R²D²深度解析:NVIDIA三大神经网络突破如何变革机器人学习
引言:从实验室到现实,机器人学习的"最后一公里"
尽管今天的机器人在受控环境中表现出色,但它们在面对现实世界的不可预测性、灵巧性以及与环境进行精细交互时,仍然显得力不从心。无论是组装精密的电子元件,还是像人一样自然地操作日常物品,都对机器人的学习和适应能力提出了极高的要求。
机器人学习已成为弥合实验室演示与真实世界部署之间鸿沟的关键。然而,传统方法面临着根本性的限制:
- 经典仿真器的局限:无法完全捕捉现代机器人系统(尤其是那些具有高自由度和复杂机械结构的系统)的复杂动态。
- 人类演示的转化难题:很难将人类的动作演示直接转化为不同形态的机器人能够理解和执行的策略。
- 多模态感知的缺失:人类在操作中自然而然地结合视觉和触觉,而这对机器来说仍然是一个难以企及的目标。
为了攻克这些难题,NVIDIA研究院在机器人学习领域取得了三项突破性的神经网络创新,并于CoRL 2025上隆重推出,统称为R²D² (NVIDIA Robotics Research and Development Digest)。这三大突破分别是:
- NeRD (神经机器人动力学):通过学习动力学模型来增强仿真,实现跨任务泛化和真实世界微调。
- Dexplore (灵巧操作学习):将人类动作捕捉演示视为自适应指导,解锁机器人类人级别的灵巧操作能力。
- VT-Refine (视觉-触觉协同):结合视觉与触觉感知,通过创新的"真实-仿真-真实"训练范式,掌握精确的双手协同装配任务。
本文将深入探讨这三项技术的核心思想、实现方式以及它们如何为开发者提供全新的工具和工作流,从而推动机器人学习研究迈向新的高度。

图1:NVIDIA R²D²的三大突破旨在解决机器人学习中的核心挑战
突破一:NeRD (神经机器人动力学)------用神经网络重塑仿真
仿真是机器人开发流程中的核心环节。通过在仿真环境中进行训练,机器人可以学习到鲁棒的策略,因为质量、摩擦力等物理参数可以在训练中被随机化。然而,传统仿真器在模拟具有高自由度和复杂接触动态的现代机器人时,往往力不从心。神经网络模型为此提供了新的解决方案,它们可以高效地预测复杂动态并适应真实世界的数据。
NeRD正是一个为此而生的学习型动力学模型,专门用于预测特定机器人在接触约束下的未来状态。它并非完全取代传统仿真器,而是巧妙地替换了其中的底层动力学和接触求解器,从而构建了一个混合仿真预测框架。
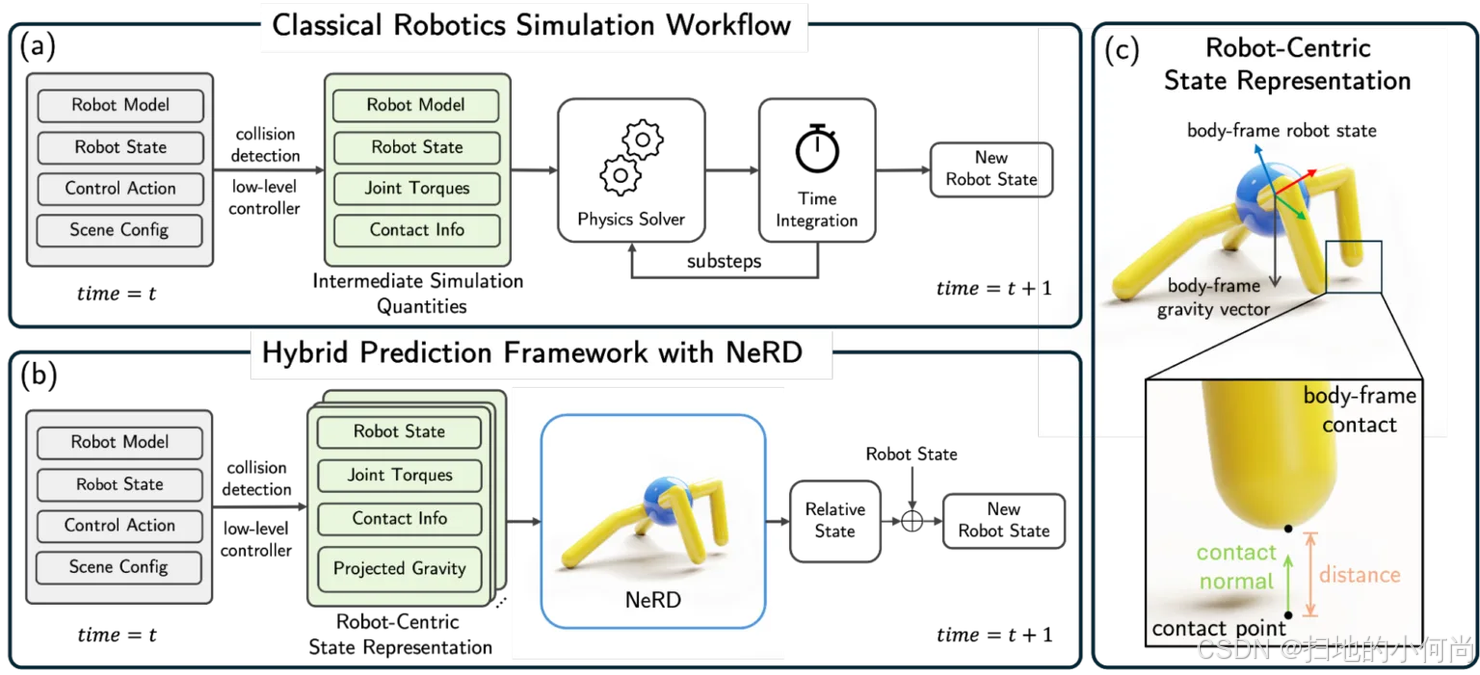
图2:NeRD混合预测框架与经典仿真工作流对比
NeRD的核心创新在于其以机器人为中心的状态表示 。这种表示方法强制了空间不变性,极大地提高了模型的训练效率和数据利用率,从而增强了其泛化能力。NeRD可以轻松集成到现有的多关节刚体仿真框架中,目前已在NVIDIA Warp 中得到验证,并计划在未来成为Newton Physics Engine的众多求解器之一。
