To be, or not to be, that is the question. ------ 莎士比亚
前言
"高内聚,低耦合"是软件工程领域广为流传的一个原则,在此原则的驱使下,应用系统逐渐从单体架构演进成微服务架构,甚至进一步按函数粒度拆分成 FaaS(函数即服务),呈分离趋势。
然而,我们又能看到很多软件系统呈统一的演进趋势,比如数据系统从批处理和流处理分离的 Lambda 架构1演进到流批一体架构、从数据仓库和数据湖分离演进到湖仓一体;比如大模型,从文本大模型演进到多模态大模型。
再往下到硬件基础设施,随着 AI 时代的到来,CPU 已难以招架新的 AI 负载,各类加速芯片纷纷出现,如 GPU、TPU、DPU,整体呈从通用到专用的分离趋势;但包含 36 个 CPU 和 72 个 GPU 的 NVIDIA GB200 NVL722、包含 192 个 CPU 和 384 个 NPU 的 HUAWEI CloudMatrix3843 等超节点的出现,似乎又呈现统一趋势。
那么,从顶层业务到底层硬件,整个系统到底是趋于分离,还是统一呢?
这是个问题。
本文将从业务、模型、平台、基础设施四个视角出发,探讨各类系统走向分离或者统一的原因,并尝试从中总结出趋势。
