检索:使用语义相似度搜索你的数据
检索 API 允许你对数据执行语义搜索,这是一种能呈现语义相似结果的技术------即使结果与关键词匹配很少或不匹配。检索本身就很有用,但与我们的模型结合使用来生成响应时尤其强大。
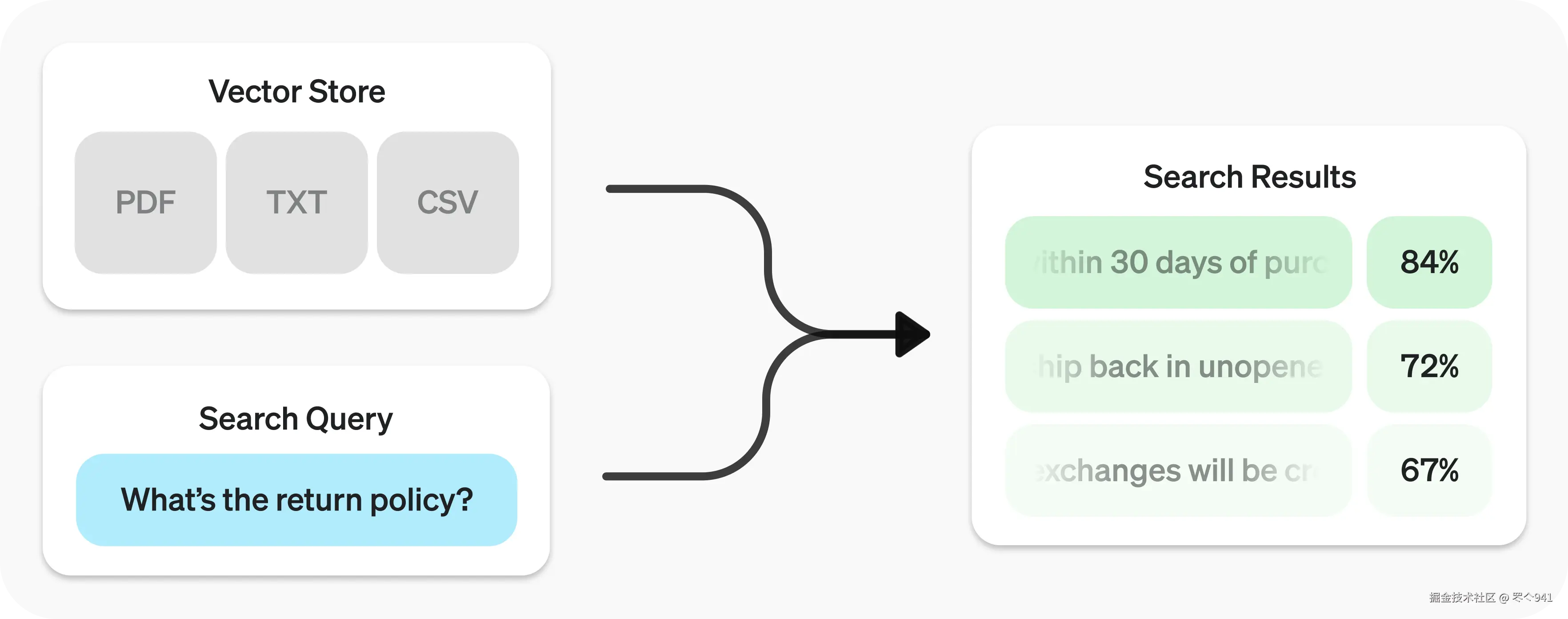
检索 API 由向量存储提供支持,向量存储充当数据的索引。本指南将介绍如何执行语义搜索,并详细讲解向量存储。
快速入门
- 创建向量存储并上传文件。
创建带文件的向量存储
python
from openai import OpenAI
client = OpenAI(base_url="https://api.aaaaapi.com")
vector_store = client.vector_stores.create( # 创建向量存储
name="支持FAQ",
)
client.vector_stores.files.upload_and_poll( # 上传文件
vector_store_id=vector_store.id,
file=open("customer_policies.txt", "rb")
)
javascript
import OpenAI from "openai";
const client = new OpenAI({ baseURL: "https://api.aaaaapi.com" });
const vector_store = await client.vectorStores.create({ // 创建向量存储
name: "支持FAQ",
});
await client.vector_stores.files.upload_and_poll({ // 上传文件
vector_store_id: vector_store.id,
file: fs.createReadStream("customer_policies.txt"),
});- 发送搜索查询以获取相关结果。
搜索查询
python
user_query = "退货政策是什么?"
