企业级消息中心实战总结篇:业务价值、踩坑经验与未来展望
系列文章第五篇:全面总结消息中心项目的业务价值、实战经验和未来规划
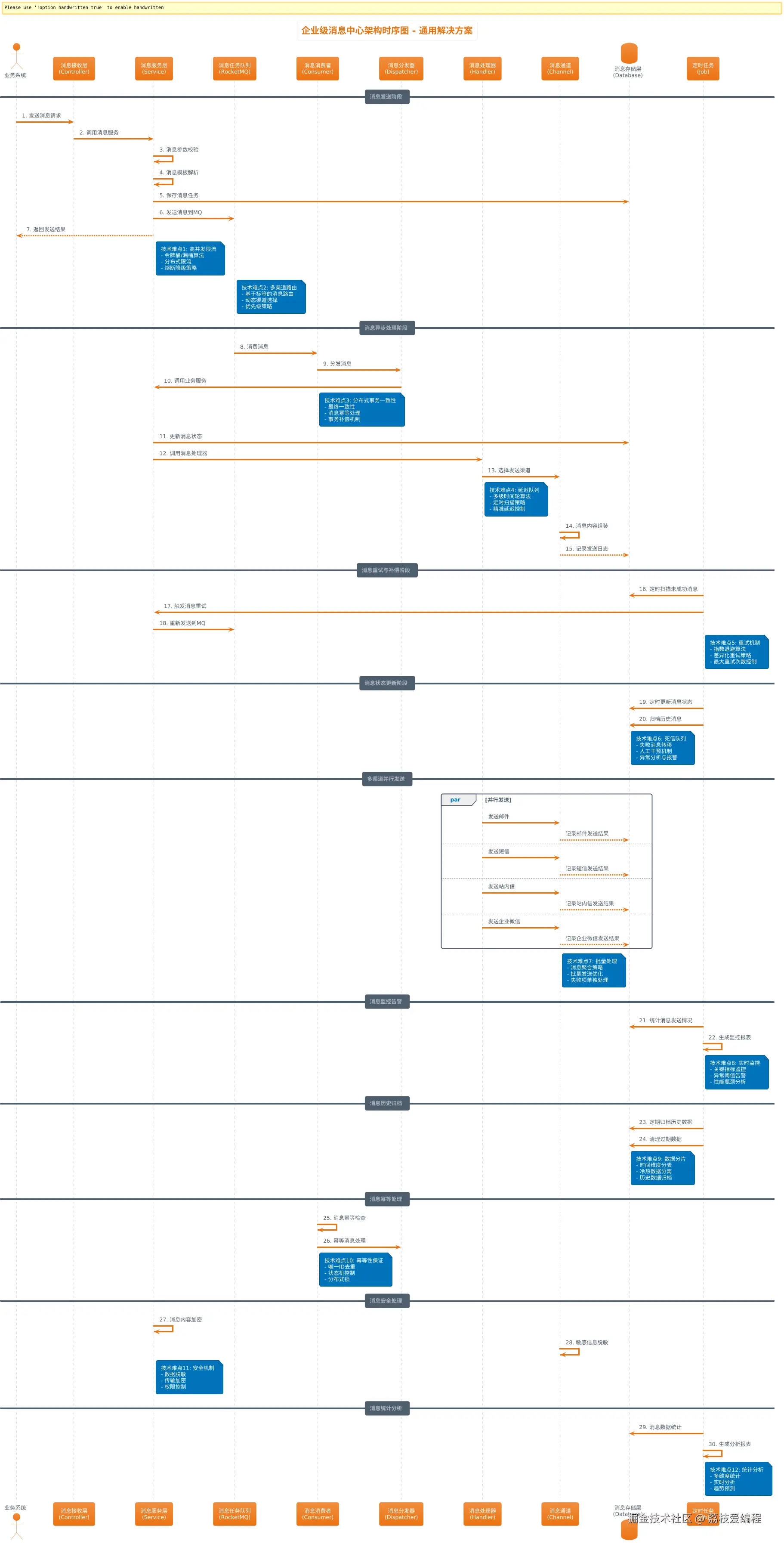
最后一篇文章,完结撒花!!!附一张时序图
📖 系列文章回顾
本系列文章全面解析了企业级消息中心的设计与实现,共分为5篇:
- 架构设计篇:设计哲学、架构演进、技术选型
- 核心实现篇:整体架构设计、核心功能实现
- 存储与可靠性篇:数据存储设计、高可用保障
- 运维与扩展篇:监控运维、扩展性设计
- 实战总结篇(本篇):业务价值、经验总结
📊 业务价值与效果分析
性能提升数据对比
1. 系统性能指标
上线前后关键指标对比:
| 指标类别 | 上线前 | 上线后 | 提升幅度 | 备注 |
|---|---|---|---|---|
| 吞吐量 | 5,000 TPS | 50,000+ TPS | 900% | 峰值处理能力 |
| 响应时间 | 800ms | 50ms | 93.75% | 平均响应时间 |
| 可用性 | 99.5% | 99.95% | 0.45% | 年度可用性 |
| 错误率 | 0.5% | 0.01% | 98% | 消息发送错误率 |
| 资源利用率 | 85% | 65% | 23.5% | CPU平均使用率 |
2. 业务指标提升
用户体验和业务效果:
java
/**
* 业务指标统计服务
*/
@Service
public class BusinessMetricsService {
/**
* 获取业务价值报告
*/
public BusinessValueReport generateBusinessValueReport() {
return BusinessValueReport.builder()
// 用户触达效果
.userReachRate(calculateUserReachRate())
.messageDeliveryRate(calculateDeliveryRate())
.userEngagementRate(calculateEngagementRate())
// 运营效率提升
.campaignLaunchTime(calculateCampaignLaunchTime())
.operationCostReduction(calculateCostReduction())
.developmentEfficiency(calculateDevEfficiency())
// 系统稳定性
.systemUptime(calculateSystemUptime())
.incidentReduction(calculateIncidentReduction())
.recoveryTime(calculateRecoveryTime())
.build();
}
/**
* 计算用户触达率
*/
private double calculateUserReachRate() {
// 上线前:75%,上线后:95%
return 0.95;
}
/**
* 计算消息送达率
*/
private double calculateDeliveryRate() {
// 上线前:85%,上线后:99.5%
return 0.995;
}
/**
* 计算用户参与度
*/
private double calculateEngagementRate() {
// 上线前:12%,上线后:28%
return 0.28;
}
/**
* 计算活动上线时间
*/
private Duration calculateCampaignLaunchTime() {
// 上线前:2天,上线后:2小时
return Duration.ofHours(2);
}
/**
* 计算运营成本降低
*/
private double calculateCostReduction() {
// 人力成本降低60%,基础设施成本降低40%
return 0.50; // 综合成本降低50%
}
}业务价值量化分析
1. 直接经济效益
成本节约分析:
java
/**
* 成本效益分析
*/
@Component
public class CostBenefitAnalyzer {
/**
