmith检查、监控和评估您的链,以便您可以持续优化并自信地部署。
- 部署 :使用 LangGraph 平台将您的 LangGraph 应用程序转变为可用于生产的 API 和助手。
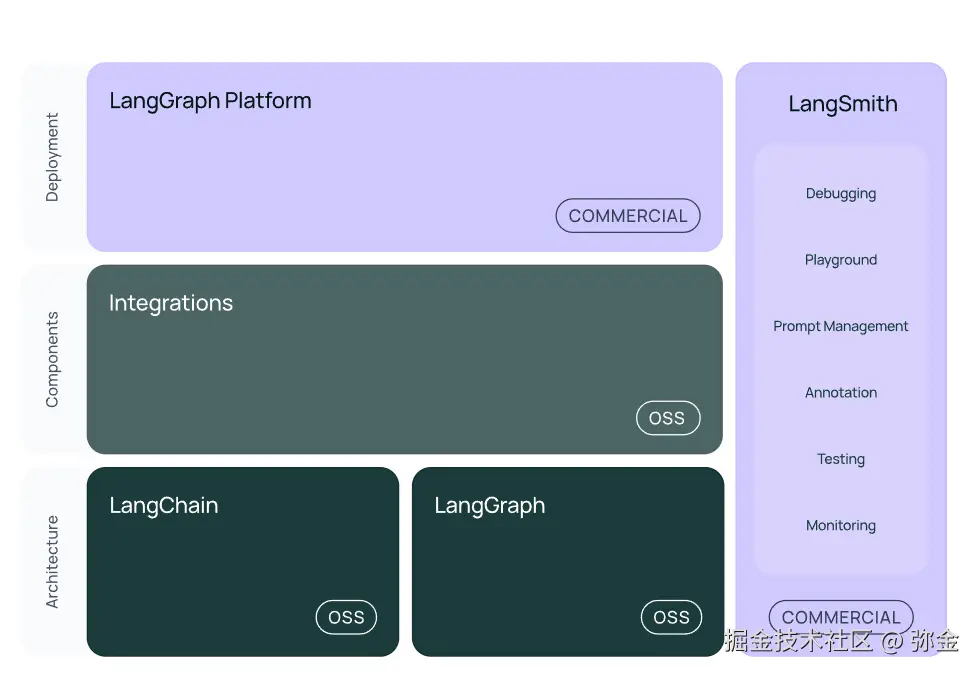
LangChain 框架由多个开源库组成。
langchain-core:聊天模型和其他组件的基础抽象。- 集成包 (例如
langchain-openai、langchain-anthropic等):重要的集成已被拆分为轻量级包,由 LangChain 团队和集成开发人员共同维护。 langchain:构成应用程序认知架构的链、代理和检索策略。langchain-community:由社区维护的第三方集成。langgraph:用于将 LangChain 组件组合成可投入生产的应用程序的编排框架,具有持久性、流式传输和其他关键功能。
LLM & Chat models PromptTemplates, OutputParses Chains
LLMs
将字符串作为输入并返回字符串的语言模型。这些通常是较旧的模型(较新的模型通常是 ChatModels)。 尽管底层模型是字符串输入、字符串输出,LangChain 封装器还允许这些模型接受消息作为输入。 这使它们可以与 ChatModels 互换使用。 当消息作为输入传入时,它们将在传递给底层模型之前在内部格式化为字符串。 LangChain 不提供任何 LLMs,而是依赖于第三方集成。
Messages(消息)
一些语言模型将消息列表作为输入并返回消息。 有几种不同类型的消息。 所有消息都有 role、content 和 response_metadata 属性。 role 描述了消息的发出者是谁。 LangChain 为不同的角色设计了不同的消息类。 content 属性描述了消息的内容。 这可以是几种不同的内容:
- 一个字符串(大多数模型处理这种类型的内容)
- 一个字典列表(用于多模态输入,其中字典包含有关该输入类型和该输入位置的信息)
AIMessage
这代表模型发送的消息。除了 content 属性外,这些消息还有: response_metadata response_metadata 属性包含有关响应的其他元数据。这里的数据通常针对每个模型提供者具体化。 这是存储对数概率和标记使用等信息的地方。 tool_calls 这些表示语言模型调用工具的决定。它们作为 AIMessage 输出的一部分包含在内。 可以通过 .tool_calls 属性从中访问。 此属性返回一个字典列表。每个字典具有以下键:
name:应调用的工具的名称。args:该工具的参数。id:该工具调用的 id。
SystemMessage
这代表系统消息,告诉模型如何行为。并非每个模型提供者都支持这一点。
FunctionMessage
这代表函数调用的结果。除了 role 和 content,此消息还有一个 name 参数,传达了生成此结果所调用的函数的名称。
ToolMessage
这代表工具调用的结果。这与 FunctionMessage 不同,以匹配 OpenAI 的 function 和 tool 消息类型。除了 role 和 content,此消息还有一个 tool_call_id 参数,传达了调用生成此结果的工具的 id。
Prompt templates(提示模板)
提示模板有助于将用户输入和参数转换为语言模型的指令。 这可用于引导模型的响应,帮助其理解上下文并生成相关和连贯的基于语言的输出。 提示模板以字典作为输入,其中每个键代表要填充的提示模板中的变量。 提示模板输出一个 PromptValue。这个 PromptValue 可以传递给 LLM 或 ChatModel,并且还可以转换为字符串或消息列表。 存在 PromptValue 的原因是为了方便在字符串和消息之间切换。 有几种不同类型的提示模板
String PromptTemplates
这些提示模板用于格式化单个字符串,通常用于更简单的输入。 例如,构建和使用 PromptTemplate 的常见方法如下:
arduino
from langchain_core.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template("Tell me a joke about {topic}")
prompt_template.invoke({"topic": "cats"})ChatPromptTemplates
这些提示模板用于格式化消息列表。这些"模板"本身是模板列表。 例如,构建和使用 ChatPromptTemplate 的常见方法如下:
arduino
from langchain_core.prompts import ChatPromptTemplate
prompt_template = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant"),
("user", "Tell me a joke about {topic}")
])
prompt_template.invoke({"topic": "cats"})在上面的示例中,当调用此 ChatPromptTemplate 时,将构建两条消息。 第一条是系统消息,没有要格式化的变量。 第二条是 HumanMessage,并将根据用户传入的 <font style="color:rgb(28, 30, 33);">topic</font> 变量进行格式化。
MessagesPlaceholder
这个提示模板负责在特定位置添加消息列表。 在上面的 ChatPromptTemplate 中,我们看到了如何格式化两条消息,每条消息都是一个字符串。 但是,如果我们希望用户传入一个消息列表,我们将其插入到特定位置,该怎么办? 这就是您使用 MessagesPlaceholder 的方式。
css
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import HumanMessage
prompt_template = ChatPromptTemplate.from_messages([ ("system", "You are a helpful assistant"), MessagesPlaceholder("msgs")])
prompt_template.invoke({"msgs": [HumanMessage(content="hi!")]})这将生成两条消息,第一条是系统消息,第二条是我们传入的 HumanMessage。 如果我们传入了 5 条消息,那么总共会生成 6 条消息(系统消息加上传入的 5 条消息)。 这对于将一系列消息插入到特定位置非常有用。 另一种实现相同效果的替代方法是,不直接使用 <font style="color:rgb(28, 30, 33);">MessagesPlaceholder</font> 类,而是:
ini
prompt_template = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant"),
("placeholder", "{msgs}") # <-- 这是更改的部分
])Output parsers(输出解析器)
