GPT系列文章
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:LLMHub,欢迎关注收藏!
2019 年,OpenAI 发布了《Language Models are Unsupervised Multitask Learners》论文,也就是 GPT-2。相比 GPT-1,GPT-2 不仅将参数规模从 1 亿级别提升至 15 亿,还首次展现了零样本(zero-shot)能力,真正让人意识到大规模语言模型的强大潜力。
这篇博客将带你走进 GPT-2 的核心思想、训练方法和模型架构,理解它为何成为后续 GPT-3/GPT-4 崛起的关键跳板。
在阅读这篇文章前,建议你先思考以下三个问题:
- GPT-2 为什么能实现"零样本学习",而不像 GPT-1 那样还需要微调?
- GPT-2 和 GPT-1 都是使用 Transformer 解码器架构,它的结构到底有什么改进?为什么规模提升能带来能力飞跃?
- GPT-2 在多任务上表现出强大的通用性,是因为训练数据变了吗?还是训练目标发生了变化?
1. 背景
GPT-1 采用了"预训练 + 微调"的范式,即先用大语料做无监督预训练,然后在每个具体任务上再进行有监督微调。但 GPT-2 提出了一个更激进的设想:
能不能完全不微调,只通过改变输入提示的方式,让模型直接完成下游任务?
这就是 GPT-2 的"零样本多任务学习"理念。
2. 模型结构
GPT-2 延续了 GPT-1 的架构 ------ Transformer Decoder(无编码器),核心结构保持不变,但做了如下几项关键改进:

结论:模型越大,性能越强,泛化能力越好。这也是"Scaling Law"(规模法则)概念的雏形。
3. 训练数据
GPT-2 没有使用 Wikipedia,而是构建了一个更具开放性和多样性的语料集 ------ WebText。
- 来源:8M 高质量网页链接,去除了 Reddit 得分 < 3 的链接,过滤了低质量内容。
- 大小:40GB,涵盖新闻、小说、维基百科、论坛、编程等各种风格
- 优点:包含更多自然对话、长文本、结构化知识
这使得 GPT-2 更具通用语言理解与生成能力。
4. 训练目标
GPT-2 只使用了**语言建模(Language Modeling)**作为唯一的训练目标:
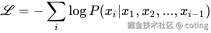
其中x1,x2,...,xi−1是当前 token 前面所有的词,作为上下文输入。
但它创新性地发现:通过设计合适的 prompt(提示词),模型可以自动"识别任务类型",并给出合适的回答。
例如:
plain
输入:Translate English to French: The house is wonderful.
输出:La maison est magnifique.在训练中 GPT-2 并没有看过这种任务标签,但因为语料中包含大量"任务式语言模式",它学会了任务迁移能力!
5. 多任务能力验证
论文在多个任务上验证了 GPT-2 的能力:
- 文本生成(Writing prompts)
- 阅读理解(RACE, LAMBADA)
- 翻译(WMT English→French/German)
- 问答(CoQA)
- 语言建模(WikiText-103)

结果显示:
- 即使没有微调(Zero-shot),GPT-2 也能在多个任务中逼近甚至超越微调模型的性能。
- 随着提示方式和样例数量的增加(One-shot, Few-shot),效果显著提升。
- 模型越大,能力越强:GPT-2 XL 是最强的。
最后,我们回答一下文章开头提出的问题。
- GPT-2 为什么能实现"零样本学习",而不像 GPT-1 那样还需要微调?
GPT-2 能实现零样本学习,是因为它在大规模通用语料(WebText)上训练了一个强大的语言建模器。通过设计不同的自然语言提示(Prompt),模型能自动理解任务意图并给出回答,无需为每个任务单独微调模型参数。
- GPT-2 和 GPT-1 都是使用 Transformer 解码器架构,它的结构到底有什么改进?为什么规模提升能带来能力飞跃?
GPT-2 在结构上与 GPT-1 相同,依然是 Transformer 解码器架构。但 GPT-2 将模型规模从 1 亿参数扩展到 15 亿,并在训练数据量和训练步数上大幅增加,遵循"规模越大,泛化越强"的 Scaling Law。这种扩展极大增强了模型的语言理解与生成能力。
- GPT-2 在多任务上表现出强大的通用性,是因为训练数据变了吗?还是训练目标发生了变化?
GPT-2 的训练目标并没有改变,仍是自回归语言建模。但其训练语料 WebText 更贴近真实世界任务语言模式,使得模型学会了对自然语言任务格式的泛化,从而实现了多任务的统一处理。这种能力来源于"数据+模型规模"的双重增强。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号算法coting!