从特征提取、特征处理到建模进行机器学习,前文已经进行了深入的探讨。针对所研究的问题,我们构建一个模型并不困难,但从已经给定的数据中构建一个具有良好的泛化能力且能对未知数据进行预测的模型则有一定的难度。那么,如何评判构建的模型的好坏呢?本章将带领读者对模型评估及改进进行深入的探讨。
8.1交叉验证
对给定的数据来说,我们无法知道哪些数据是正确的,哪些数据是错误的。对一个数据集来说,假定其中有40%的错误数据,那么当随机划分数据的时候,如果70%的训练数据中有40%的错误数据和30%的正确数据,可以肯定的是,这个模型的得分一定不会太高,但不能因此就认为根据某个算法所构建的模型不适合这个数据集,进而更换其他不是太完美的算法。这时应该对模型进行交叉验证。
交叉验证又称循环估计,它在统计学意义上将数据切割成K份,利用不同的数据来训练同一模型。每一次训练时,选取大部分数据进行建模,保留小部分数据来进行评估。它比用train-test-split方法单次划分数据更加稳定、全面。
8.1.1 K折交叉验证
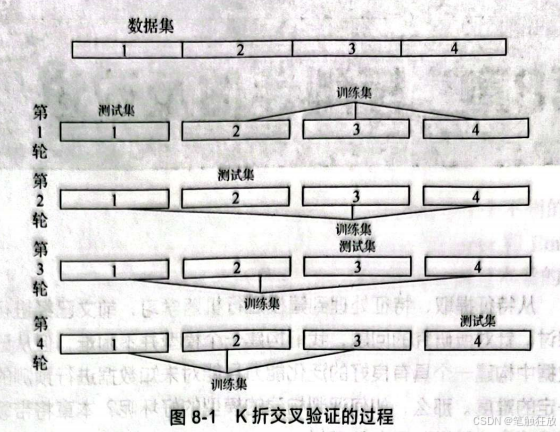
K折交叉验证是交叉验证中常用的一种方法,其过程是先将数据划分成K段,每一段称为这个数据的折,这样就得到了K个分段数据,接下来进行K轮建模训练。第1轮训练以第2~K个折为训练集,以第1个折为测试集,第2轮训练以第1个和第3~K个折为训练集,以第2个折为测试集,然后依此类推进行K轮训练,并记录每轮的模 型精度,从而帮助我们对所构建的模型进行更为全面的分析。图8-1展示出K折交叉验证的过程。
K折交叉验证,其实现利用了sklearn.model_selection中的cross_val_score()方法。
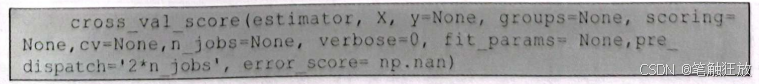
通常基本只用前3个参数和cv参数,estimator代表评估这个模型的算法,也是构建模型的算法,v的作用是指定将数据划分成几折去进行交叉验证。
下面以sklearm中的wine数据集为例进行交叉验证。代码如下:

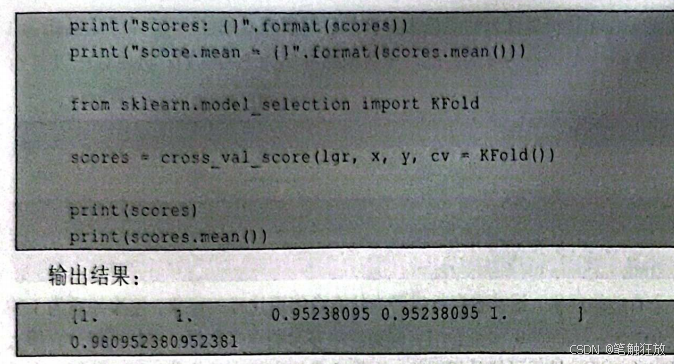
这里cross_val_score(中的cv参数默认等于5,可以通过更改cv的值来指定将数据划分为多少折。
8.1.2 分层K折交叉验证
8.1.1小节介绍了用K折交叉验证这种更为全面、高效的方法去进行模型检验,那么使用K折交叉验证会不会出现类似train-test-split一样糟糕的情况?
答案是会的,使用K折交叉验证依然会出现这种情况。接下来就以wine数据集为例,来看 wine 的 target:

可以看到,wine的target是根据红酒的品质来排列的,品质为0的红酒有59个,品质为1的红酒有71个,剩下的48个是品质为2的红酒。现在剔除品质为1的红酒,再运行一次K折交叉验证。

可以看到这样一个有趣的现象,请读者自行思考为什么会出现这样的现象。剔除品质为1的红酒后,数据只剩下107个,且品质0:2~1:1,假如忽略多余的7个数据,进行五等分,那么五等分后每个小段对应的红酒的品质可能是相同的。下面来模拟交叉训练的第1轮,以第1个折为测试集(全为品质为0的酒),以第2~5个折为训练集(品质0:2~3:5),用这种数据来进行训练和验证,实质上就等同于用训练集训练,再用训练集进行打分。因此会出现上述的结果。
那么,该如何避免这种情况呢?可以用分层K折交叉验证。分层K折交叉验证的过程和K折交叉验证的过程基本相同,只不过在取测试集和训练集的地方稍有不同。不再是选择一整个折作为测试集,剩下的折作为训练集,而是在每个折中选取前4%的数据作为测试集,将每个折剩下的1-4%的数据作为训练集,这样就能尽量避免上述情况的出现,如图8-2所示。