在训练方面,NeRD模型(基于轻量级的GPT-2 Transformer架构)使用了为六种不同机器人系统收集的训练数据,每个系统包含10万条随机轨迹,每条轨迹长达100个时间步。结果表明,NeRD模型在数千个时间步上都保持了稳定和准确,对于ANYmal四足机器人,其在1000步策略评估中的累积奖励误差低于惊人的0.1%。

图3:NeRD集成仿真器(左)与经典仿真器(右)的机器人策略执行效果高度匹配
更重要的是,NeRD展现了出色的零样本Sim-to-Real迁移能力。在NeRD集成仿真器中学习到的Franka机械臂抓取策略,无需任何修改即可在真实世界中成功执行。此外,NeRD还可以利用真实世界的数据进行微调,进一步缩小仿真与现实之间的差距。像NeRD这样的神经模型,将与经典仿真技术并驾齐驱,加速机器人学的研究进程。
突破二:Dexplore------从人类演示中学习灵巧操作
教会机器人手实现人类水平的灵巧操作,一直是机器人学领域的"圣杯"级难题。人手拥有无与伦比的运动学复杂性、柔顺性和丰富的触觉感知能力,而机器人手在自由度、驱动、感知和控制方面都存在局限。这使得机器人很难直接从人类演示中学习复杂的操控技巧。
尽管手-物动作捕捉(MoCap)库提供了大量富含接触信息的人类演示数据,但它们无法被直接用于机器人的策略学习。现有的工作流通常包含重定向、跟踪和残差校正三个主要步骤,但这会导致误差的累积。
为了解决这个问题,NVIDIA的研究人员引入了一种名为**Reference-Scoped Exploration (RSE)**的全新方法。这是一种统一的、单循环的优化过程,它将重定向和跟踪集成在一起,直接从MoCap数据中训练一个可扩展的机器人控制策略。其核心思想是,不将人类演示视为严格的"基准真相",而是将其看作"软性指导"。
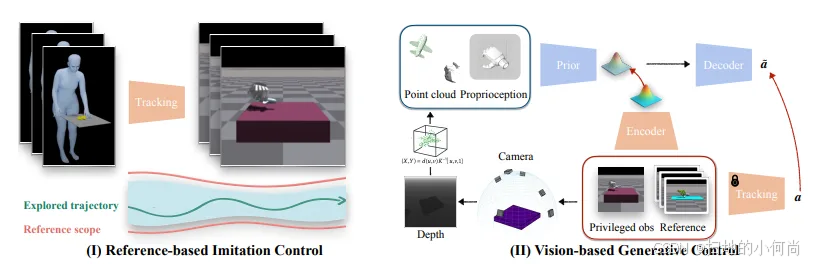
图4:Dexplore工作流:(I)基于参考的模仿控制;(II)基于视觉的生成控制
这种方法保留了演示的意图,同时允许机器人自主探索与其自身物理形态相兼容的运动方式。整个工作流程分为两部分:
- 基于状态的模仿控制策略训练:使用RSE来探索机器人特定的操作策略,学习如何模仿人类演示的核心意图。
- 基于视觉的生成控制策略学习:将第一步学到的状态策略"提炼"成一个基于视觉的策略。这使得机器人手能够仅通过单视角深度图像和稀疏的用户定义目标,来操控物体。
在训练过程中,策略的目标是让机器人手跟随给定的轨迹,以实现多样的物体操控技能,如抓取香蕉、手机、杯子和双筒望远镜。该模型由编码器、先验网络和解码器策略组成。在推理时,编码器被省略,潜在嵌入直接从学习到的先验中采样,从而产生一个能够从部分观测中执行有效的、目标导向的灵巧操作的生成式控制策略。
实验结果表明,该方法在Inspire hand上的成功率比基线方法高出近20%,并且在Inspire和Allegro两种机器人手上都表现出了一致的优越性。
