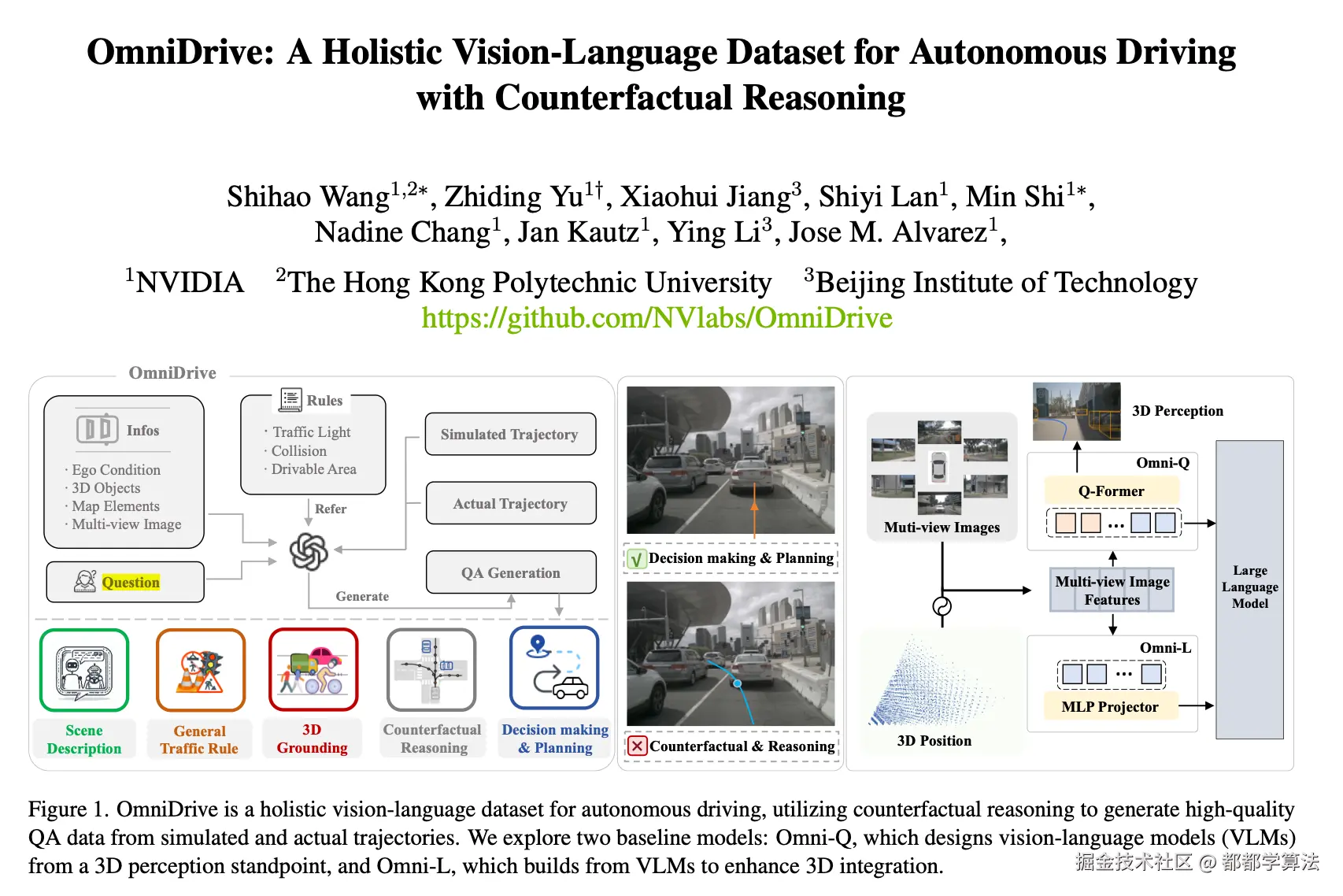
论文:OmniDrive: A Holistic Vision-Language Dataset for Autonomous Driving with Counterfactual Reasoning
背景与动机
2D 视觉语言模型(VLM)的快速发展及其强大的推理能力促进了端到端自动驾驶应用的出现。然而,对实际工程落地来说,将 VLM 的推理能力从 2D 扩展到完整的 3D 理解是一个主要的难点。尽管之前的很多工作已经证明了 LLM Agent 在自动驾驶应用的成功性,但是作者认为一个完整的框架是非常有必要的(包括数据集到 LLM Agent 的设计),作者也因此提出了 OmniDrive,通过反事实推理将 Agent 模型与 3D 自动驾驶任务保持一致,进而将 VLM 的 2D 理解和推理能力充分扩展到 3D 几何和空间理解。这种方法通过评估潜在场景及其结果来增强驾驶决策,类似于人类驾驶员考虑其他可供选择的行动。
Tips:
反事实推理 Counterfactual reasoning,来自因果推理领域的一个核心思想,指的是在当前事实(已知轨迹/状态)基础上,去推想"如果当时不是这样,而是另一种情况,会发生什么"。
另外,关于自动驾驶 VLM 的设计也面临一个基本的问题,是将现有的 2D VLM 进行 3D 空间对齐,还是将当前已有的 3D 感知堆栈集成到视觉语言框架中。作者根据这两条思路,提出了 Omni-L 和 Omni-Q 两个 LLM-agent 架构,分别代表了从 2D VLM 向 3D 迁移,以及从传统 3D 感知堆栈向 VLM 迁移的两种路径探索。
现有工作的不足
许多数据集以问答 (Q&A) 数据集的形式呈现,用于推理或路径规划类的 LLM Agent 的训练和基准测试。目前很多路径规划的基准测试,依然是在真实数据上采用专家轨迹、开环评估的方式。
