Ai思考过程
- 前言:从"零件"到"流水线"------AI学习的整体感
- [第一章:AI学习的"五脏庙"------ 核心循环总览](#第一章:AI学习的“五脏庙”—— 核心循环总览)
-
- [1.1 核心流程图:数据 -> 模型 -> 损失 -> 反向传播 -> 优化](#1.1 核心流程图:数据 -> 模型 -> 损失 -> 反向传播 -> 优化)
- [1.2 关键概念与PyTorch对应:核心组件回顾](#1.2 关键概念与PyTorch对应:核心组件回顾)
- 第二章:任务选择:搭建一个能"看懂"手写数字的AI
-
- [2.1 MNIST数据集:AI的"识字教材" (回顾与数据准备)](#2.1 MNIST数据集:AI的“识字教材” (回顾与数据准备))
- [第三章:AI"初见"------ 从"神经元"到完整训练循环](#第三章:AI“初见”—— 从“神经元”到完整训练循环)
-
- [3.1 核心组件定义:搭建AI的"大脑" (nn.Module)](#3.1 核心组件定义:搭建AI的“大脑” (nn.Module))
- [3.2 成绩单与纠错笔:定义损失函数与优化器](#3.2 成绩单与纠错笔:定义损失函数与优化器)
- [3.3 驱动引擎:编写完整的训练循环](#3.3 驱动引擎:编写完整的训练循环)
- 第四章:逐行解析:为什么每行代码都如此重要?
-
- [4.1 清空梯度](#4.1 清空梯度)
- [4.2 深入数据流:model(data)](#4.2 深入数据流:model(data))
- [4.3 误差评估:loss_fn(...)](#4.3 误差评估:loss_fn(...))
- [4.4 智慧回溯:loss.backward()](#4.4 智慧回溯:loss.backward())
- [4.5 调整认知:optimizer.step() 与 optimizer.zero_grad()](#4.5 调整认知:optimizer.step() 与 optimizer.zero_grad())
- 第五章:监控与总结:AI"学得怎么样"?
-
- [5.1 训练过程中的损失下降可视化](#5.1 训练过程中的损失下降可视化)
- [第六章 总结:你已拥有AI学习的"核心引擎"](#第六章 总结:你已拥有AI学习的“核心引擎”)
前言:从"零件"到"流水线"------AI学习的整体感
在前面的章节中,我们像一个个勤劳的"AI工匠",打造了许多核心"零件":
我们学会了Tensor这个"原子",能将数据化为AI的语言(第10.1章)。
我们知道了损失函数是AI的"成绩单",能衡量对错(第6章)。
我们理解了反向传播是AI的"反思录",能追溯错误(第6章)。
我们还掌握了优化器是AI的"纠错笔",能调整认知(第7章)。
但这些"零件"是如何协同工作,共同驱动一个AI模型进行**"学习"**的呢?它们之间隐藏着怎样的"流水线"?