突破三:VT-Refine------结合视觉与触觉,攻克精密双手装配
人类在进行双手操作和装配任务时,会同时依赖视觉和触觉反馈。想象一下用双手组装插头和插座:首先,你会用眼睛识别并抓住所需的部件;接着,在组装过程中,由于视觉可能被遮挡,触觉反馈就变得至关重要。
基于扩散策略的行为克隆虽然有效,但受限于真实世界演示数据的稀缺性以及数据收集接口上触觉反馈的局限性。
为了解决这个数据难题,VT-Refine开发了一种新颖的**"真实-仿真-真实"(Real-to-Sim-to-Real)框架**,该框架结合了仿真、视觉和触觉,专门用于解决双手协同的精密装配任务。
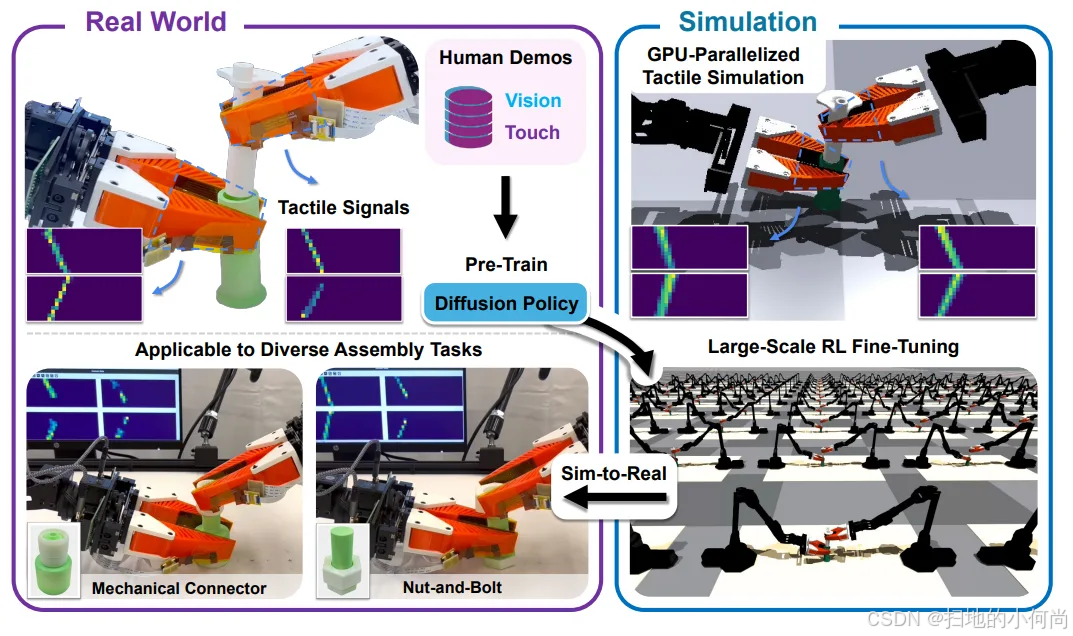
其核心步骤如下:
- 真实世界数据收集与预训练:首先,收集少量(例如30个)真实世界的演示数据,用于预训练一个双手的视觉-触觉扩散策略。
- 仿真环境中的强化学习微调 :然后,在NVIDIA Isaac Sim中创建的数字孪生并行仿真环境中,使用强化学习(RL)对这个预训练策略进行大规模微调。
- 部署回真实世界:最后,将经过充分训练的策略部署回真实的机器人上。
这个框架的关键在于其对触觉感官输入的仿真。这得益于TacSL ,一个基于GPU的触觉仿真库,它与Isaac Lab集成,能够高效地模拟触觉传感器的柔软性,从而实现可扩展的、GPU加速的仿真训练。用于训练的观测数据包括:
- 以自我为中心的相机捕捉到的点云
- 触觉传感器反馈的点云表示
- 手臂和夹爪的关节位置
通过这种方式,VT-Refine能够利用少量的人类演示作为"热启动",引导强化学习的探索方向,而无需复杂的奖励工程,从而高效地学习到需要精密接触和力反馈的复杂任务。
代码示例:将三大突破付诸实践
为了帮助开发者更好地理解这三项突破性技术,我们提供了一些概念性的代码示例,以展示它们在实际应用中的核心逻辑。
示例1:NeRD - 神经动力学模型(概念伪代码)
NeRD的核心是使用一个类似Transformer的模型来替代传统的物理引擎。下面的伪代码展示了如何使用PyTorch来定义一个简化的神经动力学模型,并在一个仿真循环中调用它。
python
import torch
import torch.nn as nn
# 1. 定义一个简化的、基于Transformer的神经动力学模型
class SimplifiedNeRD(nn.Module):
def __init__(self, state_dim, action_dim, nhead=8, num_layers=6):
super().__init__()
self.state_dim = state_dim
self.action_dim = action_dim
# 输入嵌入层,将状态和动作映射到模型维度
self.state_encoder = nn.Linear(state_dim, 512)
