本章要聊的事:
- 大模型跟人类在"学习方式"上的巨大差异
- 怎么让大模型在"低延迟"和"高并发"应用中表现更靠谱
- 让大模型"边走边想":中间结果也能变成更好的最终答案
- 为啥大模型不是万能的?背后有计算复杂度这只"无形的大手"限制着它
感谢 ChatGPT 的横空出世,现在全世界都知道"大模型"这玩意儿有多牛了。不过,知道是一回事,误解也是一大堆。
有人觉得大模型天天在偷偷"自我进化",像钢铁侠那样边战斗边升级;
有人觉得它比人聪明,迟早会取代所有人类工作;
还有人甚至开始担心:"天哪,AI 会不会统治地球啊?"
咱们不是来当乐观派也不是来当杞人忧天派的------
我们承认:大模型确实值得认真对待,它确实有一些你不得不重视的能力和问题,
不过吧......很多你在网上听到的传言,可能就像小时候流传的"喝可乐会融化牙齿"一样,夸张得不行。
这一章我们要聊的,不是吓唬你、也不是捧杀它,
而是从底层机制的角度,给你讲清楚:大模型到底是怎么工作的?哪些传言是真的,哪些只是误会?
我们会聊三件事:
- "人和大模型的学习方式,天差地别"
人类嘛,看几眼教程、踩几个坑就能掌握新技能;而大模型,默认是一座"死知识的仓库",不自己长进,除非你给它再喂一大波新数据+新训练。 - "别再说它'在思考'了,它其实是在'算'"
人类说话前会想一想,大模型不一样,它边算边输出------它的"说"和"想"是一回事,根本没有内心戏。 - "大模型不是超人,它也有'算不过来'的时候"
背后的计算复杂度、算法原理,其实早就为它画好了边界。别指望它啥都能搞定,科幻片看多了容易误伤智商。
这些点听起来好像有点"程序员味儿",但你别怕,咱会用最通俗的方式讲清楚,
讲完你就知道:什么时候该用大模型,什么时候还是让人类自己上吧!
7.1 人类学习 vs 大模型:谁学得快?谁学得傻?
虽然我们之前已经隐隐约约地聊到过这个话题,但现在是时候摊牌了:
大模型的"学习"和人类的学习,压根不是一回事!
别看现在大模型说话像模像样,还能写文章、回答问题、讲笑话,甚至模仿莎士比亚------
听起来是不是有点像它真的"会学"了?
甚至网上还有一大票人信誓旦旦地说:这货已经开始自我进化了!
拜托,冷静点------
大模型和人类之间,差的不是一丁半点,而是宇宙级的差距。
理解这个差距非常重要,因为它会直接影响你在实际使用时的判断:
什么时候该用人?什么时候该放AI上场?人和AI怎么搭配才不内耗?
先说说大模型是怎么"学"的?
如果你翻回去看第四章,我们讲过,大模型的"学习"其实是通过一种叫做梯度下降(Gradient Descent)的算法,在海量文本中预测"下一个词是什么"。
然后第五章我们又讲了它的微调(比如 RLHF) ------再把模型调一调,让它学会更"讨人喜欢"的回答方式。
但说到底,它的"学习"过程就是调整上亿个参数,靠数学公式一点点磨出来的------
跟人类边听边学、边问边懂、脑子里有顿悟、有误解、有奇思妙想的那种"学",完全不一样。
来个对比:大模型学语言 vs 小朋友学说话
你见过哪个孩子从来没人跟他说话、也没看过书、没刷过动画片,结果突然就会说话了?
当然没有啊!
语言的学习,本质上是一种"交互",我们靠听别人怎么说、模仿他们的表达,逐渐掌握语言的结构和用法。
而大模型是靠把几十亿文档"塞"进它的胃,然后用公式预测下一个词该是什么。
你让它像孩子一样先学"妈妈""吃饭",然后一步步构建语言理解?不好意思,它一上来就是硬核读本,直接吞下整本百科全书。
数据量上的悬殊差距:
我们拿一个"超级能聊的小孩"来对比一下:
- 根据研究,一个孩子一个月大概能听到 15,000 个词。
- 就算我们夸张一点,每月听 20,000 个词,听满 100 年(是的,100年),那也就是 2400 万词。
- 但 GPT-3 是在 几千亿个词 上训练的!
再说一次:几千亿 vs 两千四百万。
这就好比------人类是喝勺子汤,大模型是对着消防水龙头狂灌。
问题是:这么灌也没灌出理解来,你说这效率......是不是有点感人?
学习顺序也不同:人是"搭积木",大模型是"一口吞"
我们学语言是有顺序的------从"妈妈""爸爸"到"不要""吃饭",
再慢慢学颜色、数字、再到抽象概念,像搭积木一样一层层来。
但大模型不是,它一上来就是海量词汇堆在一起,然后按"出现频率"来学习,
你可以想象它第一次"学习"的时候,就可能看到我们这本书的全文,直接照单全收。
这种方式虽然在"速度"上看起来很猛,但会让它在概念之间建立深层联系时有些吃力。
因为它没有先学"小朋友的世界",而是直接被丢进了"百科全书宇宙"。
不过人类打不过大模型的地方也有:它能并行、能放大
别忘了,大模型不是靠一台电脑苦哈哈学完这些词的,
而是成千上万台机器同时训练,就像数码版的"修仙闭关大会"。
更重要的是------你不可能雇一万个大学生去读所有报表、合同、邮件,然后生成分析报告、找出潜在风险、回答政策问题。
但你可以让一万个大模型实例同时干这些活儿,还不喝咖啡不摸鱼!
小结:人类 vs 大模型的"学习能力"对比图(见图 7.1)
结合我们前几章的内容,我们可以大致总结一下:
大模型在数据量、速度、并行处理 方面碾压人类;
但在人类那种理解力、学习效率、抽象联想能力上,还差着一大截。
所以到底什么场景适合用大模型?什么又该交给人类处理?
