本章将介绍线程及其并发编程。在Python标准库中,有一个threading模块,它允许我们轻松地实现线程,并提供一整套用于线程同步的实用工具。整章内容将围绕该模块展开,逐一介绍所有提供的类及其功能。
章节结构
本章将讨论以下内容:
- 线程(Threads)
- 锁与递归锁(Lock 和 RLock)
- 信号量(Semaphore)
- 条件变量(Condition)
- 事件(Event)
- 线程池执行器(ThreadPoolExecutor)
线程(Threads)
并发编程的主角正是线程。对此,threading模块提供了Thread类:
ini
class threading.Thread(group=None,
target=None,
name=None,
args=(),
kwargs={},
*,
daemon=None)Thread()构造函数接受多个参数,其中最重要和最常用的是target和args。target是线程中要调用的函数,args是传递给该函数的参数。
我们通过一个实际例子立刻感受这种对象的功能。在程序中,我们定义了5个线程,它们相互竞争执行。所有线程的目标函数相同,暂且称为function()。该函数本身不执行任务,仅占用一段短暂时间,以模拟执行一组指令的耗时:
php
import threading
import time
def function(i):
print("start Thread %i\n" % i)
time.sleep(2)
print("end Thread %i\n" % i)
return
t1 = threading.Thread(target=function, args=(1,))
t2 = threading.Thread(target=function, args=(2,))
t3 = threading.Thread(target=function, args=(3,))
t4 = threading.Thread(target=function, args=(4,))
t5 = threading.Thread(target=function, args=(5,))
t1.start()
t2.start()
t3.start()
t4.start()
t5.start()
print("END Program")从代码可以看出,首先定义了5个Thread类的实例,分别对应5个线程,使用变量t1、t2等表示。线程的执行随后通过调用start()方法启动。
运行程序,我们将得到如下输出:
sql
start Thread 1
start Thread 2
start Thread 3
start Thread 4
start Thread 5
END Program
end Thread 1
end Thread 2
end Thread 4
end Thread 3
end Thread 5如果观察执行结果,我们会发现:
- 程序同时启动了五个线程,但随后并未等待它们完成就结束了,导致命令提示符回到输入状态。实际上,这五个线程仍在后台运行,并不断在命令行输出结果。
- 输出中各线程结束的顺序与开始的顺序不同,并且每次运行时可能变化。这是线程并发执行的正常现象,执行时长和顺序往往不可预测。
因此,后续我们会看到如何使用同步方法来管理线程的执行,确保程序按预期进行。
join() 方法
在前面的示例中,我们看到在程序中启动多个线程时,可能会出现主程序在线程结束之前就结束了的情况。这个问题很容易解决,因为 Python 的 threading 模块为此提供了 join() 方法。该方法用于在线程对象上调用,使主程序在继续执行之前等待该线程执行完毕。因此,在有多个线程的情况下,我们可以对每一个线程都调用 join() 方法。
将该方法应用到之前的示例中:
php
import threading
import time
def function(i):
print("start Thread %i" % i)
time.sleep(2)
print("end Thread %i" % i)
return
t1 = threading.Thread(target=function, args=(1,))
t2 = threading.Thread(target=function, args=(2,))
t3 = threading.Thread(target=function, args=(3,))
t4 = threading.Thread(target=function, args=(4,))
t5 = threading.Thread(target=function, args=(5,))
t1.start()
t2.start()
t3.start()
t4.start()
t5.start()
t1.join()
t2.join()
t3.join()
t4.join()
t5.join()
print("END Program")在这种情况下,运行程序后我们会看到如下输出:
sql
start Thread 1
start Thread 2
start Thread 3
start Thread 4
start Thread 5
end Thread 3
end Thread 1
end Thread 2
end Thread 4
end Thread 5
END Program可以看到,程序现在会等待所有线程执行完成后才会关闭。
但我们可以再深入思考一下。join() 方法也可以作为程序中的一个同步点来使用。例如,我们希望主程序的一部分代码先执行完,再等待一些线程执行完成,之后再继续执行其他操作,甚至可以在之后启动更多线程。
让我们通过修改前面的示例,来看一个简单的例子:
scss
t1.start()
t2.start()
t1.join()
t2.join()
print("First set of threads done")
print("The program can execute other code here")
t3.start()
t4.start()
t5.start()
t3.join()
t4.join()
t5.join()
print("Second set of threads done")
print("END Program")运行这个修改后的程序,我们将看到如下输出:
sql
start Thread 1
start Thread 2
end Thread 2
end Thread 1
First set of threads done
The program can execute other code here
start Thread 3
start Thread 4
start Thread 5
end Thread 3
end Thread 5
end Thread 4
Second set of threads done
END Program如你所见,使用 join() 方法可以在程序中设置一个同步点,使程序在继续之前等待某些线程完成执行,然后再从该点继续执行后续代码。
常见的线程同步模式
在前面的示例中,使用多个线程时,你可能注意到代码中有很多重复的部分。我们为每个线程分别调用了 start() 和 join() 方法,写了很多类似的语句。随着线程数量的增加,这种方式会显得更加繁琐。不过,我们可以用更简洁、更方便的方式来编写代码。
以之前涉及 5 个线程的示例为例,我们可以将代码重写如下:
php
import threading
import time
def function(i):
print("start Thread %i" % i)
time.sleep(2)
print("end Thread %i" % i)
return
n_threads = 5
threads = []
for i in range(n_threads):
t = threading.Thread(target=function, args=(i,))
threads.append(t)
t.start()
for i in range(n_threads):
threads[i].join()这样写的代码更加简洁、易读。通过一个 for 循环来控制线程数量,我们避免了显式地为每个线程命名(如 t1、t2、t3 等),同时也避免了分别调用每个线程的 start() 和 join() 方法。
运行这段代码后,输出结果与之前的示例相同:
sql
start Thread 0
