最近参考 CUDA 入门教程,想记录自己学习和思考的过程。根据这份参考教程,整体分为将以下两个部分:
- CPU 版本 vs CUDA 版本代码及要点
- CUDA 版本 vs CUDA 并行版本代码及性能对比
在这篇博客中围绕第一部分进行展开讨论。
官方手册:CUDA C 编程官方文档
CPU 版本 vs CUDA 版本代码及要点
内存分配
为什么需要传递指针的地址?
在下面这行代码中:
c
float *x;
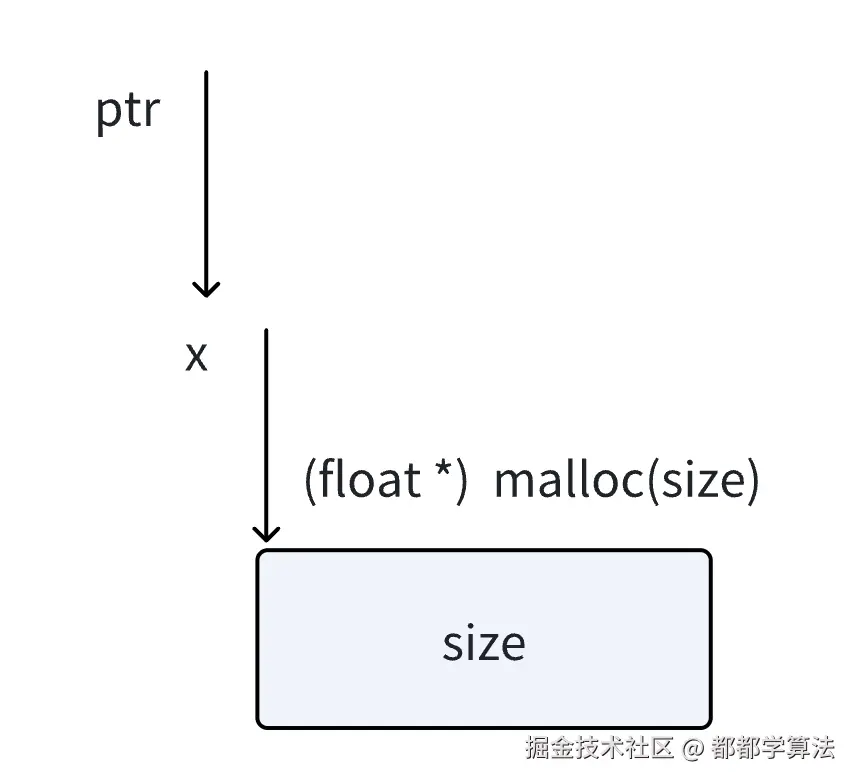
cudaMallocManaged(&x, N * sizeof(float));x 是一个指针变量,如果想要在函数内部(这里是 cudaMallocManaged)修改它的值 (即让它指向新分配的内存),就必须把它的地址传进去。这是因为函数参数默认是值传递,直接传x无法修改它本身的值。
将上面的接口类比 C 中的行为,如下:
arduino
void myMalloc(float **ptr, size_t size) {
*ptr = (float*) malloc(size);
}float **ptr 声明了 ptr,是一个指向指针的指针,*ptr 则是 ptr 指向的那个指针本身;
malloc(size) 是申请了 size 大小的地址,返回 void * 类型的指针,将其转换成 (float *) 类型的指针;
将转换后的指针的值,赋值给 *ptr,即赋值给 ptr 指向的那个指针本身;
那么 ptr 指向的指针本身就是申请的这块内存的地址;
如果我们调用 myMalloc(&x, size),&x 就是 ptr,那么 x 这个指针的地址,是一个被指向的指针;
那么 ptr 指向的就是 x,*ptr 就是 x;
那么前面得到的 (float*) malloc(size),就赋值给了 x 本身;
一个指针本身,代表的就是它指向哪里,那么就可以理解为,x 指向的内存地址,就是 (float*) malloc(size)。
Tips:
cudaMallocManaged不是直接 malloc 一段主机内存,而是申请一段可以在 CPU 和 GPU 上都访问的统一内存。
为什么不是像 malloc() 一样直接返回指针?
