FC-CLIP(在开放词汇问题上的统一)
背景
然而,由于注释这样细粒度数据集的成本很高,语义类别的数量通常限制在几十个或几百个。
因此,使用现有的工具和模型去做这种细粒度的分割,也就是说如果能够利用更多的检测的数据去做分割,可以利用更大的一部分的数据。
这种限制阻碍了现有方法在实际环境中的进一步应用,因为实际环境中可能存在无限数量的语义类别。
这些方法使用自然语言表示的类别名字的文本嵌入作为标签嵌入,而不是从训练数据集中学习它们。通过这样做,模型可以对更宽泛的词汇进行分类,从而提高处理更广泛类别的能力。
之前的方法对比
传统分割模型是在固定类别(封闭词汇)上训练的,无法识别训练集之外的类别。开放词汇分割 的目标是能够分割出训练时没见过的类别。
之前的做法(如 MaskCLIP、ODISE)是两阶段:
- 第一阶段:用一个模型生成类别无关的掩码
- 第二阶段:将每个掩码区域送入 CLIP 进行分类
两阶段方法 :先派一个助手A去把广场上每一个"人形"的轮廓都圈出来(第一阶段:找区域 ),然后你再拿着这些轮廓照片,去和你的通讯录照片一张张对比,看看这到底是谁(第二阶段:认人)。
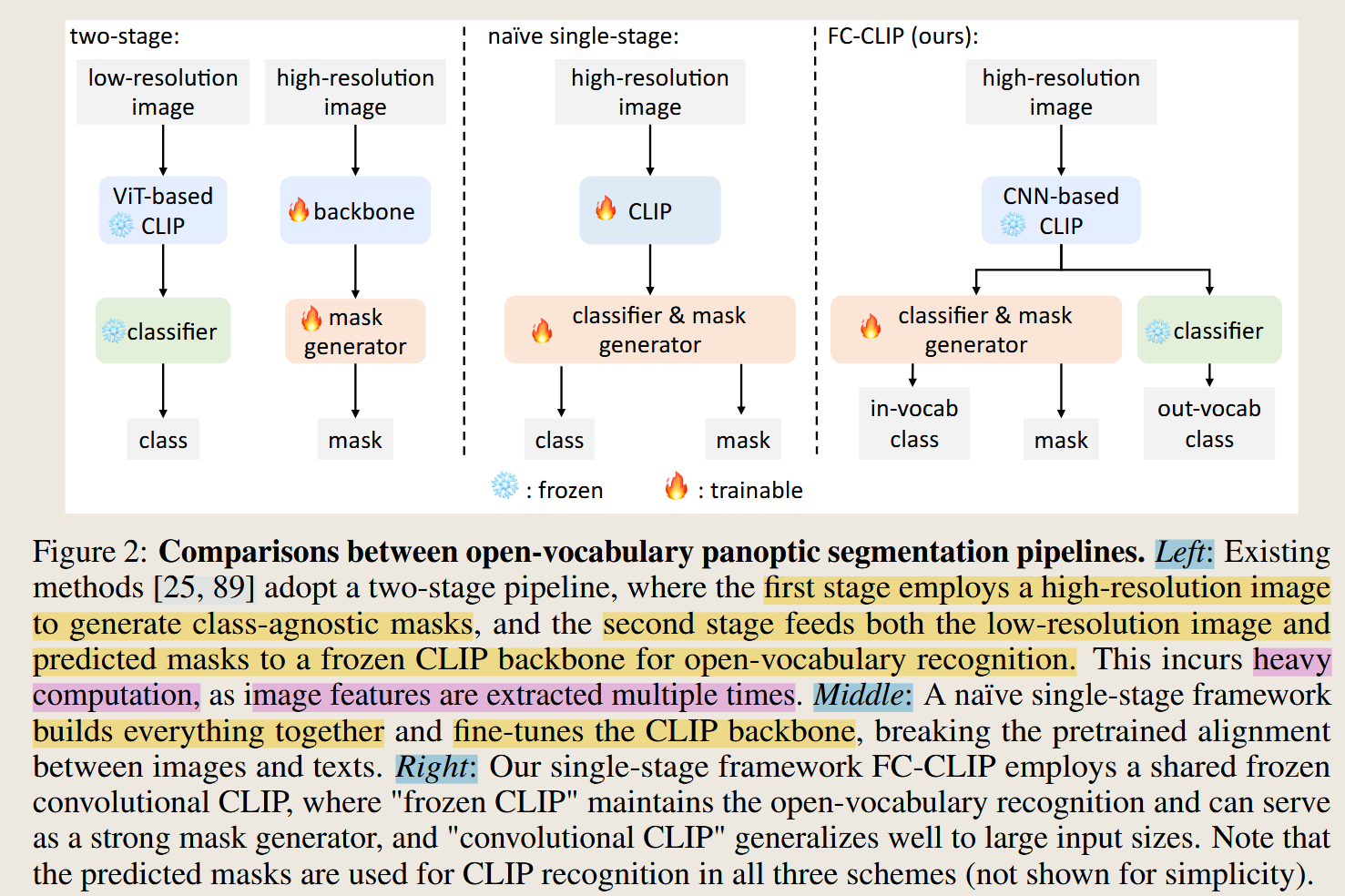
中间的单阶段的方法:
由于两阶段的方法,需要多次提取图像的特征,计算量比较高。因此后面的改进思路是在减少特征提取次数的思路。直接一次性通过CLIP,在CLIP的基础上裁剪mask特征区域。
MaskCLIP将这种方法扩展到开放词汇全景分割,但额外利用掩码建议作为CLIP主干中的注意力掩码,以有效地避免对掩码裁剪进行多次前向传递。
但是上面这样做带来了两个挑战:
- 单阶段采用的微调CLIP主干可能破坏图像和文本特征之间的对齐,导致在超出词汇范围的类别上性能大幅下降。
