本文已收录至GitHub,推荐阅读 👉 Java随想录
微信公众号:Java随想录
DSL(领域特定语言) 是一种为解决特定领域的问题而专门设计的计算机语言,它不同于通用编程语言(如 Python、Java)。它通常具有高度定制化的语法和结构,聚焦于某个特定任务或领域(如数据库查询、硬件配置、报表生成),通过提供更简洁、直观且贴近领域术语的表达方式,大幅提升该领域人员的工作效率和生产力,降低复杂性。
通俗来说,DSL 就像是为某个专业领域量身定做的"行话"工具。
说到构建自定义 DSL,高效且灵活的语法解析至关重要,ANTLR 正是解决这一核心挑战的利器。
简介
- 官方地址:www.antlr.org/
- GitHub:github.com/antlr/antlr...
- 在线调试:lab.antlr.org/
- IDEA插件:ANTLR V4
ANTLR 4(AN other T ool for L anguage Recognition,版本4)是一个开源的解析器生成器工具,用于构建语言识别程序。它能够根据用户定义的语法规则,自动生成词法分析器(Lexer)和语法分析器(Parser),从而实现对结构化文本(如编程语言、配置文件、数据格式等)的解析、转换或翻译。
ANTLR 4 最大的核心价值就是降低语言处理的门槛。在ANTRL 4没有出现之前,语言处理主要依赖正则表达式、手工编写解析器以及早期的解析器生成工具(如Lex/Yacc)。
ANTLR 4 的使用很简单,因为其存在的本身的意义就是为了加快语言类应用程序的编写速度,就是为了非专业人员对语言类应用程序快速开发而生的。
首先我们要进行ANTLR 4元语言的编写,也就是需要我们根据我们自己的需要来编写一份语法文件,一份后缀为 .g4 的文件,这份文件是我们构建ANTLR 4语言类应用程序的基础,目前ANTLR 4已经支持了数十种编程语言的生成,可以满足不同语言的开发需求。
官方也提供了相关的文件,GitHub:github.com/antlr/gramm...
有了这些 Java 文件,语言类应用程序的开发人员就不需要再去思考如何手动编写解析语法树的程序,因为ANTLR 4已经帮我们把这些事情都做了,ANTLR 4自带的jar 包和自动生成的这些语法分析器以及之后所提到的监听器 Listener 和访问器 Visitor 都能够完美的帮我们来处理任何语言类应用程序的自定义需求,从而真正达到即使你没学过编译原理也能自己开发应用程序的效果。
ANTLR 是用 Java 编写的,因此你需要首先安装 Java,哪怕你的目标是使用 ANTLR 来生成其他语言(如C#和C++)的解析器。
下图是我使用 IDEA 中的 ANTLR 4 插件,以及我自己编写的语法,自动生成的语法解析树,这一切都是ANTLR 4帮我们自动完成的。
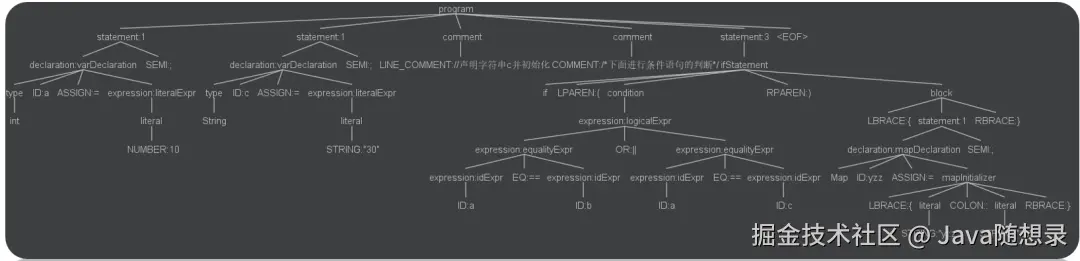
简而言之,ANTLR 工具将语法文件转换成可以识别该语法文件所描述的语言的程序。例如,给定一个识别 JSON 的语法,ANTLR工具将会根据该语法生成一个程序,此程序可以通过 ANTLR 运行库来识别输入的 JSON。
基础概念
文件声明
以下是一个包含完整头部声明的 ANTLR 4 语法文件示例,涵盖所有关键字的解释:
java
// =========== ANTLR4 语法文件头部声明示例 ===========
grammar MathParser; // [1] 主声明
// [2] 导入声明(组合语法)
import TrigParser, VectorParser; // 导入其他语法模块
// [3] 选项配置
options {
language = Java; // 目标生成语言
tokenVocab = CoreTokens; // 从外部语法导入词法符号
superClass = MathBase; // 自定义基类
contextSuperClass = MyCtx; // 自定义上下文基类
}
// [4] 辅助符号声明
tokens {
// 显式定义新token
PI = 'π'; // 带字面量的token
FUNCTION_CALL, // 无字面量的抽象token
VECTOR_DOT_PRODUCT // 用于语法树节点的标签
}
// [5] 头部注入 (生成文件顶部的代码)
@header {
package com.company.math;
import static com.company.math.TrigUtil.*;
}
// [6] 成员注入 (向解析器类添加代码)
@members {
private boolean debug = true;
private int errorCount = 0;
@Override
public void reportError(RecognitionException e) {
errorCount++;
super.reportError(e);
}
public int getErrorCount() {
return errorCount;
}
}
// [7] 规则定义区
expression: /* 规则内容 */;
// ========================================- grammar:定义语法名称(必须匹配文件名),声明完整/词法/解析语法类型。
- import:导入外部语法文件实现规则复用,支持模块化开发。语法导入允许你将语法分解成可复用的逻辑单元。ANTLR 处理被导入的语法的方式和面向对象语言中的父类非常相似。一个语法会从其导入的语法中继承所有的规则、词法符号声明和具名的动作。位于"主语法"中的规则将会覆盖其导入的语法中的规则,以此来实现继承机制。ANTLR将被导入的规则放置在主语法的词法规则列表末尾。这意味着,主语法中的词法规则具有比被导入语法中的规则更高的优先级。
