这篇论文是2025年发表在arxiv上的一个3D VLA论文,稍微有一种大力出奇迹的感觉,3D感知部分将点云转到同一个坐标系下,然后用 Uni3D 进行编码;语言指令直接用 CLIP 输出不参与训练;整体模型还是需要大量的泛化场景进行预训练,然后针对不同的任务进行微调,但作者说微调后可以很好的泛化到不同场景以及物体上;
写在最前面
为了方便你的阅读,以下几点的注意事项请务必了解:
- 该系列文章每个字都是我理解后自行翻译并写上去的,可能会存在笔误与理解错误,如果发现了希望读者能够在评论区指正,我会在第一时间修正错误。
- 阅读这个系列需要你有基本的 VLN, LLM, VLM 相关基础知识,有时候我会直接使用英文名词,因为这些词汇实在不容易找到符合语境的翻译。
- 原文可能因为版面限制存在图像表格与段落不同步的问题,为了更方便阅读,我会在博文中重新对图像表格进行排版,并做到引用图表的文字下方就能看到被引用的图表。因此可能会出现一张图片在博客中多处位置重复出现的情况。
- 对于原文中的图像,我会在必要时对图像描述进行翻译并附上我自己的理解,但如果图像描述不值得翻译我也不会强行写上去。
Basic Information
- 论文标题:FP3: A 3D Foundation Policy for Robotic Manipulation
- 原文链接: https://arxiv.org/abs/2503.08950
- 发表时间:2025年03月11日
- 发表平台:arxiv
- 预印版本号:v1 Tue, 11 Mar 2025 23:01:08 UTC (10,815 KB)
- 作者团队:Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever
- 院校机构:
- Tsinghua University, IIIS;
- Shanghai AI Laboratory;
- Shanghai Qi Zhi Institute;
- UC San Diego;
- 项目链接: https://3d-foundation-policy.github.io
- GitHub仓库: https://github.com/horipse01/3d-foundation-policy
Abstract
继自然语言处理和计算机视觉领域取得成功后,基于大规模多任务数据集预训练的基础模型在机器人技术领域也展现出巨大潜力。然而,现有的大多数机器人基础模型仅依赖于2D图像观测,而忽略了三维几何信息,而这些信息对于机器人感知和推理三维世界至关重要。本文介绍了 FP3,这是首个用于机器人操控的大规模三维基础策略模型。FP3 基于可扩展的difussion transformer架构,并使用点云观测数据在 6 万条轨迹上进行预训练。凭借合理的模型设计和丰富的预训练数据,FP3 可以高效地针对下游任务进行微调,同时展现出强大的泛化能力。在真实机器人上的实验表明,仅需 80 次演示FP3 就能在包含未知物体的新环境中以超过 90% 的成功率学习新任务,显著超越现有的机器人基础模型。可视化效果和代码可访问项目网站:https://3d-foundation-policy.github.io。
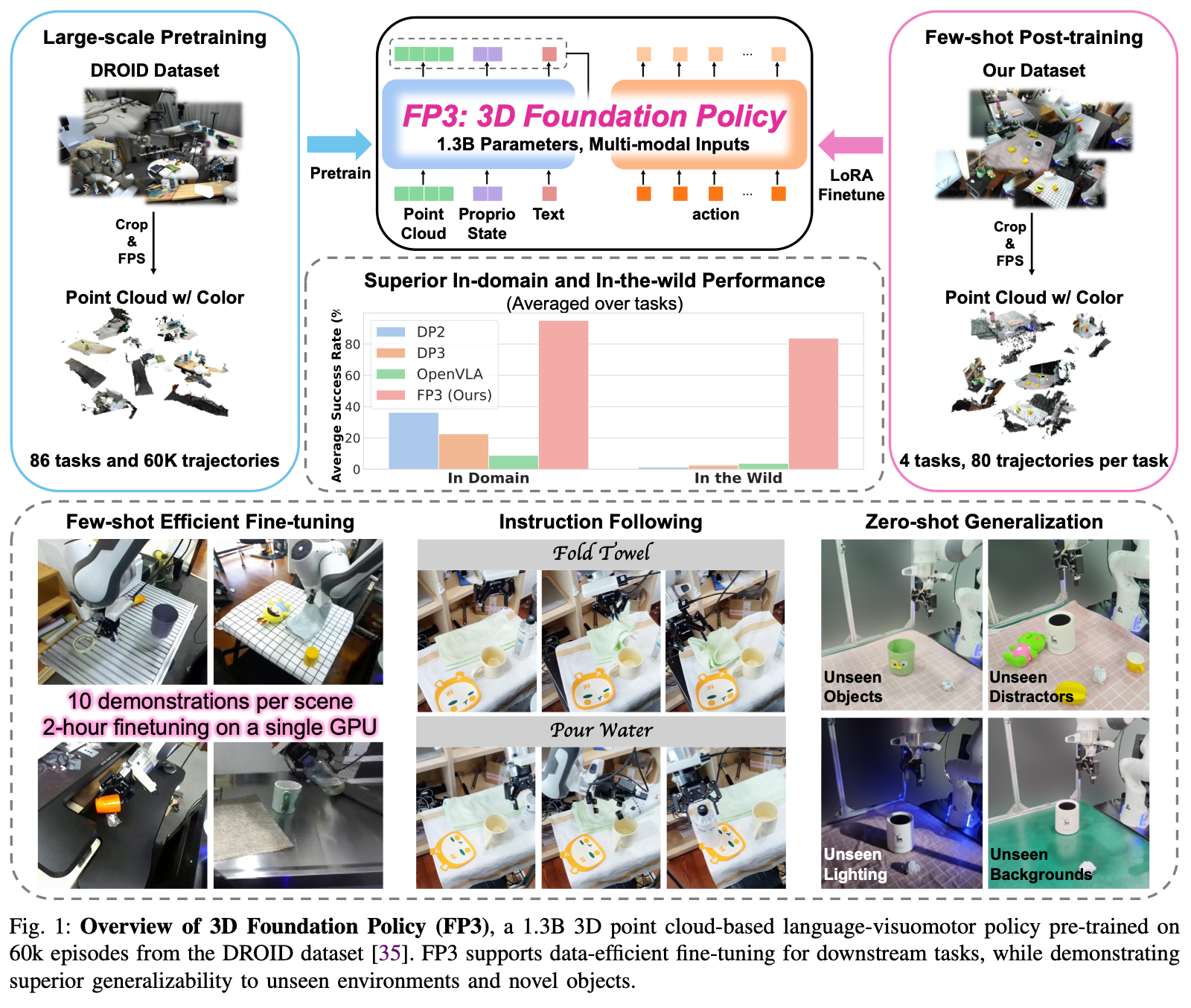