开环评估局限性
- 对自车状态存在隐性的偏差
- 过于简单的规划场景
- 容易过度适应专家轨迹
Tips:
开环 Open-loop: 模型只输出预测,不真的控制车辆。
专家数据局限性
- 仅提供稀疏监督,主要反映安全的轨迹,而没有深入研究复杂的决策和潜在的推理过程
主要工作
OmniDrive Dataset
针对开环评估中专家数据的局限性,作者提出基于反事实推理的合成数据标注过程,将反事实推理与 VLM 的思维链功能相结合,建立规划轨迹和基于语言的推理之间的联系。大致流程:
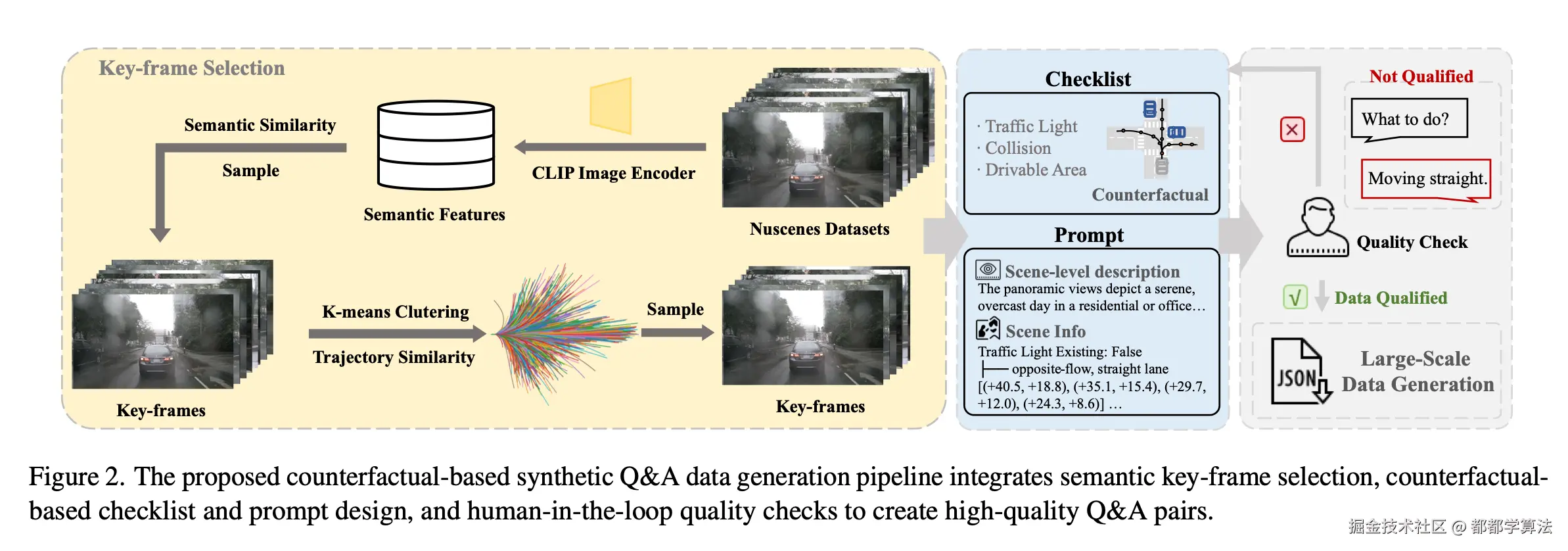
主要需要从 Nuscenes 数据集中进行关键帧筛选,并基于反事实推理设计 checklist 及 prompt,再进行质检,进而生成可用数据,整体确保所生成数据的可靠性和可解释性。
OmniDrive Agent
作者提出了两个多模态基础模型框架 Omni-L 和 Omni-Q,探讨了 LLM 在自动驾驶任务中的集成方式。
- Omni-L 借助 LLaVA 的多模态投影方式将 2D 图像与语言模型对齐
- Omni-Q 则基于 StreamPETR 和 Q-Former 的 BEV + Query 架构构建 3D 感知-语言对齐路径
这两个方案分别代表了"从 2D 向 3D 迁移"与"将现有 3D 感知融入 VLM"的两种范式,论文实验证明前者更高效。
方法与技术方案
OmniDrive Dataset 生成技术
Step1:筛选面向路径规划的关键帧
- 使用 CLIP 模型从 nuScenes 数据集中提取正前视图图像的语义 embeddings,使用这些 embeddings 做 K-means 聚类,选出前 20% 的聚类中心帧。目标是覆盖如红绿灯、道路标志、车辆、行人等静态与动态要素。
- 再基于自车未来轨迹的动态行为做聚类,以期保留动态行为多样的场景,例如:左转、急刹、变道等。