业务视角
大多数业务始于单体架构,它架构和技术栈简单,非常利于初创团队进行原型验证。然而,随着业务的增长,代码量和用户量变得更多,单体架构逐渐显现出它的局限性:
-
可维护性差。某个模块新增或修改一个特性,就必须重新升级整个系统。
-
可用性差。某个模块出现一个 BUG 可能会导致整个系统宕机,对外无法提供服务。
这些局限性背后的原因是系统模块间耦合太深,导致牵一发而动全身。
我们可以根据业务属性,将模块拆分出来成为独立的服务,于是就有了服务化架构。更近一步,再将数据解耦,让每个服务拥有独立的数据库实例,就有了微服务架构4。
更详细的从单体架构演进到微服务架构的内容,参考《软件架构,一切尽在权衡4》。
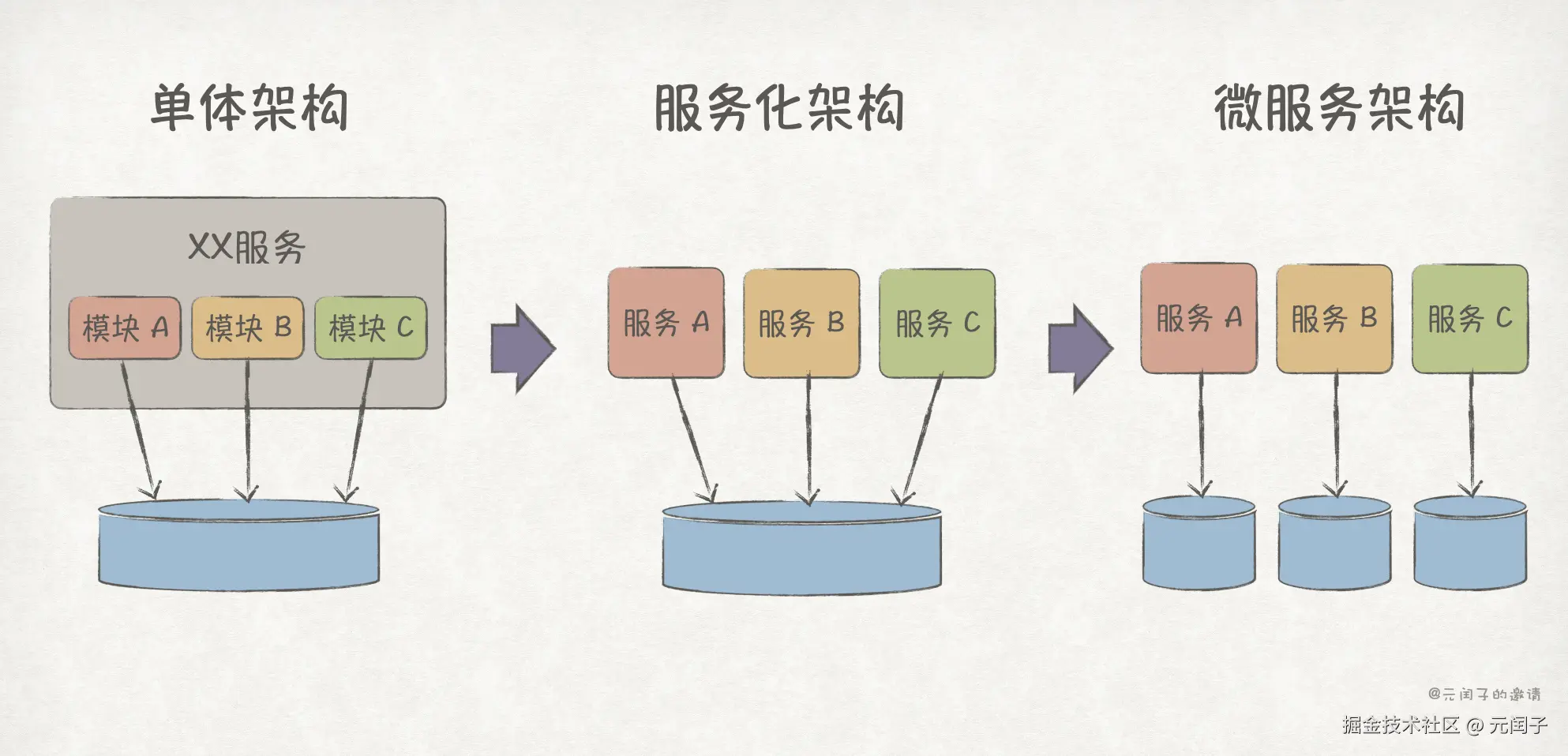
虽然微服务架构也有缺点,比如服务间通信导致的性能下降,但人们更倾向于在平台或基础设施层去解决它们,而不是走回单体架构的路。
AI 时代的应用也是如此,虽然目前 Multi-Agent 系统的失败率普遍在 60% 以上 5,存在 Agent 间无效通信等诸多问题,但大多人都不会怀疑从 Single-Agent 到 Multi-Agent 的演进趋势。