| 版本号 | 日期 | 说明 |
|---|---|---|
| 1.0 | 2022-03-11 | 第一版 |
| 2.0 | 2024-01-04 | ELK 上云后部分更新 |
| 2.1 | 2025-02-12 | ELK 访问地址更新 |
序言
公司IT业务在快速发展过程中,业务系统的复杂度和访问逐年上升,日志量也在不断增长。截止至2021年底,核心业务线各应用组件每天可产生50TB以上的海量日志。
为了处理如此大量的日志,运维团队搭建了公司日志中心平台。该平台基于业界流行的Elasticsearch + Logstash + Kibana(ELK)文本采集和搜索引擎解决方案,为线上业务的日常维护及排障提供日志收集、搜索、分析等支持。
为方便开发及运维人员快速入门公司ELK平台的使用,更好地发挥该平台的能力,特撰写此文,供使用者参考。
从2023年12月底开始,2站ELK的日志保留时间均为3天。
一、登录和主界面介绍
1、登录地址
公司日志中心为三站部署(金山、腾讯、万国)。其中金山ELK负责收录金山机房及华为云业务日志,腾讯、万国ELK分别负责各自所属站点的业务日志。
每个站点提供两个登录入口,用户可任意选择其中一个登录。每个站点仅可查询到当前站点的日志信息,目前暂无法进行跨站查询。
| 站点 | 地址 | 逻辑单元 |
|---|---|---|
| YUMC3 ELK | 上云后使用域名访问(AD账号访问):~~ks-logcenter-kibana.hwwt2.com:5601~~yumc3-logcenter-kibana.hwwt2.com:5601 | yumc0yumc1yumc3 |
| YUMC4 ELK | 上云后使用域名访问(AD账号访问):yumc4-logcenter-kibana.hwwt2.com:5601 | yumc2yumc4 |
2、账号申请(上云后,直接使用AD账号)
公司日志中心通过本地账号认证登录,账号信息与公司的其他系统账号或员工域账号不通用。
如需申请新账号或遗忘密码需要重置,可以在Jira中提交NDRP项目的工单。如有疑问,请联系运维的DBA团队。
Jira 申请单 模板 :
【标题】(KS/WG/QC)ELK账号申请/ELK账号密码重置
【正文】
使用者邮箱地址(域账号) / topic名 / 角色(开发 | 运维)
样 例:
css
【ELK账号申请】
james.bond@yumchina.com(jams0101) / ec-kfc-preorder-server / 开发3、日志中心(ELK)名称术语介绍
