本文介绍了美团技术团队在国际顶会ACL 2025中发表的8篇论文,研究方向覆盖了生成式检索算法、多目标偏好对齐训练、富文本图像理解、搜索词推荐、跨语言迁移能力、多模态数学推理、第三人称任务等技术领域,希望相关研究能给同学们带来一些帮助或启发。
ACL是计算语言学和自然语言处理领域最重要的顶级国际会议,由国际计算语言学协会组织,每年举办一次。据谷歌学术计算语言学刊物指标显示,ACL影响力位列第一,是CCF-A类推荐会议。ACL成立于1962年,是世界上影响力最大、最具活力的国际学术组织之一,它每年夏天都会召开大会,供学者发布论文,分享最新成果,它的会员来自全球60多个国家和地区,是NLP领域最高级别的国际学术组织,代表了国际计算语言学的最高水平。
01 Multi-level Relevance Document Identifier Learning for Generative Retrieval
论文类型:Long Paper(ACL 2025 Main)
论文下载 :PDF
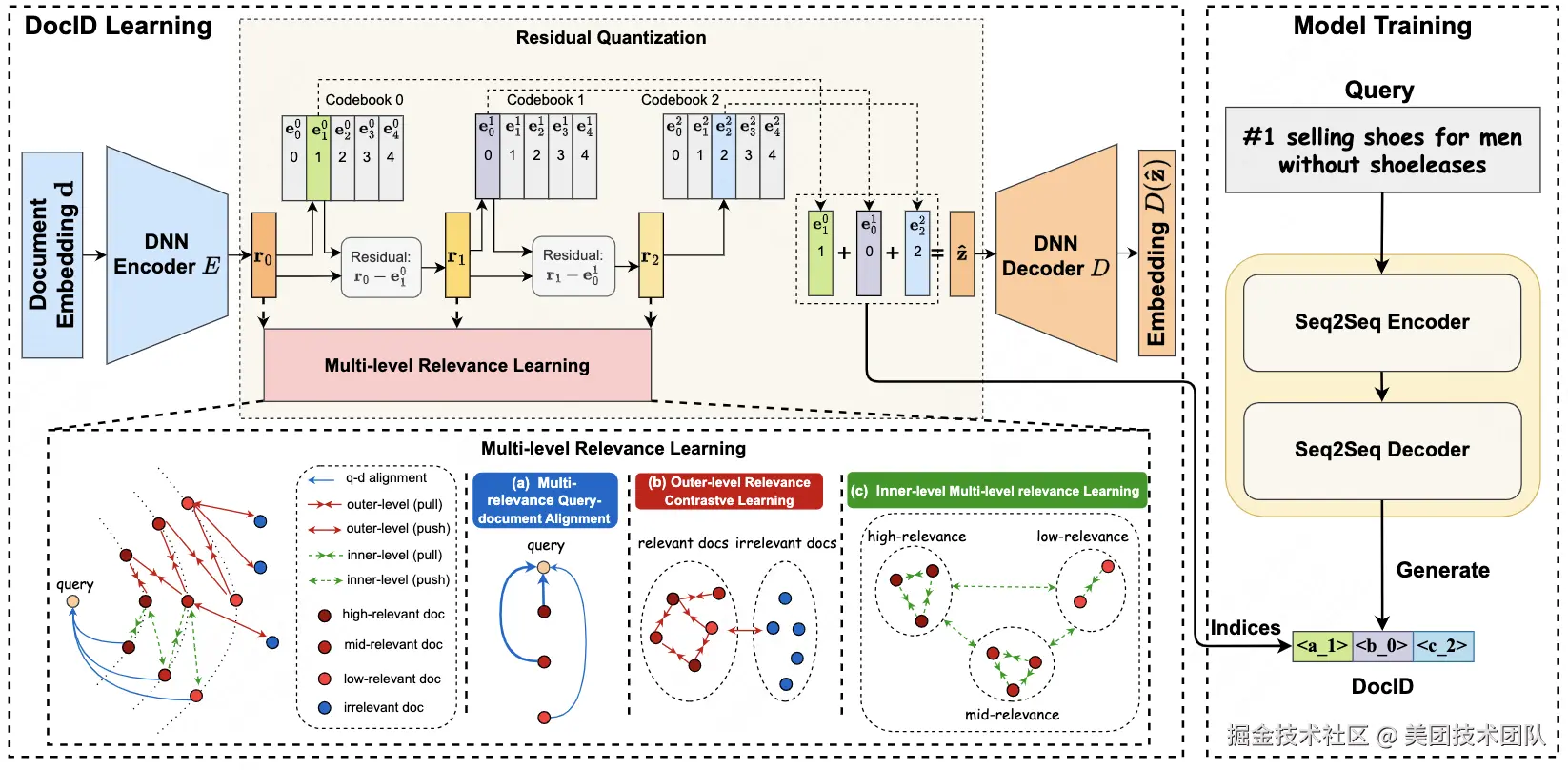
论文简介:本文提出一种基于多级相关性的生成式检索文档标识符学习方法(MERGE),旨在解决生成式检索范式中的关键挑战。针对现有方法仅依赖文档文本生成离散标识符(DocIDs)导致语义关联不足的问题,本方法引入查询作为关联桥梁,构建多级文档相关性学习框架。该方法通过三个核心模块实现:多相关性查询-文档对齐模块建立文档表征与相关查询的有效映射,外层对比学习模块捕捉二元相关性特征,内层多级相关性学习模块实现细粒度文档区分。