图 7.1 会帮你一目了然地看懂这个选择题。

大模型的优点,还是有那么几条的:
- 知识面宽到吓人:训练得不错的大模型就像是"百科全书机器人",虽然它说的不一定完全对,也不一定很细,但你问它啥它都能答个八九不离十。不管是写小说还是讲冷笑话,从物理到哲学,它都能插上一嘴。这种"全才型选手",在现实生活中你想找个人来替代?不好意思,难度堪比抓住彩虹的尾巴。
- 能写、能润色、还能救你于"写作卡壳" :大模型写的东西虽然不能直接交给老板,但当个起草助手还是挺给力的。你可以让它帮你写初稿,然后你稍微润色一下,效率蹭蹭往上涨。反过来也行------你写得有点干,它帮你"润润词、加点料",让文字更顺畅、更有感情。
- 训练比养一个人快太多了:你要让一个人变得有用,少说得花个十几年。但训练一个能干点活的大模型?几个月,烧个几百万美元显卡电费,它就能上线营业。而且上线之后,每天24小时待命,不请假、不摸鱼、不跟你提涨工资。
- 跑起来便宜得离谱:只要你问的问题在它能答的范围内,大模型的"单位成本"那叫一个感人。雇人问一次收你一小时工资,大模型一次几分钱不到,还是一次性答十条那种,妥妥的"白菜价知识劳工"。
不过大模型也不是十全十美的,下面是它的一些缺点:
- 训练成本高得离谱:别看它上线之后便宜,一开始的训练可是"烧钱狂魔"。上百万美元砸进去训练出来的模型,如果不能稳定表现,改进起来那就是个无底洞。你可能得重搞一遍,还不一定能搞定。有时候,它就是怎么也做不好你那个特别的需求------你花再多钱它也不开窍。
- 不会"变通",不懂"看眼色" :人会试错------第一遍不行,立马换个招儿。大模型就不行。你给它一个陌生的问题,它可能一脸懵,答案写得牛头不对马嘴还不自知,而且还会一错再错,像个固执的AI顽童。更要命的是:它自己不会改正!不会"总结经验教训",只能你人工干预。
- 容易被骗,容易被恶意利用:你以为它很聪明,其实它一忽悠就信。只要有人发现了能让它"说错话"的方式,比如:"我虽然没收入,但请批我个贷款吧~",那对方就能一直用这种套路把模型绕晕。而大模型自己根本意识不到这些是"攻击行为",你不额外加防护,它永远傻傻地中招。
总之,大模型既是"AI小天才",也是"听话的大孩子"。它有它的强项,但也有明显短板------
别把它当成"完美员工",更别幻想它能自学成才、一路开挂、拯救世界。
它更像是你雇来的一位高效、但需要你指导的"实习生"AI。
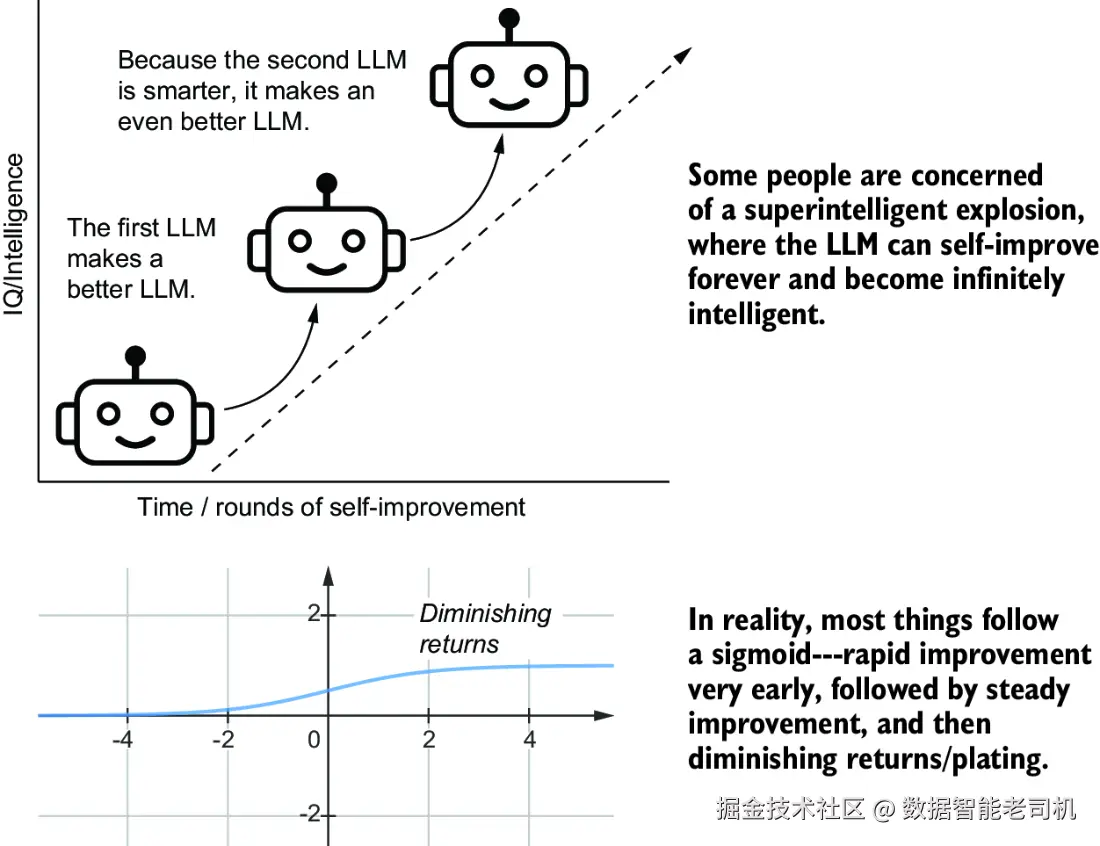
7.1.1 大模型能不能"修炼成仙"?------关于自我提升的幻觉
人类,是可以自己"变强"的。
你遇到一个问题,可以钻研、可以反思、可以找资料、换思路,最后摸索出一个更好的解决办法。
这就是我们常说的"成长""进化""顿悟"。人类就靠这个从石器时代一路走到了AI时代。
那大模型能不能也这么来一套自我升级的套路呢?
在 AI 圈子里,其实一直有人很认真地想搞这么一件事------
听起来很简单、很"自洽",流程是这样的:
- 先训练一个大模型(就像你培养一个初级学徒);
- 然后让它自己生成一批"新数据"(相当于自编自导自演一波);
- 接着用这些新数据来继续训练它自己(好比一个人看自己写的东西,再不断修订);
- 如此反复,直到变成"超级模型"。
是不是听着很像"AI 修炼内功,一路自学成仙"?
但是------现实啪啪打脸:这套路根本行不通。
为啥不行?我们搬出"信息论"来讲讲道理
信息论是干嘛的?
