天池AFAC赛道四-智能体赋能的金融多模态报告自动化生成part1
- [0 赛题](#0 赛题)
- [1 整体框架](#1 整体框架)
- [2 数据获取源](#2 数据获取源)
-
- [2.0 数据存储结构](#2.0 数据存储结构)
- [2.1 获取公司的基本信息和近期股票价格](#2.1 获取公司的基本信息和近期股票价格)
-
- [2.1(a) 观察网页结构](#2.1(a) 观察网页结构)
- [2.1(b) 具体数据获取](#2.1(b) 具体数据获取)
- [2.2 股本结构数据获取](#2.2 股本结构数据获取)
-
- [2.2(a) 网页结构观察](#2.2(a) 网页结构观察)
- 2.2(b)具体数据获取
- [2.3 三大财务报表](#2.3 三大财务报表)
- [2.4 港股财务分析数据(ROE)等](#2.4 港股财务分析数据(ROE)等)
- [2.5 财务信息摘要](#2.5 财务信息摘要)
-
- 2.5(a)网页结构观察
- [2.5(b) 具体数据获取](#2.5(b) 具体数据获取)
- [2.6 行业对比数据获取](#2.6 行业对比数据获取)
-
- [2.6(a) 网页结构观察](#2.6(a) 网页结构观察)
- [2.6(b) 具体数据获取](#2.6(b) 具体数据获取)
- [2.7 未来的机构评级数据](#2.7 未来的机构评级数据)
-
- 2.7(a)网页结构观察
- [2.7(b) 具体数据获取](#2.7(b) 具体数据获取)
- [2.8 未来股价预测数据](#2.8 未来股价预测数据)
- [2.9 行业研报数据](#2.9 行业研报数据)
-
- 2.9(a)相似行业判断
- [2.9(b) 获取行业报告列表里面的标题、url](#2.9(b) 获取行业报告列表里面的标题、url)
- [2.9(c) 研报具体内容获取](#2.9(c) 研报具体内容获取)
- [2.10 宏观数据](#2.10 宏观数据)
- [3 数据存储和加载示例](#3 数据存储和加载示例)
-
- [3.1 公司研报](#3.1 公司研报)
- [3.2 行业研报](#3.2 行业研报)
- [3.3 宏观研报](#3.3 宏观研报)
0 赛题
本任务需要参赛团队研发一个能够自动撰写三大类季度/年度跟踪型金融研报(宏观经济/策略研报、行业/子行业研报、公司/个股研报)的智能Agent系统,需实现生成研报质量及构建使用技术两部分的目标。
生成研报应满足:
- 多模态呈现:包含图表(如股票/指数走势图、关键金融、宏观或行业指标对比图、财务报表表格等)与文字说明,图文一致;
- 专业性和深度:行业术语规范、分析方法应用合理,掌握基本财务常识,避免常识性错误,分析具备一定原创性,避免机械摘录原始资料;
- 数据融合与事实溯源:整合实时权威数据源(如国家统计局、证券交易所、主流新闻),为所有数据与事实提供明确的来源引用。此外,报告内容应仅限于上市公司,数据来源应仅限于网络免费公开可获取数据和信息,不可直接接入付费第三方整理好的数据API;
- 格式与逻辑:满足中国证券业协会《发布证券研究报告暂行规定》排版与披露要求,论点-论据链完整,章节衔接流畅
具体任务要求:
- 生成公司/个股研报 应能够自动抽取三大会计报表与股权结构,输出主营业务、核心竞争力与行业地位;支持财务比率计算与行业对比分析(如ROE分解、毛利率、现金流匹配度),结合同行企业进行横向竞争分析;构建估值与预测模型,模拟关键变量变化对财务结果的影响(如原材料成本、汇率变动);结合公开数据与管理层信息,评估公司治理结构与发展战略,提出投资建议与风险提醒
- 行业/子行业研报 应能够聚合行业发展相关数据(协会年报、企业财报等),输出行业生命周期与结构解读(如集中度、产业链上下游分析);融合趋势分析与外部变量预测能力(如政策影响、技术演进),支持3年以上的行业情景模拟;提供行业进入与退出策略建议,支持关键变量(如上游原材料价格)敏感性分析;自动生成图表辅助说明行业规模变动、竞争格局等核心要素
- 宏观经济/策略研报 应能够自动抽取与呈现宏观经济核心指标(GDP、CPI、利率、汇率等),对政策报告与关键口径进行解读;构建政策联动与区域对比分析模型,解释宏观变量间的交互影响(如降准对出口与CPI的传导路径);支持全球视野的模拟建模(如美联储利率变动对全球资本流动的影响);提供对潜在"灰犀牛"事件的风险预警机制与指标设计。
Agent系统技术应满足:
1.多Agent协同:通过多Agent分工与链式推理完成端到端流程,自动拆解任务并分阶段调用功能模块(如信息检索、图表生成、内容撰写与审查),包含自检与反馈循环;
2.任务泛化能力:对不同行业、公司、宏观环境具备稳健性;
3.落地潜力:在实际业务场景下有落地可能性,具备可接受的生成效率及部署复杂度;
4.创新性:鼓励前沿相关技术(如MCP、A2A、工具调用、RAG)的使用。
5.开源限制:只能使用开源的模型及其API,不能使用闭源模型以及AI搜索接口
初赛赛题
公司:商汤科技(00020.HK)
行业:智能风控&大数据征信服务
宏观:生成式AI基建与算力投资趋势(2023-2026)
复赛赛题
公司:4Paradigm(06682.HK)
行业:中国智能服务机器人产业
宏观:国家级"人工智能+"政策效果评估 (2023-2025)
官方baseline
DataWhale的baseline:https://www.datawhale.cn/learn/summary/174
1 整体框架
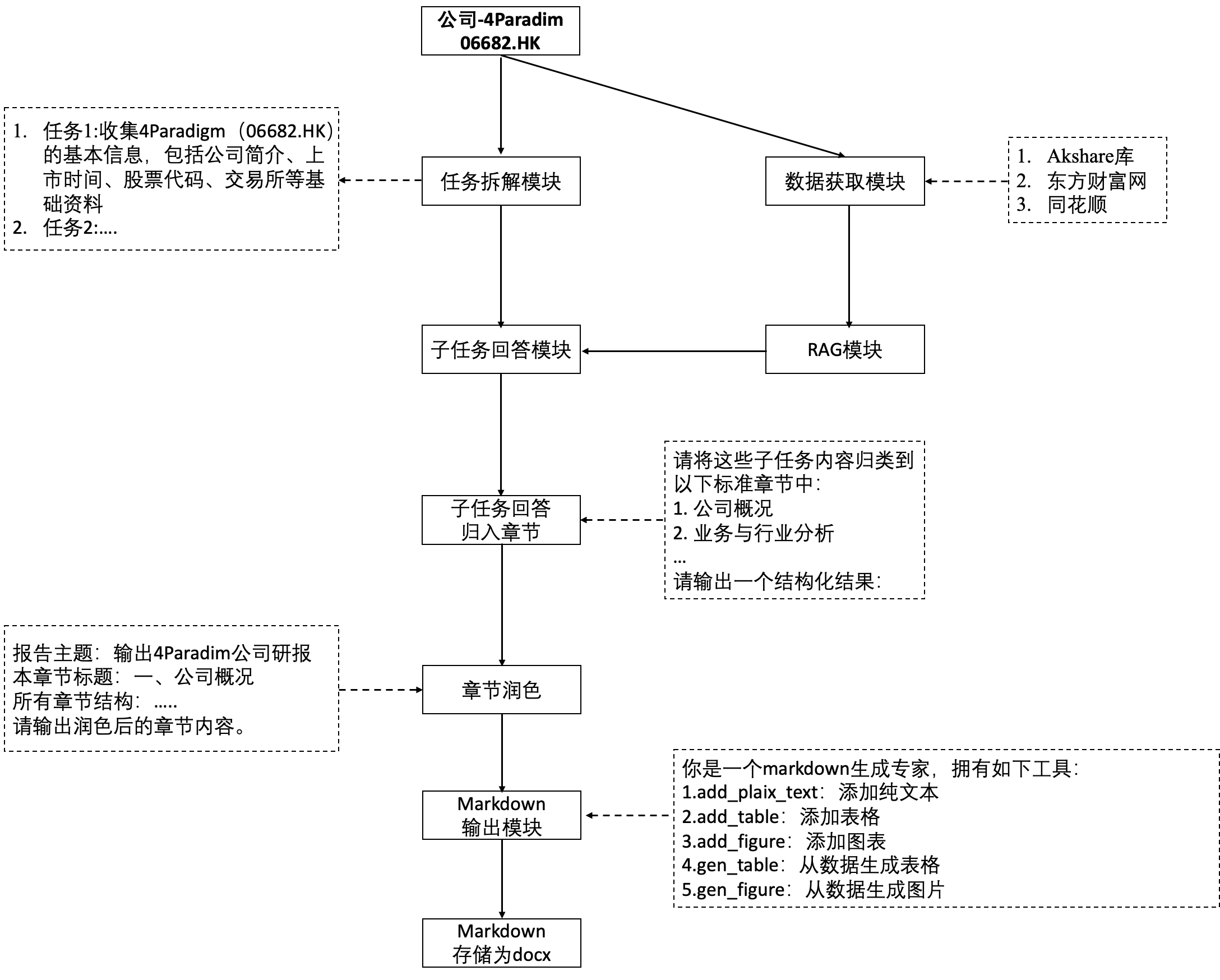
2 数据获取源
比赛没有提供数据,这个比赛的门槛主要是在数据获取上(如果没有金融背景,可能不知道从哪里获取对应的数据,有哪些数据,每个数据是什么含义)。官方的baseline里面提供了一些数据获取的源方式(使用akshare、爬取东方财富、爬取同花顺)等。
2.0 数据存储结构
为了便于存储和读取,使用3个全局变量存储,分别存值、类型和描述
python
# 信息获取后,数据存储到dict里面
collected_data_value = {} # 存储数据
collected_data_type = {} # 存储数据类型(是str、dict还是一个dataframe)
collected_data_desc = {} # 存储对数据的表述摘要,便于后面RAG存储和加载函数:
python
def save_extracted_info(data_value,
data_type,
data_desc):
global collected_data_value, collected_data_type, collected_data_desc
if data_type=='dict': # 普通的dict直接放进去就可以了
collected_data_value.update(data_value)
# 注意提取出data_value里面的key作为后面的数据类型和描述的key
for key in data_value.keys():
collected_data_type[key] = 'str'
collected_data_desc[key] = str(key)
elif data_type=='dict_dataframe':
collected_data_value.update(data_value)
# 注意提取出data_value里面的key作为后面的数据类型和描述的key
for key in data_value.keys():
collected_data_type[key] = 'dataframe'
collected_data_desc[key] = data_desc
elif data_type=='dict_special_list': # 最复杂的一种,这个的data_value是一个list
for i in range(len(data_value['issue'])):
issue = data_value['issue'][i]
title = data_value['title'][i]
ps = data_value['ps'][i]
dataframe = data_value['table'][i]
description = f"{issue} - {title} - ({ps})"
if '行业分类' in title:
key = str(issue) + '行业财务数据'
else:
if '价值' in title or '表现' in title:
key = str(issue) + '行业价值表现数据'
else:
key = str(issue) + '行业财务经营数据'
collected_data_value[key] = dataframe
collected_data_type[key] = 'dataframe'
collected_data_desc[key] = description
import pickle
def save_collected_data_to_local():
with open('collected_data_value.pkl', 'wb') as f:
pickle.dump(collected_data_value, f)
with open('collected_data_type.pkl', 'wb') as f:
pickle.dump(collected_data_type, f)
with open('collected_data_desc.pkl', 'wb') as f:
pickle.dump(collected_data_desc, f)
print("数据已成功保存到本地。")
def load_collected_data_from_local():
global collected_data_value, collected_data_type, collected_data_desc
try:
with open('collected_data_value.pkl', 'rb') as f:
collected_data_value = pickle.load(f)
with open('collected_data_type.pkl', 'rb') as f:
collected_data_type = pickle.load(f)
with open('collected_data_desc.pkl', 'rb') as f:
collected_data_desc = pickle.load(f)
print("数据已从本地加载。")
except FileNotFoundError:
print("未找到本地数据文件,请先运行保存操作。")2.1 获取公司的基本信息和近期股票价格
2.1(a) 观察网页结构
- 主要获取的数据:公司名称、主营业务、所属行业、公司简介、近半年股价
python
def get_company_info_util_ths(url):
"""
通过同花顺获取目标公司基本信息
"""
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
main_business = soup.find('strong', class_='hltip fl', text=lambda x: '业务' in x if x else False)
if main_business:
main_business_info = main_business.find_next('span').text
else:
main_business_info="NULL"
main_field = soup.find('strong', class_='hltip fl', text=lambda x: '行业' in x if x else False)
if main_field:
main_field_info = main_field.find_next('span').text
else:
main_field_info="NULL"
# 公司简介 company_intro
company_intro = ''
all_tr = soup.find_all('tr')
for tr in all_tr:
# 如果tr里面有strong才看,否则跳过
strong = tr.find('strong')
if strong:
# 如果strong里面有公司简介才看,否则跳过
if '公司简介' in strong.text:
p = tr.find('p')
company_intro = p.text.strip() if p else ''
else:
continue
if company_intro:
company_intro_info = company_intro if company_intro else "NULL"
else:
company_intro_info = "NULL"
# 公司名称 company_name
company_name = soup.find('strong', class_='hltip fl', text=lambda x: '公司名称' in x if x else False)
if company_name:
company_name_info = company_name.find_next('span').text
else:
company_name_info = "NULL"
# 公司英文名称 company_en_name
company_en_name = soup.find('strong', class_='hltip fl', text=lambda x: '英文名称' in x if x else False)
if company_en_name:
company_en_name_info = company_en_name.find_next('span').text
else:
company_en_name_info = "NULL"
# 结果返回
company_info = {
'公司名称': company_name_info,
'英文名称': company_en_name_info,
'主营业务': main_business_info,
'所属行业': main_field_info,
'公司简介': company_intro_info
}
return company_info
except Exception as e:
print(f"Error fetching company info from {url}: {e}")
return {
'公司名称': "NULL",
'英文名称': "NULL",
'主营业务': "NULL",
'所属行业': "NULL",
'公司简介': "NULL"
}
def get_company_profile_ths_cn(symbol):
"""
# https://basic.10jqka.com.cn/000066/company.html
获取中国大陆上市公司的基本信息,来自同花顺
:param symbol: 6位股票代码,不带交易所代码
:return: 公司基本信息dataframe,公司名称、所属行业、主营业务、公司简介,没有的为空
"""
symbol = symbol.upper()
symbol = ''.join(filter(str.isdigit, symbol)) # 只保留数字
if len(symbol) > 6:
symbol = symbol[-6:]
url = f"https://basic.10jqka.com.cn/{symbol}/company.html"
company_info = get_company_info_util_ths(url)
return company_info