该方法在保持文档标识符唯一性的同时,编码了丰富的层次化语义信息。在公开的多语言电商搜索数据集的实验表明,MERGE在检索性能上显著优于现有基准方法,验证了其通过多级相关性建模提升文档标识符语义表征能力的有效性。
02 HierGR: Hierarchical Semantic Representation Enhancement for Generative Retrieval in Food Delivery Search
论文类型:Industry Oral
论文下载 :PDF
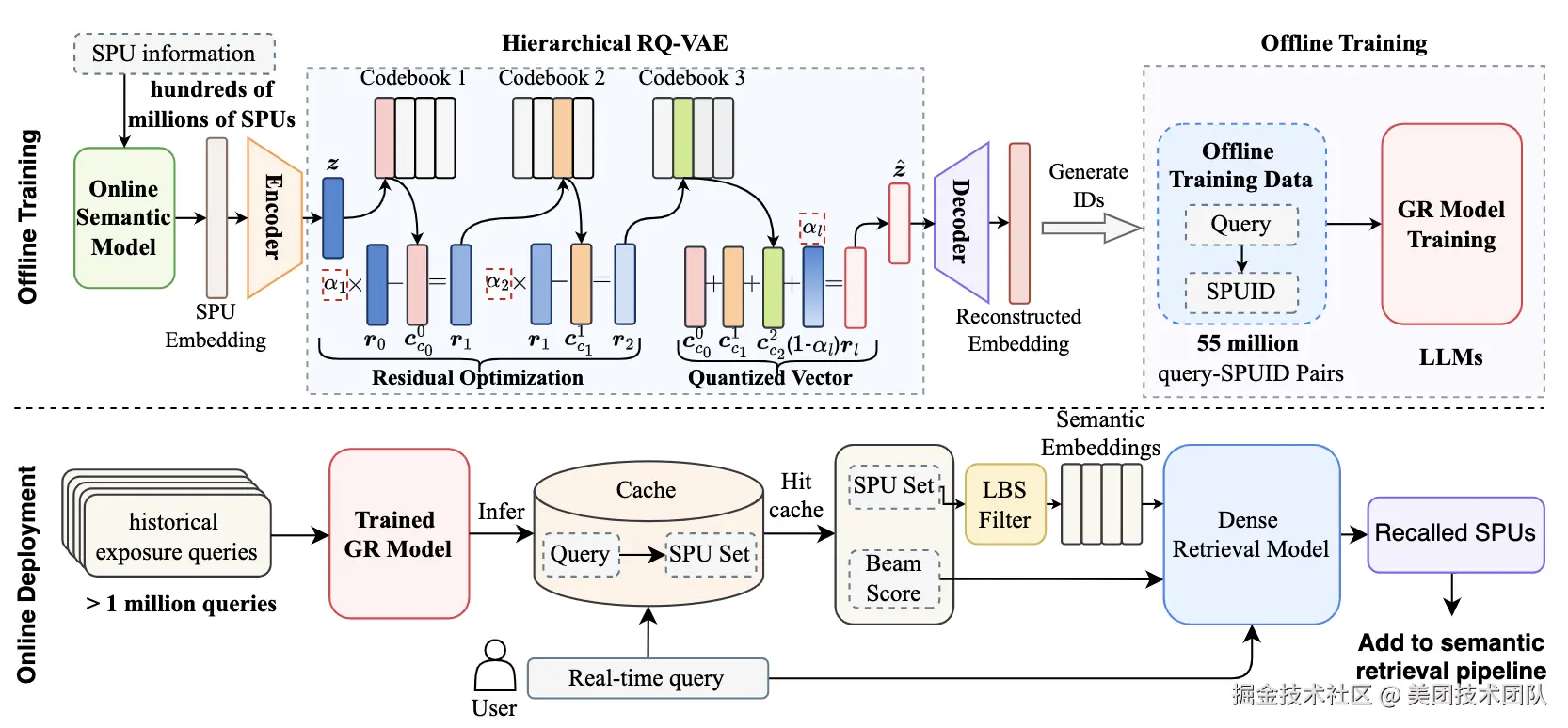
论文简介:本文针对生成式检索(Generative Retrieval, GR)在外卖搜索场景中的实际应用挑战展开研究,提出基于层次化语义表征增强的生成式检索方法(HierGR)。针对在线部署面临的商品规模大、大模型推理延迟高及地理位置服务(LBS)限制严格等核心问题,本文提出了离线训练与在线部署协同优化方法:首先设计改进残差量化过程的层次化语义标识符生成方法,构建具有空间层级特征的语义ID体系;其次采用查询缓存机制降低延迟,并通过与在线稠密检索模型的联合部署满足实时搜索需求。实验结果表明,在美团外卖搜索场景下,复杂意图Query的搜索效果提升显著,千人成单+0.68%,验证了生成式检索技术在外卖搜索领域落地的可行性。
03 AMoPO: Adaptive Multi-objective Preference Optimization without Reward Models and Reference Models