1. Introduction
基于学习的策略已在机器人操控领域展现出卓越的效果。然而,这些学习到的策略通常对未知场景、新物体、干扰因素表现出有限的泛化能力甚至为零。此外,目前大多数方法都针对单一或少数任务进行训练,需要相对大量的专家演示(通常约 200 个回合)才能学习一项新任务。相比之下,自然语言处理 (NLP) 和计算机视觉 (CV) 在开发基础模型方面取得了显著成功,这些模型可在大规模数据和多样化任务上进行训练,使其能够泛化到任意自然场景。因此,在机器人操控领域构建类似的基础模型,使其能够泛化到新的物体、场景和任务,成为一个极具前景的课题。
为了实现策略基础模型的目标,一些学者对VLA 模型进行了初步尝试。这些模型以基于互联网规模的视觉和语言数据训练的VLM为基础,继承常识性知识,并在大规模机器人数据集上对 VLM 进行微调。同时,诸如 RDT 之类的研究尝试扩展扩散模型以构建基础策略。尽管取得了显著进展,但面对新的任务、物体、场景、摄像机视角等,它们的泛化能力仍然有限。
当前策略基础模型的一个潜在局限性是它们完全依赖于2D图像观测,缺乏三维观测输入。然而,三维几何信息对于感知三维环境和推理空间关系至关重要。已有研究表明,三维表征可以提高机器人操作策略的采样效率和泛化能力。在所有三维表征(例如RGB-D图像、点云、体素和三维高斯分布34)中,点云被发现是最有效的。
在本研究中,作者提出了 3D 基础策略 (FP3),这是第一个基于 3D 点云的机器人操作语言-视觉运动策略基础模型,展现出强大的泛化能力和高效的采样效率。为了从 3D 点云观测中提取丰富的语义和几何表征,FP3 采用了预训练的大规模点云编码器 Uni3D。进一步利用编解码器Diffusion Transformer(DiT) 架构来整合点云表征、语言向量、本体感觉,从而对动作进行去噪。
仿照LLM的常见做法对FP3 进行预训练和后训练,即在大规模多样化语料库上对模型进行预训练,并在精选的任务特定数据上进行微调以适应下游任务。首先在大规模机器人操作数据集 DROID上对 FP3 进行预训练,该数据集包含来自 564 个场景和 86 个任务的 76k 条演示轨迹或 350h 交互数据。然后,为多个任务采集少量高质量的遥操作数据并对 FP3 进行微调。结果表明,模型仅使用 80 条训练后轨迹即可高效掌握新任务,并且能够对新物体和环境进行零样本泛化,成功率约为 90%。相比之下 DP3 和 OpenVLA 这样的baseline在这种环境下几乎完全失败。由于 3D 表征的优势,FP3 对背景变化、光照条件、摄像机角度、干扰因素也具有良好的鲁棒性。最后,进行了消融研究,以证明 3D 表征、数据缩放和模型缩放均有助于提升模型的性能。
作者的主要贡献总结如下:
- 提出了一种新颖的基于扩散的 3D 机器人策略架构
FP3; - 使用的大规模3D 观测机器人操作数据对
FP3进行预训练,建立了 1B 参数 3D 策略基础模型; - 采集了几个新任务的数据,并展示了
FP3的高效和可推广的微调,仅通过 2 小时和单 GPU 微调,就实现了在baseline上平均约 60% 的域内性能提升和 80% 的野外性能提升;
2. Related Work
A. Foundation Models in Robotics