这里提到的是将模型的文本输出进行解析,转换为更结构化表示的解析器。 越来越多的模型支持函数(或工具)调用,可以自动处理这一过程。 建议使用函数/工具调用,而不是输出解析。
负责接收模型的输出并将其转换为更适合下游任务的格式。 在使用LLMs生成结构化数据或规范化聊天模型和LLMs的输出时非常有用。 LangChain有许多不同类型的输出解析器。下表列出了LangChain支持的各种输出解析器及相关信息:
名称:输出解析器的名称
支持流式处理:输出解析器是否支持流式处理
具有格式说明:输出解析器是否具有格式说明。通常是可用的,除非在提示中未指定所需模式,而是在其他参数中指定(如OpenAI函数调用),或者当OutputParser包装另一个OutputParser时。
调用LLM :此输出解析器是否调用LLM。通常只有尝试纠正格式不正确的输出的输出解析器才会这样做。 输入类型:预期的输入类型。大多数输出解析器适用于字符串和消息,但有些(如OpenAI函数)需要具有特定kwargs的消息。
输出类型:解析器返回的对象的输出类型。
描述:我们对此输出解析器的评论以及何时使用它的说明。
示例代码
ini
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
model = ChatOpenAI(model="gpt-4")
messages = [
SystemMessage(content="将以下内容从英语翻译成中文"),
HumanMessage(content="It's a nice day today"),
]
parser = StrOutputParser()
result = model.invoke(messages)
#使用parser处理model返回的结果
response = parser.invoke(result)
print(response)
#今天天气很好Chains(链式调用)
Chains 是 LangChain 中用于将多个步骤组合成一个工作流程的模块。它们允许你定义一系列操作,并将它们链接在一起。比如在这个Chain中,每次都会调用输出解析器。这个链条的输入类型是语言模型的输出(字符串或消息列表),输出类型是输出解析器的输出(字符串)。
我们可以使用 | 运算符轻松创建这个Chain。| 运算符在 LangChain 中用于将两个元素组合在一起。
如果我们现在看一下 LangSmith,我们会发现这个链条有两个步骤:首先调用语言模型,然后将其结果传递给输出解析器。我们可以在 LangSmith 跟踪 中看到这一点。
smith.langchain.com/public/f1bd...
示例代码
ini
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
model = ChatOpenAI(model="gpt-4")
messages = [
SystemMessage(content="将以下内容从英语翻译成中文"),
HumanMessage(content="Let's go for a run"),
]
parser = StrOutputParser()
# 使用Chains方式调用
chain = model | parser #等于 model.invoke() + parser.invoke()
response = chain.invoke(messages)
print(response)
#我们去跑步吧
LCEL & Runable interface
LCEL 英文全称 LangChain Execution Language(LangChain 表达语言) 是一种声明性的方式来链接 LangChain 组件。 LCEL 从第一天起就被设计为支持将原型投入生产,无需更改代码,从最简单的"提示 + LLM"链到最复杂的链(我们已经看到有人成功地在生产中运行了包含数百步的 LCEL 链)。以下是您可能想要使用 LCEL 的一些原因的几个亮点:
一流的流式支持 当您使用 LCEL 构建链时,您将获得可能的最佳时间到第一个标记(直到输出的第一块内容出现所经过的时间)。对于某些链,这意味着我们直接从 LLM 流式传输标记到流式输出解析器,您将以与 LLM 提供程序输出原始标记的速率相同的速度获得解析的增量输出块。
异步支持 使用 LCEL 构建的任何链都可以使用同步 API(例如,在您的 Jupyter 笔记本中进行原型设计)以及异步 API(例如,在 LangServe 服务器中)进行调用。这使得可以在原型和生产中使用相同的代码,具有出色的性能,并且能够在同一服务器中处理许多并发请求。
优化的并行执行 每当您的 LCEL 链具有可以并行执行的步骤时(例如,如果您从多个检索器中获取文档),我们会自动执行,无论是在同步接口还是异步接口中,以获得可能的最小延迟。
重试和回退 为 LCEL 链的任何部分配置重试和回退。这是使您的链在规模上更可靠的好方法。我们目前正在努力为重试/回退添加流式支持,这样您就可以获得额外的可靠性而无需任何延迟成本。
访问中间结果 对于更复杂的链,访问中间步骤的结果通常非常有用,即使在生成最终输出之前。这可以用于让最终用户知道正在发生的事情,甚至只是用于调试您的链。您可以流式传输中间结果,并且在每个 LangServe 服务器上都可以使用。
输入和输出模式 输入和输出模式为每个 LCEL 链提供了从链的结构推断出的 Pydantic 和 JSONSchema 模式。这可用于验证输入和输出,并且是 LangServe 的一个组成部分。
无缝 LangSmith 追踪 ****随着您的链变得越来越复杂,准确理解每一步发生的事情变得越来越重要。 使用 LCEL,所有 步骤都会自动记录到 LangSmith 中,以实现最大的可观察性和可调试性。
无缝 LangServe 部署 ****使用 LCEL 创建的任何链都可以轻松地通过 LangServe 部署。
Runable interface(可运行接口)
为了尽可能简化创建自定义链的过程,我们实现了一个 "Runnable" 协议。许多 LangChain 组件都实现了 <font style="color:rgb(28, 30, 33);">Runnable</font> 协议,包括聊天模型、LLMs、输出解析器、检索器、提示模板等等。此外,还有一些有用的基本组件可用于处理可运行对象,您可以在下面了解更多。 这是一个标准接口,可以轻松定义自定义链,并以标准方式调用它们。 标准接口包括:
这些还有相应的异步方法,应该与 asyncio 一起使用 <font style="color:rgb(28, 30, 33);">await</font> 语法以实现并发:
<font style="color:rgb(28, 30, 33);">astream</font>: 异步返回响应的数据块<font style="color:rgb(28, 30, 33);">ainvoke</font>: 异步对输入调用链<font style="color:rgb(28, 30, 33);">abatch</font>: 异步对输入列表调用链<font style="color:rgb(28, 30, 33);">astream_log</font>: 异步返回中间步骤,以及最终响应<font style="color:rgb(28, 30, 33);">astream_events</font>: beta 流式传输链中发生的事件(在<font style="color:rgb(28, 30, 33);">langchain-core</font>0.1.14 中引入)
