在特殊发票版式识别方面,越来越多的公司开始使用OCR大模型,通过输入提示词,利用大模型强大的泛化能力,无需预设模板即可精准抽取任意发票版式信息,从根本上解决了传统OCR面对新版式时识别率低、维护成本高的问题。
传统OCR如何识别特殊版式?
传统的OCR识别解决了从"手动"到"自动"的问题,但其固有的局限性在今天愈发明显。
1、OCR原理解释
传统系统通过学习海量样本,为每一种发票(如增值税发票、火车票、定额发票)预先训练一个专用识别模型。当接收到图像时,系统会先进行版式匹配,然后调用对应的模板进行字段切割和识别。
2、OCR识别新版式有什么局限性?
● 新增版式识别困难:每当出现一种新的或不常见的发票版式,就需要重新收集样本、人工标注、训练新模型。整个过程耗时数天甚至数周,无法敏捷响应业务变化。
● 维护极其复杂:企业需要管理和维护数十个不同的模型和API接口,不仅导致硬件资源利用率低,也让技术维护成本居高不下。
OCR大模型如何识别新版式文档?
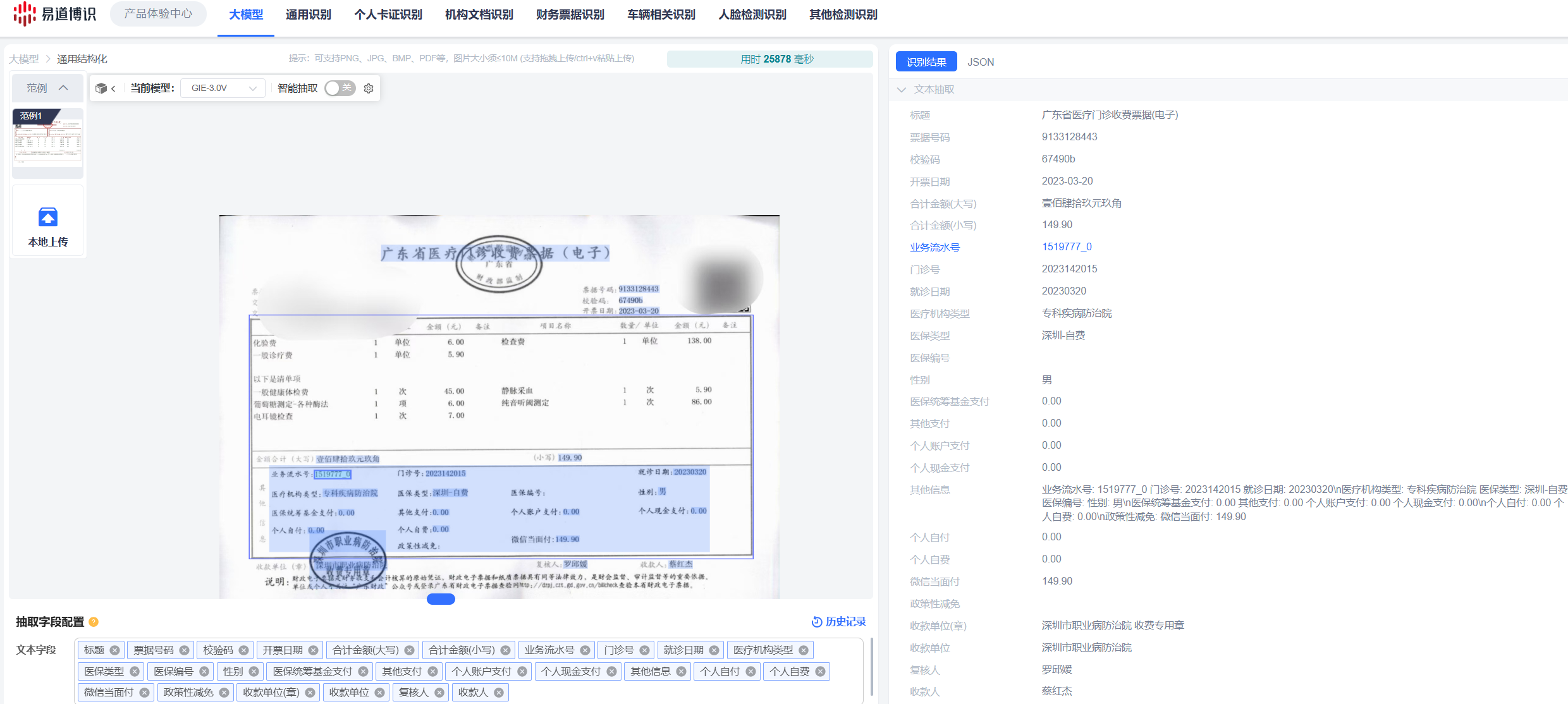
OCR大模型的出现,标志着文档识别技术从"专用模型"向"通用智能"的根本性转变。比如易道博识的OCR大模型,可以帮助企业实现任意版式文档字段的识别抽取。
-
什么是GIE大模型?
GIE(General Information Extraction)是基于海量多样化文档数据训练的通用信息抽取大模型。它不再依赖僵化的版式模板,而是深度融合了版式布局理解和强大的语义理解能力,能够像人一样"读懂"文档。
2.它如何解决传统OCR的痛点? GIE大模型的核心优势在于其无与伦比的通用性和泛化能力。
● 从"多模型"到"一模型":过去需要为每种文档训练专用模型,现在一个GIE大模型,通过一个统一的API接口,就能应对所有已知和未知的版式文档识别需求。
● 从"模型训练"到"Prompt配置":一个常见的误区是,认为增加新字段或识别新版式必须进行复杂的AI模型训练。现在使用GIE大模型,业务人员只需通过"提示词"(Prompt),即可完成新需求配置,上线时间从数周缩短至几小时。
● 从"高成本"到"低成本":统一的大模型架构大幅简化了系统操作,显著降低了服务器和人力维护成本。
- OCR大模型如何保证更高的准确率?
● 零样本泛化能力 (Zero-shot):GIE学习了足够多的场景,即使面对从未见过的发票版式,也能实现高精度识别和结构化提取。
● 强大的语义理解:它能精准理解复杂表格(如无线表格、跨页表格)、多栏版式(如合同、报告)甚至图文混合的文档,准确抽取所需信息。
● 大小模型交叉验证:举个例子,在银行等对数据质量要求极高的场景,可以创新性地采用"大小模型双录"方案。即由传统小模型和GIE大模型分别识别,系统自动比对结果。只有在两者结果不一致时才推送给人工审核,从而构建起数据质量的双重保险,极大降低了人力复核成本。
常见问题 (FAQ)
问题1:OCR大模型的识别准确率具体有多少?
答:根据权威厂商的实测数据,GIE大模型在核心文档类型上表现优异。例如,处理发票财税单据的实体字段精度可达96%,表格精度达到97%;对于各类企业合同和报告,精度可达96%(实体)和98%(表格)。
问题2:部署OCR大模型是否需要非常昂贵的硬件?
答:部署方式灵活且成本可控。GIE可以根据企业需求部署不同参数量的模型,支持在主流的NVIDIA GPU(如T4, A10)或国产硬件上进行私有化部署,确保数据安全。同时,也支持开箱即用的软硬一体机交付模式。
问题3:OCR大模型和传统OCR最大的区别是什么?
答:最大的区别在于通用性和灵活性。传统OCR是"专才",一个模型对应一种版式,新增需求必须重新训练。GIE大模型是"通才",一个模型通过灵活的提示词(Prompt)就能适应所有版式。