文章目录
- 简介
- [138. 随机链表复制](#138. 随机链表复制)
- [148. 排序链表](#148. 排序链表)
- [23. 合并K个升序链表](#23. 合并K个升序链表)
- [146. LRU缓存](#146. LRU缓存)
- 个人学习总结
简介
本篇作为链表专题的下篇,将深入探讨四道更具挑战性的题目:随机链表的复制、排序链表、合并 K 个升序链表以及经典的LRU 缓存设计。
这些问题不仅考验我们对指针操作的熟练度,更引导我们思考如何将分治、递归、哈希表、优先队列等高级算法思想和数据结构巧妙地应用于链表场景。
138. 随机链表复制
问题描述:
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 val, random_index 表示:
- val:一个表示 Node.val 的整数。
- random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。
你的代码 只 接受原链表的头节点 head 作为传入参数。
示例:
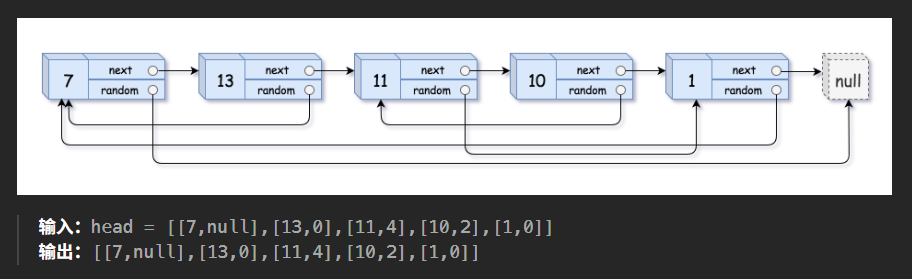
标签提示: 哈希表、链表
哈希表迭代法
解题思想
该算法的核心思想是利用哈希表(映射)来建立原始节点与复制节点之间的一一对应关系。通过这种映射,我们可以将"创建新节点"和"连接指针"这两个步骤解耦。首先,遍历原链表,为每个节点创建一个副本,并将这对关系存入哈希表。然后,再次遍历原链表,利用哈希表能够以 O(1) 时间复杂度查找的特性,快速找到 next 和 random 指针所对应的复制节点,从而完成新链表的指针连接。这种方法将问题转化为两次简单的线性遍历,逻辑清晰直观。
解题步骤
- 创建节点与映射:初始化一个哈希表。第一次遍历原始链表,对于每个节点,创建一个值相同的新节点,并将 <原始节点, 新节点>
的键值对存入哈希表。 - 连接指针:第二次遍历原始链表。对于每一个原始节点,从哈希表中获取其对应的复制节点。然后,利用哈希表查找其 next 和 random
指针所指向的节点对应的复制节点,并赋值给复制节点的 next 和 random 指针。 - 返回结果:遍历结束后,从哈希表中获取原始头节点对应的复制节点,并将其作为新链表的头节点返回。
实现代码
java
class Solution {
public Node copyRandomList(Node head) {
if(head == null){
return head;
}
Map<Node, Node> map = new HashMap<>();
Node curr = head;
// 新建复制链表,的所有节点
while(curr != null){
map.put(curr, new Node(curr.val));
curr = curr.next;
}
// 设置next、random指针
curr = head;
while(curr != null){
Node newnode = map.get(curr);
newnode.next = map.get(curr.next);
newnode.random = map.get(curr.random);
curr = curr.next;
}
return map.get(head);
}
}复杂度分析
-
时间复杂度:O(N)
其中 N 是链表的节点数量。算法包含两次对链表的完整遍历,每次遍历的操作都是常数时间(哈希表的插入和查找平均为 O(1)),因此总时间复杂度为 O(N)。
-
空间复杂度:O(N)
哈希表需要存储 N 个 <原始节点, 复制节点> 的映射对,因此需要 O(N) 的额外空间。
递归回溯+哈希表
解题思想
该算法采用深度优先搜索(DFS)与记忆化相结合的递归思想。其核心是将复杂问题分解为子问题:要复制一个节点,必须先复制其 next 指向的节点和 random 指向的节点。为了避免因 random 指针形成的环而导致无限递归,并确保每个原始节点只被复制一次,算法引入一个哈希表作为"记忆"或缓存。这个哈希表存储了原始节点到其复制节点的映射,在递归过程中,如果遇到已经处理过的节点,直接从缓存中返回其副本,从而巧妙地解决了循环引用和重复创建的问题。
解题步骤
- 递归基准情况:如果当前节点 head 为 null,直接返回 null。
- 记忆化查询:检查哈希表中是否已存在当前节点 head 的映射。
- 如果存在:说明该节点及其后续结构已经被复制过,直接从哈希表中取出并返回其复制节点。
- 如果不存在:执行以下步骤来创建和连接。
- 创建与缓存:为当前节点 head 创建一个新的复制节点 newhead,并立即将 <head, newhead> 这对映射存入哈希表。这一步必须在递归调用之前完成,以切断可能的循环引用。
- 递归构建:递归调用 copyRandomList 函数,分别处理 head.next 和
head.random。递归调用的返回值就是复制后的 next 节点和 random 节点。 - 连接指针:将上一步递归返回的结果分别赋值给 newhead.next 和 newhead.random。
- 返回结果:返回当前节点 head 对应的复制节点 newhead(即 map.get(head))。
实现代码
java
class Solution {
Map<Node, Node> map = new HashMap<Node, Node>();