| 名词 | 解释 |
|---|---|
| Elasticsearch / ES | ELK的核心服务组件,用于存储、索引日志数据,并提供查询接口 |
| Kibana | 一个开源的分析与可视化平台,作为Elasticsearch的前端UI提供查询、调试、配置管理等功能,方便用户、开发和管理员日常操作 |
| filebeat | 日志收集程序,负责读取本地日志文件并解析上传至平台中。通常部署在应用服务器上。如果应用是容器部署,则filebeat作为容器sidecar |
| topic | 一组关联日志的名称。通常一个应用或是一条业务线的所有日志,会根据组件类型进行分类,之后统一收集到一个或数个topic中。Topic的名称通常反映具体的业务,如:ec-kfc-preorder-server这一topic用于收集EC KFC PreOrder业务线的所有Java应用程序(server)日志 |
| document | ES中存储的一条数据,存储形式为一个JSON结构体。应用服务器上的每一行日志,收录到ELK中都会形成一条document。类似于关系型数据库中的一行数据 |
| field | document中的一个字段。根据存储的数据内容,每个field都有一个固定的字段类型,常见的有:text/keyword(文本)、long/float(数字)、date(日期)、boolean(布尔)等 |
| index | 同一类documents组成的集合。在日志中心ELK中,一个topic对应了一组index。比如ec-kfc-preorder-server这一topic,每天的日志会归集产生ec-kfc-preorder-server-2022.01.01这样的多个index。一个index类似于关系型数据库中的一张表 |
| mapping | ES是一个非结构化的数据库,或者说是一个无模式的数据库,因此需要指定field和index的mapping关系,来维护index的结构mapping可以类比于关系型数据库中的表结构定义 |
| 分词 | ES作为一个文本检索引擎,可以对输入的文本内容,经过一些预设的分词规则进行解析,并把全文本转换成一系列单词(term/token)。这一过程被称为分词这些单词会作为索引的一部分收录在ES中,之后可作为关键词进行搜索和统计 |
4、登录首页
首先确定需要查询日志的应用当前部署的IDC站点。根据前文提供的登陆地址,输入账号和密码,登录对应站点环境的kibana。
登录后的首页如下:
5、操作入门
按照上一步截图里描述,进入 discover 页面,也就是日志排障过程中最常用到的查询界面。接下来我们通过一些常用操作,分块介绍每个页面组件的功能
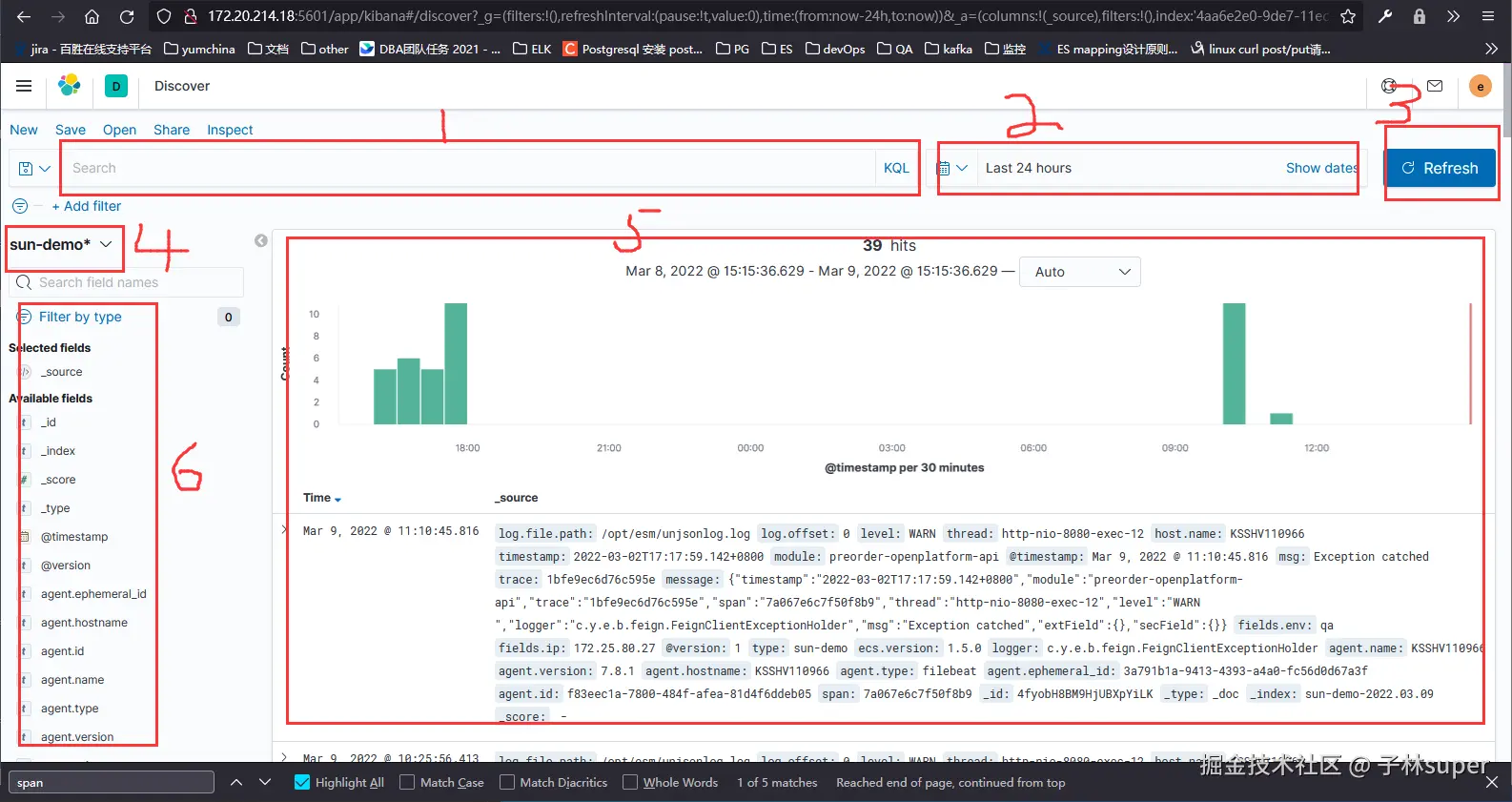
我们进行一次简单的演示操作。具体步骤如下:
第一步:选择index pattern(topic)
根据日志所属的topic,在index pattern下拉框(标记4)中选择需要查看的index。比如:要查看EC PreOrder的调用日志,可以选择ec-kfc-preorder-monitor``-*这个pattern。这个pattern会匹配所有ec-kfc-preorder-monitor作为前缀的index,并合并成一个视图。
选择topic后,可以先点击查询/刷新按钮(标记3),Kibana默认会展示该topic下最新的日志内容。可以了解到该应用输出日志的大体格式、内容、字段,方便后续进一步搜索过滤。
第二步:输入查询条件
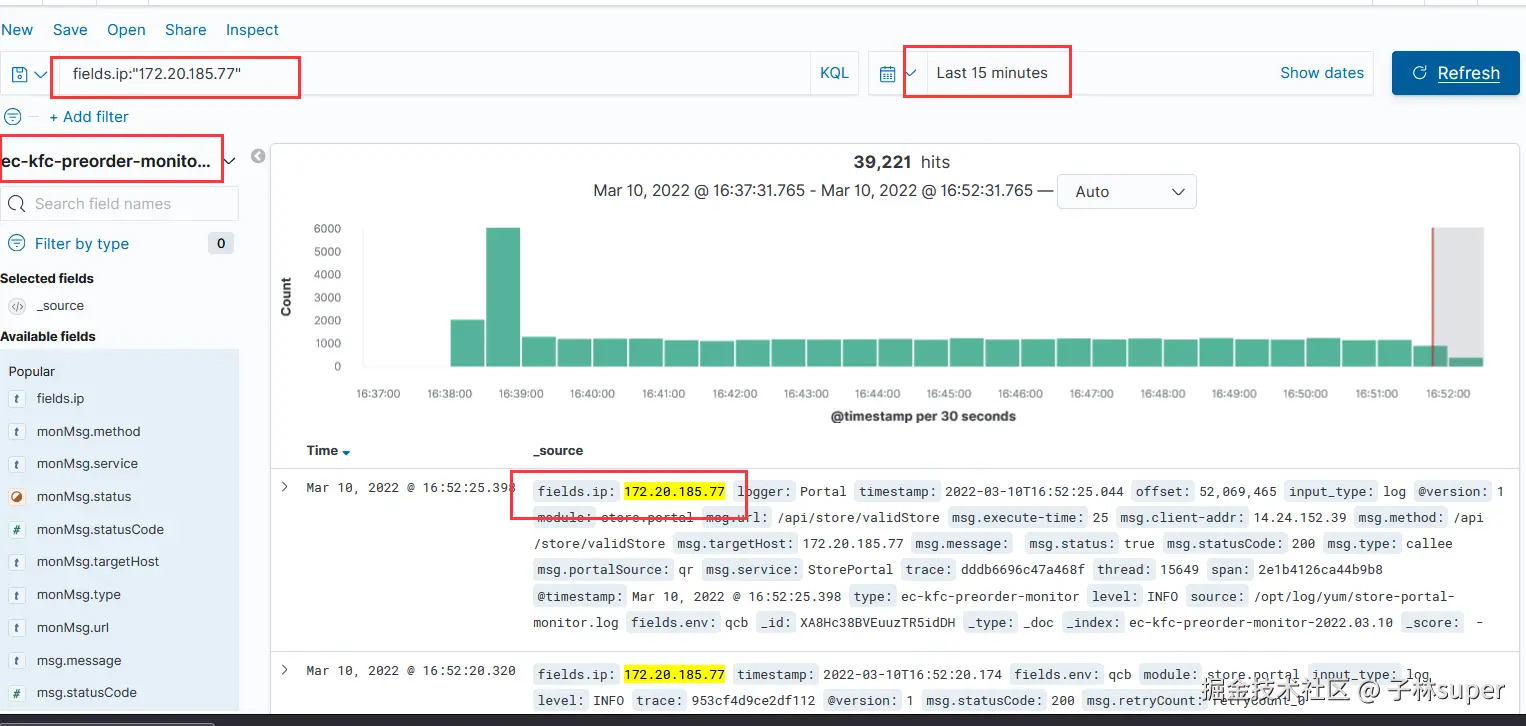
有时候我们需要通过特定的搜索条件来对日志进行过滤,比如按照业务的trace号、应用报错的关键字等进行搜索。此时我们可以在搜索框(标记1)处输入一些查询条件。比如:我们想查询IP为172.20.185.77的应用服务生成的日志信息。可以在输入框中输入:
fields.ip:"172.20.185.77"
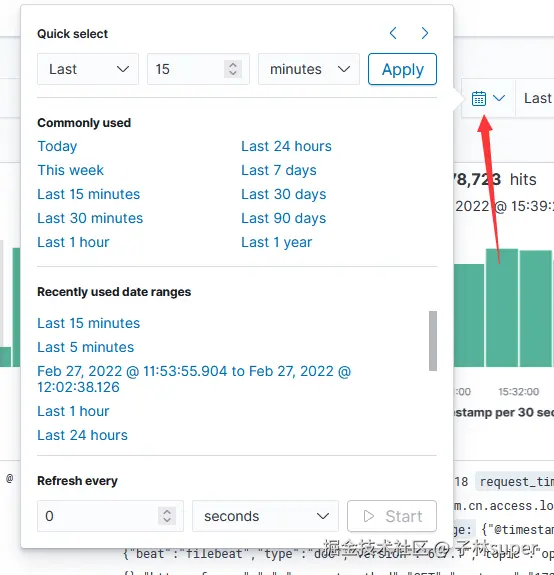
第三步:筛选时间
数字2 标记的是时间过滤器,过滤器中点击后如下所示,会有多时间范围可供选择,我们选择最近15分钟。
第四步:点击查询
点击搜索按钮(数字3标记)。
第五步:查看日志详情
在日志详情区域(标记5)中查看日志明细。包括日志正文和时间分布。如图所示,ELK近15分钟内收录的,IP为172.20.185.77的应用主机,产生的ec-kfc-preorder-monitor日志有 39221 条。图中绿色柱状图显示了,每一小段时间内,日志的生成速率:
第六步:日志过滤
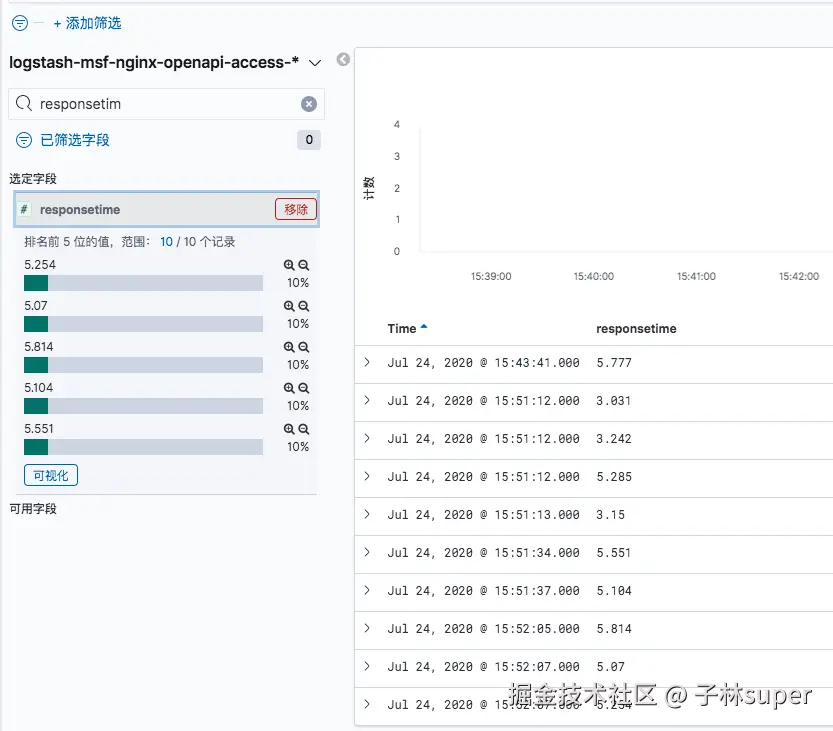
在左侧栏中(标记6)还可以对字段进行进一步筛选,例如在下面的搜索结果中,选择responsetime字段,可以详细看到字段的具体值,并且倒序排序。如果选定了字段后,在右侧就优先展示该字段的内容
6、查询语法概述
