1. 说明
在自然语言理解(NLU)任务中,尤其是 语义解析(Semantic Parsing) 场景,模型输出通常是一个 结构化的函数调用,例如:
json
{
"name": "app_switch",
"arguments": {
"app_name": "FM",
"action": "打开"
}
}传统的 分类准确率(Accuracy) 只适合用于单一标签分类,无法有效评估这种 复杂结构化预测 。因此,需要设计一套 综合指标 来衡量模型的性能。
2. 评测指标体系
在语义解析中,我们关注三个主要维度:意图识别、槽位填充和生成文本相似度。
✅ 2.1 意图准确率(Intent Accuracy, fn_acc_name)
-
定义:模型预测的函数名是否与标注完全一致。
-
计算方式 :
fnaccname=意图预测正确的样本数总样本数fn_acc_name=意图预测正确的样本数总样本数 fn_acc_name=意图预测正确的样本数总样本数\text{fn\_acc\_name} = \frac{\text{意图预测正确的样本数}}{\text{总样本数}} fnaccname=意图预测正确的样本数总样本数fn_acc_name=总样本数意图预测正确的样本数
意义:衡量模型识别用户意图的能力,是最基础的 NLU 指标。
✅ 2.2 整体解析准确率(Joint Accuracy, fn_acc_all)
-
定义 :不仅要求函数名正确,还要求 所有参数(槽位)完全正确。
-
特点:
- 如果参数允许部分得分,则计算每个参数匹配的平均值;
- 如果参数严格要求完全一致,则只有全部正确才算 1。
-
计算方式(参数级得分):
fn_acc_name:
fn_acc_name=意图预测正确的样本数总样本数 \text{fn\_acc\_name} = \frac{\text{意图预测正确的样本数}}{\text{总样本数}} fn_acc_name=总样本数意图预测正确的样本数
-
意义:更严格地衡量模型整体语义解析的准确性。
✅ 2.3 ROUGE(Recall-Oriented Understudy for Gisting Evaluation)
-
定义 :常用于文本摘要和生成任务,衡量 预测文本和参考文本的 n-gram 重叠度。
-
常见指标:
- ROUGE-1:基于单词(unigram)重叠;
- ROUGE-2:基于二元词组(bigram)重叠;
- ROUGE-L:基于最长公共子序列(LCS)。
-
计算方式:
ROUGE:
ROUGE=重叠的 n-gram 数参考文本 n-gram 总数 ROUGE = \frac{\text{重叠的 n-gram 数}}{\text{参考文本 n-gram 总数}} ROUGE=参考文本 n-gram 总数重叠的 n-gram 数
-
意义:衡量模型生成文本与参考文本的覆盖程度。
✅ 2.4 BLEU(Bilingual Evaluation Understudy)
-
定义 :衡量 预测文本和参考文本之间的 n-gram 一致性,广泛用于机器翻译评估。
-
特点:
- 结合了 精确率(Precision) 和 惩罚短句的BP因子;
- 常用 BLEU-4 计算四元组(4-gram)的一致性。
-
计算公式(简化版) :
BLEU=BP⋅exp(∑n=14wnlogpn)BLEU=BP⋅exp(∑n=14wnlogpn) BLEU=BP⋅exp(∑n=14wnlogpn)BLEU = BP \cdot \exp\left( \sum_{n=1}^4 w_n \log p_n \right) BLEU=BP⋅exp(∑n=14wnlogpn)BLEU=BP⋅exp(n=1∑4wnlogpn)
意义:衡量预测与参考在 n-gram 层面的相似度。
3. 实现方案
本文实现了一个名为 fc_score 的评测函数,支持以下功能:
- ✅ 意图准确率 (
fn_acc_name) - ✅ 整体解析准确率 (
fn_acc_all) - ✅ ROUGE(中文优化版,结合 jieba 分词)
- ✅ BLEU-4 (使用
nltk提供的平滑函数,适合短文本)
代码已优化,支持字段后处理、异常保护,并且输出标准化的 JSON 结果。
4. 示例输出
json
{
"eval_size": 40,
"fn_acc_name": 0.85,
"fn_acc_all": 0.65,
"rouge-1": 0.98531,
"rouge-2": 0.98103,
"rouge-l": 0.98531,
"bleu-4": 0.9544
}- fn_acc_name = 0.85 → 意图识别准确率 85%
- fn_acc_all = 0.65 → 只有 65% 的样本参数完全正确
- ROUGE/BLEU → 模型生成结果与标注在文本层面高度一致
3. 计算acc的代码
计算方式一
这种 更贴合具体业务(NLU Function Call)
jieba:用于中文分词,保证 ROUGE/BLEU 在中文场景下的有效性。
nltk :使用 sentence_bleu 和 SmoothingFunction 计算平滑后的 BLEU 分数,避免短句 BLEU 过低。
rouge :使用 rouge 库计算中文优化的 ROUGE 分数,支持 rouge-1、rouge-2 和 rouge-l。
