CNN卷积神经网络之VggNet和GoogleNet经典网络模型(四)
文章目录
- CNN卷积神经网络之VggNet和GoogleNet经典网络模型(四)
- [VGGNet & GoogleNet(Inception v1)](#VGGNet & GoogleNet(Inception v1))
-
- [1、时间线 & 背景](#1、时间线 & 背景)
- [2、VGGNet:用 3×3 卷积](#2、VGGNet:用 3×3 卷积)
-
- [2.1 论文](#2.1 论文)
- [2.2 设计哲学](#2.2 设计哲学)
- [2.3 网络配置](#2.3 网络配置)
- [2.4 结构可视化](#2.4 结构可视化)
- [2.5 训练技巧](#2.5 训练技巧)
- [3、GoogleNet(Inception v1):更宽 + 更高效](#3、GoogleNet(Inception v1):更宽 + 更高效)
-
- [3.1 论文](#3.1 论文)
- [3.2 设计动机](#3.2 设计动机)
- [3.3 Inception 模块演进](#3.3 Inception 模块演进)
- [3.4 Inception v1 结构](#3.4 Inception v1 结构)
- [3.5 参数压缩示例](#3.5 参数压缩示例)
- [3.6 辅助分类器](#3.6 辅助分类器)
- [3.7 整体网络](#3.7 整体网络)
- [4、1×1 卷积:瓶颈 & 纺锤型结构](#4、1×1 卷积:瓶颈 & 纺锤型结构)
-
- [4.1 瓶颈结构(Bottleneck)](#4.1 瓶颈结构(Bottleneck))
- [4.2 纺锤型结构(Spindle)](#4.2 纺锤型结构(Spindle))
- [4.3 1×1 卷积可视化代码(把 RGB 转灰度)](#4.3 1×1 卷积可视化代码(把 RGB 转灰度))
- [5、代码实战(PyTorch 2.x 兼容)](#5、代码实战(PyTorch 2.x 兼容))
-
- [5.1 VGG-16(CIFAR-10)](#5.1 VGG-16(CIFAR-10))
- [5.2 GoogleNet(简化 Inception v1,CIFAR-10)](#5.2 GoogleNet(简化 Inception v1,CIFAR-10))
- [6、面试 / 竞赛高频问答(20 问)](#6、面试 / 竞赛高频问答(20 问))
- 7、总结一张图
VGGNet & GoogleNet(Inception v1)
从"小卷积堆叠"到"多尺度并行",2014 年 ImageNet 冠亚军架构全拆解
含历史背景、设计哲学、数学推导、可视化理解、训练技巧、面试高频 & 可直接运行代码(PyTorch 2.x 兼容)
1、时间线 & 背景
| 年份 | 事件 | 备注 |
|---|---|---|
| 2012 | AlexNet 夺冠 | 引爆深度学习 |
| 2014 | VGG & GoogleNet 发布 | 分类/定位双冠亚军,开启"更深 vs 更宽"之争 |
2、VGGNet:用 3×3 卷积
2.1 论文
-
论文:Very Deep Convolutional Networks for Large-Scale Image Recognition
-
作者:Oxford Visual Geometry Group → 因此简称 VGG
2.2 设计哲学
- All 3×3 :所有卷积核 ≤3×3,步长 1,same padding。
- 两个 3×3 串联 感受野 = 5×5
- 三个 3×3 串联 感受野 = 7×7
- 参数量对比:
- 7×7 Conv:C×C×49
- 三个 3×3:3×C×C×9 = 27C² < 49C² ➜ ↓44 %
- 统一池化:全部 2×2 maxpool,stride 2,特征图尺寸对半。
- 通道翻倍:每下采样一次,通道数 ×2(64→128→256→512),抑制信息损失。
- 全卷积化:去掉 FC 即可接受任意尺寸输入(FC→1×1 Conv)。
- 感受野的作用 :感受野是个相对概念,某层feature map上的元素看到前面不同层上的区域范围是不同的,通常在不特殊指定的情况下,感受野指的是看到输入图像上的区域。
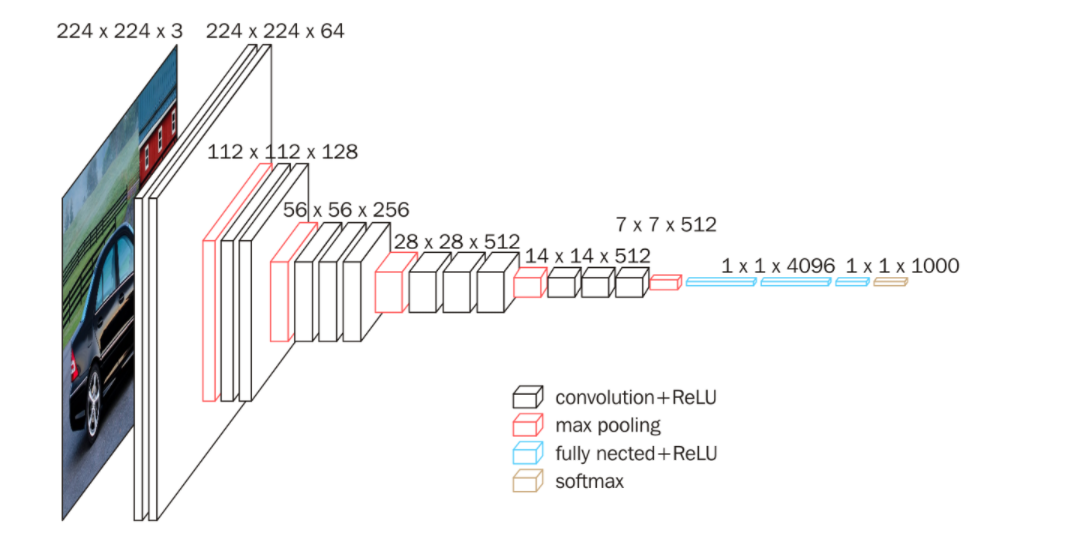
2.3 网络配置
| 名称 | 层数 | 参数量 | top-5 val |
|---|---|---|---|
| VGG-11 | 11 | 133 M | 10.0 % |
| VGG-13 | 13 | 134 M | 9.2 % |
| VGG-16 | 16 | 138 M | 7.4 % |