- 由于CLIP在预训练过程中,通常在相对较低分辨率的输入上进行预训练,密集预测任务 ( 这个任务就是mask decoder的部分,生成mask,mask generator) 需要更高分辨率才能达到最佳性能。这使得将CLIP预训练的主干直接应用于下游的密集预测任务变得困难,特别是基于ViT的CLIP模型,需要仔细处理。因此,FCCLIP使用的是卷积的主干。
为什么是"卷积"的?
- ViT 结构在输入分辨率变大时特征会变"嘈杂"
- CNN 结构(如 ConvNeXt)对分辨率变化更鲁棒,适合密集预测任务
为了缓解这两个挑战,作者提出
- 在一个共享的冻结卷积CLIP主干上构建掩码生成器和CLIP分类器,形成一个单阶段的框架FCCLIP。冻结的CLIP主干确保预训练的图像文本特征对齐完好,可以进行超出词汇范围的类别分类。
- 作者通过将高分辨率的图像缩小到CLIP主干预训练的分辨率来解决第二个挑战,以适应CLIP分类器的要求。
- 然后,作者使用一个轻量级的解码器来生成密集的掩码预测,并将其与图像特征进行融合,以实现开放词汇分割。
- 为了提高模型的性能,作者还提出一种自适应的特征融合策略,通过学习特定类别的注意力权重,来加强与类别相关的特征。具体来说,作者通过全局平均池化层和全连接层从图像特征中生成类别注意力权重,然后将其应用于特征融合过程。
模型结构
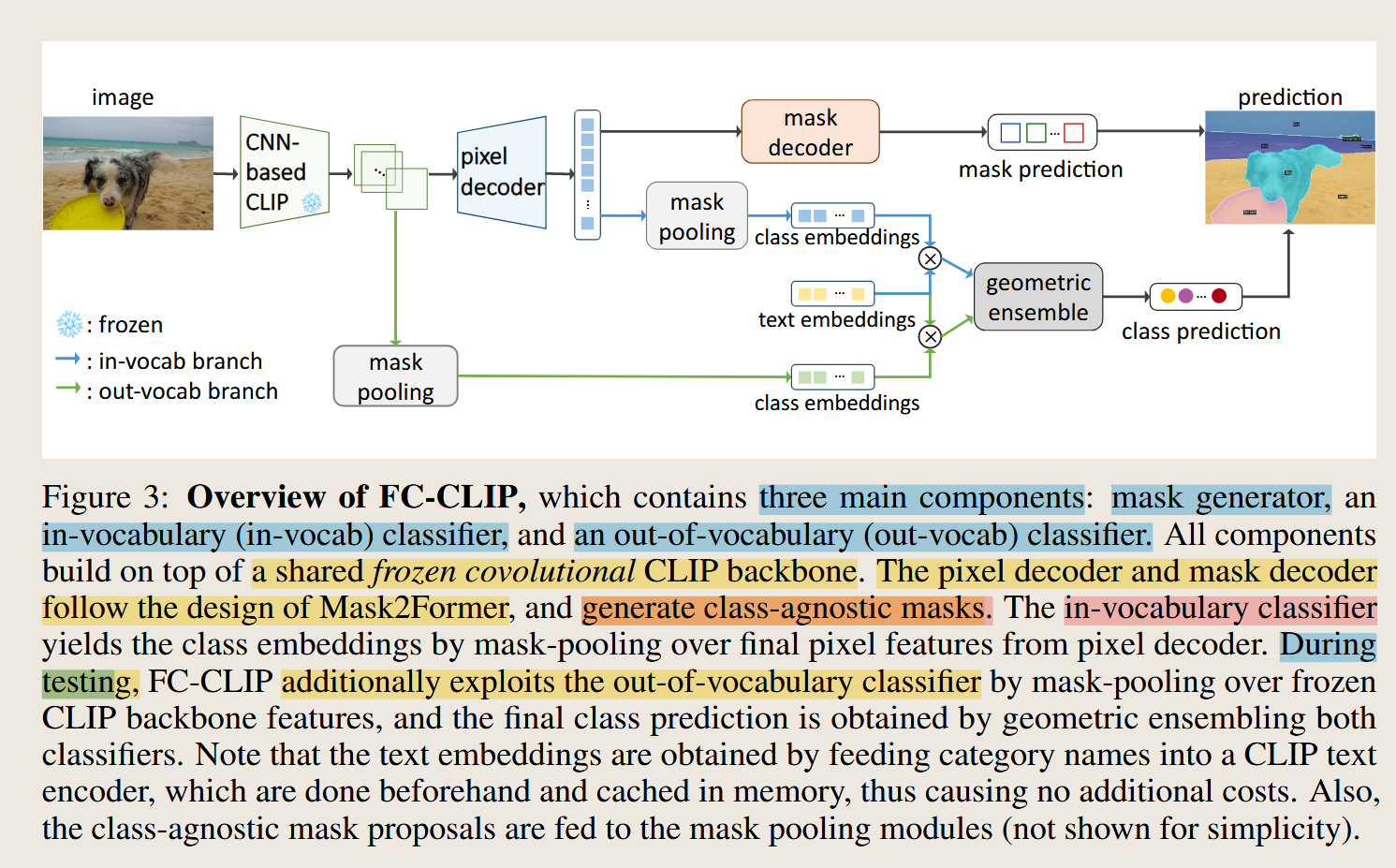
两阶段的方法:首先生成多个类无关的mask区域,然后将每个掩码区域送入 CLIP 进行分类。
- 两阶段方法 :先派一个助手A去把广场上每一个"人形"的轮廓都圈出来(第一阶段:找区域 ),然后你再拿着这些轮廓照片,去和你的通讯录照片一张张对比,看看这到底是谁(第二阶段:认人)。
"Although this framework has achieved impressive open-vocabulary segmentation performance, it has two limitations."(Yu 等, p. 5) 尽管该框架取得了令人印象深刻的开放词汇分割性能,但它有两个局限性。