- options:配置代码生成选项(目标语言/基类/符号表等)。
- tokens:声明辅助符号(抽象Token/别名/语法树标签)。tokens 区域存在的意义在于,它定义了一份语法所需,但却未在本语法中列出对应规则的词法符号。大多数情况下,tokens 区域用于定义本语法中动作所需的词法符号类型。
- @header:向生成文件顶部注入代码(包声明/导入语句)。用于将代码注入生成的识别类中的类声明之前。用于将代码注入为识别类的字段和方法。
- @members:向解析器类添加自定义成员(字段/方法/状态管理)。
关于 @header 和 @members,其中 @header 用于当 ANTLR 4 工具生成词法分析器和语法分析器时,将 @header 中的内容原封不动的复制到生成的 Java 文件的顶部,而 @members 用于将代码插入到生成的 Java 类当中,其中可以包含字段声明,自定义方法等内容。

从图中我们可以看到我们预先在语法文件中进行了 @header 和 @members 的定义和编写,然后利用 ANTLR 4 工具自动生成我们所需要的词法解析器和语法分析器等相关的 Java 文件,后续生成的这些 Java 文件中的相关位置包含了我们在 @header 和 @members 中所定义的相关内容。
不带前缀的语法声明是混合语法,可以同时包含词法规则和语法规则。欲创建一份只允许语法规则出现的文件,使用如下声明:
java
parser grammar Name;同理,纯词法的文件如下所示:
java
lexer grammar Name;词法规则
词法文件的规则以大写字母开头。
将字符聚集为单词或者符号(词法符号,token)的过程称为词法分析(lexicalanalysis)或者词法符号化(tokenizing)。我们把可以将输入文本转换为词法符号的程序称为词法分析器(lexer)。词法分析器可以将相关的词法符号归类,例如INT(整数)、ID(标识符)、FLOAT(浮点数)等。当语法分析器不关心单个符号,而仅关心符号的类型时,词法分析器就需要将词汇符号归类。词法符号包含至少两部分信息:词法符号的类型(从而能够通过类型来识别词法结构)和该词法符号对应的文本。

Java 词法规则示例:

接下来介绍一下词法规则是如何编写的。

如上图所示词法规则以大写的字母开头,或者以冒号开头后跟大写字母,这样做是为了与之后所要介绍的语法规则做区分。例如上图中我们就给出了一些示例的规则,定义了INT,ID,STRING类型的词法单元,冒号后面是对这些词法单元的描述。
这种词法规则的类型被称之为标准词法符号类型,这一类词法规则必须用大写字母开头,经过ANTLR 4工具处理会生成可直接在解析器中引用的符号,其规则匹配的优先级由在语法文件中声明词法规则的顺序和词法规则的长度来决定。
其中有很多符号,比如"+"代表着 INTEGER 这一词法规则使用出现至少一次的自然数组成的,而 IDENTIFIER 这一规则中的"*"则代表着 IDENTIFIER 这一词法规则是由大小写字母或下划线加上至少出现0次的单词字符组成的。而 STRING 词法规则中单引号中间的内容则代表着中间的内容直接匹配,是固定的。

第二类词法规则被称之为片段规则,通过关键字 fragment 来定义。
片段规则具有以下特点:首先片段规则是不能独立匹配的,fragment 规则不能直接用于匹配输入文本。它们只能被其他非片段的词法规则所引用。
将一条规则声明为 fragment 可以告诉 ANTLR,该规则本身不是一个词法符号,它只会被其他的词法规则使用。这意味着我们不能在文法规则中引用 HEX_DIGIT。
通常使用片段规则是为了提高可读性和重用性,通过将常用的字符模式提取为片段规则,可以使词法规则更加简洁和易于维护。例如,可以将字母或数字的模式定义为片段规则,然后在多个词法规则中引用它们。
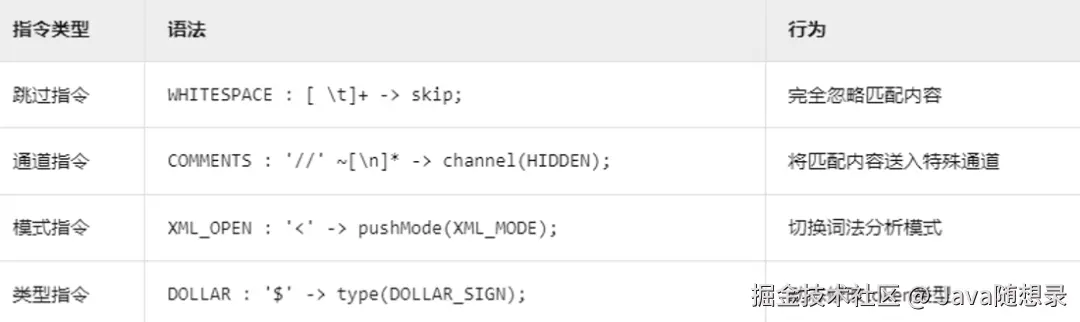
第三类词法规则被称之为指令规则。
- 第一种被称之为跳过指令,ANTLR 4在词法分析过程中会忽略这些匹配的空白字符,不会将它们作为(token)传递给语法分析器;
- 第二种被称之为通道指令,使用 -> channel(HIDDEN) 指令,ANTLR 将这些注释标记发送到一个隐藏通道,使得它们不会被默认的语法分析器处理,但仍然可以在需要时访问;
- 第三种被称之为模式指令,使用 -> pushMode(XML_MODE) 指令,ANTLR 会切换到 XML_MODE 模式,这允许在不同的上下文中使用不同的词法规则集;
- 最后一种被称之为类型指令,使用 -> type(DOLLAR_SIGN) 指令,ANTLR 会将匹配的标记类型动态设置为 DOLLAR_SIGN,这可以用于在语法分析中对不同类型的标记进行区分和处理。
语法规则
语法文件的规则以小写字母开头。
首先我们来介绍语法规则的规则组成元素。

以上名为 assignment 的语法规则中所包含的大写字母序列 IDENTIFIER 被称之终结符,它来自词法分析器,我们在词法规则中会对其进行定义。

与此相对的是非终结符,比如以上 expression 语法规则中的 term,这些非终结符,由小写字母命名,并且由其他规则所定义。

除了之前介绍的终结符和非终结符两种元素之外,还有带参数的规则和带返回值的规则。因此,参数和返回值也是语法规则的重要元素。
