目录
[2.1 配置大模型](#2.1 配置大模型)
[2.1.1 通过 OneAPI 接入模型](#2.1.1 通过 OneAPI 接入模型)
[2.2 创建知识库](#2.2 创建知识库)
[2.3 创建工作流](#2.3 创建工作流)
[2.4 示例讲解](#2.4 示例讲解)
前言
官网文档:Docker Compose 快速部署 | FastGPT
本篇主讲工作流编排实现基于知识库 | http请求+知识库 -> 大模型输出,将跳过docker安装等步骤,侧重于应用自定义流程及扩展。主包刚学习的时候也看了很多博主写的文件和视频,大部分偏向基本使用并没有告诉我各组件节点组合使用是否可行,还是需要自己摸索尝试。所以本篇文件希望给大家一点小灵感方便构建实现自己需求的agent!
一、本地部署
准备docker环境后可,可去GitHub找到需要的向量数据库,下载到本地。
注意配置文件有注释需要查看默认的登录账号以及密码
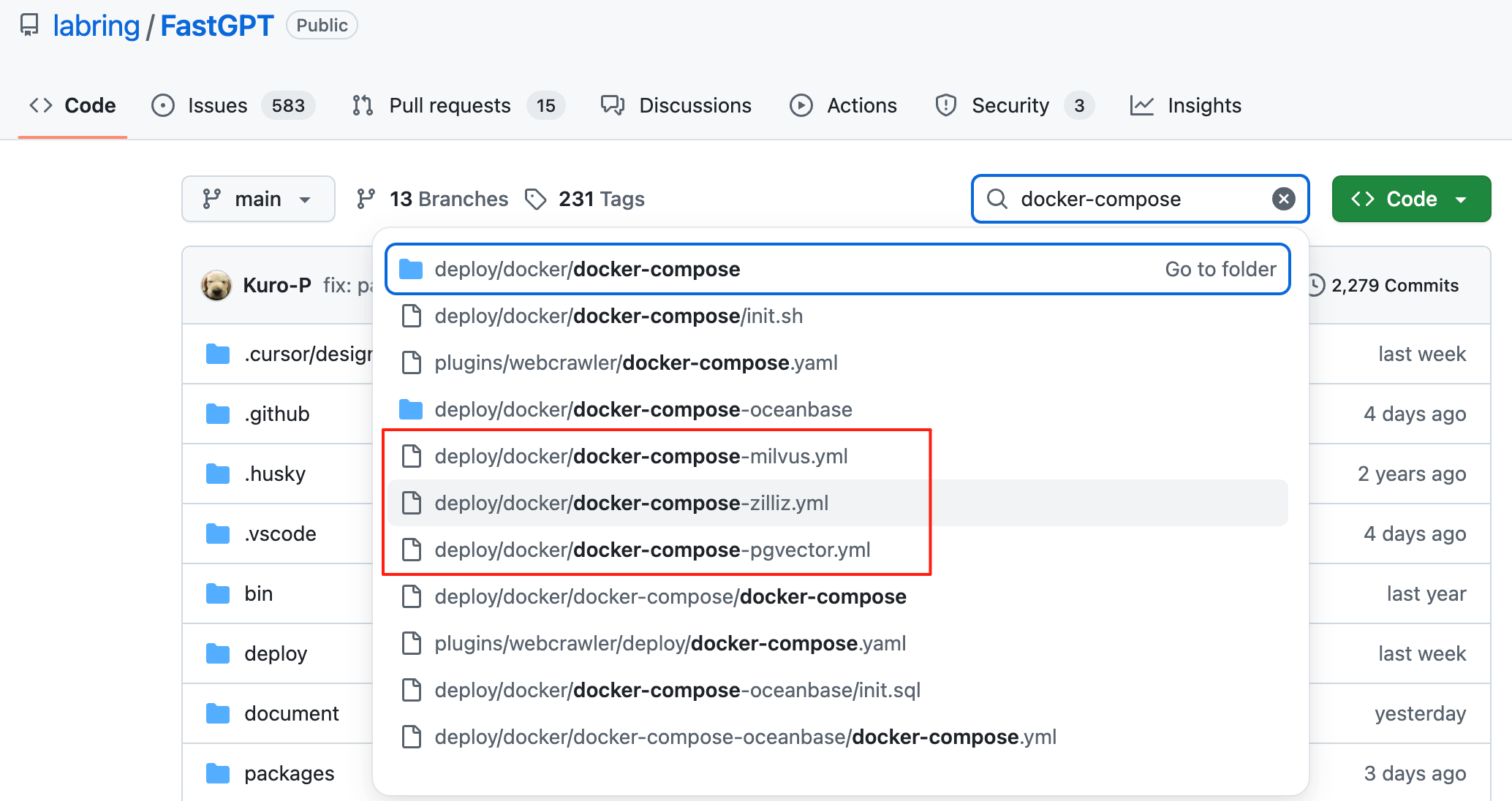
Linux 快速脚本
bash
mkdir fastgpt