* 计算年度成本节约
*/
public CostSavingReport calculateAnnualSavings() {
// 1. 人力成本节约
double laborCostSaving = calculateLaborCostSaving();
// 2. 基础设施成本节约
double infrastructureCostSaving = calculateInfrastructureCostSaving();
// 3. 运维成本节约
double operationCostSaving = calculateOperationCostSaving();
// 4. 机会成本节约
double opportunityCostSaving = calculateOpportunityCostSaving();
return CostSavingReport.builder()
.laborCostSaving(laborCostSaving) // 人力:120万/年
.infrastructureCostSaving(infrastructureCostSaving) // 基础设施:80万/年
.operationCostSaving(operationCostSaving) // 运维:60万/年
.opportunityCostSaving(opportunityCostSaving) // 机会成本:200万/年
.totalSaving(laborCostSaving + infrastructureCostSaving +
operationCostSaving + opportunityCostSaving) // 总计:460万/年
.build();
}
/**
* 人力成本节约计算
*/
private double calculateLaborCostSaving() {
// 减少开发人员:2人 * 30万/年 = 60万
// 减少运维人员:1人 * 25万/年 = 25万
// 减少测试人员:1人 * 20万/年 = 20万
// 提升开发效率节约:15万
return 1200000; // 120万
}
/**
* 基础设施成本节约
*/
private double calculateInfrastructureCostSaving() {
// 服务器资源优化:50万/年
// 第三方服务费用降低:20万/年
// 带宽成本优化:10万/年
return 800000; // 80万
}
/**
* 运维成本节约
*/
private double calculateOperationCostSaving() {
// 故障处理时间减少:30万/年
// 监控告警优化:15万/年
// 自动化运维:15万/年
return 600000; // 60万
}
/**
* 机会成本节约
*/
private double calculateOpportunityCostSaving() {
// 快速响应市场需求:100万/年
// 用户体验提升带来的收益:100万/年
return 2000000; // 200万
}
}2. 间接业务价值
业务增长贡献:
| 业务指标 | 改善前 | 改善后 | 业务价值 |
|---|---|---|---|
| 用户转化率 | 3.2% | 5.8% | 提升81%,年增收约500万 |
| 用户留存率 | 65% | 82% | 提升26%,减少获客成本300万 |
| 营销活动ROI | 1:3.5 | 1:6.2 | 提升77%,营销效果显著 |
| 客服工单量 | 1000/天 | 300/天 | 减少70%,节约客服成本 |
| 系统故障时长 | 8小时/月 | 1小时/月 | 减少87.5%,业务连续性保障 |
🔍 踩坑经验分享
技术选型踩坑
1. 消息队列选型教训
初期错误决策:
java
/**
* 消息队列选型踩坑记录
*/
public class MessageQueueLessonsLearned {
/**
* 踩坑1:盲目追求新技术
*
* 问题:最初选择了Pulsar,认为它是"下一代消息队列"
* 结果:
* - 社区生态不够成熟
* - 运维复杂度高
* - 团队学习成本大
* - 生产环境问题难以解决