输入类型 和 输出类型 因组件而异:
| 组件 | 输入类型 | 输出类型 |
|---|---|---|
| 提示 | 字典 | 提示值 |
| 聊天模型 | 单个字符串、聊天消息列表或提示值 | 聊天消息 |
| LLM | 单个字符串、聊天消息列表或提示值 | 字符串 |
| 输出解析器 | LLM 或聊天模型的输出 | 取决于解析器 |
| 检索器 | 单个字符串 | 文档列表 |
| 工具 | 单个字符串或字典,取决于工具 | 取决于工具 |
所有可运行对象都公开输入和输出 模式 以检查输入和输出:
<font style="color:rgb(28, 30, 33);">input_schema</font>: 从可运行对象结构自动生成的输入 Pydantic 模型<font style="color:rgb(28, 30, 33);">output_schema</font>: 从可运行对象结构自动生成的输出 Pydantic 模型
流式运行对于使基于 LLM 的应用程序对最终用户具有响应性至关重要。 重要的 LangChain 原语,如聊天模型、输出解析器、提示模板、检索器和代理都实现了 LangChain Runnable 接口。 该接口提供了两种通用的流式内容方法:
- 同步
stream和异步astream:流式传输链中的最终输出 的默认实现。 - 异步
astream_events和异步astream_log:这些方法提供了一种从链中流式传输中间步骤 和最终输出的方式。 让我们看看这两种方法,并尝试理解如何使用它们。
Stream(流)
所有 Runnable 对象都实现了一个名为 stream 的同步方法和一个名为 astream 的异步变体。 这些方法旨在以块的形式流式传输最终输出,尽快返回每个块。 只有在程序中的所有步骤都知道如何处理输入流时,才能进行流式传输;即,逐个处理输入块,并产生相应的输出块。 这种处理的复杂性可以有所不同,从简单的任务,如发出 LLM 生成的令牌,到更具挑战性的任务,如在整个 JSON 完成之前流式传输 JSON 结果的部分。 开始探索流式传输的最佳方法是从 LLM 应用程序中最重要的组件开始------LLM 本身!
LLM 和聊天模型
大型语言模型及其聊天变体是基于 LLM 的应用程序的主要瓶颈。 大型语言模型可能需要几秒钟 才能对查询生成完整的响应。这比应用程序对最终用户具有响应性的约 200-300 毫秒的阈值要慢得多。 使应用程序具有更高的响应性的关键策略是显示中间进度;即,逐个令牌流式传输模型的输出。 我们将展示使用聊天模型进行流式传输的示例。从以下选项中选择一个:
让我们从同步 <font style="color:rgb(28, 30, 33);">stream</font> API 开始:
ini
chunks = []
for chunk in model.stream("天空是什么颜色?"):
chunks.append(chunk)
print(chunk.content, end="|", flush=True)天|空|是|什|么|颜|色|?|或者,如果您在异步环境中工作,可以考虑使用异步 <font style="color:rgb(28, 30, 33);">astream</font> API:
ini
chunks = []
async for chunk in model.astream("天空是什么颜色?"):
chunks.append(chunk)
print(chunk.content, end="|", flush=True)天|空|是|什|么|颜|色|?|让我们检查其中一个块:
css
chunks[1]
ini
AIMessageChunk(content='天', id='run-b36bea64-5511-4d7a-b6a3-a07b3db0c8e7')我们得到了一个称为 <font style="color:rgb(28, 30, 33);">AIMessageChunk</font> 的东西。该块表示 <font style="color:rgb(28, 30, 33);">AIMessage</font> 的一部分。 消息块是可叠加的------可以简单地将它们相加以获得到目前为止的响应状态!
css
chunks[0] + chunks[1] + chunks[2] + chunks[3] + chunks[4]
ini
AIMessageChunk(content='天空是什么颜色', id='run-b36bea64-5511-4d7a-b6a3-a07b3db0c8e7')Chain(链)
几乎所有的 LLM 应用程序都涉及不止一步的操作,而不仅仅是调用语言模型。 让我们使用 LangChain 表达式语言 (LCEL) 构建一个简单的链,该链结合了一个提示、模型和解析器,并验证流式传输是否正常工作。 我们将使用 StrOutputParser 来解析模型的输出。这是一个简单的解析器,从 AIMessageChunk 中提取 content 字段,给出模型返回的 token。
LCEL 是一种声明式 的方式,通过将不同的 LangChain 原语链接在一起来指定一个"程序"。使用 LCEL 创建的链可以自动实现 stream 和 astream,从而实现对最终输出的流式传输。事实上,使用 LCEL 创建的链实现了整个标准 Runnable 接口。
ini
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template("给我讲一个关于{topic}的笑话")
parser = StrOutputParser()
chain = prompt | model | parser
async for chunk in chain.astream({"topic": "鹦鹉"}):
print(chunk, end="|", flush=True)
|一个|人|去|宠|物|店|买|鹦|鹉|。|店|员|说|:"|这|只|鹦|鹉|会|说|话|。"|
|买|回|家|后|,|那|人|发|现|鹦|鹉|只|会|说|一|句|话|:"|我|是|鹦|鹉|。"|
|那|人|就|去|找|店|员|,|说|:"|你|不|是|说|这|只|鹦|鹉|会|说|话|吗|?|它|只|会|说|'|我|是|鹦|鹉|'|。"|
|店|员|回|答|:"|它|确|实|会|说|话|,|你|想|它|怎|么|可能|知|道|自|己|是|鹦|鹉|呢|?"||请注意,即使我们在上面的链条末尾使用了parser,我们仍然可以获得流式输出。parser会对每个流式块进行操作。许多LCEL基元也支持这种转换式的流式传递,这在构建应用程序时非常方便。
自定义函数可以被设计为返回生成器,这样就能够操作流。
某些可运行实体,如提示模板和聊天模型,无法处理单个块,而是聚合所有先前的步骤。这些可运行实体可以中断流处理。
LangChain表达语言允许您将链的构建与使用模式(例如同步/异步、批处理/流式等)分开。如果这与您构建的内容无关,您也可以依赖于标准的命令式编程方法,通过在每个组件上调用invoke、batch或stream,将结果分配给变量,然后根据需要在下游使用它们。
使用输入流
如果您想要在输出生成时从中流式传输JSON,该怎么办呢?
