在AI圈子里,我们似乎已经习惯了这样一个场景:无论是GPT还是其他大模型,生成内容时总像是位耐心的诗人,一个词一个词地往外"吟唱"。这种"从左到右"的自回归模式虽然强大,但一个"慢"字,始终是悬在所有开发者和用户头顶的达摩克利斯之剑。
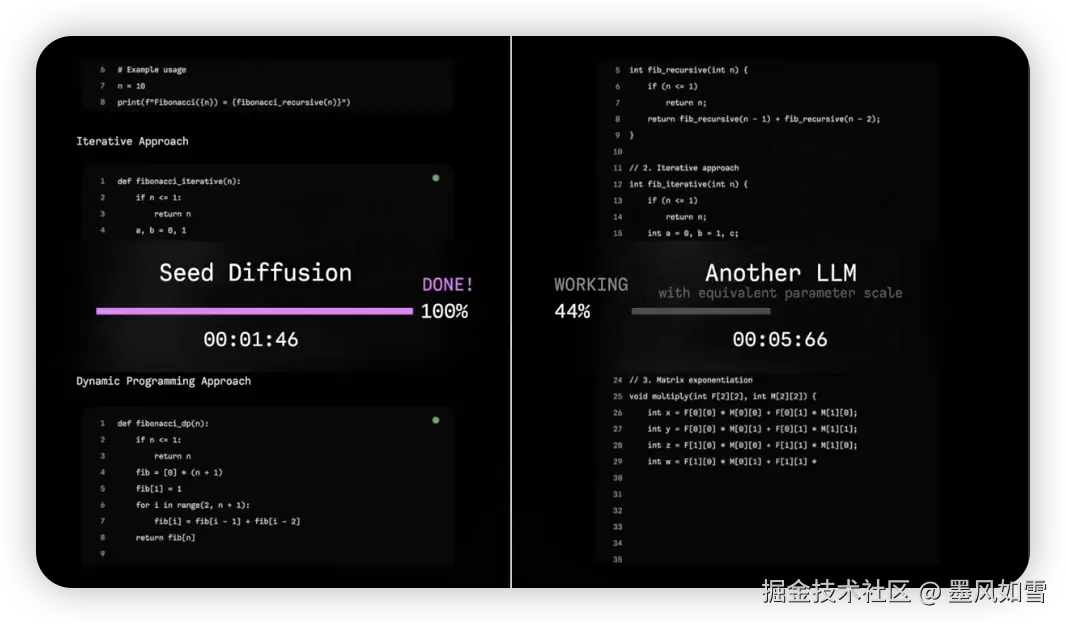
但如果,生成代码不再是逐字蹦,而是像思想的闪电一样,成块成块地涌现呢?
最近,字节跳动的Seed团队就带着这样一份惊艳的答卷来了。他们发布的实验性项目------Seed Diffusion Preview,不像一个常规的模型迭代,更像是一场蓄谋已久的"技术突袭",直指当前大模型架构的核心痛点。
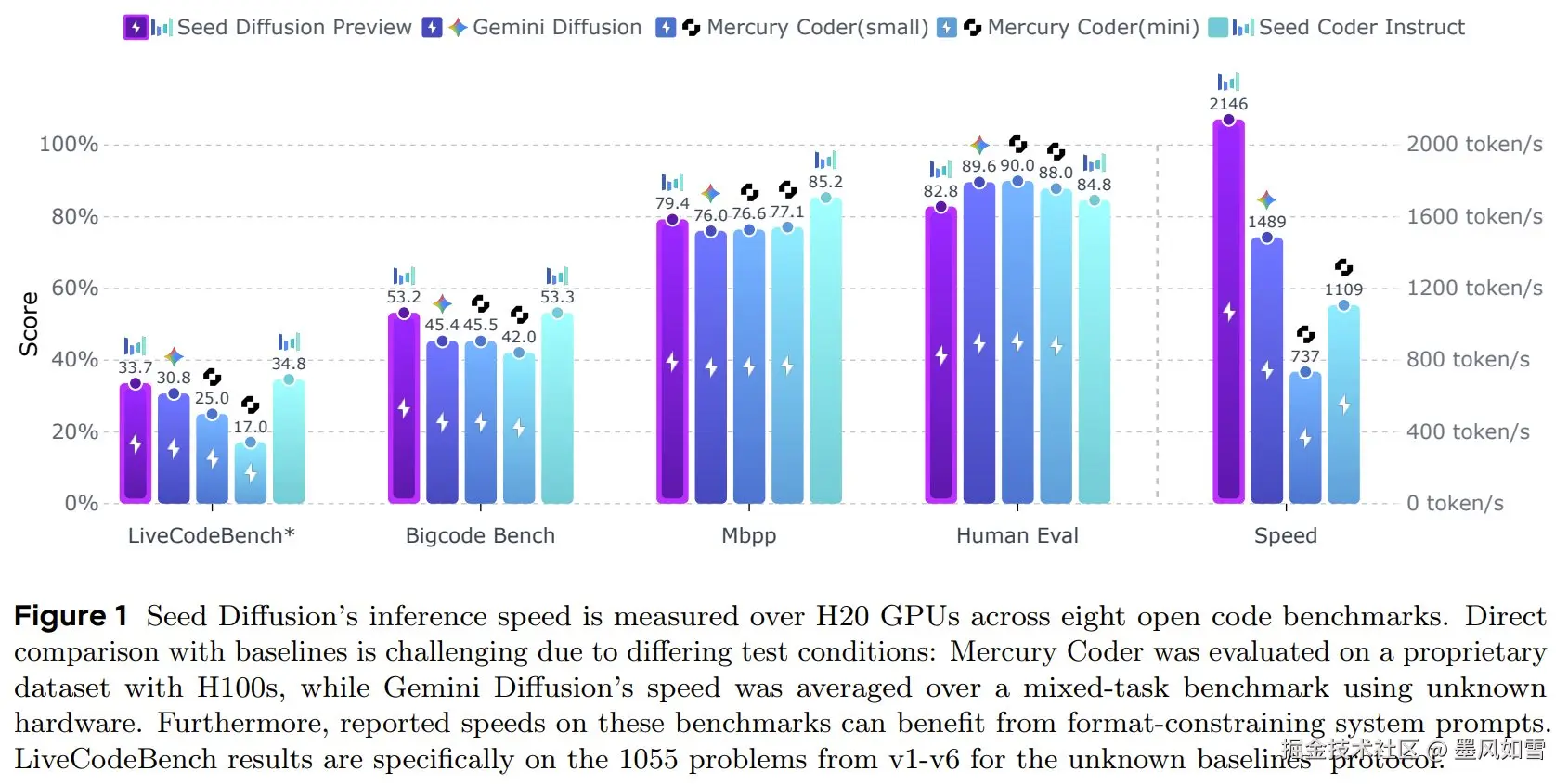
不止是快,是碾压式的快
我们先抛开复杂的术语,看两个最震撼的数字:
- 推理速度 :2146 tokens/s。
- 速度提升 :相比同等规模的自回归模型,快了整整 5.4 倍。
这是什么概念?当你还在等待传统模型慢悠悠地吐出几行代码时,Seed Diffusion可能已经完成了一整个函数的构建。它彻底打破了序列生成的瓶颈,让实时、流畅的交互式编程从奢望变成了可能。
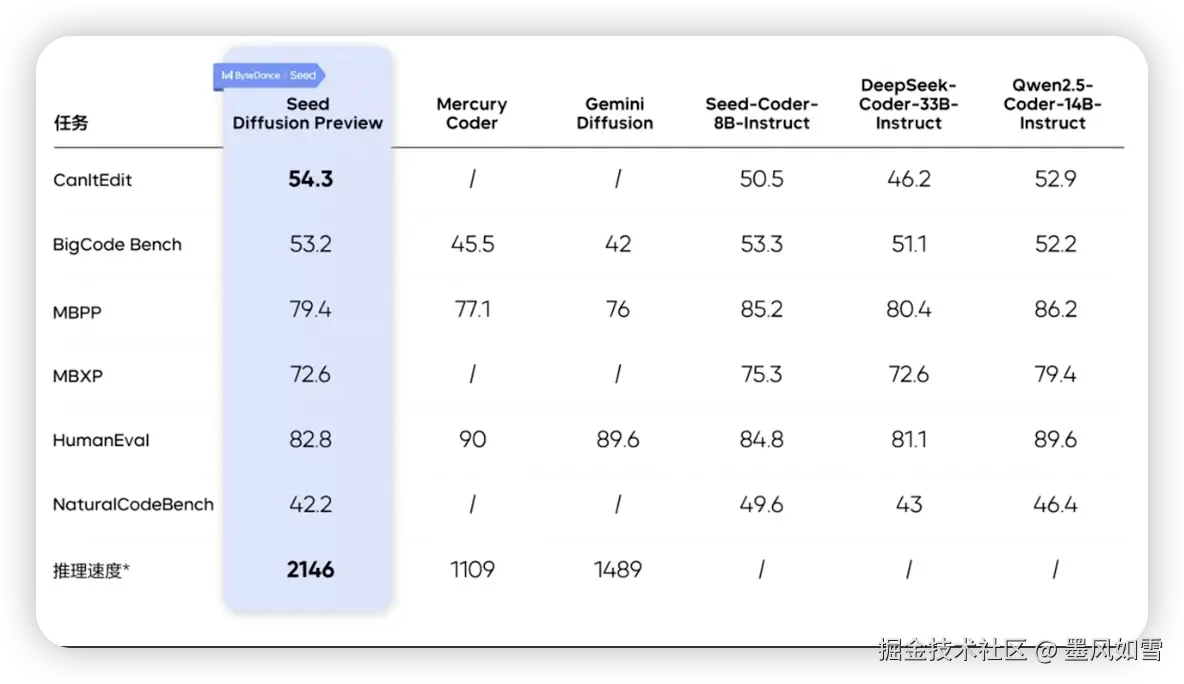