self.action_encoder = nn.Linear(action_dim, 512)
# Transformer编码器层
encoder_layer = nn.TransformerEncoderLayer(d_model=512, nhead=nhead)
self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)
# 输出层,预测下一个状态
self.decoder = nn.Linear(512, state_dim)
def forward(self, current_state, action):
"""
预测下一个机器人状态
:param current_state: 当前的机器人状态 (e.g., 关节角度、速度)
:param action: 施加在机器人上的动作 (e.g., 关节力矩)
:return: 预测的下一个状态
"""
# 1. 将输入编码到高维空间
state_embedding = self.state_encoder(current_state)
action_embedding = self.action_encoder(action)
# 2. 将状态和动作组合成一个序列(这里简化处理)
# 在实际NeRD中,会使用更复杂的机器人中心表示
input_sequence = (state_embedding + action_embedding).unsqueeze(0) # (Sequence, Batch, Dim)
# 3. 通过Transformer模型进行处理
transformer_output = self.transformer_encoder(input_sequence)
# 4. 解码得到下一个状态的预测值
predicted_next_state_delta = self.decoder(transformer_output.squeeze(0))
# 5. 预测的是状态变化量,与当前状态相加得到最终预测
predicted_next_state = current_state + predicted_next_state_delta
return predicted_next_state
# --- 仿真循环中的使用 ---
def simulation_step(nerd_model, current_robot_state, robot_action):
"""执行一个仿真步骤"""
# 使用NeRD模型来预测下一个状态,而不是传统的物理求解器
# nerd_model.eval() # 设置为评估模式
with torch.no_grad():
next_state = nerd_model(current_robot_state, robot_action)