results = client.vector_stores.search(
vector_store_id=vector_store.id,
query=user_query,
)
javascript
const userQuery = "退货政策是什么?";
const results = await client.vectorStores.search({
vector_store_id: vector_store.id,
query: userQuery,
});要了解如何将结果与我们的模型结合使用,请查看生成响应部分。
语义搜索
语义搜索 是一种利用向量嵌入呈现语义相关结果的技术。重要的是,这包括很少或没有共享关键词的结果,而传统搜索技术可能会错过这些结果。
例如,让我们看看"我们什么时候登上月球的?"的潜在结果:
| 文本 | 关键词相似度 | 语义相似度 |
|---|---|---|
| 第一次月球着陆发生在1969年7月。 | 0% | 65% |
| 第一个登上月球的人是尼尔·阿姆斯特朗。 | 27% | 43% |
| 我吃月饼的时候,味道好极了。 | 40% | 28% |
(关键词使用杰卡德指数,语义使用text-embedding-3-small的余弦相似度。)
请注意,最相关的结果不包含搜索查询中的任何单词。这种灵活性使语义搜索成为查询任何规模知识库的强大技术。
语义搜索由向量存储提供支持,我们将在本指南后面详细介绍。本节将重点介绍语义搜索的机制。
执行语义搜索
你可以使用search函数并以自然语言指定query来查询向量存储。这将返回一个结果列表,每个结果都包含相关的片段、相似度分数和来源文件。
搜索查询
python
results = client.vector_stores.search(
vector_store_id=vector_store.id,
query="每位乘客允许携带多少只土拨鼠?",
)
javascript
const results = await client.vectorStores.search({
vector_store_id: vector_store.id,
query: "每位乘客允许携带多少只土拨鼠?",
});结果
json
{
"object": "vector_store.search_results.page",
"search_query": "每位乘客允许携带多少只土拨鼠?",
"data": [
{
"file_id": "file-12345",
"filename": "woodchuck_policy.txt",
"score": 0.85,
"attributes": {
"region": "北美",
"author": "野生动物部门"
},
"content": [
{
"type": "text",
"text": "根据最新规定,每位乘客最多可携带两只土拨鼠。"
},
{
"type": "text",
"text": "确保土拨鼠在运输过程中得到妥善安置。"
}
]
},
{
"file_id": "file-67890",
"filename": "transport_guidelines.txt",
"score": 0.75,
"attributes": {
"region": "北美",
"author": "运输局"
},
"content": [
{
"type": "text",
"text": "乘客必须遵守运输局制定的关于土拨鼠运输的指导方针。"
}
]
}
],
"has_more": false,
"next_page": null
}响应默认最多包含10个结果,但你可以使用max_num_results参数设置最多50个。
查询重写
某些查询风格会产生更好的结果,因此我们提供了一个设置,可以自动重写你的查询以获得最佳性能。执行search时,通过设置rewrite_query=true启用此功能。
重写后的查询将在结果的search_query字段中可用。
| 原始查询 | 重写后查询 |
|---|---|
| 我想知道主办公楼的高度。 | 主办公楼高度 |
| 运输危险材料的安全规定是什么? | 危险材料安全规定 |
| 如何就服务问题提出投诉? | 服务投诉提交流程 |
属性过滤
属性过滤通过应用条件帮助缩小结果范围,例如将搜索限制在特定日期范围内。你可以在attribute_filter中定义和组合条件,以便在执行语义搜索之前根据文件的属性定位文件。
使用比较过滤器 将文件attributes中的特定key与给定的value进行比较,并使用复合过滤器 通过and和or组合多个过滤器。
比较过滤器
json
{
"type": "eq" | "ne" | "gt" | "gte" | "lt" | "lte", // 比较运算符
"property": "attributes_property", // 属性
"value": "target_value" // 要比较的值
}复合过滤器
json
{
"type": "and" | "or", // 逻辑运算符
"filters": [...]