start Thread 1
start Thread 2
start Thread 3
start Thread 4
end Thread 0
end Thread 1
end Thread 2
end Thread 3
end Thread 4注意事项:
不要像下面这样写,除非你是故意要实现串行行为:
scss
for i in range(n_threads):
t = threading.Thread(target=function, args=(i,))
threads.append(t)
t.start()
t.join()如果将 join() 方法写在与 start() 相同的循环中,每次都会等待当前线程执行完毕后才启动下一个线程。这样就不再是多个线程同时执行的情况,而是变成了串行执行:第一个线程执行完成后,才启动第二个线程,然后第三个,以此类推。这种情况下就无法体现多线程的并发优势。
concurrent.futures 模块与 ThreadPoolExecutor
除了 threading 模块外,标准库中还有一个非常有用的模块,可以帮助我们更方便地使用线程(下一章还会介绍它在进程中的用法)。这个模块就是 concurrent.futures,它提供了一个高层接口来异步执行可调用对象(callable)。
在这个模块中,有一个非常好用的类------ThreadPoolExecutor,它可以帮助我们同时管理多个线程。事实上,当程序中需要管理很多线程时,最有效率的方式就是创建一个 ThreadPoolExecutor。
举个例子,如果我们想要同时启动四个线程(它们分别执行某些函数),与其写四个 Thread 实例、四次 start() 调用和四次 join() 调用,不如用 ThreadPoolExecutor 来简化代码。
下面是一个例子:
scss
import concurrent.futures
import time
def thread(num, t):
print("Thread %s started" % num)
time.sleep(t)
print("Thread %s ended" % num)
with concurrent.futures.ThreadPoolExecutor(max_workers=4) as t:
t.submit(thread, 1, 10)
t.submit(thread, 2, 1)
t.submit(thread, 3, 10)
t.submit(thread, 4, 4)
print("Program ended")运行这段代码,我们会得到类似如下的结果:
Thread 1 started
Thread 1 ended
Thread 2 started
Thread 2 ended
Thread 3 started
Thread 3 ended
Thread 4 started
Thread 4 ended
Program ended看起来线程是一个接一个地顺序执行 的,并且似乎带有某种同步机制。其实,ThreadPoolExecutor 内部确实会对线程任务做一定的调度和管理,看上去更整齐。
如果不用 ThreadPoolExecutor,而是直接用 threading 模块来实现同样的逻辑,比如这样:
scss
import threading
import time
def thread(num, t):
print("Thread %s started" % num)
time.sleep(t)
print("Thread %s ended" % num)
t1 = threading.Thread(target=thread, args=(1, 10))
t2 = threading.Thread(target=thread, args=(2, 1))
t3 = threading.Thread(target=thread, args=(3, 10))
t4 = threading.Thread(target=thread, args=(4, 4))
t1.start()
t2.start()
t3.start()
t4.start()
t1.join()
t2.join()
t3.join()
t4.join()
print("Program ended")运行这个版本的代码,输出结果会完全不同:
Thread 1 started
Thread 2 started
Thread 3 started
Thread 4 started
Thread 2 ended
Thread 4 ended
Thread 1 ended
Thread 3 ended
Program ended可以看到,这里线程是同时启动并并发执行的,每个线程的结束时间取决于它自身的执行时长。
在上面的示例中,我们用多个线程执行的是同一个函数 。但还有一种非常常见的情况是:每个线程执行不同的函数 。接下来我们将看看这种情况下 ThreadPoolExecutor 的用法会有什么不同。
线程竞争
下面是一个简单又直观的例子,用来观察两个竞争线程(并发编程)的行为。每个线程分别执行不同的函数 addA() 和 addB(),它们模拟一个周期性执行的操作,分别在每次迭代时耗时 timeA 和 timeB。这两个线程会同时启动,由于 Python 中线程无法真正并行执行(同一时刻只能执行一个线程),它们会在程序运行期间竞争尽快完成各自的循环(COUNT 定义为 5 次迭代)。为了监控两个线程的执行顺序,这两个函数在每个循环中会向一个字符串中添加对应线程的字母 A 和 B,表示各自的执行:
ini
import threading
import time
sequence = ""
COUNT = 5
timeA = 5
timeB = 10
def addA():
global sequence
for i in range(COUNT):
time.sleep(timeA)
sequence = "%sA" % sequence
print("Sequence: %s" % sequence)
def addB():
global sequence
for i in range(COUNT):
time.sleep(timeB)
sequence = "%sB" % sequence
print("Sequence: %s" % sequence)
# 主程序
t1 = threading.Thread(target=addA)
t2 = threading.Thread(target=addB)
t1.start()
t2.start()
t1.join()
t2.join()在程序执行期间,你可以观察到执行序列的变化。如果运行上面这段代码,你可能得到类似如下的结果:
makefile
Sequence: A
Sequence: AA
Sequence: AAB
Sequence: AABA
Sequence: AABAA
Sequence: AABAAB
Sequence: AABAABA
Sequence: AABAABAB
Sequence: AABAABABB
Sequence: AABAABABBB从结果可以看出,两个线程在执行时以一种任意的方式交替进行。你会发现每次运行的序列可能都不同。你还可以通过调整 timeA 和 timeB 变量的值来改变每个线程的执行时间,从而影响两个竞争线程的执行顺序,增加一些有趣的变化。
使用 Thread 子类
在之前的例子中,我们通过 Thread() 构造函数定义线程,并将函数名通过 target 参数传入:
ini
t = threading.Thread(target=function_name)这种方式将线程和线程要执行的代码(定义在函数中)分成了两个独立的实体。
另一种写法是定义一个新的线程类,继承自 Thread,并将要执行的代码写在这个类的方法里,这样就不需要再调用外部函数。通过这种方式,线程就是真正的对象,符合面向对象编程思想。
首先,我们直接从 threading 模块导入 Thread 类:
javascript
from threading import Thread接着定义 Thread 的子类,并重写 __init__(self[, args]) 方法,可以在子类初始化时添加自定义代码:
ruby
class myThread(Thread):
def __init__(self):
Thread.__init__(self)