Multi-Agent 系统下,各个 Agent 各司其职,在复杂任务的执行上对比 Single-Agent 系统有着绝对的优势。
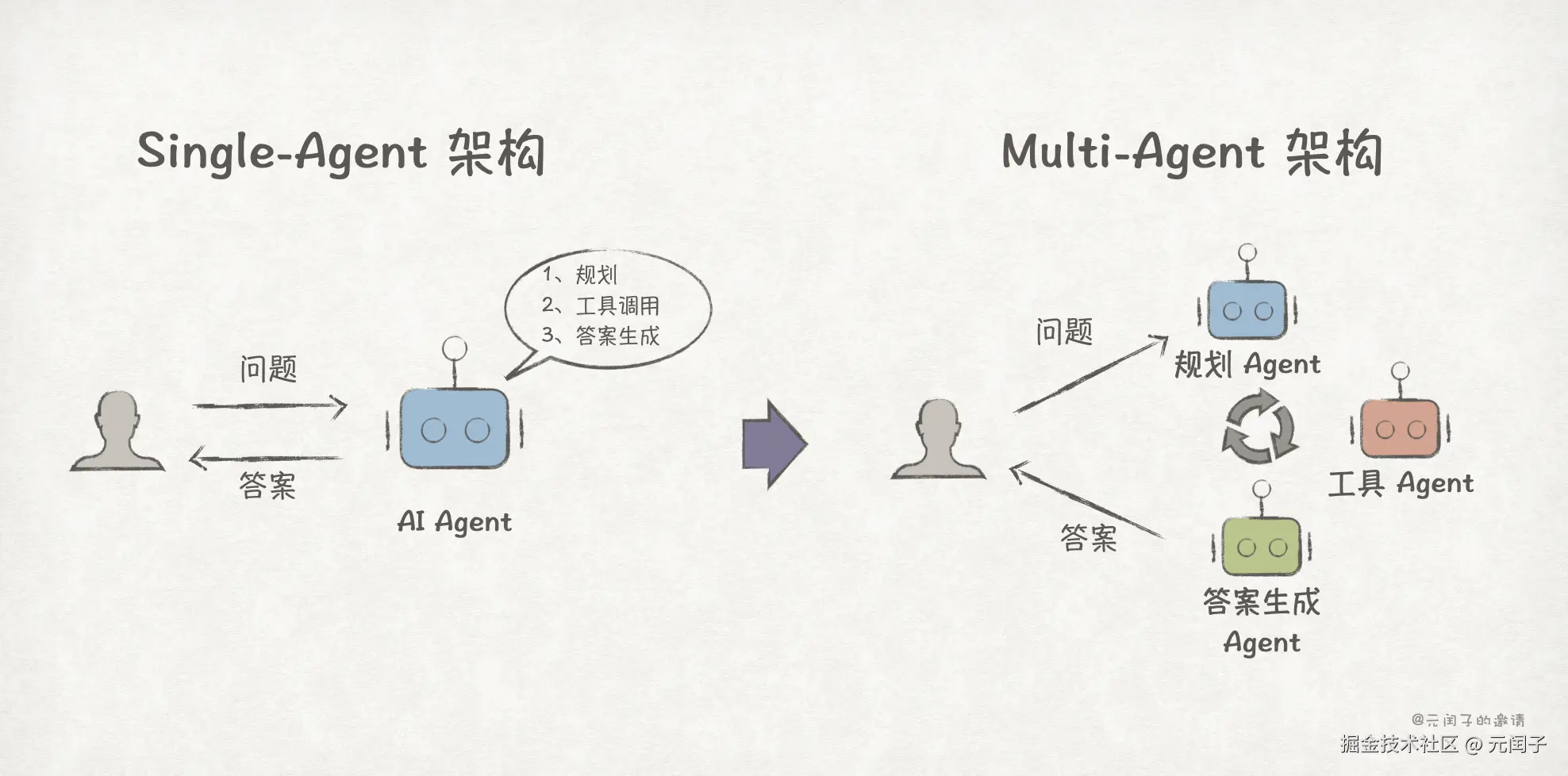
到目前为止,从业务应用视角看,分离貌似是个必然的趋势。其背后的逻辑是,专业的人做专业的事,在各自领域做到最优,尽可能降低相互影响。
然而,我们再往上来到用户交互层,又会发现明显的统一趋势。从黄页到搜索框,从复杂的图形交互界面 APP 到简单的自然语言交互 AI Agent,应用趋于将分散的交互入口汇聚成简单易用的统一入口。
模型视角
从大模型的视角,我们可以看到很多统一的趋势。
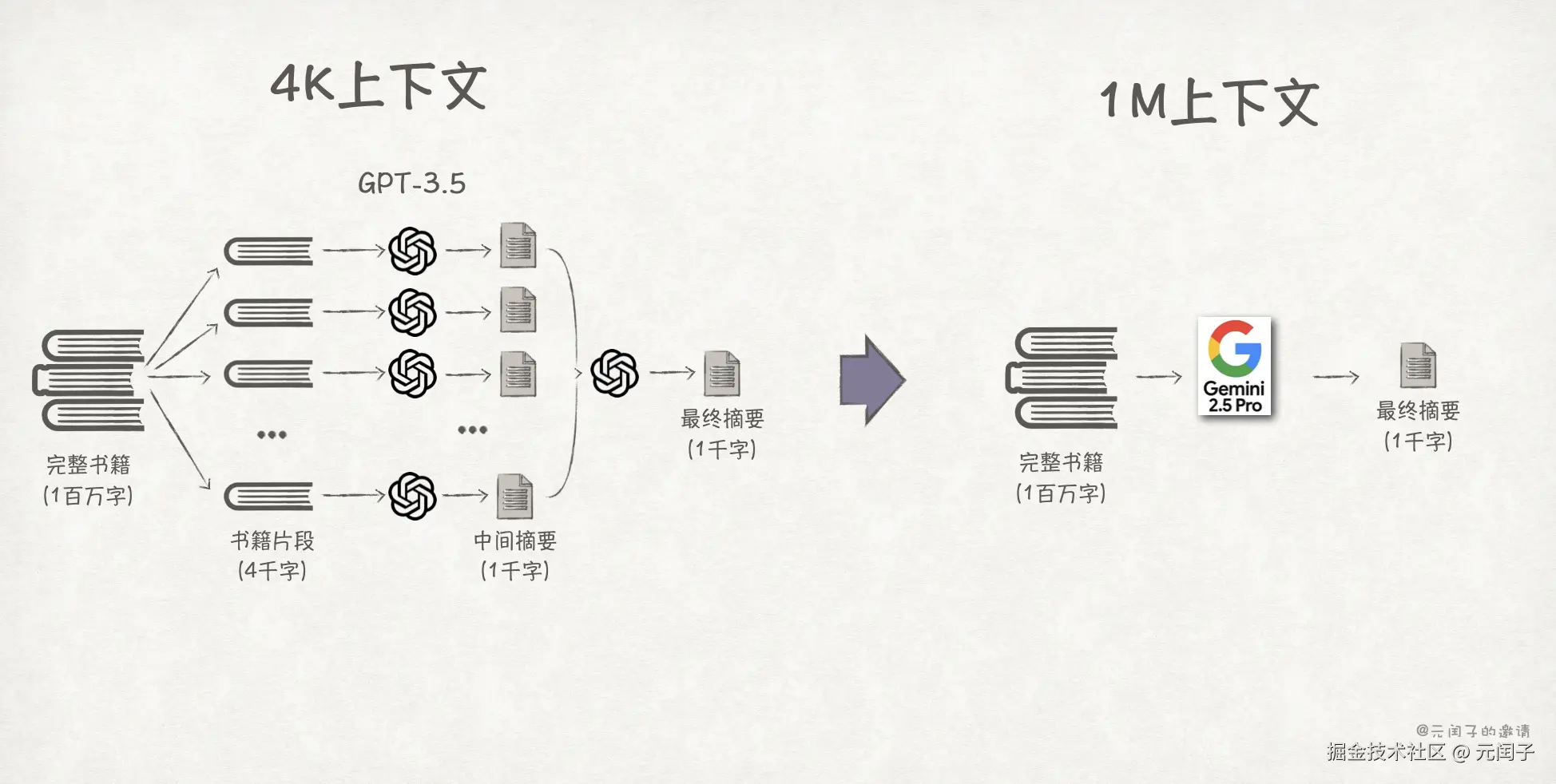
1、模型所支持的 token 上下文长度上限变得越来越大,过去需要分多次执行的推理请求,现在执行一次推理即可。2023 年发布的 GPT-3.5 模型最高支持 4 K 上下文长度(约 4 千个汉字),到今年发布的 Gemini 2.5 Pro 模型已经可以支持 1 M 上下文长度(约 2 百万个汉字)。