Tips:
CLIP 是 OpenAI 在 2021 年提出的一个视觉-语言对齐模型,全称是 Contrastive Language--Image Pretraining,它的基本思想是,输入一张图像和一段文本,训练一个模型,让图像和描述这张图的文本之间的表示距离尽可能接近(相似),同时让不相关图文的表示距离尽可能远。
Step2:设计反事实推理 checklist 及 prompt
上一步聚类了所有原始轨迹,提取代表性的轨迹类别,每个类别代表一种行为(如左转、右转、加速)。这一步生成 prompt 时,会对某一具体场景,模拟其它可能的驾驶行为(Simulated trajectories)。接着,通过一个基于交通规则的 checklist 来评估这些模拟轨迹是否合法或安全。这种方式既拓展了数据的多样性,也为后续的大模型生成问答提供了更扎实的训练语料。
Tips:
比如这个场景中真实的车辆是"右转",那么就在这个同样的环境中,模拟左转、直行、掉头、加速等轨迹。这就构成了反事实推理:如果不是右转,而是左转会怎么样?如果掉头会不会违章?
checklist
这边 checklist 应该只是作为生成完整 prompt 中间过程的辅助工具。
- rule-based checklist:
对于一些固定的交通违规类型(比如:撞上障碍物、越界、闯红灯),使用已有的数据标注,用程序规则直接判断。
- counterfactual reasoning based checklist:
仅靠前面这些已有标注,无法覆盖所有交通规则,比如一些复杂语义问题。因此,作者将模拟轨迹转换为高层决策信息,再用 GPT-4 对图像进行分析,判断这些行为是否符合交通规则、是否安全。
Tips:
复杂语义、高层决策信息是指,比如这个轨迹是换道?加速?变道?超车?属于哪个车道?打算和哪个目标互动?换道时是否打灯?当前环境是否适合变道?与对向车道是否安全?