# 在这里添加你的代码然后重写 run(self[, args]) 方法,定义线程启动时执行的代码(当调用 start() 方法时,会执行这里的代码):
ruby
def run(self):
# 在这里写线程要执行的代码随后,创建新定义的 myThread 类实例,如果有参数则传入,最后调用实例的 start() 方法启动线程,执行 run() 中的代码:
scss
t = myThread()
t.start()现在我们回顾之前的例子,两个不同的方法通过 target 选项传给同一个 Thread 类的两个实例。基于上面介绍的方法,这两个函数可以改写成两个不同的子类,每个子类在 run() 方法中实现对应的功能。
改写后的代码如下:
python
from threading import Thread
import time
sequence = ""
COUNT = 5
timeA = 5
timeB = 10
class ThreadA(Thread):
def __init__(self):
Thread.__init__(self)
def run(self):
global sequence
for i in range(COUNT):
time.sleep(timeA)
sequence = "%sA" % sequence
print("Sequence: %s" % sequence)
class ThreadB(Thread):
def __init__(self):
Thread.__init__(self)
def run(self):
global sequence
for i in range(COUNT):
time.sleep(timeB)
sequence = "%sB" % sequence
print("Sequence: %s" % sequence)
# 主程序
t1 = ThreadA()
t2 = ThreadB()
t1.start()
t2.start()
t1.join()
t2.join()这样,线程的执行逻辑就封装在了线程类本身,代码更符合面向对象设计。
同步机制
正如我们在上一节看到的,线程是并发执行的,因此它们同时运行(但并非真正并行)。这种特性常常导致不可预测的行为,如果不加控制,可能会引发竞态条件 问题,尤其是在多个线程争抢共享资源访问时。为此,threading 模块提供了一系列有用的类,帮助实现线程同步机制。它们种类多样,各有特点。本章中我们将逐一介绍,并通过简单示例帮助理解其工作原理。
threading 模块提供的同步对象包括:
LockRLockSemaphoreConditionEvent
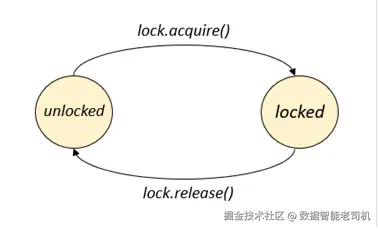
Lock(锁)
在所有同步类中,Lock 是同步级别最低的一种。它本质上只有两种状态:
- Locked(已锁定)
- Unlocked(未锁定)
Lock 主要有两个方法:
acquire()release()
它们的作用是改变锁的状态,在"锁定"和"未锁定"之间切换。
当使用 Lock() 构造一个锁时,初始状态是未锁定。当某个线程调用 lock.acquire() 方法时,锁变为锁定状态,该线程将获得锁且继续执行;如果锁已经被其他线程占用,调用 acquire() 的线程将被阻塞,进入等待状态。
当另一个线程调用 lock.release() 方法时,锁释放变为未锁定状态,等待的线程(如果有)将被唤醒,继续执行(见图 2.1)。
如果这个同步机制管理不当,反而可能导致比不使用同步更混乱的情况。实际上,可能会有多个线程同时调用了 lock.acquire() 方法,全部在等待至少另一个线程调用 lock.release(),将锁的状态从"锁定"改为"未锁定"。此时,哪个等待线程会被唤醒并继续执行是不可预测的,且可能因实现不同而异。
为了演示锁的工作原理,举一个有两个线程、分别执行不同函数的例子。我们称这两个函数为 funcA() 和 funcB()。在第一章中我们看到竞争的线程共享进程内存,因此这里使用一个共享变量 shared_data,这是两个线程都可以访问的整数。第一个线程(执行 funcA())将该值加10,而另一个线程(执行 funcB())将该值减10。两个函数都执行10次该操作。
代码如下:
scss
import threading
import time
shared_data = 0
def funcA():
global shared_data
for i in range(10):
local = shared_data
local += 10
time.sleep(1)
shared_data = local
print("Thread A wrote: %s" % shared_data)
def funcB():
global shared_data
for i in range(10):
local = shared_data
local -= 10
time.sleep(1)
shared_data = local
print("Thread B wrote: %s" % shared_data)
t1 = threading.Thread(target=funcA)
t2 = threading.Thread(target=funcB)
t1.start()
t2.start()
t1.join()
t2.join()运行后,输出可能如下:
less
Thread A wrote: 10
Thread B wrote: -10
Thread A wrote: 20
Thread B wrote: -20
Thread B wrote: -30
Thread A wrote: 30
Thread A wrote: 40
Thread B wrote: 20
Thread A wrote: 50
Thread B wrote: 10
Thread A wrote: 60
Thread B wrote: 0
Thread A wrote: 70
Thread B wrote: -10
Thread B wrote: -20
Thread A wrote: 80
Thread B wrote: 70
Thread A wrote: 90
Thread B wrote: 60
Thread A wrote: 100首先可以看到,两个函数内部的循环是分开执行的。线程对各自的循环操作是原子性的,每一步循环执行时,funcA() 和 funcB() 的执行交替进行(因为 Python 线程不能真正并行)。因此,每次循环执行时,两个函数的某一个循环会先执行。但这正是多线程同时运行时我们预期的行为。
问题出现在共享变量的值上。理论上,执行完毕时 shared_data 的值应该是 0,但实际输出中它是 100(但这个值是随机的,每次运行都不同)。这就是典型的竞态条件。从输出可以看到,这种错误不止出现一次,即使只有两个线程,循环只有10次,竞态问题也很频繁。
显然,为了让程序正常运行,必须使用同步机制协调两个线程访问共享变量,避免竞态条件的发生。threading 模块提供的 Lock 类是最简单的解决方案。
我们在程序开头定义一个 Lock 实例,然后在线程函数中分别调用 acquire() 和 release(),如下:
scss
import threading
import time
shared = 0
lock = threading.Lock()
def funcA():
global shared
for i in range(10):
lock.acquire()
local = shared
local += 10
time.sleep(1)
shared = local
print("Thread A wrote: %s" % shared)
lock.release()
def funcB():
global shared
for i in range(10):
lock.acquire()
local = shared
local -= 10
time.sleep(1)
shared = local
print("Thread B wrote: %s" % shared)
lock.release()
t1 = threading.Thread(target=funcA)
t2 = threading.Thread(target=funcB)
t1.start()
t2.start()
t1.join()
t2.join()这次运行的结果非常不同:
less
Thread A wrote: 10