与自然语言处理和计算机视觉中的情况类似,基础模型已广泛应用于机器人技术的多个方面,包括表示学习、高级任务规划、免训练机器人操作等。本文专注于机器人中的策略基础模型,这些模型也经常指在大规模机器人数据集上训练的多任务"通才"机器人策略。策略基础模型的一个重要子集包括自回归VLA 模型,如 RT-2 和 OpenVLA,它们直接微调预先训练的大型VLM,通过将离散化动作视为语言标记来预测动作。最近,RDT 扩展了扩散transformer,以构建双手操作的基础模型。另一项近期研究 π 0 \pi0 π0研究了预训练的 VLM 主干网络与扩散模型的组合,用于机器人控制。作者的研究在架构方面与 RDT 最为相似,因为两者都建立在扩散transformer的基础上,但也存在一些关键差异,例如条件反射模块。RDT 采用交叉注意模块,而这里选择 adaLN 模块来稳定训练。
除了架构之外,这些方法与 FP3 的一个关键区别在于观察方式。与这些均以 2D 图像观测作为输入的研究不同,作者的研究利用 3D 点云观测来增强对 3D 几何信息的感知和空间关系的推理,从而为作者所知的首个具有 3D 表示的策略基础模型奠定了基础。
B. Robotic Manipulation with 3D representations
与2D图像相比,RGB-D 图像、点云、体素等 3D 表示包含更丰富的几何信息,因此广泛应用于机器人操控。Kite 直接利用 RGB-D 观测进行语义操控。其他研究从 RGB-D 图像重建点云,并使用点云编码器对其进行处理以进行操控。将点云体素化以供感知也是一个可行的解决方案。另一组研究 将二维图像特征提升到三维空间,以利用语义和几何信息。人们也尝试将隐式或显式三维重建(NeRF、3D gaussians)与机器人操作相结合。在本研究中,选择点云作为三维表示,因为在DP3中被发现相比较其他表示更有效。
尽管表征方式存在差异,但上述所有方法均由在有限数量任务上训练的小型网络组成。FP3 与这些方法在多个方面有所不同:它是一个在大型多任务数据集上训练的基础模型,将点云编码器扩展到 3 亿个参数,将整个网络扩展到 13 亿个参数,并且支持针对新任务进行高效且可泛化的微调。
C. Diffusion models in Robotics
扩散模型通过渐进式去噪对复杂的高维连续分布进行建模,在图像生成和视频生成中取得了巨大成功。由于其卓越的表现力,扩散模型也被应用于机器人技术的各个领域,包括强化学习、模仿学习 、运动规划。作者的工作重点是"扩散策略",它是指直接采用条件扩散模型作为模仿学习的视觉运动策略模型的方法。与本文的工作最密切相关的是 RDT 一个用于操作的扩散基础模型,与 RDT 的一个主要区别在于,FP3 模型利用 3D 点云表示来实现更高的数据效率和泛化能力。
3. Method
介绍用于通用机器人操作的 3D 基础策略 (FP3) 模型,该模型实现了高数据效率和泛化能力。FP3 是一个 1.3B 的 encoder-decoder Transformer 网络,遵循两阶段预训练和后训练方案。首先在第三部分 A 中提供 FP3 的详细架构和关键设计决策;然后,分别在第三部分 B 和第三部分 C 中描述预训练和后训练流程。
A. FP3 model