def get_company_profile_ths_hk(symbol):
"""
# https://basic.10jqka.com.cn/HK0020/company.html
# 获取香港上市公司的基本信息,来自同花顺
# symbol需要是后4位,前面加上'HK'前缀
"""
# 去掉symbol里面的字母,判断symbol位数,取最后4位
# symbol的字母可能大写可能小写
symbol = symbol.upper()
symbol = ''.join(filter(str.isdigit, symbol)) # 只保留数字
if len(symbol) > 4:
symbol = symbol[-4:]
url = f"https://basic.10jqka.com.cn/HK{symbol}/company.html"
company_info = get_company_info_util_ths(url)
return company_info
def get_cn_company_profile_ak(symbol):
"""
获取中国上市公司的基本信息
:param symbol: 6位股票代码,不带交易所代码
:return: 公司基本信息dataframe
# ['股票代码', '主营业务', '产品类型', '产品名称', '经营范围']
"""
symbol = symbol.upper()
symbol = ''.join(filter(str.isdigit, symbol)) # 只保留数字
if len(symbol) > 6:
symbol = symbol[-6:]
company_profile = ak.stock_zyjs_ths(symbol=symbol)
return company_profile
def get_hk_company_profile_ak(symbol):
"""
获取香港上市公司的基本信息
:param symbol: 5位股票代码
:return: 公司基本信息dataframe
#['公司名称', '英文名称', '注册地', '注册地址', '公司成立日期', '所属行业', '董事长', '公司秘书', '员工人数',
'办公地址', '公司网址', 'E-MAIL', '年结日', '联系电话', '核数师', '传真', '公司介绍']
"""
symbol = symbol.upper()
symbol = ''.join(filter(str.isdigit, symbol)) # 只保留数字
if len(symbol) > 4:
symbol = symbol[-4:]
company_profile = ak.stock_hk_company_profile_em(symbol='0'+symbol)
return company_profile2.1(b) 具体数据获取
- 从网上获取到信息后,提取出来公司基本信息,同时从akshare获取公司近期股票价格数据(akshare的用法可以参考官方文档)
python
def extract_company_basic_info(stock_type,stock_code):
"""
输入股票类型和股票代码,提取公司的基本信息
Args:
stock_type (str): 股票类型,'A股' 或 '港股'
stock_code (str): 股票代码,A股为6位数字,港股为4位数字
Returns:
Dict[str, Any]: 包含以下键的字典:
data_value (Dict[str, str]): 公司基本信息数据值,包括公司名称、英文名称、主营业务、所属行业和公司简介
data_type (str): 数据类型
data_desc (str): 数据内容描述,说明返回的数据包含哪些信息
"""
if stock_type == '港股':
hk_code = 'HK' + stock_code
company_info = get_company_profile_ths_hk(hk_code)
else:
a_code = stock_code
company_info = get_company_profile_ths_cn(a_code)
return {
'data_value': {
"公司名称": company_info['公司名称'],
"英文名称": company_info['英文名称'],
"主营业务": company_info['主营业务'],
"所属行业": company_info['所属行业'],
"公司简介": company_info['公司简介']
},
'data_type': 'dict',
'data_desc': '公司基本信息,包括公司名称、英文名称、主营业务、所属行业和公司简介'
}
# 提取公司基本信息
# company_basic_info = extract_company_basic_info(stock_type, stock_code)
## 获取最近的几个月,月度的股票数据
def get_date_range_months(months_back=6):
end_date = datetime.today().replace(day=1) # 当月1号
start_date = end_date - timedelta(days=30*months_back)
start_date = start_date.replace(day=1) # 第一天
return {
"start_date": start_date.strftime("%Y%m%d"),
"end_date": end_date.strftime("%Y%m%d")
}
def extract_stock_info(stock_type, stock_code,months_back=6):
"""
提取公司股票的近期基本价格和成交信息,默认提取最近6个月的月度数据;
返回值是一个字典,包含日期、开盘、收盘、最高、最低、成交量、成交额、振幅、涨跌幅、涨跌额和换手率等信息。
返回结果的价格,对于港股单位是港元,对于A股单位是人民币。
Args:
stock_type (str): 股票类型,'A股' 或 '港股'
stock_code (str): 股票代码,A股为6位数字,港股为4位数字
months_back (int): 回溯的月数,默认为6个月
Returns:
Dict[str, Any]: 包含以下键的字典:
data_name (Dict[str, list]): 存放数据值,包含日期、开盘、收盘、最高、最低、成交量、成交额、振幅、涨跌幅、涨跌额和换手率
data_type (Dict[str, str]): 数据类型
data_desc (Dict[str, str]): 包含上述信息的内容描述
"""
start_date = get_date_range_months(months_back)["start_date"]
end_date = get_date_range_months(months_back)["end_date"]
if stock_type == '港股':
hk_code = 'HK' + stock_code
stock_info = get_hk_stock_info(hk_code, period="monthly", start_date=start_date, end_date=end_date)
else:
a_code = stock_code
stock_info = get_cn_stock_info(a_code, period="monthly", start_date=start_date, end_date=end_date)
return {
'data_value': {
"股票近期价格和交易信息": stock_info
},
'data_type': 'dict_dataframe',
'data_desc': '包含股票的日期、开盘价、收盘价、最高价、最低价、成交量、成交额、振幅、涨跌幅、涨跌额和换手率等信息,通过key值访问list数据'
}
# 提取股票信息
# stock_info = extract_stock_info(stock_type, stock_code)2.2 股本结构数据获取
- 对于akshare里面没有提供的数据,在ths里面存在equity.html
2.2(a) 网页结构观察
python
def get_capital_structure_util(url):
try:
# 获取股本结构
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response_eq = requests.get(url, headers=headers)
soup_eq = BeautifulSoup(response_eq.content, 'html.parser')
# div = <div class="m_box gqtz">下面有股本的表格
equity_table = soup_eq.find('div', class_='m_box gqtz')
# 把股本表格进行解析,包括表头,只有表头列,没有表头行
# 这个表不规范,第一行的tr里面都是th的形式
equity_rows = equity_table.find_all('tr')
# 假设 equity_table 是你已经提取到的 div 包含的表格部分
equity_rows = equity_table.find_all('tr')
# 用于存储最终结果
table_data = []
# 第一行处理:提取"公告日期"和各个日期
first_row = equity_rows[0]
# 获取第一个 tr 的原始 HTML 字符串
row_html = str(first_row)
# 使用正则提取所有的日期(格式为 YYYY-MM-DD)
dates = re.findall(r'>(\d{4}-\d{2}-\d{2})\n<', row_html)
# 添加表头
header = first_row.find('th').get_text(strip=True) if first_row.find('th') else '时间' + dates
table_data.append(header)
# 处理后续每一行(每个指标)
for row in equity_rows[1:]:
cells = row.find_all(['th', 'td'])
row_data = [cell.get_text(strip=True) for cell in cells]
# 确保长度一致,补空
while len(row_data) < len(dates) + 1:
row_data.append('')
table_data.append(row_data)
# # 打印结果查看
# for row in table_data:
# print(row)
data_dict = {}
for row in table_data:
key = row[0] # 指标名,如"总股本"
values = row[1:] # 对应值
data_dict[key] = values
df = pd.DataFrame(data_dict)
return df
except Exception as e:
print(f"Error fetching capital structure data: {e}")
return pd.DataFrame() # 返回空的DataFrame以表示失败
def get_capital_structure_cn_ths(symbol):
"""
# https://basic.10jqka.com.cn/000066/equity.html
获取中国大陆上市公司的基本信息,来自同花顺
:param symbol: 6位股票代码,不带交易所代码
:return: 公司基本信息dataframe,公司名称、所属行业、主营业务、公司简介,没有的为空
"""
symbol = symbol.upper()
symbol = ''.join(filter(str.isdigit, symbol)) # 只保留数字
if len(symbol) > 6:
symbol = symbol[-6:]
url = f"https://basic.10jqka.com.cn/{symbol}/equity.html"
company_info = get_capital_structure_util(url)
return company_info
def get_capital_structure_hk_ths(symbol):
"""
# https://basic.10jqka.com.cn/HK0020/equity.html
# 获取香港上市公司的基本信息,来自同花顺
# symbol需要是后4位,前面加上'HK'前缀
"""
# 去掉symbol里面的字母,判断symbol位数,取最后4位
# symbol的字母可能大写可能小写
symbol = symbol.upper()
symbol = ''.join(filter(str.isdigit, symbol)) # 只保留数字
if len(symbol) > 4:
symbol = symbol[-4:]
url = f"https://basic.10jqka.com.cn/HK{symbol}/equity.html"
company_info = get_capital_structure_util(url)
return company_info2.2(b)具体数据获取
python
def extract_capital_structure(stock_type, stock_code):
"""
提取股本结构信息
Args:
stock_type (str): 股票类型,'A股' 或 '港股'
stock_code (str): 股票代码,A股为6位数字,港股为4位数字
Returns:
Dict[str, Any]: 包含以下键的字典:
data_value (Dict[str, list]): 股本结构数据值,港股的包括总股本、港股总股本、优先股和变动日期;A股包括总股本、A股总股本、流通A股、限售A股和变动原因
data_type (str): 数据类型
data_desc (str): 数据内容描述,说明返回的数据包含哪些信息
"""
if stock_type == '港股':
hk_code = 'HK' + stock_code
captial_structure = get_capital_structure_hk_ths(hk_code)
return {
'data_value': {
"港股股本": captial_structure,
},
'data_type': 'dict_dataframe',
'data_desc': '对应港股的股本结构信息,包括总股本、港股总股本、优先股和变动日期'
}
else:
a_code = stock_code
cn_captial_structure = get_capital_structure_cn_ths(a_code)
# return {
# "总股本(股)": cn_captial_structure['总股本(股)'],
# "A股总股本(股)": cn_captial_structure['A股总股本(股)'],
# "流通A股(股)": cn_captial_structure['流通A股(股)'],
# "限售A股(股)": cn_captial_structure['限售A股(股)'],
# "变动原因": cn_captial_structure['变动原因']
# }
return {
'data_value': {