Kibana中支持两种查询语法,Lucene与KQL。可以通过搜索栏(标记1)右端的 KQL/Lucene 按钮进行切换。两种语法的简单介绍如下:
Lucene是ES的底层存储引擎,它的查询语法以接近日常口语的方式书写。
KQL(Kibana Query Language),也就是在Kibana上面进行查询时使用的语法,基于Lucene查询语法。 在Kibana中进行查询的时候,建议使用指定索引查询,这样的效率更高,而不建议使用全局查找的方式。
KQL相比较Lucene使用更容易入手, Lucene 学习成本相对比较高。本文所有的查询语法都是基于KQL。如需具体了解Lucene,请参考对应的官方文档,文档链接见"参考文献"。
分词器在查询的时候影响不小,因此在查询日志的时候必定绕不开这个。简单来说,分词器就是将一个大的文本内容拆分多个小的文本内容,让查询的粒度变得更小。例如:关键词"百胜中国",没有分词器的情况只能输入"百胜中国"才能出结果;使用分词器后,可以通过"百胜中国"、"百胜"、"中国"、"百"、"胜"、"中"、"国"等和关键词有关的文档数据进行查询。
自从ElasticSearch5.x版本开始,字符串(string)被分为了两种类型,分别是text和keyword:
- text:用于全文索引,该类型的字段将通过分词器进行分词,最终用于构建索引。
- keyword:不分词,只能搜索该字段的完整的值。
对于结构化日志中的字段,固定短语(如日志等级、接口地址、程序模块名)、标识串(如trace id、session id、用户手机号)等,一般使用keyword格式;长文本(如报错明细、订单详情、客户地址),一般使用text格式。
由于前端日志格式灵活多变,ELK在收录时默认会将message和msg字段以text格式收录,其他字段则默认全部以keyword格式收录。DBA会定期检查已收录的日志信息,如发现字段内容较长、适宜做分词,会修改该字段为text。此外,如果用户发现搜索结果不理想,也可以联系DBA协助对字段格式进行优化。
二、常用搜索语法
KQL是Kibana默认的查询方式,这里着重介绍KQL的查询。 KQL匹配时是不区分大小写,可以使用括号改变匹配优先级。
1、全字匹配
查询的时候选择 KQL,用key:value的形式进行查询。
例如使用 trace字段(keyword数据类型),不具备分词功能,trace值为系统中生成的交易ID,根据此值可以找到需要的交易单。
trace:"54c090a5f3b13aa3"
例子:查询 trace 为"54c090a5f3b13aa3"。注意双引号里不能有空格!