String className,表示这个规则接受一个参数 className,类型为 String。在解析过程中,可以将外部传入的类名用于匹配。Object value,表示这个规则在匹配成功后会返回一个 Object 类型的值,存储在 value 中。
ANTLR 4的语法规则的核心语法构造分为四种模式,分别是序列模式、选择模式、分组模式、循环模式。
序列模式
java
sqlSelect : SELECT column FROM table WHERE condition;元素必须严格按顺序出现(如 SQL 语句结构)。
选择模式
java
dataType : INT | STRING | BOOL;多选一匹配(如数据类型只能为三者之一)。
分组模式
java
functionCall : ID '(' (arg (',' arg)*)? ')';括号强制组合子规则(如函数参数列表的逗号分隔结构)。
循环模式
java
emailList : address (',' address)+;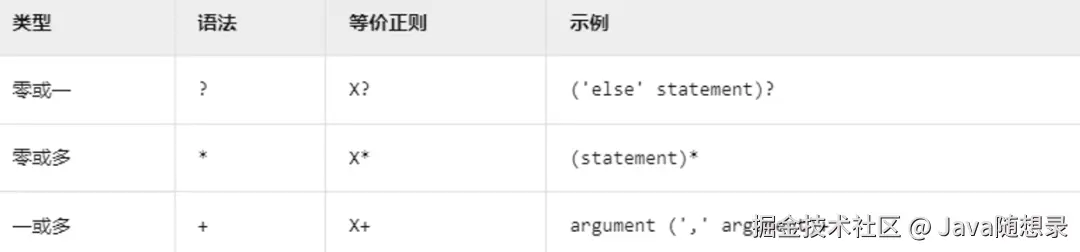
后缀运算符控制重复次数(如至少一个邮箱地址的逗号分隔列表)。
规则标签
在 ANTLR 4 中,规则标签(Rule Labels)是提升语法可读性、精确控制解析树生成的关键机制,我们可以使用 # 给最外层的备选分支添加标签,以获得更加精确的语法分析器监听器事件。一条规则中的备选分支要么全部带上标签,要么全部不带标签。标签主要有两种应用形式:
分支备选标签(Alternative Labels)
在规则的选择分支(|)中标注备选项:
java
expression
: left=expr '+' right=expr # AddExpr // # 定义标签
| left=expr '*' right=expr # MulExpr
| NUMBER # NumLiteral
;作用:
为每个分支生成独立的上下文类(如
AddExprContext),在监听器/访问器中提供类型精确的访问方法
生成代码优势:
java
// 自动生成精确的进入/退出方法
@Override
public void enterAddExpr(MyParser.AddExprContext ctx) {
// 直接访问带标签的元素
ExprContext left = ctx.left; // 无需遍历子节点
ExprContext right = ctx.right;
}元素标签(Element Labels)
在规则中标记特定子元素:
ini
funcCall : func=ID '(' args+=expr (',' args+=expr)* ')';三种标记方式:
| 标签语法 | 适用对象 | 返回值类型 | 访问示例 |
|---|---|---|---|
label=TOKEN |
词法符号 | TerminalNode |
ctx.ID().getText() |
label=rule |
规则引用 | RuleContext子类 |
ctx.expr().value |
labelList+=... |
重复元素 | List<?> |
for (exprContext e : ctx.args) |
实战应用场景
- 场景1:四则运算精确解析
java
expr
: left=expr op=('*'|'/') right=expr # MulDiv
| left=expr op=('+'|'-') right=expr # AddSub
| NUM # Number
| '(' expr ')' # Parens
;生成的监听器接口:
java
void enterMulDiv(ExprParser.MulDivContext ctx);
void enterAddSub(ExprParser.AddSubContext ctx);
void exitMulDiv(ExprParser.MulDivContext ctx);
// ...- 场景2:函数调用语义分析
java
functionCall
: func=ID '('
(firstArg=expr (',' otherArgs+=expr)*)?
')' # FuncCall
;在访问器中直接获取元素:
java
public Object visitFuncCall(FuncCallContext ctx) {
String funcName = ctx.func.getText();
List<ExprContext> args = new ArrayList<>();
if(ctx.firstArg != null) {
args.add(ctx.firstArg);
args.addAll(ctx.otherArgs);
}
// ...处理函数调用
}TokenStream
词法分析器处理字符序列并将生成的词法符号提供给语法分析器,语法分析器随即根据这些信息来检查语法的正确性并建造出一棵语法分析树。这个过程对应的ANTLR 类是 CharStream、Lexer、Token、Parser,以及 ParseTree。连接词法分析器和语法分析器的"管道"就是 TokenStream。下图展示了这些类型的对象在内存中的交互方式。
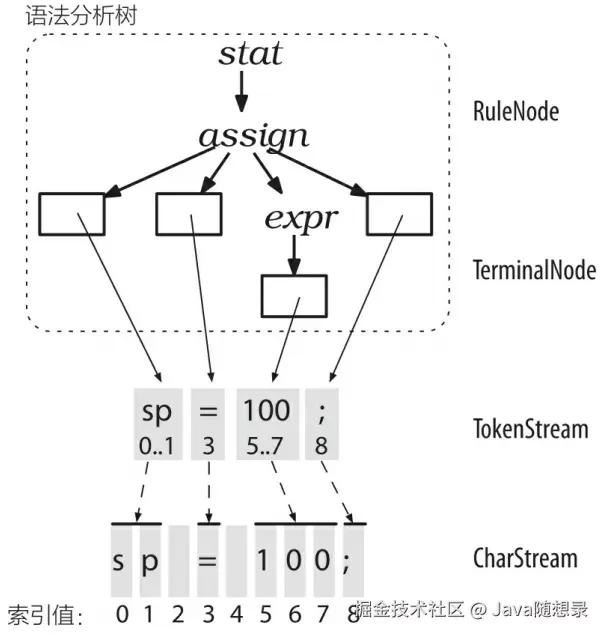
ParseTree 的子类 RuleNode 和 TerminalNode ,二者分别是子树的根节点和叶子节点。RuleNode 有一些令人熟悉的方法,例如 getChild() 和 getParent() ,但是,对于一个特定的语法,RuleNode 并不是确定不变的。为了更好地支持对特定节点的元素的访问,ANTLR 会为每条规则生成一个 RuleNode 的子类。如下图所示,在我们的赋值语句的例子中,子树根节点的类型实际上是:StatContext、AssignContext 以及 ExprContext。
