前言
因为我司准备于25年7月底复现下NaVILA,而在研究NaVILA的过程中,注意到了这个NaVid
- 虽然NaVid目前已经不是VLN sota了,但其首次展示了VLM在无需地图、里程计或深度输入的情况下,能够实现优秀的导航性能
- 且对后来的很多VLN工作------比如对NaVILA 都有比较大的启发、借鉴意义,且VLN论文中 其实提供了 "不少更好理解NaVILA" 的背景知识或基础,比如VLN-CE、MP3D等等
- 总之,如果相对VLN有相对完整深入的理解,NaVid是必看工作之一
加之导航在人形落地中的重要性,故
一方面,为了加强我司现有同事和将来同事对VLN的深入
故成此文
第一部分 NaVid
1.1 引言与相关工作
1.1.1 引言
如原NaVid论文所述
- 作为具身人工智能的基础任务,视觉与语言导航VLN
32-Vision-and-language navigation: A survey of tasks, methods, and future directions
70-Visual language navigation: A survey and open challenges
要求智能体在多样化且尤其是未见过的环境中,依据自由形式的语言指令进行导航 - 比如VLN要求机器人能够理解复杂且多样的视觉观测,同时解析细粒度的指令
13-Touchdown: Natural language navigation and spatial reasoning in visual street environments
99-Talk2nav: Long-range vision-and-language navigation with dual attention and spatial memory
如"上楼梯并在门口停下",因此该任务始终具有挑战性
为应对这一挑战,大量研究
- 85-Lm-nav: Robotic navigation with large pretrained models of language, vision, and action
- 18-History aware multimodal transformer for vision-and-language navigation
- 104-Scaling data generation in vision-and-language navigation
- 98-Multimodal large language model for visual navigation
- 69-Langnav: Language as a perceptual representation for navigation
- 48-Iterative vision-and-language navigation
- 4-Etpnav:Evolving topological planning for vision-language navigation in continuous environments