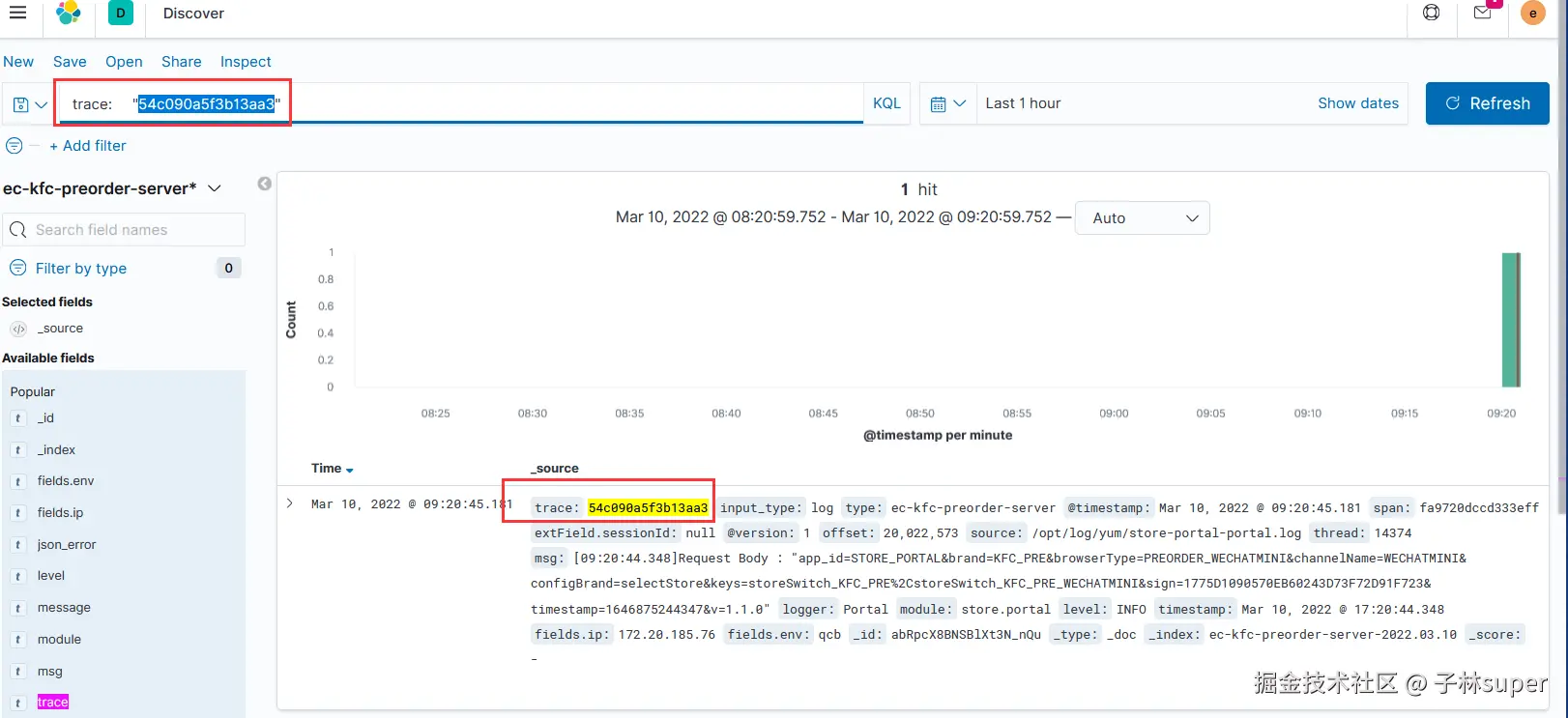
注意:keyword格式的字段如果其中的数据超过256个字符,检索将会失败,查询匹配不到结果。
2、模糊匹配
2.1 通配符匹配查询
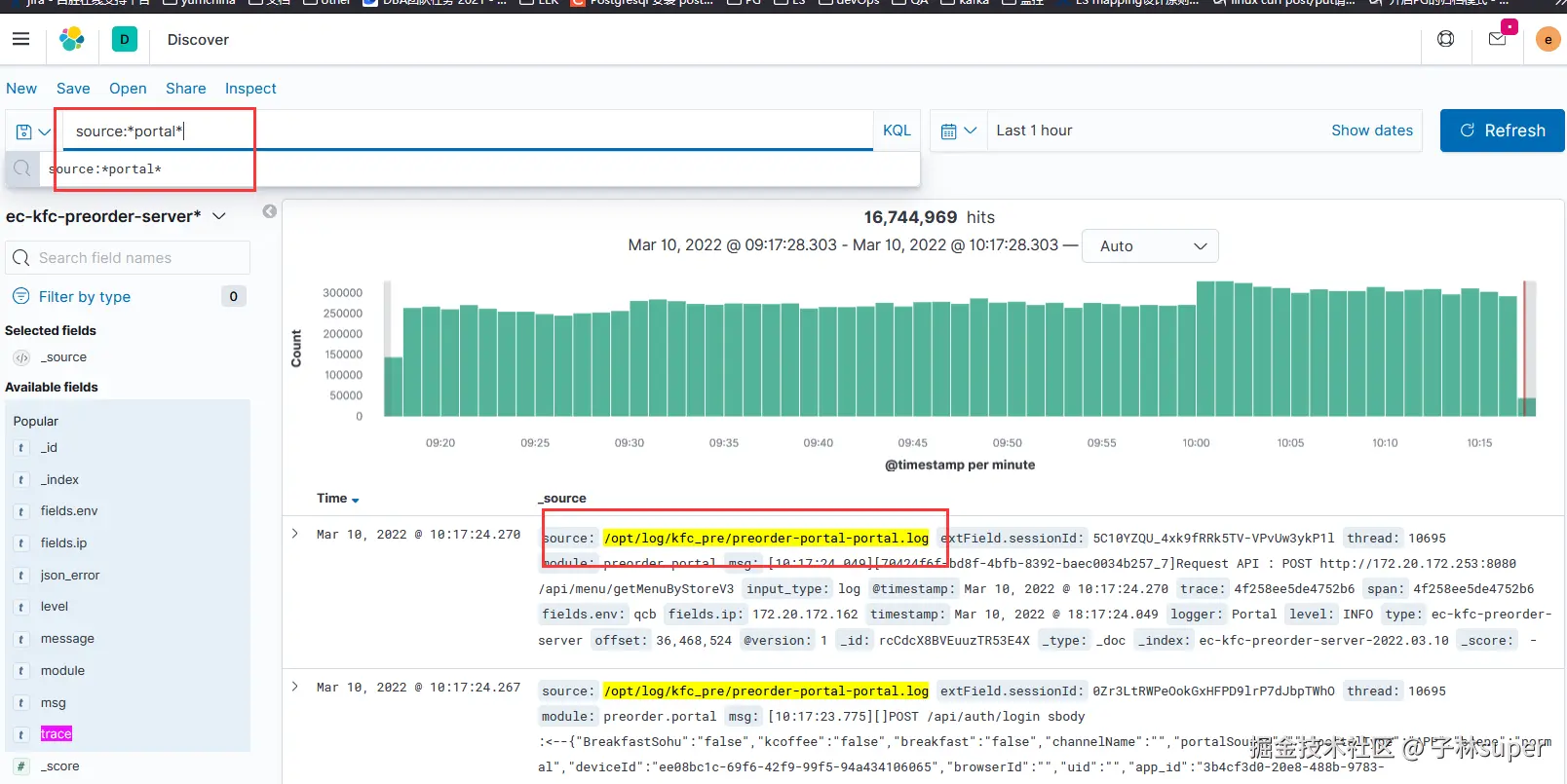
source为keyword类型数据,不具备分词功能。查询此类不具备分词器的字段时,需要注意使用*号,以及去掉双引号,查询的关键词之间不能有空格。
source:*portal*
以上表达式,查询符号 * ,用于统配查询,以上的表达式查出的是source字段找中包含 portal的数据。结果如下:
2.2 带有分词功能字段的检索
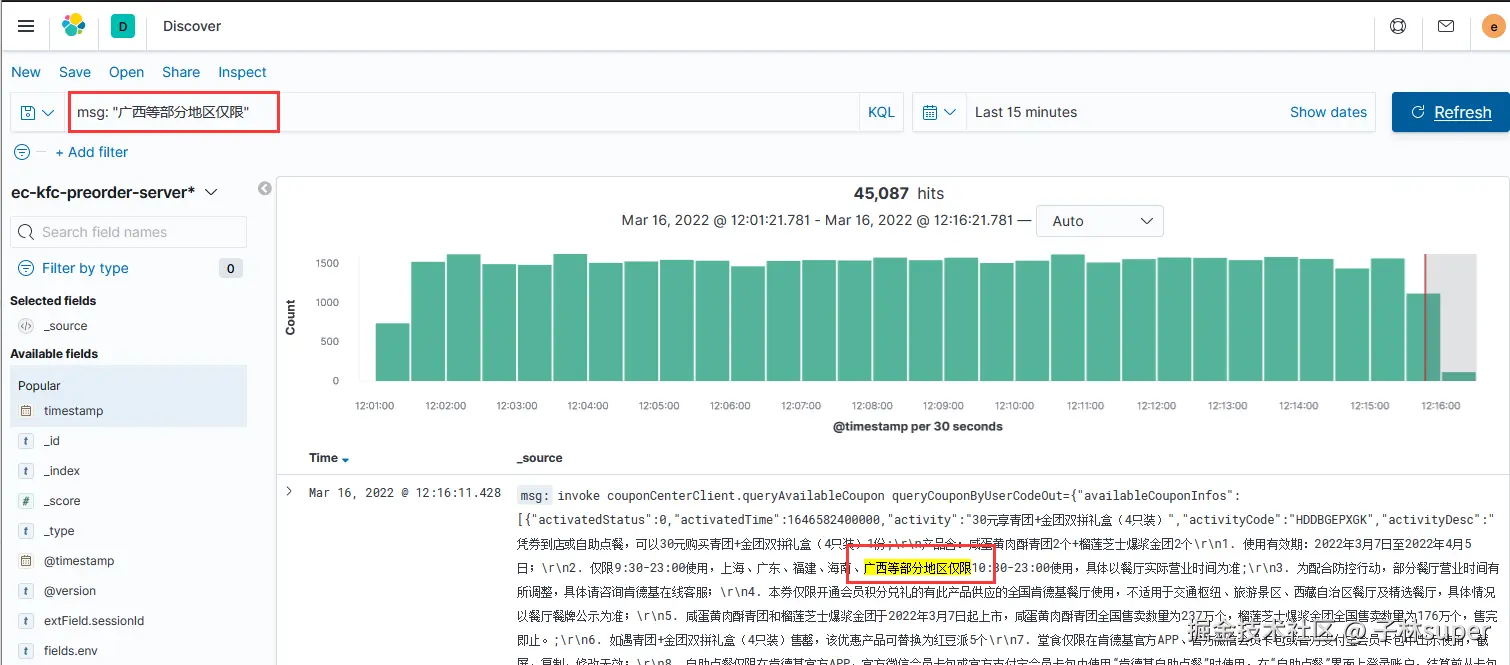
msg字段开启了分词功能,搜索的方式与不具备分词的有区别在于是否使用*。