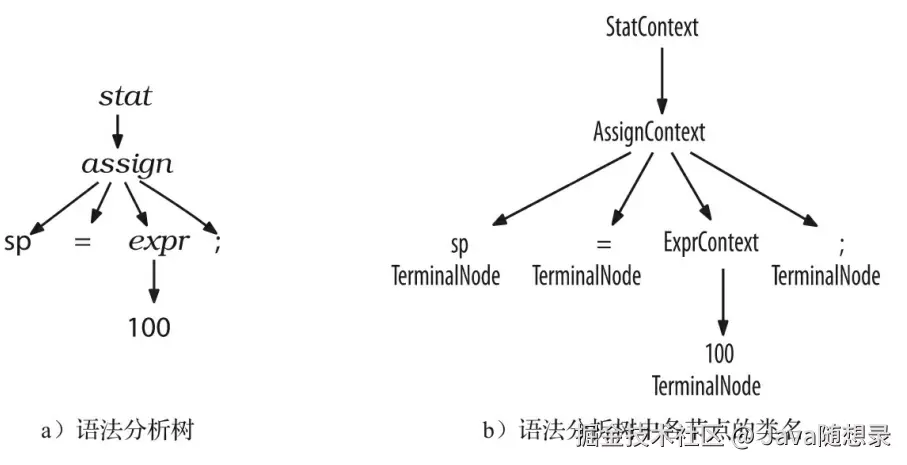
因为这些根节点包含了使用规则识别词组过程中的全部信息,它们被称为上下文(context)对象。每个上下文对象都知道自己识别出的词组中,开始和结束位置处的词法符号,同时提供访问该词组全部元素的途径。例如,AssignContext 类提供了方法 ID() 和方法 expr() 来访问标识符节点和代表表达式的子树。
监听器和访问器
ANTLR 的运行库提供了两种遍历树的机制。默认情况下,ANTLR 使用内建的遍历器访问生成的语法分析树,并为每个遍历时可能触发的事件生成一个语法分析树监听器接口(parse-tree listener interface)。监听器非常类似于 XML 解析器生成的 SAX 文档对象。SAX 监听器接收类似 startDocument() 和 endDocument() 的事件通知。一个监听器的方法实际上就是回调函数,正如我们在图形界面程序中响应复选框点击事件一样。除了监听器的方式,我们还将介绍另外一种遍历语法分析树的方式:访问者模式(vistor pattern)。
监听器
为了将遍历树时触发的事件转化为监听器的调用,ANTLR 运行库提供了 ParseTreeWalker 类。我们可以自行实现 ParseTreeListener 接口,在其中填充自己的逻辑代码(通常是调用程序的其他部分),从而构建出我们自己的语言类应用程序。ANTLR 为每个语法文件生成一个 ParseTreeListener 的子类,在该类中,语法中的每条规则都有对应的 enter 方法和 exit 方法。例如,当遍历器访问到 assign 规则对应的节点时,它就会调用 enterAssign() 方法,然后将对应的语法分析树节点------AssignContext 的实例------当作参数传递给它。在遍历器访问了 assign 节点的全部子节点之后,它会调用 exitAssign() 。下图用粗虚线标识了 ParseTreeWalker对语法分析树进行深度优先遍历的过程。
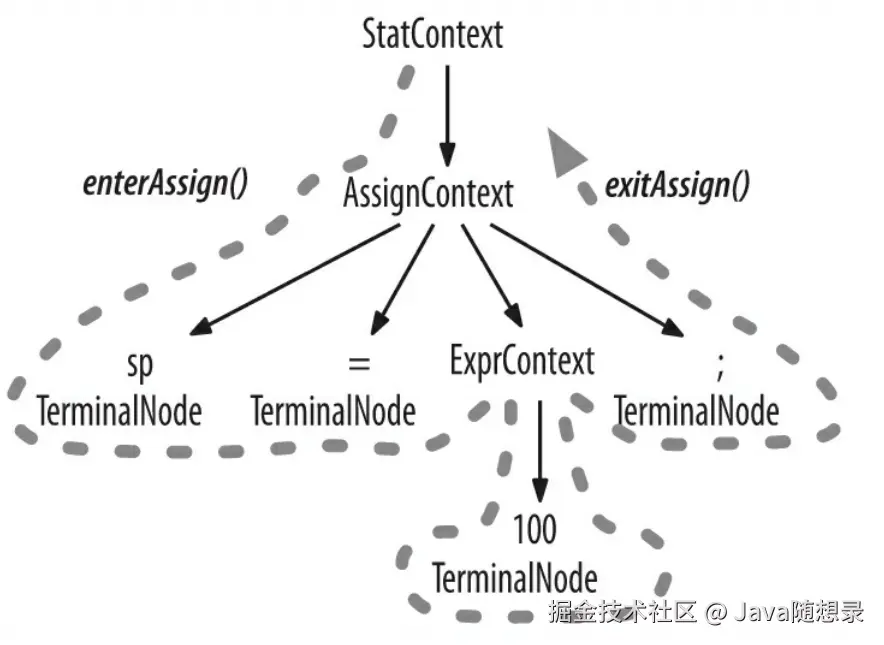
下图显示了在我们的赋值语句生成的语法分析树中,ParseTreeWalker 对监听器方法的完整的调用顺序。
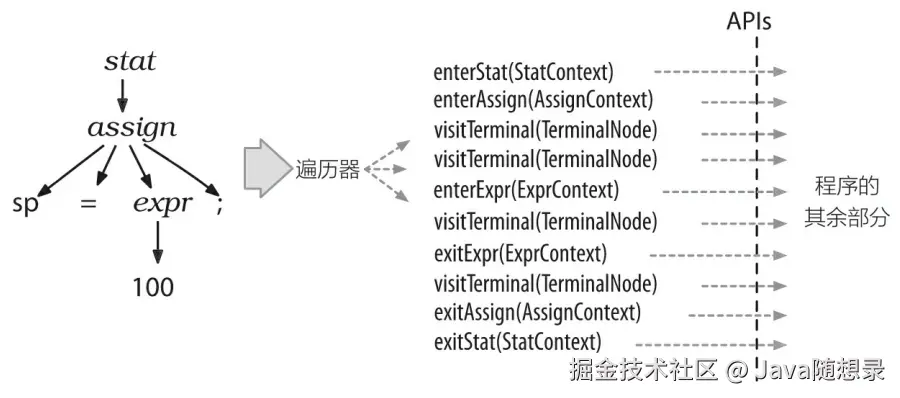
监听器机制的优秀之处在于,这一切都是自动进行的。我们不需要编写对语法分析树的遍历代码,也不需要让我们的监听器显式地访问子节点。
访问器
有时候,我们希望控制遍历语法分析树的过程,通过显式的方法调用来访问子节点。下图是是使用常见的访问者模式对我们的语法分析树进行操作的过程。
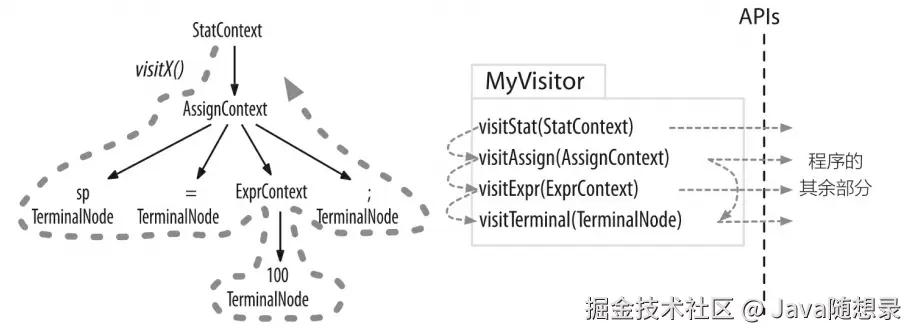
其中,粗虚线显示了对语法分析树进行深度优先遍历的过程。细虚线标示出访问器方法的调用顺序。我们可以在自己的程序代码中实现这个访问器接口,然后调用visit() 方法来开始对语法分析树的一次遍历。
java
ParseTree tree=...; // tree是语法分析得到的结果
MyVisitor v = new MyVisitor();
v.visit(tree);ANTLR 内部为访问者模式提供的支持代码会在根节点处调用 visitStat() 方法。接下来,visitStat() 方法的实现将会调用 visit() 方法,并将所有子节点当作参数传递给它,从而继续遍历的过程。或者,visitMethod() 方法可以显式调用 visitAssign() 方法等。ANTLR会提供访问器接口和一个默认实现类,免去我们一切都要自行实现的麻烦。这样,我们就可以专注于那些我们感兴趣的方法,而无须覆盖接口中的方法。
同时访问者机制支持泛型返回值,可以实现数据聚合。
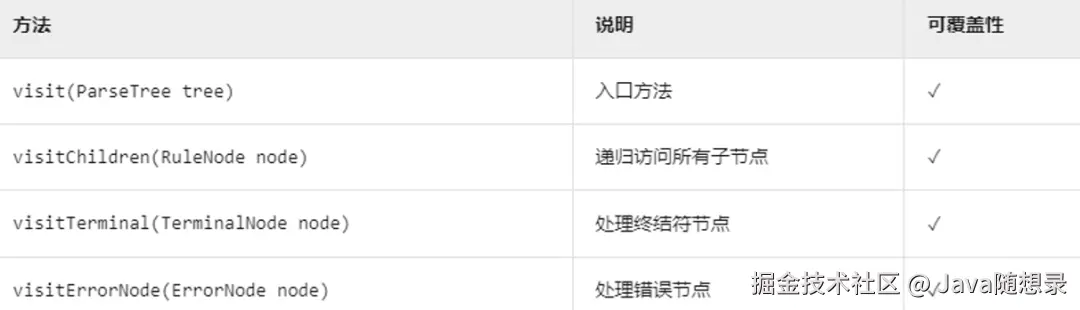
访问器机制和监听器机制的最大的区别在于,监听器的方法会被 ANTLR 提供的遍历器对象自动调用,而在访问器的方法中,必须显式调用 visit 方法来访问子节点。忘记调用visit() 的后果就是对应的子树将不会被访问。
语义判定
语义判定(Semantic Predicates)允许在语法规则中嵌入布尔表达式,从而在运行时动态控制解析过程。这使得 ANTLR4 能够处理上下文相关的语法结构。
基本语法:
dart
ruleName
: {布尔表达式}? 规则元素 // 验证型判定
| {布尔表达式}?=> 规则元素 // 门控型判定
;判定类型
验证型判定
- 语法:
{布尔表达式}? - 行为:
- 尝试匹配规则元素
- 如果匹配成功,评估布尔表达式
- 如果表达式为
false,放弃当前分支并尝试其他备选分支
bash
expr
: {isType("int")}? ID // 只有当 isType("int") 为 true 时才匹配
| INT
;门控型判定
- 语法:
{布尔表达式}?=> - 行为:
- 在尝试匹配规则元素前评估布尔表达式
- 如果表达式为
false,立即放弃整个分支 - 不会尝试匹配规则元素
dart
statement
: {inLoop()}?=> 'break' ';' // 只有在循环中才允许 break
| 'continue' ';'
;实现机制
在语法文件中声明:
java
grammar ContextSensitive;
@parser::members {