}以下是一些示例过滤器。
地区
按地区过滤
json
{
"type": "eq",
"property": "region",
"value": "us"
}日期范围
按日期范围过滤
json
{
"type": "and",
"filters": [
{
"type": "gte",
"property": "date",
"value": 1704067200 // 2024-01-01的unix时间戳
},
{
"type": "lte",
"property": "date",
"value": 1710892800 // 2024-03-20的unix时间戳
}
]
}文件名
过滤以匹配一组文件名中的任何一个
json
{
"type": "or",
"filters": [
{
"type": "eq",
"property": "filename",
"value": "example.txt"
},
{
"type": "eq",
"property": "filename",
"value": "example2.txt"
}
]
}复杂过滤
过滤具有特定英文名称的绝密项目
json
{
"type": "or",
"filters": [
{
"type": "and",
"filters": [
{
"type": "or",
"filters": [
{
"type": "eq",
"property": "project_code",
"value": "X123"
},
{
"type": "eq",
"property": "project_code",
"value": "X999"
}
]
},
{
"type": "eq",
"property": "confidentiality",
"value": "top_secret"
}
]
},
{
"type": "eq",
"property": "language",
"value": "en"
}
]
}排序
如果你发现文件搜索结果的相关性不够,可以调整ranking_options来提高响应质量。这包括指定ranker,例如auto或default-2024-08-21,以及设置0.0到1.0之间的score_threshold。较高的score_threshold将把结果限制为更相关的片段,但可能会排除一些潜在有用的片段。
向量存储
向量存储是为检索API和助手API文件搜索工具提供语义搜索支持的容器。当你将文件添加到向量存储时,它会自动被分块、嵌入和索引。
向量存储包含vector_store_file对象,这些对象由file对象支持。
| 对象类型 | 描述 |
|---|---|
| file | 表示通过Files API上传的内容。通常与向量存储一起使用,但也用于微调等其他用途。 |
| vector_store | 可搜索文件的容器。 |
| vector_store.file | 专门表示已被分块和嵌入并与vector_store关联的文件的包装类型。包含用于过滤的属性映射。 |
定价
你将根据所有向量存储中使用的总存储量收费,这由解析的片段及其相应嵌入的大小决定。
| 存储 | 费用 |
|---|---|
| 最多1 GB(所有存储总和) | 免费 |
| 超过1 GB | $0.10/GB/天 |
有关最小化成本的选项,请参见过期政策。
向量存储操作
创建
创建向量存储
python
client.vector_stores.create(
name="支持FAQ",
file_ids=["file_123"]
)
javascript
await client.vector_stores.create({
name: "支持FAQ",
file_ids: ["file_123"]
});检索
检索向量存储
python
client.vector_stores.retrieve(
vector_store_id="vs_123"
)
javascript
await client.vector_stores.retrieve({
vector_store_id: "vs_123"
});更新
更新向量存储
python
client.vector_stores.update(
vector_store_id="vs_123",
name="支持FAQ已更新"
)
javascript
await client.vector_stores.update({
vector_store_id: "vs_123",
name: "支持FAQ已更新"
});删除
删除向量存储
python
client.vector_stores.delete(
vector_store_id="vs_123"
)
javascript
await client.vector_stores.delete({
vector_store_id: "vs_123"
});列表
列出向量存储
python
client.vector_stores.list()
javascript
await client.vector_stores.list();向量存储文件操作
有些操作,如vector_store.file的create,是异步的,可能需要时间完成------使用我们的辅助函数,如create_and_poll来阻塞直到完成。否则,你可以检查状态。
创建
创建向量存储文件
python
client.vector_stores.files.create_and_poll(
vector_store_id="vs_123",
file_id="file_123"
)
javascript
await client.vector_stores.files.create_and_poll({
vector_store_id: "vs_123",
file_id: "file_123"
});上传
上传向量存储文件
python
client.vector_stores.files.upload_and_poll(
vector_store_id="vs_123",
file=open("customer_policies.txt", "rb")
)
javascript
await client.vector_stores.files.upload_and_poll({
vector_store_id: "vs_123",
file: fs.createReadStream("customer_policies.txt"),
});检索
检索向量存储文件
python
client.vector_stores.files.retrieve(
vector_store_id="vs_123",
file_id="file_123"
)
javascript