在简化场景下展开,即在离散环境中进行决策------例如在MP3D模拟器 *12-Matterport3d: Learning from rgb-d data in indoor environments*中的R2R *46-Beyond the nav-graph: Vision and language navigation in continuous environments*
-
具体而言,真实环境被抽象为连通图,导航过程被建模为在这些图上的航点集之间的跳跃。尽管这些方法发展迅速并取得了令人瞩目的成果
85-Lm-nav: Robotic navigation with large pretrained models of language, vision, and action
121-Navgpt:Explicit reasoning in vision-and-language navigation with large language models
63-Discuss before moving: Visual language navigation via multi-expert discussions
104-Scaling data generation in vision-and-language navigation但离散化的环境设置也带来了额外的挑战,例如,需要使用地标图
45-Beyond the nav-graph: Visionand-language navigation in continuous environments
47-Waypoint models for instruction-guided navigation in continuous environments以及一个用于在地标之间导航的本地模型
84-Ving: Learning open-world navigation with visual goals
87-Gnm: A general navigation model to drive any robot
83-Fast marching methods -
为了实现更为真实且直接的建模,连续环境中的导航(如R2R-CE、RxR-CE)受到越来越多的关注。大量优秀的研究致力于缩小仿真到现实(Sim-to-Real)之间的差距47, 37, 108, 9
然而,由于模型输入中的RGBD、里程计数据或地图等数据稀缺以及领域差异,这些方法在泛化能力上仍面临严重挑战。泛化问题在大规模现实世界部署中,特别是在已见场景到新环境、仿真到现实(Sim-to-Real)等转变过程中,构成了一个关键但尚未充分研究的挑战
-
近年来,大型视觉语言模型(VLMs)的兴起在众多研究领域展现了前所未有的潜力109, 52,3。且大型语言模型(LLMs)已被证明在离散环境中的视觉语言导航(VLN)规划任务中表现出色 63,69, 121, 14, 74
来自1 Peking University、2 Beijing Academy of Artificial Intelligence、3 CASIA、4 University of Adelaide、5 Australian National University、6 GalBot的研究者,首次尝试利用基础VLMs的强大能力,将VLN泛化到现实世界,并提出了一种基于视频的VLM导航智能体,命名为NaVid

- 其对应的项目地址为:pku-epic.github.io/NaVid