论文类型:Long Paper
论文下载 :PDF
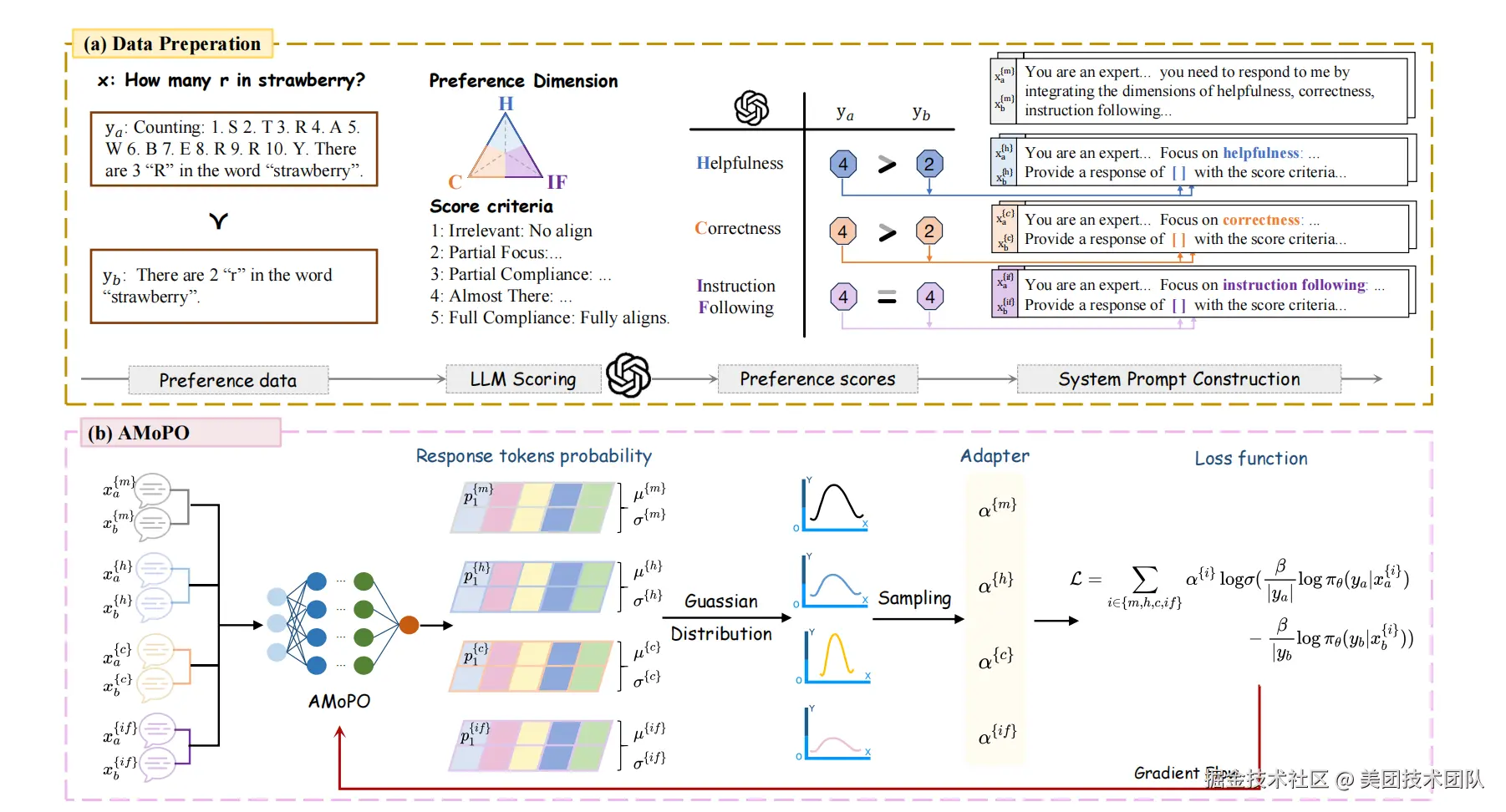
论文简介:本文提出了一种自适应参考模型自由的多目标偏好优化算法AMoPO(Adaptive Reference-free Multi-objective Preference Optimization),以解决现有多目标偏好优化方法在训练复杂度和计算资源消耗上的突出问题。传统方法如DPO、SimPO和MODPO在多目标优化时需要多轮训练或多个奖励模型,导致效率低下、资源消耗大。而在实际业务中,对一个回复的评估常常涉及多个维度(如拟人性、指令遵循性等),单一维度的优化难以满足需求。为此,本论文提出了AMoPO算法无需依赖参考模型和奖励模型,通过自适应采样策略动态调整各维度权重,在单次优化过程中即可高效实现多目标偏好优化。该方法显著降低了计算资源消耗,同时实现了多维度偏好的自适应优化。在公开数据集上以及业务上的实验结果表明,AMoPO在有效性、效率和多维度自适应优化能力方面均具有显著优势。
04 Multimodal Large Language Models for Text-rich Image Understanding: A Comprehensive Review
论文类型:Findings
论文下载 :PDF
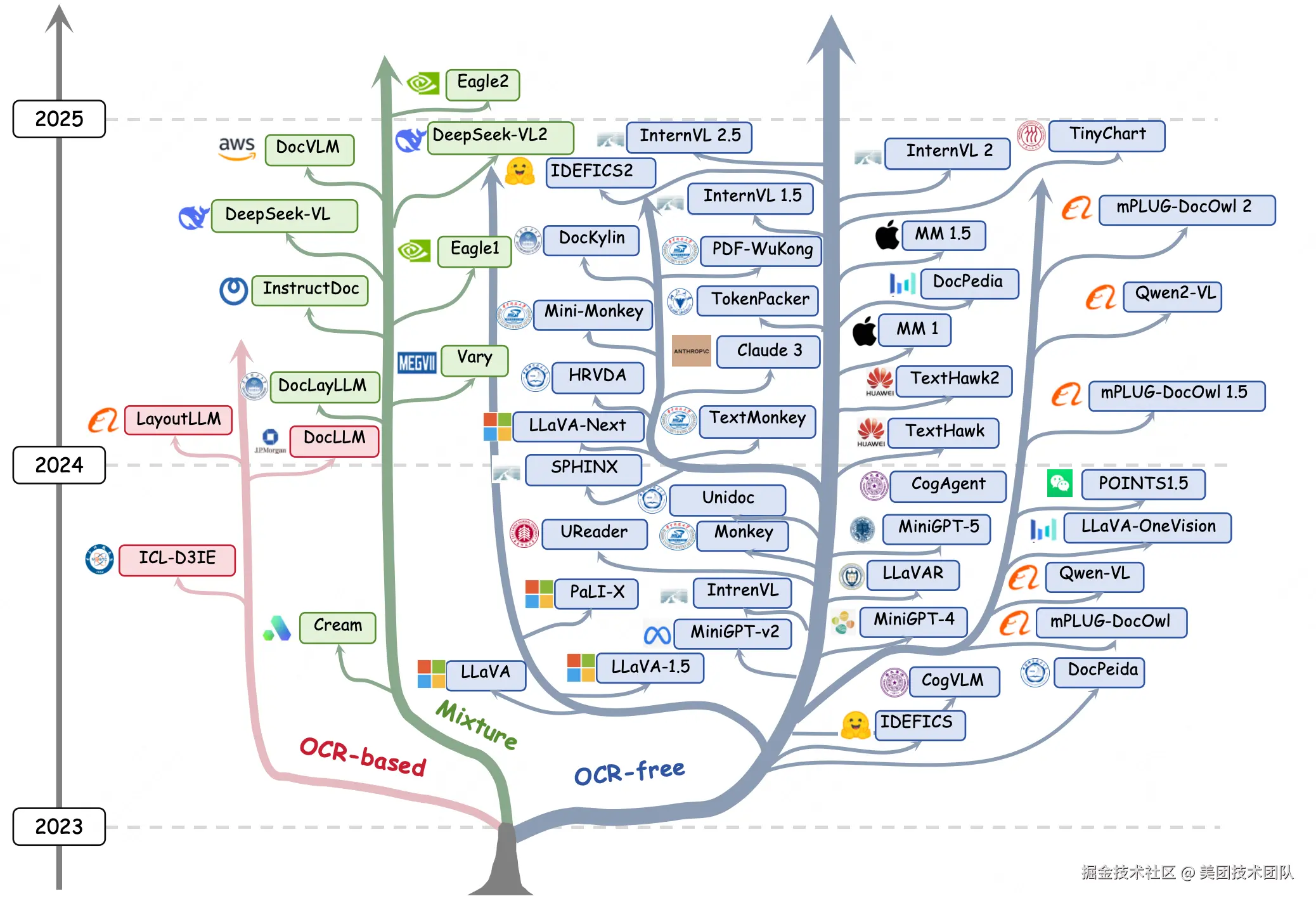
