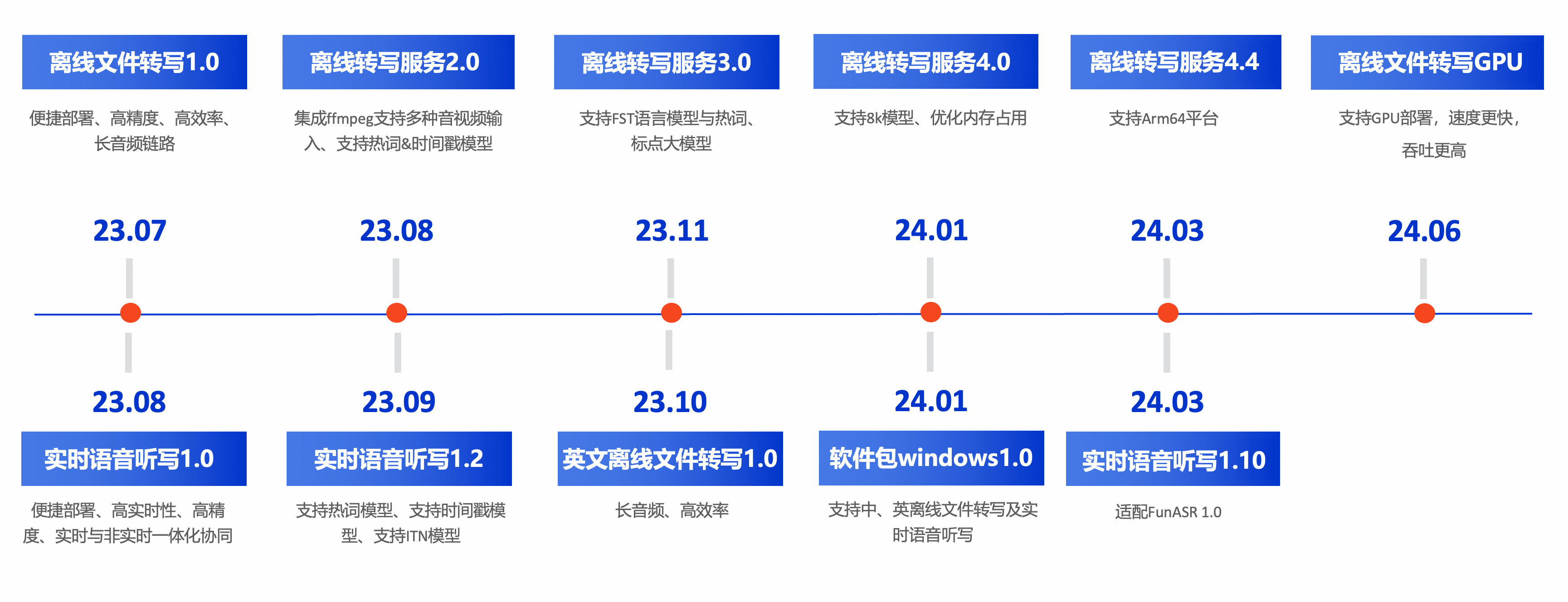
核心功能 :FunASR是一个基础语音识别工具包,提供多种功能,包括语音识别(ASR)、语音端点检测(VAD)、标点恢复、语言模型、说话人验证、说话人分离和多人对话语音识别等。FunASR提供了便捷的脚本和教程,支持预训练好的模型的推理与微调。
项目地址: FunASR
模型仓库: ModelScope
支持以下几种服务部署:
一、FunASR离线文件转写服务GPU版本
FunASR离线文件转写GPU软件包,提供了一款功能强大的语音离线文件转写服务。拥有完整的语音识别链路,结合了语音端点检测、语音识别、标点等模型,可以将几十个小时的长音频与视频识别成带标点的文字,而且支持上百路请求同时进行转写。输出为带标点的文字,含有字级别时间戳,支持ITN与用户自定义热词等。服务端集成有ffmpeg,支持各种音视频格式输入。软件包提供有html、python、c++、java与c#等多种编程语言客户端,支持直接使用与进一步开发。
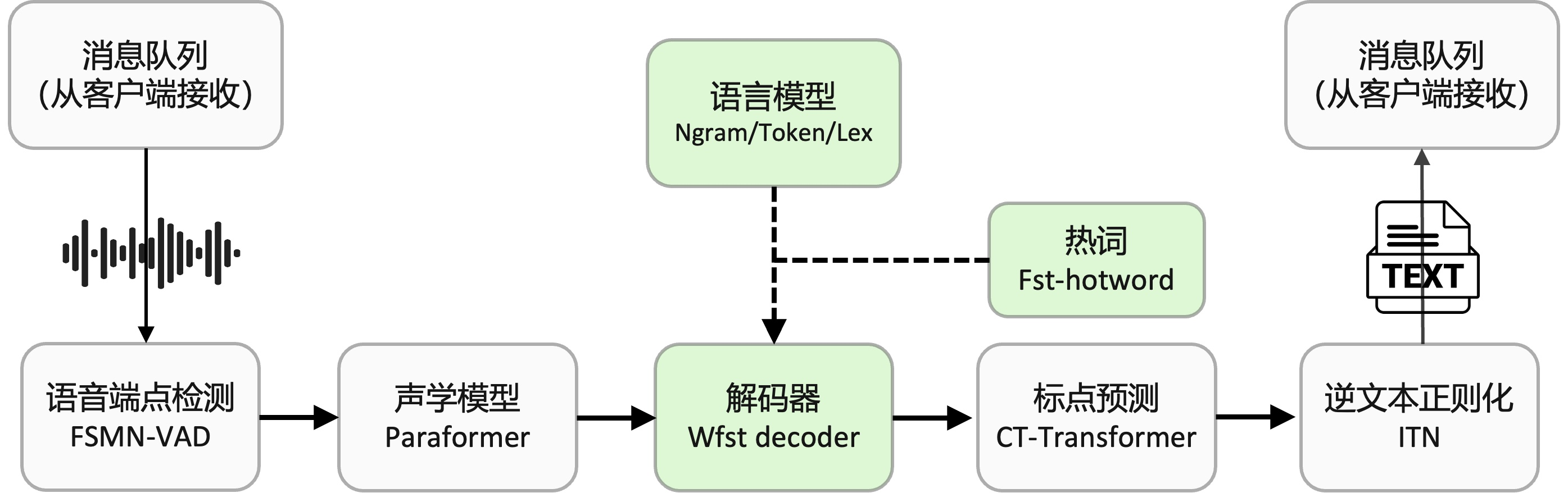
官方推荐配置 :8核vCPU,内存32G,V100,单机可以支持大约20路的请求(详细性能测试报告、云服务试用)
快速使用:
1、docker安装
python
curl -O https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/shell/install_docker.sh;
sudo bash install_docker.sh2、镜像启动
通过下述命令拉取并启动FunASR软件包的docker镜像:
python
sudo docker pull \
registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-gpu-0.2.1
mkdir -p ./funasr-runtime-resources/models
sudo docker run --gpus=all -p 10098:10095 -it --privileged=true \
-v $PWD/funasr-runtime-resources/models:/workspace/models \
registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-gpu-0.2.13、服务端启动
docker启动之后,启动 funasr-wss-server服务程序:
python
cd FunASR/runtime
nohup bash run_server.sh \
--download-model-dir /workspace/models \
--vad-dir damo/speech_fsmn_vad_zh-cn-16k-common-onnx \
--model-dir damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch \
--punc-dir damo/punc_ct-transformer_cn-en-common-vocab471067-large-onnx \
--lm-dir damo/speech_ngram_lm_zh-cn-ai-wesp-fst \
--itn-dir thuduj12/fst_itn_zh \
--hotword /workspace/models/hotwords.txt > log.txt 2>&1 &
***服务首次启动时会导出torchscript模型,耗时较长,请耐心等待***
# 如果您想关闭ssl,增加参数:--certfile 0
# 默认加载时间戳模型,如果您想使用nn热词模型进行部署,请设置--model-dir为对应模型:
# damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch(时间戳)
# damo/speech_paraformer-large-contextual_asr_nat-zh-cn-16k-common-vocab8404(nn热词)
# 如果您想在服务端加载热词,请在宿主机文件./funasr-runtime-resources/models/hotwords.txt配置热词(docker映射地址为/workspace/models/hotwords.txt):
# 每行一个热词,格式(热词 权重):阿里巴巴 20(注:热词理论上无限制,但为了兼顾性能和效果,建议热词长度不超过10,个数不超过1k,权重1~100)可定制ngram(参考文档)
客户端测试与使用
下载客户端测试工具目录samples
python
wget https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/sample/funasr_samples.tar.gz以Python语言客户端为例,进行说明,支持多种音频格式输入(.wav, .pcm, .mp3等),也支持视频输入(.mp4等),以及多文件列表wav.scp输入