如果您依赖json.loads来解析部分JSON,那么解析将失败,因为部分JSON不会是有效的JSON。
您可能会束手无策,声称无法流式传输JSON。
事实证明,有一种方法可以做到这一点------解析器需要在输入流上操作,并尝试将部分JSON"自动完成"为有效状态。
让我们看看这样一个解析器的运行,以了解这意味着什么。
scss
model = ChatOpenAI(model="gpt-4")
parser = StrOutputParser()
chain = (
model | JsonOutputParser()
# 由于Langchain旧版本中的一个错误,JsonOutputParser未能从某些模型中流式传输结果
)
async def async_stream():
async for text in chain.astream(
"以JSON 格式输出法国、西班牙和日本的国家及其人口列表。"
'使用一个带有"countries"外部键的字典,其中包含国家列表。'
"每个国家都应该有键`name`和`population`"
):
print(text, flush=True)
bash
{}
{'countries': []}
{'countries': [{}]}
{'countries': [{'name': ''}]}
{'countries': [{'name': 'France'}]}
{'countries': [{'name': 'France', 'population': 670}]}
{'countries': [{'name': 'France', 'population': 670810}]}
{'countries': [{'name': 'France', 'population': 67081000}]}
{'countries': [{'name': 'France', 'population': 67081000}, {}]}
{'countries': [{'name': 'France', 'population': 67081000}, {'name': ''}]}
{'countries': [{'name': 'France', 'population': 67081000}, {'name': 'Spain'}]}
{'countries': [{'name': 'France', 'population': 67081000}, {'name': 'Spain', 'population': 467}]}
{'countries': [{'name': 'France', 'population': 67081000}, {'name': 'Spain', 'population': 467330}]}
{'countries': [{'name': 'France', 'population': 67081000}, {'name': 'Spain', 'population': 46733038}]}
{'countries': [{'name': 'France', 'population': 67081000}, {'name': 'Spain', 'population': 46733038}, {}]}
{'countries': [{'name': 'France', 'population': 67081000}, {'name': 'Spain', 'population': 46733038}, {'name': ''}]}
{'countries': [{'name': 'France', 'population': 67081000}, {'name': 'Spain', 'population': 46733038}, {'name': 'Japan'}]}
{'countries': [{'name': 'France', 'population': 67081000}, {'name': 'Spain', 'population': 46733038}, {'name': 'Japan', 'population': 126}]}
{'countries': [{'name': 'France', 'population': 67081000}, {'name': 'Spain', 'population': 46733038}, {'name': 'Japan', 'population': 126300}]}
{'countries': [{'name': 'France', 'population': 67081000}, {'name': 'Spain', 'population': 46733038}, {'name': 'Japan', 'population': 126300000}]}Stream events(事件流)
现在我们已经了解了stream和astream的工作原理,让我们进入事件流的世界。🏞️
事件流是一个beta API。这个API可能会根据反馈略微更改。
本指南演示了V2 API,并且需要 langchain-core >= 0.2。对于与旧版本 LangChain 兼容的V1 API,请参阅这里。
arduino
import langchain_core
langchain_core.__version__为了使astream_events API正常工作:
- 在代码中尽可能使用
async(例如,异步工具等) - 如果定义自定义函数/可运行项,请传播回调
- 在没有 LCEL 的情况下使用可运行项时,请确保在LLMs上调用
.astream()而不是.ainvoke以强制LLM流式传输令牌
事件参考
下面是一个参考表,显示各种可运行对象可能发出的一些事件。
当流式传输正确实现时,对于可运行项的输入直到输入流完全消耗后才会知道。这意味着inputs通常仅包括end事件,而不包括start事件。
| 事件 | 名称 | 块 | 输入 | 输出 |
|---|---|---|---|---|
| on_chat_model_start | 模型名称 | {"messages": \[SystemMessage, HumanMessage]} | ||
| on_chat_model_end | 模型名称 | {"messages": \[SystemMessage, HumanMessage]} | AIMessageChunk(content="hello world") | |
| on_llm_start | 模型名称 | {'input': 'hello'} | ||
| on_llm_stream | 模型名称 | 'Hello' | ||
| on_llm_end | 模型名称 | 'Hello human!' | ||
| on_chain_start | format_docs | |||
| on_chain_stream | format_docs | "hello world!, goodbye world!" | ||
| on_chain_end | format_docs | Document(...) | "hello world!, goodbye world!" | |
| on_tool_start | some_tool | {"x": 1, "y": "2"} | ||
| on_tool_end | some_tool | {"x": 1, "y": "2"} | ||
| on_retriever_start | 检索器名称 | {"query": "hello"} | ||
| on_retriever_end | 检索器名称 | {"query": "hello"} | Document(...), .. | |
| on_prompt_start | 模板名称 | {"question": "hello"} | ||
| on_prompt_end | 模板名称 | {"question": "hello"} | ChatPromptValue(messages: SystemMessage, ...) |
聊天模型
让我们首先看一下聊天模型产生的事件。
csharp
events = []
async for event in model.astream_events("hello", version="v2"):
events.append(event)
arduino
/home/eugene/src/langchain/libs/core/langchain_core/_api/beta_decorator.py:87: LangChainBetaWarning: This API is in beta and may change in the future.