public Node copyRandomList(Node head) {
if(head == null){
return null;
}
if(!map.containsKey(head)){
Node newhead = new Node(head.val);
map.put(head, newhead);
newhead.next = copyRandomList(head.next);
newhead.random = copyRandomList(head.random);
}
return map.get(head);
}
}复杂度分析
- 时间复杂度:O(N)
其中 N 是链表的节点数量。由于哈希表的记忆化,每个原始节点只会被访问和处理一次,所有操作(创建节点、哈希表存取)的平均时间复杂度都是 O(1),因此总时间复杂度为 O(N)。 - 空间复杂度:O(N)
空间消耗主要来自两部分:
1.哈希表:需要存储 N 个原始节点到复制节点的映射,占用 O(N) 的空间。
2.递归调用栈:在最坏情况下(链表无 random 指针形成的环),递归的深度会达到 N,因此调用栈也需要 O(N) 的空间。
综合来看,总空间复杂度为 O(N)。
148. 排序链表
问题描述:
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
示例:
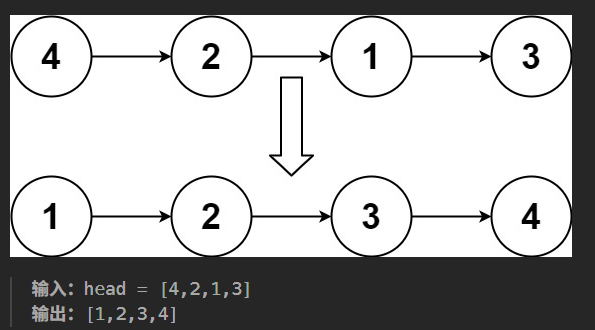
标签提示: 链表、双指针、分治、归并排序
解题思想
该算法采用归并排序 的思想,这是一种高效的、基于"分治"策略的排序算法。其核心是将一个大问题分解为若干个结构相同的小问题,递归地解决这些小问题,然后将子问题的解合并,最终得到原问题的解。
在链表排序中,具体实现为:
- 分:利用快慢指针技术,在 O(N) 时间内找到链表的中间节点,将链表从中间断开,形成两个独立的子链表。
- 治:递归地对这两个子链表分别进行排序,直到子链表的长度为 0 或 1(天然有序)。
- 合:将两个已经排好序的子链表合并成一个大的有序链表。
由于链表的节点可以方便地断开和重新连接,归并排序在链表上的实现非常自然且高效。
解题步骤
- 递归基准情况:如果链表为空或只有一个节点,则它已经是有序的,直接返回头节点。
- 分割链表:
- 调用 midNode 辅助函数,通过快慢指针找到链表的中间节点 mid。
- 定义左子链表的头 leftHead 为原链表的头 head,右子链表的头 rightHead 为 mid.next。
- 执行 mid.next = null,将链表从中间彻底断开,形成两个独立的子链表。
- 递归排序:递归调用 sortList 函数,分别对 leftHead 和 rightHead 进行排序,得到两个已排序的子链表 sortLeft 和 sortRight。
- 合并链表:调用 merge 辅助函数,将 sortLeft 和 sortRight 合并成一个完整的有序链表,并返回其头节点。
实现代码
java
class Solution {
// 得利用归并排序,那么就需要两个辅助函数:1.寻找中间节点;2.合并有序链表
// 1.寻找中间节点,使用快慢指针
public ListNode midNode(ListNode head){
ListNode slow = head;
ListNode fast = head.next;
while(fast != null && fast.next != null){
slow = slow.next;
fast = fast.next.next;
}
return slow;
}
// 2.合并两个有序序列
public ListNode merge(ListNode l1, ListNode l2){
ListNode dummy = new ListNode(-1);
ListNode tail = dummy;
while(l1 != null && l2 != null){
if(l1.val <= l2.val){
tail.next = l1;
l1 = l1.next;
}else{
tail.next = l2;
l2 = l2.next;
}
tail = tail.next;
}
tail.next = (l1 != null) ? l1 : l2;
return dummy.next;
}
public ListNode sortList(ListNode head) {
if(head == null || head.next == null){
return head;
}
// 分割节点,并递归
ListNode mid = midNode(head);
ListNode leftHead = head;
ListNode rightHead = mid.next;
mid.next = null; // 断开链表
// 递归排序
ListNode sortLeft = sortList(leftHead);
ListNode sortRight = sortList(rightHead);
// 返回合并链表
return merge(sortLeft, sortRight);
}
}复杂度分析
-
时间复杂度:O(N log N),其中 N 是链表的长度。
- 分割:每次递归调用 midNode 函数寻找中点,需要遍历半个链表,时间复杂度为 O(N/2)。