python
python3 funasr_wss_client.py --host "127.0.0.1" --port 10095 --mode offline --audio_in "../audio/asr_example.wav"客户端用法详解
在服务器上完成FunASR服务部署以后,可以通过如下的步骤来测试和使用离线文件转写服务。 目前分别支持Python、CPP、HTML、JAVA
python-client
若想直接运行client进行测试,可参考如下简易说明,以python版本为例:
python
python3 funasr_wss_client.py --host "127.0.0.1" --port 10095 --mode offline \
--audio_in "../audio/asr_example.wav" --output_dir "./results"
--host 为FunASR runtime-SDK服务部署机器ip,默认为本机ip(127.0.0.1),如果client与服务不在同一台服务器,需要改为部署机器ip
--port 10095 部署端口号
--mode offline表示离线文件转写
--audio_in 需要进行转写的音频文件,支持文件路径,文件列表wav.scp
--thread_num 设置并发发送线程数,默认为1
--ssl 设置是否开启ssl证书校验,默认1开启,设置为0关闭
--hotword 热词文件,每行一个热词,格式(热词 权重):阿里巴巴 20
--use_itn 设置是否使用itn,默认1开启,设置为0关闭cpp-client
进入samples/cpp目录后,可以用cpp进行测试,指令如下:
python
./funasr-wss-client --server-ip 127.0.0.1 --port 10095 --wav-path ../audio/asr_example.wav
--server-ip 为FunASR runtime-SDK服务部署机器ip,默认为本机ip(127.0.0.1),如果client与服务不在同一台服务器,需要改为部署机器ip
--port 10095 部署端口号
--wav-path 需要进行转写的音频文件,支持文件路径
--hotword 热词文件,每行一个热词,格式(热词 权重):阿里巴巴 20
--thread-num 设置客户端线程数
--use-itn 设置是否使用itn,默认1开启,设置为0关闭Html网页版
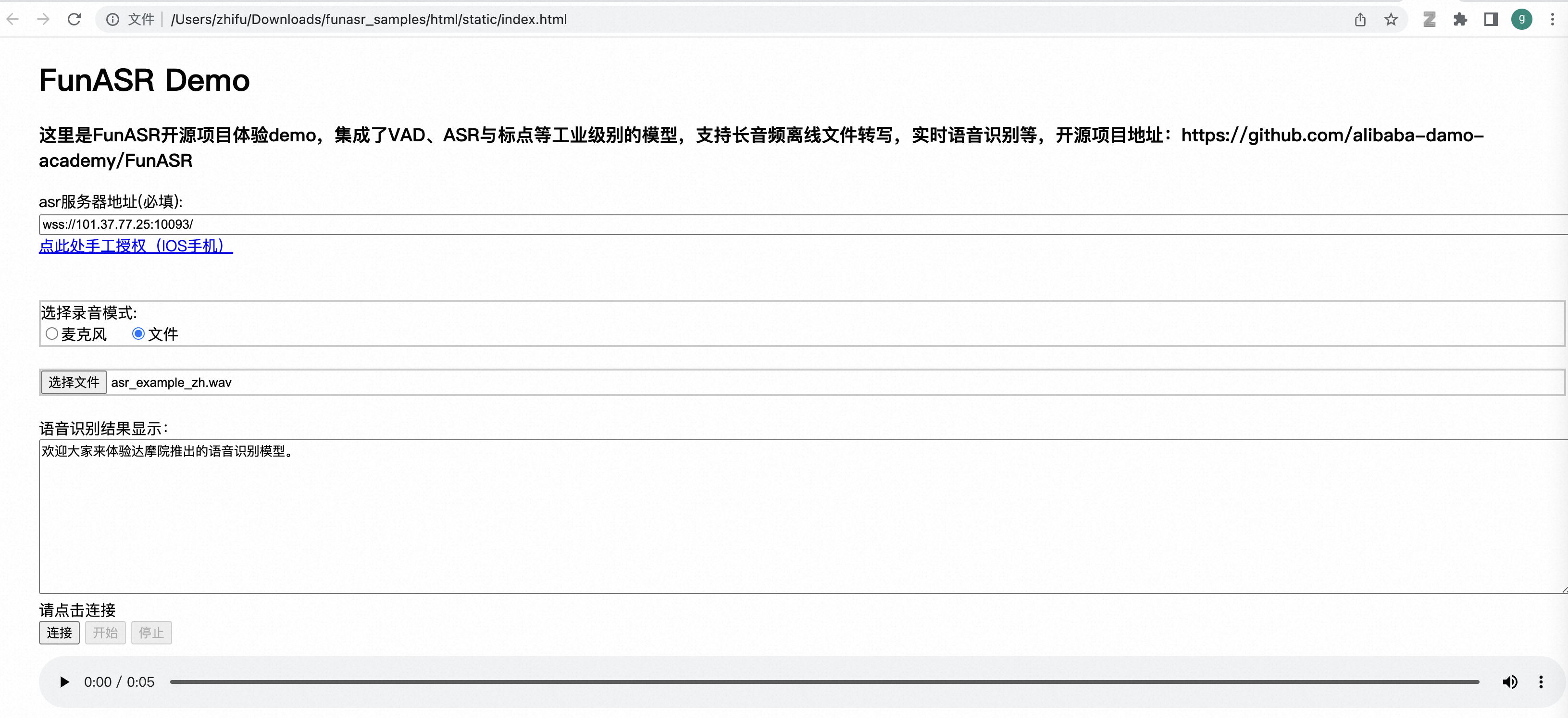
在浏览器中打开 html/static/index.html,即可出现如下页面,支持麦克风输入与文件上传,直接进行体验
Java-client
python
FunasrWsClient --host localhost --port 10095 --audio_in ./asr_example.wav --mode offline服务端用法详解:
启动FunASR服务
python
cd /workspace/FunASR/runtime
nohup bash run_server.sh \
--download-model-dir /workspace/models \
--model-dir damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch \
--vad-dir damo/speech_fsmn_vad_zh-cn-16k-common-onnx \
--punc-dir damo/punc_ct-transformer_cn-en-common-vocab471067-large-onnx \
--lm-dir damo/speech_ngram_lm_zh-cn-ai-wesp-fst \
--itn-dir thuduj12/fst_itn_zh \
--certfile ../../../ssl_key/server.crt \
--keyfile ../../../ssl_key/server.key \
--hotword ../../hotwords.txt > log.txt 2>&1 &run_server.sh命令参数介绍
python
--download-model-dir 模型下载地址,通过设置model ID从Modelscope下载模型
--model-dir modelscope model ID 或者 本地模型路径
--vad-dir modelscope model ID 或者 本地模型路径
--punc-dir modelscope model ID 或者 本地模型路径
--lm-dir modelscope model ID 或者 本地模型路径
--itn-dir modelscope model ID 或者 本地模型路径
