Github:
dvlab-research/LISA: Project Page for "LISA: Reasoning Segmentation via Large Language Model"
paper:
摘要
LISA(Large Language Instructed Segmentation Assistant)是一种开创性的多模态人工智能模型,它成功地将大型语言模型(LLM)的复杂推理能力与像素级图像分割任务相结合,催生了一个名为"推理分割"(Reasoning Segmentation)的新领域。该模型不仅能够理解简单的指代性词语(如"那只猫"),更能解析包含复杂关系、属性描述、空间逻辑乃至常识推理的自然语言指令,并据此在图像中生成高精度的分割掩码。本文将深入剖析LISA的核心架构、创新的工作原理、训练方法论、在多个基准测试上的量化性能,并探讨其在AI领域的深远影响。

1. 引言:从"分割"到"推理分割"的飞跃
传统的图像分割技术,无论是语义分割、实例分割还是全景分割,主要依赖于预定义的类别标签或简单的指代性描述。然而,现实世界的需求远比这复杂。用户可能希望分割"照片左侧所有看起来很旧的椅子"、"离狗最远的那个球"或者"图中所有可以食用的水果"。这些指令要求模型不仅要"看懂"图像,更要"理解"语言中的复杂逻辑和隐含的常识。
为了应对这一挑战,LISA应运而生。它旨在赋予模型一种全新的能力------推理分割 ,即根据复杂的、对话式的、包含多步推理的文本查询,精确地定位并分割出图像中的目标区域。LISA的出现,标志着计算机视觉从感知智能向认知智能迈出了重要一步,它不仅仅是一个分割工具,更是一个能够与用户进行深度语义交互的智能助手。
2. LISA的核心架构与"Embedding as Mask"范式
LISA的强大能力源于其精巧的架构设计,它将三个关键组件有机地融合在一起:一个强大的视觉编码器、一个先进的多模态大语言模型,以及一个创新的连接范式。
2.1 关键架构组件
LISA的架构并非从零开始,而是巧妙地站在了巨人的肩膀上,其主要组件包括: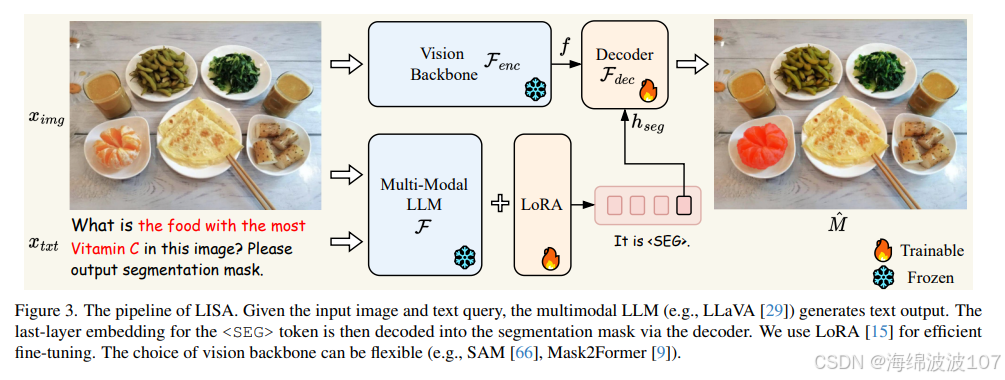
- 多模态LLM基础:LISA的核心是一个预训练好的多模态大语言模型(MLLM),例如LLaVA-7B-v1-1或LLaVA-13B-v1-1。这使得LISA天然继承了LLM强大的语言理解、生成和一定程度的图文关联能力 。
- 视觉编码器(Visual Encoder) :为了获得高质量的视觉特征,LISA采用了业界领先的 ViT-H SAM(Segment Anything Model) 作为其视觉骨干网络 。SAM以其强大的零样本分割能力和对图像细节的精细捕捉而闻名。在LISA的训练过程中,这个视觉编码器通常被冻结,以最大限度地保留其预训练阶段获得的强大视觉表征能力,同时降低训练成本。
- 特殊