本章将是一次关键的"集成实战"。我们将把这些零散的概念,通过PyTorch代码,"穿针引线"般地串联起来,亲手搭建并运行一个最简单的、完整的AI学习循环。本章结束时,你将彻底告别AI学习的"碎片感",建立起一个清晰、可操作的AI学习"整体流程图"。
第一章:AI学习的"五脏庙"------ 核心循环总览
AI的学习,本质上是一个不断试错、评估、反思、调整的循环过程。它主要包含以下五个核心步骤:
1.1 核心流程图:数据 -> 模型 -> 损失 -> 反向传播 -> 优化
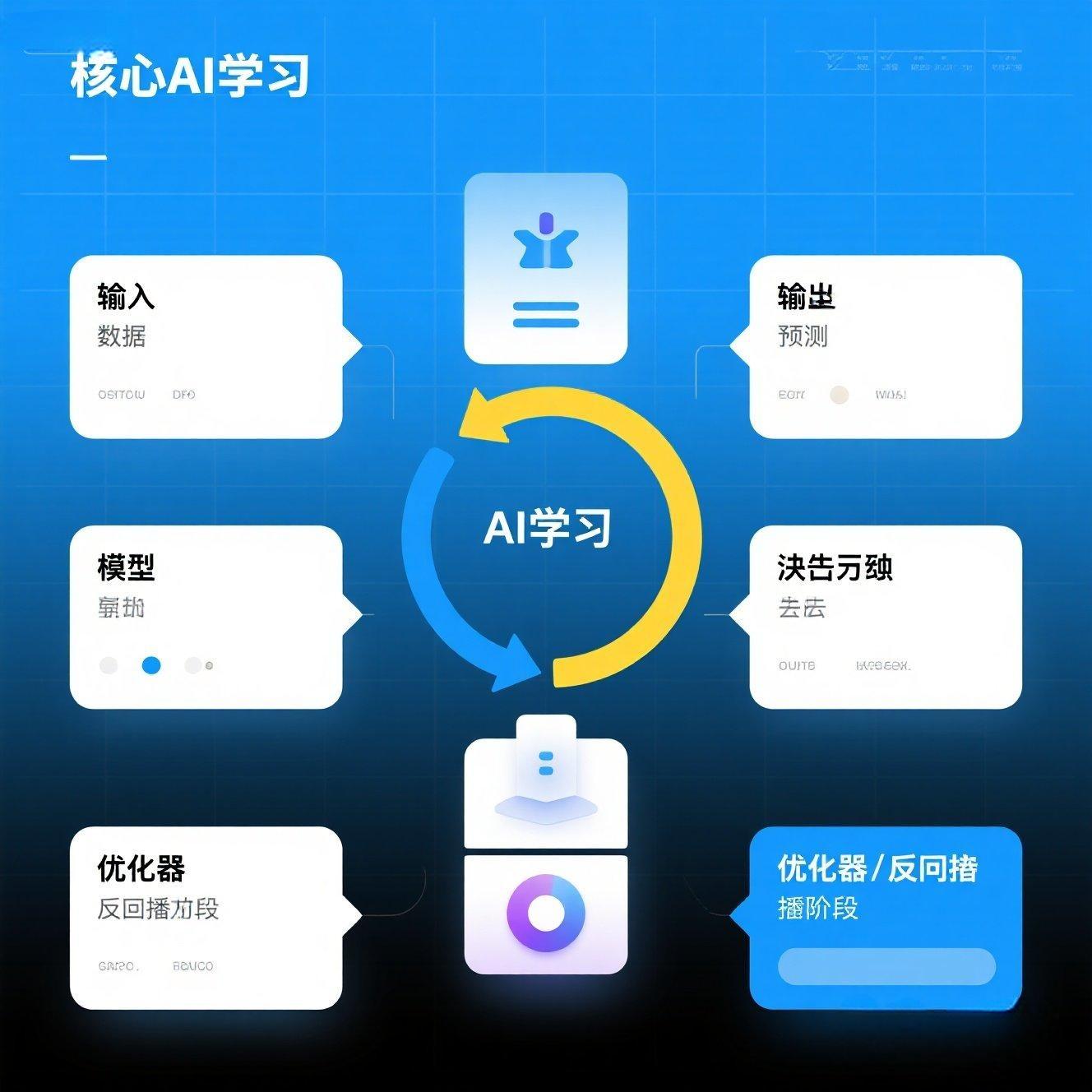
1.2 关键概念与PyTorch对应:核心组件回顾
核心步骤 作用 PyTorch中对应
数据 AI的"食粮",被学习的对象 torch.Tensor, DataLoader
模型 AI的"大脑",进行预测 nn.Module, nn.Linear, 激活函数
损失函数 AI的"成绩单",评估预测与真实差距 nn.CrossEntropyLoss, nn.MSELoss
反向传播 AI的"反思录",追溯错误并计算修正方向 loss.backward()
优化器 AI的"纠错笔",实际调整模型参数 torch.optim.Adam, optimizer.step(), optimizer.zero_grad()
第二章:任务选择:搭建一个能"看懂"手写数字的AI
并简要介绍所用的数据集,为代码实践做准备。
2.1 MNIST数据集:AI的"识字教材" (回顾与数据准备)
我们将使用经典的MNIST手写数字数据集。它包含60000张28x28像素的灰度训练图和10000张测试图,以及对应的0-9标签。这是一个非常适合入门分类任务的数据集。
数据特点回顾:
图像尺寸:28x28像素。
通道数:1 (灰度图)。
标签:0-9的数字。
PyTorch准备方式:使用torchvision.datasets.MNIST和DataLoader来加载和批处理数据
第三章:AI"初见"------ 从"神经元"到完整训练循环
们将把所有学过的"零件"组装到一起,编写一个完整的Python脚本,实现从数据加载到模型训练、再到初步评估的端到端AI学习循环。
python
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import os
# --- 0. 定义超参数 ---
# 这是模型的"设定值",你可以尝试调整它们
BATCH_SIZE = 64 # 每批次处理64张图片
LEARNING_RATE = 0.001 # 学习率,每次参数调整的"步长"
EPOCHS = 5 # 训练周期数,完整遍历数据集5次
INPUT_DIM = 28 * 28 # MNIST图片展平后的维度:784 (28*28)
HIDDEN_DIM = 256 # 神经网络隐藏层神经元数量
OUTPUT_DIM = 10 # MNIST有10个类别 (0-9)
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 智能选择GPU或CPU
# 为保存模型和结果图创建一个目录
os.makedirs('mnist_results', exist_ok=True)3.1 核心组件定义:搭建AI的"大脑" (nn.Module)
用随机数据测试模型的输入输出。
python