private SymbolTable symbolTable = new SymbolTable();
private boolean isType(String id) {
return symbolTable.isType(id);
}
}
expr
: {isType($ID.text)}? ID // 使用语义判定
| INT
;ANTLR 会将语义判定转换为解析器代码:
java
public class ContextSensitiveParser extends Parser {
// ...
public final ExprContext expr() {
// 尝试第一个备选分支
if (isType(input.LT(1).getText())) {
// 创建上下文对象
// 匹配 ID
}
// 否则尝试第二个分支
else {
// 匹配 INT
}
}
}Channel
在 ANTLR 4 中,通道(channels)是一种强大的机制,用于将词法标记(tokens)分类处理。ANTLR 4 有两个预定义通道:
- 默认通道 (Token.DEFAULT_CHANNEL),通道号: 0,包含所有需要被解析器处理的标记。
- 隐藏通道 (Token.HIDDEN_CHANNEL),通道号: 1,包含所有不需要被解析器直接处理的标记。
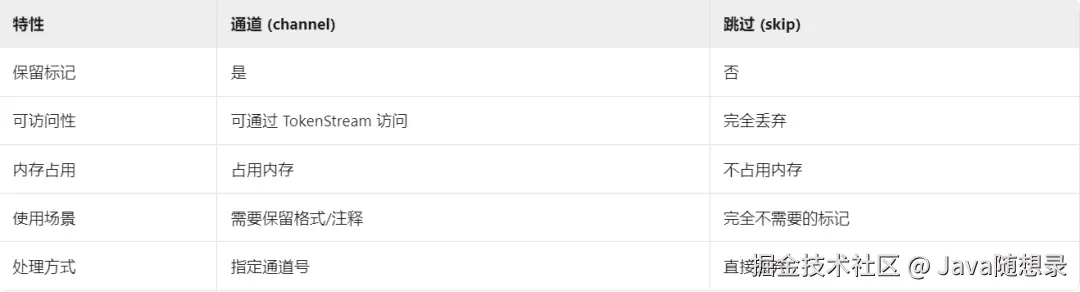
通道与 skip 的区别
自定义通道
scss
// ===== 1. 声明通道 =====
channels {
ERROR_CHANNEL, // 自定义错误信息通道
HIDDEN_COMMENTS // 隐藏注释通道
}
// ===== 2. 将词法规则定向到通道 =====
ERROR_TOKEN : '<!' .*? '!>' -> channel(ERROR_CHANNEL); // 捕获错误标记
LINE_COMMENT : '//' ~[\r\n]* -> channel(HIDDEN_COMMENTS); // 隐藏注释
BLOCK_COMMENT : '/*' .*? '*/' -> channel(HIDDEN_COMMENTS);
// ===== 3. 保留传统空白符处理 =====
WS : [ \t\r\n]+ -> skip; // 完全跳过空白符ANTLR 4 通过 channels{} 声明自定义通道,并用 -> channel(NAME) 将词法规则输出定向到指定通道,保留但隔离特殊内容。
嵌入动作
ANTLR 的嵌入动作(Embedded Actions)是在语法规则中直接插入目标语言代码的机制,它允许开发者在解析过程的关键节点执行自定义逻辑。
语法规则 { 代码块 }ANTLR 在解析时会在对应位置实时执行这些代码
执行时机
- 元素匹配前 :
{代码} 规则元素 - 元素匹配后 :
规则元素 {代码} - 规则匹配完成 :
规则元素 @after {代码}
动作类型与代码示例
- 简单打印动作(调试追踪)
ini
expression
: left=expression '+' { System.out.println("检测到加号"); }
right=expression
{ System.out.println("完成加法: "+$left.value+"+"+$right.value); }
;输出示例:
makefile
检测到加号
完成加法: 5+3- 条件拦截动作(语义检查)
php
vectorOperation
: ID '=' (vec1=vector '×' vec2=vector
{
if($vec1.dimension != $vec2.dimension)
throw new RuntimeException("维度不匹配");
})
{ System.out.println("叉积运算完成"); }
;- 动态计算动作(属性传递)
ini
number returns [int value]
: digits=INT { $value = Integer.parseInt($digits.text); }
| hex='0x' hexDigits=HEX
{ $value = Integer.parseInt($hexDigits.text,16); }
;- 集合构造动作(数据聚合)
perl
jsonArray returns [List<Object> list = new ArrayList<>()]
: '['
(first=jsonValue { $list.add(first); }
(',' next=jsonValue { $list.add(next); })*
)? ']'
;- 符号表管理动作(语义分析)
ini
variableDecl
: type ID
{
Symbol sym = new Symbol($ID.text, $type.text);
currentScope.addSymbol(sym);
}
'=' expr ';'
;- 自动代码生成(DSL编译)
css
sqlSelect
: 'SELECT' columns+=column (',' columns+=column)*
{ out.write("SELECT " + $columns.get(0).text);
for(int i=1; i<$columns.size(); i++) {
out.write("," + $columns.get(i).text);
}
}
'FROM' table=ID
{ out.write(" FROM " + $table.text); }
;注意:动作会使语法与目标语言耦合,优先使用监听器/访问器模式,避免过度使用。