_TOKEN:这是LISA架构中的一个精妙设计。研究者在LLM的词汇表中引入了一个新的特殊标记_TOKEN。当模型在生成文本回复时,一旦遇到这个标记,就意味着接下来的输出不再是文本,而是应该生成一个分割掩码。这个_TOKEN就像一个开关,巧妙地将语言生成任务引导至视觉分割任务。 - 投影层(Projection Layer γ) :为了让语言模型能够"理解"视觉编码器抽取的特征,LISA使用了一个多层感知机(MLP)作为投影层。该投影层将SAM输出的视觉特征(通道维度为256)映射到与LLM隐藏状态兼容的维度空间(例如256, 4096, 4096),从而搭建起视觉与语言之间的桥梁 。
- 解码器(Decoder Fdec) :这是一个专门用于生成最终分割掩码的解码器。与冻结的视觉编码器不同,该解码器在训练过程中被完全微调,以学会如何将
_TOKEN对应的嵌入向量转换为精确的像素级掩码 。
2.2 核心创新:"Embedding as Mask"范式
LISA最核心的创新在于提出了 "Embedding as Mask"(嵌入即掩码) 的范式。传统的多模态模型通常难以直接输出像素级的分割结果。LISA通过引入_TOKEN解决了这个问题。
其工作流程如下:
- 用户输入一张图像和一个复杂的文本指令(例如,"把那个被书本部分遮挡的杯子分割出来")。
- 图像经过冻结的SAM视觉编码器,生成丰富的视觉特征。
- 文本指令和处理后的视觉特征被一同输入到LLM中。
- LLM进行推理,理解指令中的"杯子"、"被书本遮挡"等复杂关系。
- 在生成回复时,LLM会在适当的位置输出
_TOKEN。 - 与
_TOKEN相关联的隐藏层嵌入(embedding)被提取出来。这个嵌入向量此刻已经蕴含了分割目标的所有信息。 - 这个嵌入向量通过可训练的解码器(Fdec),最终被解析并上采样,生成与原始图像大小一致的二值分割掩码。
这个范式优雅地将LLM的输出从离散的文本标记扩展到了连续的、富含空间信息的嵌入向量,并最终转化为像素级的视觉输出,从而实现了端到端的联合训练,这是LISA能够进行推理分割的关键所在。
3. 高效的训练方法与数据策略
为了激发并对齐LLM的推理能力和分割能力,LISA采用了一套精心设计的训练策略。
-
高效微调策略 :考虑到从头训练一个大型多模态模型的巨大成本,LISA主要采用了 LoRA(Low-Rank Adaptation) 的低秩自适应微调技术 。这种方法只针对模型中的一小部分参数进行更新,例如投影层γ、LLM的词元嵌入(token embeddings)和语言模型头(lm head),而模型的大部分权重保持不变。这不仅极大地提高了训练效率(例如,可以在8块24G显存的3090 GPU上完成训练 ,还最大限度地保留了LLM在预训练阶段学到的海量知识 。
-
多元化的训练数据:LISA的训练并非仅依赖于推理分割数据,而是采用了一个包含多种类型数据集的"鸡尾酒"方案,以确保模型的全面能力:
- 语义分割数据集:使用ADE20K、COCO-Stuff等大规模数据集,奠定模型基础的像素级分割能力。
- 指代分割数据集:用于训练模型理解简单的指代关系。
- 视觉问答(VQA)数据集:用于维持和增强模型的多模态对话与理解能力。
- 推理分割数据集(ReasonSeg) :这是LISA训练的"点睛之笔"。该数据集包含图像-复杂指令对,专门用于微调模型的推理分割能力。值得注意的是,即使只使用非常少量的推理分割数据(例如,仅239个图像-指令对),LISA的性能也能得到显著提升,展示了其强大的学习潜力 。

4. 全方位性能评估与量化分析
LISA的性能在多个维度和基准上得到了验证。评估主要采用 gIoU(全局交并比) 和 cIoU(类别/累积交并比)。其中,gIoU是所有图像IoU的平均值,而cIoU会受物体面积大小影响,因此gIoU通常被认为是更稳定、更鲁棒的评估指标。
4.1 在标准语义分割基准上的表现
消融实验表明,不同训练数据的组合对LISA的泛化能力有显著影响。在一项研究中,研究者对比了不同训练数据配置下的模型表现 :
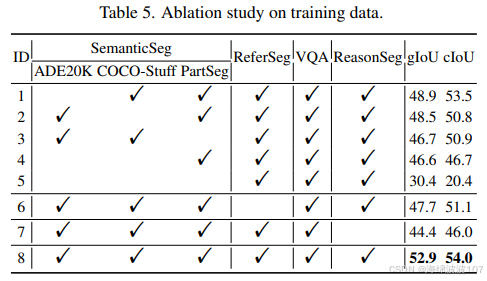
从上表可以看出,使用全部数据集(ID 8)训练的模型在ADE20K和COCO-Stuff上均取得了最佳性能。而当移除语义分割数据后(ID 5),模型在ADE20K上的性能急剧下降,这证明了基础分割数据对于模型能力的重要性。
4.2 在核心任务"推理分割"基准(ReasonSeg)上的表现
ReasonSeg是检验LISA核心能力的试金石。
-
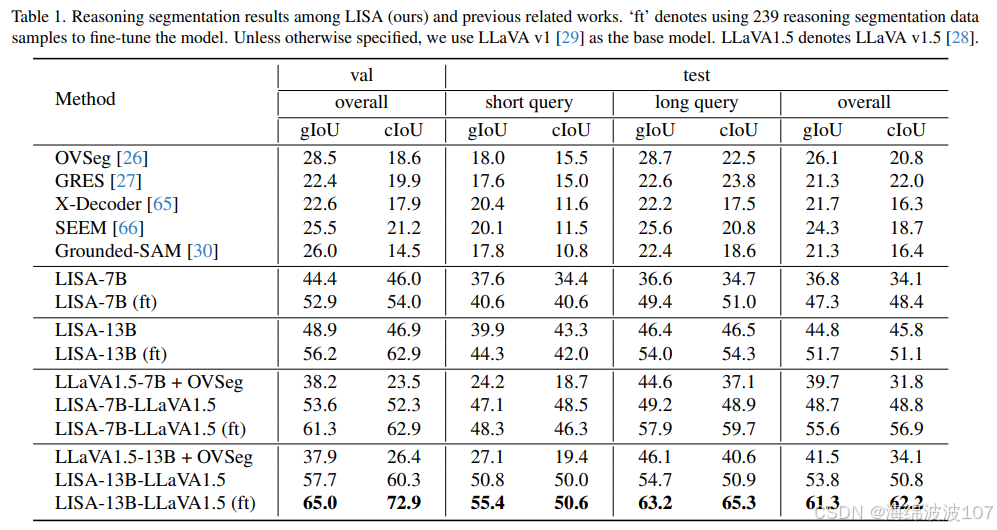
零样本能力 :LISA展现了惊人的零样本推理分割能力。在没有经过任何ReasonSeg数据微调的情况下,仅依靠从其他数据集中学到的泛化知识,LISA-13B在ReasonSeg验证集上的零样本表现就达到了gIoU 48.9% 和 cIoU 46.9% 。这充分说明其架构本身就具备引导LLM进行视觉推理的潜力。
-
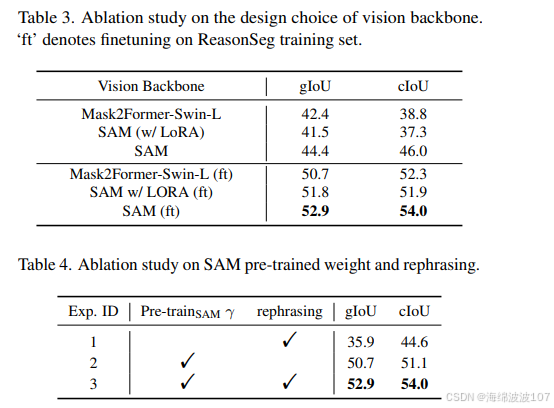
基础模型与微调后性能 :LISA基础模型(使用SAM作为骨干,未在ReasonSeg上微调)在ReasonSeg-Sem验证集上的gIoU为44.4 ,cIoU为46.0 。经过ReasonSeg训练数据微调后,性能显著提升,gIoU达到52.9 ,cIoU达到54.0 。这再次验证了少量特定任务数据微调的有效性。
4.3 LISA++:性能的再进化
LISA的后续改进版LISA++ 通过引入新的指令微调数据,进一步优化了实例分割和对话分割能力 。
-
在ReasonSeg-Sem上的飞跃 :LISA++在ReasonSeg-Sem验证集上的表现极为出色,其gIoU达到了63.8% ~ 64.2% ,cIoU达到了67.0% ~ 68.1%(不同来源报告的数值有微小差异)。相比于LISA基础模型,这是一个巨大的性能飞跃,提升幅度在gIoU上约1.4%-1.5%,在cIoU上约2.6%-2.7% 。