warn_beta(嘿,API中那个有趣的version="v2"参数是什么意思?😾 这是一个beta API ,我们几乎肯定会对其进行一些更改(事实上,我们已经做了!) 这个版本参数将允许我们最小化对您代码的破坏性更改。 简而言之,我们现在让您感到烦恼,这样以后就不必再烦恼了。 v2仅适用于 langchain-core>=0.2.0。
让我们看一下一些开始事件和一些结束事件。
css
events[:3]
css
[{'event': 'on_chat_model_start', 'data': {'input': 'hello'}, 'name': 'ChatAnthropic', 'tags': [],
'run_id': 'a81e4c0f-fc36-4d33-93bc-1ac25b9bb2c3',
'metadata': {}},
{'event': 'on_chat_model_stream',
'data': {'chunk': AIMessageChunk(content='Hello', id='run-a81e4c0f-fc36-4d33-93bc-1ac25b9bb2c3')},
'run_id': 'a81e4c0f-fc36-4d33-93bc-1ac25b9bb2c3',
'name': 'ChatAnthropic',
'tags': [],
'metadata': {}},
{'event': 'on_chat_model_stream',
'data': {'chunk': AIMessageChunk(content='!', id='run-a81e4c0f-fc36-4d33-93bc-1ac25b9bb2c3')},
'run_id': 'a81e4c0f-fc36-4d33-93bc-1ac25b9bb2c3',
'name': 'ChatAnthropic',
'tags': [],
'metadata': {}}]
css
events[-2:]
bash
[{'event': 'on_chat_model_stream',
'data': {'chunk': AIMessageChunk(content='?', id='run-a81e4c0f-fc36-4d33-93bc-1ac25b9bb2c3')},
'run_id': 'a81e4c0f-fc36-4d33-93bc-1ac25b9bb2c3',
'name': 'ChatAnthropic',
'tags': [],
'metadata': {}},
{'event': 'on_chat_model_end',
'data': {'output': AIMessageChunk(content='Hello! How can I assist you today?', id='run-a81e4c0f-fc36-4d33-93bc-1ac25b9bb2c3')},
'run_id': 'a81e4c0f-fc36-4d33-93bc-1ac25b9bb2c3',
'name': 'ChatAnthropic',
'tags': [],
'metadata': {}}]LLM apps debug: LangSmith Tracing & Verbose, Debug Mode
与构建任何类型的软件一样,使用LLM构建时,总会有调试的需求。模型调用可能会失败,模型输出可能格式错误,或者可能存在一些嵌套的模型调用,不清楚在哪一步出现了错误的输出。 有三种主要的调试方法:
- 详细模式(Verbose):为你的链中的"重要"事件添加打印语句。
- 调试模式(Debug):为你的链中的所有事件添加日志记录语句。
- LangSmith跟踪:将事件记录到LangSmith,以便在那里进行可视化。
| 详细模式(Verbose Mode) | 调试模式(Debug Mode) | LangSmith跟踪 | |
|---|---|---|---|
| 免费 | ✅ | ✅ | ✅ |
| 用户界面 | ❌ | ❌ | ✅ |
| 持久化 | ❌ | ❌ | ✅ |
| 查看所有事件 | ❌ | ✅ | ✅ |
| 查看"重要"事件 | ✅ | ❌ | ✅ |
| 本地运行 | ✅ | ✅ | ❌ |
LangSmith Tracing(跟踪)
使用LangChain构建的许多应用程序将包含多个步骤,其中包含多次LLM调用。 随着这些应用程序变得越来越复杂,能够检查链或代理内部发生了什么变得至关重要。 这样做的最佳方式是使用LangSmith。 在上面的链接上注册后,请确保设置你的环境变量以开始记录跟踪:
arduino
#windows导入环境变量
setx LANGCHAIN_TRACING_V2 "true"
setx LANGCHAIN_API_KEY "..."
setx TAVILY_API_KEY "..."
#mac 导入环境变量
export LANGCHAIN_TRACING_V2="true"
export LANGCHAIN_API_KEY="..."
export TAVILY_API_KEY="..."假设我们有一个代理,并且希望可视化它所采取的操作和接收到的工具输出。在没有任何调试的情况下,这是我们看到的:
python
import os
from langchain_openai import ChatOpenAI
from langchain.agents import AgentExecutor, create_tool_calling_agent
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.prompts import ChatPromptTemplate
from langchain.globals import set_verbose
llm = ChatOpenAI(model="gpt-4o")
tools = [TavilySearchResults(max_results=1)]
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"你是一位得力的助手。",
),
("placeholder", "{chat_history}"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
]
)
# 构建工具代理
agent = create_tool_calling_agent(llm, tools, prompt)
set_verbose(True)
# 通过传入代理和工具来创建代理执行器
agent_executor = AgentExecutor(agent=agent, tools=tools)
agent_executor.invoke(
{"input": "谁执导了2023年的电影《奥本海默》,他多少岁了?"}
)
css
{'input': '谁执导了2023年的电影《奥本海默》,他多少岁了?', 'output': '克里斯托弗·诺兰(Christopher Nolan)出生于1970年7月30日。截至2023年,他53岁。'}我们没有得到太多输出,但由于我们设置了LangSmith,我们可以轻松地看到发生了什么: smith.langchain.com/public/a89f...
Verbose(详细日志打印)
如果你在Jupyter笔记本中进行原型设计或运行Python脚本,打印出链运行的中间步骤可能会有所帮助。 有许多方法可以以不同程度的详细程度启用打印。 注意:即使启用了LangSmith,这些仍然有效,因此你可以同时打开并运行它们。
set_verbose(True)
设置 verbose 标志将以稍微更易读的格式打印出输入和输出,并将跳过记录某些原始输出(例如 LLM 调用的令牌使用统计信息),以便您可以专注于应用程序逻辑。
python
from langchain.globals import set_verbose
set_verbose(True)
agent_executor = AgentExecutor(agent=agent, tools=tools)
agent_executor.invoke(
{"input": "Who directed the 2023 film Oppenheimer and what is their age in days?"}
)
rust
> Entering new AgentExecutor chain...
