在沉寂了半年之后,智谱推出了新一代开源模型GLM-4.5系列,采用MOE架构并使用混合推理模式。模型统一提升了在推理、代码与智能体等多方面的能力,专为复杂智能体应用打造。由于官方的技术报告暂未发布,模型细节暂时无从得知,本文内容仅做导读,方便读者对该系列模型有个初步认识。
技术架构
参数
GLM-4.5系列包含两个主要模型,均采用MoE架构:
● GLM-4.5:355B总参数,32B激活参数
● GLM-4.5-Air:106B总参数,12B激活参数
混合推理模式
GLM-4.5的一个突出特性是其混合推理能力,提供两种不同的工作模式:
● 思考模式(Thinking Mode):用于复杂推理和工具使用场景
● 非思考模式(Non-thinking Mode):提供即时响应
训练过程
模型架构与预训练
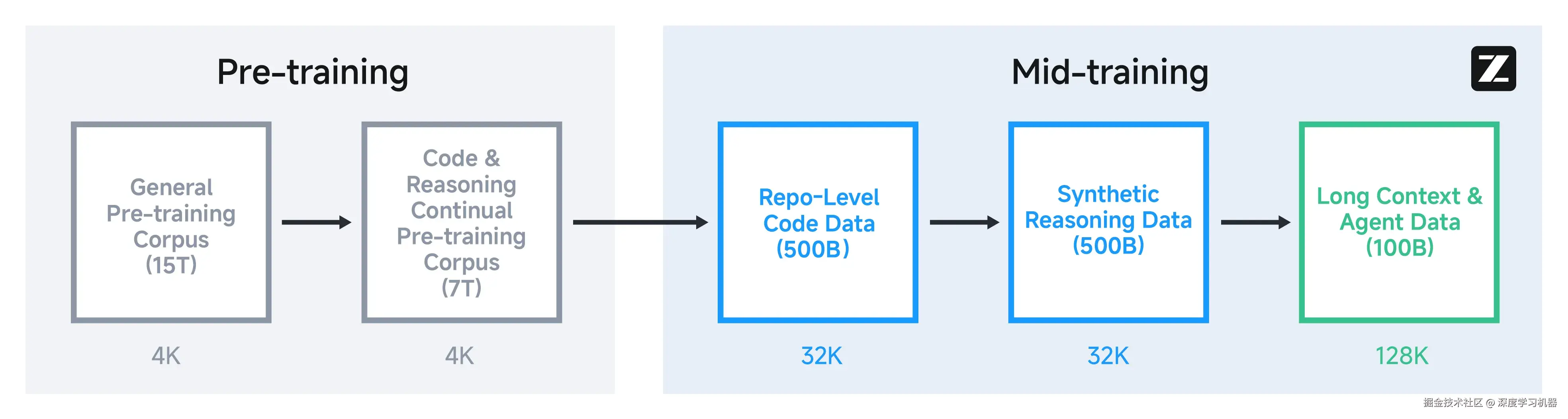
GLM-4.5系列模型采用了MoE架构,并且在MoE层中使用了无损的负载均衡路由以及sigmoid门控机制。相比DeepSeek-V3和Kimi K2降低了模型的宽度,改为增加了模型的深度。在自注意力模块中,使用了GQA并引入了部分旋转位置编码。优化器则使用了Muon优化器,加快了收敛速度并支持更大的批量大小。同时引入了QK-Norm,用于保持注意力logits的稳定。此外,GLM-4.5系列模型均加入了 MTP层,以支持推理阶段的推测解码。 基础模型经历了多个训练阶段。在预训练期间,模型首先在15万亿tokens的通用语料库上进行训练,随后又在7万亿tokens 的代码与推理语料库上进一步训练。在预训练之后,引入了额外的阶段以进一步提升模型在关键下游任务上的性能。不同于此前基于大规模通用文档的预训练,这些阶段使用的是中等规模的领域特定数据集,包括指令类数据。