Thread A wrote: 20
Thread A wrote: 30
Thread A wrote: 40
Thread A wrote: 50
Thread A wrote: 60
Thread A wrote: 70
Thread A wrote: 80
Thread A wrote: 90
Thread A wrote: 100
Thread B wrote: 90
Thread B wrote: 80
Thread B wrote: 70
Thread B wrote: 60
Thread B wrote: 50
Thread B wrote: 40
Thread B wrote: 30
Thread B wrote: 20
Thread B wrote: 10
Thread B wrote: 0可以看到,不再存在竞态条件。共享变量的读取和修改都由一个线程同步进行,避免了错误结果的产生。
不过需要注意的是,引入同步机制后,线程似乎失去了并发的表现。事实上,线程在同步代码块内不再并发执行。从结果看,funcA() 先完整执行了所有 10 次循环并修改共享变量到 100,然后 funcB() 才执行,将共享变量还原到 0。
带有 Lock 的上下文管理协议
threading 模块中所有使用 acquire() 和 release() 方法的对象,比如 Lock 对象,都可以通过 with 语句作为上下文管理器来使用(详见下方注释)。
注: 在 Python 中,with 语句创建了一个运行时上下文,允许你在上下文管理器的控制下执行一段代码块:
csharp
with 表达式:
# 代码块上下文管理器的核心是对与 with 相关联的代码块进行上下文表达式的求值。该表达式必须返回一个实现了上下文管理协议的对象,该协议主要包括两个方法:
__enter__()------ 进入上下文时调用__exit__()------ 退出上下文时调用
此外,with 语句还有一个额外优势,即它集成了 try ... finally 的功能。
因此,使用 with 语句可以写出更易读且更易复用的代码。正因为这些优势,标准库中许多类都支持用 with 语句来替代传统的 try...finally 结构。
对于锁对象来说,进入 with 代码块时会自动调用 acquire() 方法,退出时会自动调用 release() 方法。
也就是说,下面的代码:
csharp
lock.acquire()
try:
# 代码块
finally:
lock.release()可以简写为:
csharp
with lock:
# 代码块我们用支持上下文管理协议的方式改写之前的示例代码:
ini
import threading
import time
shared_data = 0
lock = threading.Lock()
def funcA():
global shared_data
for i in range(10):
with lock:
local = shared_data
local += 10
time.sleep(1)
shared_data = local
print("Thread A wrote: %s" % shared_data)
def funcB():
global shared_data
for i in range(10):
with lock:
local = shared_data
local -= 10
time.sleep(1)
shared_data = local
print("Thread B wrote: %s" % shared_data)
t1 = threading.Thread(target=funcA)
t2 = threading.Thread(target=funcB)
t1.start()
t2.start()
t1.join()
t2.join()如你所见,代码更加简洁且易读。运行时,行为与之前的代码完全一致。
with 语句支持的上下文管理协议,同样适用于 threading 模块中其他使用 acquire() 和 release() 方法实现同步机制的对象,我们在本章后续会介绍它们:
RLockConditionSemaphore
所有这些对象,都可以用 with 语句来简化锁的使用。
使用 Lock 的另一种可能的同步方案
我们继续分析之前的代码。正如我们所见,之前加入的同步机制似乎完全(或至少几乎)取消了两个线程的并发行为。
我们创建的同步机制是最直观的一种,在每个线程内部成对调用 acquire() 和 release() 方法,明确划分了代码块范围。使用 with 语句的上下文管理器时,这两段代码在两个线程中是对称的,结构非常清晰。
但其实,我们并不必须采用这种对称操作。你可以尝试更复杂的同步条件,风险自负。实际上,可以非对称地插入 acquire() 和 release() 调用------比如在代码中不对称的位置调用它们,甚至一个线程调用 acquire(),另一个线程调用 release()。这样就失去了上下文管理器定义的清晰代码块,转而依赖更复杂的同步控制。
在这种情况下,不仅可能出现竞态条件,还可能发生死锁。此外,如果在锁处于未锁定状态时调用 release(),会抛出运行时错误。
不过别灰心,可以通过多做测试,或许还是能找到同步且具备并发性的解决方案。
比如,我们将代码修改如下:
scss
import threading
import time
shared = 0
lock = threading.Lock()
def funcA():
global shared
for i in range(10):
time.sleep(1)
shared += 10
print("Thread A wrote: %s" % shared)
lock.acquire()
def funcB():
global shared
lock.acquire()
for i in range(10):
time.sleep(1)
shared -= 10
print("Thread B wrote: %s" % shared)
lock.release()
t1 = threading.Thread(target=funcA)
t2 = threading.Thread(target=funcB)
t1.start()
t2.start()
t1.join()
t2.join()这里变化很多:
funcA()函数中,acquire()被放在每次迭代结束时调用,但不再调用release();funcB()函数中,acquire()在循环外部执行,且最后调用了release();- 两个函数不再使用局部变量,直接修改共享变量。
运行修改后的代码,可能得到如下输出:
less
Thread A wrote: 10
Thread B wrote: 0
Thread B wrote: -10
Thread A wrote: 0
Thread B wrote: -10
Thread A wrote: 0
Thread A wrote: 10
Thread B wrote: 0
Thread B wrote: -10
Thread A wrote: 0
Thread B wrote: -10
Thread A wrote: 0
Thread A wrote: 10
Thread B wrote: 0
Thread B wrote: -10
Thread A wrote: 0
Thread A wrote: 10
Thread B wrote: 0
Thread B wrote: -10
Thread A wrote: 0如你所见,这次看起来一切正常。最终共享变量的值是 0,并且两个线程之间恢复了并发行为。两个线程的迭代执行顺序再次呈现随机交替的并发状态。
如果不确定两个线程是否轮流执行,或者其中一个线程是否被阻塞而另一个继续运行,可以在调试阶段加入一些打印信息来确认两线程的执行进度。
例如,我们在打印语句中加上循环次数:
scss
import threading
import time
shared = 0
lock = threading.Lock()
def funcA():
global shared
for i in range(10):
time.sleep(1)
shared += 10
print("Thread A wrote: %s, %i" % (shared, i))
lock.acquire()
def funcB():
global shared