处理优先级、左递归和结合性
在自顶向下的语法和手工编写的递归下降语法分析器中,处理表达式都是一件相当棘手的事情,这首先是因为大多数语法都存在歧义,其次是因为大多数语言的规范使用了一种特殊的递归方式,称为左递归(left recursion)。
自顶向下的语法和语法分析器的经典形式无法处理左递归。为了阐明这个问题,假设有一种简单的算术表达式语言,它包含乘法和加法运算符,以及整数因子。表达式是自相似的,所以,很自然地,我们说,一个乘法表达式是由*连接的两个子表达式,一个加法表达式是由+连接的两个子表达式。另外单个整数也可以作为简单的表达式。这样写出的就是下列看上去非常合理的规则:

问题在于,对于某些输入文本而言,上面的规则存在歧义。换句话说,这条规则可以用不止一种方式匹配某种输入的字符流,这个语法在简单的整数表达式和单运算符表达式上工作得很好------例如1+2和1*2------是因为只存在一种方式去匹配它们。对于1+2,上述语法只能用第二个备选分支去匹配,如下图左侧的语法分析树所示。
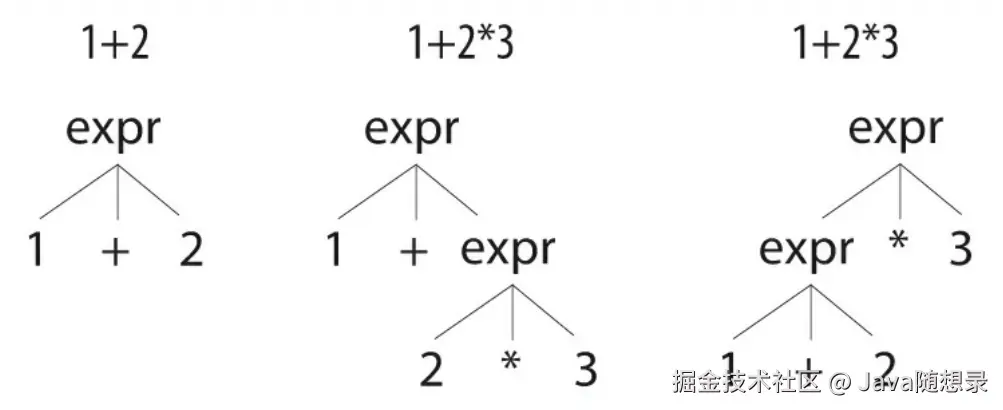
但是对于 1+2*3 这样的输入而言,上述规则能够用两种方式解释它,如上图中间和右侧的语法分析树所示。它们的差异在于,中间的语法分析树表示将1加到2和3相乘的结果上去,而右侧的语法分析树表示将1和2相加的结果与3相乘。这就是运算符优先级带来的问题,传统的语法无法指定优先级。大多数语法工具,例如Bison,使用额外的标记来指定运算符优先级。
与之不同的是,ANTLR 通过优先选择位置靠前的备选分支来解决歧义问题,这隐式地允许我们指定运算符优先级。例如,expr 规则中,乘法规则在加法规则之前,所以ANTLR在解决歧义问题时会优先处理乘法。默认情况下,ANTLR按照我们通常对*和+的理解,将运算符从左向右地进行结合。尽管如此,一些运算符------例指数运算符------是从右向左结合的,所以我们需要在这样的运算符上使用 assoc 选项手工指定结合性。这样,输入的 2^3^4 就能够被正确解释为2^(3^4):

注:在ANTLR 4.2之后,<assoc=right> 需要被放到备选分支的最左侧,否则会收到警告。在本例中,正确写法是:

如下图所示的语法分析树展示了^符号的左结合版本和右结合版本在处理相同输入时的差异。通常人们采用右侧语法分析树所代表的解释方式,不过,语言设计者可以自由地决定使用哪一种结合性。
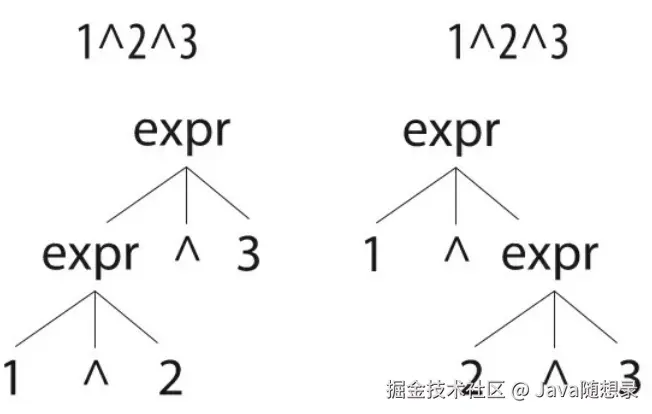
若要将上述三种运算符组合成为同一条规则,我们就必须把^放在最前面,因为它的优先级比*和+都要高(1+2^3的结果是9)。

ANTLR 4的一项重大改进就是,它已经可以处理直接左递归了。左递归规则是这样的一种规则:在某个备选分支的最左侧以直接或者间接方式调用了自身。上面的例子中的expr规则是直接左递归的,因为除INT之外的所有备选分支都以expr规则本身开头(它同时也是右递归(rightrecursive)的,因为它的某些备选分支在最右侧引用了expr)。虽然ANTLR 4已经能够处理直接左递归,但是它还无法处理间接左递归。这意味着我们无法将expr规则分解为下列规则,尽管它们在语义上等价:

非贪婪匹配
在 ANTLR 中,非贪婪匹配(Non-Greedy Matching) 是处理文本模式的特殊策略,它会尽可能少地匹配字符(即采用"最小匹配"原则)。这与默认的贪婪匹配(尽可能多匹配)形成对比,是解决词法歧义的关键技术。
贪婪匹配(默认行为)
perl
STRING : '"' .* '"'; // 匹配从第一个"到最后一个"非贪婪匹配
arduino
STRING_LAZY : '"' .*? '"'; // ? 启用非贪婪通配符模式说明:
| 模式 | 符号 | 匹配策略 |
|---|---|---|
| 贪婪 | .* |
最长可能匹配 |
| 非贪婪 | .*? |
最短可能匹配 |
实战应用场景
- 场景1:注释匹配
arduino
// 错误:贪婪匹配会吃光所有内容
DOC_COMMENT : '/*' .* '*/';
// 正确:非贪婪只匹配最近的一对
DOC_COMMENT_LAZY : '/*' .*? '*/';- 场景2:模板字符串
css
TEMPLATE : '`' ('\\`' | .)*? '`';正确处理带转义符的模板:
- 场景3:XML标签内联
css
TAG_CONTENT : '<' .*? '>';辅助类
ParseTreeProperty
ParseTreeProperty 是 ANTLR 4 中一个强大的辅助类,用于将自定义数据与解析树(Parse Tree)中的节点关联起来。它是实现属性文法(Attribute Grammar)的核心工具,特别适用于需要在语法分析过程中计算和传递属性的场景。
ParseTreeProperty 主要用于解决以下问题:
- 存储节点相关数据:为每个解析树节点关联自定义属性
- 实现属性传递:在树遍历过程中收集和传递上下文信息
- 实现代码生成:保存每个节点的代码生成结果
- 类型检查:记录表达式的类型信息
- 符号表关联:将作用域和符号表与语法结构关联
java
/ 1. 创建数据容器
ParseTreeProperty<DataType> dataMap = new ParseTreeProperty<>();
// 2. 向节点注入数据(通常在监听器/访问器中)
@Override
public void exitAddExpr(CalcParser.AddExprContext ctx) {
int left = dataMap.get(ctx.left); // 取左子树数据