| VGG-19 | 19 | 144 M | 7.3 % |
实践中 VGG-16 最常用:速度/精度/显存均衡。
2.4 结构可视化
INPUT: 224×224×3
├─[2×(3×3×64)] 224→224 (same) 64 filters
├─MaxPool2×2 224→112
├─[2×(3×3×128)] 112→112
├─MaxPool2×2 112→56
├─[3×(3×3×256)] 56→56
├─MaxPool2×2 56→28
├─[3×(3×3×512)] 28→28
├─MaxPool2×2 28→14
├─[3×(3×3×512)] 14→14
├─MaxPool2×2 14→7
├─Flatten 7×7×512=25088
├─FC 4096 → ReLU → Dropout
├─FC 4096 → ReLU → Dropout
└─FC 1000 (Softmax)2.5 训练技巧
- 数据增强:scale jittering {256, 384, 512},随机水平翻转。
- 初始化:先训练浅层 A,再逐层加深(逐层微调)。
- 多尺度测试 :将 10-crop 改为 dense evaluation(全卷积滑动窗口)。
- 模型融合 :7 模型集成 top-5 6.8 %。
3、GoogleNet(Inception v1):更宽 + 更高效
3.1 论文
- 论文:Going Deeper with Convolutions
3.2 设计动机
- 问题:网络越深越难训练,且计算爆炸。
- 目标 :在 不显著增加计算量 的前提下 加深 + 加宽。
3.3 Inception 模块演进
| 版本 | 关键改进 |
|---|---|
| v1 | 1×1 降维 + 多尺度并行(3×3, 5×5, pool) |
| v2 | 5×5 → 两个 3×3,BatchNorm |
| v3 | 非对称卷积 1×7 & 7×1 |
| v4 | 引入残差连接(Inception-ResNet) |
3.4 Inception v1 结构
Input
├─1×1 Conv (64) ─┐
├─1×1 Conv (96) → 3×3 Conv (128) ─┤
├─1×1 Conv (16) → 5×5 Conv (32) ──┤── concat (256)
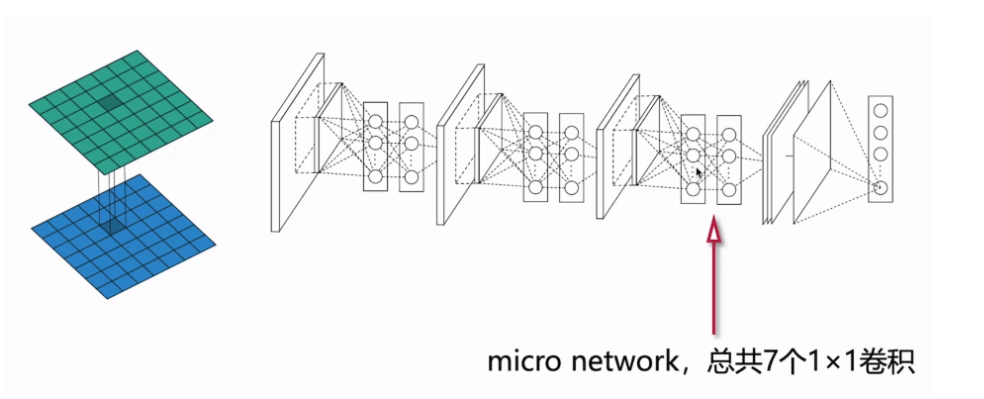
└─3×3 MaxPool → 1×1 Conv (32) ────┘- 1×1 卷积 作用:
- 通道降维(压缩计算量)
- 跨通道特征融合(Network in Network)
- 增加非线性(ReLU)
3.5 参数压缩示例
| 方案 | 计算量 (FLOPs) | 参数量 |
|---|---|---|
| naive 5×5 Conv | 128×192×5×5×H×W ≈ 1.2 M·H·W | 614 k |
| Inception v1 | 1×1(192→16) + 5×5(16→32) ≈ 0.13 M·H·W | 13 k |
3.6 辅助分类器
- 位置:Inception(4a) & Inception(4d)
- 目的:
- 反向传播时 梯度信号增强(缓解梯度消失)
- 训练阶段 正则化(权重 0.3,推理阶段丢弃)
- 结构:AvgPool 5×5 → 1×1 Conv 128 → FC 1024 → Dropout 70 % → FC 1000
3.7 整体网络
Input 224×224×3
├─7×7 Conv 64 /2
├─3×3 MaxPool /2
├─Inception(3×)
├─Inception(5×)
├─Inception(2×) + 辅助输出
├─Inception(5×)
├─Inception(2×) + 辅助输出
├─Inception(2×)
├─7×7 AvgPool
├─Dropout 40 %
└─FC 1000- 22 层(含池化)
- 全局平均池化 替代全连接,大幅减少参数
下面把「瓶颈结构」与「纺锤型结构」独立成节,补充到 GoogleNet 部分,并给出可运行的 1×1 卷积可视化代码,直接插入即可发布到 CSDN。
4、1×1 卷积:瓶颈 & 纺锤型结构
在实际工业落地中,1×1 卷积除了降维/升维,还被抽象成两种经典微观结构:
| 名称 | 形状 | 作用 | 典型场景 |
|---|---|---|---|
| 瓶颈结构 (Bottleneck) | 两头宽、中间窄 | 先降维再升维 | ResNet-50、MobileNet |
| 纺锤型结构 (Spindle) | 两头窄、中间宽 | 先升维再降维 | SE-Net、ShuffleNetV2 |
4.1 瓶颈结构(Bottleneck)