"A股股本": cn_captial_structure
},
'data_type': 'dict_dataframe',
'data_desc': '对应A股的股本结构信息,包括总股本、A股总股本、流通A股、限售A股和变动原因'
}
# 提取股本结构信息
# capital_structure = extract_capital_structure(stock_type, stock_code)2.3 三大财务报表
- 这些数据可以直接使用akshare获取
python
# ##资产负债表:反映企业在特定日期的财务状况,包括资产、负债和所有者权益。
# ##利润表:展示企业在一定会计期间的经营成果,反映企业的收入、费用和利润。
# ##现金流量表:记录企业在特定期间内的现金流入和流出,反映企业的现金流动情况。
# TODO--这个是个大表,看一下到底需要哪些列的信息
def extract_financial_statements(stock_type, stock_code):
"""
提取年度三大会计报表:资产负债表、利润表和现金流量表
返回值是一个字典,包含三个DataFrame,分别对应资产负债表、利润表和现金流量表。
Args:
stock_type (str): 股票类型,'A股' 或 '港股'
stock_code (str): 股票代码,A股为6位数字,港股为4位数字
Returns:
Dict[str, Any]: 包含以下键的字典:
data_value (Dict[str, pd.DataFrame]): 包含三个DataFrame的字典,分别是资产负债表、利润表和现金流量表
data_type (str): 数据类型
data_desc (str): 数据内容描述,说明返回的数据包含哪些信息
"""
if stock_type == '港股':
hk_code = 'HK' + stock_code
hk_code = hk_code.upper()
hk_code = ''.join(filter(str.isdigit, hk_code)) # 只保留数字
if len(hk_code) > 4:
hk_code = hk_code[-4:]
hk_code = '0' + hk_code # 确保是5位数字
stock_financial_bi_df = ak.stock_financial_hk_report_em(stock=hk_code, symbol="资产负债表", indicator="年度")
stock_benefit_bi_df = ak.stock_financial_hk_report_em(stock=hk_code, symbol="利润表", indicator="年度")
stock_cash_bi_df = ak.stock_financial_hk_report_em(stock=hk_code, symbol="现金流量表", indicator="年度")
else:
a_code = stock_code
stock_financial_bi_df = ak.stock_financial_debt_ths(symbol=a_code, indicator="按年度")
stock_benefit_bi_df = ak.stock_financial_benefit_ths(symbol=a_code, indicator="按年度")
stock_cash_bi_df = ak.stock_financial_cash_ths(symbol=a_code, indicator="按年度")
return {
'data_value': {
"资产负债表": stock_financial_bi_df,
"利润表": stock_benefit_bi_df,
"现金流量表": stock_cash_bi_df
},
'data_type': 'dict_dataframe',
'data_desc': '包含对应股票代码的会计报表'
}
# 提取年度三大会计报表
# financial_statements = extract_financial_statements(stock_type, stock_code)2.4 港股财务分析数据(ROE)等
- 这部分发现akshare上有相关数据可以获取到
python
def extract_hk_financial_analysis(stock_type, stock_code):
"""
提取港股的财务指标分析数据
Args:
stock_type (str): 股票类型,'港股'
stock_code (str): 港股股票代码,4位数字
Returns:
Dict[str, Any]: 包含以下键的字典:
data_value (Dict[str, pd.DataFrame]): 港股财务分析指标数据,包含ROE等指标
data_type (str): 数据类型
data_desc (str): 数据内容描述,说明返回的数据包含哪些财务指标分析数据
"""
if stock_type == '港股':
hk_code = 'HK' + stock_code
hk_code = hk_code.upper()
hk_code = ''.join(filter(str.isdigit, hk_code)) # 只保留数字
if len(hk_code) > 4:
hk_code = hk_code[-4:]
hk_code = '0' + hk_code # 确保是5位数字
stock_financial_analysis_indicator_em_df = ak.stock_financial_hk_analysis_indicator_em(symbol=hk_code, indicator="年度")
return {
'data_value': {'港股财务分析指标数据':stock_financial_analysis_indicator_em_df},
'data_type': 'dict_dataframe',
'data_desc': '港股的财务指标分析数据,包括ROE等指标'
}
else:
return None
# 提取港股的财务指标分析数据
# hk_financial_analysis = extract_hk_financial_analysis(stock_type, stock_code)2.5 财务信息摘要
- 在ths上发现很多公司页面上会有自己写的对自己财报的分析总结和展望
2.5(a)网页结构观察
python
def get_company_finance_summary_hk(symbol):
"""
港股是返回2024年的摘要
"""
symbol = symbol.upper()
symbol = ''.join(filter(str.isdigit, symbol)) # 只保留数字
if len(symbol) > 4:
symbol = symbol[-4:]
url = f"https://basic.10jqka.com.cn/HK{symbol}/business.html"
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response_stock_summary = requests.get(url, headers=headers)
soup_stock_summary = BeautifulSoup(response_stock_summary.content, 'html.parser')
stock_summary_info = soup_stock_summary.find('p', class_='f14').get_text(strip=True, separator=' ')[:-5]
stock_summary_info_remain = soup_stock_summary.find('span', class_='text-remain').get_text(strip=True, separator=' ')
stock_summary_info = stock_summary_info + ' ' + stock_summary_info_remain
date = soup_stock_summary.find('a', class_='businessTab').get_text(strip=True) # 日期
return {
date: stock_summary_info
}
except Exception as e:
print(f"Error fetching company finance summary: {e}")
return {}
def get_company_finance_summary_cn(symbol):
"""
cn股票通常返回近3次的摘要
"""
try:
symbol = symbol.upper()
symbol = ''.join(filter(str.isdigit, symbol)) # 只保留数字
if len(symbol) > 6:
symbol = symbol[-6:]
url = f"https://basic.10jqka.com.cn/{symbol}/operate.html"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response_stock_summary = requests.get(url, headers=headers)
soup_stock_summary = BeautifulSoup(response_stock_summary.content, 'html.parser')
stock_summary_divs = soup_stock_summary.select('div[class="m_tab_content m_tab_content2"]')#.find_all('div', class_='m_tab_content m_tab_content2')
stock_summary_data = []
for div in stock_summary_divs:
# 获取标题
content = div.find('p', class_='f14 none clearfix pr').get_text(strip=True, separator=' ')
# 添加到列表
stock_summary_data.append(
content
)
date_div = soup_stock_summary.select('div[class="m_tab"]')#.find_all('a',class_='operateTab')
data_a_list = date_div[0].find_all('a', class_='operateTab')
date_list = []
for a in data_a_list:
# 获取日期
date = a.get_text(strip=True)
# 添加到列表
date_list.append(
date
)
result_dict = {}
for i, date in enumerate(date_list):
if i < len(stock_summary_data):
result_dict[date] = stock_summary_data[i]
else:
result_dict[date] = ""
return result_dict
except Exception as e:
print(f"Error fetching company finance summary: {e}")
return {}2.5(b) 具体数据获取
python
def extract_financial_summary(stock_type, stock_code):
"""
提取公司财务摘要信息
Args:
stock_type (str): 股票类型,'A股' 或 '港股'
stock_code (str): 股票代码,A股为6位数字,港股为4位数字
Returns:
Dict[str, Any]: 包含以下键的字典:
data_value (Dict[str, str]): 公司财务摘要信息
data_type (str): 数据类型
data_desc (str): 数据内容描述,说明返回的数据包含哪些信息
"""
if stock_type == '港股':
hk_code = 'HK' + stock_code
official_finance_summary = get_company_finance_summary_hk(hk_code)
else:
a_code = stock_code
official_finance_summary = get_company_finance_summary_cn(a_code)
return {
'data_value': {
"财务摘要": official_finance_summary
},
'data_type': 'dict',
'data_desc': '公司财务信息的摘要分析信息,包括业绩回顾、展望和竞争力分析等内容'
}
# 提取财务摘要信息
# financial_summary = extract_financial_summary(stock_type, stock_code)2.6 行业对比数据获取
- ths上每个公司自己的页面上有行业对比的页面,包含主要的财务指标数据
2.6(a) 网页结构观察
- 注意有的公司有2期,有的只有1期
python
def get_hk_company_field_compare(symbol):
symbol = symbol.upper()
symbol = ''.join(filter(str.isdigit, symbol)) # 只保留数字
if len(symbol) > 4:
symbol = symbol[-4:]
url = f"https://basic.10jqka.com.cn/HK{symbol}/field.html"
# 获取页面内容
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=header)
soup_field_hk = BeautifulSoup(response.content, 'html.parser')
data_list = []
# 最上面的,HK的是价值表现
# <p class="threecate f14 fl tip">
title_and_filed_0 = soup_field_hk.find('p', class_='threecate f14 fl tip').get_text(strip=True, separator=' ') # 标题和行业信息
#<div class="field_date1" id="dateSelect">
field_date_div = soup_field_hk.find('div', class_='field_date1')
# 获取里面的<a>的tag="0"和tag="1"的文本
issue_0 = field_date_div.find('a', tag='0').get_text(strip=True) # 最新
issue_1 = field_date_div.find('a', tag='1').get_text(strip=True) # 上一期
#<p class="clearfix p10_0">
field_data_p = soup_field_hk.find_all('p', class_='clearfix p10_0')
# 可能是一个列表,"注:"里面的内容,可能是换算为港币
notation_list = []