- 其对应的paper地址为:NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation
该方法完全依赖机器人单目摄像头捕获的视频和人类发布的指令,作为端到端规划下一步动作的输入
为了更好的阐述清楚NaVid,做个同类对比
- 与AGI模型 109 或所谓的导航通用模型 120 相比,这些模型能进行粗略的导航规划,而NaVid是一个实用的视觉-语言-动作(VLA)模型,能够推理出带有定量参数(如移动距离、旋转角度)的可执行动作,使其能够在真实环境中部署
- 与采用LLM作为规划器的VLN模型相比,NaVid对VLN进行了更为真实的建模
具体而言,NaVid直接在连续环境中推导低层次可执行动作,并以视频形式编码视觉观测,而不是像以往LLM方法那样在离散空间建模VLN或用文本描述编码历史观测 69, 121, 63, 14 - 区别于现有的专用VLN模型,NaVid在动作规划过程中不依赖里程计数据、深度信息或地图,从而避免了由里程计噪声、深度感知或导航地图领域差异带来的泛化难题,使NaVid易于部署
作者宣称,他们所提出的NaVid是首个用于连续环境中VLN的视频VLM,实现了仅凭RGB信息的导航,类似于人类的导航行为
总之,NaVid 利用预训练视觉编码器对视觉观测进行编码,并采用预训练的大型语言模型(LLM)推理导航动作。通过这种方式,大规模预训练中获得的通用知识被迁移到视觉-语言导航(VLN)任务中,从而促进学习并提升泛化能力
受先进的视频基础视觉语言模型 LLaMA-VID 57的启发,作者用两种类型的 token 表示机器人视觉观测中的每一帧
-
第一种为基于指令查询的token,能够提取与给定指令高度相关的视觉特征
-
第二种为与指令无关的 token,能够全局编码细粒度视觉信息,其 token 数量决定了所编码特征的细致程度。历史观测的 token 数量可以与当前观测的不同
因此,在 NaVid 中,机器人的历史轨迹被编码为视频形式的视觉 token ,这相比以往基于 LLM的 VLN 模型中采用离散编码空间18, 19或使用文本描述69, 121, 63, 14的方法,能够提供更丰富且更具适应性的上下文信息总之,这种基于视频的建模对模型输入施加了严格的约束,因为它不涉及除单目视频之外的其他信息,例如深度、里程计数据或地图。如果能够正确利用,这种方法有助于缓解由于里程计噪声以及以往VLN工作中深度感知或导航地图的领域差异所带来的泛化挑战
此外,作者在仿真环境和真实环境中对所提出的 NaVid 进行了大量实验评估
- 具体来说,NaVid 在 VLN-CER2R 数据集上达到了当前最先进(SOTA)水平的性能,并在跨数据集评测(R2R-RxR)中表现出显著提升
- 此外,在仿真到现实(Sim-to-Real)部署中展现出卓越的鲁棒性,在四个不同的室内场景中基于 200 条指令,使用仅 RGB 视频作为输入,成功率约为 66%
1.1.2 相关工作
第一,关于视觉与语言导航(VLN)
- 在离散化的仿真场景中,围绕学习根据人类指令在未访问环境中导航的研究已取得重大进展 7, 49, 72, 97。在这些场景中,智能体通过在预定义导航图上的节点间瞬移,并对齐语言与视觉观测以进行决策 64, 101,27, 96, 42, 29, 71, 35。尽管这种方法高效,但直接将离散空间中训练的VLN模型应用于现实世界的机器人场景并不现实