现假设要为一本 1 百万字的中文书籍生成 1000 字的摘要,那么需要调用 GPT-3.5 约 161 次,生成效率低且不说,还可能会损失部分全局信息导致结果不准确;而 Gemini 2.5 Pro 只需调用 1 次即可,更高效、也更准确。
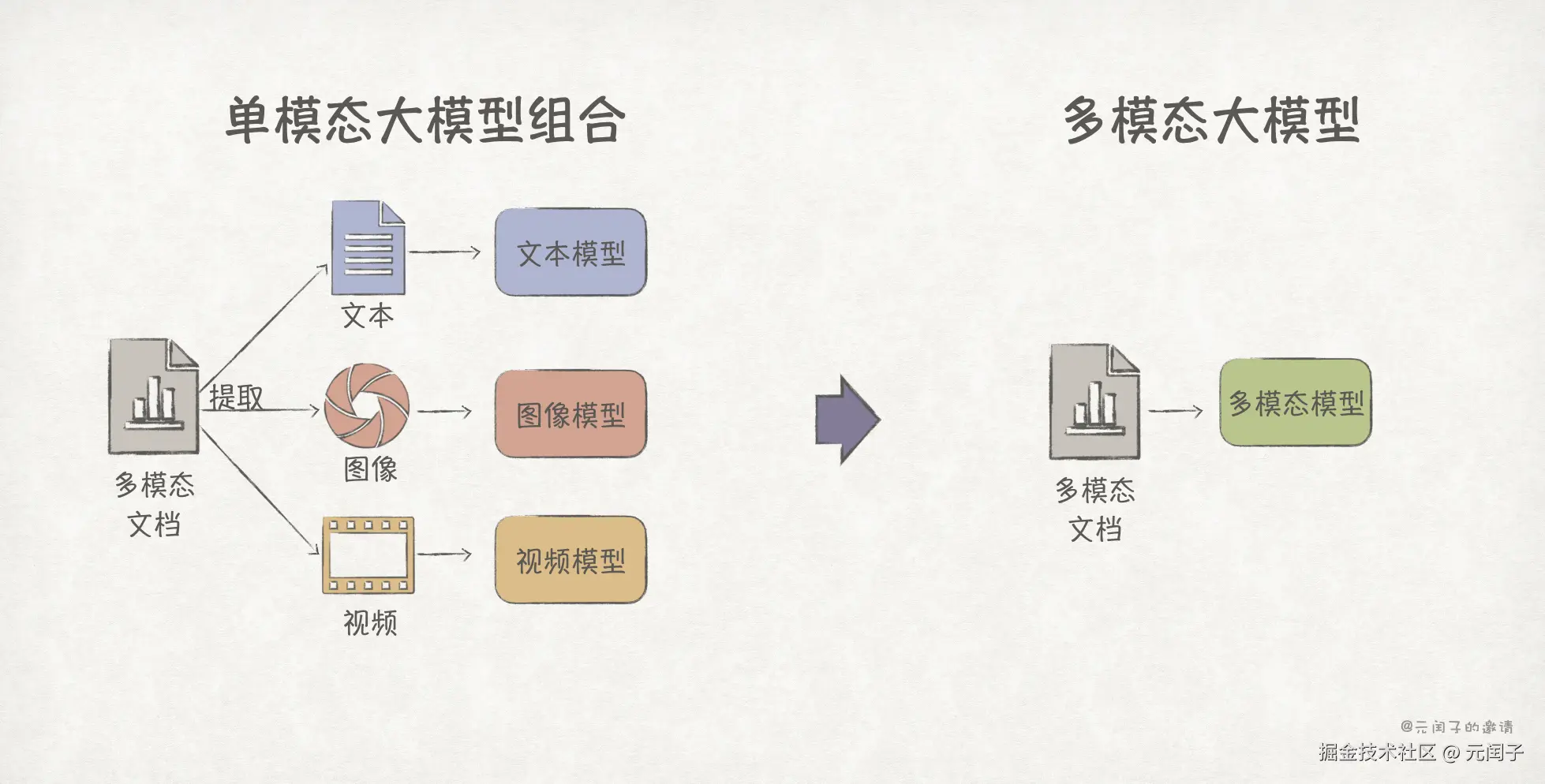
2、多模态大模型已经成为主流,今年发布的豆包 1.6、Gemini 2.5、Grok 4 等都已原生支持多模态理解能力。我们正处于多模态数据融合的时代,一个典型的例子,如今很多文章往往会融入了大量的图表、插图和视频。为了更好地整合和理解文章内容,过去可能使用文本模型 + 图像模型 + 视频模型的组合方案,现在你只需一个多模态模型即可。
3、模型趋于集成工具调用能力。我们在利用大模型执行任务时,很多情况下都需要额外的工具调用,比如通过联网搜索或向量数据库来增强输出质量、执行一段代码等。过去最常见的解决方案是借助 LangChain 这类第三方框架搭建一套工作流,模型会先根据用户输入确定要调用哪些工具,再由框架进行工具调用并将结果反馈给模型,最后模型生成答案。