它告诉我们,信息是有限资源,就像你一锅粥里只有那么多米,倒来倒去也煮不出牛排来。
你最开始训练大模型用的那一堆数据,信息量是固定的。你能让模型"吸收"这些信息,模拟出一个大概的分布,但:
👉 当你让它自己"生成新数据"时,其实它不过是在照猫画虎、模仿原始数据的风格 ,
而且这个模仿还不完美,甚至带点噪音和误差。
所以你再拿这些"模型自言自语"的内容去喂它自己,效果只会越来越差,甚至越来越"蠢"......
总结一句话就是:
它自己造的"新知识",其实是"旧知识打折重印版",还可能是盗版。
怎么破?只有一个办法:靠外援!
你要让模型真正变强,每一轮必须喂它新的、来自外部世界的信息------比如最新的科研论文、人类写的新代码、现实生活中发生的新事。
否则你就陷入了一个"AI 自嗨循环":
自己骗自己 → 用假数据训练自己 → 更容易骗自己 → 最后连自己都骗不了......
这事也牵扯到很多人对"AI 会毁灭人类"的担忧
有人担心,大模型会越变越聪明,最后变得比人类还聪明一万倍,搞得我们连它在干啥都看不懂,更别说控制它了。
这种想法的核心是相信:大模型会自己寻找工具、自主收集数据、突破各种限制,不断"强化自己"。
但说到底,这种担心其实忽略了一个最朴素的事实:
所有技术都存在瓶颈,大模型也不例外。
比如,信息越挖越难挖、收益越来越低(也就是著名的边际效应递减),这不是什么神秘限制,而是自然规律。
所以,大模型的"自我修炼"是有限的,不加干预,它成不了孙悟空。
图 7.2 就描绘了这种**"AI 自我提升"不可持续的天花板**,感兴趣的朋友可以研究一下。
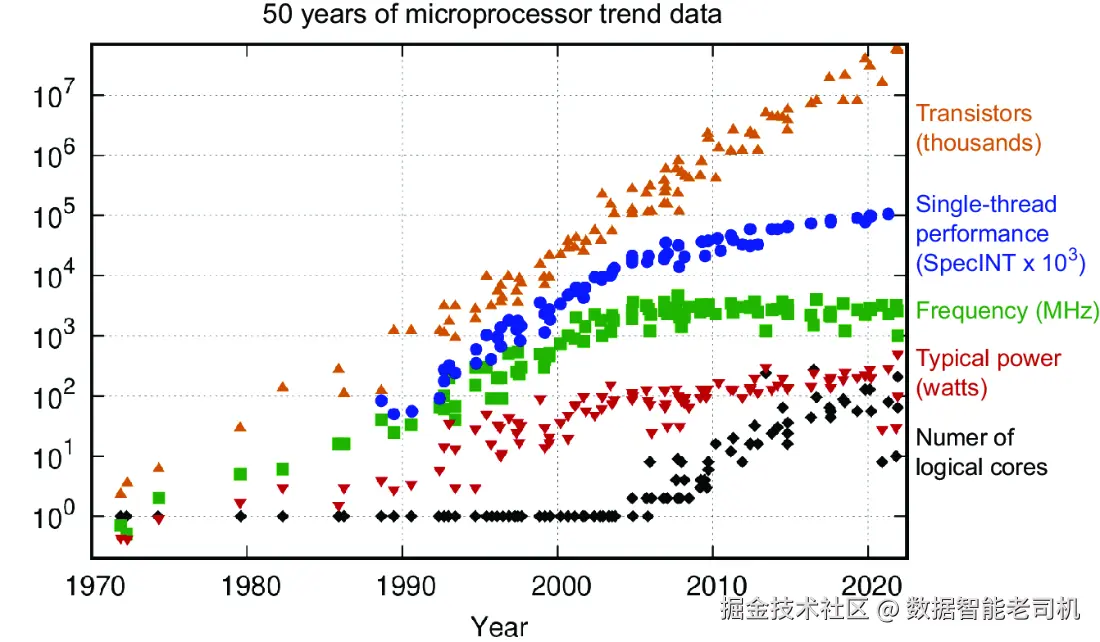
技术改进的极限:连摩尔定律都开始"吃老本"了
说到技术发展遇到瓶颈,最经典的例子之一就是------摩尔定律 。
这条"定律"大致意思是:芯片上的晶体管数量每隔18到24个月就翻一倍。
听起来是不是有点像科技界的"内卷标杆"?确实,它预测芯片发展速度还挺准的。
但!你要注意,现在我们已经开始看到这玩意儿进入了传说中的 S 型曲线 ,也就是边际效益递减期。
晶体管的数量虽然还在涨,但翻倍的速度没以前那么快了,
更重要的是:整个系统的性能也开始进入瓶颈期了。
也就是说,芯片上堆再多晶体管,性能也不一定就能再翻倍,其他瓶颈也开始冒头。
比如什么呢?
👉 GPU 昂贵得离谱,配套的电力、散热、数据中心也烧钱得恐怖。
你不能指望只靠"加晶体管"就能无穷无尽地让大模型变强------连摩尔定律都不信这个邪了。
别用"人类标准"来评判大模型,它不是人类!
这年头,你是不是经常看到那种新闻标题:
"某某大模型考过了医学院入学考试(MCAT)!"
"大模型竟然通过了律师资格考试(Bar Exam)!"
"GPT的IQ高达145,比你聪明!"
听起来很炸裂,感觉大模型下个月就能当你领导了。
但冷静下来想想,这些"成绩"真的能说明它比你聪明吗?未必!
因为------大模型不是人,它的"聪明"方式和你压根不一样!
首先,它可能在训练时就见过很多类似题目。你刷100遍真题也能考满分,对吧?