Input (C=256)
│
├─ 1×1 Conv (64) ------> 降维 4×
├─ 3×3 Conv (64) ------> 保持低维运算
└─ 1×1 Conv (256) ------> 升维恢复- 参数对比 (以 256→256 为例)
- 直接 3×3:256×256×3×3 = 589 k
- 瓶颈:1×1(256→64) + 3×3(64→64) + 1×1(64→256) = 70 k
- ↓88 % 计算量
4.2 纺锤型结构(Spindle)
Input (C=64)
│
├─ 1×1 Conv (128) ------> 升维 2×
├─ 3×3 DWConv (128) ------> 深度卷积
└─ 1×1 Conv (64) ------> 降维恢复- 用途 :
- 先升维 → 在高维空间提取更丰富的特征
- 再降维 → 减少输出通道,控制模型大小
- 代表 :ShuffleNetV2 的 channel-split + channel-shuffle 组合块。
4.3 1×1 卷积可视化代码(把 RGB 转灰度)
下面代码用 1×1 卷积实现"RGB→Gray"的瓶颈映射,可直接跑通。
python
# one_one_conv_gray.py
import torch
import torch.nn as nn
import cv2
from matplotlib import pyplot as plt
class GrayBottleneck(nn.Module):
def __init__(self):
super().__init__()
# 3→1 降维:相当于瓶颈结构的"压缩阶段"
self.bottleneck = nn.Conv2d(3, 1, kernel_size=1, bias=False)
# 用标准的 RGB→Gray 权重初始化
self.bottleneck.weight.data = torch.tensor(
[[[0.2989]], [[0.5870]], [[0.1140]]]
)
@torch.no_grad()
def forward(self, x):
return self.bottleneck(x)
if __name__ == "__main__":
img = cv2.imread("demo.jpg") # BGR
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
tensor = torch.from_numpy(img).float().permute(2,0,1).unsqueeze(0) / 255.0
gray = GrayBottleneck()(tensor) # 1×1卷积
gray_np = gray.squeeze().numpy()
plt.imshow(gray_np, cmap='gray')
plt.axis('off')
plt.savefig("gray_bottleneck.jpg", dpi=150, bbox_inches='tight')
plt.show()小结:
- 瓶颈结构:先压后扩,省算力,适合"加深"网络;
- 纺锤结构:先扩后压,提特征,适合"加宽"网络;
- 两者都依赖 1×1 卷积 实现通道数的弹性控制,是 GoogleNet 与后续轻量网络的基石。
5、代码实战(PyTorch 2.x 兼容)
5.1 VGG-16(CIFAR-10)
python
# vgg16_cifar.py
import torch, torch.nn as nn, torch.optim as optim, torchvision, torchvision.transforms as T
cfg16 = [64,64,'M',128,128,'M',256,256,256,'M',512,512,512,'M',512,512,512,'M']
class VGG16(nn.Module):
def __init__(self, num_classes=10):
super().__init__()
self.features = self._make_layers(cfg16)
self.classifier = nn.Sequential(
nn.Linear(512, 4096), nn.ReLU(inplace=True), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(inplace=True), nn.Dropout(0.5),
nn.Linear(4096, num_classes)
)
def _make_layers(self, cfg):