但这类方案需要人工进行工作流编排,对普通用户来说有一定的使用门槛;而且大模型与外部系统间必然存在中间转换的开销。因此,目前趋势更倾向于将工具调用融入到模型推理的过程中,比如 Claude 4、Kimi K2,毕竟只有模型自己才知道在推理的哪一步需要调用什么样的工具才能生成质量更高的答案。
长文本、多模态、工具调用,这些能力都是用户可以感知到的,无一例外都趋于 All in one 原生集成到模型中,呈统一趋势。
然而,当深入到用户感知不到的模型内部架构,我们又会发现一些分离的趋势,最典型的就是 FFN 层从稠密到稀疏的演进。
在 Transformer 架构中,Self-Attention 层后面会跟着 Feed-Forward Network 层,为线性的注意力机制加上非线性的能力,使模型能够学习更复杂的模式。在稠密架构下,FFN 层计算时它的所有参数都是激活的,无论与任务是否相关。
举个例子,假设这些参数中分成数字处理、因果推理、文学创作、实体识别这四大类,现在用户询问 "1+1=?",即使这是一个数字处理相关的问题,但其他三类参数仍会参与计算,导致算力浪费。
如果模型能够提前识别输入问题的类别,并只激活相关的参数参与计算,那么就能有效减少算力了。