class SimpleMLPClassifier(nn.Module):
"""
一个简单的多层感知机(MLP)分类器,用于识别MNIST手写数字。
它包含两个全连接层和一个ReLU激活函数。
"""
def __init__(self, input_dim, hidden_dim, output_dim):
# 必须调用父类nn.Module的构造函数
super(SimpleMLPClassifier, self).__init__()
# 第一个线性层 (全连接层): 将展平后的图片输入(784维)映射到隐藏层维度(256维)
self.fc1 = nn.Linear(input_dim, hidden_dim)
# 激活函数: ReLU (修正线性单元),引入非线性能力
self.relu = nn.ReLU()
# 第二个线性层: 将隐藏层维度(256维)映射到输出类别维度(10维)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
# x的形状最初是 [BATCH_SIZE, 1, 28, 28] (来自DataLoader)
# 我们需要将其展平为 [BATCH_SIZE, 784] 以适应第一个线性层(self.fc1)的输入
x_flattened = x.view(-1, input_dim) # -1 会自动推断Batch维度,input_dim是784
# 数据流: x_flattened -> fc1 -> ReLU -> fc2
out = self.fc1(x_flattened) # 经过第一个线性层
out = self.relu(out) # 经过ReLU激活函数
out = self.fc2(out) # 经过第二个线性层,输出每个类别的原始分数(Logits)
# 注意: 这里不加Softmax,因为nn.CrossEntropyLoss内部会自带Softmax
# 模型的最终输出out的形状是 [BATCH_SIZE, OUTPUT_DIM],例如 [64, 10]
return out测试模型的向前传播
python
if __name__ == '__main__':
print("--- 案例#002:测试模型的前向传播 ---")
# 实例化一个临时的模型,用于测试
test_model = SimpleMLPClassifier(INPUT_DIM, HIDDEN_DIM, OUTPUT_DIM)
# 创建一个模拟的输入数据 (例如,1个Batch,包含BATCH_SIZE张图片)
# 形状 [BATCH_SIZE, 1, 28, 28],像素值随机
dummy_input = torch.randn(BATCH_SIZE, 1, 28, 28)
# 将模拟输入喂给模型,执行前向传播
dummy_output = test_model(dummy_input)
print(f"模拟输入数据形状: {dummy_input.shape}")
print(f"模型输出预测形状 (Logits): {dummy_output.shape}") # 形状应为 [BATCH_SIZE, OUTPUT_DIM]
assert dummy_output.shape == torch.Size([BATCH_SIZE, OUTPUT_DIM]), "模型输出形状不匹配预期!"
print("模型前向传播测试通过!")