- 因此,更加贴近真实环境的连续空间视觉与语言导航(VLN-CE)被提出 45, 81,允许智能体通过预测低层控制指令78, 40, 15, 31, 16 ,或由航点预测器估算的可导航子目标中选择,自由地导航到模拟器中任何无障碍空间 37, 47, 44
- 与此同时,得益于从大规模网页图文对中学习通用视觉-语言表征的成功20, 56, 91, 53, 95,许多VLN模型受益于大型视觉-语言模型 55, 36, 18, 19 及针对VLN的预训练 34, 67, 33, 107, 73
最近,通过扩展导航训练数据,VLN智能体在广泛认可的R2R基准 46上的表现已接近人类水平 104。这一重大进展表明,将VLN技术应用于现实世界机器人已变得日益可行且时机成熟
第二,对于仿真到现实的VLN迁移
尽管取得了巨大进展,现有VLN方法主要在仿真环境中构建和评估,极大忽略了现实世界环境的复杂性和不可预知性
-
仿真到现实的VLN迁移仍是一个研究不足的话题;迄今为止,唯一系统性研究该问题的文献来自Anderson等人 8,其论证了由于动作空间和视觉域的差异,成功率下降超过50%的性能差距
此外,还需强调泛化到自由形式语言指令的挑战------即使在数百万域内视觉数据上训练,智能体也常常无法理解不同风格的指令 104, 41 -
鉴于此,许多最新研究利用大型(视觉)语言模型卓越的泛化能力来促进VLN(视觉语言导航)的泛化
相关研究
要么考察LLMs(大型语言模型)本身所具备的导航推理能力121, 69, 120, 63, 14, 82, 58
要么通过模块化设计将LLMs集成到导航系统中,以便于指令解析17,或通过注入常识知识74来增强系统能力作者遵循这一趋势,进一步探索如何利用统一的大模型进行低层级动作预测,以及其在真实场景中的泛化能力。该方法旨在通过利用LLMs的全面理解和多样化能力121, 69, 120, 63,14, 74,不仅推动VLN领域的发展,还弥合仿真环境与现实应用中多样化挑战之间的差距
第三,对于大型模型作为具身智能体
-
近年来,研究者开始探索将大型模型集成到不同的具身智能领域26, 121,59, 86, 90, 82, 39。例如,PaLM-E26提出将多种模态的token(包括文本token)输入到大型模型中,然后模型为移动操作、运动规划等任务生成高层次的机器人指令以及桌面操作
-
更进一步,RT-2 11 为机器人生成低层次动作,实现闭环控制
GR-1 106 引入了一种专为多任务语言条件视觉机器人操作111 设计的 GPT 风格模型 75, 121, 63。该模型能够根据语言指令、观测到的图像和机器人状态预测机器人动作及未来图像RoboFlamingo54 提出了一个视觉-语言操作框架,利用预训练的视觉-语言模型来制定机器人操作策略。其目标是为机器人操作提供一种高性价比、高性能的解决方案 22, 94, 111, 89,允许用户通过大模型对机器人进行微调
EMMA-LWM 112 通过语言交流开发了面向驾驶智能体的世界模型,并在数字游戏环境中展现了令人信服的结果100
深入探讨这些工作后,本文聚焦于另一个关键的具身领域:视觉与语言导航,该任务要求机器人在未知环境中根据人类指令完成导航