for p in field_data_p:
# 获取每个<p>的文本
notation = p.get_text(strip=True, separator=' ')
notation_list.append(notation)
table_0_0 = soup_field_hk.find('table', class_='m_table m_hl', id='hy3_table_1')
# 获取表头
table_0_header = table_0_0.find('thead').find_all('th')
# 获取表头文本
table_0_header_text = [th.get_text(strip=True) for th in table_0_header]
# 获取表格数据
table_0_rows = table_0_0.find('tbody').find_all('tr')
# 获取每一行的数据
table_0_data = []
for row in table_0_rows:
cols = row.find_all('td')
cols_text = [col.get_text(strip=True) for col in cols]
table_0_data.append(cols_text)
table_0_df = pd.DataFrame(table_0_data, columns=table_0_header_text)
data = dict()
data['issue'] = issue_0
data['title'] = title_and_filed_0
data['ps'] = notation_list[0] if len(notation_list) > 0 else ''
data['table'] = table_0_df
data_list.append(data)
table_0_1 = soup_field_hk.find('table', class_='m_table m_hl', id='hy3_table_2')
# 获取表头
table_1_header = table_0_1.find('thead').find_all('th')
# 获取表头文本
table_1_header_text = [th.get_text(strip=True) for th in table_1_header]
# 获取表格数据
table_1_rows = table_0_1.find('tbody').find_all('tr')
# 获取每一行的数据
table_1_data = []
for row in table_1_rows:
cols = row.find_all('td')
cols_text = [col.get_text(strip=True) for col in cols]
table_1_data.append(cols_text)
# 变成dataframe格式
table_1_df = pd.DataFrame(table_1_data, columns=table_1_header_text)
data = dict()
data['issue'] = issue_1
data['title'] = title_and_filed_0
data['ps'] = notation_list[0] if len(notation_list) > 1 else ''
data['table'] = table_1_df
data_list.append(data)
title_and_filed_1 = soup_field_hk.find('p', class_='threecate fl f14 tip').get_text(strip=True, separator=' ') # 标题和行业信息
#<div class="field_date1" id="dateSelect">
field_date_div = soup_field_hk.find('div', class_='field_date1')
if field_date_div is not None:
# 获取里面的<a>的tag="0"和tag="1"的文本
issue_2 = field_date_div.find('a', tag='0').get_text(strip=True) # 最新
issue_3 = field_date_div.find('a', tag='1').get_text(strip=True) # 上一期
table_1_0 = soup_field_hk.find('table', class_='m_table m_hl', id='hy2_table_1')
# 获取表头
table_1_0_header = table_1_0.find('thead').find_all('th')
# 获取表头文本
table_1_0_header_text = [th.get_text(strip=True) for th in table_1_0_header]
# 获取表格数据
table_1_0_rows = table_1_0.find('tbody').find_all('tr')
# 获取每一行的数据
table_1_0_data = []
for row in table_1_0_rows:
cols = row.find_all('td')
cols_text = [col.get_text(strip=True) for col in cols]
table_1_0_data.append(cols_text)
# 变成dataframe格式
table_1_0_df = pd.DataFrame(table_1_0_data, columns=table_1_0_header_text)
data = dict()
data['issue'] = issue_2
data['title'] = title_and_filed_1
data['ps'] = notation_list[1] if len(notation_list) > 1 else ''
data['table'] = table_1_0_df
data_list.append(data)
tabel_1_1 = soup_field_hk.find('table', class_='m_table m_hl', id='hy2_table_2')
# 获取表头
table_1_1_header = tabel_1_1.find('thead').find_all('th')
# 获取表头文本
table_1_1_header_text = [th.get_text(strip=True) for th in table_1_1_header]
# 获取表格数据
table_1_1_rows = tabel_1_1.find('tbody').find_all('tr')
# 获取每一行的数据
table_1_1_data = []
for row in table_1_1_rows:
cols = row.find_all('td')
cols_text = [col.get_text(strip=True) for col in cols]
table_1_1_data.append(cols_text)
# 变成dataframe格式
table_1_1_df = pd.DataFrame(table_1_1_data, columns=table_1_1_header_text)
data = dict()
data['issue'] = issue_3
data['title'] = title_and_filed_1
data['ps'] = notation_list[1] if len(notation_list) > 1 else ''
data['table'] = table_1_1_df
data_list.append(data)
return data_list
def get_cn_company_field_compare(symbol):
symbol = symbol.upper()
symbol = ''.join(filter(str.isdigit, symbol)) # 只保留数字
if len(symbol) > 6:
symbol = symbol[-6:]
url = f"https://basic.10jqka.com.cn/{symbol}/field.html"
# 获取页面内容
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=header)
soup_field_cn = BeautifulSoup(response.content, 'html.parser')
data_list_cn = []
# 获取标题和行业信息
# <p class="threecate fl">三级行业分类:<span class="tip f14">计算机 -- 计算机设备 -- 其他计算机设备 (共<strong>57</strong>家)</span></p>
title_and_filed_0_cn = soup_field_cn.find('p', class_='threecate fl').get_text(strip=True, separator=' ') # 标题和行业信息
# 获取日期选择
field_date_div_cn = soup_field_cn.find('div', class_='field_date1')
# 获取里面的<a>的tag="0"和tag="1"的文本
issue_0_cn = field_date_div_cn.find('a', tag='0').get_text(strip=True) # 最新
issue_1_cn = field_date_div_cn.find('a', tag='1').get_text(strip=True) # 上一期
# 获取注释信息
field_data_p_cn = soup_field_cn.find_all('p', class_='clearfix p10_0')
notation_list_cn = []
for p in field_data_p_cn:
# 获取每个<p>的文本
notation = p.get_text(strip=True, separator=' ')
notation_list_cn.append(notation)
# 第一个表 <table class="m_table m_hl" id="hy3_table_1">
# 获取表格数据
table_0_0 = soup_field_cn.find('table', id='hy3_table_1')
# 获取表格表头
table_0_0_title = table_0_0.find('thead').get_text(strip=True, separator=' ')
# 获取表格数据
table_0_0_data = []
for tr in table_0_0.find_all('tr')[1:]: # 跳过表头
row_data = [td.get_text(strip=True) for td in tr.find_all('td')]
table_0_0_data.append(row_data)
# dataframe
import pandas as pd
df_table_0_0 = pd.DataFrame(table_0_0_data, columns=table_0_0_title.split())
data = dict()
data['issue'] = issue_0_cn
data['title'] = title_and_filed_0_cn
data['ps'] = notation_list_cn[0] if len(notation_list_cn) > 0 else ''
data['table'] = df_table_0_0
data_list_cn.append(data)
# 第二个表 <table class="m_table m_hl" id="hy3_table_2">
table_0_1 = soup_field_cn.find('table', id='hy3_table_2')
# 获取表格表头
table_0_1_title = table_0_1.find('thead').get_text(strip=True, separator=' ')
# 获取表格数据
table_0_1_data = []
for tr in table_0_1.find_all('tr')[1:]: # 跳过表头
row_data = [td.get_text(strip=True) for td in tr.find_all('td')]
table_0_1_data.append(row_data)
# dataframe
df_table_0_1 = pd.DataFrame(table_0_1_data, columns=table_0_1_title.split())
data = dict()
data['issue'] = issue_1_cn
data['title'] = title_and_filed_0_cn
data['ps'] = notation_list_cn[0] if len(notation_list_cn) > 0 else ''
data['table'] = df_table_0_1
data_list_cn.append(data)
# 获取行业标题 <p class="threecate">二级行业分类:<span class="tip f14">计算机 -- 计算机设备 (共<strong>80</strong>家)</span></p>
title_and_filed_1_cn = soup_field_cn.find('p', class_='threecate').get_text(strip=True, separator=' ') # 标题和行业信息
# 获取期数
field_date_div_1_cn = soup_field_cn.find('div', class_='field_date2')
if field_date_div_1_cn is not None:
# 获取里面的<a>的tag="0"和tag="1"的文本
issue_2_cn = field_date_div_1_cn.find('a', tag='0').get_text(strip=True) # 最新
issue_3_cn = field_date_div_1_cn.find('a', tag='1').get_text(strip=True) # 上一期
# 表格1 hy2_table_1
table_1_0 = soup_field_cn.find('table', id='hy2_table_1')
# 获取表格表头
table_1_0_title = table_1_0.find('thead').get_text(strip=True, separator=' ')
# 获取表格数据
table_1_0_data = []
for tr in table_1_0.find_all('tr')[1:]: # 跳过表头
row_data = [td.get_text(strip=True) for td in tr.find_all('td')]
table_1_0_data.append(row_data)
# dataframe
df_table_1_0 = pd.DataFrame(table_1_0_data, columns=table_1_0_title.split())