int right = dataMap.get(ctx.right);
int result = left + right;
dataMap.put(ctx, result); // 当前节点存储计算结果
}
// 3. 从根节点获取最终结果
public int getResult(ParseTree tree) {
return dataMap.get(tree); // 返回根节点存储的计算结果
}TokenStreamRewriter
TokenStreamRewriter 是 ANTLR4 中一个强大的工具类,用于在不修改原始令牌流的情况下,对令牌流进行非破坏性编辑。它特别适用于源代码转换、重构和代码生成等场景。
其中的关键之处在于,TokenStreamRewriter 对象实际上修改的是词法符号流的"视图"而非词法符号流本身。它认为所有对修改方法的调用都只是一个"指令",然后将这些修改放入一个队列;在未来词法符号流被重新渲染为文本时,这些修改才会被执行。在每次我们调用 getText() 的时候,rewriter 对象都会执行上述队列中的指令。
简单使用示例:在方法调用前插入日志
java
public class RewriterExample {
public static void main(String[] args) {
// 1. 创建输入流
String input = "public class Test {\n" +
" public void method() {\n" +
" System.out.println(\"Hello\");\n" +
" }\n" +
"}";
CharStream charStream = CharStreams.fromString(input);
// 2. 创建词法分析器和令牌流
JavaLexer lexer = new JavaLexer(charStream);
CommonTokenStream tokens = new CommonTokenStream(lexer);
// 3. 创建重写器
TokenStreamRewriter rewriter = new TokenStreamRewriter(tokens);
// 4. 创建解析器
JavaParser parser = new JavaParser(tokens);
ParseTree tree = parser.compilationUnit();
// 5. 遍历解析树并修改
ParseTreeWalker walker = new ParseTreeWalker();
walker.walk(new InsertLogListener(rewriter), tree);
// 6. 获取修改后的文本
System.out.println(rewriter.getText());
}
static class InsertLogListener extends JavaBaseListener {
private final TokenStreamRewriter rewriter;
public InsertLogListener(TokenStreamRewriter rewriter) {
this.rewriter = rewriter;
}
@Override
public void enterMethodCall(JavaParser.MethodCallContext ctx) {
// 获取方法名令牌
Token methodNameToken = ctx.Identifier().getSymbol();
// 在方法调用前插入日志语句
String logStmt = "\n System.out.println(\"Calling method: " +
methodNameToken.getText() + "\");";
rewriter.insertBefore(methodNameToken.getTokenIndex(), logStmt);
}
}
}输出结果:
java
public class Test {
public void method() {
System.out.println("Calling method: println");
System.out.println("Hello");
}
}错误报告与恢复
ANTLR 的错误报告与恢复机制是其生成健壮解析器的核心,它通过智能的错误检测、精确报告及自动恢复策略,确保即使面对非法输入也能进行结构化处理而非直接崩溃。
对于词法错误和语法错误,ANTLR 4 会定位错误的起始位置,向后删除字符直到发现合法的 token 边界,然后就会接着解析后续输入。
arduino
// 自动生成详细的错误诊断
line 5:8 missing '}' at '{'
line 10:22 mismatched input ';' expecting ','-
信息结构:
makefile位置: 行号:列号 类型: [missing|mismatched|extraneous] 详情: 期望内容/实际内容
自定义错误处理器
重写 BaseErrorListener:
java
public class VerboseListener extends BaseErrorListener {
@Override
public void syntaxError(Recognizer<?,?> recognizer,
Object offendingSymbol,
int line, int charPos,
