一. 作用
图像增广可以通过调节训练样本,从而增加模型的泛化能力。
二. 代码
通过torchvision.transforms 实现
| 作用 | 函数 |
|---|---|
| 左右翻转 | RandomHorizontalFlip() |
| 上下翻转 | RandomVerticalFlip() |
| 随机裁剪 | RandomResizedCrop((width,height),scale=(0.1,1), ratio=()) |
| 改变颜色 | ColorJitter(brightness=0.5,contrast=0,saturation=0,hue=0) |
| 多种结合 | Compose( ) |
注:
- scale 代表相对原始面积的缩放比例,示例中设置的 10%-100%
- ratio 代表宽高比,0.5-2
- brightness 代表亮度
- contrast 代表对比度
- saturation 代表饱和度
- hue 代表色调
三. 具体实现
3.1 数据预处理
数据集下载与查看
从torchvision的datasets中下载 CIFAR-10 数据集(10 分类,50000 张图片),并用 0.8 的比例查看前 32 个训练样本。

python
all_images = torchvision.datasets.CIFAR10(root='data/CIFAR',train=True,download=True)
d2l.show_images([all_images[i][0] for i in range(32)],4,8,scale=0.8)加载数据集
我们只针对训练样本进行增广,这里我们只使用最简单的随机左右翻转,并利用 ToTensor 实例将一批图像转换为深度学习框架所需要的格式,即形状为(批量大小,通道数,高度,宽度)的 32位浮点数,取值范围为 0-1。
python
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
])
test_augs = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
])封装加载数据函数,在读取数据阶段,进行数据的预处理(通过transform 设置参数),并加载相应批量的数据。
python
def load_cifar10(is_train,augs,batch_size):
dataset = torchvision.datasets.CIFAR10(root='data/CIFAR',train=is_train,download=True,transform=augs)
dataloader = torch.utils.data.DataLoader(dataset,batch_size=batch_size,shuffle=True,num_workers=d2l.get_dataloader_workers())
return dataloader注意这里对于 dataloader 的理解:
对于 Dataloader 主要为了避免把过度数据加载到内存,而导致内存溢出,从而分批次的加载数据,也就是 batch_size, 同时利用len(train_iter)也可以查看批次的数量,比如对于 50000 的数据,如果 batch_size 等于 5000,那么 len(train_iter) 就等于 10
另外,也可以通过 enumerate 方法对于每个批次进行迭代, 如下图,每次返回的是10000 批次的数据,一共迭代 5 次。 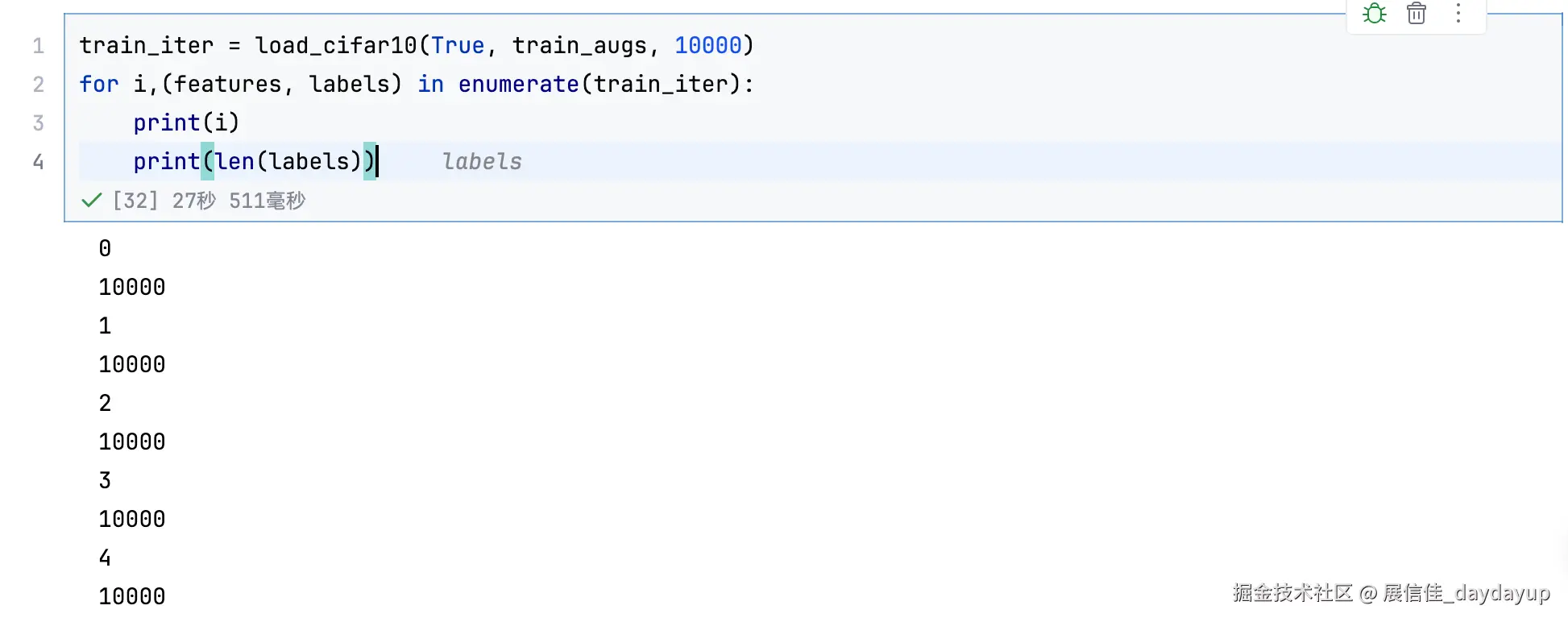
3.2 模型定义与选择
这里采用resnet 模型(10 类,3 个通道),通过调用d2l 中对应的代码
3.3 模型初始化
设置每次批次的大小的 256,采用 gpu 和 resnet 模型
之后进行模型参数初始化,如果当前层是线性层(nn.Linear)或二维卷积层(nn.Conv2d),就使用 Xavier 均匀分布(xavier_uniform_)初始化该层的权重
Xavier 初始化的优点是可以让网络中信号的正向传播和反向传播时的方差尽可能一致,有助于加快模型收敛
python
batch_size, devices, net = 256,[ torch.device("gpu")], d2l.resnet18(10, 3)
def init_weights(m):
if type(m) in [nn.Linear, nn.Conv2d]:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)3.4 模型训练
单批量训练
1)设置为训练模式
通过net.train() 设置模型为训练模式,此时会激活 dropout,批量归一化
注:
- dropout 是一种常见的正则化技术,通过随机丢弃一些节点,限制模型复杂度,以及对于某个节点的过度依赖,导致模型过拟合。
- 批量归一化通常用于卷积层或全连接层之后、激活函数之前,对层的输入进行归一化处理,为激活函数提供更稳定的输入分布,从而实现加速训练收敛
2)计算模型损失
初始化优化器的梯度,并计算 loss,并利用反向传播,更新模型参数,同时统计 loss 和 acc
python
def train_batch_ch13(net, X, y, loss, trainer, device):
if isinstance(X, list):
X = [x.to(cpu_device) for x in X]
else:
X = X.to(cpu_device)
y = y.to(cpu_device)
net.train()
trainer.zero_grad()
pred = net(X)
l = loss(pred, y)