MoE(Mixture-of-Experts)架构就是这个思路,它将不同类别的参数拆分出来成为一个个 Expert 专家,由 Gating Network(路由) 将 token 路由到对应的 Top-K 个 Expert 上进行计算,未激活的 Expert 不参与计算。
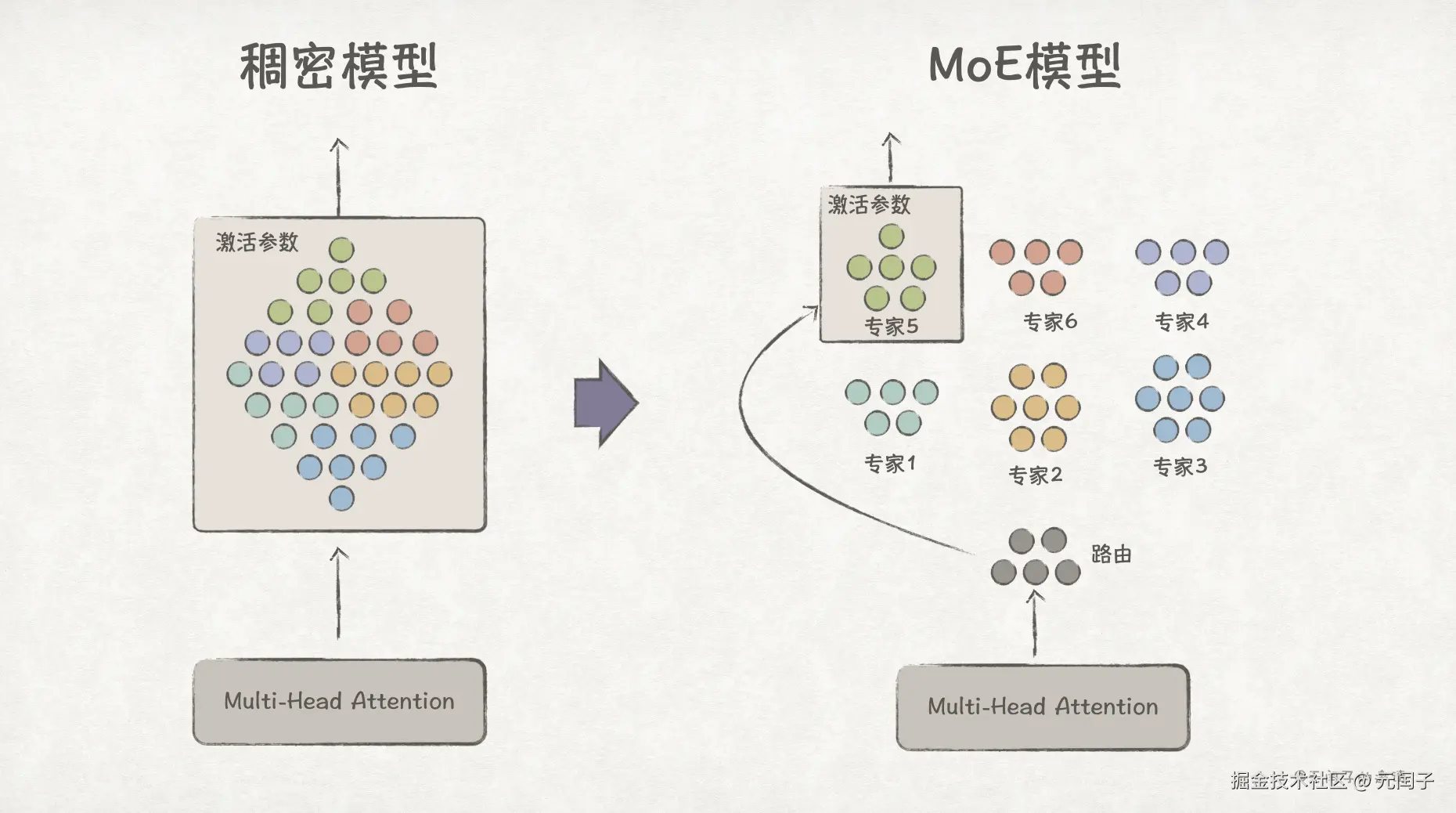
可见,模型也不是一昧的统一。
平台视角
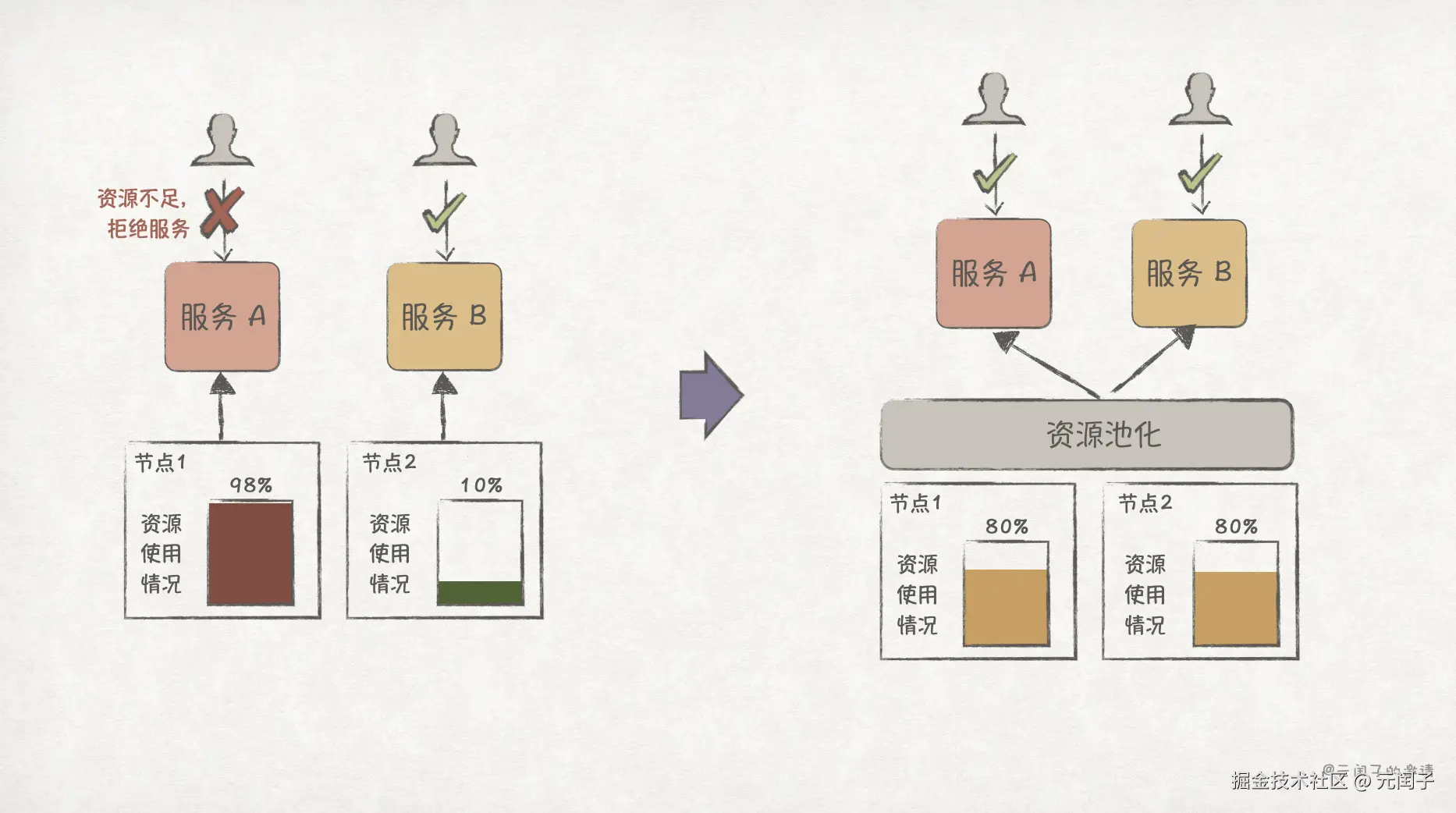
回到前文微服务的例子,服务拆分后,最简单的部署方案是把各服务部署在独立的节点上。然而,微服务的工作负载通常都是不稳定的,有波峰波谷,这种部署方案会带来资源利用率低的问题。比如在某个时间点,服务 A 正处于业务高峰期,节点资源已经用满,为保障 SLA 不得不采取限流机制;而服务 B 正处于业务空闲期,有大量的资源空闲。
更好的方法(也是当前的主流方法)是将所有节点资源池化,通过全局的调度器(比如 K8S)来进行统一调度,这样就可以将原来服务 B 所在节点的资源给服务 A 使用了。