可以看到,尽管还是会出现scores=1的情况,但是出现的个数比之前少了两个,这是必然的,这里的数据太少(只有107个)如果数据足够多,出现这种情况的概率就会大大降低。
这里导入了skleam中的KFold分离器类,其作用是将数据按层分离,可以通过n_split 去控制将数据分成几折。
8.1.3 留一交叉验证和打乱划分交叉验证
(1)留一交叉验证(Leave-One-Out)也是交叉验证中比较常用的一种方法,其原理是将数据划分成K折,在单独的一个折中将单个数据作为测试集进行打分。对小型数据集来说这种方法可能比前两种方法还要好,但是对大型数据集来说,这种方法非常耗时。
下面还是以wine数据集为例来看其实现:
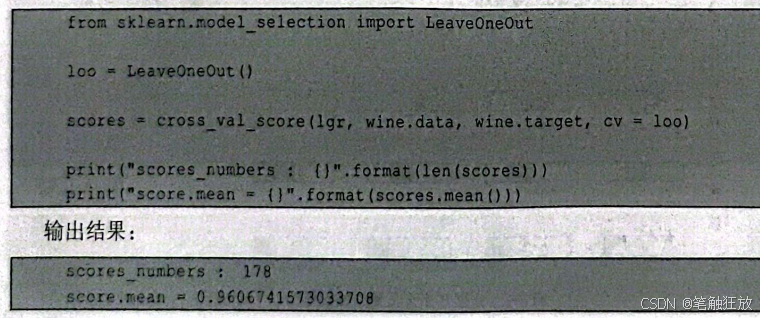
由于留一交叉验证是对单个数据进行交叉验证的,因此这里不展示单个数据的打分情况(正确为1,错误为0)。可以看到留一交叉验证对每个数据都进行了打分,且大部分的数据都是正确的,说明逻辑回归可以用在模型上对数据进行预测。
(2)打乱划分交叉验证也是交叉验证中的一种方法,其原理是对于整个数据集,每次选取train_size指定的数据作为训练集,选取test_size指定的数据作为测试集,对模型进行训练并打分。训练集和测试集选取的地方并不交叉,共进行n次。
train_size和test_size的值可以是整数,也可以是浮点数,两者的值是整数表示选择train_size和test_size个数据作为训练集和数据集,但两者之和不应超过整个数据集的数据量:两者的值是浮点数表示选取数据集中train_size%的数据和test_size%的数据作为训练集和测试集,同样两者之和不应超过1。
下面还是以 wine 数据集为例来看其实现。train_size和 test_size取整数:
8.2 网格搜索
8.1节介绍了如何对一个模型的泛化能力进行全面的验证。请读者思考一个问题:一个模型的泛化能力低是不是说明构建的模型的核心算法不对?答案是否定的。一个模型的泛化能力低可能有多个影响因素,例如数据量的大小、数据的准确性、算法的参数等。如果模型交叉验证的得分较低,先不要着急否定算法,尝试着去找出问题的所在。下面讲解如何通过改变模型的参数来提高模型的泛化能力。
通过改变参数来提高模型的泛化能力,最常用的方法之一就是网格搜索。那么什么是网格搜索呢?下面以简单的网格搜索为例,假设一个模型中存在参数A(A∈0.001,1)和参数B(B∈0.001,1),那么参数的取值就有1000×1000种可能。所以就可以把参数A和参数B的可能值以1000×1000的网格列出来(见图8-3),不断进行尝试,最终求出最佳的参数使得模型的泛化能力最高。Python实现就是通过两个for循环不断进行建模、打分,求出最佳参数,而这就是一个简单的网格搜索例子。


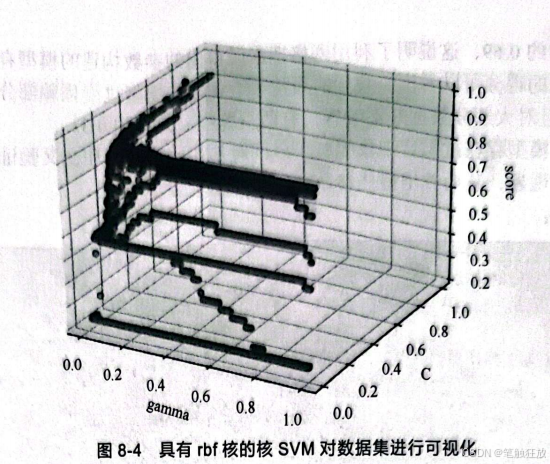
此时,可以看到参数gamma的变化量不大,只有0.001,而参数C的变化量则为0.039,因此大致可以认为C=0.76、gamma=0.02就是这个模型的最佳参数。
可以再次进行数据可视化,如图8-5所示。
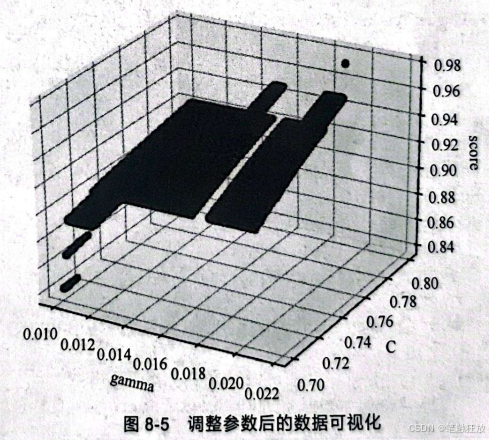
可以看到,gamma和C的微小变动对score 的影响不是很大。
两次用SVM构建的模型的平均得分约是97,未进行交叉验证之前这个模型确实是一个非常好的模型。因此,接下来对模型进行交叉验证:

这里使用了分层K折交叉验证来对模型进行评估,读者一定可以猜到这个模型的得分并不那么理想,来看一下结果:

平均得分只有约0.69,这说明了利用网格搜索所得出的参数构建的模型存在过拟合现象。从交叉验证每一折的得分可以看出,找到的最佳参数构建的模型过度依赖部分数据(居然有约0.97的得分),并且对大部分数据并不敏感,有两折的得分只有约0.3。
那么如何避免模型存在过拟合现象呢?可以同时使用网格搜索和交叉验证,这样就可以遵免模型存在过拟合现象,从而找出最佳参数。
下面看其实现:

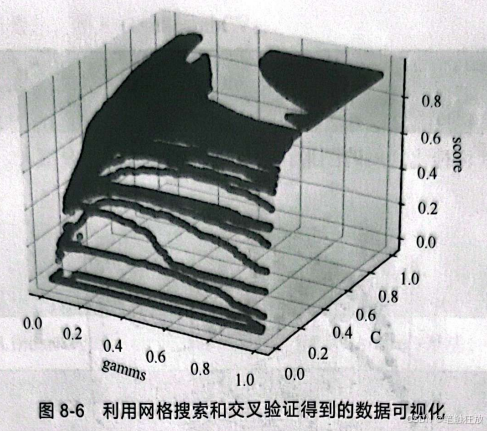
再次进行数据可视化,如图8-6所示。
由于在(0.17,0.96,0.93)旁边的数据点较多,因此在图8-6中看不太清楚最佳参数点的位置,但是根据对图8-6的分析,在交叉验证的辅助下,可以发现参数C越靠近0.96,score的值就越大:gamma越靠近0.17,score 的值越大。平均得分约为0.93,虽然比0.97低了一点,但是对比两次模型选择的参数可以看到,两次选择的参数相差很大,却降低了模型过拟合的风险。

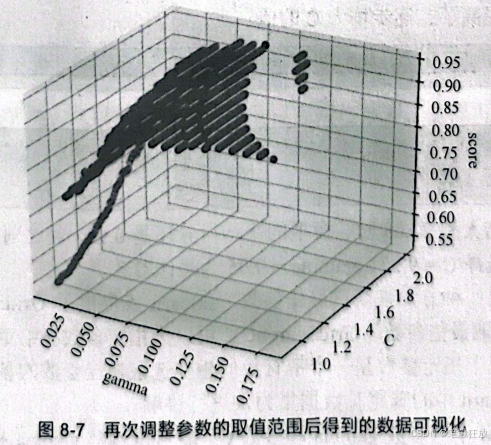
这时可以看到,模型的平均得分并没有改变,改变的只有参数gamma和参数c的取值。随着C的增大,gamma有缩小的趋势,因此再次增大c的取值:
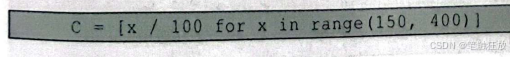

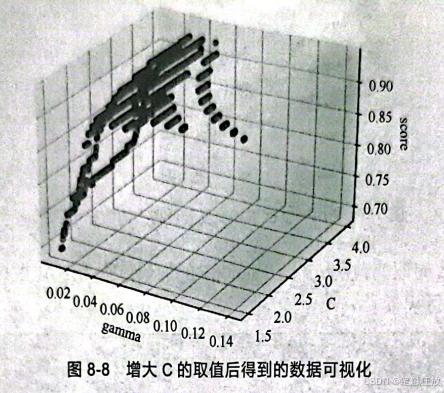

可以看到,当C增大到22.08时,模型的平均得分还是0.94,与之前的0.93相比几乎没有什么变化,因此可以选择C=9.23、gamma=0.05为最佳参数。
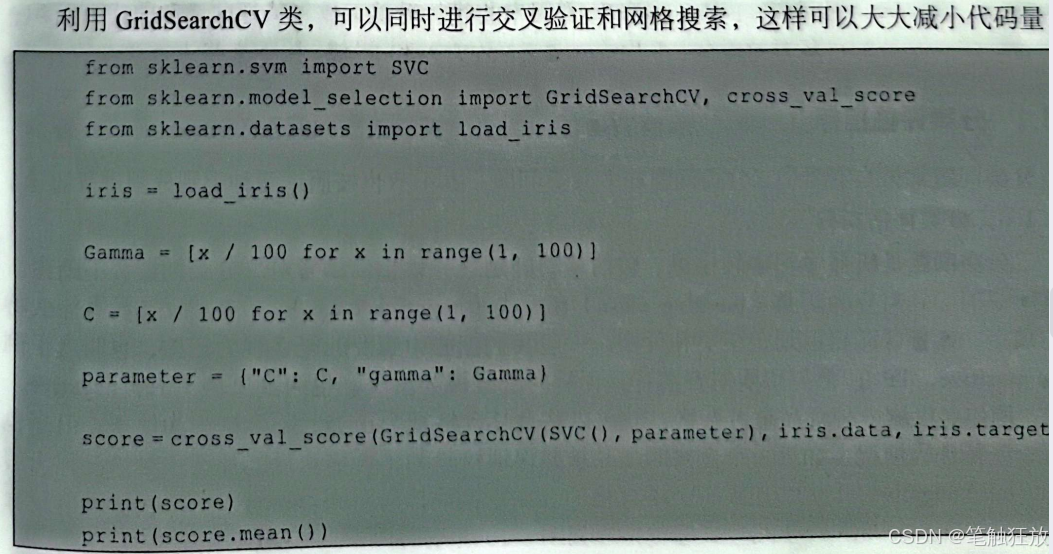
当然还可以使用另一种方法来获取最佳参数,sklearn库提供了GridSearchCV类,可以使用GridSearchCV来获取最佳参数。GridSearchCV可以为指定参数在给定的数值范围内自动选取最佳参数,通常情况下指定参数是一个带有我们想要选取最佳参数的参数名称和参数值的字典。接下来还是以sklearn中的鸢尾花数据集为例进行讲解。
假设想要调节 SVM 中的参数 gamma 和参数C,就可以构建 gamma 和C的字典:



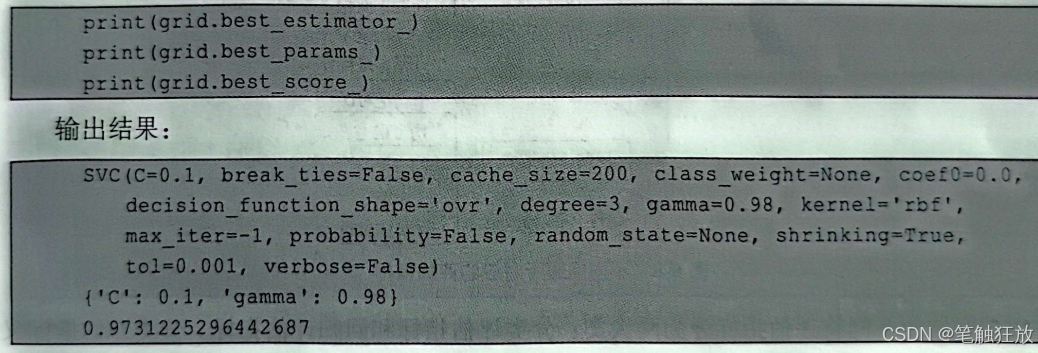
还可以用best_estimator_O方法查看最佳参数对应的模型,用best_paramsO方法查看指定数的最佳参数值,用bestscore_O方法查看训练集在交叉验证中的平均得分:

8.3 评估指标
前文介绍了如何用精度来评估解决分类问题的模型以及如何利用网格搜索找到最佳参数。但模型仅仅靠精度这一个指标来评估是远远不够的,例如构建了一个可以诊断人类是否患有胃癌的模型,并且精度达到了99.99%,那么前来诊断的人是否相信模型诊断出的结果呢?
我们构建模型的最终目的是解决问题,如果只靠精度这一个评估指标就认定这个模型可以在现实生活中被用来解决实际问题是非常不理智的。因此接下来要介绍更多可以用来评估模型的指标。不同问题所对应的评估指标如图8-9所示。
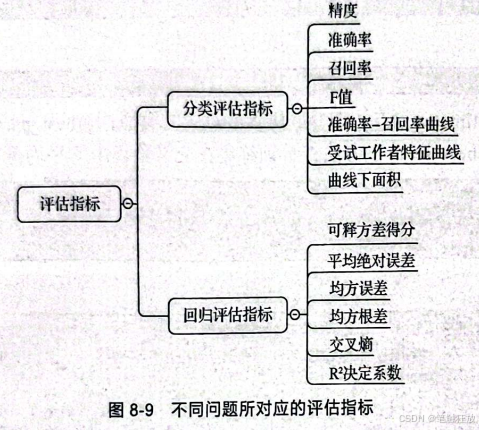
根据问题的不同将评估指标分为两大类:分类评估指标和回归评估指标。分类评估指标又分为精度、准确率、召回率、F值、准确率-召回率曲线、受试工作者特征曲线和曲线下面积;回归评估指标又分为可释方差得分、平均绝对误差、均方差和R值。接下来将进行详细的介绍。
8.3.1分类评估指标
分类问题常见的主要是二分类问题和多分类问题,本小节也按照这两种类别分别进行讨论。
1.二分类评估指标 二分类问题是机器学习中较常见、较简单的问题之一,相信读者对二分类问题都不陌生。通常所说的二分类分为正类(positive class)和反类(negative class)。正类和反类没有什么特殊的规定,读者可以自己划定正类和反类。一般我们把心中想要的答案视为正类,也叫真正例(true positive,TP);把与想要的答案背道而驰的答案视为反类,也叫真反例(true negative,TN)。例如要检测一种食品是否合格,就可以将食品合格视为正类,不合格视为反类。但是也会有一些特殊的情况,如果一个合格的食品被错误地检验为不合格食品,那么这种情况称为假反例(false negative,FN)。如果一个不合格的食品被错误地检验为合格食品,那么这种情况称为假正例(false positive,FP)。二分类指标如图 8-10所示。
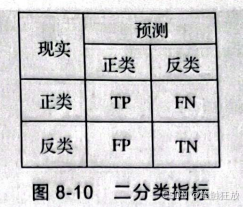
在现实生活中,我们希望构建的模型出现FN和FP的次数越小越好,如果单纯看模型的精度而不去考虑FN和FP,那么这样的模型即使精度高达100%也没有什么现实意义,不能用来解决问题。
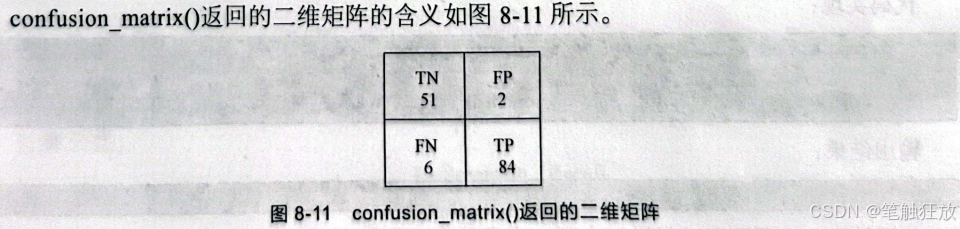
那么在进行评估之前,如何查看二分类的结果呢?这里介绍一种常用的方法一------混淆矩阵(confusion matrix)。通过利用sklearn.metrics中的confusion_matrix(方法,可以查看通过模型预测的预测值和真实值之间的差异,也就是观察TP、TN、FP和TN的个数,且由于讨论的只有两个类别,因此confusion_matrix(返回的是一个二维矩阵。
下面以sklearn中的乳腺癌数据集为例,代码如下:
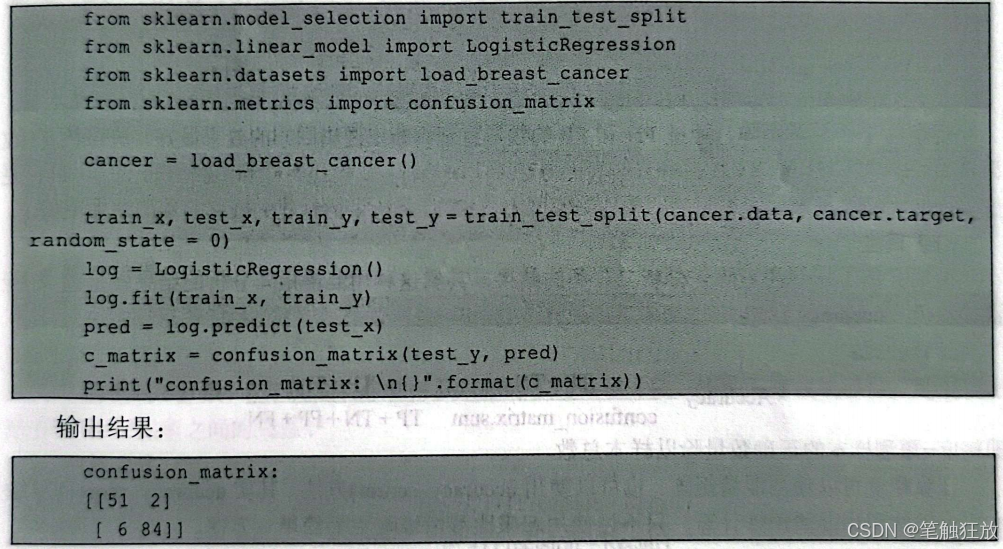
通过观察混淆矩阵,可以直观地观察到模型是否能得到想要的结果。下面用混淆矩阵来比较决策树、核SVM和逻辑回归在乳腺癌数据集上的效果。代码如下:

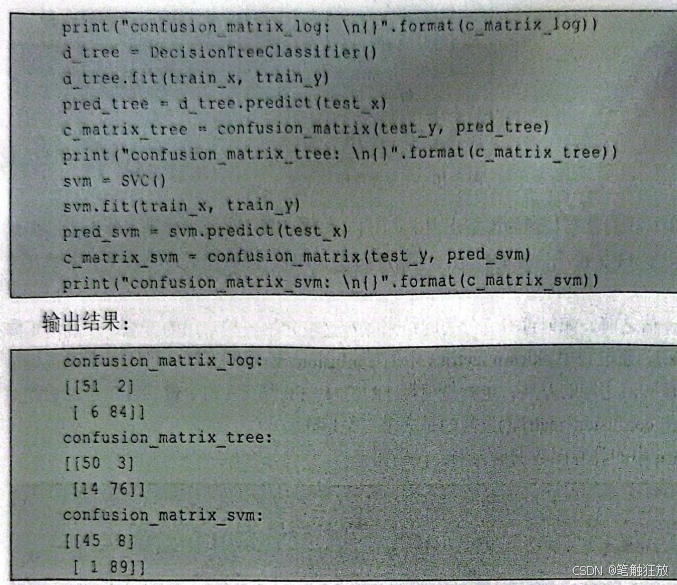
观察这3个混淆矩阵,通过FN和FP的数量直观判断出逻辑回归的效果最好,决策树的效果最差。逻辑回归和核SVM在各方面表现得都要比决策树好,但逻辑回归预测出的TP和TN更少。因此从结果上来看,逻辑回归构建的模型比核SVM和决策树构建的模型的预测效果更好。
(1)精度 前面介绍了用混淆矩阵来分析二分类的结果,其实这种用混淆矩阵分析的结果就是前文所讲的精度(accuracy),也叫精确率。
计算公式:

即精度=预测样本的正确数量除以样本总数。
计算精度可以使用混淆矩阵,也可以使用accuracy_score(方法。其实accuracy_score(方法本质上仍然利用混淆矩阵计算,只不过使用起来比混淆矩阵更为简单、方便。
代码实现:

关于精度,这里不再进行详细介绍,本章的8.1节和8.2节已经有所介绍。
(2)准确率
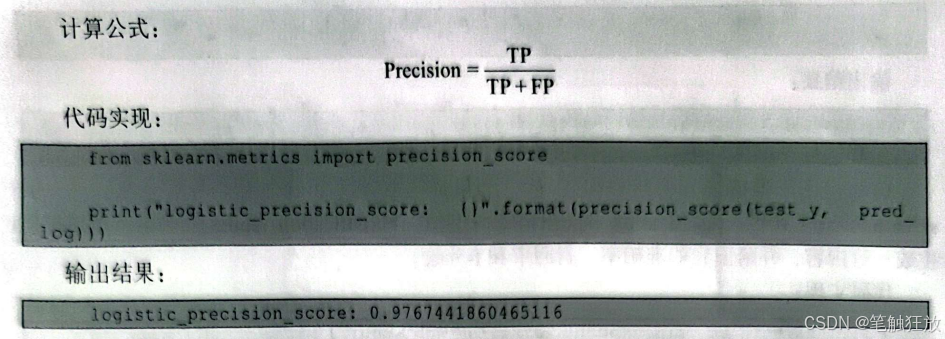
下面介绍另一种评估指标一一准确率(precision),也叫阳性预测值(positive predictionvalue,PPV),即预测正确的样本中有多少是TP。准确率和精确率从字面上看很难区分,准确率表示的是预测正确样本中TP的准度,而精确率则表示的是整个样本中预测正确样本的准度,预测正确样本中既包含TP也包含TN。
(3)召回率
召回率(recall)也叫灵敏度(sensitivity)、命中率(hit rate)和真正例率(true positive rate,TRR)、指在所有正确的样本中有多少TP。召回率适用于避免FN的情况,例如区分网贷中信用良好的客户中的不良信用的用户、找到患病病人中的健康人等。召回率越高,那么FN被预测出来的概率就越高。
计算公式:


(4)F值
F值也叫f-分数,f-分数是准确率和召回率的平均调和函数,使用f分数能够很好地展现出准确率和召回率之间的关系。
计算公式:

通常情况下取β²=1,这一变体称为fi-score,也叫f1分数。把f1分数作为二分类的评估指标普遍比把精度作为二分类的评估指标要好得多。
计算公式:



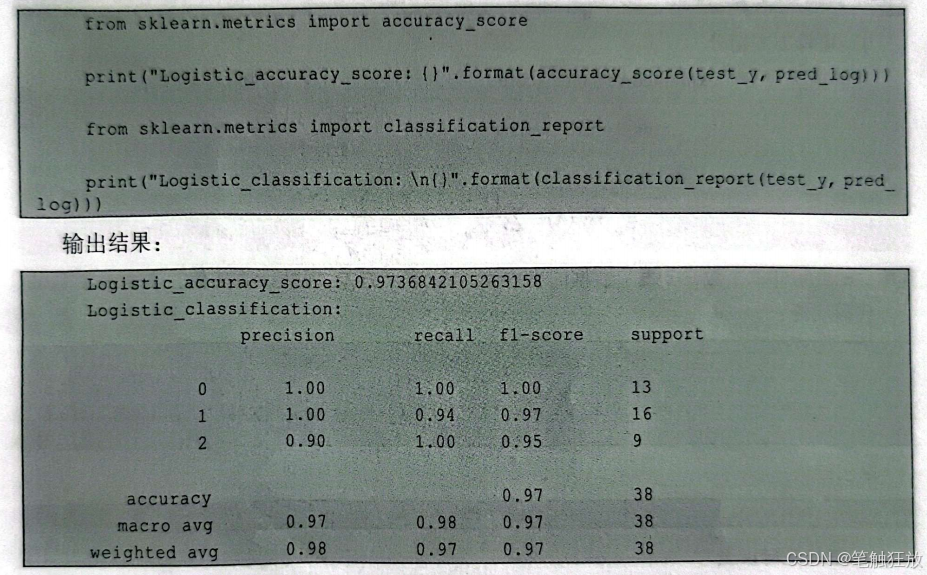
前面介绍了准确率、召回率和F值,如果觉得查看这3个评估指标太复杂,可以用sklearn.metrics中的classification_report(方法来查看。classification_report(会为每个类别单独生成一行内容、并给出它的准确率、召回率和f分数。
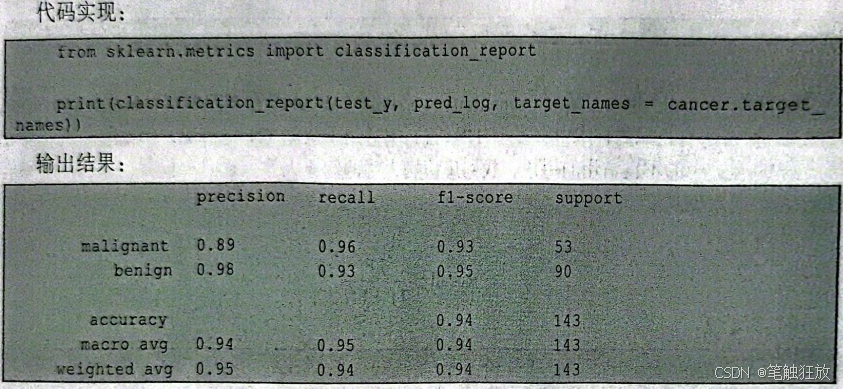
这里分别列出了良性肿瘤和恶性肿瘤的准确率、召回率和F值,support代表样本,macro avg是良性肿瘤和恶性肿瘤各项指标的算数平均值(如fl-score=0.94=(0.93+0.95)/2),weightedavg是良性肿瘤和恶性肿瘤的加权平均值(如precision=((0.89×53)+(0.98×90)/(53+90)~0.95)。
(5)准确率-召回率曲线
对分类模型而言,通常可以调节做出分类决策的阈值来提高模型的准确率、召回率和fl-score等指标。在进行初次建模的时候,我们想要这个模型能够在某一个阈值上识别出80%的恶性肿瘤,可是不知道最佳的阈值,所以一般可以把所有可能取到的阈值先列出来,每一个阈值分别对应一个准确率和一个召回率,这样就可以根据准确率和召回率绘制出一条曲线,以便选择合适的阈值,这样的曲线就叫作准确率-召回率曲线(P-R曲线),能够满足需求的阈值也叫工作点。代码如下:

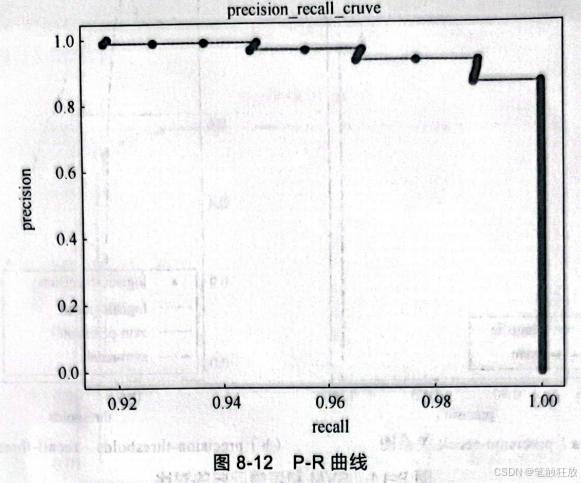
从图8-12中可以看到,越靠近右上角,准确率和召回率就越高,而此时的阈值就是想要的阔值。或者也可以绘制如下P-R曲线:

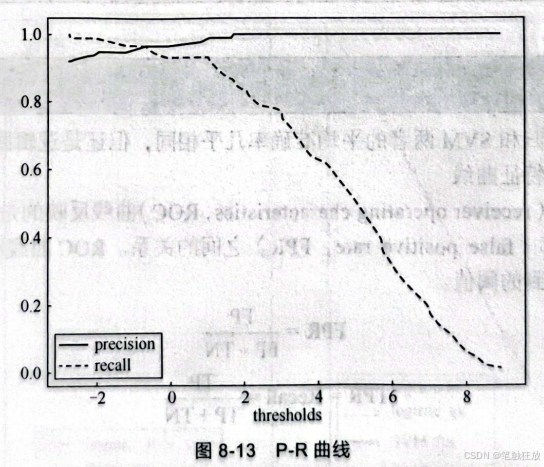
这样就可以比较直观地看出我们需要的最佳阀值。图8-14所示为SVM和逻辑回归的对比,图8-14(a)所示为 precision-recall关系图,图8-14(b)所示为 precision-thresholds、recall-thresholds关系图,从这两张图中能够很明显地看出逻辑回归的效果要比SVM好得多。
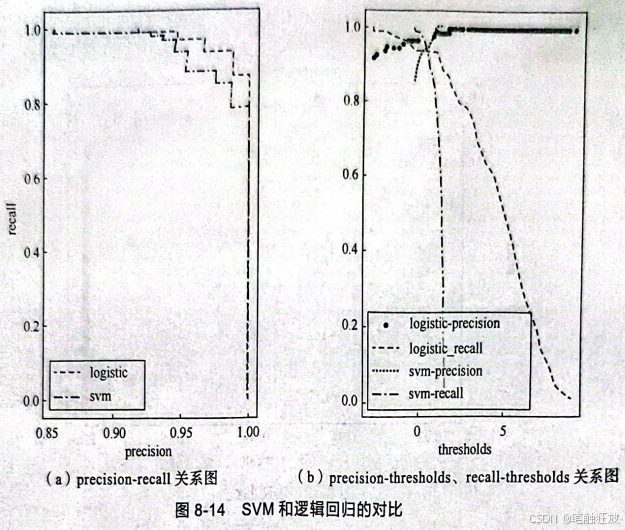
虽然观察图像可以给我们很多好的建议,但是如果数据量足够大而且不同模型的表现基本相同时,观察并从图像中获取信息可能是一件非常令人头痛的事情,所以可以借助sklearmmetrics中的 average_precision_score)(用于计算平均准确率)来总结 P-R 曲线。averageprecision_score(会自动计算并返回P-R曲线的积分(即与横坐标轴围成的面积)。
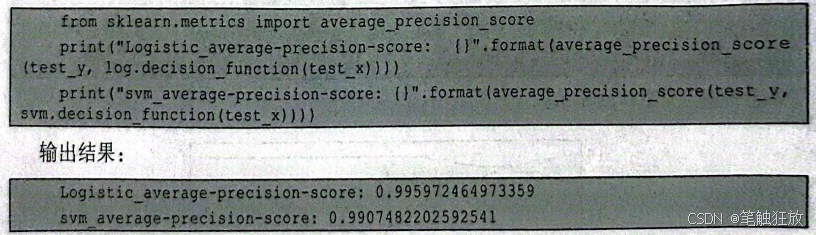
可以看到逻辑回归和SVM两者的平均准确率几乎相同,但还是逻辑回归领先一步。
(6)受试者工作特征曲线
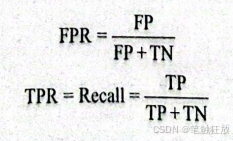
受试者工作特征(receiver operating characteristics,ROC)曲线反映的是真正率(true positiverate,TPR)和假正率(false positive rate,FPR)之间的关系。ROC 曲线和P-R曲线类似,都考虑的是所有可能取到的阀值.


