CUDA 13.0深度解析:统一ARM生态、UVM增强与GPU共享的革命
文章目录
- [CUDA 13.0深度解析:统一ARM生态、UVM增强与GPU共享的革命](#CUDA 13.0深度解析:统一ARM生态、UVM增强与GPU共享的革命)
-
- 引言:嵌入式与边缘计算的性能新纪元
- 统一ARM生态系统:一次构建,随处部署
- UVM与完全一致性:Jetson平台的内存管理革命
- [提升GPU共享效率:MPS与Green Contexts](#提升GPU共享效率:MPS与Green Contexts)
-
- 多进程服务(MPS):解锁Tegra的全部潜力
- [绿色上下文(Green Contexts):为短期任务优化的轻量级上下文](#绿色上下文(Green Contexts):为短期任务优化的轻量级上下文)
- [结论:CUDA 13.0开启边缘计算新篇章](#结论:CUDA 13.0开启边缘计算新篇章)
- 推荐阅读
引言:嵌入式与边缘计算的性能新纪元
随着NVIDIA CUDA Toolkit 13.0的发布,嵌入式和边缘计算领域正迎来一场深刻的变革。专为搭载NVIDIA Blackwell GPU架构的Jetson Thor SoC优化,此版本不仅带来了前所未有的性能提升,更通过一系列革命性的更新,重塑了开发者的工作流。从统一的ARM平台CUDA工具包,到完全硬件一致性的统一虚拟内存(UVM),再到多进程服务(MPS)和绿色上下文等GPU共享功能,CUDA 13.0正在为边缘AI应用开启一个更快、更高效、更通用的新时代。
本文将深入探讨CUDA 13.0的核心新特性,并通过丰富的代码示例,展示这些技术突破如何为机器人、自动驾驶和智能设备等前沿领域注入新的活力。

图1:CUDA 13.0为Jetson Thor等下一代嵌入式平台带来强大的计算能力
统一ARM生态系统:一次构建,随处部署
CUDA 13.0最引人注目的变化之一,是统一了ARM平台的CUDA工具包。在此之前,开发者需要为服务器级(SBSA兼容)和嵌入式设备(如Jetson系列)维护不同的工具链和安装环境。现在,这一障碍已被彻底清除(目前唯一的例外是Jetson Orin,它将暂时沿用现有路径)。
这一统一带来了巨大的生产力飞跃。开发者现在可以:
构建一次机器人或AI应用,在GB200和DGX Spark等高性能系统上进行仿真,然后将完全相同的二进制文件直接部署到Jetson Thor等嵌入式目标上,无需任何代码更改。
编译器和运行时仍然会为目标GPU架构生成优化代码,但开发者不再需要管理两个独立的工具链。这一变革也延伸到了容器领域,整合了NVIDIA的镜像生态系统,使得仿真、测试和部署工作流可以依赖于共享的容器血统,从而减少了重复构建,降低了持续集成(CI)的开销。
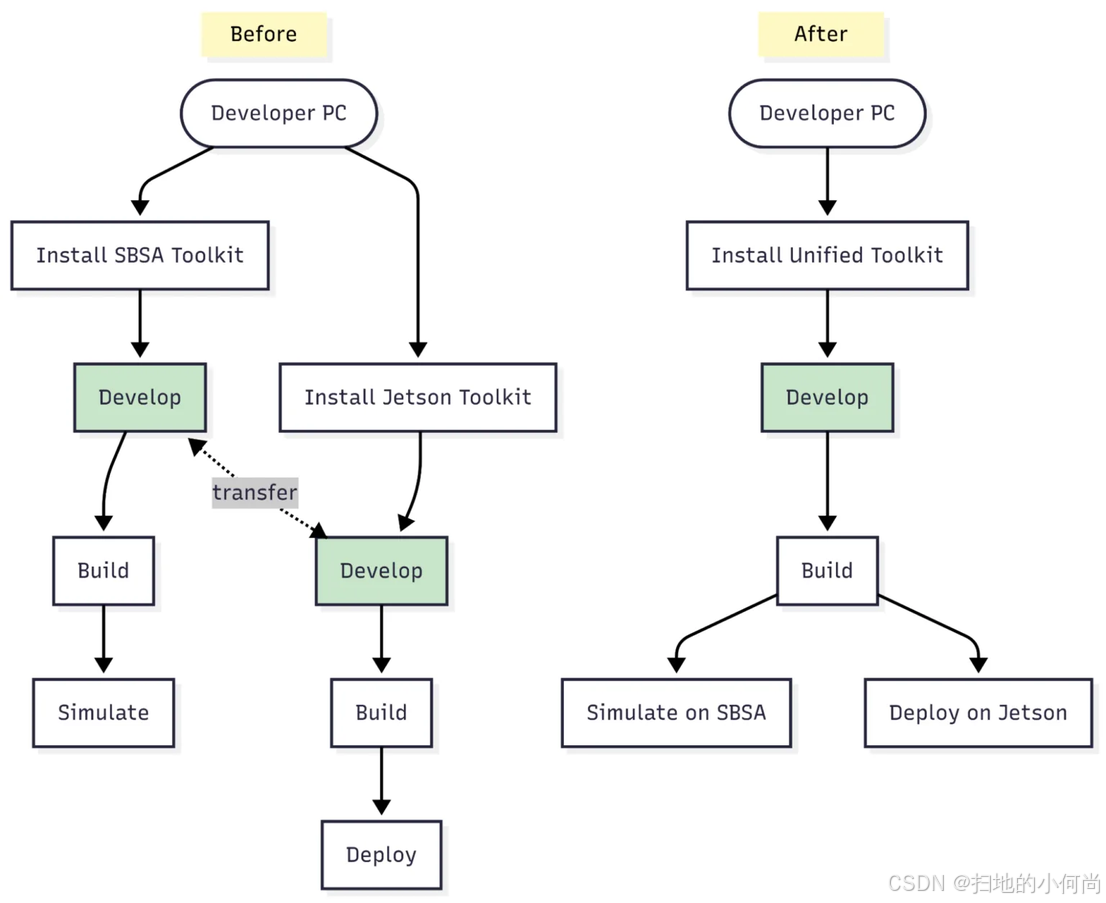
图2:统一工具包的工作流对比。左侧为旧流程,需要为不同平台维护独立工具链;右侧为CUDA 13.0的新流程,实现了"一次构建,随处部署"
UVM与完全一致性:Jetson平台的内存管理革命
CUDA 13.0为NVIDIA Jetson平台首次带来了统一虚拟内存(UVM)和完全硬件一致性 的支持。这意味着GPU现在可以通过主机的页表直接访问可分页的主机内存。在Jetson Thor平台上,cudaDeviceProp::pageableMemoryAccessUsesHostPageTables属性值为1,表明GPU访问CPU缓存的内存也会在GPU上进行缓存,并且完全的缓存一致性由硬件互连自动管理。
在实践中,这意味着通过标准mmap()或malloc()创建的系统分配内存,现在可以直接在GPU内核中使用,无需任何显式的CUDA内存分配或cudaMemcpy()调用。这不仅简化了代码,还因避免了数据拷贝而带来了显著的性能提升。
代码示例:使用mmap和UVM进行直方图计算
下面的代码示例完美地展示了这一新特性。它首先使用mmap()将一个文件映射到内存中,然后直接将这个内存指针传递给一个GPU内核来执行直方图计算。输出的直方图缓冲区同样是通过mmap()获得的。整个过程中,输入数据和输出直方图都在GPU的L2缓存中进行缓存,一致性由硬件自动管理。