Invoking: `tavily_search_results_json` with `{'query': '2023 movie Oppenheimer director'}`
[{'url': 'https://www.imdb.com/title/tt15398776/fullcredits/', 'content': 'Oppenheimer (2023) cast and crew credits, including actors, actresses, directors, writers and more. Menu. ... director of photography: behind-the-scenes Jason Gary ... best boy grip ... film loader Luc Poullain ... aerial coordinator'}]
Invoking: `tavily_search_results_json` with `{'query': 'Christopher Nolan age'}`
[{'url': 'https://www.nme.com/news/film/christopher-nolan-fans-are-celebrating-his-54th-birthday-youve-changed-things-forever-3779396', 'content': "Christopher Nolan is 54 Still my fave bit of Nolan trivia: Joey Pantoliano on creating Ralph Cifaretto's look in The Sopranos: 'The wig I had them build as an homage to Chris Nolan, I like ..."}]2023年的电影《奥本海默》由克里斯托弗·诺兰(Christopher Nolan)执导。他目前54岁。
> Finished chain.
css
{'input': '谁执导了2023年的电影《奥本海默》,他多少岁了?', 'output': '克里斯托弗·诺兰(Christopher Nolan)出生于1970年7月30日。截至2023年,他53岁。'}Debug(调试日志打印)
set_debug(True)
设置全局的 debug 标志将导致所有具有回调支持的 LangChain 组件(链、模型、代理、工具、检索器)打印它们接收的输入和生成的输出。这是最详细的设置,将完全记录原始输入和输出。
python
from langchain.globals import set_debug
# 构建工具代理
agent = create_tool_calling_agent(llm, tools, prompt)
#打印调试日志
set_debug(True)
#不输出详细日志
set_verbose(False)
# 通过传入代理和工具来创建代理执行器
agent_executor = AgentExecutor(agent=agent, tools=tools)
agent_executor.invoke(
{"input": "谁执导了2023年的电影《奥本海默》,他多少岁了?"}
)
css
[chain/start] [chain:AgentExecutor] Entering Chain run with input:
{
"input": "谁执导了2023年的电影《奥本海默》,他多少岁了?"
}
[chain/start] [chain:AgentExecutor > chain:RunnableSequence] Entering Chain run with input:
{
"input": ""
}
[chain/start] [chain:AgentExecutor > chain:RunnableSequence > chain:RunnableAssign<agent_scratchpad>] Entering Chain run with input:
{
"input": ""
}
[chain/start] [chain:AgentExecutor > chain:RunnableSequence > chain:RunnableAssign<agent_scratchpad> > chain:RunnableParallel<agent_scratchpad>] Entering Chain run with input:
{
"input": ""
}
[chain/start] [chain:AgentExecutor > chain:RunnableSequence > chain:RunnableAssign<agent_scratchpad> > chain:RunnableParallel<agent_scratchpad> > chain:RunnableLambda] Entering Chain run with input:
{
"input": ""
}
[chain/end] [chain:AgentExecutor > chain:RunnableSequence > chain:RunnableAssign<agent_scratchpad> > chain:RunnableParallel<agent_scratchpad> > chain:RunnableLambda] [1ms] Exiting Chain run with output:
{
"output": []
}
[chain/end] [chain:AgentExecutor > chain:RunnableSequence > chain:RunnableAssign<agent_scratchpad> > chain:RunnableParallel<agent_scratchpad>] [4ms] Exiting Chain run with output:
{
"agent_scratchpad": []
}
[chain/end] [chain:AgentExecutor > chain:RunnableSequence > chain:RunnableAssign<agent_scratchpad>] [10ms] Exiting Chain run with output:
{
"input": "谁执导了2023年的电影《奥本海默》,他多少岁了?",
"intermediate_steps": [],
"agent_scratchpad": []
}
[chain/start] [chain:AgentExecutor > chain:RunnableSequence > prompt:ChatPromptTemplate] Entering Prompt run with input:
{
"input": "谁执导了2023年的电影《奥本海默》,他多少岁了?",
"intermediate_steps": [],
"agent_scratchpad": []
}
[chain/end] [chain:AgentExecutor > chain:RunnableSequence > prompt:ChatPromptTemplate] [1ms] Exiting Prompt run with output:
[outputs]
[llm/start] [chain:AgentExecutor > chain:RunnableSequence > llm:ChatOpenAI] Entering LLM run with input:
{
"prompts": [
"System: 你是一位得力的助手。\nHuman: 谁执导了2023年的电影《奥本海默》,他多少岁了?"