- 合并:每次递归调用 merge 函数合并两个子链表,需要遍历所有节点,时间复杂度为 O(N)。
根据归并排序的递推公式 T(N) = 2T(N/2) + O(N),可以解出总时间复杂度为 O(N log N)。
-
空间复杂度:O(log N)。
- 算法本身没有使用与输入规模相关的额外数据结构。
- 空间消耗主要来自于递归调用栈。每次递归调用都会在栈上创建一层栈帧,递归的深度等于链表被分割的次数,即 log N。因此,空间复杂度为 O(log N)。
23. 合并K个升序链表
问题描述:
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例:
示例 1:
输入:lists = [[1,4,5],[1,3,4],[2,6]]
输出:[1,1,2,3,4,4,5,6]
解释:链表数组如下:
[
1->4->5,
1->3->4,
2->6
]
将它们合并到一个有序链表中得到。
1->1->2->3->4->4->5->6
示例 2:
输入:lists = []
输出:[]
示例 3:
输入:lists = [[]]
输出:[]标签提示: 链表、分治、最优队列、归并排序
分治合并
解题思想
该算法采用分治策略,其思想与归并排序高度相似。它将"合并 K 个有序链表"这个大问题,递归地分解为"合并 2 个有序链表"这个基础子问题。
具体来说:
- 分:将包含 K 个链表的数组,从中间一分为二,形成两个子数组,每个子数组包含大约 K/2 个链表。
- 治:递归地对这两个子数组进行合并,直到子数组中只剩下一个链表(此时它天然有序,无需合并)。
- 合:将递归返回的两个已经合并好的、更大的有序链表,再通过一个基础的"合并两个有序链表"函数,最终合并成一个完整的有序链表。
通过这种方式,问题规模逐层减半,最终高效地得到结果。
解题步骤
-
主函数 mergeKLists:
- 处理边界情况:如果输入数组为空或长度为 0,直接返回 null。
- 调用递归辅助函数 merge(lists, 0, lists.length - 1),开始分治过程。
-
递归辅助函数 merge(lists, left, right):
- 递归基准:当 left == right 时,表示子数组中只有一个链表,直接返回该链表 listsleft。
- 分割:计算中间索引 mid,将区间 left, right 分割为 left, mid 和 mid + 1, right。
- 递归:分别对左右两个子区间调用 merge 函数,得到两个已排序的链表 leftPart 和 rightPart。
- 合并:调用 mergeTwoList 函数,将 leftPart 和 rightPart 合并,并返回合并后的头节点。
-
基础合并函数 mergeTwoList:
- 使用经典的哑节点法,迭代地合并两个有序链表,并返回新链表的头节点。
实现代码
java
class Solution {
// 1.一个合并有序链表的函数
public ListNode mergeTwoList(ListNode l1, ListNode l2){
ListNode dummy = new ListNode(-1);
ListNode tail = dummy;
while(l1 != null && l2 != null){
if(l1.val <= l2.val){
tail.next = l1;
l1 = l1.next;
}else{
tail.next = l2;
l2 = l2.next;
}
tail = tail.next;
}
tail.next = (l1 !=null) ? l1 : l2;
return dummy.next;
}
// 分治方法合并
public ListNode merge(ListNode[] lists, int left, int right){
if(left == right){
return lists[left];
}
// 分治
int mid = left + (right - left) / 2;
ListNode leftPart = merge(lists, left, mid);
ListNode rightPart = merge(lists, mid + 1, right);
return mergeTwoList(leftPart, rightPart);
}
public ListNode mergeKLists(ListNode[] lists) {
if(lists == null || lists.length == 0){
return null;
}
return merge(lists, 0, lists.length - 1);
}
}复杂度分析
-
时间复杂度:O(N log K)
其中 N 是所有链表中的总节点数,K 是链表的数量。
递归的深度为 log K。
在每一层递归中,所有子链表被合并的总工作量都是 O(N)(每个节点都会被处理一次)。
因此,总时间复杂度为 O(N) * O(log K) = O(N log K)。
-
空间复杂度:O(log K)
算法本身没有使用与输入规模相关的额外数据结构。
空间消耗主要来自于递归调用栈。递归的深度为 log K,所以空间复杂度为 O(log K)。
优先队列合并
解题思想
该算法利用优先队列(最小堆)这种数据结构来高效地找到所有链表头节点中的最小值。其核心思想是"贪心"的:每次都从所有可选的节点中,选择最小的那个连接到结果链表中。