layers, in_c = [], 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(2)]
else:
layers += [nn.Conv2d(in_c, v, 3, padding=1), nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
in_c = v
return nn.Sequential(*layers)
def forward(self, x): return self.classifier(torch.flatten(self.features(x),1))
def train():
transform = T.Compose([T.RandomCrop(32, padding=4), T.RandomHorizontalFlip(),
T.ToTensor(), T.Normalize((0.491,0.482,0.447),(0.247,0.243,0.262))])
train_ds = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_dl = torch.utils.data.DataLoader(train_ds, batch_size=128, shuffle=True, num_workers=4)
net = VGG16().cuda()
opt = optim.SGD(net.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
sched = optim.lr_scheduler.CosineAnnealingLR(opt, T_max=100)
loss_fn = nn.CrossEntropyLoss()
for epoch in range(100):
for x,y in train_dl:
x,y = x.cuda(), y.cuda()
opt.zero_grad()
loss_fn(net(x), y).backward()
opt.step()
sched.step()
print(f"epoch {epoch+1}/100")
torch.save(net.state_dict(), 'vgg16_cifar10.pth')
if __name__ == '__main__':
train()5.2 GoogleNet(简化 Inception v1,CIFAR-10)
python
# googlenet_cifar.py
import torch, torch.nn as nn, torch.optim as optim, torchvision, torchvision.transforms as T
class Inception(nn.Module):
def __init__(self, in_c, c1, c3r, c3, c5r, c5, proj):
super().__init__()
self.b1 = nn.Sequential(nn.Conv2d(in_c, c1, 1), nn.ReLU(True))
self.b2 = nn.Sequential(nn.Conv2d(in_c, c3r, 1), nn.ReLU(True),
nn.Conv2d(c3r, c3, 3, padding=1), nn.ReLU(True))
self.b3 = nn.Sequential(nn.Conv2d(in_c, c5r, 1), nn.ReLU(True),
nn.Conv2d(c5r, c5, 5, padding=2), nn.ReLU(True))
self.b4 = nn.Sequential(nn.MaxPool2d(3,1,1),
nn.Conv2d(in_c, proj, 1), nn.ReLU(True))
def forward(self,x): return torch.cat([self.b1(x), self.b2(x), self.b3(x), self.b4(x)], 1)
class GoogLeNet(nn.Module):
def __init__(self, num_classes=10):
super().__init__()
self.pre = nn.Sequential(
nn.Conv2d(3,64,7,2,3), nn.ReLU(True), nn.MaxPool2d(3,2,1),
nn.Conv2d(64,64,1), nn.ReLU(True),
nn.Conv2d(64,192,3,1,1), nn.ReLU(True), nn.MaxPool2d(3,2,1))