lock.acquire()
for i in range(10):
time.sleep(1)
shared -= 10
print("Thread B wrote: %s, %i" % (shared, i))
lock.release()
t1 = threading.Thread(target=funcA)
t2 = threading.Thread(target=funcB)
t1.start()
t2.start()
t1.join()
t2.join()运行后,你会看到两个线程交替完成执行:
less
Thread A wrote: 10, 0
Thread B wrote: 0, 0
Thread B wrote: -10, 1
Thread A wrote: 0, 1
Thread B wrote: -10, 2
Thread A wrote: 0, 2
Thread B wrote: -10, 3
Thread A wrote: 0, 3
Thread B wrote: -10, 4
Thread A wrote: 0, 4
Thread B wrote: -10, 5
Thread A wrote: 0, 5
Thread B wrote: -10, 6
Thread A wrote: 0, 6
Thread B wrote: -10, 7
Thread A wrote: 0, 7
Thread B wrote: -10, 8
Thread A wrote: 0, 8
Thread B wrote: -10, 9
Thread A wrote: 0, 9即使代码中锁的调用顺序不对称,锁机制仍然能正常工作,虽然无法保证每次执行完全相同。
RLock(可重入锁)
另一种用于线程同步的类是 RLock,即可重入锁。这个类与 Lock 非常相似,但不同之处在于同一个线程可以多次获得(acquire)这把锁。除了"锁定-未锁定"状态之外,RLock 还保存了拥有者线程的信息以及递归获取的次数。
和 Lock 一样,线程可以通过调用 acquire() 方法获得 RLock,这时锁进入锁定状态,调用线程成为拥有者。调用 release() 方法则会释放锁。但与 Lock 不同的是,RLock 的 acquire() 和 release() 方法可以成对多次嵌套调用,多个线程调用 acquire() 会加入拥有者列表,只有最后一次 release() 调用才真正释放锁,让其他线程得以继续执行。
举个例子,使用三个线程运行同一个函数,函数内部有两个嵌套的 for 循环,两层循环都访问共享变量。通过设置不同线程的执行时间,能更明显体现并发行为:
scss
import threading
import time
shared = 0
rlock = threading.RLock()
def func(name, t):
global shared
for i in range(3):
rlock.acquire()
local = shared
time.sleep(t)
for j in range(2):
rlock.acquire()
local += 1
time.sleep(2)
shared = local
print("Thread %s-%s wrote: %s" % (name, j, shared))
rlock.release()
shared = local + 1
print("Thread %s wrote: %s" % (name, shared))
rlock.release()
t1 = threading.Thread(target=func, args=('A', 2))
t2 = threading.Thread(target=func, args=('B', 10))
t3 = threading.Thread(target=func, args=('C', 1))
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()运行结果类似:
yaml
Thread A-0 wrote: 1
Thread A-1 wrote: 2
Thread A wrote: 3
Thread A-0 wrote: 4
Thread A-1 wrote: 5
Thread A wrote: 6
Thread A-0 wrote: 7
Thread A-1 wrote: 8
Thread A wrote: 9
Thread B-0 wrote: 10
Thread B-1 wrote: 11
Thread B wrote: 12
Thread B-0 wrote: 13
Thread B-1 wrote: 14
Thread B wrote: 15
Thread B-0 wrote: 16
Thread B-1 wrote: 17
Thread B wrote: 18
Thread C-0 wrote: 19
Thread C-1 wrote: 20
Thread C wrote: 21
Thread C-0 wrote: 22
Thread C-1 wrote: 23
Thread C wrote: 24
Thread C-0 wrote: 25
Thread C-1 wrote: 26
Thread C wrote: 27在这个例子中,和 Lock 一样,同步保证了共享变量的正确管理,但线程的并发行为被牺牲了。没有使用 RLock 的同步机制(即去掉 acquire() 和 release() 调用)时,程序会出现类似下面的结果:
yaml
Thread C-0 wrote: 1
Thread A-0 wrote: 1
Thread C-1 wrote: 2
Thread C wrote: 3
Thread A-1 wrote: 2
Thread A wrote: 3
Thread C-0 wrote: 4
Thread C-1 wrote: 5
Thread C wrote: 6
Thread A-0 wrote: 4
Thread B-0 wrote: 1
Thread A-1 wrote: 5
Thread A wrote: 6
Thread C-0 wrote: 7
Thread B-1 wrote: 2
Thread B wrote: 3
Thread C-1 wrote: 8
Thread C wrote: 9
Thread A-0 wrote: 7
Thread A-1 wrote: 8
Thread A wrote: 9
Thread B-0 wrote: 4
Thread B-1 wrote: 5
Thread B wrote: 6
Thread B-0 wrote: 7
Thread B-1 wrote: 8
Thread B wrote: 9正如结果所示,存在竞态条件,导致共享变量被错误地修改。
信号量(Semaphore)
threading 模块中另一种同步机制是基于信号量的同步原语。信号量是计算机科学史上最古老的同步机制之一,由 Edsger W. Dijkstra 于 1962 年发明。
它的目的是同步管理同一进程中多个线程对共享资源的使用。为此,每个信号量都关联着一个共享资源,允许多个线程访问该资源,直到其内部计数器的值变为负数。
信号量对象与锁类似,主要通过调用 acquire() 和 release() 方法来工作。内部维护一个计数器,每调用一次 acquire(),计数器减一;每调用一次 release(),计数器加一。
因此,如果某线程需要访问受信号量保护的共享资源,它首先调用 acquire() 方法,信号量的计数器减一。如果计数器的值大于或等于零,线程就可以访问资源;如果计数器小于零,线程将被阻塞,直到有其他线程调用 release(),使计数器加一并允许等待线程继续执行,从而访问所需资源。
所以,十分重要的一点是:每个调用过 acquire() 的线程,在访问共享资源完成后,必须调用对应的 release(),以便其他线程能够继续访问该资源,避免死锁的发生。
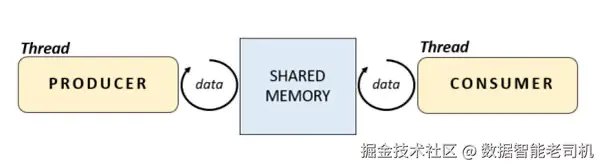
使用 Semaphore 进行同步的示例:生产者-消费者模型
在使用 Semaphore 进行同步时,我们采用生产者-消费者模型(见图 2.2)。该编程模型基于两个对象操作数据流:生产者(Producer)生成数据,通常从外部资源获取;消费者(Consumer)使用生产者生成的数据。问题在于这两个对象独立工作,速度不同且可能变化,数量也可能不一,比如一个生产者多个消费者,或反之。此模型非常适合线程(也适合进程),因此很适合用作示例。