安装依赖
pip install jieba nltk rouge
fc_score.py
python
import copy
import json
import jieba
from typing import List, Dict, Callable, Union, Optional
from nltk.translate.bleu_score import SmoothingFunction, sentence_bleu
from rouge.rouge import Rouge
def common_score_arguments(fn_gold: Dict, fn_pred: Dict) -> float:
"""比较函数参数是否完全一致,完全一致返回1,否则0"""
return 1.0 if fn_gold.get("arguments", {}) == fn_pred.get("arguments", {}) else 0.0
def compute_rouge_bleu(gold_text: str, pred_text: str) -> Dict[str, float]:
"""计算 ROUGE 和 BLEU-4 指标"""
hypothesis = list(jieba.cut(pred_text))
reference = list(jieba.cut(gold_text))
results: Dict[str, float] = {}
# 计算 ROUGE
try:
rouge = Rouge()
rouge_scores = rouge.get_scores(" ".join(hypothesis), " ".join(reference))[0]
results["rouge-1"] = rouge_scores["rouge-1"]["f"]
results["rouge-2"] = rouge_scores["rouge-2"]["f"]
results["rouge-l"] = rouge_scores["rouge-l"]["f"]
except Exception as e:
print(f"[ROUGE ERROR] {e}")
results.update({"rouge-1": 0.0, "rouge-2": 0.0, "rouge-l": 0.0})
# 计算 BLEU-4
try:
smooth_func: Callable = SmoothingFunction().method3
bleu = sentence_bleu([reference], hypothesis, smoothing_function=smooth_func) # type: ignore
results["bleu-4"] = bleu
except Exception as e:
print(f"[BLEU ERROR] {e}")
results["bleu-4"] = 0.0
return results
def fn2str(fn: Dict) -> str:
"""将函数调用转为字符串"""
return fn["name"] + json.dumps(fn.get("arguments", {}), sort_keys=True, ensure_ascii=False)
def fns2str(fn_list: List[Dict]) -> str:
"""将函数调用列表序列化为字符串"""
return ";".join(sorted(fn2str(f) for f in fn_list))
def postprocess_fn(fn_list: List[Dict],
processors: Optional[List[Callable]] = None,
fn_schema_map: Optional[Dict] = None) -> List[Dict]:
"""后处理函数调用(支持归一化处理)"""
if not processors:
return fn_list
fn_schema_map = fn_schema_map or {}
processed = []
for fn in fn_list:
fn_new = copy.deepcopy(fn)
for p in processors:
fn_new = p(fn_new, fn_schema_map)
processed.append(fn_new)
return processed
def score_fn(fn_gold: List[Dict],
fn_pred: List[Dict],
score_fn_args_func: Callable[[Dict, Dict], float] = common_score_arguments) -> (float, float):
"""计算函数名准确率(fn_acc_name)和参数准确率(fn_acc_all)"""
if not fn_gold and not fn_pred:
return 1.0, 1.0
if len(fn_gold) != len(fn_pred):
return 0.0, 0.0
fn_gold_sorted = sorted(fn_gold, key=fn2str)