await client.vector_stores.files.retrieve({
vector_store_id: "vs_123",
file_id: "file_123"
});更新
更新向量存储文件
python
client.vector_stores.files.update(
vector_store_id="vs_123",
file_id="file_123",
attributes={"key": "value"}
)
javascript
await client.vector_stores.files.update({
vector_store_id: "vs_123",
file_id: "file_123",
attributes: { key: "value" }
});删除
删除向量存储文件
python
client.vector_stores.files.delete(
vector_store_id="vs_123",
file_id="file_123"
)
javascript
await client.vector_stores.files.delete({
vector_store_id: "vs_123",
file_id: "file_123"
});列表
列出向量存储文件
python
client.vector_stores.files.list(
vector_store_id="vs_123"
)
javascript
await client.vector_stores.files.list({
vector_store_id: "vs_123"
});批量操作
创建
批量创建操作
python
client.vector_stores.file_batches.create_and_poll(
vector_store_id="vs_123",
file_ids=["file_123", "file_456"]
)
javascript
await client.vector_stores.file_batches.create_and_poll({
vector_store_id: "vs_123",
file_ids: ["file_123", "file_456"]
});检索
批量检索操作
python
client.vector_stores.file_batches.retrieve(
vector_store_id="vs_123",
batch_id="vsfb_123"
)
javascript
await client.vector_stores.file_batches.retrieve({
vector_store_id: "vs_123",
batch_id: "vsfb_123"
});取消
批量取消操作
python
client.vector_stores.file_batches.cancel(
vector_store_id="vs_123",
batch_id="vsfb_123"
)
javascript
await client.vector_stores.file_batches.cancel({
vector_store_id: "vs_123",
batch_id: "vsfb_123"
});列表
批量列表操作
python
client.vector_stores.file_batches.list(
vector_store_id="vs_123"
)
javascript
await client.vector_stores.file_batches.list({
vector_store_id: "vs_123"
});属性
每个vector_store.file都可以有关联的attributes,这是一个字典,在执行带有属性过滤的语义搜索时可以引用。该字典最多可以有16个键,每个键最多256个字符。
创建带有属性的向量存储文件
python
client.vector_stores.files.create(
vector_store_id="<vector_store_id>",
file_id="file_123",
attributes={
"region": "US",
"category": "Marketing",
"date": 1672531200 # 2023年1月1日
}
)
javascript
await client.vector_stores.files.create(<vector_store_id>, {
file_id: "file_123",
attributes: {
region: "US",
category: "Marketing",
date: 1672531200, // 2023年1月1日
},
});过期政策
你可以使用expires_after为vector_store对象设置过期政策。向量存储过期后,所有关联的vector_store.file对象将被删除,你将不再为它们付费。
为向量存储设置过期政策
python
client.vector_stores.update(
vector_store_id="vs_123",
expires_after={
"anchor": "last_active_at",
"days": 7
}
)
javascript
await client.vector_stores.update({
vector_store_id: "vs_123",
expires_after: {
anchor: "last_active_at",
days: 7,
},
});限制
最大文件大小为512 MB。每个文件包含的令牌不应超过5,000,000个(附加文件时自动计算)。
分块
默认情况下,max_chunk_size_tokens设置为800,chunk_overlap_tokens设置为400,这意味着每个文件通过分割成800个令牌的块进行索引,连续块之间有400个令牌的重叠。
你可以在将文件添加到向量存储时通过设置chunking_strategy来调整这一点。chunking_strategy有一定的限制:
max_chunk_size_tokens必须在100到4096之间(含100和4096)。chunk_overlap_tokens必须是非负的,且不应超过max_chunk_size_tokens / 2。
支持的文件类型
对于text/ MIME类型,编码必须是utf-8、utf-16或ascii之一。
| 文件格式 | MIME类型 |
|---|---|
| .c | text/x-c |
| .cpp | text/x-c++ |
| .cs | text/x-csharp |
| .css | text/css |
| .doc | application/msword |