我们定义两个 Thread 子类:Producer 和 Consumer,在它们的 run() 方法中实现执行代码。生产者实现一个 request() 方法,模拟向外部请求数据,执行时延用 time.sleep()。
代码示例:
scss
from threading import Thread, Semaphore
import time
import random
semaphore = Semaphore(1)
shared = 1
class Consumer(Thread):
def __init__(self):
Thread.__init__(self)
global semaphore
def run(self):
global shared
semaphore.acquire()
print("consumer has used this: %s" % shared)
shared = 0
semaphore.release()
class Producer(Thread):
def __init__(self):
Thread.__init__(self)
global semaphore
def request(self):
time.sleep(1)
return random.randint(0, 100)
def run(self):
global shared
semaphore.acquire()
shared = self.request()
print("producer has loaded this: %s" % shared)
semaphore.release()
t1 = Producer()
t2 = Consumer()
t1.start()
t2.start()
t1.join()
t2.join()运行结果示例:
kotlin
producer has loaded this: 60
consumer has used this: 60因为信号量通过 acquire() 和 release() 方法实现同步,也支持上下文管理协议,所以代码可以改写为:
python
from threading import Thread, Semaphore
import time
import random
semaphore = Semaphore(1)
shared = 1
class Consumer(Thread):
def __init__(self):
Thread.__init__(self)
global semaphore
def run(self):
global shared
with semaphore:
print("consumer has used this: %s" % shared)
shared = 0
class Producer(Thread):
def __init__(self):
Thread.__init__(self)
global semaphore
def request(self):
time.sleep(1)
return random.randint(0, 100)
def run(self):
global shared
with semaphore:
shared = self.request()
print("producer has loaded this: %s" % shared)
t1 = Producer()
t2 = Consumer()
t1.start()
t2.start()
t1.join()
t2.join()运行结果相同。
如果让生产者产生多个值(如 5 次),消费者消费同样多次,改写代码:
python
from threading import Thread, Semaphore
import time
import random
semaphore = Semaphore(1)
shared = 1
count = 5
class consumer(Thread):
def __init__(self, count):
Thread.__init__(self)
global semaphore
self.count = count
def run(self):
global shared
for i in range(self.count):
semaphore.acquire()
print("consumer has used this: %s" % shared)
shared = 0
semaphore.release()
class producer(Thread):
def __init__(self, count):
Thread.__init__(self)
self.count = count
global semaphore
def request(self):
time.sleep(1)
return random.randint(0, 100)
def run(self):
global shared
for i in range(self.count):
semaphore.acquire()
shared = self.request()
print("producer has loaded this: %s" % shared)
semaphore.release()
t1 = producer(count)
t2 = consumer(count)
t1.start()
t2.start()
t1.join()
t2.join()结果示例:
kotlin
producer has loaded this: 59
producer has loaded this: 85
producer has loaded this: 20
producer has loaded this: 4
producer has loaded this: 7
consumer has used this: 7
consumer has used this: 0
consumer has used this: 0
consumer has used this: 0
consumer has used this: 0这不是我们期望的行为。生产者连续写入共享资源,消费者被阻塞,直到生产者完成全部五次循环后才开始消费,只消费了最后一个值,之前的四个值被覆盖丢失。
此时,信号量的简单原子管理(acquire() - 代码块 - release())已不满足需求。我们需要重新设计 acquire() 和 release() 的调用机制:
- 生产者在线程执行开始时调用
acquire(),确保先访问共享资源; - 消费者在线程消费后调用
release(),释放资源供生产者继续生产。
示例代码:
python
from threading import Thread, Semaphore
import time
import random
semaphore = Semaphore(1)
shared = 1
count = 5
def request():
time.sleep(1)
return random.randint(0, 100)
class consumer(Thread):
def __init__(self, count):
Thread.__init__(self)
global semaphore
self.count = count
def run(self):
global shared
for i in range(self.count):
semaphore.acquire()
print("consumer has used this: %s" % shared)
shared = 0
class producer(Thread):
def __init__(self, count):
Thread.__init__(self)
self.count = count
global semaphore
def run(self):
global shared
for i in range(self.count):
shared = request()
print("producer has loaded this: %s" % shared)
semaphore.release()
t1 = producer(count)
t2 = consumer(count)