cd fastgpt
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
# pgvector 版本(测试推荐,简单快捷)
curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-pgvector.yml
# oceanbase 版本(需要将init.sql和docker-compose.yml放在同一个文件夹,方便挂载)
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-oceanbase/docker-compose.yml
# curl -o init.sql https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-oceanbase/init.sql
# milvus 版本
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-milvus.yml
# zilliz 版本
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-zilliz.ymlconfig.json 文件也就是一些模型的配置:
bash{ "systemEnv": { "vectorMaxProcess": 10, // 向量处理线程数量 "qaMaxProcess": 10, // 问答拆分线程数量 "vlmMaxProcess": 10, // 图片理解模型最大处理进程 "tokenWorkers": 30, // Token 计算线程保持数,会持续占用内存,不能设置太大。 "hnswEfSearch": 100, // 向量搜索参数,仅对 PG 和 OB 生效。越大,搜索越精确,但是速度越慢。设置为100,有99%+精度。 "hnswMaxScanTuples": 100000, // 向量搜索最大扫描数据量,仅对 PG生效。 "customPdfParse": { "url": "", // 自定义 PDF 解析服务地址 "key": "", // 自定义 PDF 解析服务密钥 "doc2xKey": "", // doc2x 服务密钥 "price": 0 // PDF 解析服务价格 } }, "llmModels": [{}], // 语言模型 "vectorModels": [{}], // 向量模型 "reRankModels": [{}], // 重排模型 }
将两个文件放在一个目录执行命令:
bash
# 在 docker-compose.yml 同级目录下执行
docker-compose pull // 拉取容器
docker-compose up -d // 启动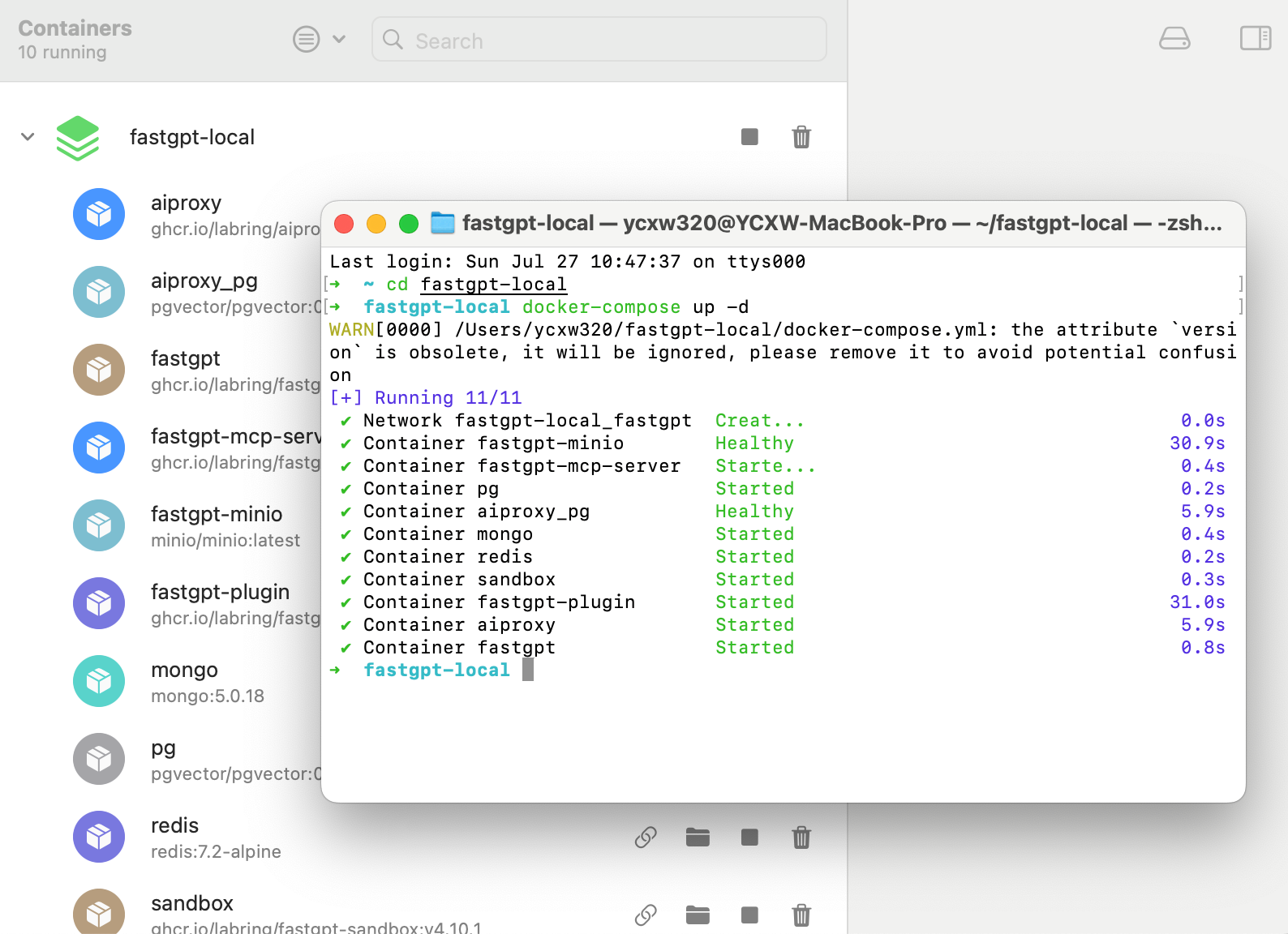
二、工作流编排
2.1 配置大模型
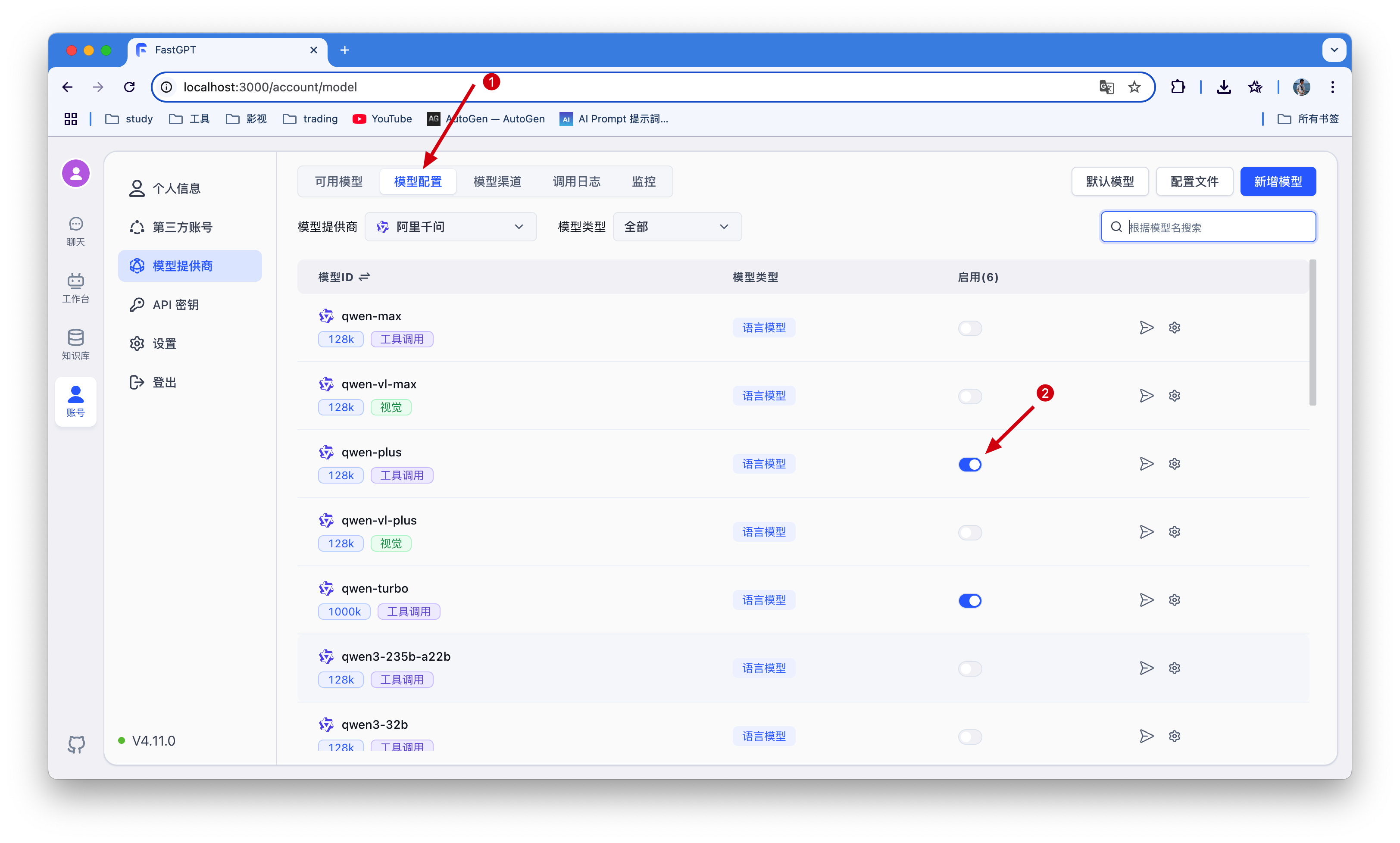
在上面讲到config.json文件就是一些大模型的配置,源文件定义了需求模型,但是我们不能用,需要自己添加才行
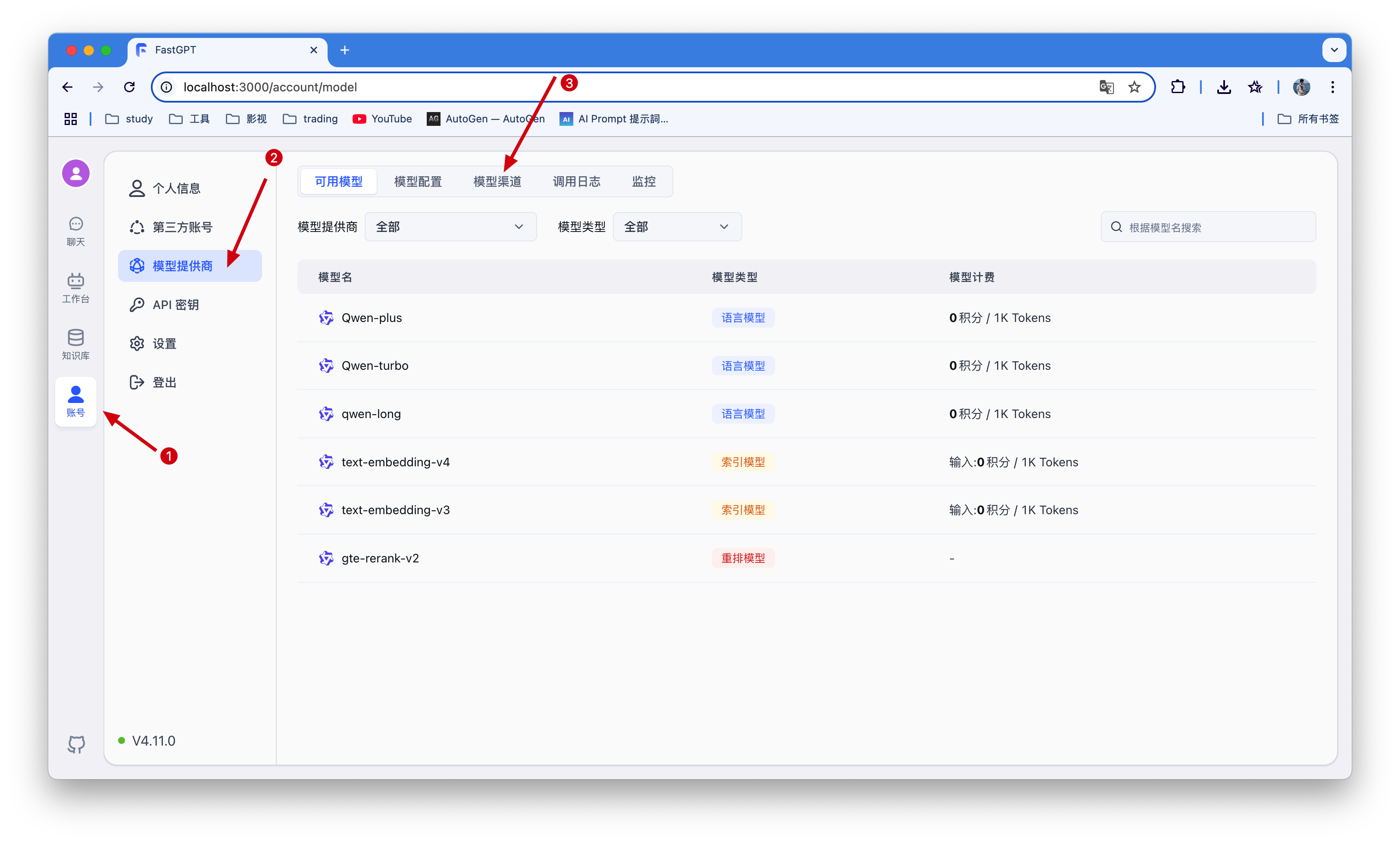
首先需要新增一个模型渠道,我这里使用了通义千问,可根据自己拥有的模型新增 。