cpp
#include <stdio.h>
#include <stdlib.h>
#include <cuda_runtime.h>
#include <sys/mman.h>
#include <fcntl.h>
#include <unistd.h>
#define HIST_BINS 64
#define IMAGE_WIDTH 512
#define IMAGE_HEIGHT 512
// CUDA错误检查宏
#define CUDA_CHECK(call) \
if ((call) != cudaSuccess) { \
cudaError_t err = cudaGetLastError(); \
printf("CUDA error calling \"%s\", code is %d\n", #call, err); \
}
// GPU内核:计算直方图
__global__ void histogram(
unsigned int elementsPerThread,
unsigned int *histogramBuffer, // 输出:直方图缓冲区
unsigned int *inputBuffer // 输入:图像数据
) {
unsigned int offset = threadIdx.x + blockDim.x * blockIdx.x;
unsigned int stride = gridDim.x * blockDim.x;
for (unsigned int i = 0; i < elementsPerThread; i++) {
// 计算每个像素值对应的直方图bin索引
unsigned int indexToIncrement = inputBuffer[offset + i * stride] % HIST_BINS;
// 使用原子操作安全地增加bin的计数值
atomicAdd(&histogramBuffer[indexToIncrement], 1);
}
}
int main(int argc, char **argv) {
size_t alloc_size = IMAGE_HEIGHT * IMAGE_WIDTH * sizeof(int);
size_t hist_size = HIST_BINS * sizeof(int);
// 1. 使用mmap直接分配主机内存用于直方图,无需cudaMalloc
unsigned int *histogramBuffer = (unsigned int*)mmap(NULL, hist_size, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS, -1, 0);
unsigned int *inputBuffer;
// 打开输入文件
int fd = open("inputFile.bin", O_RDONLY, 0);
if (fd == -1) {
printf("Error opening input file: inputFile.bin\n");
return -1;
}
// 2. 使用mmap将文件内容映射到主机内存,无需cudaMalloc
inputBuffer = (unsigned int*)mmap(NULL, alloc_size, PROT_READ, MAP_PRIVATE, fd, 0);
// 设置CUDA内核启动参数
const unsigned int elementsPerThread = 4;
const unsigned int blockSize = 512;
dim3 threads(blockSize);
dim3 grid((IMAGE_WIDTH * IMAGE_HEIGHT) / (blockSize * elementsPerThread));
// 3. 直接在GPU内核中使用通过mmap获得的内存指针
histogram<<<grid, threads>>>(elementsPerThread, histogramBuffer, inputBuffer);