fn_pred_sorted = sorted(fn_pred, key=fn2str)
fn_acc_name = 1.0 if [g["name"] for g in fn_gold_sorted] == [p["name"] for p in fn_pred_sorted] else 0.0
fn_acc_all = 0.0
if fn_acc_name:
arg_scores = [score_fn_args_func(g, p) for g, p in zip(fn_gold_sorted, fn_pred_sorted)]
fn_acc_all = sum(arg_scores) / len(arg_scores)
return fn_acc_name, fn_acc_all
def fc_score(score_data: List[Dict]) -> Dict[str, Union[int, float]]:
"""计算整体评测结果,包括 ACC、ROUGE 和 BLEU"""
if not score_data:
raise ValueError("score_data 不能为空")
results: List[Dict[str, Union[str, float]]] = []
for item in score_data:
fn_gold = item.get("gold_fn", [])
fn_pred = item.get("pred_fn", [])
fn_acc_name, fn_acc_all = score_fn(fn_gold, fn_pred)
metrics: Dict[str, Union[str, float]] = {
"query": item.get("query", ""),
"fn_acc_name": fn_acc_name,
"fn_acc_all": fn_acc_all
}
# 计算文本相似度指标
try:
nlg_scores = compute_rouge_bleu(fns2str(fn_gold), fns2str(fn_pred))
metrics.update(nlg_scores)
except Exception as e:
print(f"[NLG SCORE ERROR] {e}")
metrics.update({"rouge-1": 0.0, "rouge-2": 0.0, "rouge-l": 0.0, "bleu-4": 0.0})
results.append(metrics)
# 聚合平均得分
final_scores: Dict[str, Union[int, float]] = {"eval_size": len(results)}
for key in results[0]:
if key == "query":
continue
final_scores[key] = round(sum(float(r[key]) for r in results) / len(results), 5)
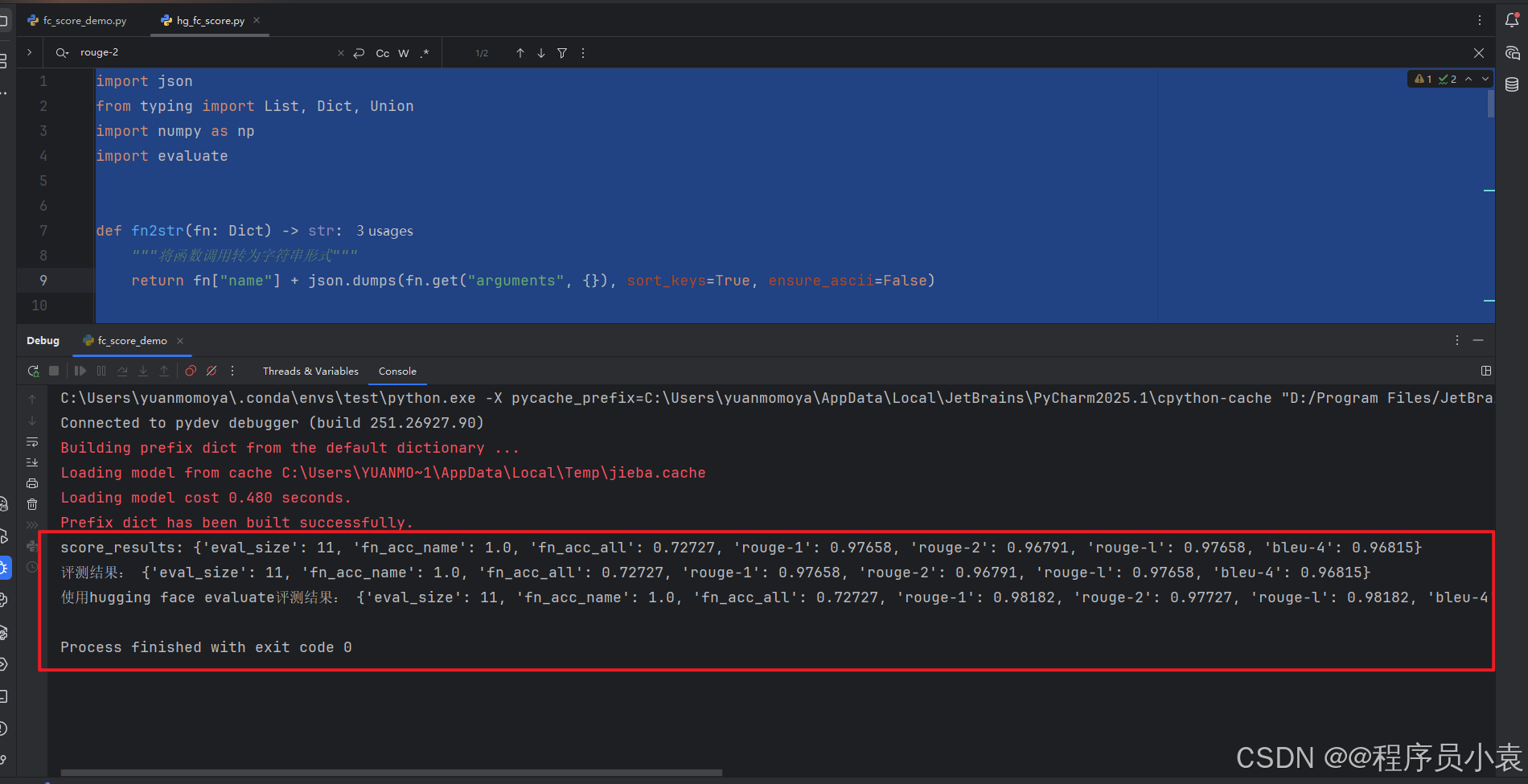
print(f"score_results: {final_scores}")
return final_scoresfc_score_demo.py
python
from fc_score import fc_score
mock_data = [
{
"query": "打开客厅灯",
"gold_fn": [{"name": "light_control", "arguments": {"room": "客厅", "action": "打开"}}],
"pred_fn": [{"name": "light_control", "arguments": {"room": "客厅", "action": "打开"}}],
},
{
"query": "关闭卧室空调",
"gold_fn": [{"name": "ac_control", "arguments": {"room": "卧室", "action": "关闭"}}],
"pred_fn": [{"name": "ac_control", "arguments": {"room": "卧室", "action": "关闭"}}],
},
{
"query": "调节厨房温度到22度",
"gold_fn": [{"name": "temperature_set", "arguments": {"room": "厨房", "temperature": "22"}}],
"pred_fn": [{"name": "temperature_set", "arguments": {"room": "厨房", "temperature": "23"}}], # 温度错了
},
{
"query": "客厅窗帘拉上",
"gold_fn": [{"name": "curtain_control", "arguments": {"room": "客厅", "action": "关闭"}}],
"pred_fn": [{"name": "curtain_control", "arguments": {"room": "客厅", "action": "关闭"}}],
},
{
"query": "开启卧室加湿器",