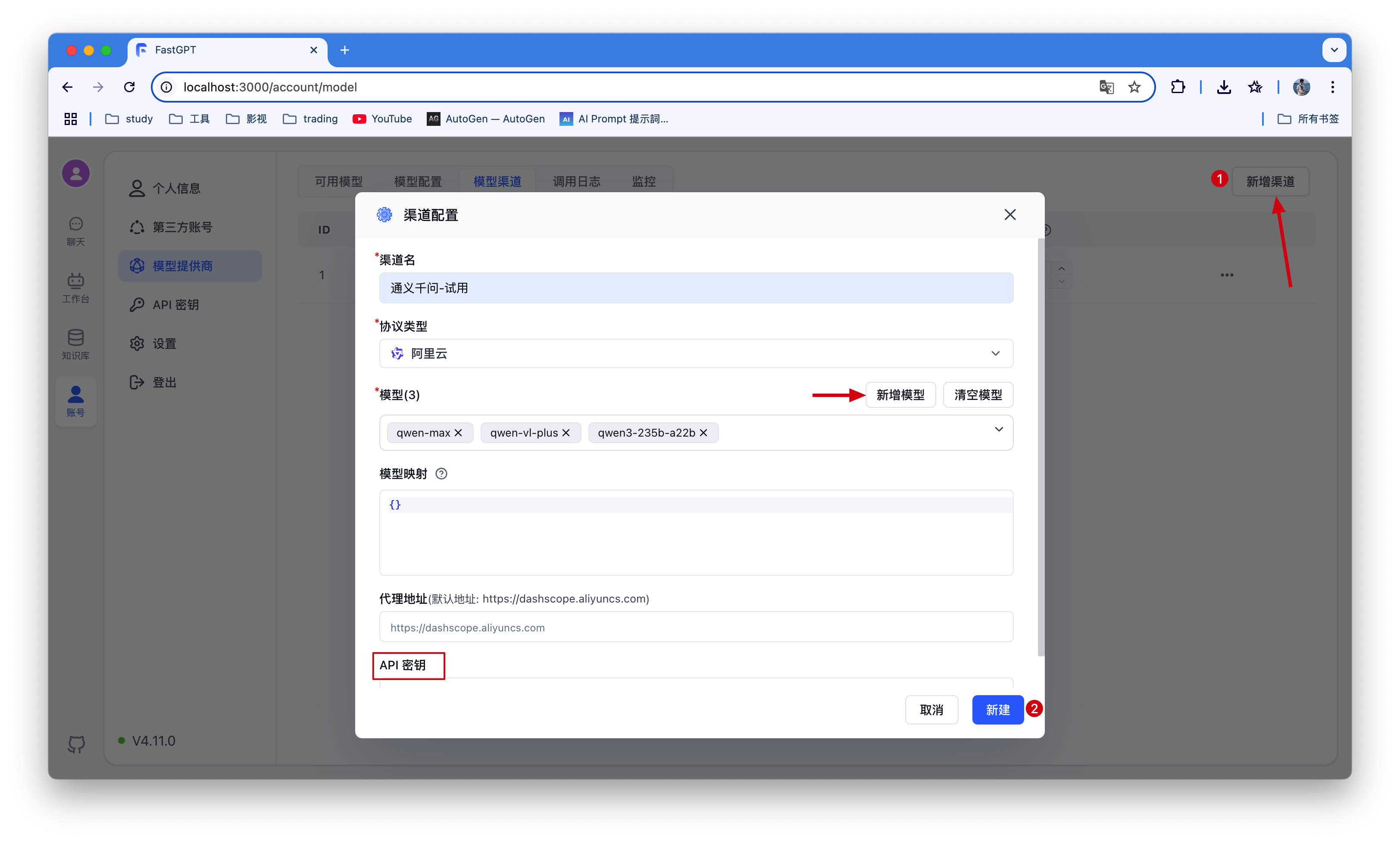
接着把新增的模型启动即可,不然到后面没有模型选择🤦
2.1.1 通过 OneAPI 接入模型
项目地址:https://github.com/songquanpeng/one-api
很多博主都分享通过这种方式统一配置管理大模型,FastGPT 目前采用模型分离的部署方案,因为只兼容 OpenAI 的模型规范(OpenAI 不存在的模型采用一个较为通用的规范),并通过 One API 来实现对不同模型接口的统一。但是主包貌似没有找到mac包所以直接使用以上方法,fastgpt已接入了AI Proxy。
2.2 创建知识库
注意web站点与第三方知识库同步需要付费,商业版才可用,我们个人直接使用本地上次知识库即可!!!
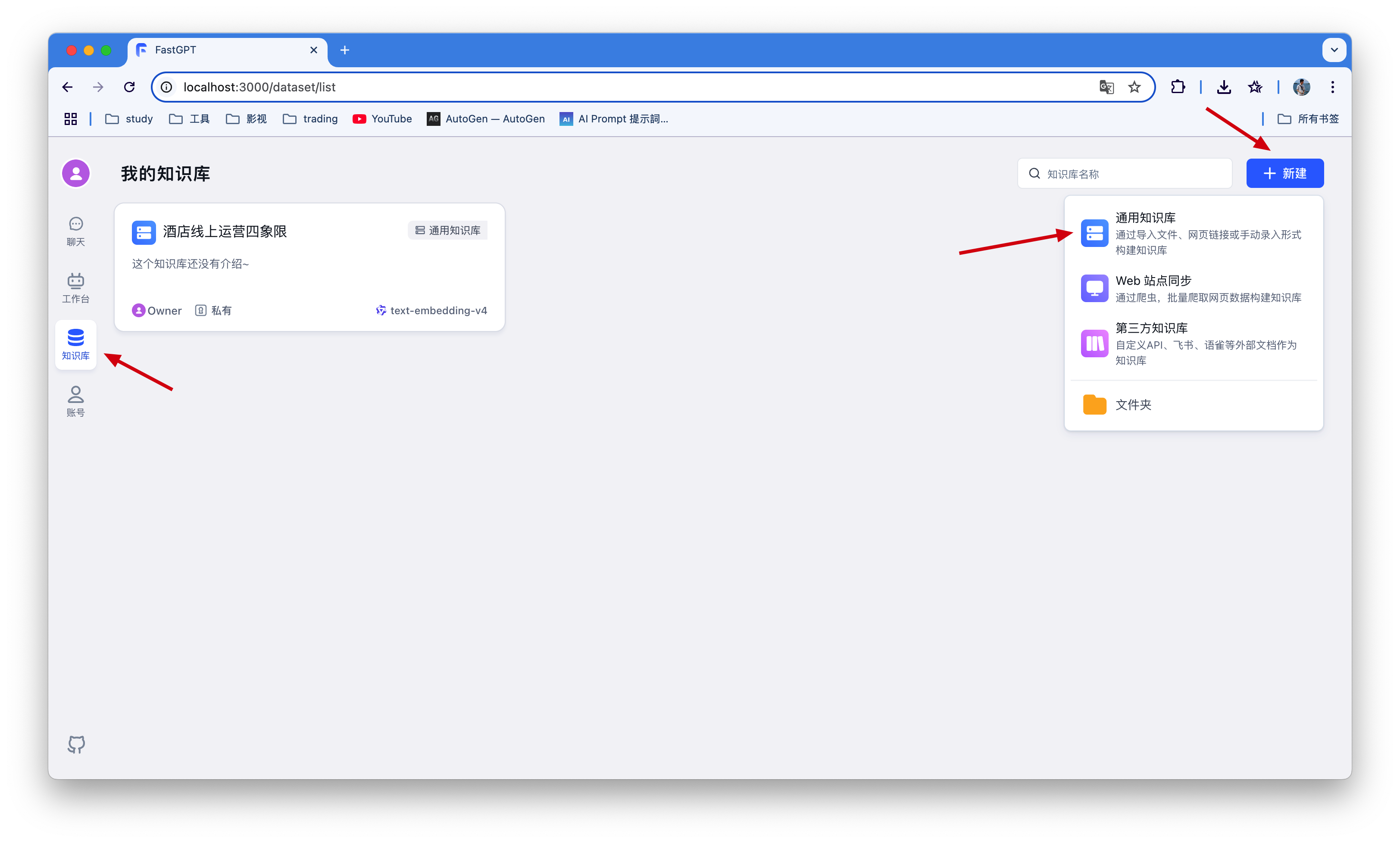
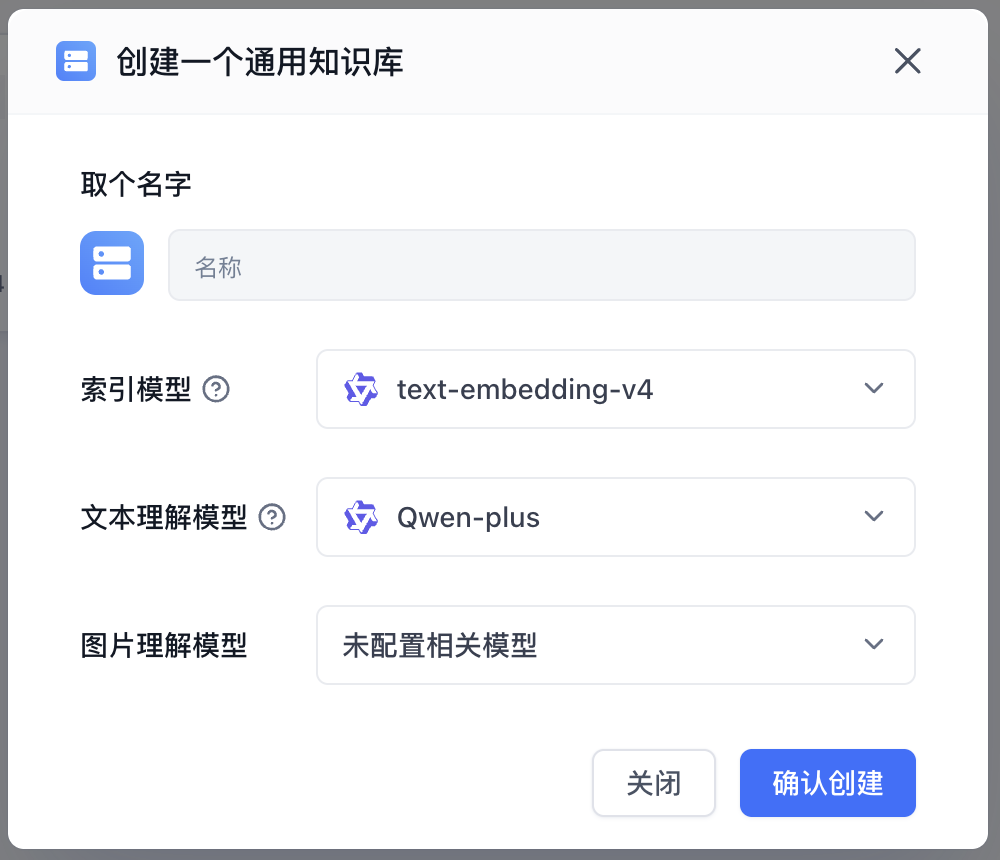
这时可以选择已经配置的模型进行处理,后面就是导入本地文件
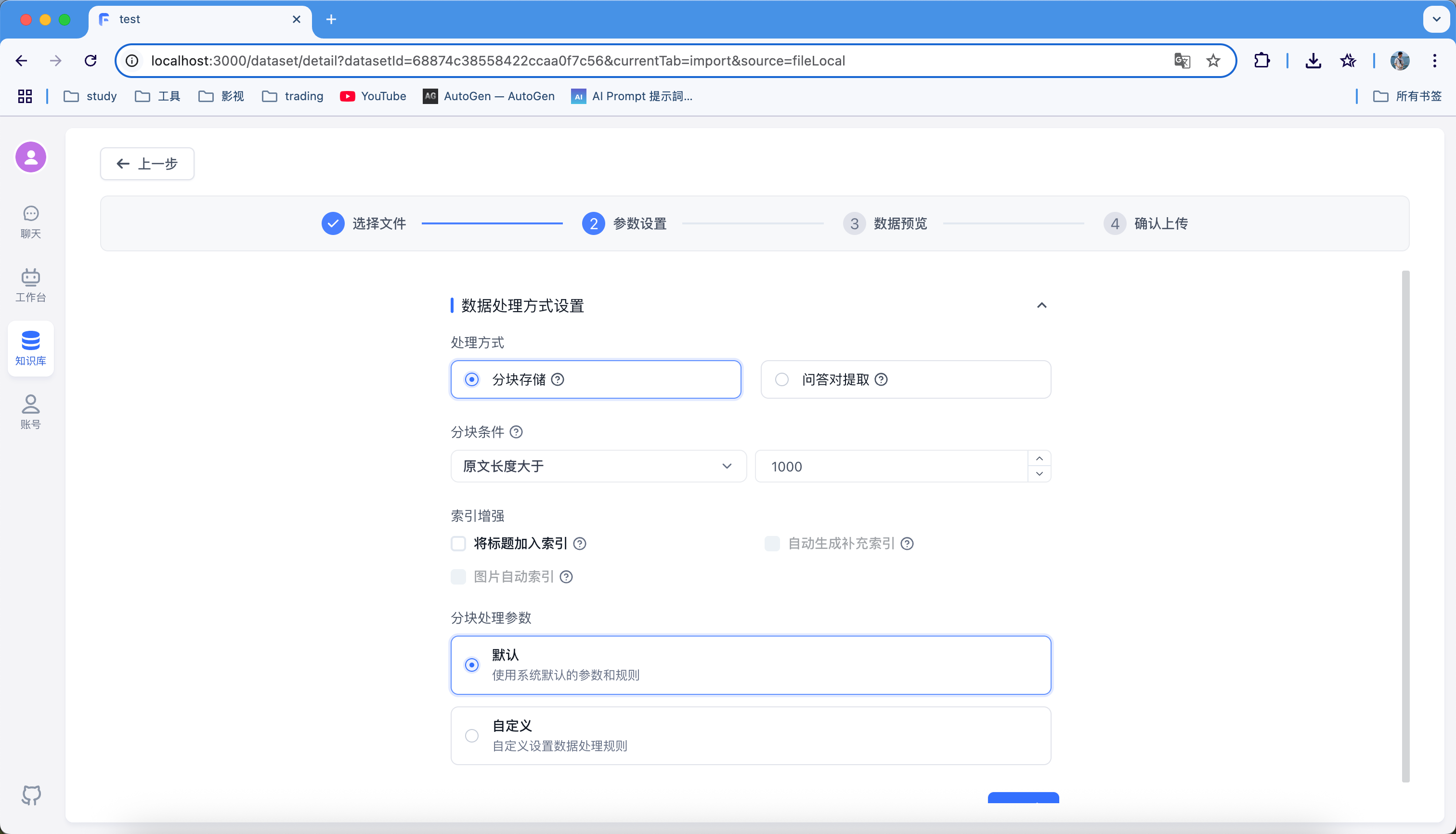