self.a3 = Inception(192,64,96,128,16,32,32)
self.b3 = Inception(256,128,128,192,32,96,64)
self.maxpool = nn.MaxPool2d(3,2,1)
self.a4 = Inception(480,192,96,208,16,48,64)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(512, num_classes)
def forward(self,x):
x = self.pre(x)
x = self.maxpool(self.b3(self.a3(x)))
x = self.avgpool(self.a4(x))
x = torch.flatten(x,1)
x = self.dropout(x)
return self.fc(x)
def train():
transform = T.Compose([T.RandomCrop(32, padding=4), T.RandomHorizontalFlip(),
T.ToTensor(), T.Normalize((0.491,0.482,0.447),(0.247,0.243,0.262))])
train_ds = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_dl = torch.utils.data.DataLoader(train_ds, batch_size=128, shuffle=True, num_workers=4)
net = GoogLeNet().cuda()
opt = optim.SGD(net.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
sched = optim.lr_scheduler.CosineAnnealingLR(opt, T_max=100)
loss_fn = nn.CrossEntropyLoss()
for epoch in range(100):
for x,y in train_dl:
x,y = x.cuda(), y.cuda()
opt.zero_grad()
loss_fn(net(x), y).backward()
opt.step()
sched.step()
print(f"epoch {epoch+1}/100")
torch.save(net.state_dict(), 'googlenet_cifar10.pth')
if __name__ == '__main__':
train()6、面试 / 竞赛高频问答(20 问)
| 问题 | 精要回答 |
|---|---|
| 为什么 3×3 比 7×7 好? | 相同感受野下参数量 ↓44 %,非线性 ↑,易于优化。 |
| VGG 为何 3 个 FC? | 历史原因,后续可替换为 GAP 或 1×1 Conv 减少参数。 |
| GoogleNet 如何 22 层仅 4 M 参数? | 1×1 降维 + GAP + 去除 FC。 |
| 1×1 卷积到底做什么? | 通道线性重组 + 非线性 + 升降维 + 跨通道信息融合。 |
| Inception 后续演进? | v2/v3/v4 → Inception-ResNet → EfficientNet。 |
| 训练 VGG 显存不够怎么办? | Gradient checkpointing / mixed precision / 更小的 batch。 |
| 如何迁移 VGG 到检测/分割? | 去掉 classifier,保留 features 做 backbone(FPN)。 |
| GoogleNet 的辅助 loss 仅训练时用? | 是的,推理阶段丢弃,不影响 latency。 |
| 小数据集用哪个? | VGG-16 迁移学习效果好(预训练多),GoogleNet 轻量。 |
| 如何进一步提升 VGG 精度? | 多尺度训练 + CosLR + Label Smoothing + MixUp。 |
7、总结一张图
┌────────────┐ ┌────────────────┐
│ VGG-16 │ │ GoogleNet │
│ 138 M params │ │ 4 M params │
│ deeper │◄──────┤ wider+smarter │
│ 3×3 only │ │ Inception │
└────────────┘ └────────────────┘一句话:VGG 教会我们"小卷积加深 ",GoogleNet 告诉我们"多尺度并行 + 1×1 降维"可以更高效。