--port 服务端监听的端口号,默认为 10095
--decoder-thread-num 服务端线程池个数(支持的最大并发路数),
**建议每路分配1G显存,即20G显存可配置20路并发**
--io-thread-num 服务端启动的IO线程数
--model-thread-num 每路识别的内部线程数(控制ONNX模型的并行),默认为 1,其中建议 decoder-thread-num*model-thread-num 等于总线程数
--certfile ssl的证书文件,默认为:../../../ssl_key/server.crt,如果需要关闭ssl,参数设置为0
--keyfile ssl的密钥文件,默认为:../../../ssl_key/server.key
--hotword 热词文件路径,每行一个热词,格式:热词 权重(例如:阿里巴巴 20),如果客户端提供热词,则与客户端提供的热词合并一起使用,服务端热词全局生效,客户端热词只针对对应客户端生效。关闭FunASR服务
python
# 查看 funasr-wss-server 对应的PID
ps -x | grep funasr-wss-server
kill -9 PID修改模型及其他参数
替换正在使用的模型或者其他参数,需先关闭FunASR服务,修改需要替换的参数,并重新启动FunASR服务。其中模型需为ModelScope中的ASR/VAD/PUNC模型,或者从ModelScope中模型finetune后的模型。
python
# 例如替换ASR模型为 damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch,则如下设置参数 --model-dir
--model-dir damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch
# 设置端口号 --port
--port <port number>
# 设置服务端启动的推理线程数 --decoder-thread-num
--decoder-thread-num <decoder thread num>
# 设置服务端启动的IO线程数 --io-thread-num
--io-thread-num <io thread num>
# 关闭SSL证书
--certfile 0执行上述指令后,启动离线文件转写服务。如果模型指定为ModelScope中model id,会自动从MoldeScope中下载模型
二、英文离线文件转写服务(CPU版本)
英文离线文件转写服务部署(CPU版本),拥有完整的语音识别链路,可以将几十个小时的长音频与视频识别成带标点的文字,而且支持上百路请求同时进行转写。
FunASR提供可一键本地或者云端服务器部署的英文离线文件转写服务,内核为FunASR已开源runtime-SDK。FunASR-runtime结合了达摩院语音实验室在Modelscope社区开源的语音端点检测(VAD)、Paraformer-large语音识别(ASR)、标点检测(PUNC) 等相关能力,可以准确、高效的对音频进行高并发转写。
服务器配置
官方推荐配置:
python
· 配置1: (X86,计算型),4核vCPU,内存8G,单机可以支持大约32路的请求
· 配置2: (X86,计算型),16核vCPU,内存32G,单机可以支持大约64路的请求
· 配置3: (X86,计算型),64核vCPU,内存128G,单机可以支持大约200路的请求1、docker安装
python
curl -O https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/shell/install_docker.sh;
sudo bash install_docker.sh2、镜像启动
python
sudo docker pull \
registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-en-cpu-0.1.8
mkdir -p ./funasr-runtime-resources/models
sudo docker run -p 10097:10095 -it --privileged=true \
-v $PWD/funasr-runtime-resources/models:/workspace/models \
registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-en-cpu-0.1.83、服务端启动
python
cd FunASR/runtime
nohup bash run_server.sh \
--download-model-dir /workspace/models \
--vad-dir damo/speech_fsmn_vad_zh-cn-16k-common-onnx \