更关键的是,它并非"傻快"。在速度飙升的同时,生成质量丝毫没有妥协。在HumanEval、MBPP等主流代码基准测试中,它的表现与顶尖的自回归模型不相上下。而在更考验大局观、需要深思熟虑的代码编辑和修复任务中,它甚至以4.8%的优势实现了反超。

这就像一位短跑运动员,不仅刷新了百米纪录,还在冲线后顺便完成了一套优雅的体操动作------力量与技巧兼备。
速度与智慧并存的"黑魔法"
那么,字节跳动是如何解开这个"速度与质量不可兼得"的魔咒的?答案在于他们对扩散模型的一次大胆改造,可以通俗地理解为三步妙棋:
第一步:先学"填空",再学"改错"
传统的扩散模型训练,就像是让学生做完形填空,只关心被遮住的部分。而Seed团队设计了一套"两阶段课程":
- 前期(掩码扩散):先通过大量填空题,让模型学会理解局部代码的模式和上下文。
- 后期(编辑扩散):这是点睛之笔。训练师会故意把完整的代码"改坏",引入各种插入、删除的逻辑错误,然后逼着模型去修复。这一步,强制模型跳出局部思维,建立起对代码整体结构的全局审视能力。
经过这番"折磨",模型不再盲目信任给定的上下文,而是学会了批判性地思考。
第二步:从"随心所欲"到"遵守规则"
扩散模型的另一个问题是生成时天马行空,容易忽略代码的内在逻辑,比如"先声明变量再使用"。Seed团队通过一种"约束顺序扩散"技术,将这些代码世界的"物理定律"作为先验知识注入模型,确保它在并行生成时既能策马奔腾,又不会跑出赛道。