t1.start()
t2.start()
t1.join()
t2.join()结果示例:
kotlin
consumer has used this: 1
producer has loaded this: 0
consumer has used this: 0
producer has loaded this: 47
consumer has used this: 47
producer has loaded this: 25
consumer has used this: 25
producer has loaded this: 82
consumer has used this: 82
producer has loaded this: 23从结果看,虽然活动在消费者和生产者间交替,但第一个访问共享资源的是消费者,导致首次消费的是初始默认值 1,而生产者最后生成的值未被消费。
解决方案是将信号量初始值改为 0:
ini
semaphore = Semaphore(0)再次运行,结果正确:
kotlin
producer has loaded this: 25
consumer has used this: 25
producer has loaded this: 45
consumer has used this: 45
producer has loaded this: 60
consumer has used this: 60
producer has loaded this: 9
consumer has used this: 9
producer has loaded this: 4
consumer has used this: 4这样实现了完美同步,因为这里的原子操作是一个生产-消费的完整周期,涉及两个线程同时配合:
- 同步阶段 1:生产者(1 次循环)+ 消费者(1 次循环)
- 同步阶段 2:生产者(1 次循环)+ 消费者(1 次循环)
- ...依次类推,直到所有循环结束。
之前示例中错误的同步方案是:
- 同步阶段 1:生产者(5 次循环)
- 同步阶段 2:消费者(5 次循环)
综上,当想在代码中引入同步机制时,必须先理解涉及线程的运行机制,再从正确执行的角度划分出"原子阶段",即要重复同步的代码块(通常局限于单线程代码块,但可涵盖多线程协作),并据此设计合适的同步方案。
当同步阶段涉及多个线程时,不能简单使用 with 语句的上下文管理协议,需手动管理 acquire() 和 release() 调用。
Condition(条件变量)
另一种用于线程同步的机制是 Condition 类。Condition 内部包含一个锁(Lock),通过 acquire() 和 release() 方法控制锁的加锁和释放状态。除此之外,它还提供了其他方法:
wait()方法:释放锁并阻塞当前线程,直到有其他线程调用notify()或notify_all()方法。notify()方法:唤醒等待该条件变量的一个线程(如果有的话)。notify_all()方法:唤醒所有等待该条件变量的线程。
我们回到之前使用 Semaphore 的例子,这次用 Condition 来实现线程同步。修改后的代码如下:
scss
from threading import Thread, Condition
import time
import random
condition = Condition()
shared = 1
count = 5
class Consumer(Thread):
def __init__(self, count):
Thread.__init__(self)
global condition
self.count = count
def run(self):
global shared
for i in range(self.count):
condition.acquire()
if shared == 0:
condition.wait()
print("consumer has used this: %s" % shared)
shared = 0
condition.notify()
condition.release()
class Producer(Thread):
def __init__(self, count):
Thread.__init__(self)
self.count = count
global condition
def request(self):
time.sleep(1)
return random.randint(0, 100)
def run(self):
global shared
for i in range(self.count):
condition.acquire()
shared = self.request()
print("producer has loaded this: %s" % shared)
condition.wait()
if shared == 0:
condition.notify()
condition.release()
t1 = Producer(count)
t2 = Consumer(count)
t1.start()
t2.start()
t1.join()
t2.join()运行该代码,结果类似于:
kotlin
producer has loaded this: 43
consumer has used this: 43
producer has loaded this: 98
consumer has used this: 98
producer has loaded this: 51
consumer has used this: 51
producer has loaded this: 57
consumer has used this: 57
producer has loaded this: 40
consumer has used this: 40在这个例子中,Condition 的同步机制与 Semaphore 类似,同样能有效协调生产者与消费者线程的运行。
Event(事件)
除了 Semaphore 和 Condition,还有另一种同步机制------Event。从概念上讲,Event 是最简单的线程间通信机制之一,即一个线程向另一个等待某事件发生的线程发送信号。
Event 对象管理一个内部的布尔标志。它有两个方法用来设置该标志的值:
set():将标志设为Trueclear():将标志设为False(默认值)
还有一个 wait() 方法,调用它的线程会阻塞,直到标志变为 True。
换句话说,一个线程调用 wait() 时会"冻结",等待事件发生;当另一个线程调用 set() 时,前者解除阻塞继续执行,随后调用 clear() 重置事件状态。
以之前的生产者-消费者示例为基础,我们用 Event 替代之前的同步机制,代码如下:
python
from threading import Thread, Event
import time
import random
event = Event()
shared = 1
count = 5
class Consumer(Thread):
def __init__(self, count):
Thread.__init__(self)
global event
self.count = count
def run(self):
global shared
for i in range(self.count):
event.wait()
print("consumer has used this: %s" % shared)
shared = 0
event.clear()
class Producer(Thread):
def __init__(self, count):
Thread.__init__(self)
self.count = count
global event
def request(self):
time.sleep(1)
return random.randint(0, 100)
def run(self):
global shared
for i in range(self.count):
shared = self.request()
print("producer has loaded this: %s" % shared)
event.set()
t1 = Producer(count)