**类无关的mask生成器:**生成masks
In-vocab 分类头:给masks分类
类无关的mask生成器 :用 Mask2Former 风格的 pixel decoder + mask decoder,从共享特征里直接产出一批"候选掩码"(不带类别)。这是"谁都能分"的关键(图3总览;训练时与GT做Hungarian匹配)。
pixel decoder 和 mask decoder 是现代 Transformer-based 分割模型(如 Mask2Former)中的关键组件。
pixel decoder的作用相当于是对多尺度特征图进行融合,输出高分辨率是像素嵌入特征图。虽然叫decoder,但实际在做特征增强和上采样。因为前面说过生成mask需要高分辨率。
所以从整个系统的视角看,pixel decoder 处于编码器之后、最终预测之前,承担了特征重建的任务,因此被命名为"decoder"。不是encoder那种为了生成低分辨率、高语义的特征图的结构。
mask decoder生成的是mask实例M,这个M集合中的每一个的实例表示了一个实例,一个图像中具体的物体或者区域是在哪里。(边界)图3中的那个例子就是5个实例。
"The resulting segmentation logits are obtained by performing a matrix multiplication between the object query and pixel features."(Yu 等, p. 6)通过在对象查询query和像素特征pixel features之间执行矩阵乘法获得结果分割逻辑。
通过这个decoder,我就知道我这个像素和图像的哪个区域相似度比较高,相似度较高的就是一个区域的。
内部处理也是有object query,和pixel decoder的特征图做cross-attention。这些注意力权重实际上就是初步的掩码!