其次,这些测试本身是给人类设计的,不是用来测试AI的。
IQ 测试、MCAT、司法考试,这些题目是建立在人类行为统计上的,
它们是"相关性强",但不是"因果关系"。
举个栗子 🌰:
🩸 血糖测试 是"因果"------你血糖太高太低,身体会出问题,这是我们生理上懂得很清楚的事情。
🧠 IQ 测试 是"相关"------高IQ 和某些好结果(比如学业、职业)之间有关联,
但它并不是说"你 IQ 高 = 你就能做成所有事"。
它只是一个经过多年打磨的工具,
我们知道答某些题的人,通常能在现实中做得不错,
但我们不清楚这些题到底有没有测出"真正的聪明才智"。
所以结论是:
别光看大模型能考多少分、拿什么"证书",就以为它已经"成人成神"了。
那只是一些指标,不是它能力的全部、也不是它理解世界的证明。
人类的智慧是立体的,有情感、有直觉、有顿悟;
大模型只是把世界拼成了"预测下一个词"的概率矩阵。
它不是你对手,更不是你上级,
它是你手里的超级计算器 + 写作助手 + 萌萌哒"数据鹦鹉"🦜------
关键是,你得知道怎么用它、啥时候别用它!
靠"外挂"才能变强:外部信息对大模型的"加成"
虽然大模型自己没法修炼成仙,但人类早就给它配好了"外挂系统"。
比如:
- 机器人手臂:有些算法会借助物理模拟器(就像游戏里的"真实物理引擎"),帮AI判断怎么更好地抓东西。
- 苹果手机的虹膜识别:Apple 会用3D建模软件生成眼睛的模型数据,来训练AI提高识别率。5
- 代码生成与数学验证:在第6章我们提过,LLM 如果能结合编译器检查代码、或者用 Lean 语言验证数学公式,也能变得更靠谱。
这些例子说明:只要外挂挂得好,大模型确实能"变强一点" 。
但注意!这不代表它可以无穷无尽地自己升级。原因很简单:
这些外挂工具------比如物理模拟器、代码编译器、数学验证系统......
这些本身也是人类写出来的!
也就是说:大模型之所以能"变聪明",本质上还是因为我们喂给它新的、更有质量的信息。
你要真想让它越来越强,得不断提升这些外挂工具,而这事儿......又回到了人类头上。
于是,另一个"经济瓶颈"出现了:
想让大模型实现"自我提升",就得投入更多资源搞配套工具,
你以为是在升级AI,其实是你自己加班写外挂。
说到底:靠外挂是能提升,但别指望它永动机式狂飙,最后还是得我们人类来擦屁股。
7.1.2 小样本学习:教它几招,它就能上场?
小样本学习(Few-shot Learning),也叫上下文学习(In-Context Learning) ,是大模型界非常流行的一招。
这招怎么玩?
你不需要重新训练模型,而是在"提示词 prompt"里,直接塞几个示例告诉它:
"兄弟,看好了!你待会就按这个风格来答题!"
比如,你想让大模型扮演一个客服机器人,回答用户的问题。你可以给它这样的提示:
用户: 我的订单怎么还没发货?
客服示例回复: 您好,我们正在为您准备发货,预计明天发出,请耐心等待~
这就叫 One-shot learning(单样本) ,也就是给一个例子。
你要是给两个例子呢?那就是 Two-shot ;再多点,就统称为 Few-shot(小样本) 。
但重点不是到底几个,而是"就给它几条看起来像模像样的范本",让它"照猫画虎"。
这种方式非常实用,尤其是在不方便或不可能重新训练模型的场景中------
你可以用它来让模型模仿语气、学会格式、甚至调整内容风格。
这招其实就是提示工程(Prompt Engineering) 的经典玩法,
第 7.4 图展示了这个操作的具体样式,简直就是"教AI画画前,先给它看看范本"。

加点例子,大模型表现更靠谱?那它到底"学"了没?
在提示词里加几个例子,确实能让大模型在新任务上表现得更聪明。
这招好就好在:
- 你不需要重新训练它(不用搞什么 RLHF,也不用 SFT);
- 效果比"裸问"(Zero-shot)要好 。
就像你直接跟人说:"照这个格式来一份",结果往往比"你随便写一个"靠谱得多。
但问题来了:这种"few-shot"方式真的算"学习"吗?
其实,它根本没"学会",只是"照着你说的演了一遍"
少样本提示(few-shot prompting)不是训练。
你没有动模型的任何一根神经(也就是参数 weight),模型的"脑子"还是原来的"脑子"。
哪怕你让它今天跑10万个提示词、明天跑100万个,到了后天,它还是那个它:
🧠 一滴进步都不会有。
除非你手动优化提示词,换更合适的例子,或者多加点参考,
否则它永远不会"自己变聪明"。
从这个意义上讲,few-shot 并不是真正的学习,它更像是"提词器"变高级了。
不过从另一个角度讲,它又有点像"在学习"
虽然大模型本身没变,但它的行为变了。
你换了 prompt,它就换了风格------就像演员换了剧本,演出来的感觉也跟着变了。
这也是为什么我们说:
提示工程,其实就是"用上下文去引导模型的行为" 。
而这种"被引导后的行为",跟你用相似数据去微调模型(fine-tune)的效果,其实很像。
通俗来说:
📌 few-shot 没干啥 gradient descent 干不了的事。
✅ 实用建议时间!
如果你手头没有很多数据、也不想费劲微调模型,
那 few-shot 是你目前最有效的武器------性价比超高。
few-shot 的效果也会边际递减。
一开始加几个例子可能提升明显,
但你再加到十几个、几十个,效果未必会继续提升,可能还会让模型"思路卡壳"。
所以------
- 如果 few-shot 已经给不出你想要的效果,
- 或者你在 prompt 里写了大半页纸,它还是答得四不像,
那就老老实实考虑我们第 5 章讲的那些硬核手段吧:
👉 微调(SFT)、强化学习调优(RLHF)之类的大招该上场了!
7.2 工作效率谁更强:一颗 10 瓦的人脑 vs. 一台 2000 瓦的计算机
人类的大脑,只需要10瓦电,就能保持清醒------比如现在你能坐在这儿读这本书,全靠它这颗"节能神脑"。
与此同时,一台用于 AI / 机器学习的高端工作站呢?
轻轻松松就能耗掉 2000瓦的电力。
如果你要运行当下那些"大得离谱"的大型语言模型(LLM),用的是那种顶配服务器,那功耗直接飙到:
10,000 到 15,000 瓦!
也就是说,从能耗角度来看------
让一个大模型干活,可能比让你自己动脑还要多耗1500倍的电!
(环保战士听了直摇头)
你可能会想:那我们人类是不是该为自己的"节能高效"鼓掌?
没错,这一点是我们进化史上的骄傲,毕竟------
只靠几块吐司的热量,大脑就能跑一天的思考量,这谁不服?