具体流程如下:
- 将 K 个链表的头节点全部放入一个最小堆中。堆的顶元素就是全局最小的节点。
- 循环地从堆中取出顶部节点(当前最小值),将其连接到结果链表的末尾。
- 如果被取出的节点还有下一个节点(next),则将这个 next 节点加入堆中,以代表该链表的下一个候选者。
- 重复步骤 2 和 3,直到堆为空,表示所有节点都已被处理完毕。
解题步骤
- 初始化:
- 处理边界情况。
- 创建一个最小堆 PriorityQueue,并通过 Lambda 表达式 (a, b) -> a.val - b.val 定义比较规则,确保堆顶是 val 最小的节点。
- 建堆:
- 遍历 lists 数组,将所有非空链表的头节点加入堆中。
- 合并:
- 创建一个哑节点 dummy 作为结果链表的起点。
- 当堆不为空时,执行循环:
a. 从堆中弹出最小节点 minNode。
b. 将 minNode 连接到结果链表的尾部。
c. 如果 minNode.next 不为空,则将其推入堆中,作为该链表新的代表。
- 返回:
- 循环结束后,返回 dummy.next,即合并后链表的头节点。
实现代码
java
class Solution {
public ListNode mergeKLists(ListNode[] lists) {
if(lists == null || lists.length == 0){
return null;
}
// 使用优先队列合并
// 1.创建优先队列,并通过Lambda表达式,自定义比较器实现排序
PriorityQueue<ListNode> pq = new PriorityQueue<>((a, b) -> a.val - b.val);
// 2.将所有头结点放入队列中
for(ListNode head : lists){
if(head != null){
pq.offer(head);
}
}
// 3.创建合并后的链表
ListNode dummy = new ListNode(-1);
ListNode tail = dummy;
// 4.合并链表
while(!pq.isEmpty()){
ListNode minNode = pq.poll();
tail.next = minNode;
tail = tail.next;
if(minNode.next != null){
pq.offer(minNode.next);
}
}
return dummy.next;
}
}复杂度分析
-
时间复杂度:O(N log K)
其中 N 是总节点数,K 是链表的数量。
总共有 N 个节点需要被处理。
对于每个节点,都需要执行一次堆的 poll 操作,以及最多一次 offer 操作。堆的大小最大为 K。
堆的插入和删除操作时间复杂度为 O(log K)。
因此,总时间复杂度为 N * O(log K) = O(N log K)。
-
空间复杂度:O(K)
空间主要消耗在优先队列上。
在任何时候,堆中最多存放 K 个节点(每个链表一个)。
因此,空间复杂度为 O(K)。
146. LRU缓存
问题描述:
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存
int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
void put(int key, int value) 如果关键字 key 已经存在,则变更其数据值 value ;如果不存在,则向缓存中插入该组 key-value 。如果插入操作导致关键字数量超过 capacity ,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
示例:
输入
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出
[null, null, null, 1, null, -1, null, -1, 3, 4]
解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4标签提示: 设计、哈希表、双向链表
解题思想
LRU 缓存机制要求所有操作在 O(1) 时间内完成,这带来了两个核心需求:快速查找和顺序维护。
快速查找:哈希表是实现 O(1) 查找的理想选择。
顺序维护:我们需要一种结构来记录数据的访问顺序,以便快速定位"最久未使用"的元素。链表天然适合维护顺序。
单独使用任何一种结构都无法满足要求。因此,核心思想是结合哈希表与双向链表:
哈希表:存储 key 到链表节点的映射,负责 O(1) 时间的快速定位。
双向链表:按访问顺序存储节点。头部为最近使用,尾部为最久未使用。之所以是"双向",是因为在移动节点时,O(1) 时间删除节点需要其前驱指针。
通过这种组合,我们利用哈希表快速找到节点,再通过双向链表快速更新其位置,从而满足所有操作的 O(1) 时间复杂度要求。
解题步骤
-
基础构建:
- 定义双向链表节点,包含 key、value、prev 和 next 指针。
- 在 LRU 缓存类中,初始化哈希表、容量、以及两个哨兵节点 head 和 tail,以简化链表边界操作。
- 封装好对链表的基本操作:头部添加节点、删除任意节点、移动节点到头部、删除尾部节点。
-
实现 get(key):
- 通过哈希表查找 key 对应的节点。
- 若节点不存在,返回 -1。