--model-dir damo/speech_paraformer-large_asr_nat-en-16k-common-vocab10020-onnx \
--punc-dir damo/punc_ct-transformer_cn-en-common-vocab471067-large-onnx > log.txt 2>&1 &
# 如果您想关闭ssl,增加参数:--certfile 04、客户端测试与使用
python
wget https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/sample/funasr_samples.tar.gz
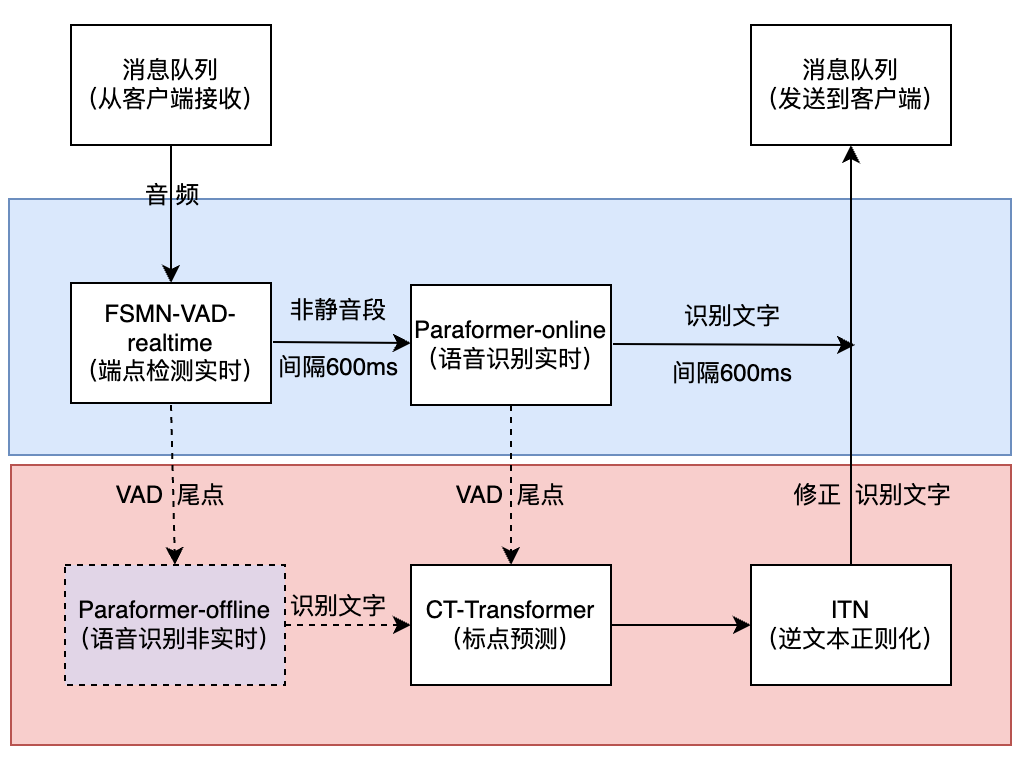
python3 funasr_wss_client.py --host "127.0.0.1" --port 10097 --mode offline --audio_in "../audio/asr_example.wav"三、中文实时语音听写服务(CPU版本)
1、docker安装
python
curl -O https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/shell/install_docker.sh
sudo bash install_docker.sh2、镜像启动
python
sudo docker pull \
registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-online-cpu-0.1.13
mkdir -p ./funasr-runtime-resources/models
sudo docker run -p 10096:10095 -it --privileged=true \
-v $PWD/funasr-runtime-resources/models:/workspace/models \
registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-online-cpu-0.1.133、服务端启动
python
cd FunASR/runtime
nohup bash run_server_2pass.sh \
--download-model-dir /workspace/models \
--vad-dir damo/speech_fsmn_vad_zh-cn-16k-common-onnx \
--model-dir damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-onnx \
--online-model-dir damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-online-onnx \
--punc-dir damo/punc_ct-transformer_zh-cn-common-vad_realtime-vocab272727-onnx \
--lm-dir damo/speech_ngram_lm_zh-cn-ai-wesp-fst \
--itn-dir thuduj12/fst_itn_zh \
--hotword /workspace/models/hotwords.txt > log.txt 2>&1 &
# 如果您想关闭ssl,增加参数:--certfile 0
# 如果您想使用SenseVoiceSmall模型、时间戳、nn热词模型进行部署,请设置--model-dir为对应模型:
# iic/SenseVoiceSmall-onnx
# damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-onnx(时间戳)
# damo/speech_paraformer-large-contextual_asr_nat-zh-cn-16k-common-vocab8404-onnx(nn热词)
# 如果您想在服务端加载热词,请在宿主机文件./funasr-runtime-resources/models/hotwords.txt配置热词(docker映射地址为/workspace/models/hotwords.txt):
# 每行一个热词,格式(热词 权重):阿里巴巴 20(注:热词理论上无限制,但为了兼顾性能和效果,建议热词长度不超过10,个数不超过1k,权重1~100)
# SenseVoiceSmall-onnx识别结果中"<|zh|><|NEUTRAL|><|Speech|> "分别为对应的语种、情感、事件信息4、客户端测试与使用
python
wget https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/sample/funasr_samples.tar.gz