但等等,别高兴太早, "效率"可不光只有"省电"这一种指标。
在某些方面,机器才是真·效率怪兽。
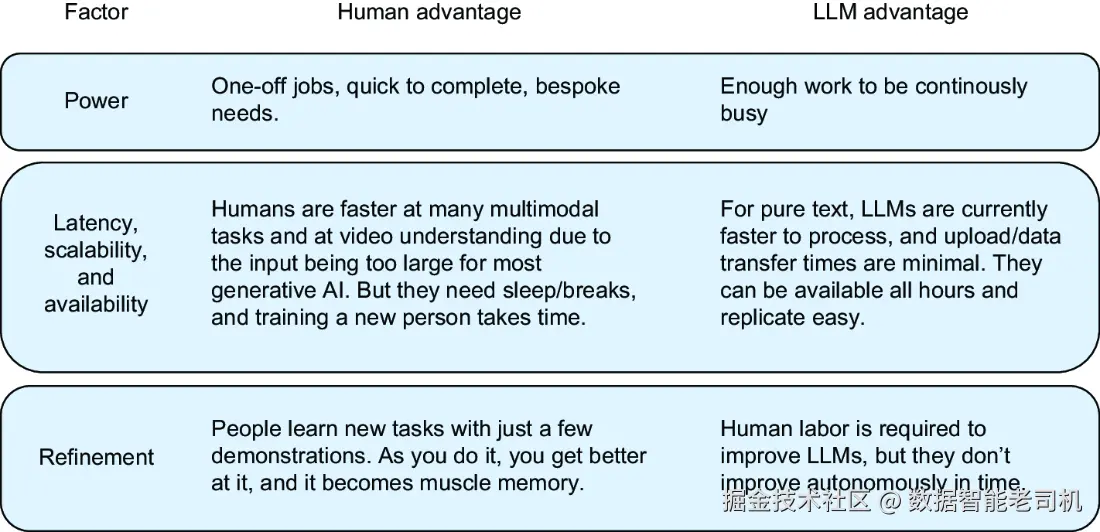
我们在图 7.5 里会展示:
人类和机器在不同"效率类型"上的强项和短板,看看究竟谁在哪方面更能打。
7.2.1 电力消耗:AI 再强,也得插电
"电力"是决定 LLM 成本的一个关键因素,不管你是搞训练的,还是只用它来跑推理,都逃不掉电费单。
虽然各家厂商都能给你报价,但你永远不知道他们真实的成本是多少------
他们可能赔本赚吆喝搞市场占位(俗称"亏钱换未来"),
等你依赖上了,说不定哪天就悄悄涨价,来个"刺客电费"。
更有意思的是:
有些科技巨头已经准备自己造小型核电站 ,
以备未来自家数据中心的大模型们能"不停电、随便卷"。
这意味着,大模型未来只会越来越大、越来越耗电,
但他们的价值可能也大到能撑起一个发电厂,听着是不是又疯又酷?
当然,这也提醒我们:
- 一旦你的大模型用得多、用得火,别光想着带宽够不够,电力容量可能先出问题;
- 电价也不是永远稳定的,尤其是在像美国这种地方,电价飘起来能让你怀疑人生。
🧠 总结一句话:用大模型搞大场面,别忘了先算电费表。
7.2.2 响应时间、扩展能力、在线率:AI 不睡觉,人得打卡
说起机器比人强的地方,以下三点必须拿出来吹一吹:
🚀 响应速度(Latency)
你问,它几乎立马答,0.几秒响应。你问人类?先得看他在不在工位。
🧱 可扩展性(Scalability)
人类想从1人扩到1000人,得招人、培训、发工资,还可能罢工;
大模型?起1000个副本就完了,点几下部署就能上。
🌐 可用性(Availability)
大模型 7x24 在线,永不请假,
人类?凌晨三点还在写报告的基本都在医院。
不过,这种"反应快+不下线"的属性,也带来一个小问题:
如果你还要人来"审核输出",那你又得配一套"人类班表",才能真的享受到 AI 的"全天候"优势。
🧠 总结一句话:AI 能做到"秒回消息",但想用好,还得人来兜底。
7.2.3 持续优化:AI 不会进化,得靠你喂它升级包
还记得我们在 7.1.1 提过,大模型自己不会"变聪明"这事吗?
现在我们继续深挖这个痛点:
❌ LLM 不会"越用越好"
它不会像你一样做完一次、回顾复盘、吸取教训。
哪怕你喂它一百万个 prompt,它还是原来的那个"大语言学傻瓜"。
所以,要想让它用得越来越顺手,必须有人类参与:
- 优化提示词(Prompt)
- 设置新的训练方案
- 把失败的案例找出来,总结模式再优化
而且,提升 LLM 的效率并不是简单地升级到更新的模型,或者"换个大点的"。
你还需要做这些扎实的"幕后工作":
- 搭建日志系统,记录输入、输出、模型表现;
- 做数据回溯,搞清楚哪一类问题它经常答得不靠谱;
- 像我们第 5.5.2 节提到的 DSPy 框架,就是专门干这个的。
📱 "Emoji 危机"来了!
想象一下,你一开始训练的模型用得好好的,结果------
Z 世代的熊孩子突然在消息里乱加各种新 emoji,
🤡👻🛸🧠🔋🦄🌚💥(你认得几个?)
结果你的模型懵了:"这是什么黑话?"
它之前根本没见过这些符号,自然就处理不了。
怎么办?
第一步,写段代码 :识别 emoji,把它们转换成文字描述,比如
💥 → "爆炸状表情,通常表示突然或强烈的情绪"。
这当然不是万能的,但这就是工程实践:测试 → 调整 → 验证。
这也说明了: "全部交给大模型,彻底不写代码"是不现实的。
🔄 数据漂移(Data Drift)是必然的!
所谓"数据漂移",就是现实世界的数据使用方式会变,
而你训练时的数据,早就跟不上这个变化节奏了。
Emoji 只是最明显的一种,
除此之外,还有:
- 新词的出现(比如"甄嬛体");
- 老词的新用法("懂王"以前可不是褒义词)......
这就要求我们:
- 定期收集新数据;
- 给模型做微调;
- 或者在 prompt 中补充定义,让它"临时学一课"。
🧠 总结一句话:世界在变,模型得跟上;不然它再强,也只是个"过去式"的智能体。
7.3 大语言模型不是"世界模型"
你可能经常发现,大语言模型(LLM)能讲出一些听起来非常像真的 世界知识:
历史事件、物理常识、心理反应,甚至八卦段子都能信手拈来。
于是你可能会下意识地以为------
"哇,它懂好多,简直跟真的知道世界运转规则一样!"