最重要的一步就是知识库处理方式,取决于知识库结构以及更好的检索
2.3 创建工作流
这里直接创建一个工作流
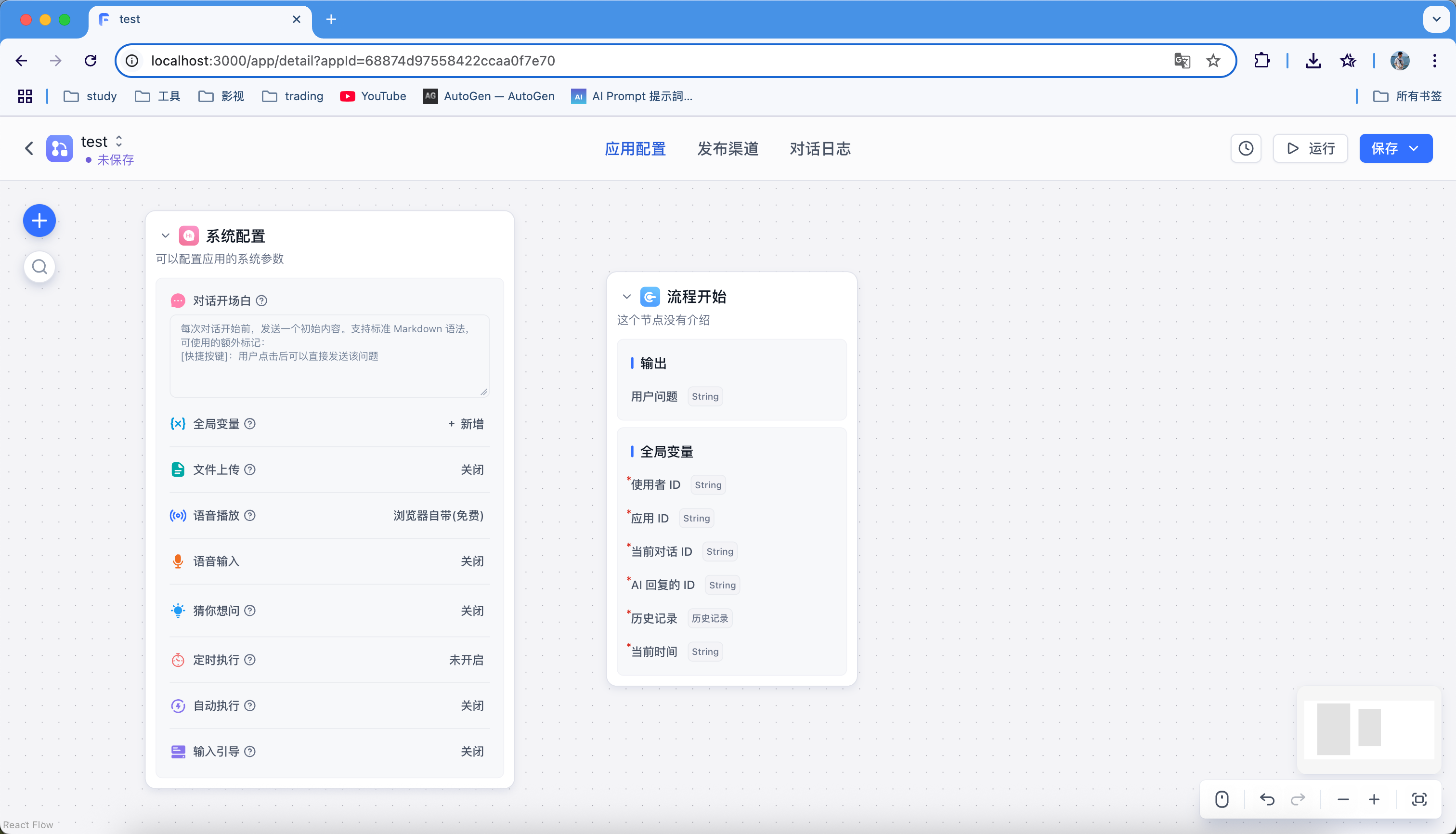
这就是一个普通空白的工作流,每个应用都是流程开始(用户问题)
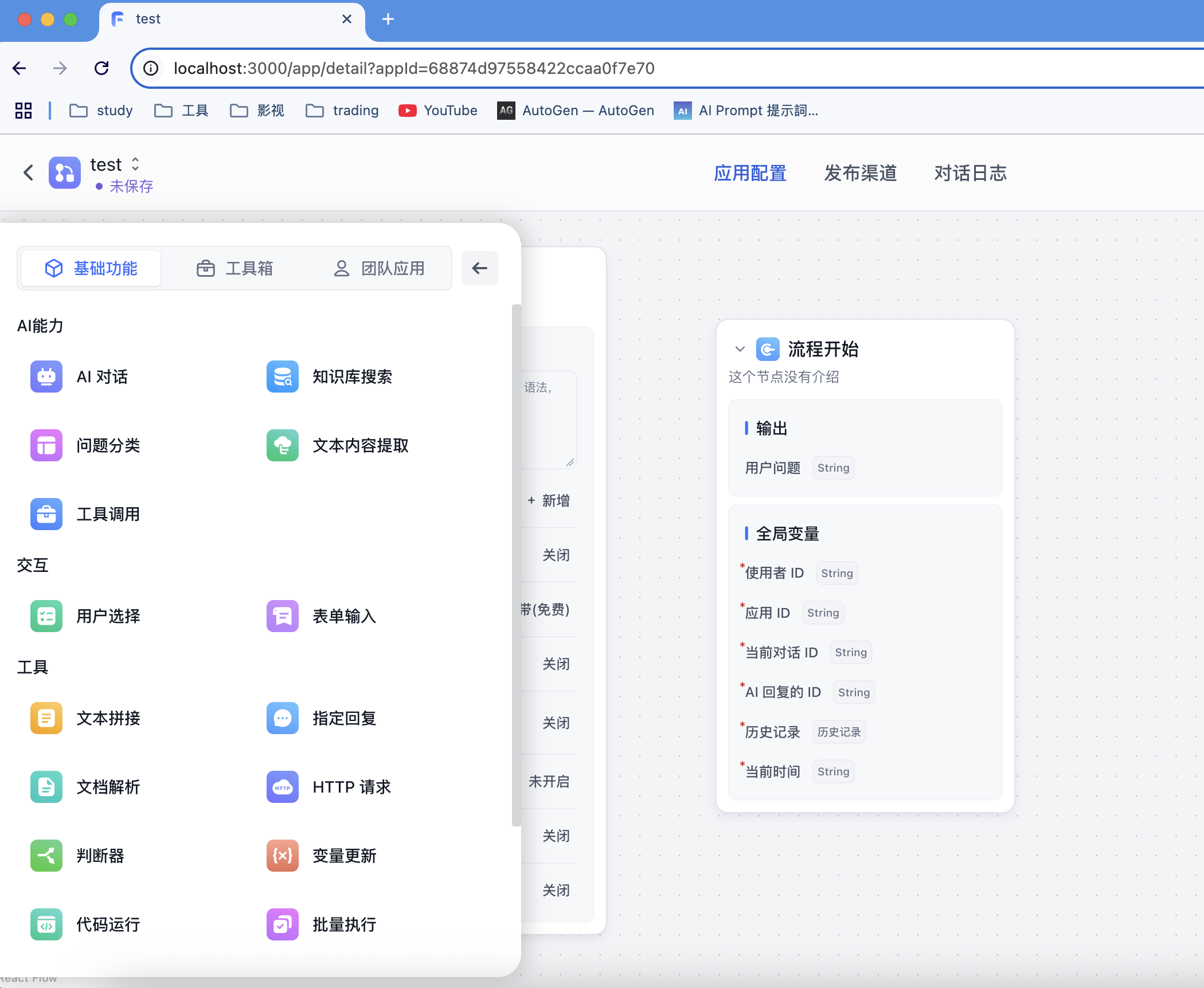
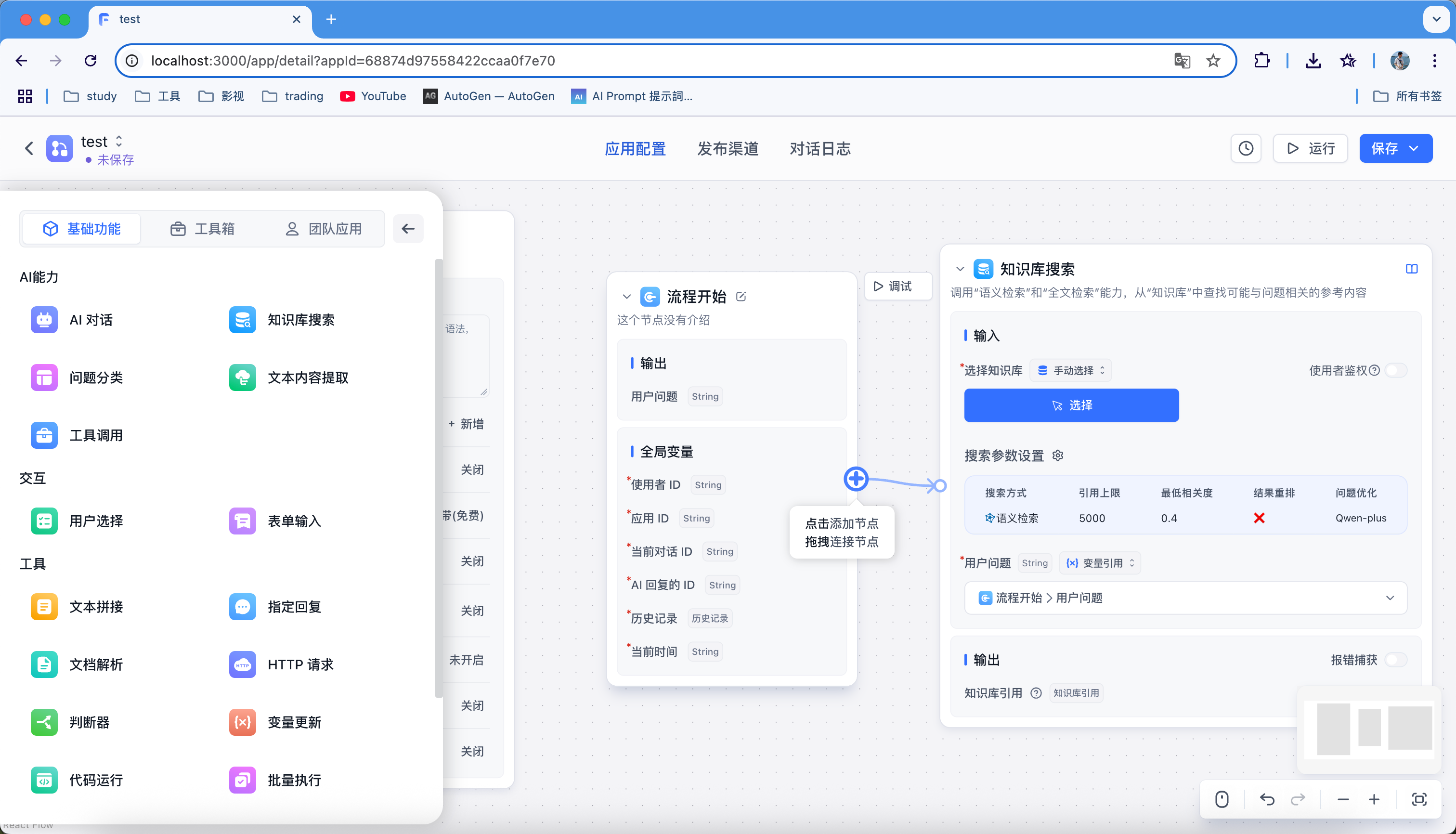
接着通过拖拉拽使用组件,再进行连接,这里需要注意每个节点需要有闭环,不然运行会提示异常
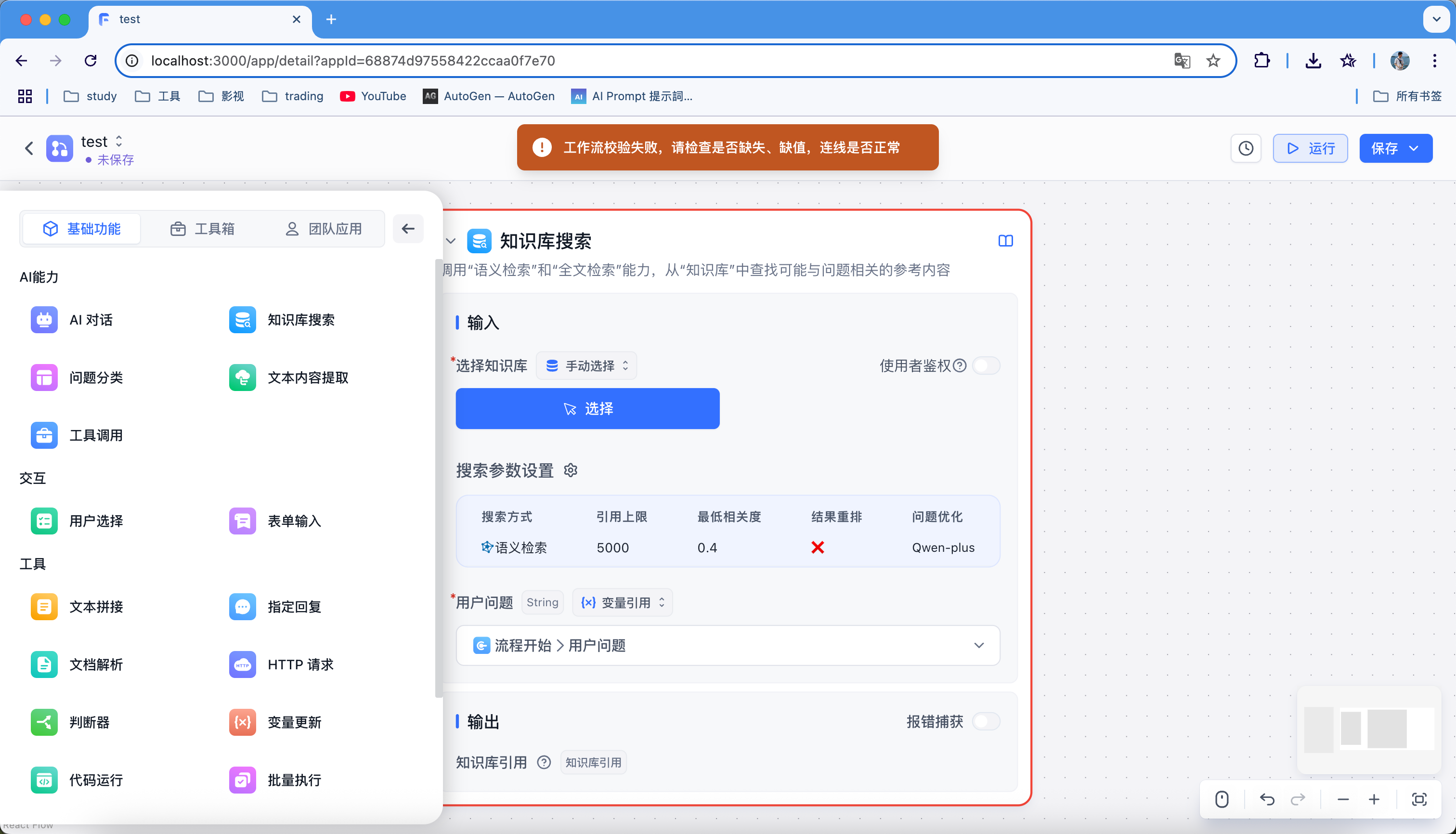
2.4 示例讲解
接下是我做的一个示例:
用户提问 -(其中我做了全局变量更新) ->问题分类 ->
- 关于酒店运营问题 -> 知识库检索 -> ai大模型输出
- 关于酒店数据分析等问题 -> 判断器->
1、 关于流量问题 -> http请求 + 知识库检索 -> ai模型输出
2、其他问题 -> 指定回答
- 打招呼,问候等问题 -> 指定回答