1.1.3 问题表述
本工作的连续环境下视觉与语言导航(VLN-CE)任务表述如下:
- 在时刻
以及由一系列帧
智能体需要为下一步规划一个低级动作
该动作将使智能体到达下一个状态,并获得新的观测 - 总体而言,可以将决策过程表述为一个部分可观测马尔可夫决策过程(POMDP),记作
在本工作中,观测空间
这种建模方式实现了一种自然的范式,其中观测完全基于视觉且易于获取,而动作则可以直接执行,类似于人类的导航行为
1.2 Navid的完整方法论
1.2.1 总体架构
通过上文已知,NaVid是首个将VLM通用知识迁移到现实视觉语言导航VLN智能体的系统
作者在通用型视频视觉语言模型 LLaMA-VID 57的基础上构建了 NaVid。对于他们提出的NaVid,他们继承了 LLaMA-VID 的主要架构,并在此基础上融入了任务特定的设计,从而促进通用知识向 VLN-CE 的迁移,使其泛化难题更易解决
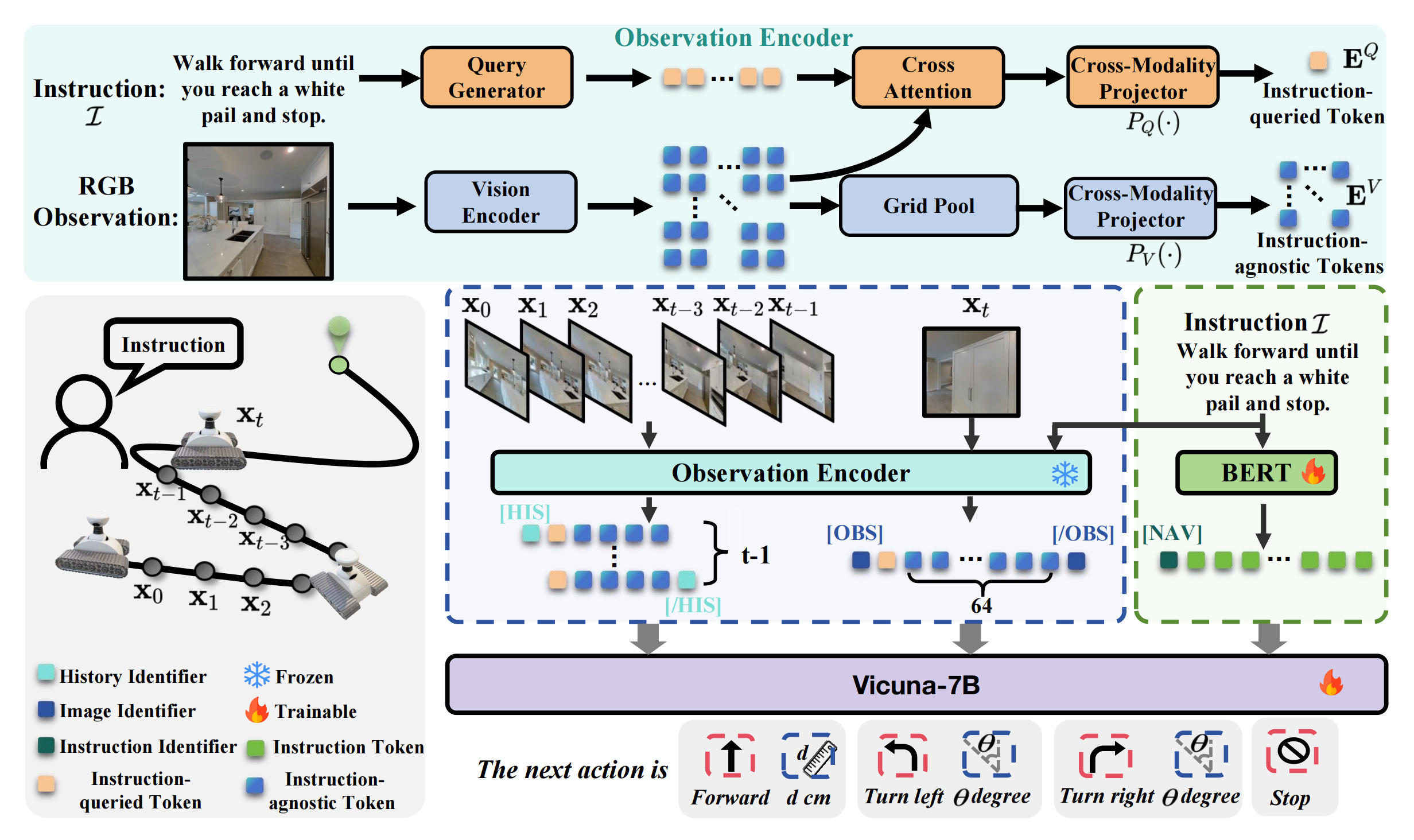
如图2所示『1 NaVid的输入包括来自在线视频观测的RGB帧以及人类指令
。对于每一帧,使用观测编码器结合指令提取视觉信息,获得观测token,包括指令query token(橙色块)和指令无关token(蓝色块)。在当前时刻t,历史帧
和当前帧
被分别编码为观测token,历史帧有4个指令无关token,当前帧有64个指令无关token。2 ,作者的方法通过文本编码器获得语言token。3 最后,通过特殊token HIS、**OBS** 和 **NAV** 进行分割,将观测token 与语言token拼接后输入Vicuna-7B,从而获得下一步动作』
-
NaVid 由视觉编码器、查询生成器、大型语言模型(LLM)和两个跨模态投影器组成
给定截至时间 t 的观测,即包含为简明起见,作者将投影后的token称为观测token
通常,指令也被分词为一组token,称为指令token -
作者将观测token与指令token拼接后输入 LLM,以推断出以语言形式表达的VLN 行为
需要注意的是,作者的工作重点在于任务特定建模,而非模型架构,详见下文
1.2.2 NaVid 的 VLN-CE 建模:涉及观测编码和动作规划
首先,对于观测编码
给定截至时刻的捕获单目视频,记为
,作者用一个指令查询的视觉token和若干个与指令无关的视觉token来表示每一帧「we represent each frame with one instruction-queried visual token and several instruction-agnostic visual tokens」
被指令查询的token 提取与给定指令特定相关的视觉特征,而与指令无关的token则全局编码细粒度的视觉信息
对于每一帧,首先通过视觉编码器获得其视觉嵌入
,其中Nx为patch 数量------
设置为256,
为嵌入维度
-
++为了获得指令查询的tokens++,作者采用基于Q-Former的查询生成器,利用查询生成器
查询生成过程可表述为:
其中
与57 中的方法类似。类似于Q-Former 52 中的操作,指令查询的tokens
其中, -
++对于与指令无关的token++,作者直接进行网格池化操作和跨模态投影以获得它们,可以表示为