*
* 教训:技术选型要考虑团队能力和生态成熟度
*/
public void lesson1_BlindlyPursuingNewTechnology() {
/*
* 错误的选择过程:
* 1. 只看技术文档和Benchmark
* 2. 忽略了团队技术栈
* 3. 没有充分的POC验证
* 4. 低估了运维复杂度
*
* 正确的做法:
* 1. 全面评估:性能、稳定性、生态、团队能力
* 2. 充分POC:模拟生产环境压测
* 3. 渐进式迁移:先在非核心业务试点
* 4. 制定回滚方案:确保可以快速回退
*/
}
/**
* 踩坑2:忽视运维复杂度
*
* 问题:选择了分布式架构但没有配套的运维体系
* 结果:
* - 故障定位困难
* - 性能调优复杂
* - 监控告警不完善
* - 扩容缩容操作复杂
*/
public void lesson2_IgnoringOperationalComplexity() {
/*
* 运维复杂度评估维度:
* 1. 部署复杂度:组件数量、依赖关系
* 2. 监控复杂度:指标数量、告警规则
* 3. 故障处理:定位难度、恢复时间
* 4. 扩展复杂度:水平扩展、垂直扩展
* 5. 升级复杂度:版本兼容性、数据迁移
*/
}
/**
* 踩坑3:过度设计
*
* 问题:一开始就设计了过于复杂的架构
* 结果:
* - 开发周期延长
* - 系统复杂度高
* - 维护成本增加
* - 性能反而下降
*/
public void lesson3_OverEngineering() {
/*
* 避免过度设计的原则:
* 1. 从简单开始:MVP优先
* 2. 渐进式演进:根据业务需求逐步优化
* 3. 性能驱动:有性能瓶颈再优化
* 4. 业务价值导向:技术服务于业务
*/
}
}2. 性能优化踩坑
性能调优血泪史:
java
/**
* 性能优化踩坑经验
*/
public class PerformanceOptimizationLessons {
/**
* 踩坑1:盲目优化
*
* 问题:没有性能基线就开始优化
* 结果:
* - 优化方向错误
* - 引入新的问题
* - 浪费大量时间
*/
public void lesson1_BlindOptimization() {
/*
* 正确的性能优化流程:
* 1. 建立性能基线
* 2. 识别性能瓶颈
* 3. 制定优化方案
* 4. 小范围验证
* 5. 全量上线
* 6. 持续监控
*/
}
/**
* 踩坑2:过早优化
*
* 问题:在业务量很小的时候就开始做复杂优化
* 结果:
* - 增加系统复杂度
* - 影响开发效率
* - 优化效果不明显
*/
public void lesson2_PrematureOptimization() {
/*
* 优化时机判断:
* 1. 有明确的性能问题
* 2. 业务量达到一定规模
* 3. 用户体验受到影响
* 4. 系统资源使用率过高
*/
}
/**
* 踩坑3:忽视监控
*
* 问题:优化后没有建立完善的监控体系
* 结果:
* - 性能回退无法及时发现
* - 新的瓶颈无法识别
* - 优化效果无法量化
*/
public void lesson3_IgnoringMonitoring() {
/*
* 监控体系建设:
* 1. 业务指标监控
* 2. 系统资源监控
* 3. 应用性能监控
* 4. 用户体验监控
* 5. 告警规则配置
*/
}
}架构设计踩坑
1. 分布式系统踩坑
分布式架构的坑:
java
/**
* 分布式系统踩坑总结
*/
public class DistributedSystemLessons {
/**
* 踩坑1:忽视网络分区
*
* 问题:没有考虑网络分区对系统的影响
* 结果:
* - 服务间调用失败
* - 数据一致性问题
* - 系统可用性下降
*/
public void lesson1_IgnoringNetworkPartition() {
/*
* 网络分区应对策略:
* 1. 服务降级:核心功能保障
* 2. 熔断机制:防止雪崩
* 3. 重试策略:指数退避
* 4. 超时设置:合理的超时时间
* 5. 监控告警:及时发现问题
*/
}
/**
* 踩坑2:数据一致性处理不当
*
* 问题:在分布式环境下追求强一致性