python3 funasr_wss_client.py --host "127.0.0.1" --port 10096 --mode 2pass除了之前的四种语言,还支持c#
四、中文离线文件转写服务(CPU版本)
官方推荐配置:
python
·配置1: (X86,计算型),4核vCPU,内存8G,单机可以支持大约32路的请求
·配置2: (X86,计算型),16核vCPU,内存32G,单机可以支持大约64路的请求
·配置3: (X86,计算型),64核vCPU,内存128G,单机可以支持大约200路的请求1、docker安装
python
curl -O https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/shell/install_docker.sh;
sudo bash install_docker.sh2、镜像启动
python
sudo docker pull \
registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-cpu-0.4.7
mkdir -p ./funasr-runtime-resources/models
sudo docker run -p 10095:10095 -it --privileged=true \
-v $PWD/funasr-runtime-resources/models:/workspace/models \
registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-cpu-0.4.73、服务端启动
python
cd FunASR/runtime
nohup bash run_server.sh \
--download-model-dir /workspace/models \
--vad-dir damo/speech_fsmn_vad_zh-cn-16k-common-onnx \
--model-dir damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-onnx \
--punc-dir damo/punc_ct-transformer_cn-en-common-vocab471067-large-onnx \
--lm-dir damo/speech_ngram_lm_zh-cn-ai-wesp-fst \
--itn-dir thuduj12/fst_itn_zh \
--hotword /workspace/models/hotwords.txt > log.txt 2>&1 &
# 如果您想关闭ssl,增加参数:--certfile 0
# 如果您想使用SenseVoiceSmall模型、时间戳、nn热词模型进行部署,请设置--model-dir为对应模型:
# iic/SenseVoiceSmall-onnx
# damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-onnx(时间戳)
# damo/speech_paraformer-large-contextual_asr_nat-zh-cn-16k-common-vocab8404-onnx(nn热词)
# 如果您想在服务端加载热词,请在宿主机文件./funasr-runtime-resources/models/hotwords.txt配置热词(docker映射地址为/workspace/models/hotwords.txt):
# 每行一个热词,格式(热词 权重):阿里巴巴 20(注:热词理论上无限制,但为了兼顾性能和效果,建议热词长度不超过10,个数不超过1k,权重1~100)
# SenseVoiceSmall-onnx识别结果中"<|zh|><|NEUTRAL|><|Speech|> "分别为对应的语种、情感、事件信息部署8k模型:
python
cd FunASR/runtime
nohup bash run_server.sh \
--download-model-dir /workspace/models \
--vad-dir damo/speech_fsmn_vad_zh-cn-8k-common-onnx \
--model-dir damo/speech_paraformer_asr_nat-zh-cn-8k-common-vocab8358-tensorflow1-onnx \
--punc-dir damo/punc_ct-transformer_cn-en-common-vocab471067-large-onnx \
--lm-dir damo/speech_ngram_lm_zh-cn-ai-wesp-fst-token8358 \
--itn-dir thuduj12/fst_itn_zh \
--hotword /workspace/models/hotwords.txt > log.txt 2>&1 &4、客户端测试与使用
python