FP3 的核心是一个基于扩散的策略模型,它将 3D 点云观测、语言、机器人本体感受状态作为输入,并预测未来动作的动作块。将语言条件下的视觉运动控制问题形式化为对分布 p ( A t ∣ o t ) p(A_{t}|o_{t}) p(At∣ot) 进行建模,其中 o t = P t 1 , ... , P t n , l t , q t o_{t}=P\^{1}_{t},\\dots,P\^{n}_{t},l_{t},q_{t} ot=Pt1,...,Ptn,lt,qt 为时间 t t t 的观测,包括来自第 i i i 个摄像机的点云观测 P i t P{it} Pit(包括历史观测信息)、语言指令 l t l_{t} lt、本体感受信息 q t q_{t} qt、预测动作块 A t = a t , a t + 1 , . . . , a t + H − 1 A_{t} = a_{t}, a_{t+1}, ..., a_{t+H-1} At=at,at+1,...,at+H−1。训练一个去噪扩散概率模型 (DDPM) 来近似条件分布,并使用去噪扩散隐式模型 (DDIM) 方法来加速推理。
现在描述 FP3 模型的详细结构,包括多模态输入的编码和基于 Transformer 的encoder-decoder架构。
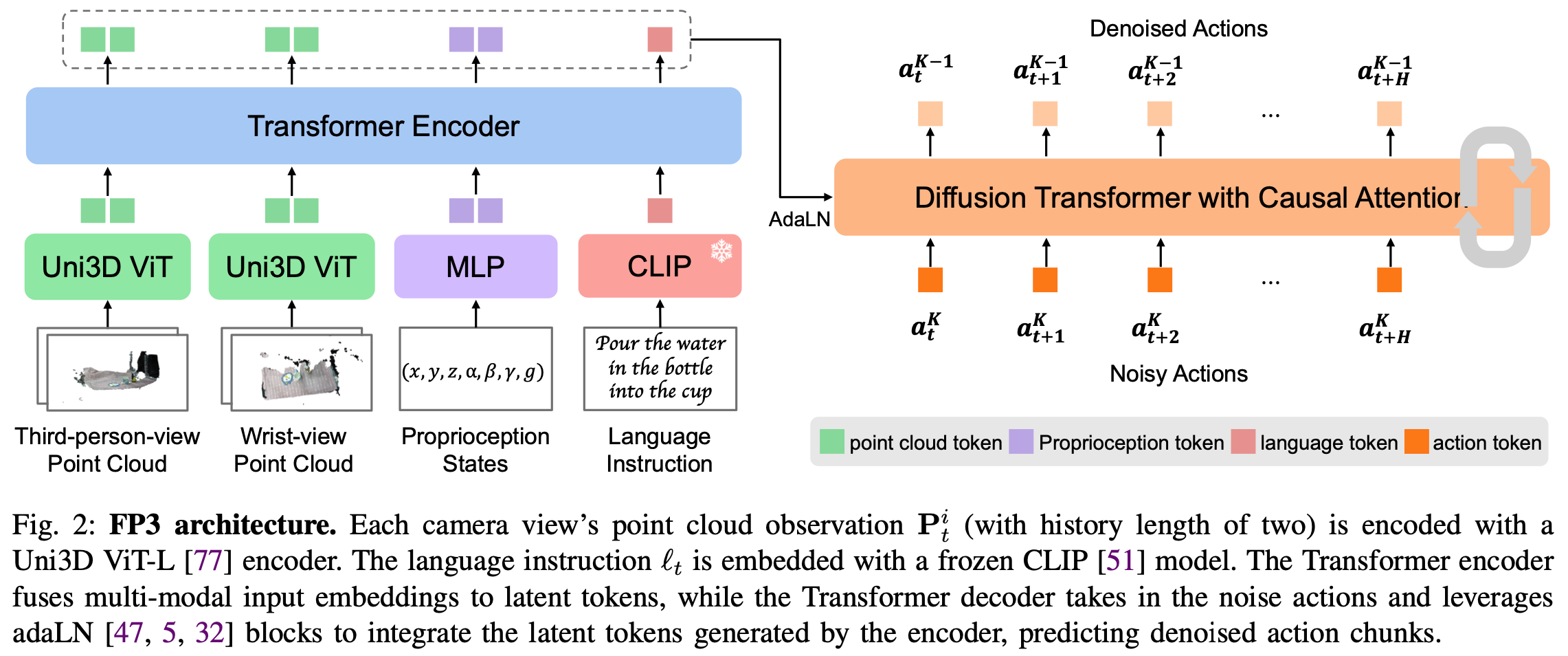
Encoding of multi-modal inputs
为了处理多模态输入,将输入信号编码到具有相同维度的统一标记空间中,如下所示:
- Point cloud observations :包含丰富的语义和几何信息,与其他 3D 表示相比更适合策略学习。使用点云作为
FP3中的 3D 表示。当前基于点云的机器人策略通常使用稀疏点云和小型网络(如PointNet++和PointNeXt)将点编码为嵌入。然而,预训练的大规模基础视觉编码器已被证明在基于图像的策略中具有优于小型编码器的性能。因此,这里将每个视图的输入点数量增加到 4000 个,并使用 300M 参数点云编码器Uni3D ViT,该编码器经过预训练以将 3D 点云特征与图像文本对齐特征以获得点云嵌入。对于第三人称视角和手腕视角点云,使用单独的编码器,因为它们的点分布可能有很大差异。策略训练期间对Uni3D ViT的权重进行微调; - Language instructions :语言指令仅使用
CLIP模型进行编码,以便与Uni3D保持一致。由于语言嵌入已经训练完毕,因此权重在训练过程中是冻结的; - Low-dimensional inputs:分别用双层 MLP 处理包括机器人本体感受状态和噪声水平在内的低维输入;
Encoder-decoder structure
由于Diffusion Transformers 在图像生成和策略学习中展现出卓越的可扩展性,作者采用了 Transformer 架构并将其扩展至 FP3。为了更好地融合点云、语言、本体感受状态嵌入,采用了 Transformer encoder-decoder架构。具体来说,FP3 首先将所有嵌入输入到 Transformer encoder中,生成一系列信息丰富的潜在标记。