data = dict()
data['issue'] = issue_2_cn
data['title'] = title_and_filed_1_cn
data['ps'] = notation_list_cn[1] if len(notation_list_cn) > 1 else ''
data['table'] = df_table_1_0
data_list_cn.append(data)
# 表格2 hy2_table_2
table_1_1 = soup_field_cn.find('table', id='hy2_table_2')
# 获取表格表头
table_1_1_title = table_1_1.find('thead').get_text(strip=True, separator=' ')
# 获取表格数据
table_1_1_data = []
for tr in table_1_1.find_all('tr')[1:]: # 跳过表头
row_data = [td.get_text(strip=True) for td in tr.find_all('td')]
table_1_1_data.append(row_data)
# dataframe
df_table_1_1 = pd.DataFrame(table_1_1_data, columns=table_1_1_title.split())
data = dict()
data['issue'] = issue_3_cn
data['title'] = title_and_filed_1_cn
data['ps'] = notation_list_cn[1] if len(notation_list_cn) > 1 else ''
data['table'] = df_table_1_1
data_list_cn.append(data)
return data_list_cn2.6(b) 具体数据获取
python
def extract_field_compare(stock_type, stock_code):
"""
提取行业对比分析数据
Args:
stock_type (str): 股票类型
stock_code (str): 股票代码
Returns:
Dict[str, Any]: 包含以下键的字典:
data_value (Dict[str, dict]): 行业对比分析数据,包含目标公司和同行业其他公司的对比数据
data_type (str): 数据类型
data_desc (str): 数据内容描述,说明返回的数据包含哪些行业对比分析数据
"""
if stock_type == '港股':
hk_code = 'HK' + stock_code
field_compare = get_hk_company_field_compare(hk_code) # 港股包括
else:
a_code = stock_code
field_compare = get_cn_company_field_compare(a_code)
issue_list = []
title_list = []
ps_list = []
dataframe_list = []
for item in field_compare:
issue_list.append(item['issue'])
title_list.append(item['title'])
ps_list.append(item['ps'])
dataframe_list.append(item['table'])
return {
'data_value':{
"issue": issue_list,
"title": title_list,
"ps": ps_list,
"table": dataframe_list
},
'data_type': 'dict_special_list',
'data_desc': '行业对比分析数据,包含目标公司和同行业其他公司的对比数据,是一个list,包括issue,title,ps和数据table,table是原始数据dataframe'
}
# 提取行业对比分析数据
# field_compare_data = extract_field_compare(stock_type, stock_code)2.7 未来的机构评级数据
- 港股的ths有比较详细的机构评级数据,A股的用akshare
2.7(a)网页结构观察
python
def get_hk_rating_info(symbol):
symbol = symbol.upper()
symbol = ''.join(filter(str.isdigit, symbol)) # 只保留数字
if len(symbol) > 4:
symbol = symbol[-4:]
url = f'https://basic.10jqka.com.cn/HK{symbol}/rating.html'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=header)
soup_rating_hk = BeautifulSoup(response.content, 'html.parser')
#<table class="m_table m_hl mt15">
rating_info = soup_rating_hk.find('table', class_='m_table m_hl mt15')
# 获取表格数据
rating_data = []
# 获取表格表头
rating_title = rating_info.find('thead')
rating_title_data = [th.get_text(strip=True) for th in rating_title.find_all('th')]
rating_data.append(rating_title_data) # 将表头作为第一行数据
for tr in rating_info.find_all('tr')[1:]: # 跳过表头
row_data = [td.get_text(strip=True) for td in tr.find_all('td')]
rating_data.append(row_data)
# 将数据转换为DataFrame
import pandas as pd
df_rating_hk = pd.DataFrame(rating_data, columns=rating_title_data)
# 删除第一行
df_rating_hk = df_rating_hk[1:] # 去掉第一行
# 重置索引
df_rating_hk = df_rating_hk.reset_index(drop=True)
return df_rating_hk
# stock_hk_profit_forecast_et_df = ak.stock_hk_profit_forecast_et(symbol='0'+symbol,indicator="盈利预测概览")
# return stock_hk_profit_forecast_et_df
def get_cn_rating_info(symbol):
symbol = symbol.upper()
symbol = ''.join(filter(str.isdigit, symbol)) # 只保留数字
if len(symbol) > 6:
symbol = symbol[-6:]
stock_profit_forecast_ths_df = ak.stock_profit_forecast_ths(symbol=symbol, indicator="业绩预测详表-详细指标预测")
return stock_profit_forecast_ths_df2.7(b) 具体数据获取
python
def extract_rating_info(stock_type: Annotated[str, InjectedToolArg], stock_code: Annotated[str, InjectedToolArg]):
"""
提取评级信息
Args:
stock_type (str): 股票类型,'A股' 或 '港股'
stock_code (str): 股票代码,A股为6位数字,港股为4位数字
Returns:
Dict[str, Any]: 包含以下键的字典:
data_value (Dict[str, Any]): 评级信息,包括评级机构的评级和投资建议
data_type (str): 数据类型
data_desc (str): 数据内容描述,说明返回的数据包含哪些评级信息
"""
if stock_type == '港股':
hk_code = 'HK' + stock_code
rating_info = get_hk_rating_info(hk_code)
else:
a_code = stock_code
rating_info = ak.stock_profit_forecast_ths(symbol=a_code, indicator="业绩预测详表-机构")
return {
'data_value': {
"评级信息": rating_info
},
'data_type': 'dict_dataframe',
'data_desc': '评级信息,包括评级机构的评级和投资建议,主要关注机构和研究员给出的数据指标是否建议买入'
}
# 提取评级信息
# rating_info = extract_rating_info(stock_type, stock_code)2.8 未来股价预测数据
- 使用akshare就可以
python
def extract_worth_predict(stock_type: Annotated[str, InjectedToolArg], stock_code: Annotated[str, InjectedToolArg]):
"""
提取股票收益和价值预测信息
Args:
stock_type (str): 股票类型,'A股' 或 '港股'
stock_code (str): 股票代码,A股为6位数字,港股为4位数字
Returns:
Dict[str, Any]: 包含以下键的字典:
data_value (Dict[str, pd.DataFrame]): 股票收益和价值预测信息,包括盈利预测概览和详细指标预测的数据值
data_type (str): 数据类型
data_desc (str): 数据内容描述,说明返回的数据包含哪些股票收益和价值预测信息
"""
if stock_type == '港股':
hk_code = 'HK' + stock_code
hk_code = hk_code.upper()
hk_code = ''.join(filter(str.isdigit, hk_code)) # 只保留数字
if len(hk_code) > 4:
hk_code = hk_code[-4:]
hk_code = '0' + hk_code # 确保是5位数字
predict_info = ak.stock_hk_profit_forecast_et(symbol=hk_code, indicator="盈利预测概览")
else:
a_code = stock_code
predict_info = ak.stock_profit_forecast_ths(symbol=a_code, indicator="业绩预测详表-详细指标预测")
return {
'data_value': {
"预测信息": predict_info
},
'data_type': 'dict_dataframe',
'data_desc': '股票收益和价值预测信息,包括盈利预测概览和详细指标预测的数据值'
}
# 提取股票收益和价值预测信息
# worth_predict = extract_worth_predict(stock_type, stock_code)2.9 行业研报数据
- 发现东方财富上有一个按行业归类的研报页面,可以获取这个页面的信息,不过它的行业名-行业id可能和比赛给出的不一样,所以首先判断比赛里面的行业名,和研报分类的哪一个最接近
2.9(a)相似行业判断
python
# 东方财富的 行业代码:行业名
# 先从industry_dict中获取最相似的行业,获取到对应的key
import requests
from bs4 import BeautifulSoup
src_mapping = """<div id="hymore" class="select-box" style="display: none;"><ul><li><b>B</b><a target="_self" data-bkval="546">玻璃玻纤</a></li><li><a target="_self" data-bkval="474">保险</a></li><li><a target="_self" data-bkval="1036">半导体</a></li><li><a target="_self" data-bkval="733">包装材料</a></li><li><b>C</b><a target="_self" data-bkval="1017">采掘行业</a></li><li><a target="_self" data-bkval="729">船舶制造</a></li><li><b>D</b><a target="_self" data-bkval="459">电子元件</a></li><li><a target="_self" data-bkval="457">电网设备</a></li><li><a target="_self" data-bkval="428">电力行业</a></li><li><a target="_self" data-bkval="1039">电子化学品</a></li><li><a target="_self" data-bkval="1034">电源设备</a></li><li><a target="_self" data-bkval="1033">电池</a></li><li><a target="_self" data-bkval="1030">电机</a></li><li><a target="_self" data-bkval="738">多元金融</a></li><li><b>F</b><a target="_self" data-bkval="451">房地产开发</a></li><li><a target="_self" data-bkval="436">纺织服装</a></li><li><a target="_self" data-bkval="1045">房地产服务</a></li><li><a target="_self" data-bkval="1032">风电设备</a></li><li><a target="_self" data-bkval="1020">非金属材料</a></li><li><b>G</b><a target="_self" data-bkval="479">钢铁行业</a></li><li><a target="_self" data-bkval="427">公用事业</a></li><li><a target="_self" data-bkval="425">工程建设</a></li><li><a target="_self" data-bkval="1038">光学光电子</a></li><li><a target="_self" data-bkval="1031">光伏设备</a></li><li><a