在 C 语言中,我们常见的内存申请方式是:
c
float *x = (float *) malloc(N * sizeof(float))malloc 会返回一段主机内存的地址,我们直接将它赋值给指针变量即可,非常简洁。但在 CUDA 中我们申请统一内存(Unified Memory)时,需要使用这样的方式:
c
float *x;
cudaMallocManaged(&x, N * sizeof(float))这就引出一个疑问:为什么 cudaMallocManaged 不直接返回一个指针,而是通过参数修改传入变量的值?其原因主要在于以下两个方面。
原因一:CUDA API 遵循显式错误处理风格
CUDA 设计中的一个核心思想:将错误处理显式化 。CUDA 的内存分配函数(包括 cudaMalloc、cudaMallocManaged 等)返回的是错误码,不是指针。例如 cudaMallocManaged 的函数签名如下:
arduino
__host__ cudaError_t cudaMallocManaged(void **devPtr, size_t size);这比 malloc() 的返回 NULL 要更可靠,因为 CUDA 的返回值可以给出详细的错误信息(如内存不足、非法参数、无设备支持等)。
原因二:统一内存涉及设备管理,不能简单用返回值表示
cudaMallocManaged 分配的是统一内存,它是由 CUDA 驱动管理、CPU 与 GPU 可以共同访问的一段内存区域:
- 需要设备支持 和驱动协调;
- 可能涉及延迟分配 、页面迁移等高级机制;
- 分配不只是创建一个地址,还可能需要额外的上下文绑定、同步等控制信息。
因此,CUDA 选择将所有这些复杂行为封装进 API 调用中,而不是通过简单的 void* 返回值暴露出来。
什么是主机端(Host)与设备端(Device)?
在 CUDA 编程模型中,整个程序运行环境分为两个世界:
| 名称 | 英文名 | 位置 | 运行内容 |
|---|---|---|---|
| 主机端 | Host | CPU | 主函数、数据初始化、内存申请等 |
| 设备端 | Device | GPU | 并行计算核函数(kernel),执行数据加速任务 |
简单来说:
-
主机端(host) :就是电脑 CPU 所执行的代码部分,比如
main()函数、new/delete、for循环等; -
设备端(device) :就是 GPU 运行的代码,通常以
global修饰符定义的核函数(kernel);
为什么要区分主机和设备?
在 C++ 中我们不会区分 CPU 和 GPU,因为一切都是在 CPU 上运行。但在 CUDA 中,GPU 与 CPU 是两个独立的处理单元,各有自己的:
- 指令集(CPU 是通用指令,GPU 是并行计算指令)
- 内存(CPU 有主存,GPU 有显存)
- 执行空间(Host 执行
main(),Device 执行 kernel)
主机和设备之间默认是不能直接共享内存的 ,所以通常需要通过 cudaMemcpy 显式地拷贝数据。但为了简化开发,CUDA 提供了统一内存(Unified Memory)机制,比如使用的 cudaMallocManaged(),它在底层自动处理主机设备的数据迁移,让开发者看起来像 CPU 和 GPU 在用同一块内存。
主机设备的数据迁移是如何处理的?
基本的 CUDA 内存模型下的数据迁移方式
在最基本的 CUDA 内存模型中,主机和设备拥有各自独立的内存空间。这就意味着必须显式地拷贝数据:
c
float *h_data = (float*)malloc(N * sizeof(float)); // Host memory
float *d_data;
cudaMalloc(&d_data, N * sizeof(float)); // Device memory
cudaMemcpy(d_data, h_data, N * sizeof(float), cudaMemcpyHostToDevice); // 拷贝数据到 GPU
kernel<<<blocks, threads>>>(d_data); // GPU 计算
cudaMemcpy(h_data, d_data, N * sizeof(float), cudaMemcpyDeviceToHost); // 拷贝回主机这种方式能精确控制内存位置和拷贝时间,同时性能也比较可控,但是程序复杂,容易出错,也不适合频繁的数据共享场景。
这就引入了统一内存,即自动数据迁移机制。
统一内存:自动数据迁移机制
当我们使用 cudaMallocManaged() 分配内存时:
c
float *x;
cudaMallocManaged(&x, N * sizeof(float));这段内存看起来是"共享"的,但实际上:CUDA 驱动会根据访问行为在主机和设备之间 "按需" 迁移数据页(page migration) ,使得当前执行的处理器始终访问自己本地的副本。
那么,这种自动迁移是如何发生的呢?
CUDA 使用类似于操作系统的虚拟内存机制,在页粒度(通常是 4KB) 上做管理:
-
初始化
x[i] = 1.0f,这在主机上运行,CUDA 标记这部分页面"属于主机"; -
GPU 执行 kernel 并首次访问
x[i]时,CUDA 检测到这是设备对"主机页面"的访问,于是:- 将这些页面从主机迁移到设备;
- 将页面标记为"只读"或"设备拥有";
- 触发硬件页面迁移(类似 page fault);
-
如果主机之后再次访问这些数据(比如结果检查),则会再次发生迁移(从 GPU → CPU);
-
为了减少频繁迁移,可以手动调用:
cudaMemPrefetchAsync(ptr, size, device_id):提示 CUDA 把数据提前迁移到某个设备;cudaMemAdvise(...):提供页面的访问模式建议(例如只读、多设备共享等)。
css
主机端代码初始化数据 → 内存页面驻留在 Host
↓
GPU kernel 访问 x[i] → Page Fault!