总结 prompt
-
Caption: 用自然语言描述图像场景,简化原始复杂 3D 感知信息,让 GPT 更好地理解环境,提高 Q&A 数据质量。
-
Expert trajectory & Relevant objects: 从 nuScenes 拿来的真实轨迹,把轨迹分类为左转、直行、加速等语义行为。另外,在轨迹附近 3 秒内靠得比较近的物体,供 GPT 理解刻画场景中可能产生交互的关键元素。
-
Simulated trajectories & checklist: 模拟当前场景可能的驾驶行为,配合 checklist 得到各种可能驾驶行为的评估结果。
Step3:生成 Q&A
将前面的 prompt 输入给 GPT-4,并设计了 Question?(并没有看到是人为设计还是自动设计的)然后由 GPT-4 基于 prompt 自动生成 Answer,另外还加入了人工审核,确保最终的数据质量是可靠的。一旦 prompt & pipeline 成熟,具备泛化能力,就开始大规模自动生成数据。
OmniDrive Agent
Omni-L 促使 MLP 从 LLaVA 向多视角图像特征与语义 embedding 对齐的方向转变。Omni-Q 的灵感来自 StreamPETR 的 BEV 架构,并结合了Q-Former 的设计,以构建 LLM 与传统 3D 自动驾驶任务之间的交互。两者共享一个视觉 encoder 来提取多视角特征,提取的图像特征融合了位置编码,然后输入给特征映射模块。在这个特征映射模块中,视觉特征和文本特征进行了对齐,然后再输入给 LLM,形成文本生成任务。
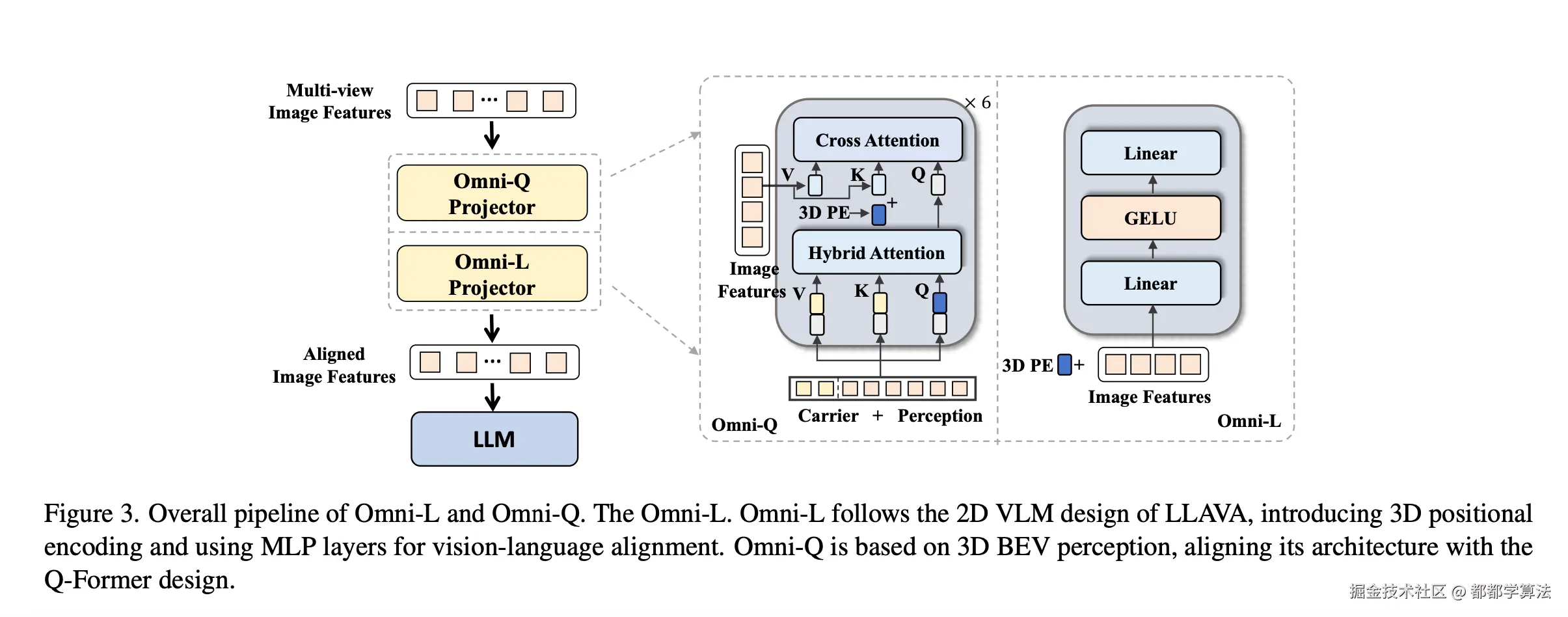
Omni-L 和 Omni-Q 的主要区别是中间的特征映射模块,Omni-L 侧重于视觉-语言特征对齐,Omni-Q 侧重于 3D 感知任务。
Omni-L