print("-" * 50)3.2 成绩单与纠错笔:定义损失函数与优化器
损失函数: nn.CrossEntropyLoss 适用于多分类问题。
python
```dart
# 它期望模型的输出是原始分数(Logits),内部会自动应用Softmax进行概率转换,
# 然后计算负对数似然损失(Negative Log Likelihood Loss)。
criterion = nn.CrossEntropyLoss()
# 优化器: Adam优化器,最常用的优化器之一。
# 它负责根据模型参数的梯度来调整参数值。
# model.parameters() 会自动获取模型中所有可学习的参数(fc1和fc2的权重和偏置)。
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
# --- 案例#004:测试损失函数和优化器的基本功能 ---
if __name__ == '__main__':
print("--- 案例#004:测试损失函数和优化器 ---")
# 假设模型的输出(Logits)
mock_outputs = torch.tensor([[0.8, 0.1, 0.1], [0.2, 0.7, 0.1]], dtype=torch.float32) # 2个样本,3个类别
# 假设真实标签 (0表示第一个类别, 1表示第二个类别)
mock_targets = torch.tensor([0, 1], dtype=torch.long)
# 计算损失
mock_loss = criterion(mock_outputs, mock_targets)
print(f"模拟损失计算: {mock_loss.item():.4f}") # 应该是一个正数,越小越好
# 模拟优化器清零梯度和走一步
# 首先,需要让参数是可求导的,这里用一个假参数
mock_param = torch.tensor([1.0], requires_grad=True)
mock_loss_for_opt = mock_param * 2 # 模拟一个简单的损失与参数关系
mock_loss_for_opt.backward() # 反向传播,计算梯度
print(f"模拟参数梯度: {mock_param.grad}") # 梯度应为2.0
# 清空梯度
mock_optimizer = optim.SGD([mock_param], lr=0.1)
mock_optimizer.zero_grad()
print(f"清空梯度后,模拟参数梯度: {mock_param.grad}") # 梯度应为0.0
print("损失函数和优化器基本功能测试通过!")
print("-" * 50)3.3 驱动引擎:编写完整的训练循环
dart
def main_training_loop():
print("\n--- 1. 数据准备 ---")
# 1.1 定义图像预处理流程
transform = transforms.ToTensor()
# 1.2 加载MNIST数据集
train_dataset = datasets.MNIST('data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST('data', train=False, download=True, transform=transform)
# 1.3 创建DataLoader,用于批量加载数据
train_loader = DataLoader(dataset=train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=BATCH_SIZE, shuffle=False)
print(f"训练集样本数: {len(train_dataset)}, Batch数: {len(train_loader)}")
print(f"测试集样本数: {len(test_dataset)}, Batch数: {len(test_loader)}")
print("数据准备完成!")
print("\n--- 2. 模型、损失函数、优化器初始化 ---")
# 2.1 实例化模型并将其移动到指定设备 (GPU或CPU)
model = SimpleMLPClassifier(INPUT_DIM, HIDDEN_DIM, OUTPUT_DIM).to(DEVICE)
print("模型定义完成!")
# 2.2 损失函数与优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
print("损失函数和优化器设置完成!")
print("\n--- 3. 开始训练AI的"思考引擎" ---")
train_losses_history = [] # 用于记录每个Epoch的平均训练损失,以便可视化
for epoch in range(1, EPOCHS + 1): # 遍历每一个训练周期 (Epoch)
model.train() # 设置模型为训练模式
running_loss = 0.0 # 记录当前Epoch的总损失
# 遍历训练数据加载器中的每个Batch
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(DEVICE), target.to(DEVICE) # 将数据移动到指定设备
# 1. 清空上一轮的梯度 (重要步骤,否则梯度会累积)
optimizer.zero_grad()
# 2. 前向传播: 模型进行预测
outputs = model(data) # model(data) 会自动调用 model.forward(data)
# 3. 计算损失: 衡量预测结果与真实标签的差距
loss = criterion(outputs, target)
# 4. 反向传播: 计算每个参数对于损失的梯度 (魔法发生处!)
loss.backward()
# 5. 更新参数: 优化器根据梯度调整模型参数 (AI"学到"了)
optimizer.step()
running_loss += loss.item() # 累加当前Batch的损失
# 每隔一定步数打印一次训练进度
if batch_idx % 100 == 0:
print(f'Epoch: {epoch}/{EPOCHS}, Batch: {batch_idx}/{len(train_loader)} | Loss: {loss.item():.4f}')
epoch_loss = running_loss / len(train_loader) # 计算当前Epoch的平均损失
train_losses_history.append(epoch_loss)
print(f'====> Epoch {epoch} 训练完成!平均损失: {epoch_loss:.4f}')
print("\n训练循环完成!")