target="_self" data-bkval="739">工程机械</a></li><li><a target="_self" data-bkval="732">贵金属</a></li><li><a target="_self" data-bkval="726">工程咨询服务</a></li><li><b>H</b><a target="_self" data-bkval="538">化学制品</a></li><li><a target="_self" data-bkval="480">航天航空</a></li><li><a target="_self" data-bkval="471">化纤行业</a></li><li><a target="_self" data-bkval="465">化学制药</a></li><li><a target="_self" data-bkval="450">航运港口</a></li><li><a target="_self" data-bkval="447">互联网服务</a></li><li><a target="_self" data-bkval="420">航空机场</a></li><li><a target="_self" data-bkval="1019">化学原料</a></li><li><a target="_self" data-bkval="731">化肥行业</a></li><li><a target="_self" data-bkval="728">环保行业</a></li><li><b>J</b><a target="_self" data-bkval="456">家电行业</a></li><li><a target="_self" data-bkval="440">家用轻工</a></li><li><a target="_self" data-bkval="429">交运设备</a></li><li><a target="_self" data-bkval="740">教育</a></li><li><a target="_self" data-bkval="735">计算机设备</a></li><li><b>L</b><a target="_self" data-bkval="485">旅游酒店</a></li><li><b>M</b><a target="_self" data-bkval="484">贸易行业</a></li><li><a target="_self" data-bkval="437">煤炭行业</a></li><li><a target="_self" data-bkval="1035">美容护理</a></li><li><b>N</b><a target="_self" data-bkval="477">酿酒行业</a></li><li><a target="_self" data-bkval="433">农牧饲渔</a></li><li><a target="_self" data-bkval="1015">能源金属</a></li><li><a target="_self" data-bkval="730">农药兽药</a></li><li><b>Q</b><a target="_self" data-bkval="481">汽车零部件</a></li><li><a target="_self" data-bkval="1029">汽车整车</a></li><li><a target="_self" data-bkval="1016">汽车服务</a></li><li><b>R</b><a target="_self" data-bkval="1028">燃气</a></li><li><a target="_self" data-bkval="737">软件开发</a></li><li><b>S</b><a target="_self" data-bkval="482">商业百货</a></li><li><a target="_self" data-bkval="464">石油行业</a></li><li><a target="_self" data-bkval="454">塑料制品</a></li><li><a target="_self" data-bkval="438">食品饮料</a></li><li><a target="_self" data-bkval="424">水泥建材</a></li><li><a target="_self" data-bkval="1044">生物制品</a></li><li><b>T</b><a target="_self" data-bkval="545">通用设备</a></li><li><a target="_self" data-bkval="448">通信设备</a></li><li><a target="_self" data-bkval="421">铁路公路</a></li><li><a target="_self" data-bkval="736">通信服务</a></li><li><b>W</b><a target="_self" data-bkval="486">文化传媒</a></li><li><a target="_self" data-bkval="422">物流行业</a></li><li><b>X</b><a target="_self" data-bkval="1037">消费电子</a></li><li><a target="_self" data-bkval="1027">小金属</a></li><li><a target="_self" data-bkval="1018">橡胶制品</a></li><li><b>Y</b><a target="_self" data-bkval="478">有色金属</a></li><li><a target="_self" data-bkval="475">银行</a></li><li><a target="_self" data-bkval="458">仪器仪表</a></li><li><a target="_self" data-bkval="1046">游戏</a></li><li><a target="_self" data-bkval="1042">医药商业</a></li><li><a target="_self" data-bkval="1041">医疗器械</a></li><li><a target="_self" data-bkval="727">医疗服务</a></li><li><b>Z</b><a target="_self" data-bkval="539">综合行业</a></li><li><a target="_self" data-bkval="476">装修建材</a></li><li><a target="_self" data-bkval="473">证券</a></li><li><a target="_self" data-bkval="470">造纸印刷</a></li><li><a target="_self" data-bkval="1043">专业服务</a></li><li><a target="_self" data-bkval="1040">中药</a></li><li><a target="_self" data-bkval="910">专用设备</a></li><li><a target="_self" data-bkval="734">珠宝首饰</a></li><li><a target="_self" data-bkval="725">装修装饰</a></li><ul></ul></ul></div>"""
soup = BeautifulSoup(src_mapping, 'html.parser')
industry_dict = {}
for a_tag in soup.select('#hymore a[data-bkval]'):
bid = a_tag.get('data-bkval')
name = a_tag.text.strip()
if bid and name:
industry_dict[bid] = name
print(industry_dict)
## {'546': '玻璃玻纤', '474': '保险', '1036': '半导体'}等
## 判断最相关的行业代码
find_most_similar_industry = f"""
你是一个金融行业的专家,你需要从 行业代码:行业名 的字典中,找到与输入的行业描述最相似的3个行业及其代码。
行业代码:行业名 的字典为
-----
{industry_dict}
-----
请从上面的行业代码:行业名 的字典中,仔细分析,找到与 {industry_input} 最相似的3个行业及其代码,并输出为json格式,不要解释。
"""
similar_industry_response = kimi_model.invoke(find_most_similar_industry)
similar_industry = similar_industry_response.content.strip()
## 判断最相关的行业代码
find_most_similar_industry_think_template = """
你是一个金融行业的专家,你需要从 行业代码:行业名 的字典中,找到与输入的行业描述最相似的1个行业及其代码。
行业代码:行业名 的字典为
-----
{industry_dict}
-----
请从上面的行业代码:行业名 的字典中,仔细分析,找到与 {industry_input} 最相似的1个行业及其代码。
请仔细思考,不要停留在字面意思,需要从行业的本质、发展趋势、市场需求等方面进行综合分析。
输出为json格式,不要解释。
"""
find_most_similar_industry_think = find_most_similar_industry_think_template.format(
industry_dict=similar_industry_response, industry_input=industry_input)
most_similar_industry_response = best_model.invoke(find_most_similar_industry_think)
most_similar_industry = most_similar_industry_response.content.strip()
# 提取行业代码,只需解析出第一个数字即可
import re
def extract_industry_code(industry_str):
match = re.search(r'\d+', industry_str)
return match.group(0) if match else None
industry_code = extract_industry_code(most_similar_industry)
# print最相似的行业名和对应代码 可以从industry_dict中获取
industry_name = industry_dict.get(industry_code, "未知行业")
print(f"最相似的行业代码: {industry_code}, 行业名: {industry_name}")
industry_code = int(industry_code)
# 最相似的行业代码: 1037, 行业名: 消费电子2.9(b) 获取行业报告列表里面的标题、url
- 注意慢点不要干扰服务
- 保存tilte和infocode,infocode可以在后面用于获取研报具体的URL
python
# 原始的获取研报的api,慢一点sleep多一点
import requests
import json
import time
from datetime import datetime, timedelta
def get_dfcf_research_report(industry_code, page=1, years_ago=2):
"""
获取东方财富网的行业研报数据。
:param industry_code: 行业代码
:param page: 页码,默认为1
"""
# API URL
url = "https://reportapi.eastmoney.com/report/list"
# 生成当前时间戳(毫秒级)
timestamp = int(time.time() * 1000)
# 当天年月日
current_date = datetime.now().strftime('%Y-%m-%d')
# 将日期字符串转为 datetime 对象
date_obj = datetime.strptime(current_date, '%Y-%m-%d')
two_years_ago = date_obj.replace(year=date_obj.year - years_ago)
# 格式化回字符串
two_years_ago_str = two_years_ago.strftime('%Y-%m-%d')
# 请求参数
params = {
'industryCode': str(industry_code),
'pageSize': 50, # 每页多少条
'industry': '*',
'rating': '*',
'ratingChange': '*',
'beginTime': two_years_ago_str, # 2年前的
'endTime': current_date, # 使用系统提供的时间:2025年6月27日
'pageNo': page,
'fields': '',
'qType': 1,
'orgCode': '',
'rcode': '',
'p': page,
'pageNum': page,
'pageNumber': page,
'_': timestamp, # 使用动态生成的时间戳
}
# 设置请求头(模拟浏览器访问,防止反爬虫机制)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0 Safari/537.36'
}
# 发送GET请求
response = requests.get(url, params=params, headers=headers)
# 检查响应状态码
if response.status_code == 200:
try:
# 移除回调函数并解析JSON数据
json_data = json.loads(response.text.replace('datatable3015936(', '').rstrip(')'))
#print(json.dumps(json_data, ensure_ascii=False, indent=4)) # 打印格式化后的JSON数据
except json.JSONDecodeError as e:
print(f"Failed to decode JSON: {e}")
else:
print(f"Failed to retrieve data: HTTP Status Code {response.status_code}")
return json_data
# 获取第一页的研报数据
from time import sleep
import pandas as pd
idx_list = []
title_list = []
infocede_list = []
url_list = []
report_date_list = []
max_page = 1 # 最大获取研报页数
idx_cnt = 0
for page in range(1,max_page+1):
print(f"正在获取第 {page} 页的研报数据...")