除了微服务,企业通常还会存在大数据、AI 训练和推荐等各类业务,过去,为了避免不同业务之间相互影响,它们通常会部署在不同的集群。随着资源调度和隔离技术的成熟12,不同业务趋于混合部署、统一调度,以追求更高的资源利用率。
再来看数据系统。
假设现在要对微服务所产生的数据进行分析,以支持商业决策。最简单的方案是直接读取各微服务的数据库。
但这个方案有着明显的缺点:数据过于分散。随着数据量的增大,这种跨库的数据查询性能将会变得很差。更好的方法是单独设立一个关系型数据仓库(Rational Data Warehouse, RDW),将各数据库的数据同步到 RDW,由 RDW 对外提供高性能的 SQL 查询服务。
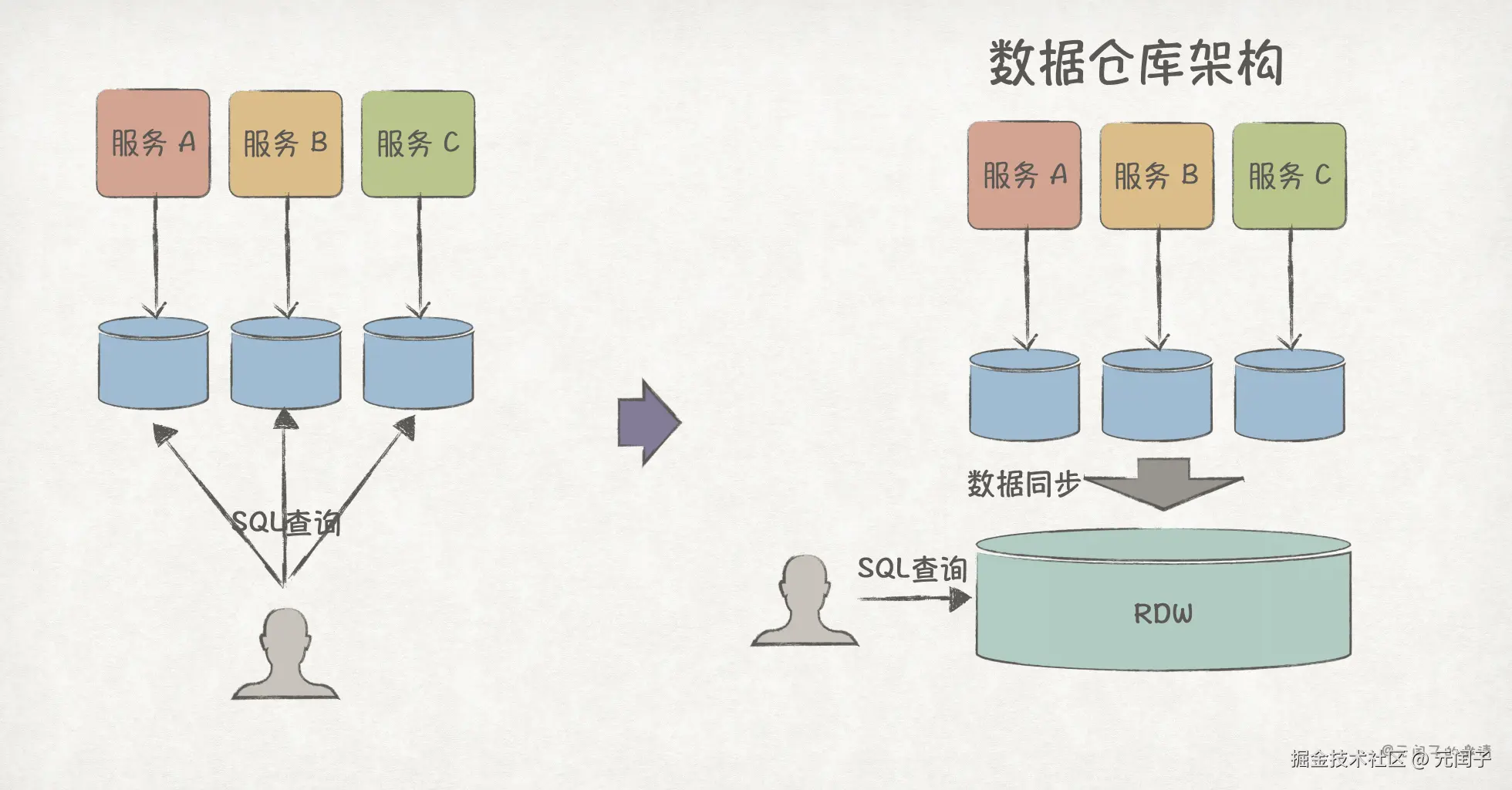
前面我们主要关注结构化的表格数据,但企业还有很多 PDF、图片、视频等非结构化数据,RDW 无法处理。为此,数据湖(Data Lake)被引入,提供非结构化数据的读写能力。
到目前为止,结构化数据的写入和非结构化数据的写入是分开的,可以让它们都统一入湖 ,再从数据湖中同步数据到 RDW,这就是现代数据仓库架构(Modern Data Warehouse,MDW)。
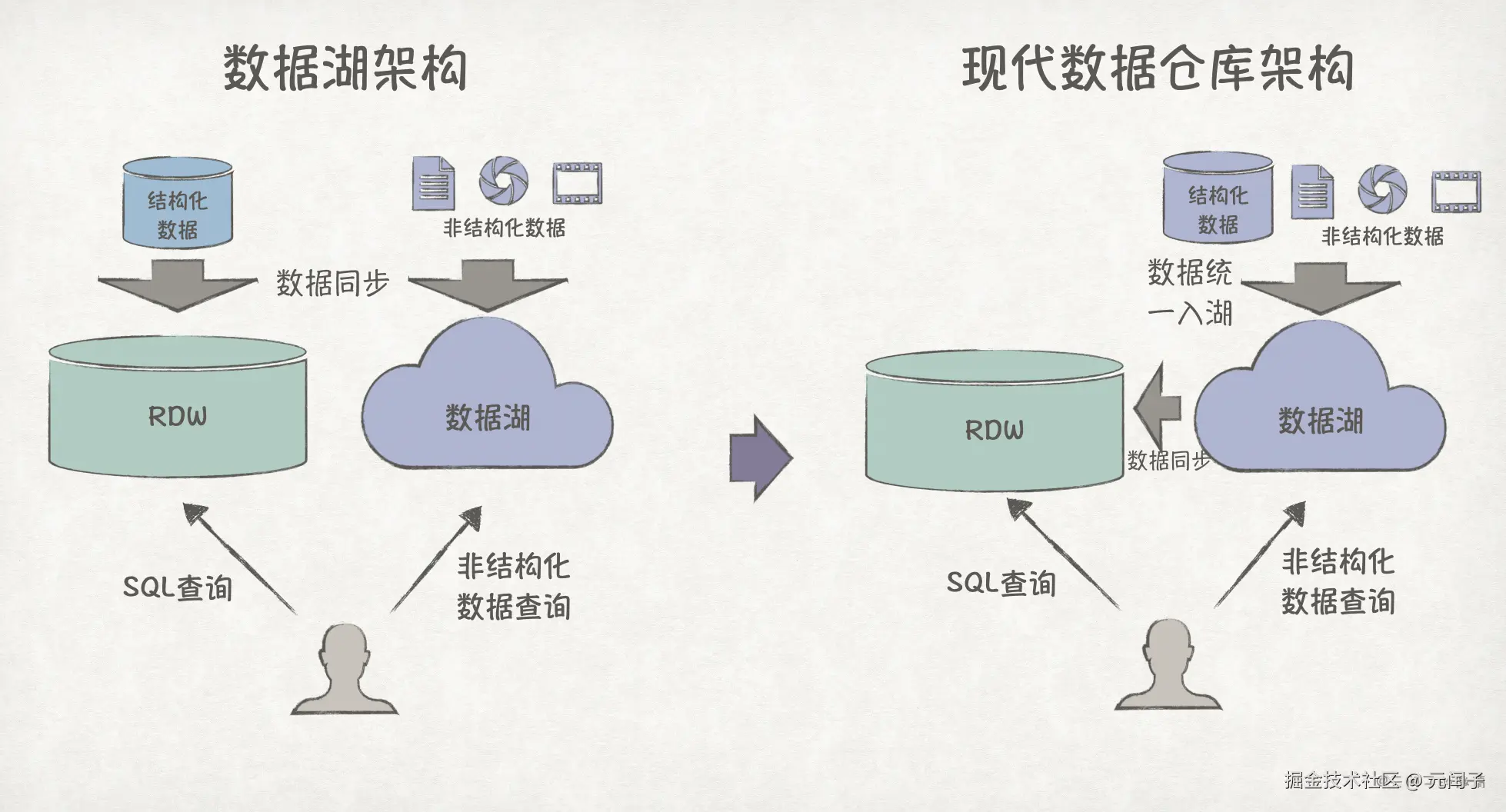