基于强化学习的后训练
后训练阶段对于大语言模型而言至关重要,它通过模型自身生成的探索式经验不断优化其策略。强化学习是推动模型能力极限的重要步骤。GLM-4.5整合了来自 GLM-4-0414的通用能力和来自 GLM-Z1的推理能力,还特别增强了模型的智能体能力,包括智能体编程、深度搜索和通用工具使用能力。这一过程首先是对精选的推理数据和合成智能体场景进行监督微调,接着进入强化学习阶段以分别培养对应的专家模型。
● 推理方面:在完整的64K上下文中进行的一阶段RL训练,结合基于难度的课程学习策略,这种方式优于传统的逐步调度方法。为了提升训练稳定性,引入了动态采样温度机制以平衡探索与利用,以及在STEM问题上的自适应剪裁策略以实现更稳健的策略更新。
● 智能体任务方面:选取了两个可验证任务:基于信息检索的问答与软件工程任务。使用可扩展的策略来自动构造基于搜索的问答样本,方法包括引入人工协助的网页内容抽取与选择性遮蔽。代码任务则依赖实际软件工程任务中的执行反馈来驱动训练。
虽然强化学习主要集中在少量可验证任务上,但所获得的能力可以迁移至其他相关领域,如通用工具使用。随后通过专家蒸馏整合这些专长技能,使 GLM-4.5 在各项任务中具备全面而强大的能力。
榜单评测
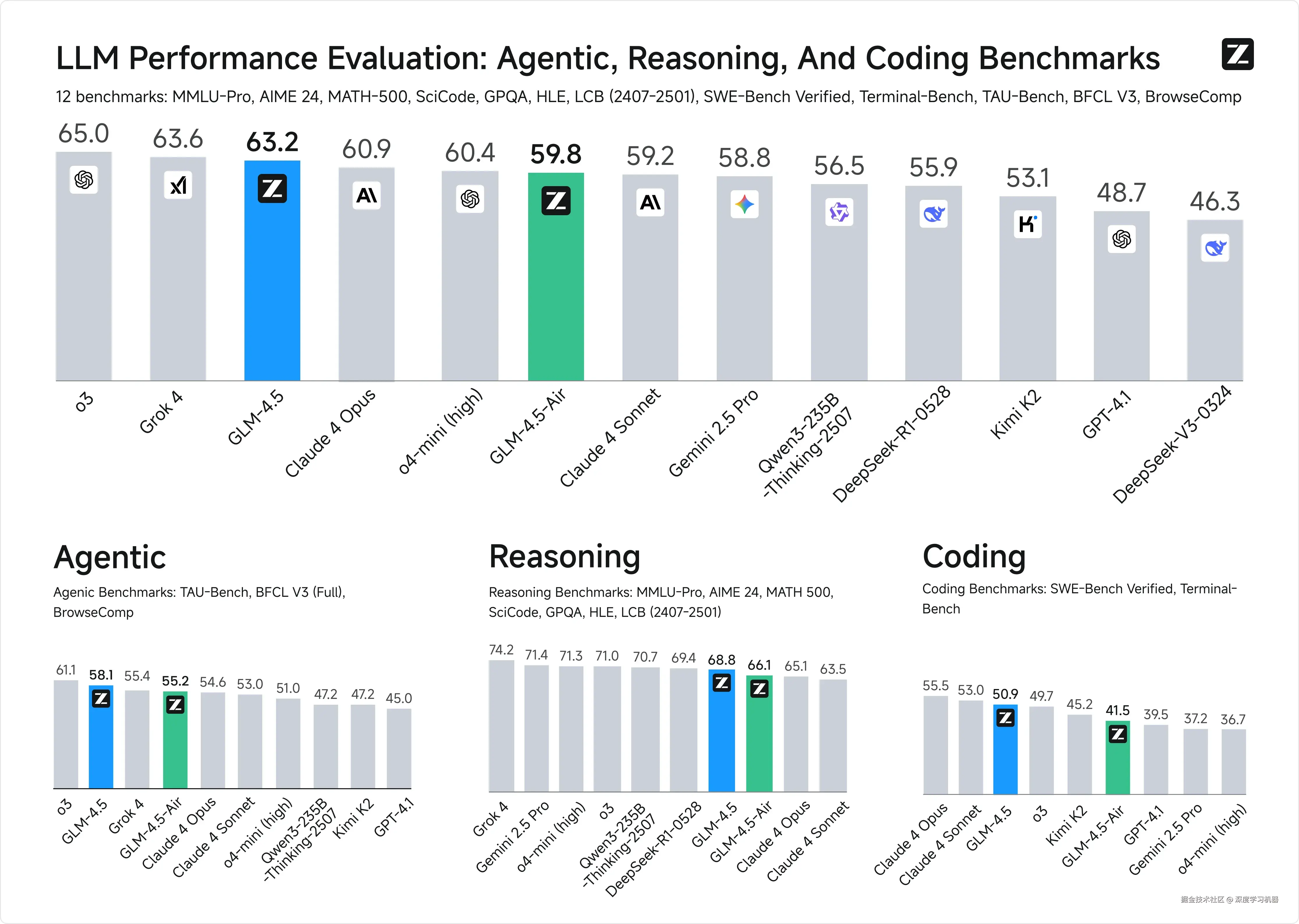
