redis的缓存更新策略
1.Cache Aside Pattern(旁路缓存模式)
这个模式是我们平常用的比较多的模式,比较适合读请求比较多的情况
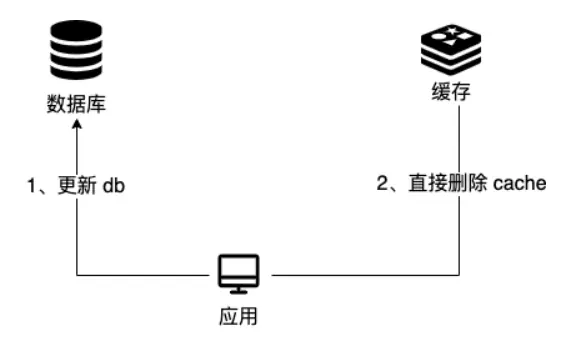
写操作
1.先更新数据库
2.然后直接删除cache
读操作
1.从 cache 中读取数据,读取到就直接返回
2.cache 中读取不到的话,就从 db 中读取数据返回
3.再把数据放到 cache 中。
疑问点 1.在写数据的过程中,可以先删除 cache ,后更新 db 么? ·
不可以!很有可能发生缓存不一致的问题
css
请求 1 先把 cache 中的 A 数据删除 -> 请求 2 从 db 中读取数据-> 请求 1 再把 db 中的 A 数据更新请求1先删除A的缓存,此时数据还没更新,这时候请求2从db中读取数据(此时请求1的数据库还没更新),这个时候cache就会有数据了
然后请求1中的db更新了,但是缓存已经存在了。就会导致redis的缓存是未更新的数据,mysql的数据是更新后的数据。
2.在写数据的过程中,先更新db,再删除redis的缓存,就一定没有问题吗?
css
请求 1 从 db 读数据 A-> 请求 2 更新 db 中的数据 A(此时缓存中无数据 A ,故不用执行删除缓存操作 )
-> 请求 1 将数据 A 写入 cache目前在redis的cache中没有缓存,请求1从db中读数据,然后在redis写数据(在写数据之前mysql的db进行了更新,而且因为此时缓存中没有A,也不用删除),这样的话,用的缓存数据就是更新前的数据了
但这种情况几乎不存在,因为reids在内存中写,会比mysql快很多。
缺陷 1:首次请求数据一定不在 cache 的问题解决办法:可以将热点数据可以提前放入 cache 中。
缺陷 2:写操作比较频繁的话导致 cache 中的数据会被频繁被删除,这样会影响缓存命中率 。 解决办法:数据库和缓存数据强一致场景:更新 db 的时候同样更新 cache,不过我们需要加一个锁/分布式锁来保证更新 cache 的时候不存在线程安全问题。 可以短暂地允许数据库和缓存数据不一致的场景:更新 db 的时候同样更新 cache,但是给缓存加一个比较短的过期时间,这样的话就可以保证即使数据不一致的话影响也比较小。
2.Read/Write Through Pattern(读写穿透)
Read/Write Through 是一种将缓存作为主要数据访问层的设计模式,应用程序只与缓存交互,缓存系统自身负责与底层数据库的数据同步。
1.读穿透 (Read Through)
应用程序直接向缓存请求数据
如果缓存命中,直接返回数据
如果缓存未命中:
缓存系统自动从数据库加载数据
将数据存入缓存
返回给应用程序
2.写穿透 (Write Through)
应用程序向缓存写入数据
缓存系统先更新自身数据
缓存系统同步将数据写入数据库
返回写入结果给应用程序
3.架构图
css
应用程序 → [ 缓存 ] ↔ 数据库
↖______ ↙4.优点分析
简化应用逻辑:应用不需要关心缓存与数据库的同步问题
数据一致性:写操作保证缓存和数据库同步更新
当应用程序执行 写操作(如更新数据) 时,缓存层(如 Redis)不会立即返回成功,而是会 同步等待数据库(如 MySQL)也更新完成,确保缓存和数据库的数据完全一致后,才向应用程序返回成功响应。 减少代码重复:避免在每个业务逻辑中重复缓存处理代码
缺点与挑战 实现复杂度:需要封装缓存层,对现有架构改造较大
写性能:每次写操作都需要等待数据库IO完成
缓存系统依赖:缓存系统需要了解数据库schema
适用场景
读多写少的系统 需要强一致性的业务场景 希望简化应用层代码的项目
3.Write Behind Pattern(异步缓存写入)
Write Behind Caching 是一种以缓存为中心的高性能写入策略,其核心哲学是:"先快速响应,后异步持久化"。这种模式将缓存视为事实上的数据源,而数据库则作为备份存储,通过异步方式保持最终一致性。
css
[应用程序] → [缓存层] ⇢ [异步队列] → [数据库]写入路径:应用 → 缓存 → 确认响应 → (异步) → 数据库
读取路径:应用 ← 缓存 (始终从缓存读取最新数据)
写入过程
1.应用发起写请求
2.系统立即更新缓存数据
3.记录变更到写缓冲区/队列
4.立即返回成功响应
5.后台线程定期批量处理缓冲区数据:
6.合并相同key的多次更新
7.批量写入数据库
8.清理已处理的缓冲区条目
读取过程
1.应用发起读请求
2.直接从缓存返回最新数据(无论是否已持久化到数据库)
潜在挑战
数据丢失风险:系统崩溃时未持久化的数据会丢失
一致性妥协:无法保证数据库实时反映最新状态
复杂度增加:需要处理故障恢复和缓冲区管理
监控难度:需要额外监控缓存-数据库延迟
适用场景
写密集型系统:如点击流、日志收集
允许数据丢失的场景:如实时统计、行为分析
突发写入高峰:需要缓冲消峰的场景
非关键业务数据:如社交媒体的点赞、浏览计数
redis的最终一致性
(1) 延迟双删策略
java
// 1. 先删除缓存
redis.del(key);
// 2. 更新数据库
db.update(data);
// 3. 休眠一段时间(如500ms)后再次删除缓存
Thread.sleep(500);
redis.del(key);(2) 基于消息队列的最终一致性
数据库更新后发送消息到MQ
消费者接收消息删除缓存
失败时可重试
(3) 基于binlog的同步
使用Canal等工具监听数据库binlog
解析变更日志后删除/更新缓存
选择策略的建议
强一致性要求:使用分布式锁+同步双写,但性能较低
最终一致性可接受:Cache Aside + 延迟双删或消息队列
读多写少:Read Through模式
写多读少:Write Behind模式