return next_state
# 假设模型已经训练好
# state_dim, action_dim = get_robot_specs()
# nerd_model = SimplifiedNeRD(state_dim, action_dim)
# nerd_model.load_state_dict(torch.load('nerd_model.pth'))
# current_state = get_initial_state()
# for t in range(simulation_horizon):
# action = policy.get_action(current_state) # 从一个策略网络获取动作
# current_state = simulation_step(nerd_model, current_state, action)
# print(f"Time {t+1}: New state predicted.")
print("NeRD模型定义完成,可用于混合仿真框架。")示例2:Dexplore - RSE优化过程(概念伪代码)
Dexplore的核心是RSE(Reference-Scoped Exploration),它将人类演示作为软指导。下面的伪代码展示了RSE优化循环的核心思想。
python
import torch
# 假设 policy 是我们的机器人控制策略网络
# 假设 mocap_trajectory 是从人类演示中获取的参考轨迹
# optimizer = torch.optim.Adam(policy.parameters(), lr=1e-4)
def rse_training_loop(policy, mocap_trajectory, robot_env):
"""
使用RSE进行训练的核心循环
"""
# 1. 从环境中获取初始状态
robot_state = robot_env.reset()
total_loss = 0
for t in range(len(mocap_trajectory)):
# 2. 策略网络根据当前机器人状态和参考轨迹生成动作
# 参考轨迹作为"软指导"输入到策略中
reference_state = mocap_trajectory[t]
action = policy(robot_state, reference_state)
# 3. 在环境中执行动作,得到下一个状态
next_robot_state, reward, done, _ = robot_env.step(action)
# 4. 计算损失函数
# 损失函数包含多个部分,鼓励策略跟随参考,同时允许探索
# a) 模仿损失:鼓励机器人状态接近参考轨迹
imitation_loss = torch.mean((robot_state - reference_state)**2)
# b) 任务奖励:来自环境的奖励,鼓励完成任务
task_loss = -reward
# c) 其他正则化项 (e.g., 动作平滑性)
regularization_loss = torch.mean(action**2)
# 5. 组合损失
# 权重可以根据任务进行调整
loss = 1.0 * imitation_loss + 0.5 * task_loss + 0.1 * regularization_loss
total_loss += loss
# 更新状态
robot_state = next_robot_state
if done:
break
# 6. 反向传播和优化
# optimizer.zero_grad()
# total_loss.backward()
# optimizer.step()
# return total_loss.item()
print("Dexplore的RSE训练循环概念定义完成。")
# for epoch in range(num_epochs):
# loss = rse_training_loop(policy, mocap_trajectory, robot_env)
# print(f"Epoch {epoch}: Loss = {loss}")示例3:VT-Refine - Real-to-Sim-to-Real框架(高级伪代码)
VT-Refine的精髓在于其"真实-仿真-真实"的训练流程。下面的伪代码描绘了这一框架的关键步骤。
python
# 假设 DiffusionPolicy 是我们的视觉-触觉扩散策略模型
# 假设 IsaacSimEnv 是一个配置好的、支持触觉仿真的Isaac Sim环境
# --- 步骤 1: 在真实世界数据上预训练 ---
def pretrain_on_real_data(policy, real_world_demonstrations):
"""
使用少量真实世界演示数据进行预训练
"""
print("开始在真实世界数据上预训练策略...")
# ... 此处为标准的行为克隆训练循环 ...
# dataloader = torch.utils.data.DataLoader(real_world_demonstrations, ...)
# for vision_obs, tactile_obs, action in dataloader:
# loss = policy.compute_loss(vision_obs, tactile_obs, action)
# ... (优化步骤) ...
print("预训练完成。")
return policy
# --- 步骤 2: 在仿真中进行强化学习微调 ---
def finetune_in_simulation(policy, sim_env):
"""
在并行的Isaac Sim环境中使用RL进行大规模微调
"""
print("开始在仿真环境中进行强化学习微调...")