msg: "广西等部分地区仅限"
以上表达式为查询msg字段中包含 "广西等部分地区仅限" 内容的数据。
补充:
分词器默认是 standard 模式,如msg或者message字段遇到查询不出来的情况,可以使用通配符查询,格式如:message:*1651565985981639001
3、条件运算符
条件运算符就是 > >= < <=,在 KQL 里边都支持,使用也很简单,比如:
msg.statusCode> "200"
以上表达式,查询 msg状态码大于200的日志信息。
4、逻辑运算符
A. NOT用法
关键词为 NOT(不等于)
NOT`` msg:"获取"
以上表达式,查询msg中不包含 "获取"的日志信息。
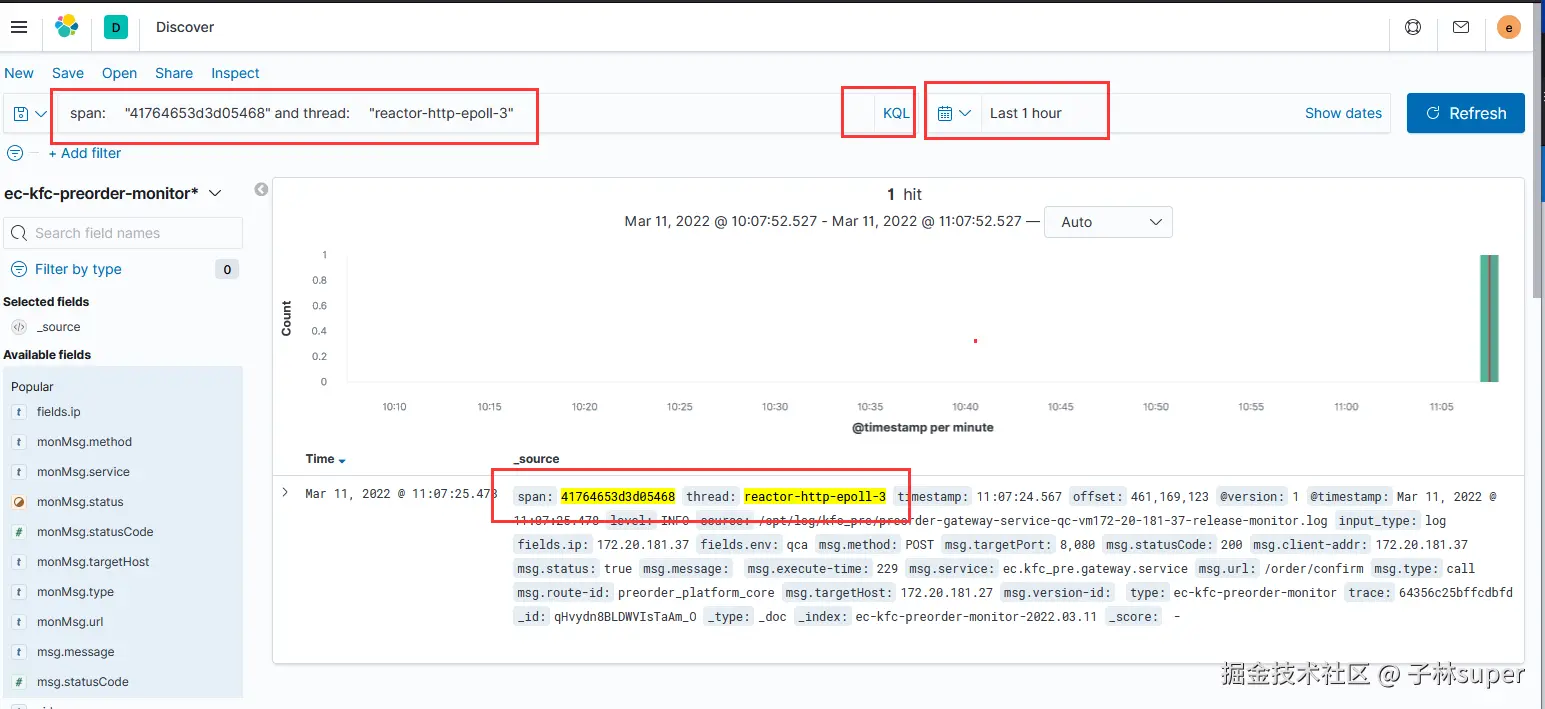
B. AND用法
span:"41764653d3d05468" ``AND`` thread:"reactor-http-epoll-3"
