ALOcc
未开源ALOcc: Adaptive Lifting-based 3D Semantic Occupancy and
Cost Volume-based Flow Prediction
https://github.com/cdb342/ALOcc
Abstract
- 引入了一种采用深度去噪的占据感知自适应提升机制,以改进2D到3D特征变换的鲁棒性,并减少对深度先验的依赖。
- 利用共享语义原型来共同约束2D和3D特征,从而加强3D特征和其原始2D模态之间的语义一致性。与基于置信度和类别的采样策略相辅相成,以应对 3D 空间中的长尾挑战。
- 为了减轻在语义和光流联合预测的编码负担,提出了一种基于BEV基于体积代价的预测方法,该方法通过代价体积将光流和语义特征链接起来,并采用分类-回归监督方案来处理动态场景中变化的流尺度。
- 2nd place in the CVPR24 Occupancy and Flow Prediction Competition.
Introduction
与传统的边界框相比,3D semantic occupancy提供了场景语义的规范化表示、更细的粒度和更通用的形式。Vision-based 3D semantic occupancy的任务是通过2D的图像做为输入,预测一个规范化的3D语义场景表示。从而引入了另一个难题:2D到3D的重建。如何将预测正确的2D语义信息准确地映射至3D空间中,是当前研究的一个难点。对此,本文研究了现有的两种2D-3D的变换方式:
- 基于深度的lift-splat-shoot(LSS)
即通过预测2.5D的结构数据(深度预测),将2D信息映射至3D空间中。
但是LSS存在两个问题:1. 需要依赖深度先验,由于早期的深度估计方法不够准确,容易陷入局部最优。2. 由于LSS方法中基于射线的映射会导致远处物体的信息丢失。 - 2D和3D的cross attention(CA).
即利用3D queries 直接进行交叉注意力,被动地、自适应地将 2D 信息转移到 3D 中。
为了解决这些问题,
- 本文提出了一种占据感知自适应提升的方法,该方法基于一个明确的深度概率,构建从表面到占据内部的稀疏位置转移概率。就像人可以通过局部视图推测被遮挡物体的形状和范围。