第三步:告别"逐字输出",开启"块级并行"
这正是速度起飞的引擎。自回归模型像一个字一个字打字的作家,而Seed Diffusion则像一位腹稿已定、段落并行喷涌的文豪。它将整个代码序列切分成多个块,在确保逻辑正确的前提下,让这些块同时生成,最后再完美拼接。这是一种从算法到系统工程的全面胜利。
这场风暴,将吹向何方?
Seed Diffusion Preview的发布,其意义远不止于一个更快的代码助手。
它像一声惊雷,向世界宣告:语言模型的技术栈,并非只有自回归一条路。
以代码生成为试验田,字节跳动成功验证了"全局优化"的扩散范式在大规模语言任务上的巨大潜力。这不仅仅是推理效率的量级提升,更预示着一种处理复杂任务的新思路。如果说自回归模型擅长"顺着写",那么扩散模型未来可能更擅长需要反复推敲、全盘考量的任务,比如程序调试、逻辑重构,甚至是数学证明和长篇内容创作。
当然,Seed Diffusion目前仍处于实验阶段,它的泛化能力还有待验证。但这颗投入平静湖面的石子,激起的涟漪足以让整个大模型领域重新审视未来的技术路线图。
从"序列生成"到"全局构思",这场语言模型的范式革命,或许已经悄然拉开序幕。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站