"gold_fn": [{"name": "humidifier_control", "arguments": {"room": "卧室", "action": "打开"}}],
"pred_fn": [{"name": "humidifier_control", "arguments": {"room": "卧室", "action": "开启"}}], # 词汇不一致
},
{
"query": "把客厅灯调暗一些",
"gold_fn": [{"name": "light_control", "arguments": {"room": "客厅", "brightness": "降低"}}],
"pred_fn": [{"name": "light_control", "arguments": {"room": "客厅", "brightness": "降低"}}],
},
{
"query": "关闭厨房排风扇",
"gold_fn": [{"name": "fan_control", "arguments": {"room": "厨房", "action": "关闭"}}],
"pred_fn": [{"name": "fan_control", "arguments": {"room": "厨房", "action": "关闭"}}],
},
{
"query": "卧室空调调到25度",
"gold_fn": [{"name": "temperature_set", "arguments": {"room": "卧室", "temperature": "25"}}],
"pred_fn": [{"name": "temperature_set", "arguments": {"room": "卧室", "temperature": "25"}}],
},
{
"query": "打开客厅音响",
"gold_fn": [{"name": "audio_control", "arguments": {"room": "客厅", "action": "打开"}}],
"pred_fn": [{"name": "audio_control", "arguments": {"room": "客厅", "action": "打开"}}],
},
{
"query": "关闭卧室灯",
"gold_fn": [{"name": "light_control", "arguments": {"room": "卧室", "action": "关闭"}}],
"pred_fn": [{"name": "light_control", "arguments": {"room": "卧室", "action": "关闭"}}],
},
{
"query": "打开书房灯",
"gold_fn": [{"name": "light_control", "arguments": {"room": "书房", "action": "打开"}}],
"pred_fn": [{"name": "light_control", "arguments": {"room": "书房", "action": "关闭"}}], # 故意动作错误
},
]
if __name__ == "__main__":
results = fc_score(mock_data)
print("评测结果:", results)计算方式二
使用hugging face evaluate来评测,原始的evaluate更标准化,适合通用 NLP 任务
添加依赖
pip install evaluate rouge_score numpy scikit-learn
测试可以使用方式一的
hg_fc_score.py
python
import json
from typing import List, Dict, Union
import numpy as np
import evaluate
def fn2str(fn: Dict) -> str:
"""将函数调用转为字符串形式"""
return fn["name"] + json.dumps(fn.get("arguments", {}), sort_keys=True, ensure_ascii=False)
def fns2str(fn_list: List[Dict]) -> str:
"""将函数调用列表序列化为字符串"""
return ";".join(sorted(fn2str(f) for f in fn_list))
def common_score_arguments(fn_gold: Dict, fn_pred: Dict) -> float:
"""评估函数参数是否完全一致"""
return 1.0 if fn_gold.get("arguments", {}) == fn_pred.get("arguments", {}) else 0.0
def score_fn(fn_gold: List[Dict], fn_pred: List[Dict],
score_fn_args_func=common_score_arguments) -> (float, float):
"""计算函数名准确率(fn_acc_name)和参数准确率(fn_acc_all)"""