论文简介:近年来,多模态大型语言模型(MLLM)的兴起为富文本图像理解(TIU)领域引入了一个新的维度,这些模型展现出令人印象深刻的性能。然而,它们的快速发展和广泛应用使得研究者们跟上最新进展变得越来越具有挑战性。为了解决这个问题,我们提出了一项系统而全面的综述,以促进对 TIU MLLM 的进一步研究。首先,我们概述了几乎所有 TIU MLLM 的时间线、架构和流程。然后,我们回顾了所选模型在主流基准测试中的表现。最后,我们探讨了该领域的发展方向、挑战和局限性。
05 Consistency-Aware Online Multi-Objective Alignment for Related Search Query Generation
论文类型:Industry Track
论文下载 :PDF
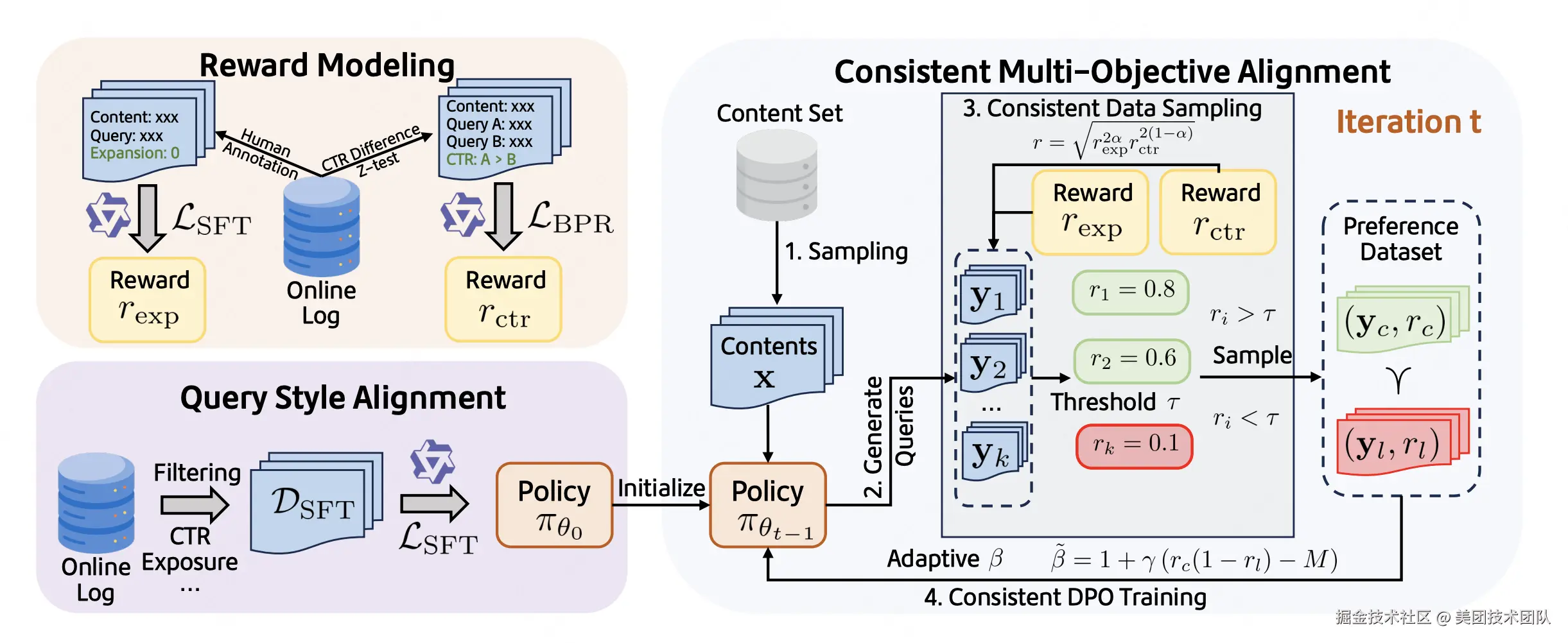
论文简介:在现代数字平台中,相关搜索场景下的搜索词推荐对于提升用户参与度和内容发现至关重要。然而,现有方法往往难以在优化点击率(CTR)和促进主题延展性这两个核心目标之间取得平衡,尤其是在利用大型语言模型(LLM)进行查询生成时,多目标对齐的挑战尤为突出。这主要面临三大挑战:1)如何精确量化并建模不同的优化目标(如CTR和主题延展性);2)如何确保生成搜索词的格式和风格与平台保持一致;3)如何有效协调可能冲突的多目标以实现共同提升,避免顾此失彼。针对这些挑战,本文提出了CMAQ(Consistency-aware Multi-objective Aligned Query generation),一个面向相关搜索词生成的在线多目标对齐框架。