目录
[回到最原始的问题 ------ 我们如何存数据?](#回到最原始的问题 —— 我们如何存数据?)
结构推导
🎯 目标:理解什么是链表(linked list),为什么我们需要它,以及它的结构从哪里来的。
回到最原始的问题 ------ 我们如何存数据?
在 C 语言中,最基础的存数据方式是:
cpp
int a[100];也就是 数组(array)。它非常常见,我们从一开始就用。
那我们先从数组的"第一性"特征说起:
数组的本质是:
一块连续的内存空间 + 索引访问
举个例子:
cpp
int a[5] = {10, 20, 30, 40, 50};这个数组在内存里是这样的(假设从地址 1000 开始):
| 地址 | 值 |
|---|---|
| 1000 | 10 |
| 1004 | 20 |
| 1008 | 30 |
| 1012 | 40 |
| 1016 | 50 |
它的特性:
-
地址连续
-
ai 的位置是:a + i × sizeof(int)
-
可以快速通过索引访问:O(1)
详细内容可以参考:数据结构:数组(Array)_array1..50-CSDN博客
第二步:我们来看看数组的限制
情况1:大小固定
如果你定义了:
cpp
int a[100];你就固定只能存最多 100 个元素。如果只用了前 5 个元素,空间也浪费。
如果你事先不知道需要多少个元素,就很难选大小。
情况2:插入麻烦
假设你已经有数组:
cpp
int a[5] = {10, 20, 30, 40, 50};现在你想在 第 2 个位置插入 99,就得把后面的都搬一格:
cpp
for (int i = 5; i > 1; i--) {
a[i] = a[i - 1];
}
a[1] = 99;这会导致O(n) 的时间复杂度。
情况3:删除也麻烦
类似的,如果你要删掉 a2,也得把后面的全往前搬一格。
总结数组的问题:
| 问题 | 描述 |
|---|---|
| 空间不灵活 | 空间必须一开始就定下来 |
| 插入慢 | 中间插入要整体移动元素 |
| 删除慢 | 删除某项也要移动后面的元素 |
| 空间浪费 | 有时只用一部分数组,但仍然占内存 |
第三步:那我们该怎么做呢?
我们思考一下:
能不能只在用到数据时,才开辟空间?
能不能插入一个元素,而不影响其它元素的位置?
这就引出了一个新的思维模型:
✅ 使用"分散空间 + 指针连接"的模型
如果我们不强求内存连续,而是:
-
每次添加一个节点时,就用
malloc单独开一块空间 -
每个节点都保存指向"下一个节点"的指针
我们就可以实现灵活的动态结构了。
这就是 链表(linked list) 的思想:
把所有的数据节点一个一个连起来,而不是排成连续数组
第四步:我们推导链表的数据结构
我们要存一个元素,它需要什么?
-
数据本身,比如:一个整数
-
指向下一个节点的"线索"(指针)
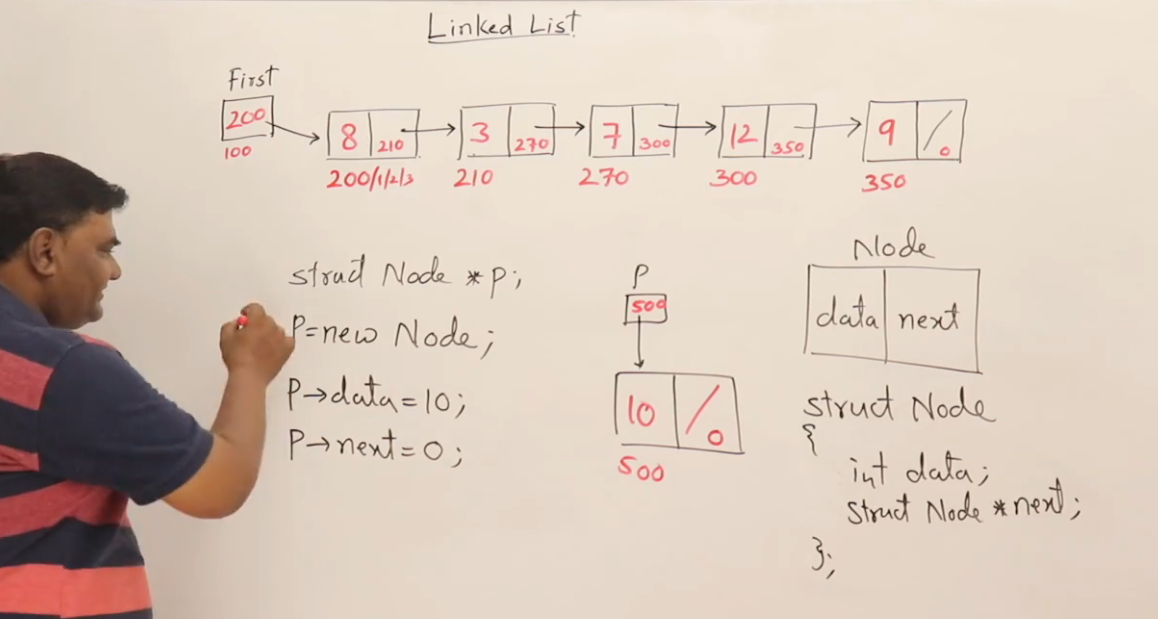
所以我们设计一个节点结构:
cpp
struct Node {
int data; // 当前节点的数据
struct Node* next; // 指向下一个节点
};那一个"链表"是什么?