# 自动计算损失 l 对模型所有可训练参数(w、b等)的梯度
l.sum().backward()
# 根据梯度更新参数
trainer.step()
train_loss_sum = l.sum()
train_acc_sum = d2l.accuracy(pred, y)
return train_loss_sum, train_acc_sum数据集训练
设置相应的轮次,并显示不同轮次的总损失,以及训练集和测试集的准确率。
其中metric的意思是衡量标准,主要存储了训练损失,训练准确度,实例数以及特征数。
labels.shape[0]:当前批次的样本数量(labels是标签张量,shape[0]表示第一维度的大小,即批次大小batch_size)。labels.numel():当前批次的标签总数量(通过numel()计算标签张量的元素总数,在分类任务中通常等于般等于样本数量,因为每个样本对应一个标签)。
animator 是d2l 库中的可视化部分,同时设置按 1/5 间隔更新,既能反映训练趋势,又不会丢失关键信息。
python
def train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices):
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch',xlim=[1, num_epochs],ylim=[0,1],legend=['train loss','train acc', 'test acc'])
net = nn.DataParallel(net,device_ids=devices).to(devices[0])
for epoch in range(num_epochs):
metric = d2l.Accumulator(4)
for i,(features, labels) in enumerate(train_iter):
timer.start()
l, acc = train_batch_ch13(net, features, labels, loss, trainer, devices)
metric.add(l,acc,labels.shape[0],labels.numel())
timer.stop()
if (i+1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch+(i+1)//num_batches, (metric[0]/metric[2],metric[1]/metric[3],None))
test_acc = d2l.evaluate_accuracy_gpu(net,test_iter)
animator.add(epoch+1, (None,None,test_acc))
print(f'loss {metric[0] / metric[2]:.3f}, train acc '
f'{metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on '
f'{str(devices)}')注意对于上述代码:
metric[0] / metric[2](计算平均损失)
metric是之前代码中使用的d2l.Accumulator类型的对象,用于累积训练过程中的各项指标数据。metric[0]存储的是整个训练过程中所有批次的总损失值(通过不断累加每个批次的损失l得到)。metric[2]存储的是整个训练过程中参与训练的总样本数(通过不断累加每个批次的样本数labels.shape[0]得到)。- 二者相除
metric[0] / metric[2]就得到了平均损失,也就是每个样本平均产生的损失值,:.3f表示将这个结果以保留三位小数的浮点数格式进行格式化输出,这样能直观地展示出模型训练过程中的损失情况,损失值越小通常意味着模型预测效果越好。
metric[1] / metric[3](计算训练准确率)
metric[1]累积的是整个训练过程中所有批次的正确预测数总和(通过不断累加每个批次的正确预测数acc得到)。metric[3]累积的是整个训练过程中所有批次的标签总数(通过不断累加每个批次的labels.numel()得到,在分类任务中通常等同于总样本数)。- 用
metric[1] / metric[3]计算出训练准确率,即模型在训练集上正确预测的样本占总样本的比例,同样以保留三位小数的浮点数格式输出,准确率越高说明模型在训练集上的表现越好。
test_acc(展示测试准确率)
test_acc是在训练结束后通过d2l.evaluate_accuracy_gpu(net, test_iter)计算得到的模型在测试集上的准确率,也是以保留三位小数的浮点数格式输出,它反映了模型对未见过的数据(测试集数据)的泛化能力,用于评估模型在实际应用场景中的表现。
下面的就是调用,同时定义数据和优化器,主要采用 Adam 进行优化。
python
def train_with_data_aug(train_augs, test_augs, net, lr=0.001):
train_iter = load_cifar10(True, train_augs, batch_size)
test_iter = load_cifar10(False, test_augs, batch_size)
loss = nn.CrossEntropyLoss(reduction="none")
trainer = torch.optim.Adam(net.parameters(), lr=lr)
train_ch13(net, train_iter, test_iter, loss, trainer, 10, devices)开始训练数据:
python
train_with_data_aug(train_augs, test_augs, net)