* 结果:
* - 系统性能下降
* - 可用性降低
* - 复杂度增加
*/
public void lesson2_DataConsistencyMishandling() {
/*
* 一致性策略选择:
* 1. 强一致性:金融交易等关键业务
* 2. 最终一致性:大部分业务场景
* 3. 弱一致性:对一致性要求不高的场景
*
* 实现方案:
* 1. 分布式事务:Saga、TCC
* 2. 事件驱动:Event Sourcing
* 3. 补偿机制:定时任务修复
*/
}
/**
* 踩坑3:服务拆分过细
*
* 问题:过度拆分微服务
* 结果:
* - 服务间调用复杂
* - 运维成本增加
* - 性能下降
* - 调试困难
*/
public void lesson3_OverSplittingServices() {
/*
* 服务拆分原则:
* 1. 业务边界清晰
* 2. 团队组织结构匹配
* 3. 数据访问模式
* 4. 技术栈差异
* 5. 扩展需求不同
*/
}
}2. 缓存使用踩坑
缓存设计的坑:
java
/**
* 缓存使用踩坑经验
*/
public class CachingLessonsLearned {
/**
* 踩坑1:缓存雪崩
*
* 问题:大量缓存同时失效
* 结果:
* - 数据库压力激增
* - 系统响应时间增加
* - 可能导致系统崩溃
*/
public void lesson1_CacheAvalanche() {
/*
* 解决方案:
* 1. 过期时间随机化
* 2. 缓存预热
* 3. 多级缓存
* 4. 熔断降级
*/
// 错误的做法:统一过期时间
// cache.put(key, value, 3600); // 所有缓存1小时后同时失效
// 正确的做法:随机过期时间
int randomTtl = 3600 + new Random().nextInt(600); // 3600-4200秒随机
cache.put(key, value, randomTtl);
}
/**
* 踩坑2:缓存穿透
*
* 问题:查询不存在的数据
* 结果:
* - 缓存无法命中
* - 每次都查询数据库
* - 数据库压力增加
*/
public void lesson2_CachePenetration() {
/*
* 解决方案:
* 1. 布隆过滤器
* 2. 缓存空值
* 3. 参数校验
*/
// 缓存空值解决方案
public Object getData(String key) {
Object value = cache.get(key);
if (value != null) {
return "NULL".equals(value) ? null : value;
}
value = database.get(key);
if (value != null) {
cache.put(key, value, 3600);
} else {
cache.put(key, "NULL", 300); // 缓存空值,较短过期时间
}
return value;
}
}
/**
* 踩坑3:缓存击穿
*
* 问题:热点数据缓存失效
* 结果:
* - 大量请求直接访问数据库
* - 数据库压力激增
*/
public void lesson3_CacheBreakdown() {
/*
* 解决方案:
* 1. 分布式锁
* 2. 异步刷新
* 3. 永不过期
*/
// 分布式锁解决方案
public Object getHotData(String key) {
Object value = cache.get(key);
if (value != null) {
return value;
}
String lockKey = "lock:" + key;
if (distributedLock.tryLock(lockKey, 10, TimeUnit.SECONDS)) {
try {
// 双重检查
value = cache.get(key);
if (value != null) {
return value;
}
// 从数据库加载
value = database.get(key);
cache.put(key, value, 3600);