一、初始化
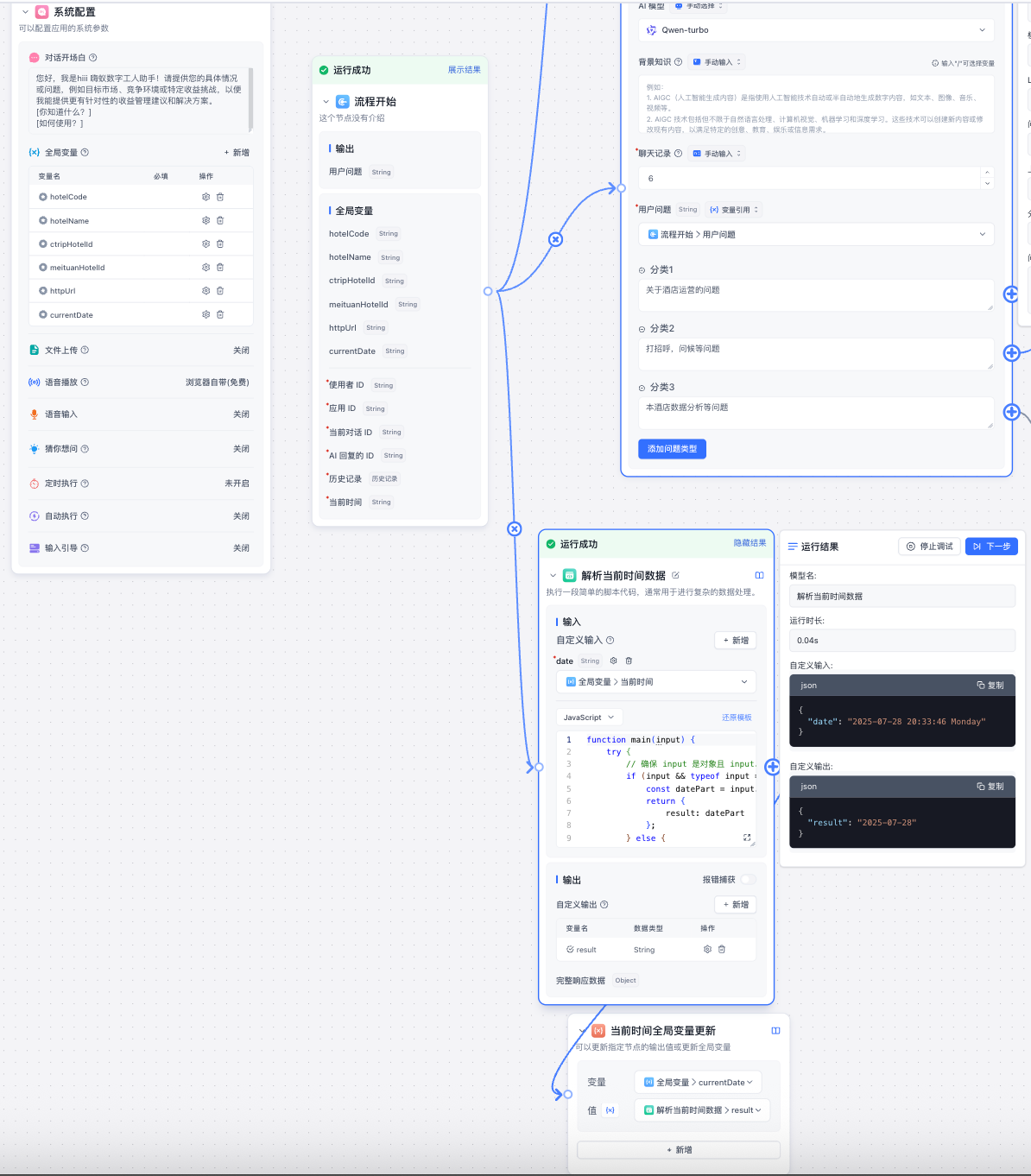
(1)流程开始添加【代码运行】节点引用全局变量当前时间,因为时间格式不是不需要的所以把它解析成我想要的格式并更新到`系统配置`的全局变量中
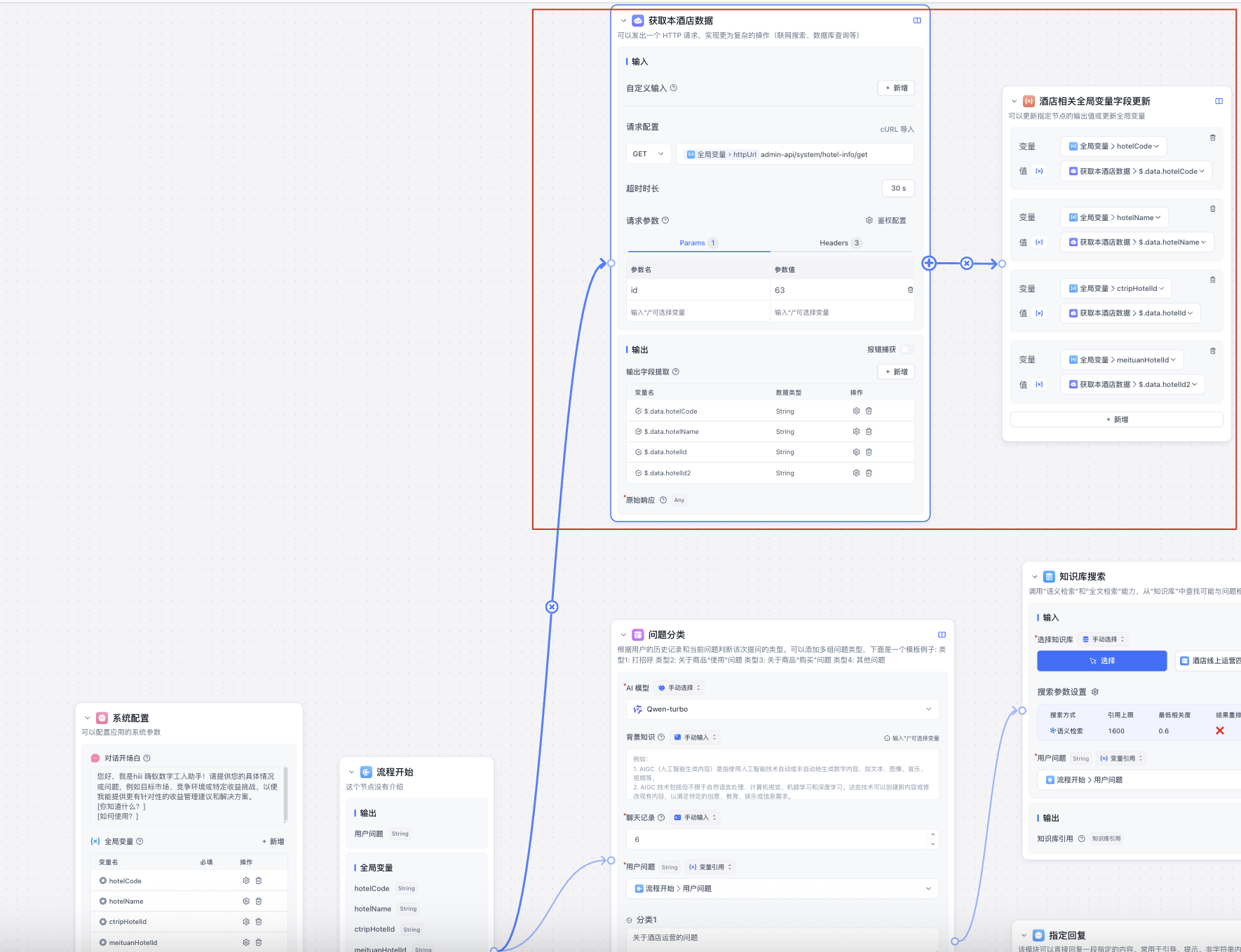
(2)流程开始添加【HTTP请求】节点,配置接口地址、参数和headers,通过JSONPath语法提取响应的字段,最后更新全局变量
二、问题分类
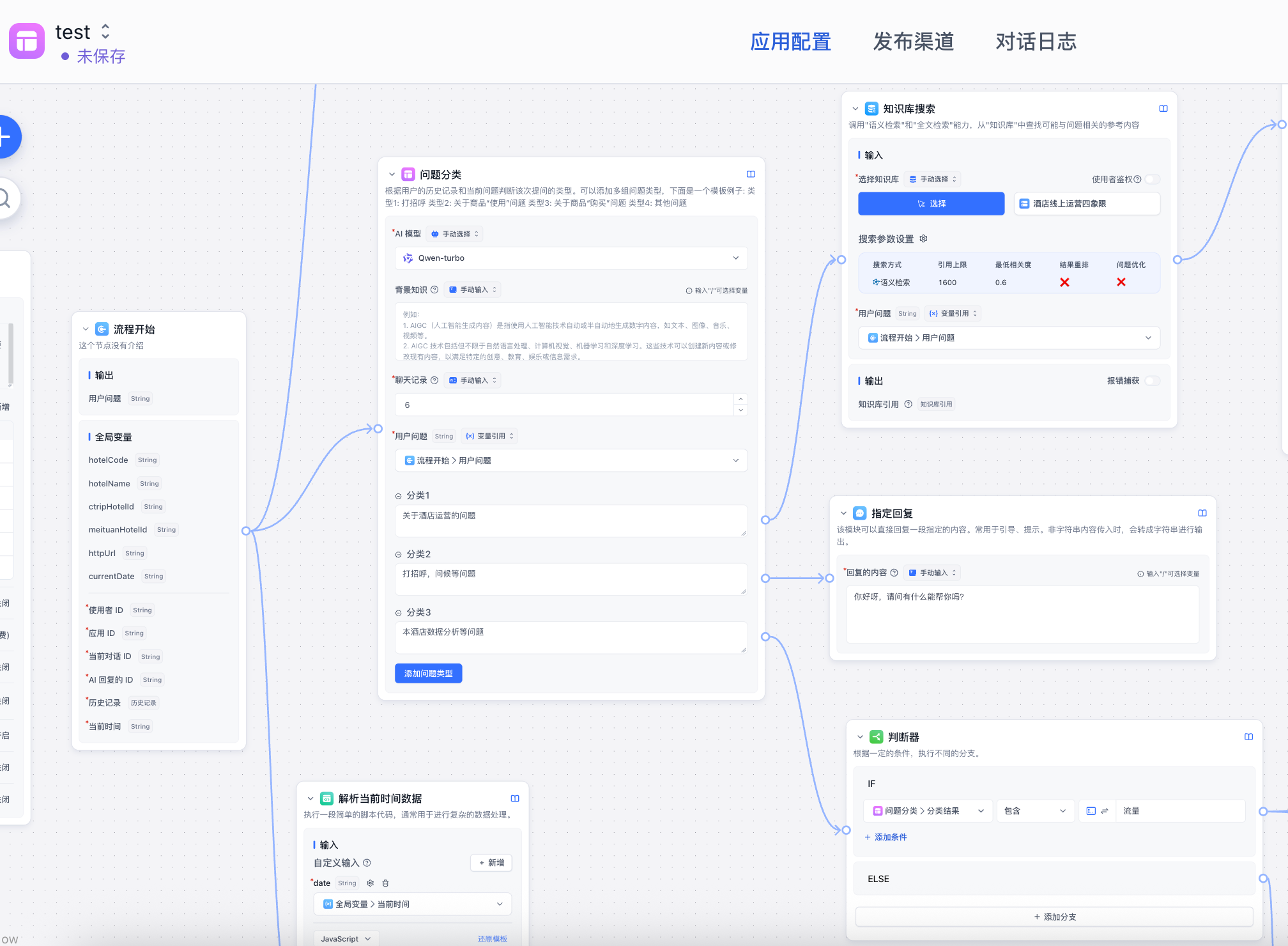
【问题分类】相当于使用ai模型分析用户意图, 这里我添加了三类问题并且每个问题都连接不同节点处理,这样用户的问题只能派指一条执行
三、本地数据+知识库
- 首先我添加了判断器来判断根据关键字再执行不同节点,这里也可以再添加一个【问题分类】分析问题调用不同接口获取数据(当前简单只有一个请求)
- 接着使用【文本内容提取】这想当于让ai模型根据用户问题提取可用的接口参数,再去调用接口。看图可以发现我的接口参数引用了全局变量,也就是初始化时获取的固定值