在12项行业标准基准测试中,GLM-4.5取得了63.2分的综合成绩,在所有专有和开源模型中排名第三,仅次于o3和Grok-4。
● 代码生成能力:在代码生成领域,GLM-4.5相对于Kimi K2取得了53.9%的胜率,对Qwen3-Coder达到了80.8%的成功率。
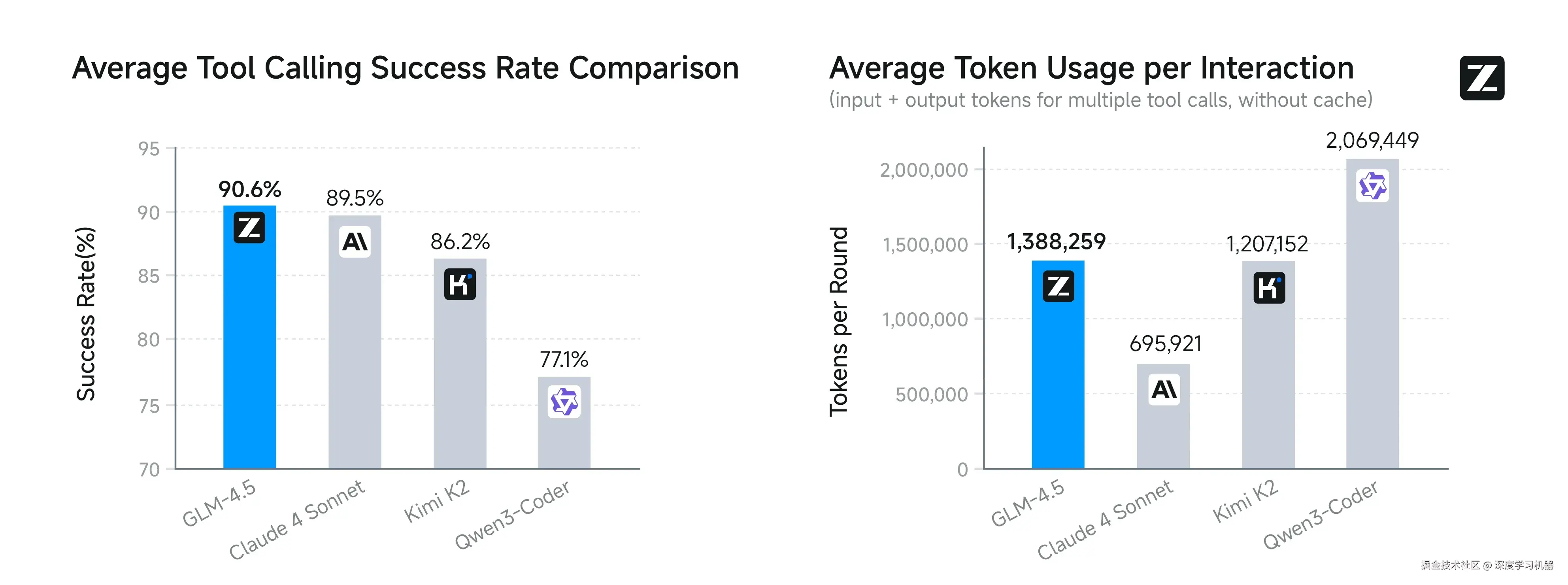
● 智能体任务表现:在Agent任务中,在工具调用成功率方面,GLM-4.5达到了90.6%的最高平均成功率,超越了Claude-4-Sonnet(89.5%)、Kimi-K2(86.2%)和Qwen3-Coder(77.1%)。
● 网络浏览能力:在BrowseComp基准测试中,GLM-4.5在网络浏览任务中取得了26.4%的正确率,超越了Claude-4-Opus的18.8%,接近o4-mini-high的28.3%。
真实数据
为了在真实场景中评估 GLM-4.5 的智能体式编程能力 ,智谱构建了 CC-Bench 测试集------以 Claude Code 作为智能体编程测试平台,对 GLM-4.5、Claude-4-Sonnet、Kimi-K2 和 Qwen3-Coder 四个模型进行了全面测试。测试涵盖 52 个精心设计的编码任务,覆盖多个开发领域。该数据集包含了这四个模型在全部 52 项任务中的完整智能体交互轨迹。 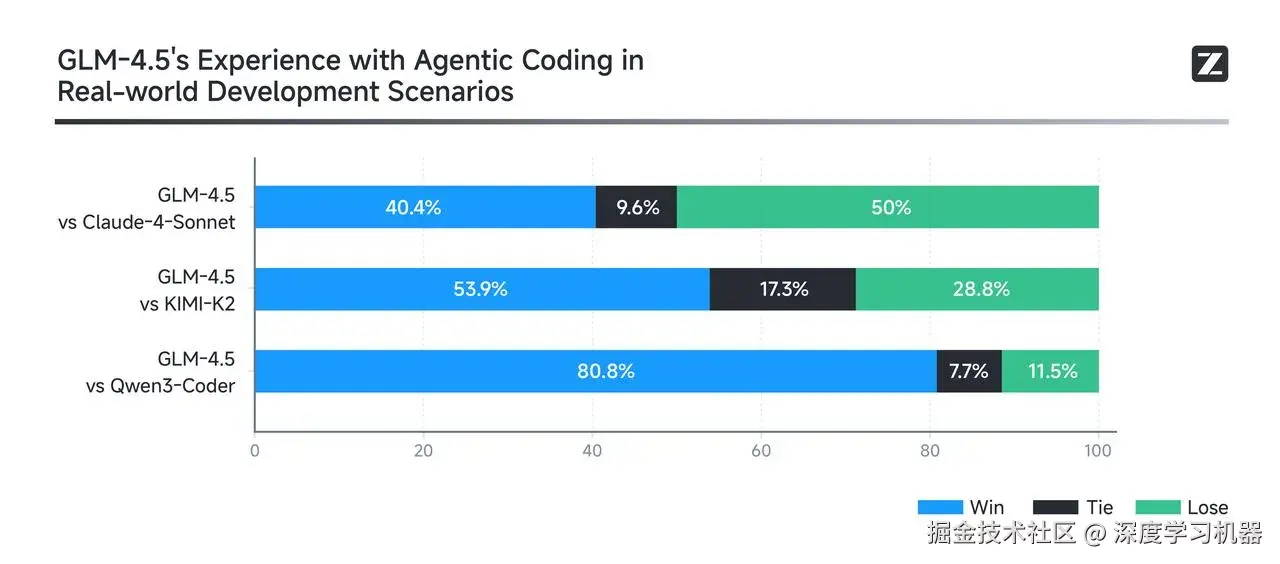
测试数据集
评估数据集分为6大类别,包含52个编码任务:
| 类别 | 描述 | 数量 | 任务ID |
|---|---|---|---|