CMAQ包含三个关键组成部分:1)精确的奖励建模,针对两个目标的区别,为CTR和主题扩展分别使用不同策略训练奖励模型;2)搜索词风格对齐,通过监督微调(SFT)使LLM适应平台搜索词风格;3)一致性感知的多目标优化,迭代式直接偏好优化(DPO)策略。该策略通过几何平均奖励进行一致性数据采样,并引入样本级别自适应的β调整DPO损失,从而在优化过程中提升样本层面和损失层面两个目标的一致性,缓解目标冲突。离线实验结果显示,CMAQ在以CTR奖励和延展性奖励为维度的帕累托前沿上显著优于基线方法。同时,在大型工业级生活服务平台大众点评上进行的在线A/B测试表明,CMAQ实现了显著的在线CTR提升(+2.3%)。此外,人工评估也证实了CMAQ生成的查询质量更高。这些结果共同证明了CMAQ不仅能有效提升查询生成质量和用户参与度,也为多目标LLM对齐提供了新的思路,有助于维护平台生态健康。
06 Investigating and Scaling up Code-Switching for Multilingual Language Model Pre-Training
论文类型:Findings
论文下载 :PDF
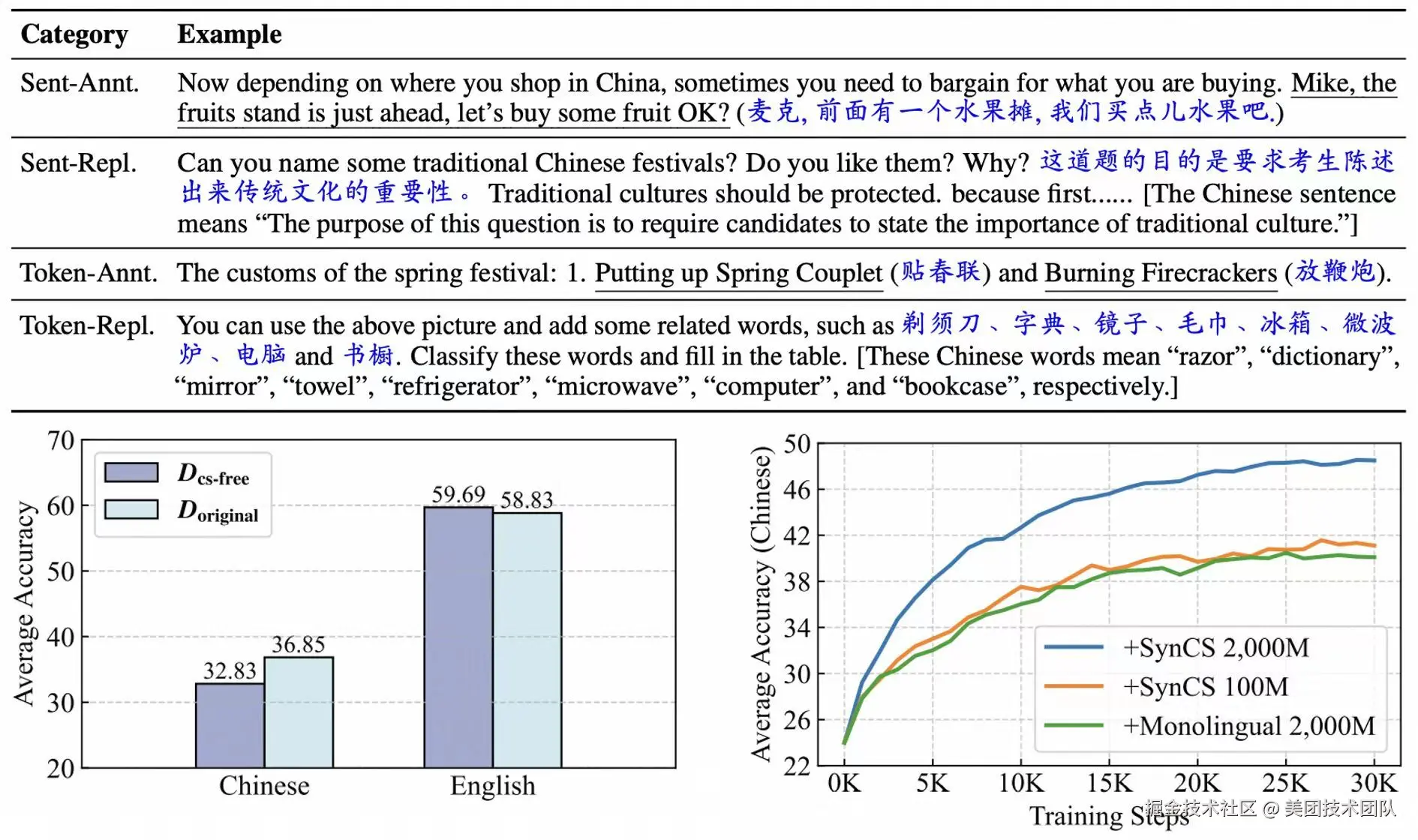
论文简介:在本文中,我们聚焦于当前大语言模型的自发跨语言迁移能力:尽管大多数开源大模型在其预训练语料中仅包含少量多语言数据(例如 LLaMA-3 的多语言数据占比仅为8%,平均到每种非英语语言则比例极低),这些模型却仍展现出较强的多语言理解与生成能力。