一个链表是"若干个 Node 连起来",只要有第一个节点(头结点)的地址,就能找到整个链表。
所以我们定义:
cpp
struct Node* head; // 指向链表的起点✅ 所以链表的基本单位是:节点 + 指针
cpp
[10 | *] --> [20 | *] --> [30 | NULL]-
每个方块是一个
Node -
*是next指针 -
最后一个节点的
next = NULL表示链表结束
结论:为什么我们需要链表?
| 问题 | 链表怎么解决 |
|---|---|
| 数组大小固定 | 链表可以动态增加节点(malloc) |
| 插入/删除慢 | 链表插入删除只需修改指针,不搬数据 |
| 空间浪费 | 用多少开多少,不多开 |
结构讲解
什么是链表?
在数组中,所有元素都在一块连续的内存空间中。你只能在一开始就分配好大小,插入/删除不方便。那么:
有没有一种数据结构,不要求数据连续存储,但依然能一个接一个地串起来?
这就是链表的本质:
链表是由若干个节点组成的线性结构,每个节点都知道下一个节点在哪里,只需要记住第一个节点就能访问整个链表。
链表的核心思想是:
每个节点知道"谁在后面",就像每一节车厢都知道后面那节车厢的位置。
整个链表就像是一列火车,每节车厢通过"挂钩"(指针)串联起来:
✅ 链表的特征:
-
节点之间不要求连续内存
-
每个节点都包含:
-
本节点的数据
-
指向下一个节点的指针
-
-
通过"指针"把节点连接起来
通常我们用一个指针 head 来指向第一个节点:
cpp
struct Node* head;什么是节点?
一个节点(Node)是链表的最基本组成单位,就是一个结构体,它包含:
-
一份数据(例如 int 类型)
-
一个指针,指向下一个节点
这就好比:
-
火车的每节车厢(节点)都有:
-
货物(数据)
-
连接器(指针)去连下一节车厢
-
用C语言表示:
cpp
struct Node {
int data; // 节点中存的数据
struct Node* next; // 指向下一个节点的指针
};| 成员 | 含义 |
|---|---|
int data |
存储数据,比如整数 10 |
Node* next |
保存下一个节点的地址,如果是最后一个就为 NULL |
如何创建节点?
为什么我们不能直接写:
cpp
struct Node node1;- 这句代码在 栈(stack)上 分配了一个 Node 类型的变量。它的特点是:
-
分配在栈上(函数调用结束后会被自动释放)
-
内存大小在编译时就已经确定
-
生命周期由作用域决定,作用域结束就失效
🔍 2. 链表是动态结构,不能预知节点个数
链表的本质是:
-
你不知道总共有多少个节点(比如根据用户输入构建)
-
每一个节点都需要"现用现开",而不是提前一次性分配
所以我们需要在"运行时"动态分配空间:
cpp
struct Node* newNode = (struct Node*) malloc(sizeof(struct Node));这行代码的含义是:
-
malloc(sizeof(struct Node))在堆(heap)上动态分配一块内存,大小正好是一个 Node -
返回值是
void*,强制类型转换成struct Node* -
newNode是一个指针,指向新建的节点
再从链表的设计需求来倒推
-
节点数是动态变化的(例如用户输入10个节点)
-
节点之间是用指针连接的
-
每个节点可能在任何时刻被插入或删除
-
节点需要长期存在,甚至跨越函数作用域
所以:必须用动态内存分配,也就是
malloc()。struct Node node1;是不能满足上述需求的
如何访问节点?
假设我们已经创建了多个节点,并链接起来:
cpp
struct Node* head = (struct Node*) malloc(sizeof(struct Node));
head->data = 10;
struct Node* second = (struct Node*) malloc(sizeof(struct Node));
second->data = 20;
head->next = second;
second->next = NULL;访问链表节点的本质逻辑是沿着 next 指针走,这就叫做遍历链表(traverse the linked list)。
举个例子,假设你有一个链表,要访问节点内容:
cpp
head → [10 | * ] → [20 | * ] → [30 | NULL]你想访问第二个节点的值 20:
你不能说 head[1],因为它不是数组。
你只能说:
cpp
head->next->data这个表达式的意义是:
-
head是第一个节点的地址 -
head->next是第二个节点的地址 -
head->next->data就是第二个节点的值
访问第二个节点的数据:
cpp
printf("%d\n", head->next->data); // 输出 20遍历就是:
从
head开始,沿着每个节点的next指针走,直到你走到 NULL(链表结尾)
cpp
struct Node* temp = head;
while (temp != NULL) {
printf("%d ", temp->data);
temp = temp->next;
}
printf("\n");这段代码会访问每个节点的 data,直到遇到 NULL。