| 前端开发 | 使用 HTML5、CSS3、JavaScript 构建轻量级前端游戏和工具 | 7 | 1-7 |
| 应用开发 | 使用 React、Node.js、Next.js、TypeScript、Go、iOS 开发管理系统、聊天系统、工具和移动应用 | 15 | 8-22 |
| UI/UX 优化 | 界面样式设计、用户体验优化、布局改进 | 13 | 23-35 |
| 构建与部署 | 项目构建、测试、部署相关问题解决 | 4 | 36-39 |
| 数据分析 | 数据处理、统计分析、可视化 | 5 | 40-44 |
| 机器学习 | 聚类、语音分析、图像处理、图像识别等 | 8 | 45-52 |
评估方法
环境设置
● 隔离测试环境:每个任务运行在一个独立的容器中,使用独立环境,并拉取对应代码分支,确保无干扰。
● 模型配置:Claude Code在任务目录中启动,各模型的base_url和api_key已正确配置。
多轮交互测试流程
-
初始提示:评估员输入预定义的任务提示,启动问题求解。
-
迭代交互:根据模型的中间输出,评估员与模型进行多轮对话,逐步调整输入以推动问题解决。
-
公平性保障:每个任务均由同一评估员完成,对所有模型采用一致的交互策略,确保公平。
评分与判定标准
● 主要标准 ------ 任务完成度:基于预定义的完成标准进行量化评分,判断 GLM-4.5 与对比模型之间的胜负或平局。
● 次要标准 ------ 效率与可靠性:若任务完成度相同,则工具调用成功率更高或token消耗更少的模型视为胜者。