FP3 的扩散降噪器是一个 Transformer decoder,通过时间因果mask对动作块进行降噪。为了将包含多模态信息的潜在标记注入降噪器,FP3 采用了自适应层范数 (adaLN) 模块进行条件反射,该模块已被证明对于在图像生成和策略学习中实现扩散训练至关重要。
B. Pre-training
Pre-training data
要构建 3D 策略基础模型,需要在大规模 3D 机器人操作数据集上训练模型。然而,大多数现有的大规模机器人数据集(如 Open X-Embodiment )主要都是 2D 数据集。因此,在本研究中使用 DROID 数据集对 FP3 进行预训练,该数据集包含 86 个任务和 76,000 个演示,并提供深度观察数据。使用 DROID 数据集中的 60,000 个演示对 FP3 进行预训练。
Data pre-processing
DROID 使用三个摄像头收集数据,在 FP3 中只使用了其中两个:一个第三视角摄像头、一个腕视摄像头。使用 RGB 图像和深度图恢复每个摄像头的 3D 点云,并将两个点云转换到同一个世界坐标系下。由于只关心操作的物体,因此裁剪了 1 米框外的点以去除冗余点。通过最远点采样FPS将每个点云下采样至 4000 个点,以便在保留足够信息的同时进行模型训练。保留每个点的颜色通道,以便进行进一步的以颜色为条件的实验。
Pre-training details
先前的研究发现,冻结预训练的视觉编码器可能会损害策略性能,因此在预训练期间对 Uni3D ViT 编码器进行了微调,同时在训练过程中随机丢弃一些数据点以进行增强,丢弃率在 0 到 0.8 之间随机选择。
使用 AdamW 优化器和余弦学习率策略。权重衰减设置为 0.1,梯度裁剪设置为 1.0。FP3 基础模型使用 8 块 NVIDIA A800 GPU 进行预训练,训练步长为 3M,批次大小为 128,耗时约 48 小时。在单块 NVIDIA A800 GPU 上对同一模型进行微调大约需要 2 小时,通过多 GPU 训练可以进一步加快速度。
为了处理偏置观察叠加 2 帧作为输入(包含 1 步观察历史)以补偿机器人缺失的动态信息。
C. Post-training
在获得预训练的基础模型后进一步采用后训练流程,使用少量高质量数据使模型适应特定任务。与大多数现有机器人基础模型所采用的微调设置不同(这些模型要么专注于微调模型以适应新的机器人设置,要么专注于在固定环境中学习新任务),作者的目标是微调模型以解决任何环境中任何物体上的特定任务。
作者采集了机器人设置中每个下游任务的数据,目标是增强环境和物体的多样性,而不仅仅是增加同一场景中的演示数量。对于每个任务,在 8 个环境中分别使用 8 个不同物体收集 10 个遥操作演示,总共 80 个演示。然后,使用参数高效的微调策略 LoRA 基于这些数据对基础模型进行微调。得益于预训练的有效初始化,这些少量的微调数据使得零样本部署到新的环境和物体成为可能。
4. Experiments
对真机进行了四项下游任务的实验,以研究以下问题:
FP3能否针对新任务进行有效微调;- 与现有的模仿学习策略相比,经过微调的
FP3对未见过的物体和场景的泛化效果如何; FP3对环境扰动(例如光照、摄像机视角、干扰因素等)的鲁棒性如何;FP3能否按照语言指令正确执行相应的任务;
A. Experimental Setups