- 在执行【文本内容提取】节点同时我又使用了【知识库】,接着使用【文本拼接】将接口数据、知识库和问题结合给ai大模型输出
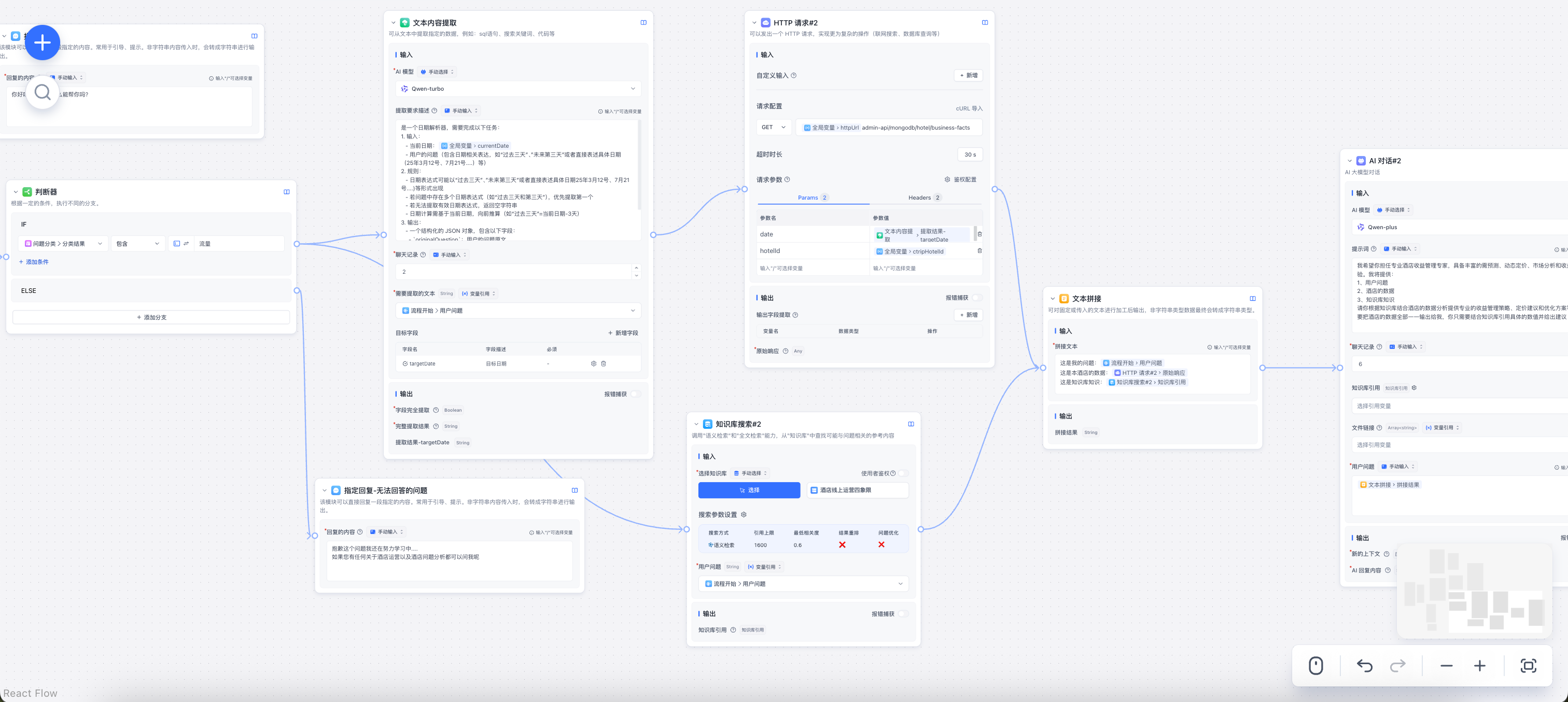
四、调试
可以直接触碰任何节点,从当前节点开始执行(需要填写当前接口需要的参数)
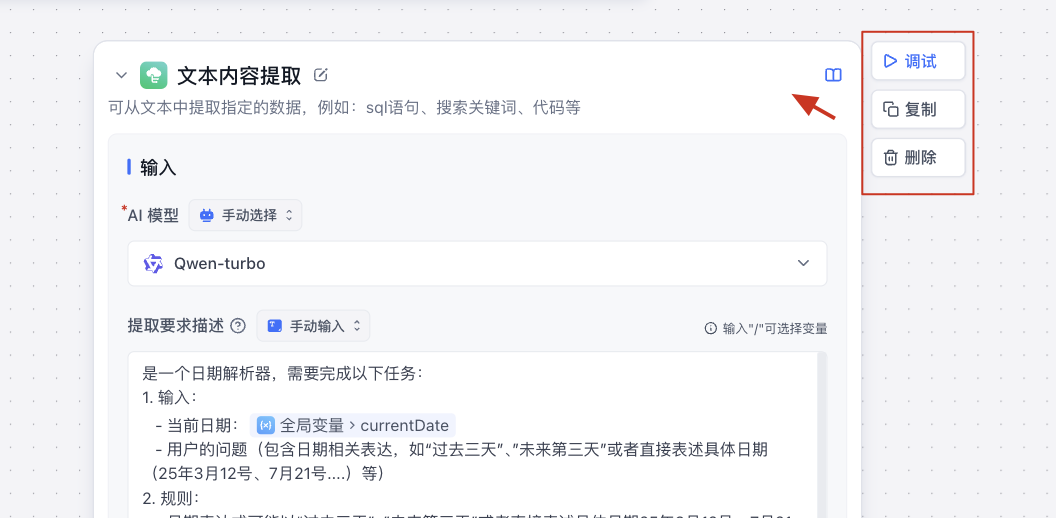
运行调试:模型回答结束后可以查看上下问引用,工作流总运行时间以及查看详情
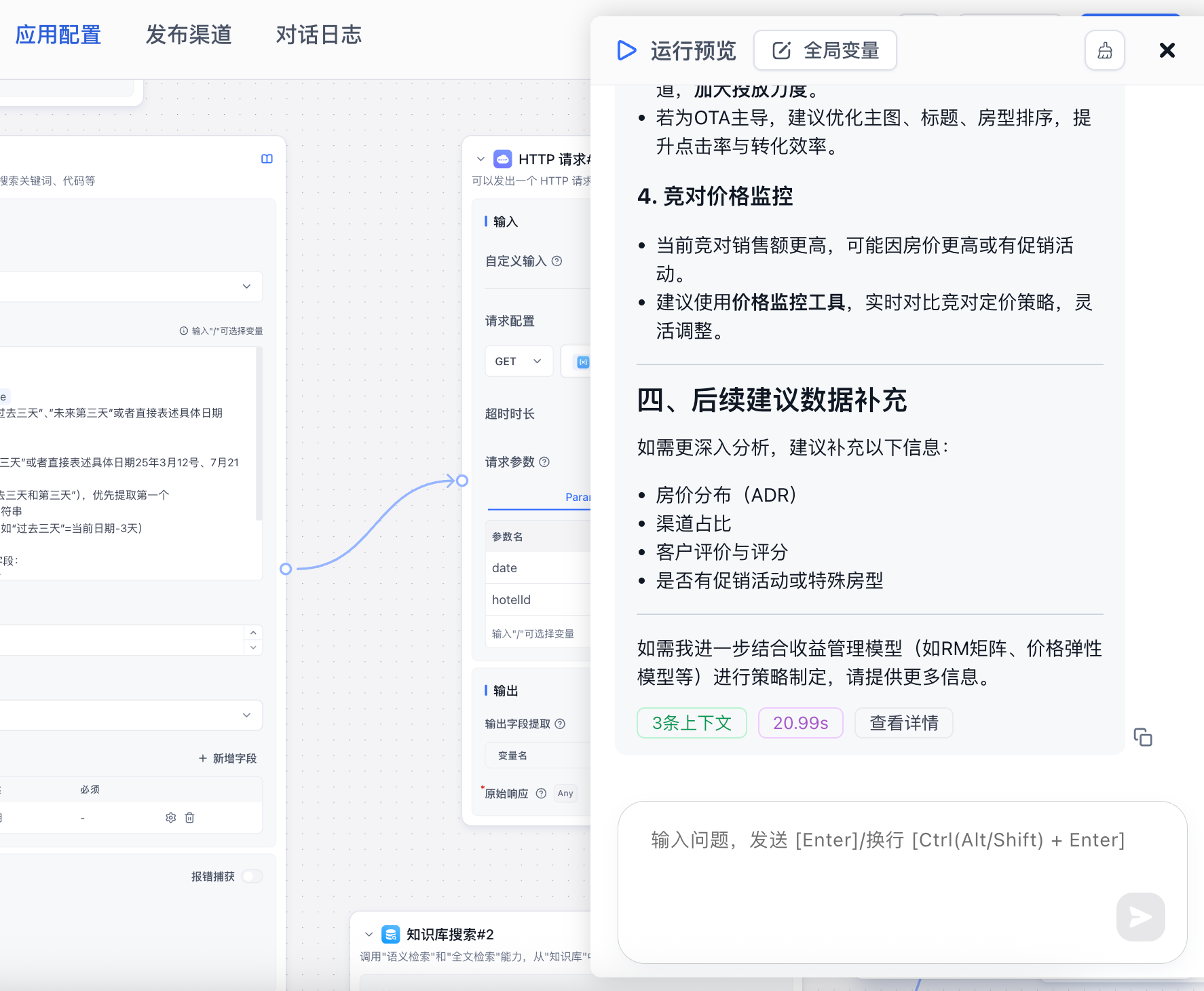
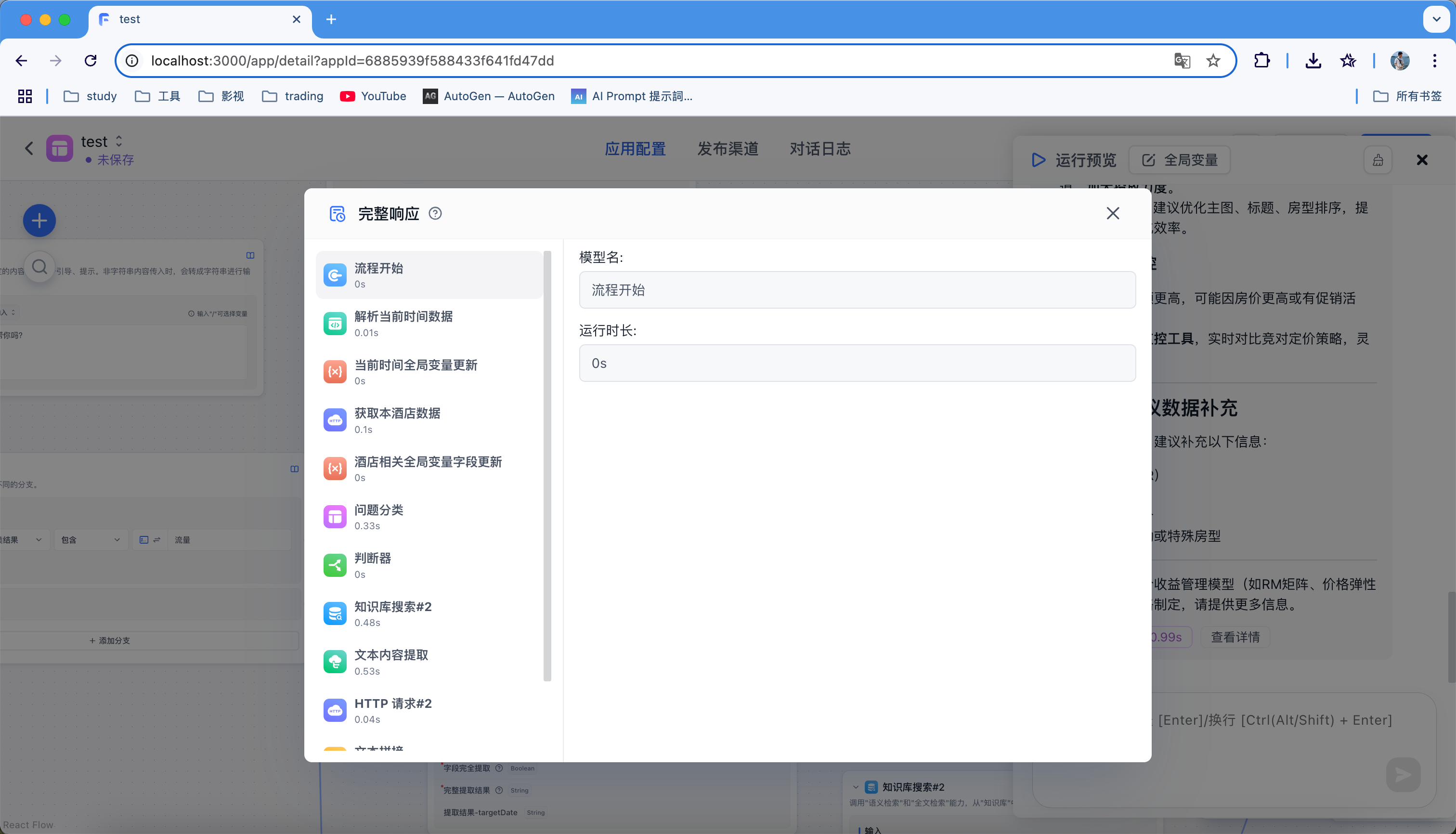
查看详情:这里可以看到每个步骤的完整响应
结语
以上就是我的分享,感谢大家看到最后。其中还有很多工具没有一一演示了,比如**数据库连接、网页内容抓取等。**如果创建一个应用就很复杂的话,我们也没必要通过一个工作流实现,不易查看,可以抽离单个工作流为一个应用,最后再建一个工作流把这些应用整合起来用。
祝你早安午安晚安。
祉猷并茂,顺遂无虞。