● 最终评估原则:优先考虑功能正确性和任务完成情况,而非效率指标,确保编程能力为核心评估重点。
整体性能表现
在一对一的直接对比中:
| 对比对象 | GLM-4.5 胜率 | 平局率 | 败率 |
|---|---|---|---|
| vs Claude-4-Sonnet | 40.4% | 9.6% | 50.0% |
| vs Kimi-K2 | 53.9% | 17.3% | 28.8% |
| vs Qwen3-Coder | 80.8% | 7.7% | 11.5% |
GLM-4.5 的平均工具调用成功率达到 90.6%,高于 Claude-4-Sonnet(89.5%)、Kimi-K2(86.2%)、和 Qwen3-Coder(77.1%),表现出在智能体编程任务中更优的稳定性与效率。 GLM-4.5相比Claude-4-Sonnet仍有提升空间,在大部分场景中可以实现平替的效果。
开发者使用
GLM-4.5 API兼容多种AI编程工具,可以与Claude Code、Gemini CLI、Cline等工具搭配使用。以下仅以Claude Code作为演示,其余工具的配置过程大同小异。
-
获取API密钥 请访问
Z.AI官方网站,获取您的API密钥。 -
配置环境变量 安装Claude Code后,可通过以下两种方式之一配置环境变量:
方法一:使用脚本配置(首次用户推荐)
bash
curl -O "http://bigmodel-us3-prod-marketplace.cn-wlcb.ufileos.com/1753683755292-30b3431f487b4cc1863e57a81d78e289.sh?ufileattname=claude_code_prod_zai.sh"方法二:手动配置