Real robot setup
在 DROID 数据集上预训练 FP3 模型的同时还构建了一个类似于 DROID 的真机设备,用于评估下游任务。该装置包含一个 Franka Emika Panda 机械臂配备 Robotiq 机械手,安装在可移动的桌面上;为了进行点云观测,使用一个 ZED mini 摄像头(腕部视角)和一个 ZED 2 摄像头(第三人称视角);Meta Quest 2 VR 头显来远程操控机器人。将绝对笛卡尔空间控制记录为策略训练和部署的动作空间。更多详细信息请参阅附录。
Tasks
选择四个下游任务来评估模型和基线:
- Fold Towel:在平面上从右向左折叠一条长毛巾;
- Clean Table:捡起一张皱巴巴的纸并将其放入桶中;
- Stand up Cup:将杯子直立放置在平坦的表面上;
- Pour Water:拿起一个水瓶,将水瓶中的水倒入杯中,然后将水瓶放在杯垫上;
Fig.3展示了这四项任务的流,更多详细信息请参见附录。

Baselines
为了全面评估 FP3 对比了三个基线:
- Diffusion Policy (DP):一种基于扩散的经典模仿学习策略,以二维图像作为观察输入;
- DP3:DP 的替代版本,将 2D 图像观察转变为 3D 点云,并设计了一个轻量级编码器对点云进行编码;
- OpenVLA:最广泛使用的基于图像的VLA模型;
这三个基线分别代表一个小型二维策略、一个小型3D策略、一个大型2D基础策略。对于 DP 和 DP3,与 FP3 相同的方式添加了一个语言调节模块,以融合语言指令。
Metrics
将成功率作为矩阵进行统计,Table.1中的结果为20次评估试验的平均值。
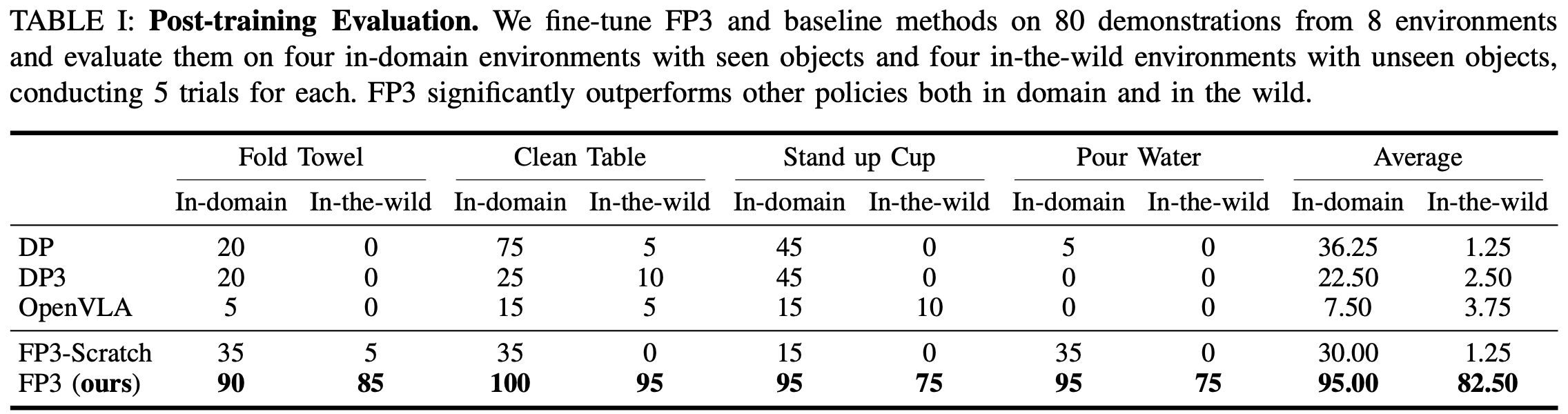
B. Efficient and generalizable fine-tuning for new tasks
首先评估 FP3 高效学习新任务的能力。为 8 对环境-对象对采集 10 个演示,从而为每个任务获得总共 80 个演示。对于 DP 和 DP3 使用这些演示来训练策略;OpenVLA 和 FP3 对每个任务的基础模型进行微调。从头开始训练 FP3 以验证预训练的必要性。
对于每个任务,不仅在四个可见对象的域内环境中评估所有策略,而且还在四个具有不可见对象的域外环境中对它们进行零样本部署,这对模型的泛化能力来说是一个巨大的挑战。
In-domain Performance
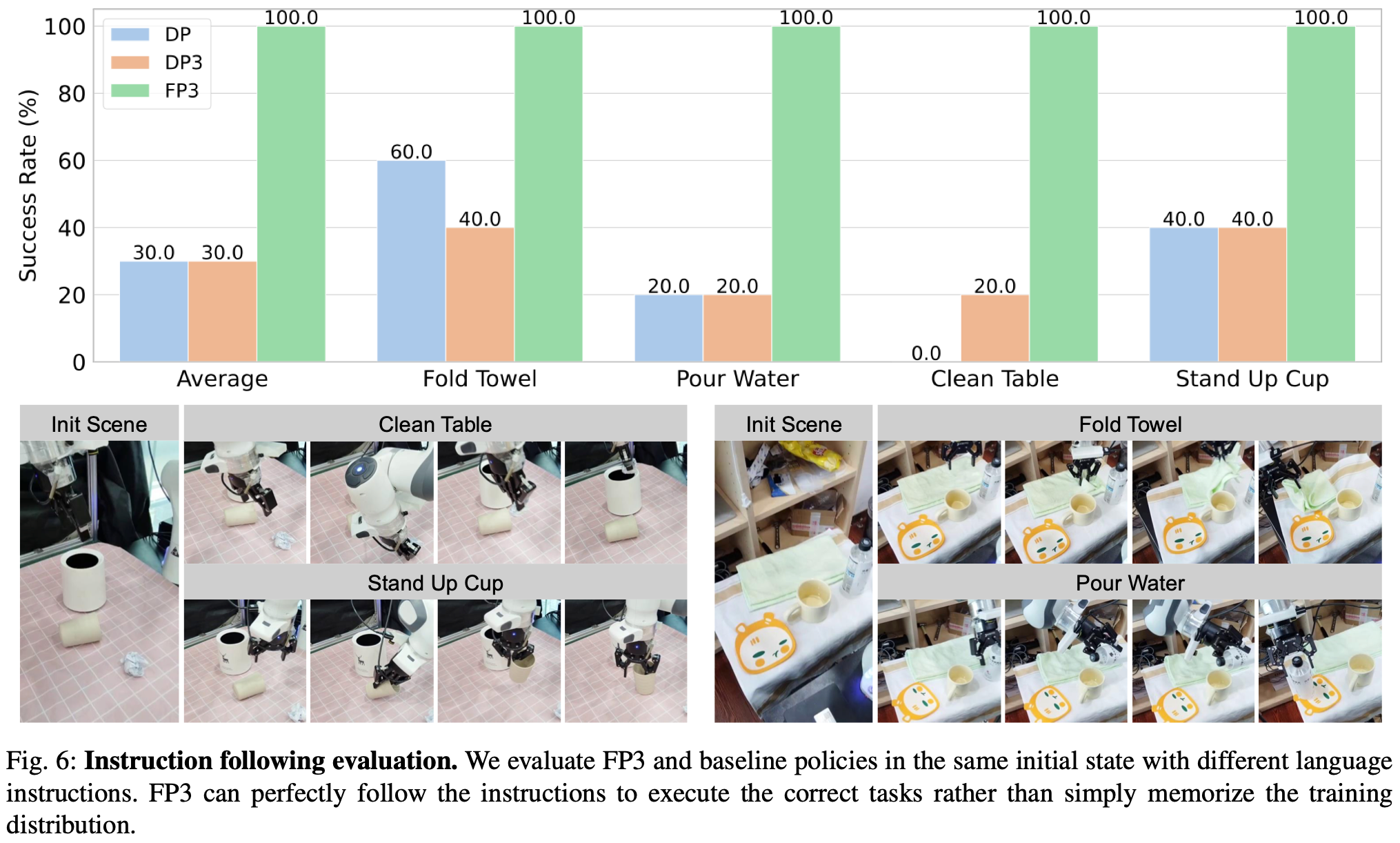
Table.1表明,在in-domain实验中,每个场景仅进行 10 次演示,DP 和 DP3 可以处理一些简单的任务,尽管在大多数情况下成功率低于 50%,然而在更困难的"倒水"任务中几乎完全失败;OpenVLA 在任何任务上都表现不佳,这可能是由于缺乏动作分块。相比之下,得益于预训练和 3D 表征,FP3 能够高效地学习所有任务,成功率超过 90%。定性分析发现,所有基线算法的失败主要归因于细节问题 ,例如尝试抓取物体时精度不够导致物体被推开,或者倒水时瓶口偏离中心等。相比之下,由于参数数量众多且进行了大量的预训练,FP3 策略可以更好地预测复杂的目标动作。FP3 策略预测的动作明显更加平滑和精确,因此与强大的基线相比,其成功率显著提高。