我们认为,这种现象源于模型在预训练过程中发生了自发的跨语言迁移 ,即模型能够从主要训练语言(如英语)中学习到的能力自动迁移到其他语言上。然而,目前关于这一现象的研究尚缺乏对其数据层面成因的系统解释 ,这在一定程度上限制了多语言大模型的发展与优化。针对该现象,本文开展了深入研究,我们发现,即使在大模型的预训练语料中 Code-Switching 数据的比例非常低,它们仍然是引发大模型自发跨语言迁移的关键因素,其中 Code-Switching 指的是在同一个上下文中混合使用多种语言的现象。在此基础上,我们进而提出了一种低成本、高效率的 Code-Switching 数据合成方法 SynCS(Synthetic Code-Switching)。我们系统比较了不同类型的 Code-Switching 数据在扩大规模时对模型跨语言迁移能力的影响差异,最终形成了一套通过合成 Code-Switching 数据来增强大模型多语言能力的有效策略 。
07 The Role of Visual Modality in Multimodal Mathematical Reasoning: Challenges and Insights
论文类型:ACL 2025 Main(Oral)
论文下载 :PDF
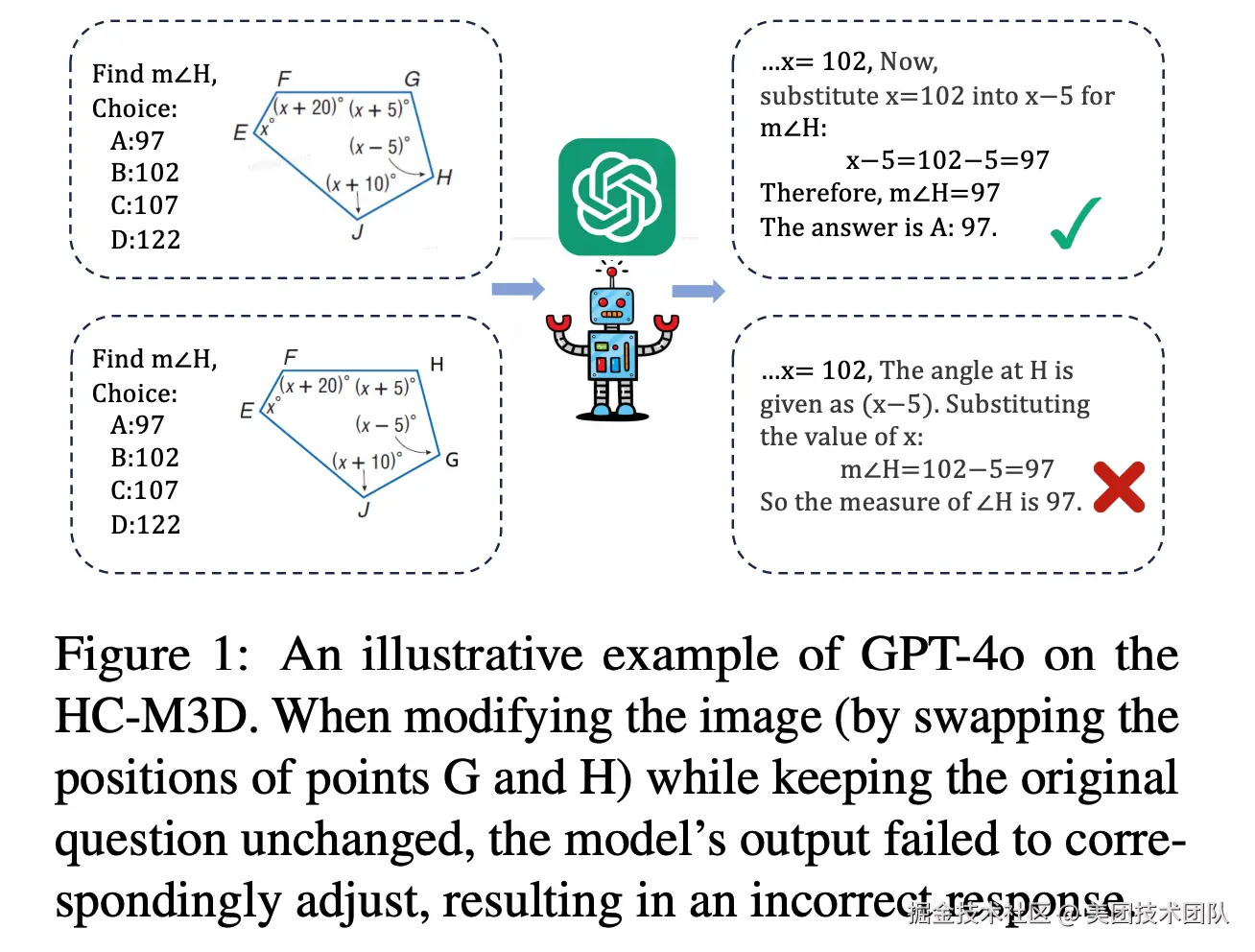