- 在occupancy decoder中,本文引入了一种语义增强方法,利用共享语义原型集将三维和二维特征关联起来。我们预先定义了每个类别的语义原型,以聚合来自三维和二维特征的类别语义。有助于将原始二维信号中的类间语义关系转移到三维信号中,并改进三维语义表征学习。然后,我们利用这些原型计算每个类别的分割mask。
- 为了解决场景中的长尾问题,只有当场景中出现相应类别时,才会对每个原型进行训练。此外,我们还在引入了一种基于不确定性和类别先验的采样技术。我们根据类别统计和每个体素预测的不确定性对体素进行抽样。,仅在采样的体素上进行训练。
- 本文提出了一种基于BEV的代价体积预测方法,以解决语义和光流联合预测的编码负担。该方法将光流和语义特征链接起来,并采用分类-回归监督方案来处理动态场景中变化的流尺度。
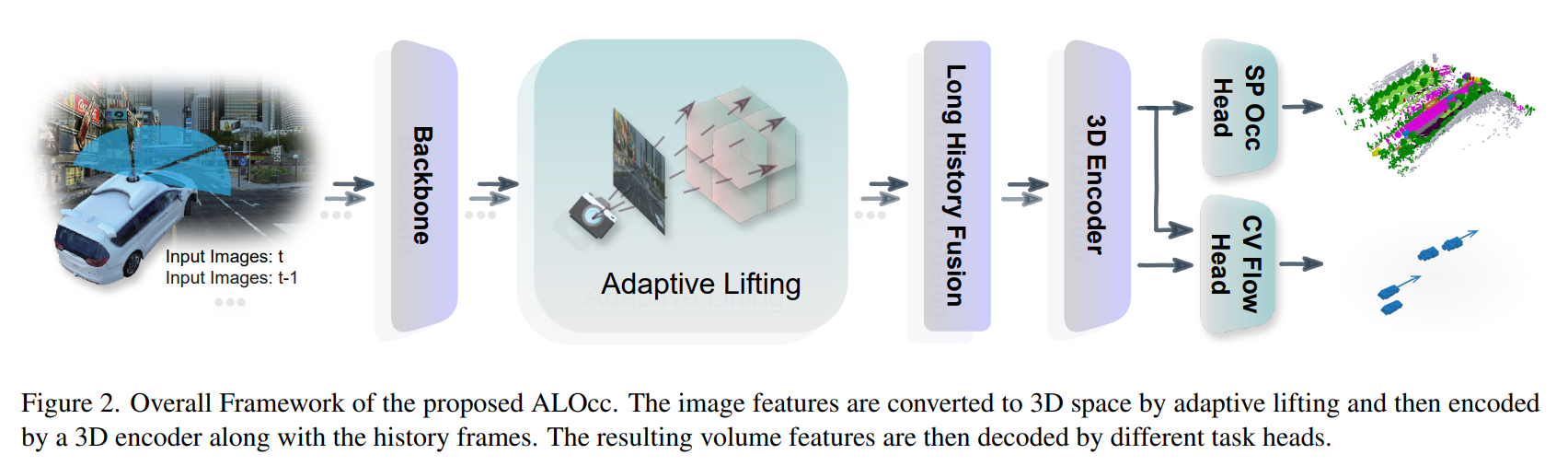
Method
Occlusion-Aware Adaptive Lifting
与depth-based LSS相比, 我们采用基于概率的软填充的方式,替换了原有的基于边界的影填充的方法,具体如图所示:
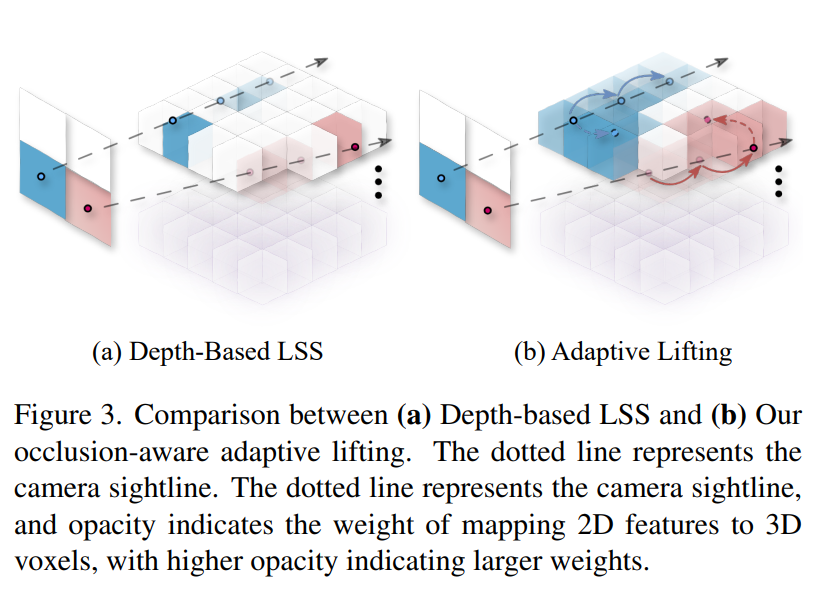
利用三线性插值将概率扩散至该点的八个临近点中,从而实现概率的扩散和空间连续性。
Depth-based LSS通过明确的概率分布来表示深度,然而深度估计的目标遵循δ分布,这导致权重集中在表面点上。因此,被遮挡区域的权重明显较低,导致归纳偏差,限制了模型捕捉这些区域信息的能力。我们的目标是弥合视图转换过程中可见部分和遮挡部分之间的差距。具体来说,我们处理两种类型的遮挡:1)同一物体内的遮挡;2)不同物体之间的遮挡。对于这两种情况,我们都要构建一个从可见部分到闭塞部分的概率转移矩阵。
对于前一种,我们设计了条件概率,将表面概率转移到闭塞长度概率。给定像素点 x 的离散深度概率,我们采用相同的bin来进行离散闭塞区域的长度预测,引入贝叶斯条件概率将离散深度概率转换为离散闭塞长度概率。
对于物体间的遮挡,我们设计了一个概率转移矩阵,将占据概率传播到周围的点。对于每个点,我们根据其特征估计topK个偏移量和相应的转移权重,然后通过软填充纳入到对应深度的变换矩阵中,在训练的过程中进行优化。
为了缓解初始深度估计不准确而造成的次优模型收敛的问题,我们引入了一种类似于queries-based目标检测算法中的去噪操作:在训练中预测深度与深度真值加权融合得到深度概率用于指导模型训练,在训练早期真值的权重为1,然后通过余弦退火策略逐渐减小为0。