CUDA_CHECK(cudaGetLastError());
CUDA_CHECK(cudaDeviceSynchronize());
printf("直方图计算完成。\n");
// 解除内存映射并关闭文件
munmap(histogramBuffer, hist_size);
munmap(inputBuffer, alloc_size);
close(fd);
return 0;
}这个例子清晰地展示了UVM和完全一致性带来的编程模型的简化。开发者可以像编写普通CPU程序一样管理内存,同时享受GPU带来的强大加速能力。
提升GPU共享效率:MPS与Green Contexts
随着Tegra GPU的计算能力不断增强,单个进程往往难以充分利用所有可用的GPU资源,尤其是在处理小型或突发性工作负载时(例如,在单个应用中运行多个小型生成式AI代理)。这会导致多进程系统中的效率低下。CUDA 13.0通过增强多进程服务(MPS)和引入绿色上下文(Green Contexts)来解决这个问题。
多进程服务(MPS):解锁Tegra的全部潜力
MPS 通过允许多个进程并发共享GPU,消除了上下文切换的开销,实现了真正的并行执行。它将多个轻量级工作负载整合到单个GPU上下文中,从而提高了占用率、吞吐量和可扩展性。最重要的是,使用MPS不需要对现有应用程序进行任何代码更改,通常只需在启动应用前设置几个环境变量并启动控制守护进程即可。
代码示例:启用MPS服务
在典型的Linux环境下,启用MPS服务通常涉及以下步骤。这并不是一个直接的程序代码,而是一个工作流展示,演示了如何配置和启动MPS环境。
bash
# 1. 设置环境变量以指定MPS管道目录
# 确保这个目录对于所有需要共享GPU的进程都是可访问的
export CUDA_MPS_PIPE_DIRECTORY=/tmp/nvidia-mps
# 2. 设置环境变量以指定MPS日志目录
export CUDA_MPS_LOG_DIRECTORY=/tmp/nvidia-log
# 3. 启动NVIDIA MPS控制守护进程
# -d 标志使其在后台运行
nvidia-cuda-mps-control -d
# 4. 检查MPS服务器状态
# 这会打印出当前活动的MPS服务器列表(初始为空)
echo get_server_list | nvidia-cuda-mps-control
# 5. 现在,正常启动你的多个CUDA应用程序
# 它们会自动连接到MPS服务器并并发执行
./my_cuda_app_1 &
./my_cuda_app_2 &
./my_cuda_app_3 &
# 等待所有应用完成
wait
# 6. 关闭MPS控制守护进程
echo quit | nvidia-cuda-mps-control绿色上下文(Green Contexts):为短期任务优化的轻量级上下文
绿色上下文是为需要快速启动和拆卸的短期工作负载设计的轻量级GPU上下文。它们显著减少了上下文创建和销毁的开销,非常适合AI推理、批处理任务以及其他需要频繁、短暂GPU计算的场景。
| 特性 | 传统GPU上下文 | 绿色上下文 (Green Contexts) |
|---|---|---|
| 创建开销 | 较高 | 极低 |
| 销毁开销 | 较高 | 极低 |
| 适用场景 | 长时间运行的计算密集型任务 | 短期、突发、频繁的计算任务 |
| 资源占用 | 较高 | 较低 |
通过结合使用MPS和绿色上下文,开发者可以在Jetson Thor平台上实现前所未有的GPU利用率和多任务处理能力,为复杂的边缘AI应用提供了坚实的基础。
结论:CUDA 13.0开启边缘计算新篇章
CUDA 13.0不仅仅是一次常规的版本更新,它是一次针对ARM和嵌入式生态系统的战略性飞跃。通过统一工具链、引入完全硬件一致性的UVM、以及增强GPU共享功能,NVIDIA极大地简化了从云端仿真到边缘部署的开发流程。
对于开发者而言,这意味着更高的生产力、更强的性能和更广阔的应用前景。Jetson Thor在CUDA 13.0的加持下,正成为构建下一代机器人、自动驾驶汽车和智能边缘设备的最强大平台。现在是时候拥抱这些新技术,探索物理AI的无限可能了。