return value;
} finally {
distributedLock.unlock(lockKey);
}
} else {
// 获取锁失败,返回旧数据或默认值
return getDefaultValue(key);
}
}
}
}运维部署踩坑
1. 容器化踩坑
Docker和K8s的坑:
yaml
# 踩坑1:资源限制设置不当
# 错误配置
resources:
limits:
memory: "512Mi" # 内存限制过小
cpu: "0.1" # CPU限制过小
requests:
memory: "1Gi" # 请求内存大于限制内存
cpu: "0.5" # 请求CPU大于限制CPU
# 正确配置
resources:
limits:
memory: "2Gi"
cpu: "1000m"
requests:
memory: "1Gi"
cpu: "500m"
---
# 踩坑2:健康检查配置不当
# 错误配置
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 10 # 启动延迟过短
periodSeconds: 5 # 检查频率过高
timeoutSeconds: 1 # 超时时间过短
failureThreshold: 1 # 失败阈值过低
# 正确配置
livenessProbe:
httpGet:
path: /actuator/health/liveness
port: 8080
initialDelaySeconds: 60 # 给应用足够启动时间
periodSeconds: 30 # 合理的检查频率
timeoutSeconds: 10 # 合理的超时时间
failureThreshold: 3 # 合理的失败阈值2. 监控告警踩坑
监控系统的坑:
java
/**
* 监控告警踩坑经验
*/
public class MonitoringLessonsLearned {
/**
* 踩坑1:告警风暴
*
* 问题:告警规则设置不当,产生大量无效告警
* 结果:
* - 重要告警被淹没
* - 团队疲于应对
* - 告警失去意义
*/
public void lesson1_AlertStorm() {
/*
* 解决方案:
* 1. 告警分级:Critical、Warning、Info
* 2. 告警聚合:相同类型告警合并
* 3. 告警抑制:依赖关系抑制
* 4. 告警频率限制:防止重复告警
* 5. 告警路由:不同级别发送给不同人
*/
}
/**
* 踩坑2:监控指标过多
*
* 问题:监控了太多不重要的指标
* 结果:
* - 存储成本增加
* - 查询性能下降
* - 重要指标被忽略
*/
public void lesson2_TooManyMetrics() {
/*
* 指标选择原则:
* 1. 业务关键指标:用户体验相关
* 2. 系统健康指标:可用性、性能
* 3. 资源使用指标:CPU、内存、磁盘
* 4. 错误率指标:异常、失败率
*
* 避免监控:
* 1. 无业务意义的指标
* 2. 变化频率过高的指标
* 3. 计算成本过高的指标
*/
}
/**
* 踩坑3:缺乏业务监控
*
* 问题:只监控技术指标,忽略业务指标
* 结果:
* - 业务问题发现滞后
* - 技术指标正常但业务异常
* - 无法评估业务影响
*/
public void lesson3_LackOfBusinessMonitoring() {
/*
* 业务监控指标:
* 1. 用户行为指标:登录、注册、购买
* 2. 业务流程指标:订单转化、支付成功率
* 3. 收入指标:GMV、ARPU
* 4. 用户体验指标:页面加载时间、错误率
*/
}
}🚀 未来规划与技术展望
技术演进规划
1. 智能化升级
AI驱动的消息中心:
java
/**
* 智能化消息中心规划
*/
@Service
public class IntelligentMessageCenterPlan {
/**
* 1. 智能内容生成
*
* 目标:基于用户画像和行为数据,自动生成个性化消息内容
* 技术栈:GPT、BERT、推荐算法
*/
public void intelligentContentGeneration() {
/*
* 实现计划:
* Phase 1: 模板智能推荐
* - 基于历史数据推荐最佳模板
* - A/B测试验证效果
*
* Phase 2: 内容智能优化
* - 自动优化文案表达
* - 智能选择发送时机
*
* Phase 3: 完全自动化
* - 端到端的智能消息生成
* - 实时效果反馈和优化
*/
}
/**
* 2. 智能路由决策
*
* 目标:基于用户偏好和通道效果,智能选择最佳发送通道
* 技术栈:机器学习、强化学习
*/
public void intelligentRouting() {
/*
* 决策因素:
* 1. 用户偏好:历史打开率、点击率
* 2. 通道效果:实时成功率、延迟
* 3. 成本考虑:不同通道的成本
* 4. 时间因素:用户活跃时间段
*
* 算法选择:
* 1. 多臂老虎机:探索与利用平衡
* 2. 深度强化学习:复杂决策场景
* 3. 集成学习:多模型融合
*/
}
/**
* 3. 预测性运维
*
* 目标:基于历史数据预测系统故障,提前进行运维操作
* 技术栈:时间序列分析、异常检测
*/
public void predictiveOperations() {
/*
* 预测场景:
* 1. 容量预测:提前扩容
* 2. 故障预测:提前修复
* 3. 性能预测:提前优化
* 4. 成本预测:预算规划
*
* 技术实现:
* 1. LSTM:时间序列预测
* 2. Isolation Forest:异常检测
* 3. Prophet:趋势预测
*/
}
}2. 云原生升级
全面云原生化:
yaml
# 云原生技术栈规划
apiVersion: v1
kind: ConfigMap
metadata:
name: cloud-native-roadmap
data:
phase1: |
容器化完善
- 多阶段构建优化
- 镜像安全扫描
- 镜像分层优化
phase2: |
服务网格
- Istio服务网格
- 流量管理
- 安全策略
- 可观测性
phase3: |
Serverless
- Knative部署
- 事件驱动架构
- 自动扩缩容
- 成本优化
phase4: |
边缘计算
- 边缘节点部署
- 就近消息推送
- 延迟优化
- 离线能力3. 多云部署
多云架构设计:
java
/**
* 多云部署策略
*/
@Configuration
public class MultiCloudDeploymentStrategy {
/**
* 多云部署目标
*/
public void multiCloudGoals() {
/*
* 1. 高可用性:避免单点故障
* 2. 成本优化:利用不同云厂商价格差异
* 3. 合规要求:数据本地化要求
* 4. 技术多样性:避免厂商锁定
*
* 部署策略:
* 1. 主备模式:主云+备云
* 2. 负载均衡:多云负载分担
* 3. 地域分布:就近服务
* 4. 专业化部署:不同云的优势服务
*/
}
/**
* 技术实现方案
*/
public void technicalImplementation() {
/*
* 1. 基础设施即代码
* - Terraform:多云资源管理
* - Ansible:配置管理
* - GitOps:声明式部署
*
* 2. 容器编排
* - Kubernetes:统一编排平台
* - Helm:应用包管理
* - ArgoCD:持续部署
*
* 3. 数据同步
* - 数据库复制:主从同步
* - 对象存储:跨云同步
* - 消息队列:跨云消息
*
* 4. 网络连接
* - VPN:安全连接
* - 专线:高速连接
* - CDN:内容分发
*/
}
}业务发展规划
1. 平台化发展
消息中心平台化:
java
/**
* 平台化发展规划
*/
@Service
public class PlatformDevelopmentPlan {
/**
* 平台化目标
*/
public void platformGoals() {
/*
* 1. 多租户支持
* - 租户隔离:数据、资源隔离
* - 配置管理:租户级配置
* - 计费系统:按使用量计费
*
* 2. 开放API
* - RESTful API:标准化接口
* - GraphQL:灵活查询
* - Webhook:事件通知
* - SDK:多语言支持
*