# --- 5.1 训练过程中的损失下降可视化 ---
print("\n--- 绘制训练损失趋势图 ---")
plt.figure(figsize=(8, 4))
plt.plot(range(1, EPOCHS + 1), train_losses_history, marker='o', linestyle='-')
plt.title("训练损失随周期下降趋势", fontsize=16)
plt.xlabel("训练周期 (Epoch)", fontsize=12)
plt.ylabel("平均损失", fontsize=12)
plt.grid(True)
plt.xticks(range(1, EPOCHS + 1)) # 设置X轴刻度
plt.tight_layout()
plt.savefig('mnist_results/training_loss_plot.png') # 保存图表
plt.show()
print(f"训练损失趋势图已保存到: mnist_results/training_loss_plot.png")
# 返回训练好的模型,供下一章评估和保存使用
return model, test_loader, DEVICE, OUTPUT_DIM
if __name__ == "__main__":
# 执行主训练流程
trained_model, test_loader_for_eval, final_device, num_output_classes = main_training_loop()
print("\n🎉 AI"识字"模型构建与训练完成!")
# 为了后续章节使用,可以简单保存模型权重
model_save_path = 'mnist_results/simple_mnist_mlp.pth'
torch.save(trained_model.state_dict(), model_save_path)
print(f"模型权重已保存到: {model_save_path}")第四章:逐行解析:为什么每行代码都如此重要?
让我们聚焦于for batch_idx, (data, target) in enumerate(train_loader):这个循环内部的**"五步真言"**,它们是驱动AI学习的精髓:

dart
# ... (在for batch_idx循环内部) ...
# 1. 清空上一轮的梯度 (重要步骤,否则梯度会累积)
optimizer.zero_grad() # ①
# 2. 前向传播: 模型进行预测
outputs = model(data) # ②
# 3. 计算损失: 衡量预测结果与真实标签的差距
loss = criterion(outputs, target) # ③
# 4. 反向传播: 计算每个参数对于损失的梯度 (魔法发生处!)
loss.backward() # ④
# 5. 更新参数: 优化器根据梯度调整模型参数 (AI"学到"了)
optimizer.step() # ⑤4.1 清空梯度
optimizer.zero_grad(): 【清空梯度】
作用:这是PyTorch训练循环中每个Batch处理前的必做第一步。它将优化器内部存储的,以及所有模型参数(model.parameters())上累积的梯度清零。
为什么重要? PyTorch的梯度计算默认是累加的。如果不清零,每次调用loss.backward()时,新计算的梯度就会和之前计算的梯度累加在一起。这将导致参数更新方向错误,模型无法正确学习。想象一下,你每次投篮(计算梯度)后,不是根据这次投篮的偏差来调整下次的动作,而是把之前所有投篮的偏差都加起来调整,结果可想而知。
对应概念:这是"优化器"在准备"纠错笔"前的"擦除"动作。
4.2 深入数据流:model(data)
outputs = model(data): 【前向传播:模型进行预测】
作用:这是前向传播(Forward Pass)。我们将当前批次的数据 data(形状 BATCH_SIZE, 1, 28, 28)喂给我们的神经网络模型 model。
内部发生:模型会执行其 forward 方法中定义的计算逻辑(即fc1 -> ReLU -> fc2),数据流经模型的各个层,进行线-性变换和非线性激活。
输出:模型返回其对每个输入样本的预测结果 outputs。对于我们的MLP分类器,outputs 的形状是 BATCH_SIZE, OUTPUT_DIM(例如 64, 10),代表每个样本对10个类别的原始分数(Logits)。
对应概念:这是"模型"的"大脑"在"感知"数据后,给出其"预测"或"认知"。
4.3 误差评估:loss_fn(...)