以上表达式查询span 字段中包含 41764653d3d05468 同时 thread字段为 reactor-http-epoll-3 的日志信息。查询的效果如下:
C. OR用法
span:"41764653d3d05468" ``OR`` thread:"reactor-http-epoll-3"
以上表达式,查询 span 和 thread 二者满足其一的日志信息。
三、进阶操作
1、query api 接口
ES官方提供了两中检索方式:
1)通过 URL 参数进行搜索
2)通过 DSL(Domain Specified Language) 进行搜索。
官方更推荐使用第二种方式。第二种方式是基于传递JSON作为请求体(request body)格式与ES进行交互,这种方式更强大,更简洁。
bash
### 第一种,通过URL参数进行探索
# 查询所有 _search 搜索的API
# q=* 匹配所有文档
GET /dangdang/emp/_search?q=*
# sort 以结果中的指定字段排序
# 查询所有,分页查询,每页5条,按年龄倒序,只查询名字,年龄和地址
GET /dangdang/emp/_search?q=*&sort=age:desc&size=5&from=0&_source=name,age,address
### 第二种方式,通过DSL进行搜索
# fuzzy 关键字: 用来模糊查询含有指定关键字的文档
# fuzzy 模糊查询 最大模糊错误 必须在0-2之间
curl -X GET "localhost:9200/dangdang/emp/_search" -d'
{
"query": {
"fuzzy": {
"content":"sprang"
}
}
}'