论文简介:随着大型视觉-语言模型(LVLMs)的迅猛发展,多模态数学推理成为了AI研究中的热门领域。然而,视觉信息在模型推理中真正发挥了多少作用?在本研究中,我们揭示了现有模型可能过于依赖文本而忽略了视觉信息的潜在价值。我们设计了一项视觉模态扰动实验,在训练过程中随机打乱图像与文本之间的对应关系或完全移除图像,训练完成后与正常训练的模型对比性能差异。结果显示,即使在这些干扰下,当前主流模型的推理性能也仅出现了轻微下降。这表明,模型的推理过程主要受文本信息的引导,视觉信息的作用远未被充分利用。与之对照的是,通用领域中,对视觉模态的扰动会大幅度降低性能。进一步分析发现,现有的评测基准中存在两个明显的问题:很大一部分数据由文本模型即可正确回答以及模型可以根据选项来猜测答案。基于上述的观察,我们认为现有的评测数据集无法准确反映视觉模态在推理过程中的重要性,因此提出了HC-M3D数据集。该数据集包含1,851条人工标注的数据,其中429个问题包含对照组,对照组为对图片做出关键修改来确保答案变化。实验发现即便是最先进的模型在面对这些细微变化时也频频「失明」,超过一半的情况下坚持原本的预测,未能根据视觉变化进行修正。这一系列发现凸显了现有多模态数学推理模型对视觉信息利用不足的深层问题,也为未来的研究指明了明确方向。我们建议,构建更具视觉挑战性的数据集、设计更精细的图像编码器以及开发更有效的视觉依赖增强机制,将是未来研究的重要突破口。
08 From Observation to Understanding: Front-Door Adjustments with Uncertainty Calibration for Enhancing Egocentric Reasoning in LVLMs
论文类型:Findings
论文下载 :PDF