bash
export ANTHROPIC_BASE_URL=https://api.z.ai/api/anthropic
export ANTHROPIC_AUTH_TOKEN={YOUR_API_KEY}- 开始使用
如果系统提示"是否要使用此 API 密钥?",选择"是"。
启动后,按如下所示授权 Claude Code 访问您当前文件夹中的文件,即可正常使用。 
结论
更强的性能,更少的参数
GLM-4.5参数量仅为DeepSeek-R1 的 1/2、Kimi-K2的1/3,但参数效率更高,性能更强 。在 SWE-Bench Verified 等图谱中,GLM-4.5 系列位于性能/参数比帕累托前沿 ,这表明在相同规模下,GLM-4.5 系列实现了最佳性能。 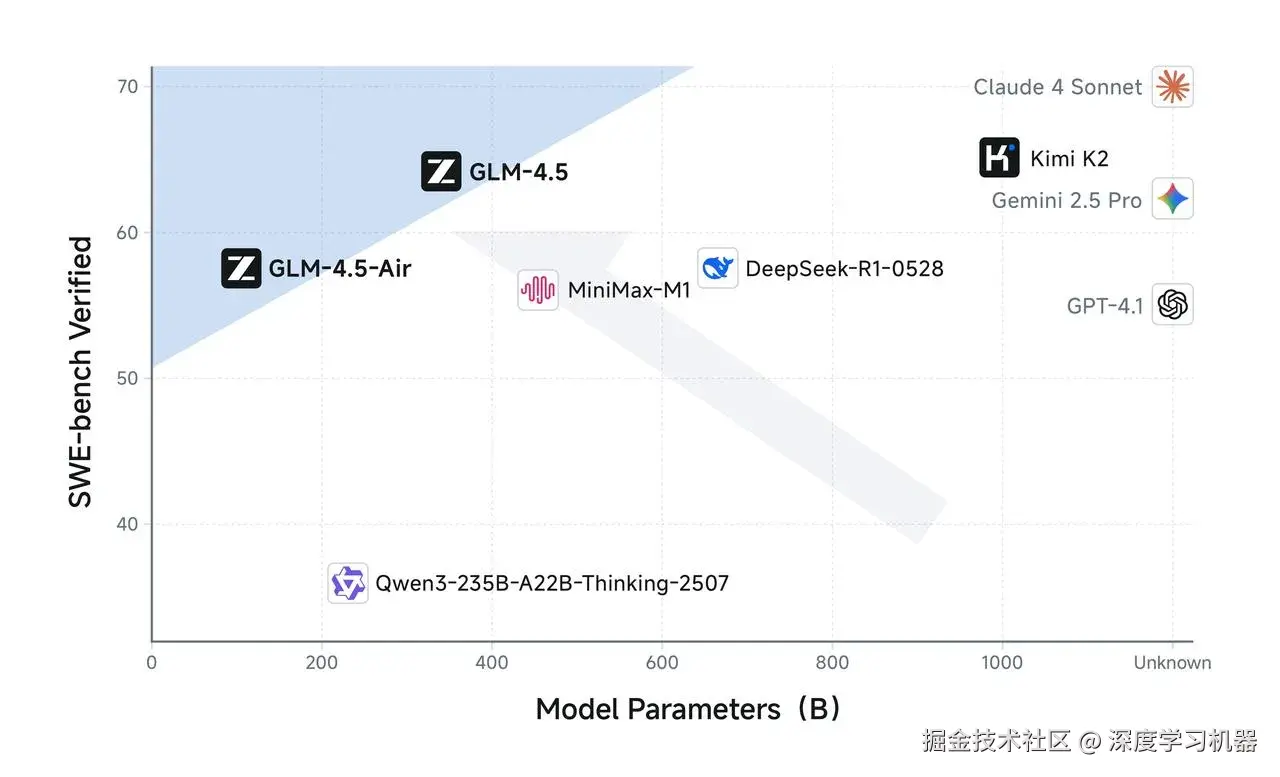
更低的成本、更高的速度
得益于参数量的减少与效率的提升,API调用价格最低可达到输入0.8元/百万 tokens,输出2元/百万tokens 。 
参考内容
● Huggingface : huggingface.co/zai-org/GLM...
● CC-Bench数据集 :huggingface.co/datasets/za...
● 官方blog :z.ai/blog/glm-4....
● Github :github.com/zai-org/GLM...