# ... 此处为标准的RL训练循环 (e.g., PPO) ...
# for _ in range(num_rl_updates):
# # 从环境中收集经验 (rollouts)
# vision_obs, tactile_obs, action, reward, ... = sim_env.collect_experience(policy)
#
# # 使用收集到的经验更新策略
# policy.update_with_rl(vision_obs, tactile_obs, action, reward, ...)
print("仿真微调完成。")
return policy
# --- 步骤 3: 部署到真实机器人 ---
def deploy_to_real_robot(policy, real_robot_interface):
"""
将最终策略部署到真实世界
"""
print("将最终策略部署到真实机器人...")
# obs_vision, obs_tactile = real_robot_interface.get_observations()
# while not task_completed:
# action = policy.get_action(obs_vision, obs_tactile)
# real_robot_interface.execute_action(action)
# obs_vision, obs_tactile = real_robot_interface.get_observations()
print("任务完成!")
# --- 完整流程 ---
# 1. 初始化模型和环境
# policy = DiffusionPolicy(...)
# real_data = load_real_demonstrations() # 加载30个真实演示
# sim_env = IsaacSimEnv(num_parallel_envs=1024) # 创建1024个并行仿真环境
# 2. 执行Real-to-Sim-to-Real
# policy = pretrain_on_real_data(policy, real_data)
# policy = finetune_in_simulation(policy, sim_env)
# deploy_to_real_robot(policy, real_robot_interface)
print("VT-Refine的Real-to-Sim-to-Real框架概念定义完成。")结论:机器人学习的新范式
NVIDIA R²D²展示的三大突破------NeRD、Dexplore和VT-Refine------共同描绘了机器人学习的未来蓝图。它们分别从仿真物理、模仿学习和多模态感知这三个核心维度,为解决机器人从虚拟走向现实的"最后一公里"问题,提供了强大而创新的解决方案。
- NeRD通过将神经网络的强大拟合能力与物理仿真的严谨性相结合,为复杂机器人系统提供了前所未有的高保真、可微调的仿真环境。
- Dexplore则重新定义了如何从人类演示中学习,将模仿从"刻板复制"转变为"意图引导下的自主探索",极大地提升了机器人学习灵巧操作的能力。
- VT-Refine更是通过其巧妙的"真实-仿真-真实"框架,解决了精密操作中对多模态感知(尤其是视觉与触觉结合)和海量高质量数据的双重需求。
这些技术不再是孤立的研究,而是相互关联、可以协同工作的工具集。它们为开发者提供了一套完整的、从数据收集、仿真训练到真实世界部署的先进工作流。随着这些技术在NVIDIA Isaac等平台上的不断集成和完善,我们有理由相信,一个由更智能、更灵巧、更能与物理世界无缝交互的机器人所构成的新时代,正在加速到来。
推荐阅读
如果您对本文探讨的机器人学习、神经网络和AI推理技术感兴趣,欢迎阅读我博客中的其他相关文章,以获得更全面的了解:
- NVIDIA Dynamo深度解析:如何优雅地解决LLM推理中的KV缓存瓶颈:了解大规模神经网络推理中的内存优化技术,这对于在机器人上部署复杂AI模型至关重要。
- CUDA 13.0重磅发布:统一ARM生态、UVM与多GPU开发者利器深度解析:深入了解驱动这些先进机器人学习框架的底层计算平台和编程模型。
- 量化感知训练:如何恢复低精度模型的准确性:探讨在资源受限的机器人硬件上部署高性能神经网络模型的关键优化技术。
- 小语言模型(SLM):构建可扩展智能AI的关键:探索更高效的AI模型架构,这对于实现机器人的实时智能决策具有重要意义。
- CUDA Python框架--Warp:NeRD等技术依赖于高性能的仿真,本专栏深入介绍了NVIDIA Warp这一强大的GPU加速仿真框架。