wget https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/sample/funasr_samples.tar.gz
python3 funasr_wss_client.py --host "127.0.0.1" --port 10095 --mode offline --audio_in "../audio/asr_example.wav"如何定制服务部署
FunASR-runtime的代码已开源,如果服务端和客户端不能很好的满足您的需求,您可以根据自己的需求进行进一步的开发:
c++ 客户端
python 客户端
自定义客户端
安装教程
·安装funasr之前,确保已经安装了下面依赖环境:
python
python>=3.8
torch>=1.13
torchaudio·pip安装
python
pip3 install -U funasr·或者从源代码安装
python
git clone https://github.com/alibaba/FunASR.git && cd FunASR
pip3 install -e ./如果需要使用工业预训练模型,安装modelscope与huggingface_hub(可选)
python
pip3 install -U modelscope huggingface huggingface_hub快速开始
可执行命令行
python
funasr ++model=paraformer-zh ++vad_model="fsmn-vad" ++punc_model="ct-punc" ++input=asr_example_zh.wav注:支持单条音频文件识别,也支持文件列表,列表为kaldi风格wav.scp:wav_id wav_path
非实时语音识别
python
SenseVoice
from funasr import AutoModel
from funasr.utils.postprocess_utils import rich_transcription_postprocess
model_dir = "iic/SenseVoiceSmall"
model = AutoModel(
model=model_dir,
vad_model="fsmn-vad",
vad_kwargs={"max_single_segment_time": 30000},
device="cuda:0",
)
# en
res = model.generate(
input=f"{model.model_path}/example/en.mp3",
cache={},
language="auto", # "zn", "en", "yue", "ja", "ko", "nospeech"
use_itn=True,
batch_size_s=60,
merge_vad=True, #
merge_length_s=15,
)
text = rich_transcription_postprocess(res[0]["text"])
print(text)参数说明:
python
·model_dir:模型名称,或本地磁盘中的模型路径。
·vad_model:表示开启VAD,VAD的作用是将长音频切割成短音频,此时推理耗时包括了VAD与SenseVoice总耗时,为链路耗时,如果需要单独测试SenseVoice模型耗时,可以关闭VAD模型。
·vad_kwargs:表示VAD模型配置,max_single_segment_time: 表示·vad_model最大切割音频时长, 单位是毫秒ms。
·use_itn:输出结果中是否包含标点与逆文本正则化。
·batch_size_s 表示采用动态batch,batch中总音频时长,单位为秒s。
·merge_vad:是否将 vad 模型切割的短音频碎片合成,合并后长度为·merge_length_s,单位为秒s。
·ban_emo_unk:禁用emo_unk标签,禁用后所有的句子都会被赋与情感标签。
python
Paraformer
from funasr import AutoModel
# paraformer-zh is a multi-functional asr model
# use vad, punc, spk or not as you need
model = AutoModel(model="paraformer-zh", vad_model="fsmn-vad", punc_model="ct-punc",
# spk_model="cam++"
)
res = model.generate(input=f"{model.model_path}/example/asr_example.wav",
batch_size_s=300,
hotword='魔搭')
print(res)注:hub:表示模型仓库,ms为选择modelscope下载,hf为选择huggingface下载。
实时语音识别
python