↓
CUDA 驱动将页面迁移到 Device
↓
GPU 正常运行 kernel
↓
主机读取 y[i] 结果 → 页面再次迁回 HostTips:
频繁主机-设备切换会导致大量迁移,严重拖慢性能。
<<<x, y>>>是什么含义?
<<<x, y>>> 是 CUDA 中调用 GPU 核函数(kernel)时的特殊语法 ,叫做:执行配置语法(execution configuration syntax)。 它用于告诉 CUDA 需要多少个线程来并行执行这个核函数,以及这些线程如何组织。
kernel 函数的基本形式
其 kernel 的基本形式如下:
bash
kernel<<<numBlocks, threadsPerBlock>>>(args...);含义:
numBlocks:表示启动多少个线程块(block)threadsPerBlock:每个线程块中包含多少个线程(thread)
最终总的线程数就是 numBlocks × threadsPerBlock。这些线程会并行 执行所定义的 global 核函数。在前面的代码中:
bash
add<<<1, 1>>>(N, x, y);表示启动 1 个线程块,每个块里 1 个线程,所以 GPU 只启动了 1 个线程来执行这个核函数。因此这个版本的 CUDA 代码实际上并没有并行加速,但结构上已经完整展示了如何定义和调用 GPU 上的代码。
由于这部分展开的篇幅会较大,因此在下一篇【CUDA编程】hello world 级入门(二)中,再详细探讨多线程块多线程的并行版本。
global 是怎么生效的?工作原理是什么?
global 限定词声明一个函数为 kernel。这样的一个函数具有以下特点:
- 在设备上执行
- 被主机端调用
- 对于计算能力 5.0 或更高的设备,也可以从设备调用
- 对 global 函数的调用是异步的,这意味着在设备完成其执行之前调用端即返回了
那么,global 内部是如何生效的呢?
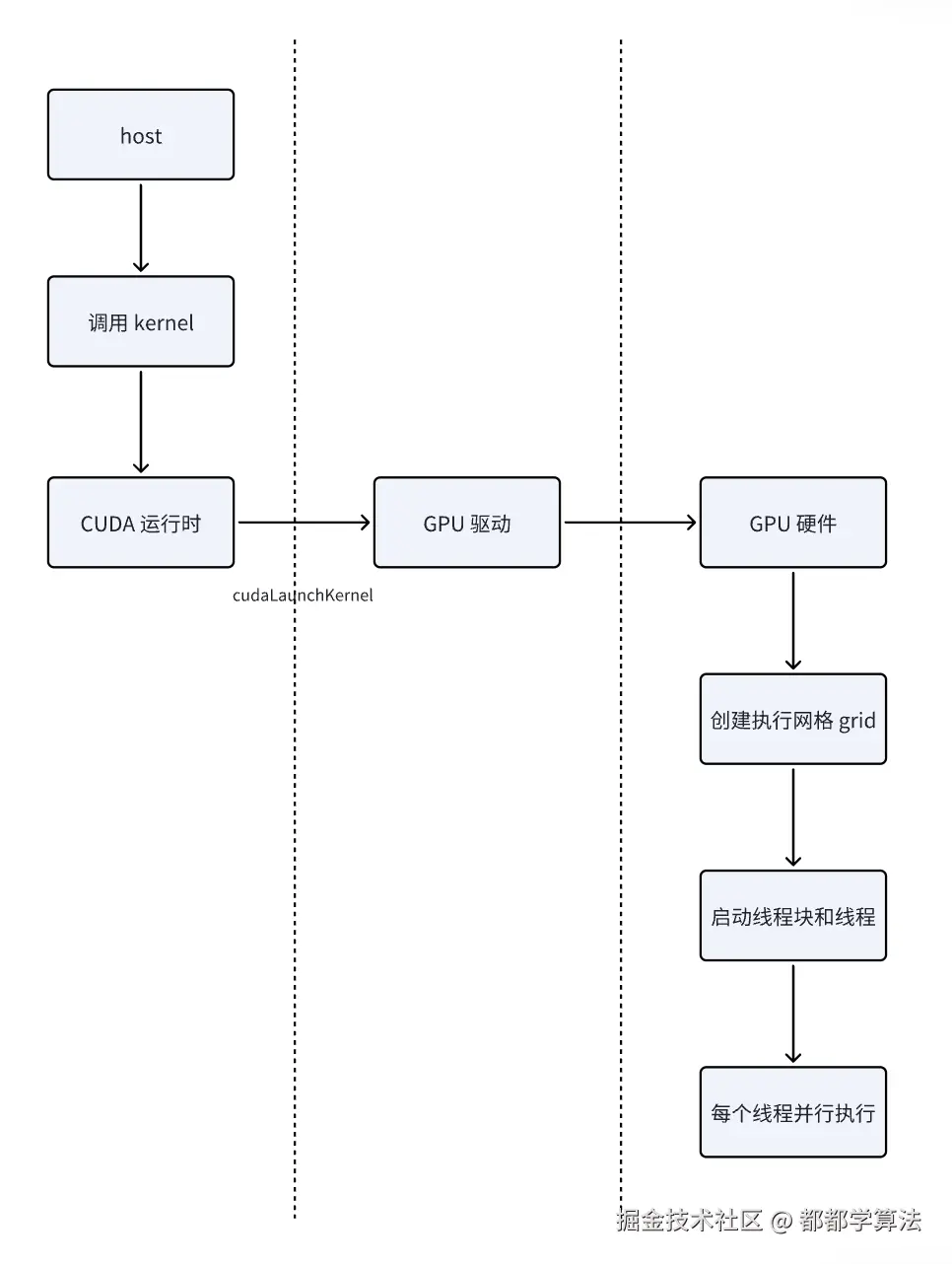
编译阶段:nvcc 生成两种代码
当编写带有 global 的函数并用 nvcc 编译时,CUDA 编译器会:
- 将主机端代码编译成普通的 CPU 机器码;
- 将标记为
global的核函数(kernel)编译成 GPU 设备代码; - 把 kernel 调用(如
kernel<<<...>>>(...))转化为一个隐藏的 API 调用(类似cudaLaunchKernel());
这就完成了主机和设备代码的双重编译流程。
执行阶段:kernel 启动流程
当主机端调用 kernel 函数时,例如:
bash
add<<<numBlocks, threadsPerBlock>>>(N, x, y);这并不是一个真正的 C++ 函数调用,而是 CUDA 语法糖(Syntactic sugar),底层做了以下几步:
-
CUDA 运行时通过
cudaLaunchKernel()等 API 向驱动发送一个 GPU 执行请求; -
CUDA 驱动接收到这个请求后:
- 将 kernel 函数的设备地址、参数、执行配置等传给 GPU;
- 启动请求的
blocks × threads数量的线程;
-
每个线程在 GPU 上并发执行
add函数体; -
内建变量(如
threadIdx.x、blockIdx.x)在每个线程的执行上下文中被自动设置。
为什么需要同步等待?
前面我们提过,CUDA 的 kernel 调用是异步的,在这样一系列逻辑中:
c
add<<<...>>>(...); // GPU 还在跑
cudaDeviceSynchronize(); // 等待 GPU 跑完
std::cout << y[0] << std::endl; // 主机安全读取结果假如不调用 ****cudaDeviceSynchronize() ,那主机代码可能访问的是 还没被 GPU 写入的值 。所以,cudaDeviceSynchronize() 会阻塞主机线程,直到 GPU 执行完成,是一种安全的做法,这能确保主机读取或处理的数据是有效的,否则主机可能读取错误或未完成计算的数据。
TODO:
是否有不需要同步等待的方式?
内存释放
比较 CUDA 和 C/C++ 在内存管理上的不同点如下:
| 内容 | delete\[\] | cudaFree() |
|---|---|---|
| 内存分配方式 | 用 new\[\] 在主机内存分配 | 用 cudaMalloc 或 cudaMallocManaged 在 GPU 或统一内存上分配 |
| 内存位置 | 主机内存 | 设备内存或统一内存 |
| 释放方式 | delete\[\] | cudaFree() |
| 操作对象是否要一致 | 必须和分配方式成对使用 | 必须和 CUDA 分配函数配对使用 |
CUDA 的内存管理是显式的,需要开发者自己负责释放,如果用 cudaMalloc 或 cudaMallocManaged 申请 CUDA 内存,必须用 cudaFree 来释放。
Tips:
CUDA 编程中,还有 cuda-memcheck 等工具来检查内存泄露等问题风险
总结
通过对比 CPU 和 CUDA 实现两个数组加法的示例,逐步理解了 CUDA 编程中的几个关键概念,包括:为什么要传递指针地址、为何 cudaMallocManaged 不直接返回指针、线程块语法 <<<x, y>>> 的作用,以及 global 函数的幕后机制等等。总之,对 CUDA 编程有了初步的认知。下一篇再深入探讨 CUDA 并行化相关的内容。