Omni-L 借鉴了 LLaVA 的设计思想,用一个简单的多层感知机(MLP),把图像 encoder 提取的视觉特征送入语言模型之前,进行对齐。这个 MLP 的作用是把图像的特征投影到语言模型可以理解的空间里。
LLaVA 原来只处理单张图像。Omni-L 支持多视图图像,另外,为了让 LLM 区分图像是从哪里拍的,还给每个图像 patch(图像块)都加上了 3D 位置编码。
合理推测,让 LLM 针对 2D 图像建立 3D 空间语义理解的核心在于:
- 3D 位置编码
- 把图像的特征投影到语言模型可以理解的空间里,即将 2D 图像与文本特征对齐
- 3D 场景空间的结构化、高质量的 Prompt
Plugin:
Omni-Q
Omni-Q 模型结合了两种技术路线:Q-Former (用于将视觉特征和语言模型对齐的模块,来自 BLIP-2)和StreamPETR(基于稀疏查询的 3D 感知模型,使用查询机制来感知 3D 场景)。
Omni-Q 的目标是让 VLM 具备空间定位和多模态生成能力。因此,Omni-Q 主要包括两类查询:
- Detection queries Qd:用于进行 3D 感知(如物体检测、3D 位置预测等)
- Carrier queries Qc:最终会送到 LLM 中去,用于多模态对齐和生成(如生成回答、描述等)。
这两种查询在 Projector 的 Transformer decoder 中进行自注意力交互。然后从图像中进行跨模态的信息聚合,即交叉注意力交互。
Plugin:
实验结果与贡献
训练策略
2D 预训练 + 3D 微调。
Omni-L 和 Omni-Q 在功能定位上不同,前者目标是从多视角 2D 图像 + 文本中建立对 3D 场景的语义理解和对齐,例如识别"哪个车在我左侧"、"是否闯红灯"等;后者专注于将 3D 感知任务中的输出结果(如轨迹、检测框)转化为文本描述或问答结果,即从 3D 感知到语言生成。那为什么能共用一套训练策略?