其中GridPool (·) 是一种网格池化操作57,将tokens 从
关于网格池化的详细描述可以在补充材料中找到注意,像LLaMA-VID 57 那样用两个tokens 表示每一帧并不满足VLN-CE 任务的要求,正如下文实验所证实的那样。这是因为LLaMA-VID 主要面向高层次的问答任务,而NaVid 需要为机器人规划可执行的动作。因此,作者在此采用网格池化,使与指令无关的tokens 能够保留足够的几何信息,从而使NaVid 中的LLM 拥有足够的上下文来推理机器人动作的定量参数
对于VLN-CE,当前帧作为导航动作推理的主要依据,而历史帧则为追踪导航进度提供了重要的上下文。鉴于它们在保持几何信息方面的不同需求,作者在对历史帧和当前帧进行编码时采用了不同数量的与指令无关的token。在本研究中,除非另有说明,作者将当前帧的与指令无关的token数量设置为64,而每个历史帧设置为4。这不仅有助于模型学习,还提升了效率
此外,为了进一步促进NaVid的训练,作者在将不同类型的信息输入NaVid内部的大语言模型(LLM)之前,通过特殊token对其进行明确区分
-
具体而言,作者采用特殊token
其中,
而 -
此外,他们还使用另一个特殊token
因此,NaVid 的输入可以总结如下Input: <HIS > {historical frames} </HIS ><OBS > {current frame} < /OBS >) < NAV >{instruction content} Output: {answer content}在此格式中,{历史帧{historical_frames}、{当前帧{current_frame}、{指令内容instruction _content}和{答案内容answer_content}分别代表历史帧、当前帧、指令和推理动作的占位符
其次,对于动作规划
NaVid以语言形式为VLN-CE规划下一步动作。其每一步输出的动作均由两个变量组成,与VLN-CE的设定保持一致
- 其中一个变量为动作类型,从离散集合
- 另一个变量为与不同动作类型对应的定量参数
对于FORWARD,NaVid进一步推断具体的移动距离;
对于TURN-LEFT和TURN-RIGHT,NaVid还预测具体的旋转角度
系统采用正则表达式解析器43,用于提取动作类型和参数,以便模型评估及实际部署
1.2.3 NaVid的训练:涉及非专家导航轨迹收集、VLN-CE与辅助任务的联合训练
现有的导航仿真数据在多样性、真实性和规模上仍然有限。作者设计了一种混合训练策略,以最大化这些数据的利用率,使NaVid能够尽可能有效地泛化到新场景或现实世界
为此,混合训练策略提出了两种关键方法:
- 一是收集非oracle导航轨迹并将其纳入训练循环;
- 二是设计辅助任务,以提升NaVid在导航场景理解和指令执行方面的能力
1.2.3.1 非专家导航轨迹收集
受 Dagger 技术 80 启发,作者收集了非专家导航轨迹,并将其纳入NaVid 的训练过程中。如果不采用这种方法,NaVid 在训练期间只能接触到专家导航轨迹,这与实际应用环境不符,并且会降低所学导航策略的鲁棒性
为此,作者首先收集专家导航轨迹,包括单目视频观测、指令和机器人动作,来自于VLN-CE R2R数据集
-