String msg, RecognitionException e) {
// 生成更友好的错误提示
String error = String.format("[CUSTOM] Line %d:%d - %s", line, charPos, msg);
System.err.println(error);
}
}
// 注册自定义监听器
parser.removeErrorListeners();
parser.addErrorListener(new VerboseListener());性能优化
提高语法分析器的速度
ANTLR 4 的自适应语法分析策略功能比 ANTLR 3 更加强大,不过这是以少量的性能损失为代价的。如果你需要尽可能快的速度和尽可能少的内存占用,你可以使用两步语法分析策略。第一步使用功能稍弱的语法分析策略------SLL------在大多数情况下它已经足够了(它和ANTLR 3的策略相似,只是不需要回溯)。如果第一步的语法分析失败,那么就必须使用全功能的 LL 语法分析。这是因为,在第一步失败后,我们无法知道原因究竟是真正的语法错误,还是 SLL 的功能不够强大
由于能够通过 SLL 的输入一定能够通过全功能的 LL,所以一旦第一步成功,就无须使用更昂贵的策略。
java
try {
parser.compilationUnit();
//如果抵达此处,证明没有语法错误,SLL(*)就够了
//无需使用全功能的LL(*)
} catch (RuntimeException ex) {
if (ex.getClass() == RuntimeException.class &&
ex.getCause() instanceof RecognitionException) {
//BailErrorStrategy会将RecognitionExceptions封装在
// RuntimeException中,所以这里需要检查是不是
//一个真正的RecognitionException
tokenStream.reset();//回滚输入流
//重新使用标准的错误监听器和错误处理器
parser.addErrorListener(ConsoleErrorListener.INSTANCE);
parser.setErrorHandler(new DefaultErrorStrategy());
parser.getInterpreter().setPredictionMode(PredictionMode.SLL);
parser.compilationUnit();
parser.addErrorListener(new SyntaxErrorListener());
ParseTree tree = parser.compilationUnit();
// 使用访问器转换DSL
Map<String, Object> externalVarMaps = new HashMap<>();
externalVarMaps.put("features", Sets.newHashSet("test_tz_string_auto_test", "test_feature_999", "sys_attr5"));
ParentVisitor visitor = new ParentVisitor(123L, tokenStream, parser, externalVarMaps);
String dsl = visitor.visit(tree);
log.info("Generated DSL:\n{}", dsl);
}
}如果第二步失败,那就意味着一个真正的语法错误。
无缓冲的字符流和词法符号流
因为 ANTLR 的识别器在默认情况下会将输入的完整字符流和全部词法符号放入缓冲区,所以它无法处理大小超过内存的文件,也无法处理类似套接字(socket)连接之类的无限输入流。为解决此问题,你可以使用字符流和词法符号流的无缓冲版本:UnbufferedCharStream 和 UnbufferedTokenStream,它们使用一个滑动窗口来处理流。
为展示二者的实际应用,下图是一个 CSV语法,它计算一个文件中两列浮点数的和:
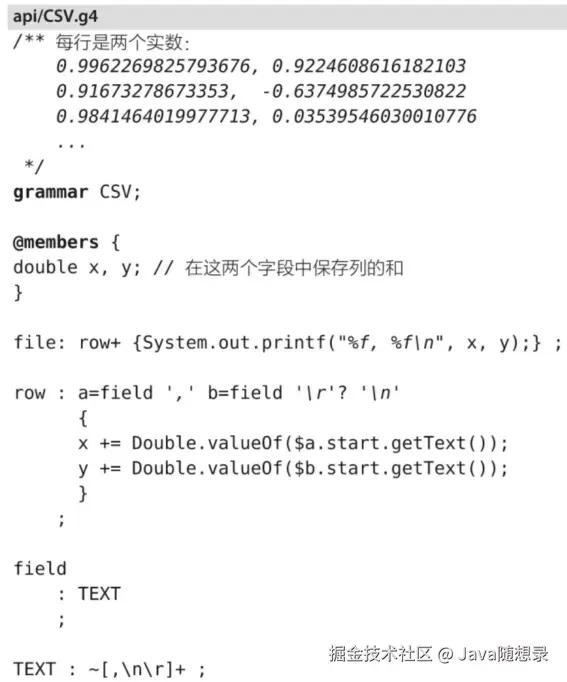
如果你需要的只是每一列的和,你就应该在内存中只保留一个或两个词法符号用于记录结果。欲关闭 ANTLR 的缓冲功能,需要完成三件事情。首先,使用无缓冲的流代替常见的 ANTLFileStream 和 CommonTokenStream。其次,传给词法分析器一个词法符号工厂,将输入流中的字符拷贝到生成的词法符号中去。否则,词法符号的 getTex() 方法就会尝试访问可能已经不再可用的字符流。最后,阻止语法分析器建立语法分析树。如下图标记的关键代码:
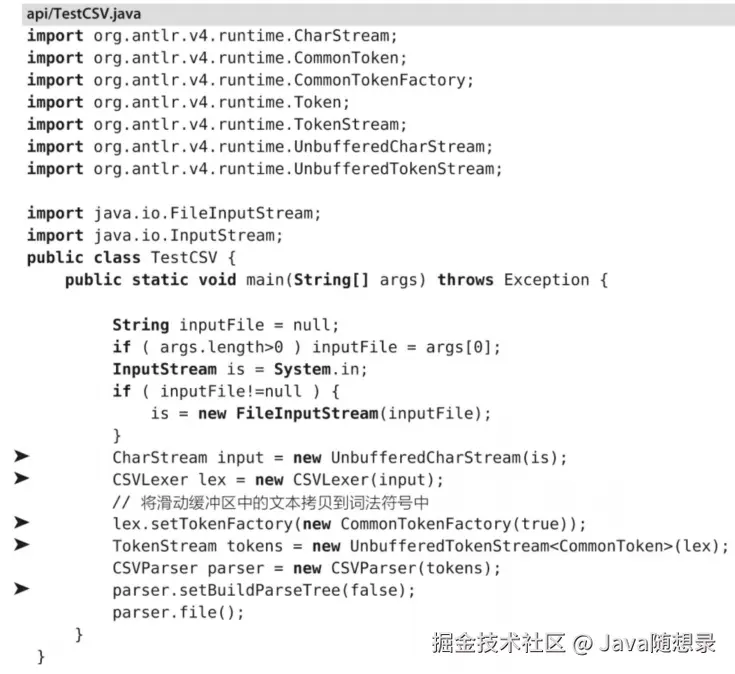
当效率是首要目标时,无缓冲流是非常有用的。使用它们的缺点是你需要手工处理与缓冲区相关的事情。例如,你不能在规则的内嵌动作中使用 $text,因为它们是从输入流中获取文本的。
结尾
这篇关于 ANTLR 的技术指南到此告一段落。作为领域特定语言(DSL)构建的利器,ANTLR 通过其强大的语法解析能力、灵活的监听器/访问器机制,以及高效的错误恢复策略,彻底革新了语言处理技术的开发范式。
无论是设计数据库查询语言、配置文件解析器,还是实现复杂的领域专用逻辑,ANTLR 都提供了从词法分析到语法树遍历的全套解决方案。其自动生成的解析器代码和直观的规则定义方式,让开发者能专注于业务逻辑而非底层细节,真正实现了"用语法驱动开发"的高效实践。通过掌握 ANTLR,你已拥有了一把打开自定义语言世界的钥匙。