]
}
[llm/end] [chain:AgentExecutor > chain:RunnableSequence > llm:ChatOpenAI] [1.81s] Exiting LLM run with output:
{
"generations": [
[
{
"text": "",
"generation_info": {
"finish_reason": "tool_calls",
"model_name": "gpt-4o-2024-05-13",
"system_fingerprint": "fp_4e2b2da518"
},
"type": "ChatGenerationChunk",
"message": {
"lc": 1,
"type": "constructor",
"id": [
"langchain",
"schema",
"messages",
"AIMessageChunk"
],
"kwargs": {
"content": "",
"additional_kwargs": {
"tool_calls": [
{
"index": 0,
"id": "call_Rhv2KLzFTU0XhJso5F79EiUp",
"function": {
"arguments": "{"query":"2023年电影《奥本海默》导演"}",
"name": "tavily_search_results_json"
},
"type": "function"
}
]
},
"response_metadata": {
"finish_reason": "tool_calls",
"model_name": "gpt-4o-2024-05-13",
"system_fingerprint": "fp_4e2b2da518"
},
"type": "AIMessageChunk",
"id": "run-cbeb35e8-b4ee-4c78-b663-e338ef90382d",
"tool_calls": [
{
"name": "tavily_search_results_json",
"args": {
"query": "2023年电影《奥本海默》导演"
},
"id": "call_Rhv2KLzFTU0XhJso5F79EiUp",
"type": "tool_call"
}
],
"tool_call_chunks": [
{
"name": "tavily_search_results_json",
"args": "{"query":"2023年电影《奥本海默》导演"}",
"id": "call_Rhv2KLzFTU0XhJso5F79EiUp",
"index": 0,
"type": "tool_call_chunk"
}
],
"invalid_tool_calls": []
}
}
}
]
],
"llm_output": null,
"run": null
}
[chain/start] [chain:AgentExecutor > chain:RunnableSequence > parser:ToolsAgentOutputParser] Entering Parser run with input:
[inputs]
[chain/end] [chain:AgentExecutor > chain:RunnableSequence > parser:ToolsAgentOutputParser] [2ms] Exiting Parser run with output:
[outputs]
[chain/end] [chain:AgentExecutor > chain:RunnableSequence] [1.85s] Exiting Chain run with output:
[outputs]
[tool/start] [chain:AgentExecutor > tool:tavily_search_results_json] Entering Tool run with input:
"{'query': '2023年电影《奥本海默》导演'}"
[tool/end] [chain:AgentExecutor > tool:tavily_search_results_json] [2.06s] Exiting Tool run with output:
"[{'url': 'https://baike.baidu.com/item/奥本海默/58802734', 'content': '《奥本海默》是克里斯托弗·诺兰自编自导的,由基里安·墨菲主演的传记电影,该片于2023年7月21日在北美上映,8月30日在中国内地上映,2024年3月29日在日本上映。该片改编自Kai Bird、Martin J. Sherwin的《美国普罗米修斯:奥本海默的胜与悲》,影片《奥本海默》讲述了美国"原子弹之父"罗伯特· ...'}]"
[chain/start] [chain:AgentExecutor > chain:RunnableSequence] Entering Chain run with input:
{
"input": ""
}
[chain/start] [chain:AgentExecutor > chain:RunnableSequence > chain:RunnableAssign<agent_scratchpad>] Entering Chain run with input:
{
"input": ""
}
[chain/start] [chain:AgentExecutor > chain:RunnableSequence > chain:RunnableAssign<agent_scratchpad> > chain:RunnableParallel<agent_scratchpad>] Entering Chain run with input:
{
"input": ""
}
[chain/start] [chain:AgentExecutor > chain:RunnableSequence > chain:RunnableAssign<agent_scratchpad> > chain:RunnableParallel<agent_scratchpad> > chain:RunnableLambda] Entering Chain run with input:
{
"input": ""
}
[chain/end] [chain:AgentExecutor > chain:RunnableSequence > chain:RunnableAssign<agent_scratchpad> > chain:RunnableParallel<agent_scratchpad> > chain:RunnableLambda] [1ms] Exiting Chain run with output:
[outputs]
[chain/end] [chain:AgentExecutor > chain:RunnableSequence > chain:RunnableAssign<agent_scratchpad> > chain:RunnableParallel<agent_scratchpad>] [4ms] Exiting Chain run with output:
[outputs]
[chain/end] [chain:AgentExecutor > chain:RunnableSequence > chain:RunnableAssign<agent_scratchpad>] [10ms] Exiting Chain run with output:
[outputs]
[chain/start] [chain:AgentExecutor > chain:RunnableSequence > prompt:ChatPromptTemplate] Entering Prompt run with input:
[inputs]
[chain/end] [chain:AgentExecutor > chain:RunnableSequence > prompt:ChatPromptTemplate] [1ms] Exiting Prompt run with output:
[outputs]
[llm/start] [chain:AgentExecutor > chain:RunnableSequence > llm:ChatOpenAI] Entering LLM run with input:
{
"prompts": [
"System: 你是一位得力的助手。\nHuman: 谁执导了2023年的电影《奥本海默》,他多少岁了?\nAI: \nTool: [{"url": "https://baike.baidu.com/item/奥本海默/58802734", "content": "《奥本海默》是克里斯托弗·诺兰自编自导的,由基里安·墨菲主演的传记电影,该片于2023年7月21日在北美上映,8月30日在中国内地上映,2024年3月29日在日本上映。该片改编自Kai Bird、Martin J. Sherwin的《美国普罗米修斯:奥本海默的胜与悲》,影片《奥本海默》讲述了美国\"原子弹之父\"罗伯特· ..."}]"
]
}
[llm/end] [chain:AgentExecutor > chain:RunnableSequence > llm:ChatOpenAI] [1.39s] Exiting LLM run with output:
{
"generations": [
[
{
"text": "2023年电影《奥本海默》的导演是克里斯托弗·诺兰。接下来我将查询他的年龄。",
"generation_info": {
"finish_reason": "tool_calls",
"model_name": "gpt-4o-2024-05-13",
"system_fingerprint": "fp_4e2b2da518"
},
"type": "ChatGenerationChunk",
"message": {
"lc": 1,
"type": "constructor",
"id": [
"langchain",
"schema",
"messages",
"AIMessageChunk"
],
"kwargs": {
"content": "2023年电影《奥本海默》的导演是克里斯托弗·诺兰。接下来我将查询他的年龄。",
"additional_kwargs": {
"tool_calls": [
{
"index": 0,
"id": "call_QuKQUKd6YLsgTgZeYcWpk2lN",
"function": {
"arguments": "{"query":"克里斯托弗·诺兰年龄"}",
"name": "tavily_search_results_json"
},
"type": "function"
}
]
},
"response_metadata": {
"finish_reason": "tool_calls",
"model_name": "gpt-4o-2024-05-13",
"system_fingerprint": "fp_4e2b2da518"
},
"type": "AIMessageChunk",
"id": "run-b7ee6125-1af5-4073-b81e-076a859755bd",