if not fn_gold and not fn_pred:
return 1.0, 1.0
if len(fn_gold) != len(fn_pred):
return 0.0, 0.0
fn_gold_sorted = sorted(fn_gold, key=fn2str)
fn_pred_sorted = sorted(fn_pred, key=fn2str)
# 计算函数名是否完全匹配
fn_acc_name = 1.0 if [g["name"] for g in fn_gold_sorted] == [p["name"] for p in fn_pred_sorted] else 0.0
# 计算参数准确率
fn_acc_all = 0.0
if fn_acc_name == 1.0:
arg_scores = [score_fn_args_func(g, p) for g, p in zip(fn_gold_sorted, fn_pred_sorted)]
fn_acc_all = sum(arg_scores) / len(arg_scores)
return fn_acc_name, fn_acc_all
def hf_fc_score(score_data: List[Dict]) -> Dict[str, Union[int, float]]:
"""
使用 Hugging Face evaluate 计算:
- fn_acc_name (函数名准确率)
- fn_acc_all (参数准确率)
- rouge-1 / rouge-2 / rouge-l
- bleu-4
"""
if not score_data:
raise ValueError("score_data 不能为空")
# 加载 Hugging Face 指标
acc_metric = evaluate.load("accuracy")
rouge_metric = evaluate.load("rouge")
bleu_metric = evaluate.load("bleu")
fn_acc_name_list = []
fn_acc_all_list = []
rouge_preds, rouge_refs = [], []
bleu_preds, bleu_refs = [], []
# 遍历样本
for item in score_data:
gold_fns = item.get("gold_fn", [])
pred_fns = item.get("pred_fn", [])
# 计算 ACC
fn_name_score, fn_arg_score = score_fn(gold_fns, pred_fns)
fn_acc_name_list.append(1 if fn_name_score == 1.0 else 0)
fn_acc_all_list.append(fn_arg_score)
# 生成文本形式供 Rouge / BLEU 评估
gold_text = fns2str(gold_fns)
pred_text = fns2str(pred_fns)
rouge_refs.append(gold_text)
rouge_preds.append(pred_text)
bleu_refs.append([gold_text])
bleu_preds.append(pred_text)
# 1️ 计算函数名准确率
acc_res = acc_metric.compute(predictions=fn_acc_name_list, references=[1] * len(fn_acc_name_list))
fn_acc_name = acc_res["accuracy"]
# 2️ 计算参数准确率
fn_acc_all = float(np.mean(fn_acc_all_list))
# 3️ 计算 ROUGE
rouge_res = rouge_metric.compute(predictions=rouge_preds, references=rouge_refs, use_stemmer=False)
# 4️ 计算 BLEU
bleu_res = bleu_metric.compute(predictions=bleu_preds, references=bleu_refs)
# 5️ 组装最终结果
results: Dict[str, Union[int, float]] = {
"eval_size": int(len(score_data)),
"fn_acc_name": float(round(fn_acc_name, 5)),
"fn_acc_all": float(round(fn_acc_all, 5)),
"rouge-1": float(round(rouge_res.get("rouge1", 0.0), 5)),
"rouge-2": float(round(rouge_res.get("rouge2", 0.0), 5)),
"rouge-l": float(round(rouge_res.get("rougeL", 0.0), 5)),
"bleu-4": float(round(bleu_res.get("bleu", 0.0), 5)),
}
return results