- 若节点存在,将其移动到链表头部,并返回其 value。
-
实现 put(key, value):
- 通过哈希表查找 key 对应的节点。
- 若节点存在:更新其 value,并将其移动到链表头部。
- 若节点不存在:创建新节点,加入哈希表并插入链表头部。此时若缓存已满,则删除链表尾部节点,并同步从哈希表中移除该节点的 key。
实现代码
java
class LRUCache {
// 使用哈希表+双向链表,一个快速查找,一个存储
// 链表记录顺序:头部为最近使用、尾部为最久未使用、插入得头插法
// 1.一个数据结构 双链表
// 2.对数据结构操作:插入头部、尾部删除、删除节点、移动到头部
// 3.通过对数据结构的操作,完成访问(利用哈希表)和添加缓存
class cacheNode{
int key;
int value;
cacheNode prev;
cacheNode next;
public cacheNode(){}
public cacheNode(int key, int value){
this.key = key;
this.value = value;
}
}
// 头部插入
public void addToHead(cacheNode node){
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
// 删除节点
public void removeNode(cacheNode node){
node.prev.next = node.next;
node.next.prev = node.prev;
}
// 尾部删除
public cacheNode removeTail(){
cacheNode node = tail.prev;
removeNode(node);
return node;
}
// 移动到头部
public void moveToHead(cacheNode node){
removeNode(node);
addToHead(node);
}
// 属性
private Map<Integer, cacheNode> map = new HashMap<Integer, cacheNode>();
private int capacity;
private int size;
private cacheNode head, tail; // 链表的哨兵节点
// 初始化
public LRUCache(int capacity) {
this.capacity = capacity;
this.size = 0;
head = new cacheNode();
tail = new cacheNode();
head.next = tail;
tail.prev = head;
}
// 快速查询,存在并移动到链表头部
public int get(int key) {
cacheNode node = map.get(key);
if(node == null){
return -1;
}else{
moveToHead(node);
return node.value;
}
}
// 插入
public void put(int key, int value) {
cacheNode node = map.get(key);
if(node != null){
node.value = value;
moveToHead(node);
}else{
node = new cacheNode(key, value);
map.put(key, node);
addToHead(node);
size ++;
// 超出容量删除尾部节点
if(size > capacity){
cacheNode tailNode = removeTail();
map.remove(tailNode.key);
size --;
}
}
}
}复杂度分析
- 时间复杂度:
get 操作:哈希表查找 O(1) + 链表移动 O(1) = O(1)。
put 操作:哈希表查找/插入 O(1) + 链表操作 O(1) = O(1)。 - 空间复杂度:
哈希表和双向链表最多存储 capacity 个元素,因此空间复杂度为 O(capacity)。
个人学习总结
这组链表题目无疑是对算法思维和代码实现能力的综合考验,总结下来,我有以下几点核心收获:
- 分治思想的威力:无论是"排序链表"还是"合并 K 个升序链表",都完美体现了分治策略的精髓。将一个复杂的大问题拆解成结构相同的小问题,递归求解后再合并,这种思想是解决许多复杂问题的"万能钥匙"。
- 数据结构的组合艺术:"LRU 缓存"是组合数据结构的典范。它告诉我们,单一数据结构往往有其局限性,而通过哈希表的快速查找和双向链表的顺序维护相结合,可以创造出满足复杂需求的、性能卓越的新结构。
- 善用工具,事半功倍:在解决"合并 K 个升序链表"时,优先队列(最小堆)提供了极其优雅的解法。这提醒我,在埋头实现底层逻辑之前,应先审视语言或标准库中是否有现成的、高效的工具可以"为我所用"。
- 递归与迭代的权衡:"随机链表的复制"同时存在递归和迭代两种优秀解法。递归思路更符合直觉,代码简洁;而迭代法则通过巧妙的链表穿插,节省了额外空间。理解这两种方法的优劣,有助于在不同场景下做出最佳选择。
掌握这些技巧,不仅是为应对面试,更是为了培养一种将复杂问题拆解、并选择合适工具进行系统性解决的工程思维。