具体来说,作者从61个MP3D室内场景12中收集数据,总计包含32万步级样本
-
随后,在这些oracle轨迹数据上训练NaVid,并将获得的智能体部署到VLN-CE环境中,进一步收集非oracle导航轨迹
-
最终,获得了另外18万步级样本。来自oracle和非oracle轨迹的样本被合并,用于NaVid的最终训练,如图3上方所示

用户 :假设你是一台被编程用于导航任务的机器人
你获得了一段历史观测的视频和一张当前观测的图像<image>
你的任务是:向前走,进入并沿着工作区中间前进。一直向前走,直到你到达地板上靠近带有黑色椅子的桌子旁的一个白色水桶处并停下
++分析这一系列图像,以决定你的下一个动作++,该动作可能包括向左或向右转动特定角度,或向前移动一定距离
助手:下一个动作是向前移动75厘米
1.2.3.2 VLN-CE与辅助任务的联合训练
作为导航智能体,除了规划导航动作外,精确理解环境和遵循给定指令是两项不可或缺的能力。为促进智能体学习,作者将VLN-CE动作规划与两个辅助任务结合,以协同训练的方式进行
-
针对环境理解,作者设计了一个名为指令推理的辅助任务。给定一个基于视频的导航轨迹,NaVidis 被要求推导出该轨迹对应的指令
该辅助任务可以通过上文1.2.2节(原论文第四节 B 部分)介绍的共享数据组织格式轻松实现,其中{instruction content}和{answer content}可以分别实例化为请求描述机器人导航轨迹的提示和数据集中提供的人类标注指令
指令推理辅助任务包含 1 万条轨迹,示例见图 3 下方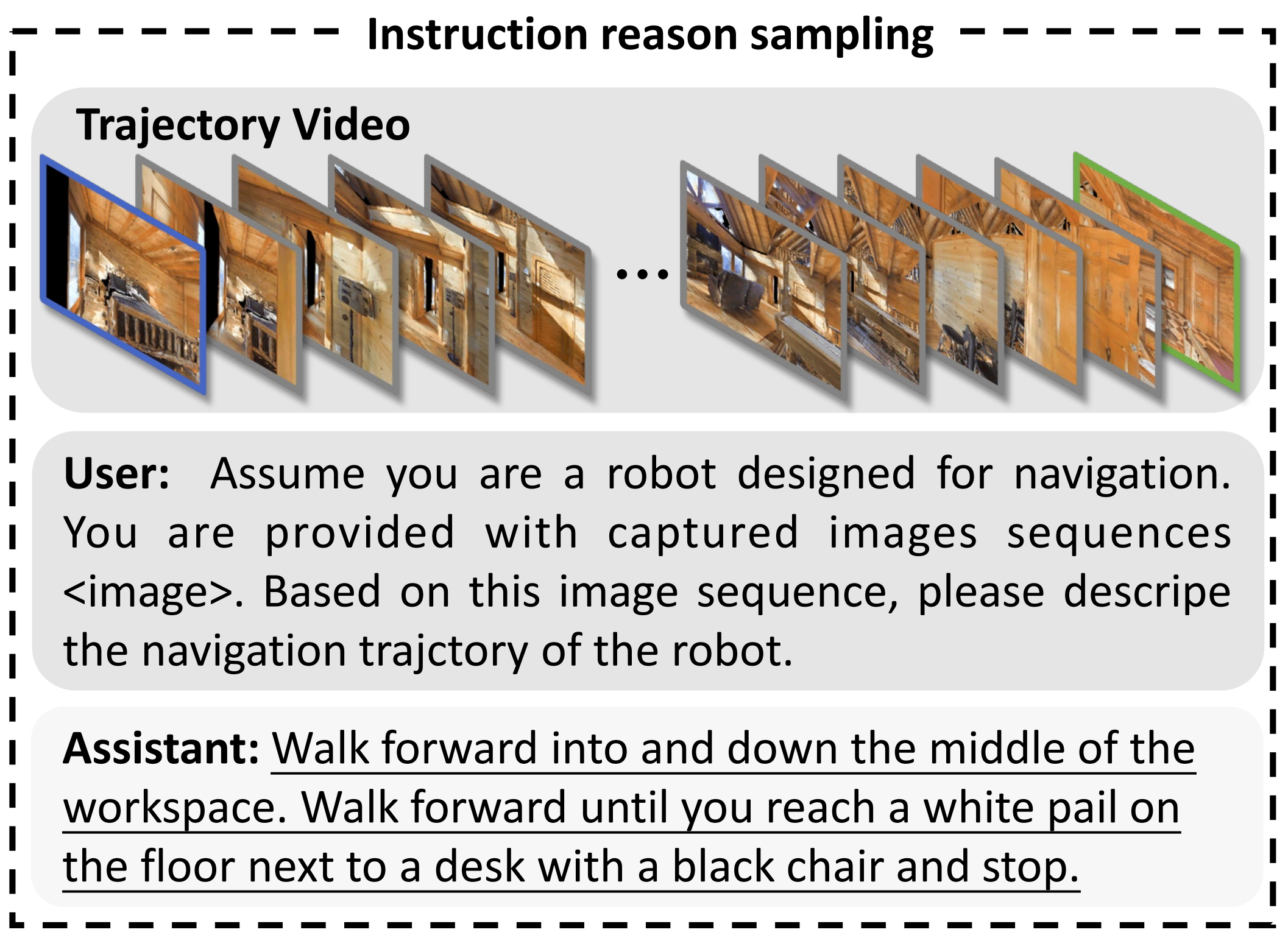
用户 :假设你是一台为导航设计的机器人。
你获得了一组捕获的图像序列<image>。 请根据该图像序列,描述机器人的导航轨迹。助手 :向前走,进入并沿着工作区中间前进。向前走,直到你到达地板上靠近带有黑色椅子的书桌旁的一个白色桶,然后停下
-
此外,为了增强指令跟随能力并防止在预训练中获得的通用知识遗忘,作者还将基于视频的问答样本纳入联合训练。详细信息可参见文献57。为简明起见,此处不再赘述
1.2.4 实现细节:训练配置、评估配置
- 对于训练配置
NaVid 在一台配备 24 块 NVIDIA A100GPU 的集群服务器上训练约 28 小时,总计 672GPU 小时
对于视频-字幕数据,以 1 帧每秒的速率采样帧,以去除连续帧之间的冗余信息。对于导航-动作数据,保留所有帧,通常不超过 300帧
在训练过程中,所有模块,包括 EVA-CLIP92、QFormer 23、BERT 24 和 Vicuna-7B21,均加载默认的预训练权重。按照文献 57 的策略,作者仅优化 LLaMA 和文本编码器的可训练参数,且仅训练 1 个 epoch - 评估配置
在NaVid预测语言动作后,作者利用正则表达式匹配43来期望获得有效动作。作者发现,这一简单算法在VLN-CE val-unseen R2R评估中获取有效动作的成功率达到100%。在真实世界导航中,使用远程服务器运行NaVid,以接收观测数据(以及文本指令),并控制本地机器人执行预测的动作
在导航过程中,智能体每帧输出一个动作大约需要1.2到1.5秒。通过采用如量化61, 60等加速技术,这一速度有望进一步提升
// 待更