sleep(20) # 东方财富网的反爬虫机制,适当延时
dfcs_top50_research_url = get_dfcf_research_report(industry_code, page=page, years_ago=2)
with open(f"dfcf_research_report_list_for_{industry_code}_page_{page}.json", 'w', encoding='utf-8') as f:
json.dump(dfcs_top50_research_url, f, ensure_ascii=False, indent=4)
for i in range(len(dfcs_top50_research_url['data'])):
idx_list.append(idx_cnt)
title_list.append(dfcs_top50_research_url['data'][i]['title'])
infocede_list.append(dfcs_top50_research_url['data'][i]['infoCode'])
url_list.append('https://data.eastmoney.com/report/zw_industry.jshtml?infocode=' + dfcs_top50_research_url['data'][i]['infoCode'])
report_date = dfcs_top50_research_url['data'][i]['publishDate']
report_date = pd.to_datetime(report_date).strftime('%Y-%m-%d')
report_date_list.append(report_date)
idx_cnt += 1
# 存储为csv文件
import pandas as pd
dfcs_research_df = pd.DataFrame({
'idx': idx_list,
'title': title_list,
'report_date': report_date_list,
'infocode': infocede_list,
'url': url_list
})
dfcs_research_df.to_csv(f'dfcs_research_report_list_for_{industry_code}.csv', index=False, encoding='utf-8')2.9© 研报具体内容获取
python
# 获取研报内容
def get_dfcf_research_report_content(url):
"""
获取东方财富网的行业研报内容。
:param url: 研报的URL
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
print(f"Failed to retrieve report content: HTTP Status Code {response.status_code}")
return None
# 解析研报内容
from bs4 import BeautifulSoup
# 找到 div ctx-content,里面是研报内容
def parse_dfcf_research_report_content(html_content):
"""
解析东方财富网的行业研报内容。
:param html_content: 研报的HTML内容
:return: 研报的文本内容
"""
soup = BeautifulSoup(html_content, 'html.parser')
content_div = soup.find('div', class_='ctx-content')
if content_div:
return content_div.get_text(strip=True)
else:
print("Content div not found.")
return None
url_content = []
for i in range(len(dfcs_research_df)):
url = dfcs_research_df['url'][i]
print(f"正在获取第 {i+1} 条研报内容,链接为:{url}")
sleep(20) # 东方财富网的反爬虫机制,适当延时
report_content = get_dfcf_research_report_content(url_list[i])
if report_content:
# 解析第一个研报的内容
parsed_content = parse_dfcf_research_report_content(report_content)
if parsed_content:
# 将解析后的内容添加到列表中
url_content.append(parsed_content)
else:
url_content.append("空")
else:
url_content.append("空")
# 保存研报内容到CSV文件
dfcs_research_df['content'] = url_content
dfcs_research_df.to_csv(f'dfcs_research_report_content_for_{industry_code}.csv', index=False, encoding='utf-8')2.10 宏观数据
- 可以从akshare的macro里面获取,具体参考:https://akshare.akfamily.xyz/data/macro/macro.html
- 注意加一些try catch这部分有的可能访问超限报错,或者只选能获取到的,例如
python
import akshare as ak
macro_cnbs_df = ak.macro_cnbs() # 中国宏观杠杆率,年份 居民部门 非金融企业部门 政府部门 中央政府 地方政府 实体经济部门 金融部门资产方 金融部门负债方
macro_cnbs_df = macro_cnbs_df[macro_cnbs_df['年份'].astype(str) >= '2019'].reset_index(drop=True) # 只保留2000年以后的数据
save_extracted_info(
key_name='中国宏观杠杆率',
data_value=macro_cnbs_df,
data_type='dict_dataframe',
data_desc='中国宏观杠杆率,包含 年份 居民部门 非金融企业部门 政府部门 中央政府 地方政府 实体经济部门 金融部门资产方 金融部门负债方'
)3 数据存储和加载示例
3.1 公司研报
需要先获取股票代码和股票类型
python
def judge_stock_type(input_stock_code: str):
"""
调用该函数,从混合着股票代码和公司信息的输入判断股票是A股的还是港股的,并提取出准确的股票代码。
Args:
input_stock_code (str): 输入的股票代码和公司信息
Returns:
Dict[str, Any]: 包含以下键的字典:
data_value (Dict[str, str]): 包含股票类型(A股或港股)和对应的股票代码
data_type (str): 数据类型
data_desc (str): 数据描述
例如:
"""
prompt = """你是一个股票研究专家,请判断这个股票代码是A股还是港股,并返回股票代码。对于A股,返回6位纯数字的股票代码;对于港股,返回4位纯数字的股票代码。
股票代码和公司信息是:{stock_code}
请只返回股票代码,不要包含其他任何信息。你输出的股票代码为:"""
response = base_model.invoke(prompt.format(stock_code=input_stock_code),enable_thinking=False)
stock_code = response.content.strip()
if len(stock_code) == 6:
stock_type = 'A股'
else:
stock_type = '港股'
return stock_type, stock_code
stock_type, stock_code = judge_stock_type(input_stock_code)数据存储
python
# 2. 提取这个公司的基本信息
company_basic_info = extract_company_basic_info(stock_type, stock_code)
save_extracted_info(
data_value=company_basic_info['data_value'],
data_type=company_basic_info['data_type'],
data_desc=company_basic_info['data_desc']
)
# 3. 提取近期股票基本数据
stock_info = extract_stock_info(stock_type, stock_code)
save_extracted_info(
data_value=stock_info['data_value'],
data_type=stock_info['data_type'],
data_desc=stock_info['data_desc']
)
# 4. 提取三大财务报表数据
financial_statements = extract_financial_statements(stock_type, stock_code)
save_extracted_info(
data_value=financial_statements['data_value'],
data_type=financial_statements['data_type'],
data_desc=financial_statements['data_desc']
)
# 5. 如果是港股,提取港股财务分析指标数据包括ROE等
hk_financial_analysis = extract_hk_financial_analysis(stock_type, stock_code)
# 保存到本地
save_extracted_info(
data_value=hk_financial_analysis['data_value'],
data_type=hk_financial_analysis['data_type'],
data_desc=hk_financial_analysis['data_desc']
)
save_collected_data_to_local()
# 6. 提取公司财务摘要信息
financial_summary = extract_financial_summary(stock_type, stock_code)
save_extracted_info(
data_value=financial_summary['data_value'],
data_type=financial_summary['data_type'],
data_desc=financial_summary['data_desc']
)
# 7. 提取行业对比分析数据
field_compare_data = extract_field_compare(stock_type, stock_code)
save_extracted_info(
data_value=field_compare_data['data_value'],
data_type=field_compare_data['data_type'],
data_desc=field_compare_data['data_desc']
)
save_collected_data_to_local()
# 8. 提取股票评级信息
rating_info = extract_rating_info(stock_type, stock_code)
save_extracted_info(
data_value=rating_info['data_value'],
data_type=rating_info['data_type'],
data_desc=rating_info['data_desc']
)
# 9. 提取股票收益和价值预测信息
worth_predict_info = extract_worth_predict(stock_type, stock_code)
save_extracted_info(
data_value=worth_predict_info['data_value'],
data_type=worth_predict_info['data_type'],
data_desc=worth_predict_info['data_desc']
)
save_collected_data_to_local()数据加载(在这里可以处理一些数据,比如三大财务报表,原始的存储方式比较冗余,pivot一下)
python
import pandas as pd
import pickle
def load_collected_data_from_local():
global collected_data_value, collected_data_type, collected_data_desc
try:
with open('collected_data_value.pkl', 'rb') as f:
collected_data_value = pickle.load(f)
with open('collected_data_type.pkl', 'rb') as f:
collected_data_type = pickle.load(f)