In-the-Wild Performance
进一步将机械臂移到新的环境中,并用未见过的物体评估策略。观察到所有未经预训练的基线策略(包括 FP3-Scratch)都经常无法识别目标物体,导致性能接近于零,如Fig.4所示。相比之下,FP3 很少遇到这种情况,并且在所有场景和任务中始终表现良好,平均成功率超过 80% 打败了所有基线。作者将优异的性能 归功于大规模预训练 ,因为预训练数据涵盖了各种各样的场景和物体,大大增强了策略的鲁棒性。此外,点云输入也是一个关键因素,它能够更好地捕捉几何信息,这对于跨域泛化至关重要。

Failure Analysis of Baselines
OpenVLA 在所有情况下都表现不佳,主要失败范式是容易卡在特定位置,并且无法与物体准确交互。卡住的问题可能源于 OpenVLA 缺乏动作分块和观察历史记录。无法精确交互的原因可能是 OpenVLA 仅使用第三人称视角观察,这会导致视野受限。
另一个有趣的问题是策略在首次尝试失败后的响应。有时策略会在首次尝试时失败,例如在清洁桌面任务中,策略未能抓住皱巴巴的纸张,在这种情况下,观察到只有 OpenVLA 和 FP3 能够进行合理的后续尝试,而 DP、DP3 和 FP3-Scratch 则容易卡住,在失败后只是在区域内徘徊,无法再次尝试。这种现象的发生可能是因为微调数据有限,因此未经预训练的策略在第一次失败后可能会陷入分布外状态,从而无法输出合理的行为。相反,FP3 中针对多样化任务和对象进行大规模预训练可以解决这个问题。
C. More experiments on generalization
在证明了 FP3 对新任务的高效适应性以及对新物体和环境的卓越泛化能力之后,使用清洁桌面任务对 FP3 在不同环境和机器人设置下的泛化能力进行了更全面的实验。Fig.5 展示了实验结果和可视化效果。
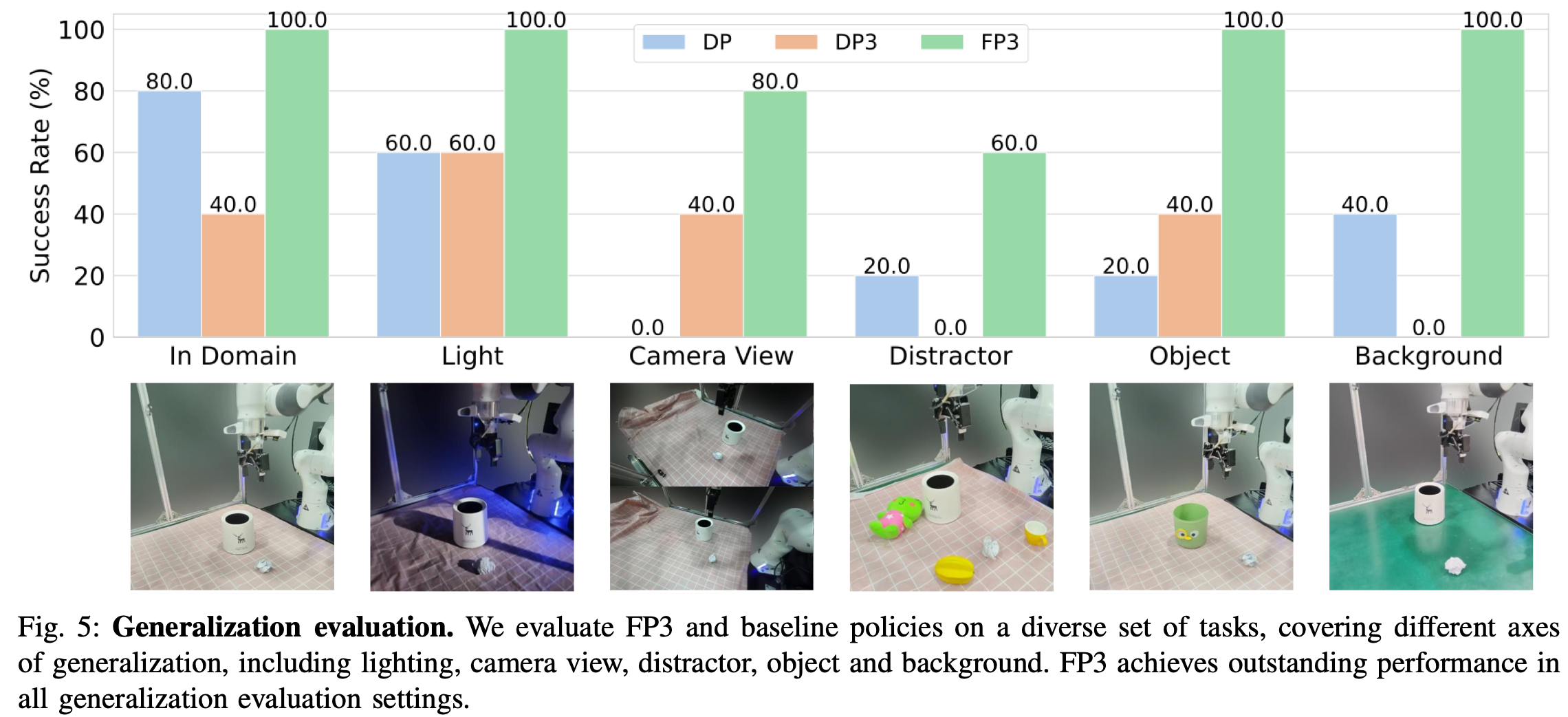
Generalization to different object appearances, back- grounds, and lighting conditions
传统的基于图像的策略网络对视觉变化较为敏感。这里系统地改变in-domain环境的某一部分:物体外观、背景纹理、光照条件。结果表明,基于图像的 DP 与域内结果相比性能有所下降,尤其是在颜色和背景发生变化的情况下。相比之下,DP3 在光照和物体颜色泛化方面的表现保持稳定,因为它消除了颜色通道并仅依赖于点位置,但仍然受到in-domain性能的限制。凭借训练前初始化和 3D 几何理解的优势FP3 超越了基线。从质量上看 DP 和 DP3 有时难以准确识别物体或估计其位置,而 FP3 始终表现良好。
Generalization to new camera views
相机视角变化一直是基于图像的策略面临的一大挑战。作者将相机视角与训练数据进行约 30 度的调整,以评估策略的鲁棒性。DP 再次在这种情况下完全失败,DP3 则受到其域内性能的限制,而 FP3 则保持了其高性能,因为只要相机校准得当,点云就会始终转换到相同的坐标。
Generalization to distractors