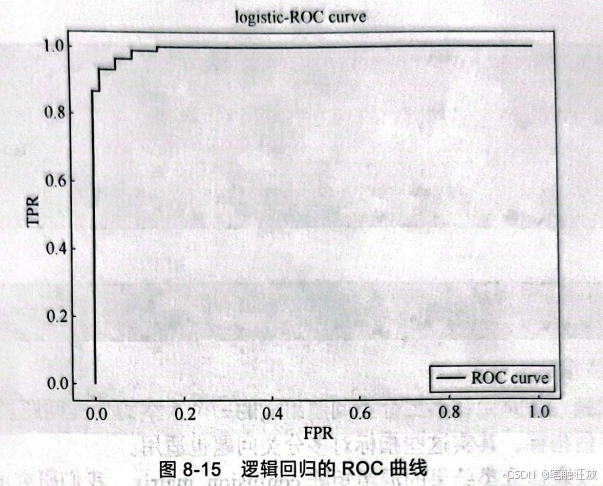
由于测试样本比较少,可以取到的阈值只有12个,因此曲线显得不是很平滑。对于构建的模型,都希望其召回率很高,但同时也要确保假正率很低,只有达到这样的效果,模型才能真正被应用来解决实际问题。所以,对ROC曲线来说,曲线越靠近左上角,模型的召回率(真正率)也就越高,假正率也就越低。
图8-16所示为SVM和逻辑回归ROC曲线的对比,也可以明显看到逻辑回归的效果要好于SVM.
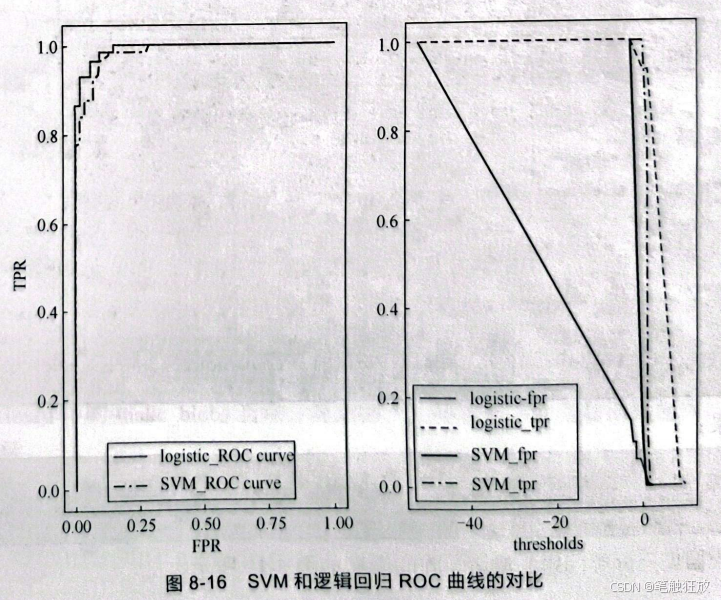
(7)曲线下面积 曲线下面积(area under the curve,AUC)中的曲线指的是ROC 曲线。AUC一般被用来计算ROC曲线的积分(即曲线与横坐标轴围成的面积),与平均准确率类似,AUC是总结ROC曲线的一种方法。
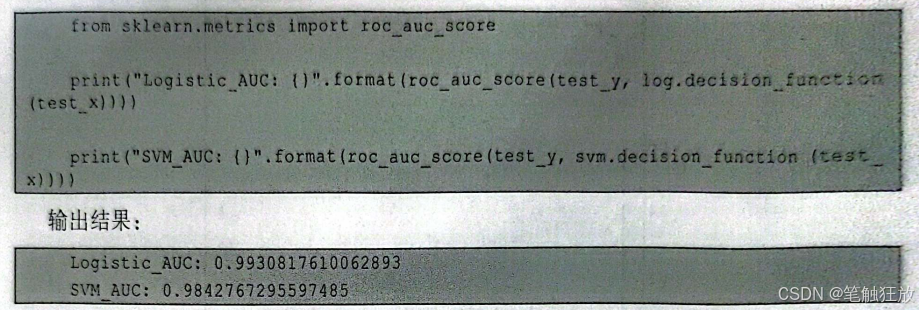
- 多分类评估指标 多分类评估问题,就是由许多二分类问题组成的一个大型的分类问题。前文讨论了许多关于二分类问题的评估指标,其实这些指标对多分类问题也适用。
例如,对于可以表达分类结果的混淆矩阵confusion_matrix,我们研究的问题有N个类别,confusion_matrix就会返回一个N×N的矩阵来显示分类的结果。
这里不再以乳腺癌数据集(只有两个类别)为例,接下来的内容将以鸢尾花数据集作为多分类问题的例子。
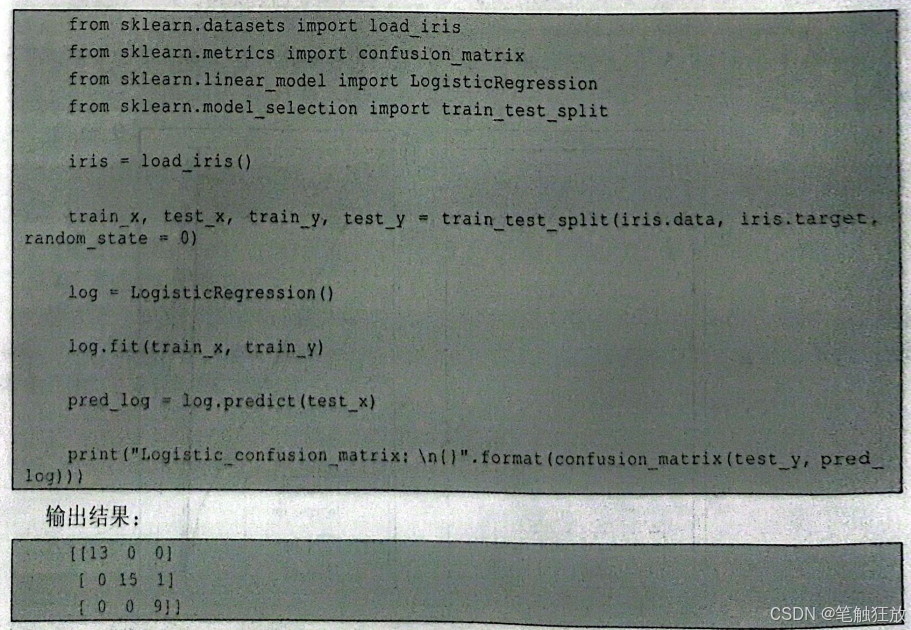
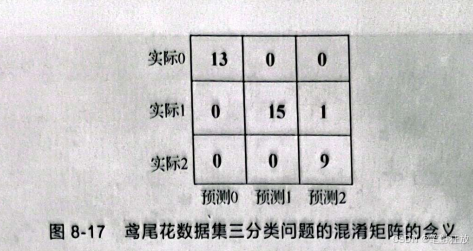
由图8-17可知,每一个类别都可以被划分成一个二分类问题来解释,即划分为一个2×2的矩阵。因此,对于多分类问题,也可以将其划分成多个二分类问题解决。
多分类问题的各项评估指标:
8.3.2 回归评估指标
8.3.1小节讨论了分类问题的评估指标,对于分类问题,可以通过精度、准确率、召回率和f1-score等多个指标来进行全面的评估。特别对于二分类问题,还可以通过P-R曲线、ROC曲线和AUC等指标来评估。但是对于回归问题,一般默认使用R决定系数来评估,也就是使用所有回归器中的score)方法。当然还可以计算出可释方差得分、平均绝对误差、均方差等一系列的回归评估指标来对模型的泛化能力进行全面的评估,但相对于R决定系数来说,这些指标更为抽象。
下面以sklearn中的make_blobs自动计算出的一个随机正态分布数据集为例,分别介绍各类回归评估指标。



 2.平均绝对误差 平均绝对误差(mean absolute error,MAE),是绝对误差的平均值,值越接近0表示回归效果越好。
2.平均绝对误差 平均绝对误差(mean absolute error,MAE),是绝对误差的平均值,值越接近0表示回归效果越好。

3.均方差 均方差(mean square error,MSE)是绝对误差平方的平均值,值越接近0表示回归效果越好。


8.4 小结
本章介绍了如何对一个模型进行全面的评估,以及评估模型的各项评估指标。利用交叉验证(如cross_val_score()来评估模型的泛化能力、利用网络搜索(如GridSearchCv)找到最佳的参数以及利用精度准确率、召回率等评估指标来对模型进行全面的分析。例如,对于二分类问题,可以使用P-R曲线、POC曲线来找到最佳的阈值,或者利用AUC来比较两种模型的优劣等;对于回归问题,可以通过R决定系数最直观地表现模型的回归效果。当然,评估模型的方法有很多,一个模型是不是一个好的模型并不只看它在这一固定的数据集上的表现及评估,还要看它是否具有解决现实生活中实际问题的能力。
习题8
1.什么是交叉验证?交叉验证有几种方法?
2.什么是网格搜索?
3.什么是精度、准确率、召回率?