from funasr import AutoModel
chunk_size = [0, 10, 5] #[0, 10, 5] 600ms, [0, 8, 4] 480ms
encoder_chunk_look_back = 4 #number of chunks to lookback for encoder self-attention
decoder_chunk_look_back = 1 #number of encoder chunks to lookback for decoder cross-attention
model = AutoModel(model="paraformer-zh-streaming")
import soundfile
import os
wav_file = os.path.join(model.model_path, "example/asr_example.wav")
speech, sample_rate = soundfile.read(wav_file)
chunk_stride = chunk_size[1] * 960 # 600ms
cache = {}
total_chunk_num = int(len((speech)-1)/chunk_stride+1)
for i in range(total_chunk_num):
speech_chunk = speech[i*chunk_stride:(i+1)*chunk_stride]
is_final = i == total_chunk_num - 1
res = model.generate(input=speech_chunk, cache=cache, is_final=is_final, chunk_size=chunk_size, encoder_chunk_look_back=encoder_chunk_look_back, decoder_chunk_look_back=decoder_chunk_look_back)
print(res)注:chunk_size为流式延时配置,[0,10,5]表示上屏实时出字粒度为10*60=600ms,未来信息为5*60=300ms。每次推理输入为600ms(采样点数为16000*0.6=960),输出为对应文字,最后一个语音片段输入需要设置is_final=True来强制输出最后一个字。
语音端点检测(非实时)
python
from funasr import AutoModel
model = AutoModel(model="fsmn-vad")
wav_file = f"{model.model_path}/example/vad_example.wav"
res = model.generate(input=wav_file)
print(res)注:VAD模型输出格式为:[[beg1, end1], [beg2, end2], .., [begN, endN]],其中begN/endN表示第N个有效音频片段的起始点/结束点, 单位为毫秒。
语音端点检测(实时)
python
from funasr import AutoModel
chunk_size = 200 # ms
model = AutoModel(model="fsmn-vad")
import soundfile
wav_file = f"{model.model_path}/example/vad_example.wav"
speech, sample_rate = soundfile.read(wav_file)
chunk_stride = int(chunk_size * sample_rate / 1000)
cache = {}
total_chunk_num = int(len((speech)-1)/chunk_stride+1)
for i in range(total_chunk_num):
speech_chunk = speech[i*chunk_stride:(i+1)*chunk_stride]
is_final = i == total_chunk_num - 1
res = model.generate(input=speech_chunk, cache=cache, is_final=is_final, chunk_size=chunk_size)
if len(res[0]["value"]):
print(res)注:流式VAD模型输出格式为4种情况:
[[beg1, end1], [beg2, end2], .., [begN, endN]]:同上离线VAD输出结果。
[[beg, -1]]:表示只检测到起始点。
[[-1, end]]:表示只检测到结束点。
[]:表示既没有检测到起始点,也没有检测到结束点 输出结果单位为毫秒,从起始点开始的绝对时间。
标点恢复
python
from funasr import AutoModel
model = AutoModel(model="ct-punc")