with open('collected_data_desc.pkl', 'rb') as f:
collected_data_desc = pickle.load(f)
print("数据已从本地加载。")
except FileNotFoundError:
print("未找到本地数据文件,请先运行保存操作。")
# 信息获取后,数据存储到dict里面
collected_data_value = {}
collected_data_type = {}
collected_data_desc = {}
# 数据加载完毕
load_collected_data_from_local()
# 数据在collected_data_value, collected_data_type, collected_data_desc
df1 = collected_data_value['资产负债表']
df2 = df1.pivot(index='REPORT_DATE', columns='STD_ITEM_NAME', values='AMOUNT')
# 重置索引,让 REPORT_DATE 变回列(可选)
df2.reset_index(inplace=True)
# 去掉列索引的名字
df2.columns.name = None
# 转换为yyyy-mm-dd格式
df2['REPORT_DATE'] = pd.to_datetime(df2['REPORT_DATE']).dt.strftime('%Y-%m-%d')
collected_data_value['资产负债表'] = df2
df1 = collected_data_value['利润表']
df2 = df1.pivot(index='REPORT_DATE', columns='STD_ITEM_NAME', values='AMOUNT')
# 重置索引,让 REPORT_DATE 变回列(可选)
df2.reset_index(inplace=True)
# 去掉列索引的名字
df2.columns.name = None
# 转换为yyyy-mm-dd格式
df2['REPORT_DATE'] = pd.to_datetime(df2['REPORT_DATE']).dt.strftime('%Y-%m-%d')
collected_data_value['利润表'] = df2
df1 = collected_data_value['现金流量表']
df2 = df1.pivot(index='REPORT_DATE', columns='STD_ITEM_NAME', values='AMOUNT')
# 重置索引,让 REPORT_DATE 变回列(可选)
df2.reset_index(inplace=True)
# 去掉列索引的名字
df2.columns.name = None
# 转换为yyyy-mm-dd格式
df2['REPORT_DATE'] = pd.to_datetime(df2['REPORT_DATE']).dt.strftime('%Y-%m-%d')
collected_data_value['现金流量表'] = df2
df1 = collected_data_value['港股财务分析指标数据']
df1['REPORT_DATE'] = pd.to_datetime(df1['REPORT_DATE']).dt.strftime('%Y-%m-%d')
df2 = df1.loc[:,['REPORT_DATE','ROE_AVG','ROA', 'PER_NETCASH_OPERATE','PER_OI', 'BPS',
'BASIC_EPS', 'DILUTED_EPS', 'OPERATE_INCOME', 'OPERATE_INCOME_YOY',
'GROSS_PROFIT', 'GROSS_PROFIT_YOY', 'HOLDER_PROFIT',
'HOLDER_PROFIT_YOY', 'GROSS_PROFIT_RATIO', 'EPS_TTM',
'OPERATE_INCOME_QOQ', 'NET_PROFIT_RATIO', 'GROSS_PROFIT_QOQ',
'HOLDER_PROFIT_QOQ', 'ROE_YEARLY', 'ROIC_YEARLY', 'TAX_EBT',
'OCF_SALES', 'DEBT_ASSET_RATIO', 'CURRENT_RATIO', 'CURRENTDEBT_DEBT','CURRENCY']]
collected_data_value['港股财务分析指标数据'] = df2
collected_data_size = {}
# 只需要对dataframe类型的数据进行大小计算,其他的认为很小就行,dataframe的返回行列,文本的形式
def gen_collected_data_size():
global collected_data_value, collected_data_type, collected_data_size
for key, value in collected_data_value.items():
if collected_data_type[key] == 'dataframe':
# 获取DataFrame的行数和列数
size_info = value.shape
collected_data_size[key] = "行数为 {}, 列数为 {}".format(size_info[0], size_info[1])
else:
# 其他类型认为是小数据
collected_data_size[key] = {"小的文本数据"}
gen_collected_data_size()3.2 行业研报
- 行业研报需要可以找出来一个代表公司,然后就可以用上面的方法获取这个代表公司的行业对比数据
python
industry_name = '中国智能服务机器人产业'
industry_input = industry_name
task2 = f"""
完成 {industry_input} 的研报。
行业/子行业研报应能够聚合行业发展相关数据(协会年报、企业财报等),
输出行业生命周期与结构解读(如集中度、产业链上下游分析);
融合趋势分析与外部变量预测能力(如政策影响、技术演进),支持3年以上的行业情景模拟;
提供行业进入与退出策略建议,支持关键变量(如上游原材料价格)敏感性分析;
自动生成图表辅助说明行业规模变动、竞争格局等核心要素。
"""
find_industry_top_stock_code = f"""
你是一个金融专家,请你分析以下行业最具有代表性的公司,行业是:{industry_input}。
请只返回该公司名及其A股代码,不要有其他内容。
"""
industry_top_stock_response = best_model.invoke(find_industry_top_stock_code)
industry_top_stock = industry_top_stock_response.content.strip()
# 返回结果为 '科沃斯(603486)'
def judge_stock_type(input_stock_code: str):
"""
调用该函数,从混合着股票代码和公司信息的输入判断股票是A股的还是港股的,并提取出准确的股票代码。
Args:
input_stock_code (str): 输入的股票代码和公司信息
Returns:
Dict[str, Any]: 包含以下键的字典:
data_value (Dict[str, str]): 包含股票类型(A股或港股)和对应的股票代码
data_type (str): 数据类型
data_desc (str): 数据描述
例如:
"""
prompt = """你是一个股票研究专家,请判断这个股票代码是A股还是港股,并返回股票代码。对于A股,返回6位纯数字的股票代码;对于港股,返回4位纯数字的股票代码。
股票代码和公司信息是:{stock_code}
请只返回股票代码,不要包含其他任何信息。你输出的股票代码为:"""
response = base_model.invoke(prompt.format(stock_code=input_stock_code),enable_thinking=False)
stock_code = response.content.strip()
if len(stock_code) == 6:
stock_type = 'A股'
else:
stock_type = '港股'
return stock_type, stock_code
# 1. 提取股票类别和股票代码
stock_type, stock_code = judge_stock_type(industry_top_stock)
# 返回结果为 ('A股', '603486')
# 7. 提取行业对比分析数据
field_compare_data = extract_field_compare(stock_type, stock_code)
save_extracted_info(
data_value=field_compare_data['data_value'],
data_type=field_compare_data['data_type'],
data_desc=field_compare_data['data_desc']
)
save_collected_data_to_local()
load_collected_data_from_local()
# 研报数据加载
df_research_data = pd.read_csv(f'dfcs_research_report_content_for_{industry_code}.csv', encoding='utf-8')3.3 宏观研报
*除了akshare提供的宏观数据外,还可以获取最相关的行业是哪个,然后从这个行业下获取一些研报数据
python
marco_name = '国家级"人工智能+"政策效果评估'
time = '2023-2025'
macro_economic = f"{marco_name} ({time})"
task3 = f"""完成宏观经济策略研报:{macro_economic}
宏观经济/策略研报应能够自动抽取与呈现宏观经济核心指标(GDP、CPI、利率、汇率等),对政策报告与关键口径进行解读;
构建政策联动与区域对比分析模型,解释宏观变量间的交互影响(如降准对出口与CPI的传导路径);
支持全球视野的模拟建模(如美联储利率变动对全球资本流动的影响);提供对潜在"灰犀牛"事件的风险预警机制与指标设计。
"""
## 判断最相关的行业代码
find_most_similar_industry = f"""
你是一个金融行业的专家,你需要从 行业代码:行业名 的字典中,找到与输入的政策描述最相关的3个行业及其代码。
行业代码:行业名 的字典为
-----
{industry_dict}
-----
请从上面的行业代码:行业名 的字典中,仔细分析,找到与{macro_economic} 最相关的3个行业及其代码,并输出为json格式,不要解释。
"""
similar_industry_response = kimi_model.invoke(find_most_similar_industry)
similar_industry = similar_industry_response.content.strip()
## 判断最相关的行业代码
find_most_similar_industry_think_template = """
你是一个金融行业的专家,你需要从 行业代码:行业名 的字典中,找到与输入的政策描述最相关的1个行业及其代码。
行业代码:行业名 的字典为
-----
{industry_dict}
-----
请从上面的行业代码:行业名 的字典中,仔细分析,找到与 {macro_economic} 最相关的1个行业及其代码。
请仔细思考,不要停留在字面意思,需要从行业的本质、发展趋势、市场需求等方面进行综合分析。
输出为json格式,不要解释。
"""
find_most_similar_industry_think = find_most_similar_industry_think_template.format(
industry_dict=similar_industry_response, macro_economic=macro_economic)
most_similar_industry_response = deepseek_v3.invoke(find_most_similar_industry_think)
most_similar_industry = most_similar_industry_response.content.strip()
# 提取行业代码,只需解析出第一个数字即可
import re
def extract_industry_code(industry_str):
match = re.search(r'\d+', industry_str)
return match.group(0) if match else None
industry_code = extract_industry_code(most_similar_industry)
# print最相似的行业名和对应代码 可以从industry_dict中获取
industry_name = industry_dict.get(industry_code, "未知行业")
print(f"最相似的行业代码: {industry_code}, 行业名: {industry_name}")
industry_code = int(industry_code)
# 最相似的行业代码: 737, 行业名: 软件开发太长了,其他部分写在part2里面