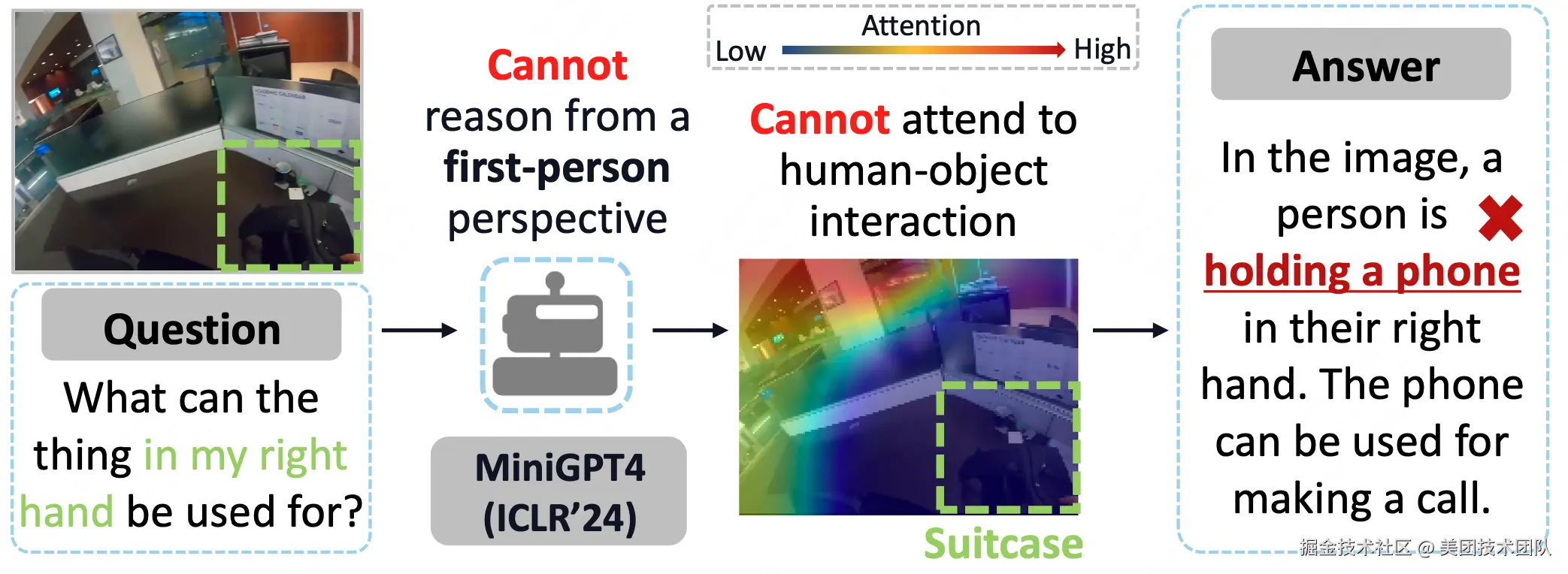
论文简介:近年来,大型视觉语言模型(LVLMs)在第三人称任务中展现出巨大潜力。现有方法在将LVLMs应用于第一人称任务时,往往忽视了关键的主体与环境的交互信息,限制了其自我中心推理能力。例如下图中MiniGPT4未能准确聚焦右下角人物与物体的交互区域,根据经验误判右手握持的物体为手机。
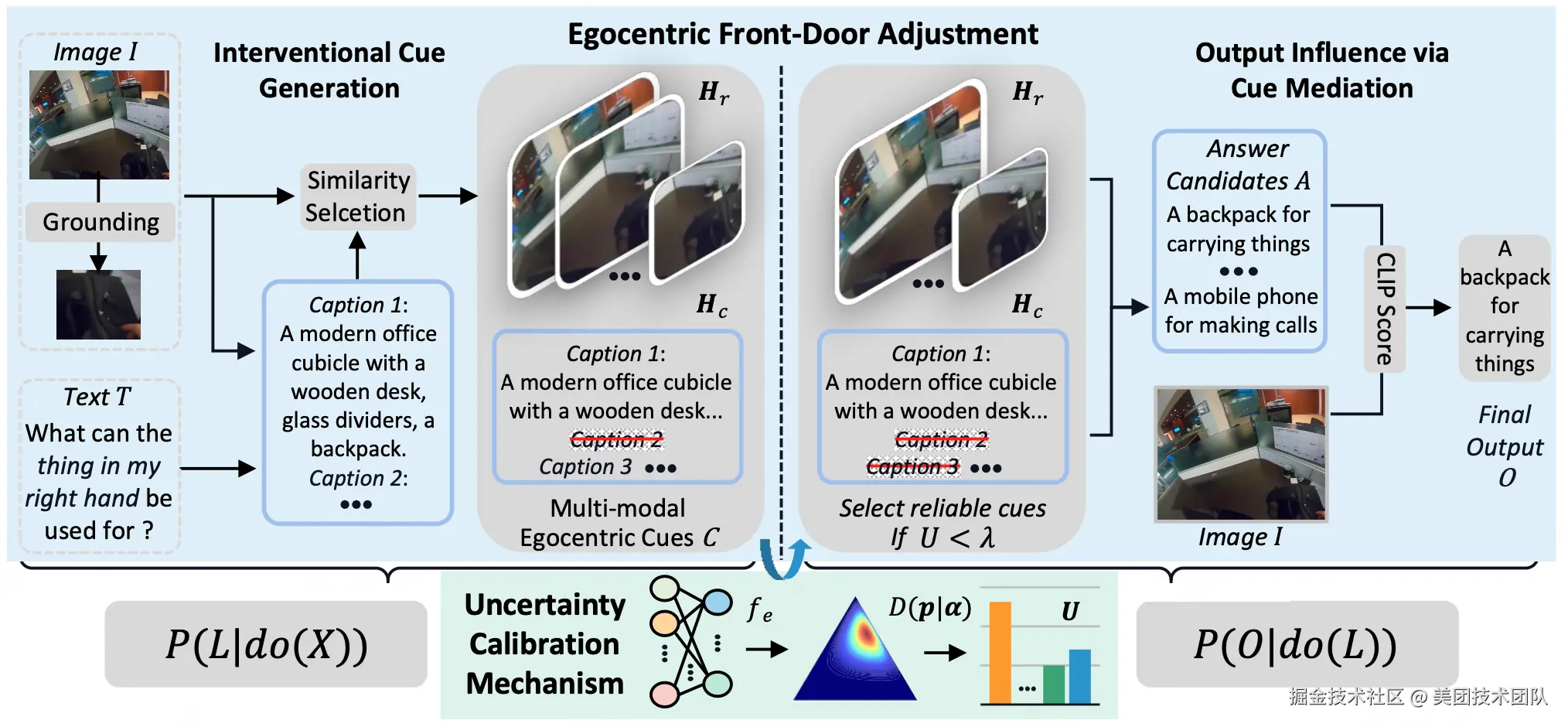
本论文提出了基于不确定性校准的前门调整方法(Front-Door Adjustments with Uncertainty Calibration,FRUIT),通过结构因果模型增强大型视觉语言模型(LVLMs)的自我中心推理能力。该方法分观察与理解两阶段:首先定位交互区域并构建层次化的视觉-文本线索,然后通过不确定性过滤线索中的噪声信息,最终将优化的观察结果整合到提示模板中,指导模型进行第一人称视角的语义理解。
阅读更多
| 关注「美团技术团队」微信公众号,在公众号菜单栏对话框回复【2024年货】、【2023年货】、【2022年货】、【2021年货】、【2020年货】、【2019年货】、【2018年货】、【2017年货】等关键词,可查看美团技术团队历年技术文章合集。

| 本文系美团技术团队出品,著作权归属美团。欢迎出于分享和交流等非商业目的转载或使用本文内容,敬请注明 "内容转载自美团技术团队"。本文未经许可,不得进行商业性转载或者使用。任何商用行为,请发送邮件至 tech@meituan.com 申请授权。