| .docx | application/vnd.openxmlformats-officedocument.wordprocessingml.document |
| .go | text/x-golang |
| .html | text/html |
| .java | text/x-java |
| .js | text/javascript |
| .json | application/json |
| .md | text/markdown |
| application/pdf | |
| .php | text/x-php |
| .pptx | application/vnd.openxmlformats-officedocument.presentationml.presentation |
| .py | text/x-python |
| .py | text/x-script.python |
| .rb | text/x-ruby |
| .sh | application/x-sh |
| .tex | text/x-tex |
| .ts | application/typescript |
| .txt | text/plain |
生成响应
执行查询后,你可能希望根据结果生成响应。你可以利用我们的模型来实现这一点,通过提供结果和原始查询,以获得有根据的响应。
执行搜索查询以获取结果
python
from openai import OpenAI
client = OpenAI(base_url="https://api.aaaaapi.com")
user_query = "退货政策是什么?"
results = client.vector_stores.search(
vector_store_id=vector_store.id,
query=user_query,
)
javascript
const { OpenAI } = require('openai');
const client = new OpenAI({ baseURL: "https://api.aaaaapi.com" });
const userQuery = "退货政策是什么?";
const results = await client.vectorStores.search({
vector_store_id: vector_store.id,
query: userQuery,
});根据结果生成响应
python
formatted_results = format_results(results.data)
'\n'.join('\n'.join(c.text) for c in result.content for result in results.data)
completion = client.chat.completions.create(
model="gpt-4.1",
messages=[
{
"role": "developer",
"content": "根据提供的来源,对查询产生简洁的回答。"
},
{
"role": "user",
"content": f"Sources: {formatted_results}\n\nQuery: '{user_query}'"
}
],
)
print(completion.choices[0].message.content)
javascript
const formattedResults = formatResults(results.data);
// 连接所有结果的文本内容
const textSources = results.data.map(result => result.content.map(c => c.text).join('\n')).join('\n');
const completion = await client.chat.completions.create({
model: "gpt-4.1",
messages: [
{
role: "developer",
content: "根据提供的来源,对查询产生简洁的回答。"
},
{
role: "user",
content: `Sources: ${formattedResults}\n\nQuery: '${userQuery}'`
}
],
});
console.log(completion.choices[0].message.content);
json
"我们的退货政策允许在购买后30天内退货。"这使用了一个示例format_results函数,其实现如下:
示例结果格式化函数
python
def format_results(results):
formatted_results = ''
for result in results.data:
formatted_result = f"<result file_id='{result.file_id}' file_name='{result.file_name}'>"
for part in result.content:
formatted_result += f"<content>{part.text}</content>"
formatted_results += formatted_result + "</result>"
return f"<sources>{formatted_results}</sources>"
javascript
function formatResults(results) {
let formattedResults = '';
for (const result of results.data) {
let formattedResult = `<result file_id='${result.file_id}' file_name='${result.file_name}'>`;
for (const part of result.content) {
formattedResult += `<content>${part.text}</content>`;
}
formattedResults += formattedResult + "</result>";
}
return `<sources>${formattedResults}</sources>`;
}在处理大量文件检索或需要稳定API连接时,选择可靠的服务至关重要。我们提供的API中转服务通过https://api.aaaaapi.com提供优化的连接,特别适合需要高效处理向量存储和语义搜索的场景。如果在使用过程中遇到任何连接问题,可访问官网了解更多解决方案,确保你的检索操作顺畅进行。