因为虽然任务不同,但底层结构是高度共享的,包括:
- 多视图图像编码器(通常是 ViT 或其变体)
- Q-Former(或 MLP Projector):用于从图像中提取对语言有用的 token/query
- LLM:最终生成文本
这三者的连接方式是类似的,所以:
| 阶段 | 如何适用于 Omni-L | 如何适用于 Omni-Q |
|---|---|---|
| 2D 预训练 | 让模型学会从多图像中提取有用语义、对齐语言空间 | 初始化视觉语言对齐模块(如 Q-Former),打通图像到文本的通道 |
| 3D 微调 | 用多视角图像 + 3D提示词(prompt)帮助模型建立空间语义理解 | 加入 3D 感知模型(如 StreamPETR)的输出,监督模型生成正确自然语言 |
实施细节
-
视觉编码器:EVA-02-L,其输出特征是对齐文本语义空间的,跟 CLIP 类似
-
2D Pretraining 阶段:沿用 LLaVA v1.5 的训练策略,这个阶段主要是训练视觉特征 → Q-Former/MLP Projector → LLM 之间的基本语义对齐能力
-
3D Finetuning 阶段:只讲了不同模块 Optimizer 和超参数设置,没看到其他细节
-
其他变体:作者还尝试了 BEV-MLP 路线,探索用 BEV 空间作为语义场景表示,是否更利于语言生成和对齐。
数据集和评估指标
两种数据集:作者自建的数据集 OmniDrive,公开数据集 DriveLM
OmniDrive
在 OmniDrive 上支持以下几种任务:
| 任务类型 | 说明 | 对应评估指标 |
|---|---|---|
| Captioning | 包括场景描述和关注目标选择 | 使用语言生成指标:- CIDEr: 句子相似度指标,衡量生成描述与参考描述的相似性 |
| Open-loop Planning | 预测未来轨迹,但不执行,仅做离线评估 | 沿用 BEV-Planner 的指标:- Collision Rate:预测轨迹中与障碍物发生碰撞的比例 |
-
Intersection Rate with Road Boundary :轨迹越界进入非可行驶区域的频率 | | Counterfactual Reasoning | 反事实推理,比如如果选择另一个动作会不会更安全等 | 使用 GPT-3.5 辅助评估:- 对模型预测结果,让 GPT-3.5 自动提取关键词(如 "安全"、"碰撞"、"闯红灯"等)
-
将提取出的关键词与人工标注的 Ground Truth 对比
-
计算各类事故类型的 Precision 和 Recall |
DriveLM
DriveLM ****是一个已有的公开多模态自动驾驶语言理解数据集,用于测试模型在图视觉问答(Graph Visual Question Answering,GVQA )任务中的表现。
评估指标:
-
文本生成类指标:
- BLEU
- ROUGE-L
- CIDEr
-
多选类题目:
- Accuracy
-
开放式问答(Open-ended QA):
- ChatGPT Score(让 GPT 来评判生成回答的合理性)
-
感知能力评估:
- Match Score:衡量模型预测的 2D 框与 Ground Truth 框的匹配程度
实验结论
OmniDrive Agent
-
使用 VLM 并加入车辆自身状态时,Omni-L/Q 在开环路径规划的表现可以接近传统最优方法。
-
和 BEV-Planner 的结论一致:车辆自身状态是规划模型的关键信息,加上之后性能显著提升。
-
轨迹对齐 ≠ 真正的语义合理性,语言模型如果过于依赖自车状态,可能忽略其他关键视觉线索,导致语义上不安全。
-
Omni-L 拥有更强的视觉语言建模能力,在没有自车状态帮助的情况下依然能保持较好表现。
-
问答式训练能提升模型在 open-loop planning 中对分布建模的泛化能力,且增强了语言模型对规划语义的理解,提升了路径安全性。
-
Omni-L 在语言主导的反事实推理任务中表现更优,适用于需要语义推理的场景;而 Omni-Q 借助 3D 感知监督,在空间理解任务(如碰撞预测)中召回率更高;仅使用 BEV+MLP 方法表现不佳。
OmniDrive Dataset
-
如果只用 DriveLM 数据集训练,模型得分是 53%;加入 OmniDrive 数据集后,提升了 3 个百分点,说明 OmniDrive 对泛化能力和任务理解都有帮助。
-
即使已经用了 LLaVA-665K 这种大规模通用 VLM 预训练数据,再加 OmniDrive 依然显著提升性能。
-
贡献上来说,OmniDrive Dataset 在大规模、自动化的前提下,通过反事实校验与人工验证机制,保持了标注的高质量。
总结
作者提出了 OmniDrive 框架,通过构建反事实 3D 驾驶问答流程,结合语言模型与多视图感知,实现了高质量数据生成与显著性能提升。两个模型 Omni-L 与 Omni-Q 分别展示了语言-视觉对齐与3D感知融合在智能驾驶中的潜力。但目前的评估仍局限于开环推理,尚未考虑多车交互下的闭环反馈,后续将借助更真实的仿真环境进一步优化。