-
在ReasonSeg-Inst上的评估 :对于实例级的推理分割任务(ReasonSeg-Inst),LISA++采用了更适合实例分割的COCO标准指标 进行评估,而不是gIoU/cIoU 。在COCO零样本实例分割基准上,LISA++的表现同样亮眼,取得了AP50: 34.1, AP75: 22.1, mAP: 21.5的成绩 。
5. 与其他模型的对比
将LISA置于更广阔的背景下进行比较,更能凸显其独特性和先进性。
-
与通用零样本分割模型的比较(如SEEM, OpenSeg) :目前,在所提供的搜索结果中,缺乏LISA与SEEM或OpenSeg在同一零样本分割基准下的直接定量对比数据 。尽管多个搜索结果提及了SEEM或OpenSeg,但均未提供其在COCO零样本实例分割任务上的AP50、AP75等可比指标 。然而,LISA被反复描述为具有"强大的零样本能力",并且其设计的核心就是为了处理复杂的、需要推理的指令,这在任务的复杂性上可能已经超越了传统的零样本分割模型 。
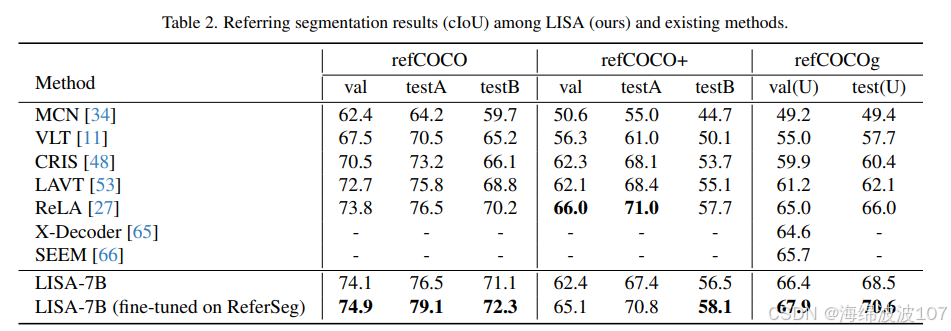

-
与LLM-Seg的比较:虽然是间接证据,但有研究指出,另一个基于LLM的分割模型LLM-Seg,在其cIoU指标上比LISA低了约10个百分点 。这从侧面反映了LISA在推理分割领域的领先地位和其架构设计的有效性。
6. 结论与展望
LISA不仅仅是一个模型,它更是一种范式,为解决需要深度语义理解的视觉任务开辟了一条全新的道路。
核心贡献总结:
- 开创"推理分割"任务:LISA定义并解决了一个全新的、更接近人类认知方式的视觉任务。
- 提出"Embedding as Mask"范式:通过这一创新,LISA优雅地将LLM的符号推理能力与计算机视觉的像素级操作无缝对接,实现了端到端的训练。
- 展示LLM的潜力:LISA证明了大型语言模型可以作为一种"通用接口"或"大脑",通过少量任务相关的微调,就能被引导去完成全新的、复杂的、跨模态的任务。
未来展望:
LISA的成功也为未来的研究指明了方向。可以预见,未来的工作将围绕以下几点展开:
- 提升效率与泛化性:探索更轻量级的模型架构和更高效的训练方法,降低其应用门槛。
- 扩展推理维度:将推理分割能力从静态图像扩展到动态视频(推理视频分割)乃至三维场景中。
- 增强对话与交互:发展更强大的对话能力,允许用户通过多轮澄清、修正和追问来 refining 分割结果,使其成为真正意义上的智能视觉助手。
总而言之,LISA是多模态AI发展史上的一个重要里程碑。它清晰地展示了,当语言的强大推理能力与视觉的精准感知能力相结合时,人工智能将能解决远比以往更加复杂和微妙的问题,向通用人工智能的目标又迈进了坚实的一步。