在目标物体周围放置随机干扰物,以评估这些策略的鲁棒性,发现策略可能会尝试抓取干扰物体。这个问题存在于所有方法中包括 FP3,但 FP3 的性能仍然是最高且最稳定的。
D. Instruction following
由于FP3是一种语言条件下的视觉运动策略,因此评估其根据语言指令执行任务的能力也至关重要。使用来自所有任务的数据,在多任务中对FP3和基线方法进行微调,并通过在相同的初始状态下提供不同的语言指令来评估它们。Fig.6表明,FP3可以在相同的起始上下文中根据不同的语言指令执行任务,而基线方法要么无法完成任务,要么会被其他任务的目标对象干扰。
E. Ablations
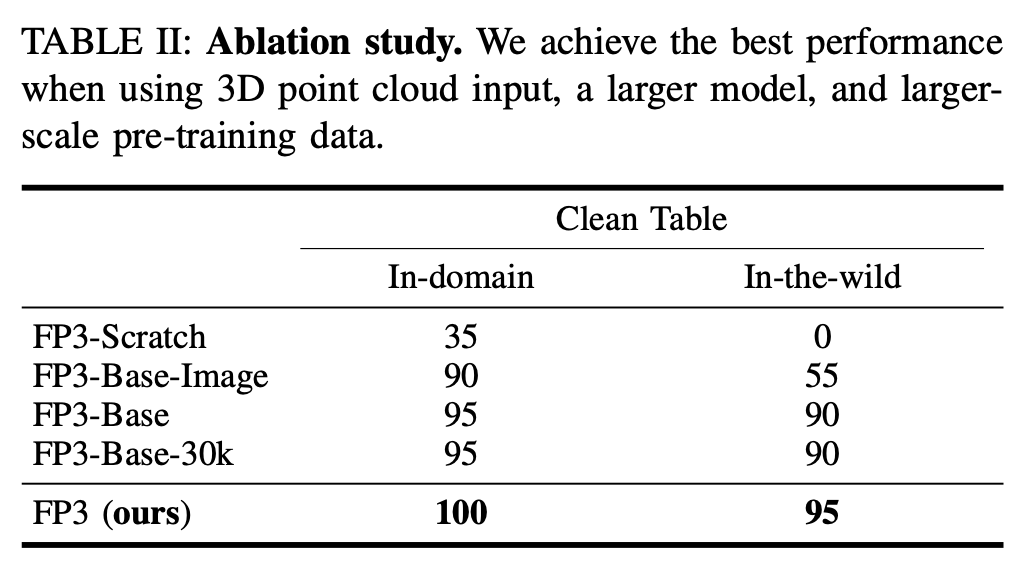
最后对观测选择、模型大小、预训练数据大小进行了消融研究。考虑了以下 FP3 变体:
- FP3-Base:将 FP3 中encoder 和decoder的transformer尺寸从
ViT-Large减小到ViT-Base总参数从 1.3B 减少到 365M; - FP3-Base-30k:进一步将
FP3-Base的预训练数据从 60k 减少到 30k 演示; - FP3-Base-Image:将点云输入转换为
FP3-Base上的图像观测,并采用DINOv2模型对图像进行编码; - FP3-Scratch:是从头开始训练的 FP3 模型,没有做任何预训练;
Table.2展示了各变体在清洁桌面任务上的结果。FP3-Scratch 在领域内和实际环境中均表现不佳,这表明预训练的重要性;FP3-Base-Image 在领域内的性能与 FP3-Base 相当,但在实际环境中性能下降幅度巨大,凸显了 3D 点云表示的有效性;FP3-Base 和 FP3-Base-30k 表现出相似的性能,均低于完整的 FP3。为了得出关于预训练精确缩放规律的更明确的结论,可能需要更具挑战性的任务和额外的数据点。
5. LIMITATIONS
虽然 FP3 作为策略基础模型表现出色,但它仍然存在一些局限性:
- 虽然
FP3能够实现高效且可泛化的下游微调,但基础模型的zero-shot性能有限。一个可能的原因是,与OXE等其他 2D 机器人数据集相比,预训练数据集DROID仍然不够大。未来的工作可以考虑收集更大的 3D 机器人数据集进行预训练; FP3通过简单的CLIP嵌入来融入语言条件,这不足以表示复杂和动态的信息。将基于扩散的FP3与 VLM 相结合以构建类似 π 0 \pi0 π0 的 VLA 模型似乎是一个有希望的未来研究方向;FP3并没有利用像DINOV2和SigLIP这样的健壮的预训练 2D 视觉编码器,将 3D 点云特征与 2D 图像特征合并,或者将 2D 特征提升到 3D 空间,都有着巨大的潜力;
6. Conclusion
本研究提出了 3D 基础策略 FP3一种以 3D 点云为输入,基于 Diffusion Transformer 的大规模策略。使用 6 万个机器人操作数据对 FP3 进行预训练,然后对其进行微调以适应下游任务。大量实验证明了 FP3 是一种出色的策略初始化方法,能够高效地进行数据处理,并针对新任务进行泛化微调。仅需 80 次演示,FP3 就能在包含未知物体的新环境中以超过 90% 的成功率学习新任务,显著超越现有的机器人策略。