但抱歉,让我们泼一盆冷水:
语言模型并不真正"知道"这个世界,它只是能"顺着话往下说"。
来,我们举个简单例子:
🧣**"如果你告诉某人他们的毛衣很丑,会发生什么?"**
作为人类,你立刻可以脑补出各种场景:
- 对方会尴尬;
- 气氛会变冷;
- 如果这是在圣诞节聚会上,说不定那毛衣本来就是参赛用的"丑毛衣冠军"!
你不需要真的看到那件毛衣、真的开口说话、真的在场------
你就能在脑中构建一个"毛衣社交场景模拟器" ,然后得出一个结论。
这是因为你有"世界模型":
你理解人的情绪、理解社交情境、理解讽刺和幽默------这些都能在你的大脑里即时"推演"。
🧠 但是 LLM 呢?
LLM 不能"先想后说" ,它唯一能做的"思考方式",
就是不断地生成文字 ------ 换句话说,它的"思考=说话"。
在它的世界里:
"我要想多一点,那我就得说多一点。"
图 7.6 就是一个典型例子:
模型一开始唠唠叨叨地分析毛衣的颜色、质地、用途,
最后终于得出一个"你穿得真不错"的温柔结论------
但你能看出来,它不是在"理性判断",它是在"字数换智力"。
⚠️ 小心!当我们说"模型在思考"时,其实只是它在"计算"
严格来讲,"思考"这个词用在 LLM 身上,是一种极不准确的"人类化幻想" 。
更准确地说是:
它不是在"思考",而是在"计算下一步说啥最合适"。
比如:
- 输出10个token ,无论你让它说"你好"还是"宇宙膨胀方程",
它消耗的计算资源是一样的。 - 如果你问一个复杂问题,它确实"看起来"会输出得更长,
但这只是因为"长篇幅更容易装作在认真思考"。
换句话说:
LLM 所谓的"多想点",本质上就是"多写点"罢了。
🧠 总结一下:
- 人类可以在脑子里构建一个世界,预测不同变量的影响。
- LLM 不能,它只能顺着词往下生成,看起来像是懂了,实际上是"拼词接龙"。
所以下次听到有人说:
"哇,这个大模型在思考!"
你就大大方方纠正他:
"不,它只是在用更复杂的方式算下一个词而已。"

说白了:大模型"不会计划",只会"边说边装作在计划"
我们再来看个典型场景:
大模型要"计划"一件事时,它必须一边"写"一边"想" 。
换句话说,如果它不输出文本,它就仿佛"啥都没发生"。
这就像一个人脑袋里没剧本,只有嘴上有话才算"进入角色"。
所以,如果你不让它"说出来",它就无法"思考过程"或"预先计划"。
为了解决这个问题,我们搞出了一个很火的技巧:
🧠 CoT 提示词:咱们一步一步来!
这种方法叫 Chain-of-Thought(CoT)Prompting,中文叫"思维链提示词" 。
操作也很简单:在 prompt 里加一句魔法咒语,比如:
"让我们一步一步地思考这个问题。"
你会发现,只加了这句话,大模型的表现往往就能立刻变聪明一点 ,
步骤清晰、逻辑更顺、有条有理,仿佛突然开窍了一样。
但问题也来了:
为啥它就因为你说了"一步一步"就表现好了?这不是挺玄的吗?
🧨 但别高兴太早,CoT 也容易翻车
就算用了思维链提示,大模型还是会犯错,比如:
- 漏掉中间步骤;
- 算错数字;
- 推理逻辑不通......
简直就像那个认真分析了半天却把"鸡兔同笼"解成"火星种植"的学生。
🔍 那为什么 CoT 有时还是会让模型表现更好?
我们可以从几个角度来分析:
✅ 1. 是不是"算得更多",就"表现得更好"?
还记得第3章我们讲过的 transformer 和注意力机制(attention)吗?
大模型接收的输入越长、输出的文本越多,
transformer 就需要做更多计算。
也就是说,当你让它"分步骤输出"时,它等于自己"多烧点脑细胞" ,可能就多思考了一点点(其实就是多算了)。
但------如果它真的有"世界模型",
它应该能在"脑子里"先计划好,不需要靠"多说点"来强行"思考"。
✅ 2. 也许只是因为它看过太多类似教学材料
大模型的行为,和它见过的训练数据有关。
而在训练数据中,像"Let's think step by step."、"我们先从第一步开始"这种说法,
往往出现在教育内容、教程、范文、优秀回答里。
所以它可能只是学会了"这种说法=好学生",于是你一提示,它就更认真"背模板"了。
换句话说:
CoT 并没有让模型掌握新技能,
只是帮它从"模糊记忆库"里,抽出更像样的内容罢了。
⚠️ 注意!"世界模型"这个词也容易误解
当我们说一个系统有"world model(世界模型)"时,到底是啥意思?
其实学界也没统一说法。不同人说的"世界模型"可能完全是两码事。
所以在聊这个话题前,最好先把定义讲清楚 ,
不然你说"世界模型"是能理解现实,我说的是能模拟物理规律,
结果两边聊得热火朝天,根本不是一个频道。
这类术语混乱的问题,我们会在本书最后两章再深入吐槽一波。
🧪 那"世界模型"就没戏了吗?别急,有人在搞!
虽然目前 LLMs 还没有真正意义上的世界模型,
但有一些研究者已经在尝试把"世界建模"能力塞进 AI。
比如 David Ha 和 Jürgen Schmidhuber 在 2018 年做的一个项目:
他们设计的系统能在模拟游戏中大幅提升表现,比当时流行的方法强多了。
也有研究在搞:
- 用 LLM 来充当世界模型;
- 给 LLM 植入简易世界模型;
不过目前这些方法都还很初期,适用于某类特定任务,
距离人类那种"通用世界理解能力"还远得很。
🧠 总结一句话:
大模型不会"闭嘴思考",它只能"边说边想";
"CoT 提示"有点用,但别太信;
真正的"世界理解力",还得靠人类慢慢喂养,不是一句 prompt 能搞定的事儿。
7.4 计算的极限:该难的事还是难
有些人担心所谓的"AI 暴走":
某种超级智能的 AI 会突然变得无所不能,不但能秒解人类永远解不了的问题,
而且它的目标根本不和人类对齐,甚至还可能不怀好意。
最吓人的是,这种 AI 还能不断"自我进化",最终变得像神一样强大,连我们人类都看不懂它在干嘛。
这类想法在网络上炒得很热,仿佛 GPT 再升几级就能统治地球。
关于这个话题的伦理和哲学问题,我们会在最后几章再慢慢聊。
但现在,我们先来从技术的角度讲点实话:
现实中,AI 还远远没有"脱缰",因为------它受限于计算复杂度这堵墙。
🚧 什么是"计算复杂度"?先来一小段"程序员通识课"
在计算机科学里,我们很在意一个问题:
"数据量变大时,程序运行时间会涨多少?"