"tool_calls": [
{
"name": "tavily_search_results_json",
"args": {
"query": "克里斯托弗·诺兰年龄"
},
"id": "call_QuKQUKd6YLsgTgZeYcWpk2lN",
"type": "tool_call"
}
],
"tool_call_chunks": [
{
"name": "tavily_search_results_json",
"args": "{"query":"克里斯托弗·诺兰年龄"}",
"id": "call_QuKQUKd6YLsgTgZeYcWpk2lN",
"index": 0,
"type": "tool_call_chunk"
}
],
"invalid_tool_calls": []
}
}
}
]
],
"llm_output": null,
"run": null
}
[chain/start] [chain:AgentExecutor > chain:RunnableSequence > parser:ToolsAgentOutputParser] Entering Parser run with input:
[inputs]
[chain/end] [chain:AgentExecutor > chain:RunnableSequence > parser:ToolsAgentOutputParser] [1ms] Exiting Parser run with output:
[outputs]
[chain/end] [chain:AgentExecutor > chain:RunnableSequence] [1.43s] Exiting Chain run with output:
[outputs]
[tool/start] [chain:AgentExecutor > tool:tavily_search_results_json] Entering Tool run with input:
"{'query': '克里斯托弗·诺兰年龄'}"
[tool/end] [chain:AgentExecutor > tool:tavily_search_results_json] [2.89s] Exiting Tool run with output:
"[{'url': 'https://baike.baidu.com/item/克里斯托弗·诺兰/5306405', 'content': '克里斯托弗·诺兰(Christopher Nolan),1970年7月30日出生于英国伦敦,导演、编剧、制片人。1998年4月24日克里斯托弗·诺兰拍摄的首部故事片《追随》在旧金山电影节上映。2000年,克里斯托弗·诺兰凭借着他的《记忆碎片》为他获得第74届奥斯卡的提名。2005年,执导《蝙蝠侠》三部曲系列首部电影 ...'}]"
[chain/start] [chain:AgentExecutor > chain:RunnableSequence] Entering Chain run with input:
{
"input": ""
}
[chain/start] [chain:AgentExecutor > chain:RunnableSequence > chain:RunnableAssign<agent_scratchpad>] Entering Chain run with input:
{
"input": ""
}
[chain/start] [chain:AgentExecutor > chain:RunnableSequence > chain:RunnableAssign<agent_scratchpad> > chain:RunnableParallel<agent_scratchpad>] Entering Chain run with input:
{
"input": ""
}
[chain/start] [chain:AgentExecutor > chain:RunnableSequence > chain:RunnableAssign<agent_scratchpad> > chain:RunnableParallel<agent_scratchpad> > chain:RunnableLambda] Entering Chain run with input:
{
"input": ""
}
[chain/end] [chain:AgentExecutor > chain:RunnableSequence > chain:RunnableAssign<agent_scratchpad> > chain:RunnableParallel<agent_scratchpad> > chain:RunnableLambda] [1ms] Exiting Chain run with output:
[outputs]
[chain/end] [chain:AgentExecutor > chain:RunnableSequence > chain:RunnableAssign<agent_scratchpad> > chain:RunnableParallel<agent_scratchpad>] [4ms] Exiting Chain run with output:
[outputs]
[chain/end] [chain:AgentExecutor > chain:RunnableSequence > chain:RunnableAssign<agent_scratchpad>] [9ms] Exiting Chain run with output:
[outputs]
[chain/start] [chain:AgentExecutor > chain:RunnableSequence > prompt:ChatPromptTemplate] Entering Prompt run with input:
[inputs]
[chain/end] [chain:AgentExecutor > chain:RunnableSequence > prompt:ChatPromptTemplate] [2ms] Exiting Prompt run with output:
[outputs]
[llm/start] [chain:AgentExecutor > chain:RunnableSequence > llm:ChatOpenAI] Entering LLM run with input:
{
"prompts": [
"System: 你是一位得力的助手。\nHuman: 谁执导了2023年的电影《奥本海默》,他多少岁了?\nAI: \nTool: [{"url": "https://baike.baidu.com/item/奥本海默/58802734", "content": "《奥本海默》是克里斯托弗·诺兰自编自导的,由基里安·墨菲主演的传记电影,该片于2023年7月21日在北美上映,8月30日在中国内地上映,2024年3月29日在日本上映。该片改编自Kai Bird、Martin J. Sherwin的《美国普罗米修斯:奥本海默的胜与悲》,影片《奥本海默》讲述了美国\"原子弹之父\"罗伯特· ..."}]\nAI: 2023年电影《奥本海默》的导演是克里斯托弗·诺兰。接下来我将查询他的年龄。\nTool: [{"url": "https://baike.baidu.com/item/克里斯托弗·诺兰/5306405", "content": "克里斯托弗·诺兰(Christopher Nolan),1970年7月30日出生于英国伦敦,导演、编剧、制片人。1998年4月24日克里斯托弗·诺兰拍摄的首部故事片《追随》在旧金山电影节上映。2000年,克里斯托弗·诺兰凭借着他的《记忆碎片》为他获得第74届奥斯卡的提名。2005年,执导《蝙蝠侠》三部曲系列首部电影 ..."}]"
]
}
[llm/end] [chain:AgentExecutor > chain:RunnableSequence > llm:ChatOpenAI] [885ms] Exiting LLM run with output:
{
"generations": [
[
{
"text": "克里斯托弗·诺兰(Christopher Nolan)出生于1970年7月30日。根据当前时间(2023年),他53岁。",
"generation_info": {
"finish_reason": "stop",
"model_name": "gpt-4o-2024-05-13",
"system_fingerprint": "fp_4e2b2da518"
},
"type": "ChatGenerationChunk",
"message": {
"lc": 1,
"type": "constructor",
"id": [
"langchain",
"schema",
"messages",
"AIMessageChunk"
],
"kwargs": {
"content": "克里斯托弗·诺兰(Christopher Nolan)出生于1970年7月30日。根据当前时间(2023年),他53岁。",
"response_metadata": {
"finish_reason": "stop",
"model_name": "gpt-4o-2024-05-13",
"system_fingerprint": "fp_4e2b2da518"
},
"type": "AIMessageChunk",
"id": "run-0cc2156a-5a9d-41c2-b8bc-ecb2a291f408",
"tool_calls": [],
"invalid_tool_calls": []
}
}
}
]
],
"llm_output": null,
"run": null
}
[chain/start] [chain:AgentExecutor > chain:RunnableSequence > parser:ToolsAgentOutputParser] Entering Parser run with input:
[inputs]
[chain/end] [chain:AgentExecutor > chain:RunnableSequence > parser:ToolsAgentOutputParser] [1ms] Exiting Parser run with output:
[outputs]
[chain/end] [chain:AgentExecutor > chain:RunnableSequence] [914ms] Exiting Chain run with output:
[outputs]
[chain/end] [chain:AgentExecutor] [9.25s] Exiting Chain run with output:
{
"output": "克里斯托弗·诺兰(Christopher Nolan)出生于1970年7月30日。根据当前时间(2023年),他53岁。"
}
css
{'input': '谁执导了2023年的电影《奥本海默》,他多少岁了?', 'output': '克里斯托弗·诺兰(Christopher Nolan)出生于1970年7月30日。根据当前时间(2023年),他53岁。'}