loss = criterion(outputs, target): 【计算损失:衡量误差】
作用:我们用之前实例化的损失函数 criterion(nn.CrossEntropyLoss),来计算模型预测 outputs 和真实的标签 target 之间的"差距"。
内部发生:nn.CrossEntropyLoss 会对 outputs(Logits)内部执行Softmax,将其转换为概率分布,然后计算这个概率分布与真实标签(被转换为one-hot编码)之间的负对数似然损失。
输出:得到一个标量值 loss,这个值越大,表示模型的预测与真实情况偏差越大。
对应概念:这是"损失函数"在扮演"成绩单"的角色,量化AI的"错误"。
4.4 智慧回溯:loss.backward()
oss.backward(): 【反向传播:智慧回溯】
作用:这是PyTorch的"魔法时刻"------反向传播(Backpropagation)。
内部发生:PyTorch的Autograd引擎会利用在outputs = model(data)这一步前向传播过程中自动构建的计算图(Computation Graph)。它从最终的 loss 开始,沿着计算图,逆向地(从输出层到输入层)应用微积分的链式法则,高效地计算出模型中所有可学习参数(如fc1和fc2的权重和偏置)相对于这个 loss 的偏导数(梯度)。
这些计算出的梯度,会被存储在每个参数的 .grad 属性中。
对应概念:这是"反向传播"在扮演"反思录"的角色,将"错误的信号"层层传递,指明每个参数应该如何调整。
4.5 调整认知:optimizer.step() 与 optimizer.zero_grad()
optimizer.step(): 【更新参数:调整认知】
作用:这是参数更新。优化器 optimizer 会根据刚刚在loss.backward()中计算出来的梯度(存储在参数的.grad属性中),以及优化器自身预设的算法(例如Adam),来实际调整模型的参数值。
内部发生:例如,对于最简单的梯度下降,它会执行 param = param - learning_rate * param.grad。Adam会执行更复杂的更新逻辑。
对应概念:这是"优化器"在扮演"纠错笔"的角色,根据反思的结果,实际"修改"AI的"大脑"连接,使它下次预测得更准确。
第五章:监控与总结:AI"学得怎么样"?
5.1 训练过程中的损失下降可视化
在main_training_loop函数执行完毕后,我们通过plt.plot(range(1, EPOCHS + 1), train_losses_history, ...)来绘制损失下降趋势图。这张图是判断模型是否在正确学习的最直观方式。
正常情况下,你会看到随着训练周期的增加,损失曲线会不断下降,这说明模型的预测越来越接近真实标签,它的"识字"能力正在不断提高。
第六章 总结:你已拥有AI学习的"核心引擎"
恭喜你!今天你已经亲手构建并运行了一个完整的AI学习循环。这不仅仅是一段代码,更是你对AI如何"学与思"的最深刻、最直观的理解。
✨ 本章惊喜概括 ✨
| 你掌握了什么? | 对应的核心操作/概念 |
|---|---|
| AI学习的整体流程 | ✅ 数据->模型->损失->反向传播->优化 的五步循环 |
| 神经网络的搭建 | ✅ nn.Module类定义,nn.Linear与激活函数 |
| 驱动AI学习的核心 | ✅ criterion, optimizer 的实例化与使用 |
| 深度理解"五步真言" | ✅ optimizer.zero_grad(), model(data), loss.backward(), optimizer.step() 的作用与原理 |
| 监控学习效果 | ✅ 训练损失的可视化分析 |
| 你现在不仅仅是"听说过"这些概念,你已经能够亲手将它们串联起来,并让一个AI模型真正地"动"起来,开始"学习"了! 这是你AI旅程中最重要的"里程碑"之一。 | |
| 🔮 敬请期待! 在下一章**《AI的"能力考":模型评估、保存与加载》中,我们将完成AI学习流程的最后闭环。你将学会如何准确评估你的AI学得有多好,以及如何将它的"智慧"安全地保存下来**,以便未来能够重新加载并投入使用! |