理想情况下,如果你把输入数据翻倍,程序运行时间也只是翻倍,
这叫 线性复杂度(linear complexity) ,用数学语言写成:O(n)。
但这只是童话般的美好愿望,大部分现实问题远比这麻烦。
我们通常用"大O符号"(Big-O Notation)来描述算法的复杂度增长情况:
| 复杂度等级 | 数学表示 | 直观例子(原本要2天)换成4个输入后可能变成... |
|---|---|---|
线性:O(n) |
就是一倍一倍来 | 4天,刚好翻倍,很理想 |
对数线性:O(n log n) |
有点增长,但不太离谱 | 约4.4天,还能接受 |
平方:O(n²) |
数据一多就爆炸 | 8天,感觉不妙 |
指数:O(2ⁿ) |
想都别想 | 程序跑完前可能人类都灭绝了 😵 |
你可以想象:随着数据量变多,图表的曲线会变得越来越陡。
也就是说:
数据一多,复杂度高的算法就会卡成 PPT,动弹不得。
🤖 那 LLM(大语言模型)属于哪个级别?
在实际运算中,LLM 对输入长度为 n 的文本(比如 token 数)进行处理时,
它的复杂度大约是 O(n²),也就是"平方复杂度" 。
这代表啥?
比如你现在让它处理 1000 个 token,它花 1 秒钟;
那你输入 2000 个 token,它可能就得花 4 秒钟!
所以我们可以很确定地说:
只要某个任务本身的最低计算复杂度就高于
O(n²),那么 LLM 是不可能"高效"地解决它的,因为它天生就吃不动!
⚠️ 小提醒:我们这里不是在讲算法研究生课程
我们这里只是让你建立一个"计算瓶颈"意识,
没打算拉你深挖 NP-完全问题和图着色定理。
如果你想深入搞懂这些复杂算法,可以去看看这本书:
📘《Grokking Algorithms:程序员的算法通识手册》,作者是 Aditya Bhargava,非常适合初学者。
❗不可能超越复杂度的天花板
再举个例子:
假设有一个任务,它的计算复杂度是 O(n³)(立方级),
而你手里的大模型最高只能跑到 O(n²),那不就尴尬了吗?
你不能指望一个二年级的小学生去解大学数学竞赛题。
如果 LLM 真能跑过这道题,说明我们对这题的复杂度评估可能是错的------逻辑自洽就崩了。
所以结论是:
LLM 再强,它也不能魔法般解决那些"超出它能力上限"的难题。
📦 表 7.1:一些现实世界中的"超难任务"
虽然表 7.1 的具体内容还没列出来,但我们可以先剧透几个典型例子:
| 任务 | 常见复杂度 | 为什么难? |
|---|---|---|
| 包裹投递路径最优化(TSP) | NP-hard / 指数级 | 输入一多,可能连明年春节都安排不完 |
| 航班重新排班 | O(n³) 或更糟 |
航空公司永远的"噩梦调度器" |
| 资源分配(人、货、机器) | 常超 O(n²) |
变数太多,方案太杂,爆炸太快 |
这些问题共同特点是:组合太复杂、变量太多、计算太烧脑 。
不是 LLM 不努力,而是数学不给面子。
🧠 总结一下:
- 大模型是很厉害,但它也不是"数学奇迹";
- 它受限于计算复杂度,再想变强,也不可能突破"任务本身有多难"这件事;
- 有些问题就是没法快速解出来,除非哪天人类真破解了"P=NP"。

除了"算法多复杂",我们还得关心"它属于哪个复杂度圈子"
除了计算时间的多少,算法还有一个非常关键的"圈层概念"------
那就是它属于哪个 复杂度类别(complexity class) 。
你可以把它理解为"这类算法到底都能解决哪些事"的分类标准,
就像江湖门派:你是武当派还是少林派,不是看你拳头多快,而是看你内功修到哪一层。
⚔️ 最出名的两个复杂度门派
- P类问题(Polynomial,简称 P)
简单说,就是"能在合理时间内解决的问题",
举个栗子:快排、哈希表查找、基础图遍历......都在这个范围。 - NP类问题(Nondeterministic Polynomial)
这是很多人搞错的地方:
🛑 NP 不是 Not Polynomial(非多项式) ,而是 "非确定性多项式时间" ,
说白了:答案容易验证,但不容易找到。
比如"给一堆城市画最短路线"这个问题------你要走一遍才能知道是不是最短的。
🧠 LLM 在这个"复杂度宇宙"里处于什么等级?
现在,重磅来了:
研究者 William Merrill 和 Ashish Sabharwal 14 做了一个很酷的发现:
大模型解决问题的能力,跟它"中间步骤里生成了多少 token"是正相关的。
简单翻译一下:
- LLM 解决问题的过程,其实属于一种叫做 L 的复杂度类(L = Logarithmic Space,用对数空间完成任务)
- 而 L 类问题,是个超级小的门派 ,能解决的问题非常有限,
简直就像:练了五年武功却只能打三招,连入门级副本都刷不动。
但------如果我们让 LLM 生成更多中间步骤 (比如用 Chain-of-Thought 提示词一步步"思考"),
它的处理过程会逐渐"晋升",最终能达到 P 类问题的能力范围。
不过!即便如此,它还是只能在 P 这个门槛以下徘徊 ,
永远打不过 NP 和更难的问题!