Semantic Prototype-based Occupancy Head
在完成二维到三维的特征转换后,我们使用共享原型来增强二维和三维特征之间的语义一致性。如图所示,我们为每个类别初始化一个语义原型,同时在计算二维和三维特征的损失时充当
类别权重。这种共享原型方法创建了连接二维和三维语义的快捷方式,促进了跨维度特征表示的一致性。
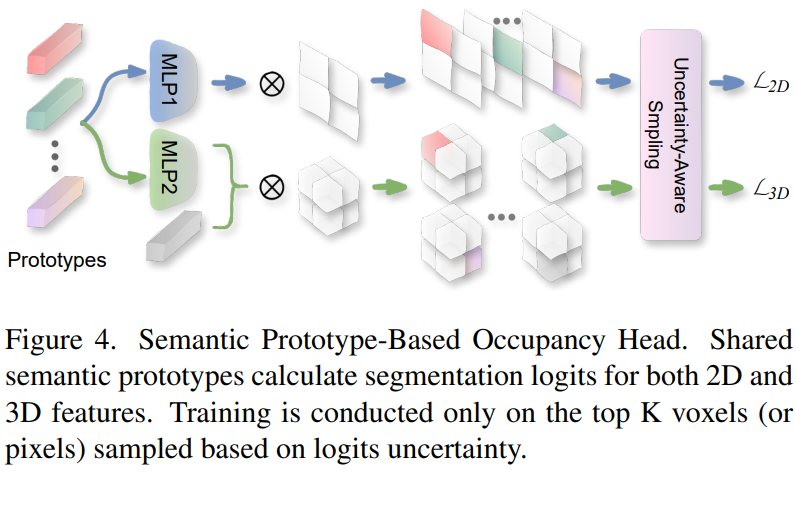
鉴于每个类别的原型,
解码语义占位的直观方法是计算体素特征与原型之间的相似性,然后进行交叉熵监督。然而,由于驾驶场景中的语义类别分布高度不平衡,这种方法并不理想。为了解决这一不平衡问题,我们提出了一种与原型无关的损失,该损失只考虑每个场景中真值的类别分布情况。
我们通过真值提取所有现有语义类别的原型(包括用于空类的嵌入),并计算这些原型与 3D 特征之间的内积,以生成类掩码。为了进一步提高尾部类别的训练效果,我们采用了一种基于不确定性和类别先验的采样技术。我们使用从内积中得出的每个原型 logit 图作为每个象素不确定性的度量。这种不确定性和类先验值构成一个多二项分布。然后,我们根据该分布,从整个占位图中抽取 K 个体素样本。损失只在采样点上计算。最终的三维感知损失被表述为二元交叉熵和分布损失的组合。
BEV Cost Volume-based Occupancy Flow Prediction
我们提出了一种基于BEV的代价体积预测方法,将 0 至 4 米高度的体积特征平均化,以创建一个聚焦前景的 BEV 特征:
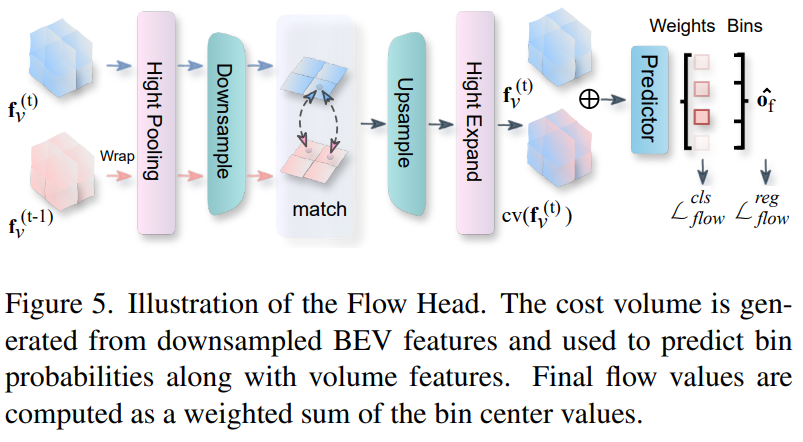
我们对 BEV 特征进行低采样,以增加感受野,同时减少计算开销。然后我们将前一帧的特征信息,利用当前帧的相机参数进行特征匹配,通过计算每对特征之间的余弦相似度构建代价体积。
基于代价体积的流量预测方法通过将特征与上一帧中不同位置的特征进行语义匹配来计算流,从而减轻了对语义和运动进行编码的表征负担。并且可以重复使用上一帧的缓存体积特征,从而避免了二次推理。
为了提高流的预测能力,我们提出了一种回归+分类混合的方法,根据从训练中得出的最大和最小流值,将流值分为多个区间。从而实现连续值的预测。
Experiment