输出:
- mask是概率的形式
- 通常输出分辨率是输入图像的 **1/4 或 1/8,**比如输入 1024x1024 → 输出 256x256 的掩码
In-vocab 分类头 :对每个候选掩码,在 pixel decoder 的最终像素特征上做mask-pooling 得到实例向量,与类别文本嵌入(用CLIP文本端预先编码并缓存)做余弦相似度,softmax 得到分类分数(式(6))。
文本特征通过CLIP 的text 特征器,图像通过pixel decoder生成的特征图。
mask pooling:会使用来自mask decoder阶段生成的mask,在特征图上取出对应的部分做加权平均生成实例的特征。
给定一张像素特征图 F ∈ ℝ^{C×H×W} (来自 pixel decoder )和某个查询 i 产生的软掩码 \\hat m_i ∈ \[0,1\]\^{H×W} (来自 mask decoder 的 logits 经 sigmoid/softmax 后),对该实例做"掩码加权的特征汇聚":
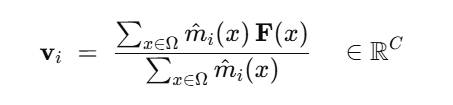
In-Vocab 分类头的核心作用
1. 利用训练数据的监督信号
- 虽然 CLIP 有强大的零样本能力,但在特定分割任务 上,模型仍然可以从训练数据(如 COCO)中学习到任务特定的特征表示
- In-vocab 分类头让模型能够微调特征空间,使其更适合分割任务,特别是对于训练集中见过的类别
2. 缓解领域偏移问题
- CLIP 是在网络图像-文本对上训练的,而分割数据集(如 COCO)有不同的数据分布
- In-vocab 分类头通过对 pixel decoder 特征进行监督学习,让特征更好地适应分割任务的视觉模式
Out-vocab 分类头(仅推理用) :在冻结的CLIP骨干特征上做同样的 mask-pooling,再与同一套文本嵌入比相似度。它保留了CLIP原生的开放词表识别能力。
"we notice that using the in-vocabulary classifier alone fails to generalize to completely novel unseen classes, as the model is only trained on a finite set of categories and thus could not recognize diverse novel concepts."(Yu 等, p. 7) 我们注意到,单独使用词汇内分类器无法泛化到完全新颖的未见过的类,因为该模型仅在有限的类别集上进行训练,因此无法识别不同的新颖概念。
由于训练的时候masks虽然生成了很多,但是会和GT进行匹配,相当于只在有限的类别上进行了训练。
最后采用几何集成的方法来对分类分数进行取舍,如果是训练集中的类别吗,可能in分支的权重大(default α = 0.4),未见过的分支就是另一个分支更大(β = 0.8),做实验可以得到。
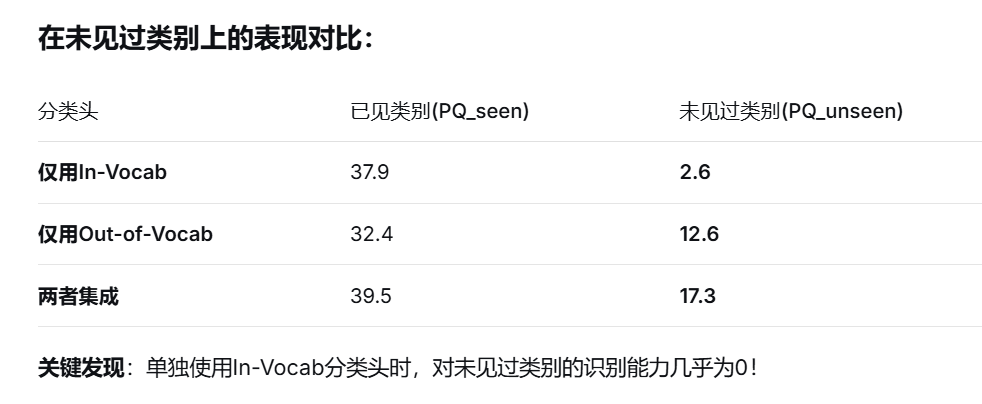
为什么会这样?哪部分的参数可能导致了这种情况?
视觉特征空间可能被压缩到这80个文本锚点张成的子空间中。
神经网络的特征表示能力是有限的。当模型专注于区分80个训练类别时:
- 它必须分配有限的表示资源
- 优先保证训练类别的可区分性
- 牺牲对无关变化的敏感性