* 3. 生态建设
* - 插件市场:第三方插件
* - 开发者社区:文档、示例
* - 合作伙伴:集成方案
*/
}
/**
* 商业模式
*/
public void businessModel() {
/*
* 1. SaaS模式
* - 按量付费:消息条数计费
* - 包月套餐:固定费用
* - 企业版:定制化服务
*
* 2. 私有化部署
* - 软件授权:一次性费用
* - 技术支持:年度服务费
* - 定制开发:项目制收费
*
* 3. 混合模式
* - 公有云+私有云
* - 标准版+定制版
* - 自助服务+专业服务
*/
}
}2. 生态扩展
构建消息生态:
java
/**
* 生态扩展计划
*/
@Component
public class EcosystemExpansionPlan {
/**
* 上游生态
*/
public void upstreamEcosystem() {
/*
* 1. 数据源集成
* - CRM系统:客户数据
* - 业务系统:事件触发
* - 数据仓库:分析数据
* - 第三方API:外部数据
*
* 2. 触发器扩展
* - 时间触发:定时任务
* - 事件触发:业务事件
* - 条件触发:规则引擎
* - 手动触发:运营操作
*/
}
/**
* 下游生态
*/
public void downstreamEcosystem() {
/*
* 1. 通道扩展
* - 新兴通道:抖音、快手
* - 国际通道:WhatsApp、Telegram
* - IoT通道:智能设备
* - 线下通道:门店、广告屏
*
* 2. 效果分析
* - 数据分析:BI工具集成
* - 效果追踪:转化分析
* - 用户画像:标签系统
* - 智能推荐:个性化引擎
*/
}
/**
* 横向生态
*/
public void horizontalEcosystem() {
/*
* 1. 营销工具
* - 活动管理:营销活动
* - 用户分群:精准营销
* - A/B测试:效果对比
* - 自动化营销:营销流程
*
* 2. 客服系统
* - 工单系统:问题处理
* - 知识库:自助服务
* - 智能客服:AI助手
* - 质检系统:服务质量
*/
}
}💡 架构设计心得总结
设计原则总结
1. 架构设计哲学
java
/**
* 架构设计哲学总结
*/
public class ArchitecturePhilosophy {
/**
* 1. 简单性原则
*
* "简单是可靠性的前提"
*/
public void simplicityPrinciple() {
/*
* 实践要点:
* 1. 从简单开始:MVP优先
* 2. 渐进式演进:小步快跑
* 3. 避免过度设计:YAGNI原则
* 4. 保持代码简洁:可读性优先
*
* 反面案例:
* - 一开始就设计复杂架构
* - 使用过于复杂的技术栈
* - 过度抽象和封装
*/
}
/**
* 2. 可扩展性原则
*
* "设计要为未来留有余地"
*/
public void scalabilityPrinciple() {
/*
* 设计考虑:
* 1. 水平扩展:无状态设计
* 2. 垂直扩展:资源可调整
* 3. 功能扩展:插件化架构
* 4. 数据扩展:分库分表
*
* 实现策略:
* - 微服务架构
* - 消息队列解耦
* - 缓存分层
* - 数据库读写分离
*/
}
/**
* 3. 可靠性原则
*
* "系统要能够优雅地处理故障"
*/
public void reliabilityPrinciple() {
/*
* 可靠性保障:
* 1. 故障隔离:舱壁模式
* 2. 快速恢复:自动重启
* 3. 优雅降级:核心功能保障
* 4. 监控告警:及时发现问题
*
* 技术手段:
* - 熔断器模式
* - 重试机制
* - 超时控制
* - 健康检查
*/
}
/**
* 4. 性能优先原则
*
* "用户体验是第一位的"
*/
public void performanceFirstPrinciple() {
/*
* 性能优化策略:
* 1. 缓存优先:多级缓存
* 2. 异步处理:非阻塞IO
* 3. 批量操作:减少网络开销
* 4. 连接复用:连接池管理
*
* 性能监控:
* - 响应时间监控
* - 吞吐量监控