t2 = Consumer(count)
t1.start()
t2.start()
t1.join()
t2.join()运行结果类似:
kotlin
producer has loaded this: 40
consumer has used this: 40
producer has loaded this: 100
consumer has used this: 100
producer has loaded this: 15
consumer has used this: 15
producer has loaded this: 27
consumer has used this: 27
producer has loaded this: 94
consumer has used this: 94如结果所示,两个线程之间的同步非常完美。
队列(Queue)
我们继续扩展之前的例子。到目前为止,我们只用了一个生产者线程和一个消费者线程。如果增加线程数量,会发生什么呢?
我们修改程序,让四个线程同时工作:两个生产者线程和两个消费者线程:
scss
from threading import Thread, Event
import time
import random
event = Event()
shared = 1
count = 5
class Consumer(Thread):
def __init__(self, count):
Thread.__init__(self)
global event
self.count = count
def run(self):
global shared
for i in range(self.count):
event.wait()
print("consumer has used this: %s" % shared)
shared = 0
event.clear()
class Producer(Thread):
def __init__(self, count):
Thread.__init__(self)
self.count = count
global event
def request(self):
time.sleep(1)
return random.randint(0, 100)
def run(self):
global shared
for i in range(self.count):
shared = self.request()
print("producer has loaded this: %s" % shared)
event.set()
t1 = Producer(count)
t2 = Producer(count)
t3 = Consumer(count)
t4 = Consumer(count)
t1.start()
t2.start()
t3.start()
t4.start()
t1.join()
t2.join()
t3.join()
t4.join()运行后,可能得到如下结果:
kotlin
producer has loaded this: 92
consumer has used this: 92
consumer has used this: 0
producer has loaded this: 53
consumer has used this: 53
consumer has used this: 0
producer has loaded this: 62
consumer has used this: 62
producer has loaded this: 70
consumer has used this: 70
consumer has used this: 0
producer has loaded this: 7
consumer has used this: 7
producer has loaded this: 46
consumer has used this: 46
producer has loaded this: 30
producer has loaded this: 43
consumer has used this: 43
producer has loaded this: 36
producer has loaded this: 59如结果所示,四个线程的行为不正确。共享变量的使用不同步,两个生产者线程产生的许多值丢失,消费者有时读取到 0,且未等待新值产生。
那么,如何解决这个问题?
这时,Queue 派上用场。
我们修改之前的代码,移除共享变量,改用 Queue,它能够正确管理多个并发线程间的资源分配,无论是生产者还是消费者:
scss
from threading import Thread
from queue import Queue
import time
import random
queue = Queue()
count = 5
class Consumer(Thread):
def __init__(self, count):
Thread.__init__(self)
self.count = count
def run(self):
global queue
for i in range(self.count):
local = queue.get()
print("consumer has used this: %s" % local)
queue.task_done()
class Producer(Thread):
def __init__(self, count):
Thread.__init__(self)
self.count = count
def request(self):
time.sleep(1)
return random.randint(0, 100)
def run(self):
global queue
for i in range(self.count):
local = self.request()
queue.put(local)
print("producer has loaded this: %s" % local)
t1 = Producer(count)
t2 = Producer(count)
t3 = Consumer(count)
t4 = Consumer(count)
t1.start()
t2.start()
t3.start()
t4.start()
t1.join()
t2.join()
t3.join()
t4.join()运行结果示例:
kotlin
producer has loaded this: 31
producer has loaded this: 33
consumer has used this: 31
consumer has used this: 33
producer has loaded this: 11
consumer has used this: 11
producer has loaded this: 2
consumer has used this: 2
producer has loaded this: 27
consumer has used this: 27
producer has loaded this: 68
consumer has used this: 68
producer has loaded this: 92
consumer has used this: 92
producer has loaded this: 19
consumer has used this: 19
producer has loaded this: 87
consumer has used this: 87
producer has loaded this: 91
consumer has used this: 91现在,线程间的行为是正确的,生产者和消费者的操作同步且有序。
总结
本章全面介绍了 threading 模块提供的各种工具。我们学习了如何在程序中以多种方式定义线程------包括调用函数、继承子类以及使用 ThreadPoolExecutor。我们还探讨了不同的线程同步机制及其差异。通过这些内容,我们认识到线程行为的不可预测性,以及竞态条件问题的普遍性和易发性。
下一章,我们将转向真正的并行编程。在 Python 中,真正的并行仅通过多进程实现。届时,我们将介绍标准库中提供的 multiprocessing 模块。