res = model.generate(input="那今天的会就到这里吧 happy new year 明年见")
print(res)时间戳预测
python
from funasr import AutoModel
model = AutoModel(model="fa-zh")
wav_file = f"{model.model_path}/example/asr_example.wav"
text_file = f"{model.model_path}/example/text.txt"
res = model.generate(input=(wav_file, text_file), data_type=("sound", "text"))
print(res)情感识别
python
from funasr import AutoModel
model = AutoModel(model="emotion2vec_plus_large")
wav_file = f"{model.model_path}/example/test.wav"
res = model.generate(wav_file, output_dir="./outputs", granularity="utterance", extract_embedding=False)
print(res)注:
1、支持Whisper-large-v3、Whisper-large-v3-turbo模型,多语言语音识别/翻译/语种识别
2、Qwen-Audio与Qwen-Audio-Chat音频文本模态大模型
python
#!/usr/bin/env python3
# -*- encoding: utf-8 -*-
# Copyright FunASR (https://github.com/alibaba-damo-academy/FunASR). All Rights Reserved.
# MIT License (https://opensource.org/licenses/MIT)
# To install requirements: pip3 install -U "funasr[llm]"
from funasr import AutoModel
model = AutoModel(model="Qwen/Qwen-Audio-Chat")
audio_in = "https://github.com/QwenLM/Qwen-Audio/raw/main/assets/audio/1272-128104-0000.flac"
# 1st dialogue turn
prompt = "what does the person say?"
cache = {"history": None}
res = model.generate(input=audio_in, prompt=prompt, cache=cache)
print(res)
# 2nd dialogue turn
prompt = 'Find the start time and end time of the word "middle classes"'
res = model.generate(input=None, prompt=prompt, cache=cache)
print(res)3、情感识别模型(生气/angry,开心/happy,中立/neutral,难过/sad)
emotion2vec+large,emotion2vec+base,emotion2vec+seed
4、SenseVoice 是一个基础语音理解模型,具备多种语音理解能力,涵盖了自动语音识别(ASR)、语言识别(LID)、情感识别(SER)以及音频事件检测(AED)
5、语音唤醒模型
fsmn_kws, fsmn_kws_mt, sanm_kws, sanm_kws_streaming
python
from funasr import AutoModel
# paraformer-zh is a multi-functional asr model
# use vad, punc, spk or not as you need
model = AutoModel(model="iic/speech_sanm_kws_phone-xiaoyun-commands-online",
keywords="小云小云",
output_dir="./outputs/debug",
device='cpu',
chunk_size=[4, 8, 4],
encoder_chunk_look_back=0,
decoder_chunk_look_back=0,
)
res = model.generate(input='https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/KWS/pos_testset/kws_xiaoyunxiaoyun.wav')
print(res)6、模型列表