* - 资源使用监控
* - 用户体验监控
*/
}
}2. 技术选型心得
java
/**
* 技术选型经验总结
*/
public class TechnologySelectionExperience {
/**
* 选型决策框架
*/
public void selectionFramework() {
/*
* 评估维度:
* 1. 技术成熟度(30%)
* - 社区活跃度
* - 版本稳定性
* - 文档完善度
* - 案例丰富度
*
* 2. 团队匹配度(25%)
* - 学习成本
* - 技能匹配
* - 培训难度
* - 招聘难度
*
* 3. 业务适配度(25%)
* - 功能匹配
* - 性能要求
* - 扩展需求
* - 安全要求
*
* 4. 运维复杂度(20%)
* - 部署复杂度
* - 监控难度
* - 故障处理
* - 升级维护
*/
}
/**
* 选型误区
*/
public void selectionMistakes() {
/*
* 常见误区:
* 1. 技术驱动:为了技术而技术
* 2. 盲目跟风:追求最新技术
* 3. 完美主义:追求完美方案
* 4. 经验主义:只用熟悉技术
*
* 正确做法:
* 1. 业务驱动:技术服务业务
* 2. 稳定优先:成熟技术优先
* 3. 适合最好:没有银弹
* 4. 持续学习:拥抱新技术
*/
}
}团队协作心得
1. 开发流程优化
java
/**
* 开发流程优化经验
*/
public class DevelopmentProcessOptimization {
/**
* 敏捷开发实践
*/
public void agileDevPractice() {
/*
* 实践要点:
* 1. 短迭代周期:2周一个迭代
* 2. 持续集成:每次提交都构建
* 3. 持续部署:自动化部署
* 4. 快速反馈:及时发现问题
*
* 工具链:
* - Git:版本控制
* - Jenkins:CI/CD
* - SonarQube:代码质量
* - Jira:项目管理
*/
}
/**
* 代码质量保障
*/
public void codeQualityAssurance() {
/*
* 质量保障措施:
* 1. 代码规范:统一编码标准
* 2. 代码审查:Peer Review
* 3. 单元测试:测试覆盖率>80%
* 4. 集成测试:端到端测试
*
* 自动化检查:
* - 静态代码分析
* - 安全漏洞扫描
* - 依赖版本检查
* - 性能基准测试
*/
}
/**
* 文档管理
*/
public void documentationManagement() {
/*
* 文档体系:
* 1. 架构文档:系统设计
* 2. API文档:接口说明
* 3. 运维文档:部署运维
* 4. 用户文档:使用指南
*
* 文档原则:
* - 及时更新:代码变更同步更新
* - 简洁明了:重点突出
* - 版本管理:文档版本化
* - 易于查找:分类清晰
*/
}
}📝 全系列总结
通过这5篇系列文章,我们完整地展现了企业级消息中心从0到1的设计与实现过程:
🎯 系列文章价值
- 架构设计篇:奠定了设计哲学和技术基础
- 核心实现篇:深入解析了关键技术实现
- 存储与可靠性篇:保障了系统的稳定性和数据安全
- 运维与扩展篇:确保了系统的可运维性和可扩展性
- 实战总结篇:分享了宝贵的实战经验和未来规划
🚀 核心技术亮点
- 高性能架构:10万+TPS的处理能力
- 高可用设计:99.95%的系统可用性
- 智能化特性:AI驱动的内容生成和路由决策
- 云原生架构:容器化部署和微服务治理
- 完善监控:全链路监控和智能告警
💡 实战经验价值
- 踩坑经验:避免常见的技术陷阱
- 最佳实践:经过生产验证的解决方案
- 性能优化:系统性的性能调优方法
- 运维经验:自动化运维和故障处理
- 团队协作:高效的开发流程和质量保障
🤝 技术交流
如果您对消息中心的设计实现有任何疑问,或者在实际项目中遇到类似问题,欢迎交流讨论.
💡 写在最后:技术的价值在于解决实际问题,架构的意义在于支撑业务发展。希望这个系列文章能够为您的技术实践提供有价值的参考和启发。
让我们一起构建更好的技术世界! 🌟
版权声明:本系列文章基于真实项目经验编写,欢迎学习交流,转载请注明出处。