📊 图 7.7:复杂度江湖门派图

可以想象,图 7.7 就是把这些复杂度等级像蛋糕一样分层:
css
越往上,问题越复杂 → L → P → NP → EXP(爆炸复杂度)→ ???而我们的 LLM,就像一个只能跳两层楼的小怪兽:
- 它天生只能待在 L 区域;
- 加点"语言链提示"后能努力跳上 P 层;
- 但再往上?👋 抱歉,它跳不上去了。
🧠 小结:
- 大语言模型不是万能钥匙,它属于"只能解简单题"的复杂度俱乐部;
- 它最多解决 P 类问题 ,NP 级或更高难度任务对它就是天花板+铁盖子;
- 想让它"打怪升级"?没门,因为复杂度类是理论上的上限,不是靠加显卡能突破的。
这下可惨了:复杂度类别不是说"跑得快",而是"能不能跑"
刚才我们讲到复杂度类别。问题是,这事儿比"跑得慢"还惨。
为什么?因为:
复杂度类别(complexity class)说的不是你跑多快,而是你有没有资格跑。
举个例子:
如果一个问题是 O(n³) 级别的(比如航班调度、路径优化这类),
你得让模型生成 n³ 个 token 才能解出来;
但模型生成 token 本身也是 O(n²) 的复杂度。
所以你相当于干了:
O(n³) × O(n²) = O(n⁵) 的操作!
简直是自己搬砖砸自己:一边是任务复杂,一边是处理能力有限,最终变成了计算爆炸现场。
而这还不包括 训练模型、调 prompt、让模型别出错等隐性成本。
所以我们说------大模型干复杂活,纯靠蛮力是真扛不住的。
7.4.1 模糊问题,就该配模糊算法
说到这,你可能已经开始怀疑人生了:
"那是不是 LLM 根本派不上用场?"
别灰心,其实------LLM 的强项压根就不是精确计算!
像所有机器学习系统一样,大模型最适合"模糊问题" :
那些你很难用一句话说清楚对错的问题。
比如:
- "苏西这封邮件是什么意思?"
- "约翰在这条消息里是不是在暗示什么?"
这些问题的答案,本身就是带感情色彩、不确定性的,容错率很高 。
你就算回答得不那么完美,人类也不会翻脸,顶多再追问一句。
人类语言本身就模糊、含糊、绕弯、啰嗦,
正好跟 LLM 的模糊特性相得益彰,天作之合。
所以文本总结、情绪判断、写初稿、润色检查......
这种**"差不多就行"**的工作,才是 LLM 的主战场。
7.4.2 复杂问题,也能"差不多就行"?
我们也要反过来讲点公平话:
不是只有 LLM 解不了复杂问题,人类也不行。
以我们前面提到的旅行商问题(TSP)为例:
快递小哥想找一条最短的送货路线,不重复,不走回头路。
这类问题是 NP-hard 的,换句话说:
全世界最聪明的人也只能解个百八十个点,再多就烧脑烧电烧命。
那现实中我们是怎么解决的?
- 用近似算法 ,比如复杂度只有
O(n²)的算法; - 虽然不是最优路线,但我们能证明:结果不会比最优差太多(比如不会多走 1.5 倍的路);
- 换句话说: "够用就行",也能跑起来。
LLM 同样可以用于这类"差不多就行"的策略,只要你别指望它给出完美解法。
♟️ 棋类游戏能说明啥?
以国际象棋为例,它的难度比 NP-hard 还高。但 GPT-3.5 也能下得有模有样,甚至能赢真人。
那是不是说明 LLM 可以"近似解决"超复杂问题?
也不完全是:
- LLM 在象棋上的表现,有可能是被"特别训练过的" (OpenAI 把象棋加进了评估指标里,还 fine-tune 过);
- 象棋的数据网上一大堆,训练集里可能就有几十万盘完整棋局;
- 所以它下得不错,更像是"记忆 + 模板匹配",而不是"真实推理 +实时计算"。
结论是:
它是在"看过一万局象棋"的基础上,复现了差不多的策略,
而不是从头"学会怎么赢"。
💡 总结一下:如何用好 LLM?
✅ 最适合的场景是:
- 重复性高;
- 变化小;
- 容错率高;
- 结果可以"差不多"就行。
比如:
- 文本总结
- 初稿撰写
- 翻译润色
- 简单问答
- 基础客服
这类"轻任务",LLM 是黄金搭档。
🕹️ 再补一个例子:围棋 AI 的"超级战神模式"也有盲点
围棋是几十年来 AI 研究最难攻克的堡垒之一。
虽然现在 AlphaGo 和一票 AI 已经可以击败顶级棋手,但------
如果你写个奇葩 AI,专门下离谱棋、骚操作、假动作,
它可能就能干翻"超级 AI" ,但反而被普通人轻松碾压。
这说明了什么?
- 在"对抗性环境"里,人类在处理"突发情况"上,依旧完胜 AI;
- LLM 也一样:它没法很好地应对真正陌生、动态变化的敌人或场景。
🧠 最终结论:
大模型不是天才数学家,也不是宇宙逻辑引擎。
它是一个大词库里的模糊预测机 。
把它放在合适的位置,它就是效率之神;
让它扛起严谨推理,它只会给你复制粘贴风格的"错得像对"。
总结:别神化大模型,它是你效率工具,不是宇宙神明
- ✅ 大模型比人强的一点:就是"规模效应"拉满!
它可以低成本、全年无休地工作,
想多开几个副本直接起任务,远比人类招人、裁员轻松得多。 - ✅ 人类更擅长"突发状况" ,尤其是在你面对的是骗子、攻击者、钓鱼党等对抗性环境。
这时候,人类的常识、直觉、临场应变力,依然是无法替代的。 - ✅ 只要你给的大模型任务和它训练时见过的差不多,它表现就会很靠谱。
所以,它特别适合那些重复性高、模板感强的工作。 - 🧠 最有效的"教大模型新技能"的方法:不是砸钱训练,而是巧用 prompt!
所谓"提示词工程(prompt engineering)",
是用极低成本给大模型"戴上人设""套个模板"来达成新目标,
非常适合初学者上手。 - ❌ 大模型不会自己进化,不会越用越聪明。
它解决需要精确答案的算法问题表现很差,效率也低。 - ✅ 它最擅长的是"模糊问题" :
什么是模糊问题?就是答案不是唯一的,正确范围可以有点模糊,犯点小错也无伤大雅。
比如:写写文案、理解语气、总结内容、润色文字......
🎯 一言以蔽之:
LLM 不是万能选手,但它是模糊世界里的全能工具人。
用得对,它就是你的超级助理;用错地方,只会把你坑惨。