MDW 架构下结构化数据和非结构化数据的查询是割裂的,可以在此之上构建一个统一的数据治理层,提高数据的可访问性、可发现性、安全性和可用性,这就是 Data Fabric 架构。
到现在,结构化数据还需从数据湖复制到 RDW,存在两份数据副本,可以在数据湖之上构建一个能够同时支持结构化和非结构化数据的读写格式,比如 Delta Lake、Iceberg,这就是 LakeHouse 湖仓一体架构。
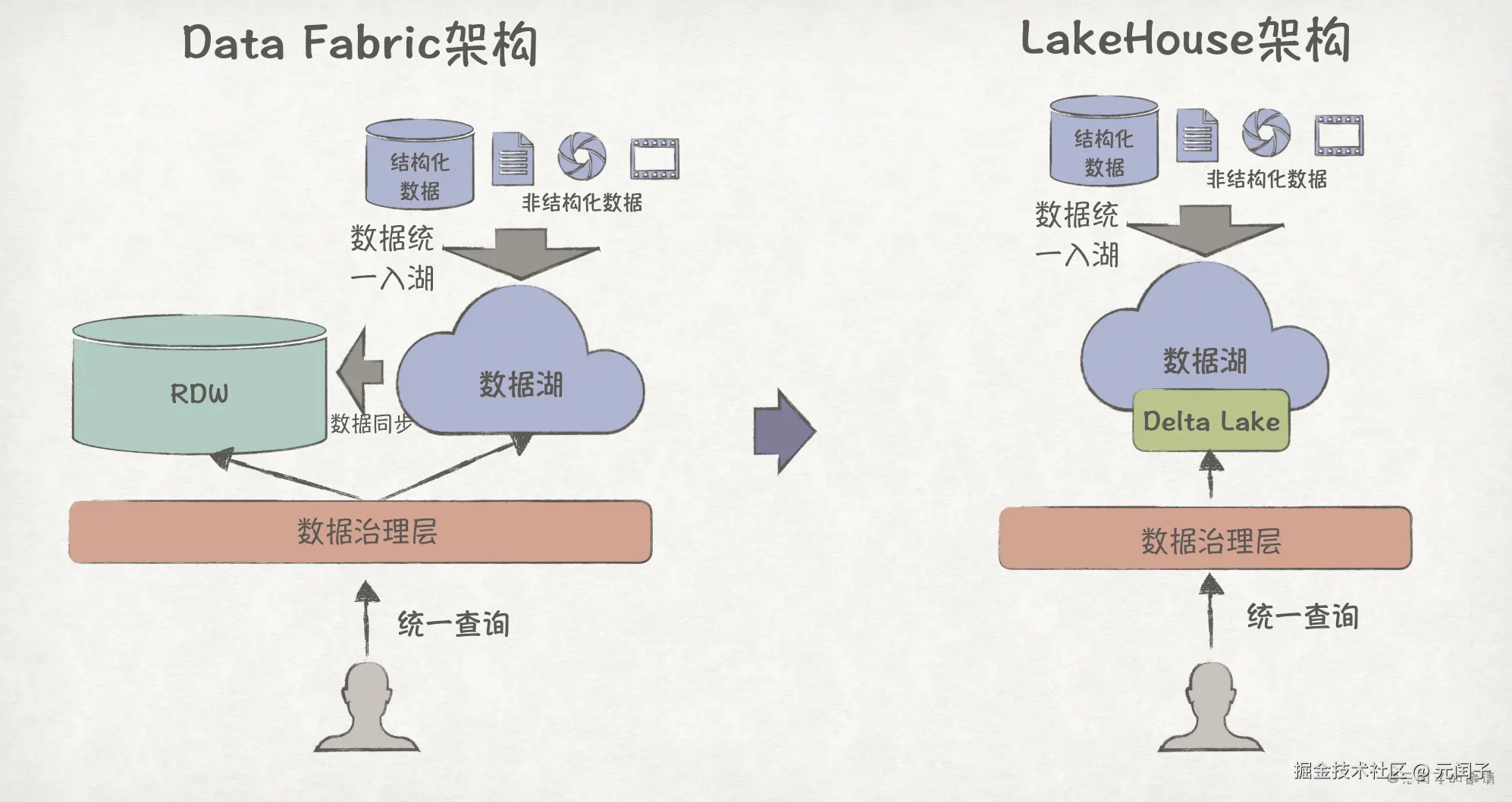
可见,从数据仓库到湖仓一体,数据系统着明显的统一趋势,旨在减少数据副本、为用户提供结构化和非结构化数据的统一查询服务。
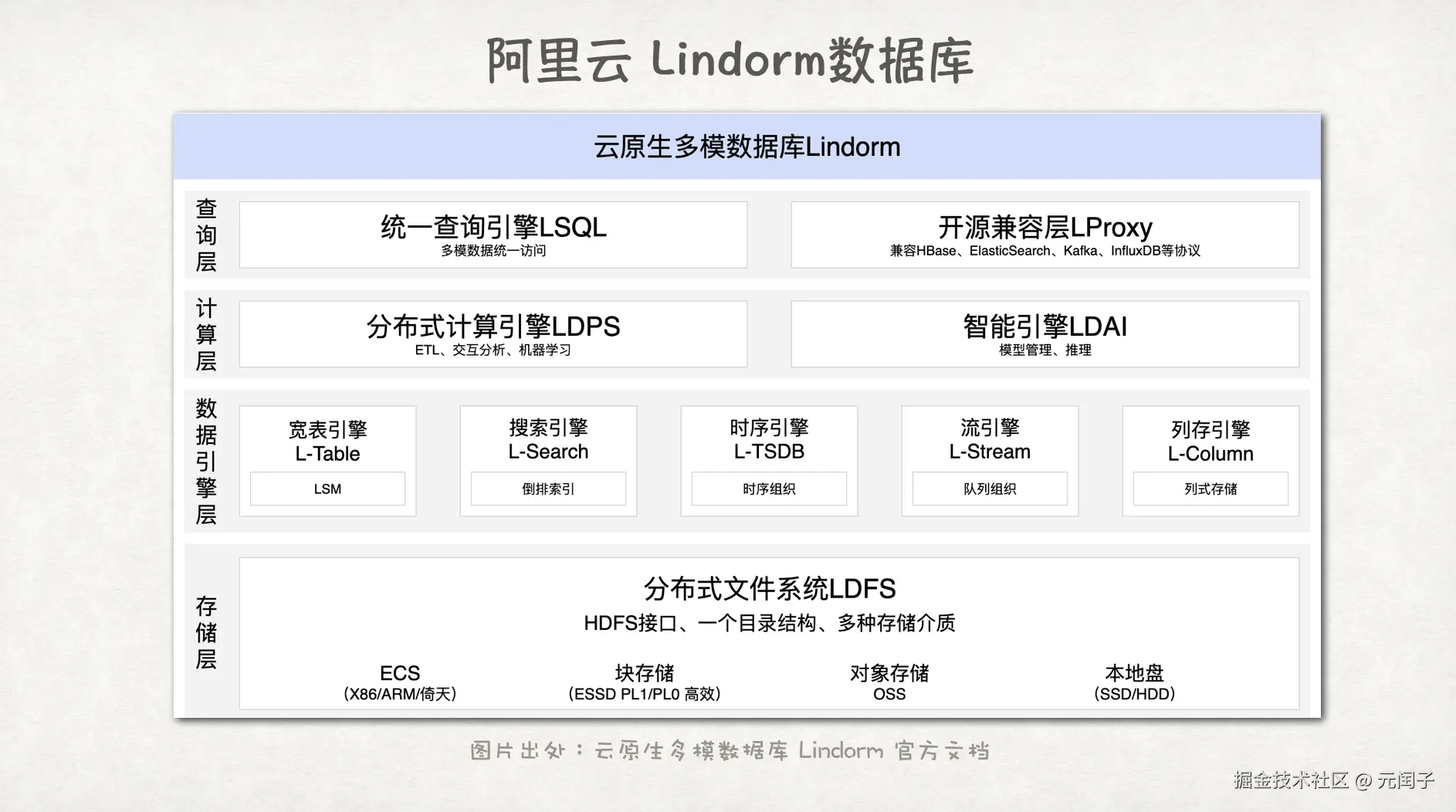
除了大数据系统,数据库系统也在走向统一的路线,特别是 AI 时代到来后,能够同时支持多种工作负载的一体化数据库13也成为了一种演进趋势。数据库虽然在功能上趋于统一,但在技术实现上却仍是分离的趋势,一体化数据库里针对 OLAP、OLTP、向量、全文检索等不同的负载,仍是采用不同类型的引擎,只是在查询层做了统一14。
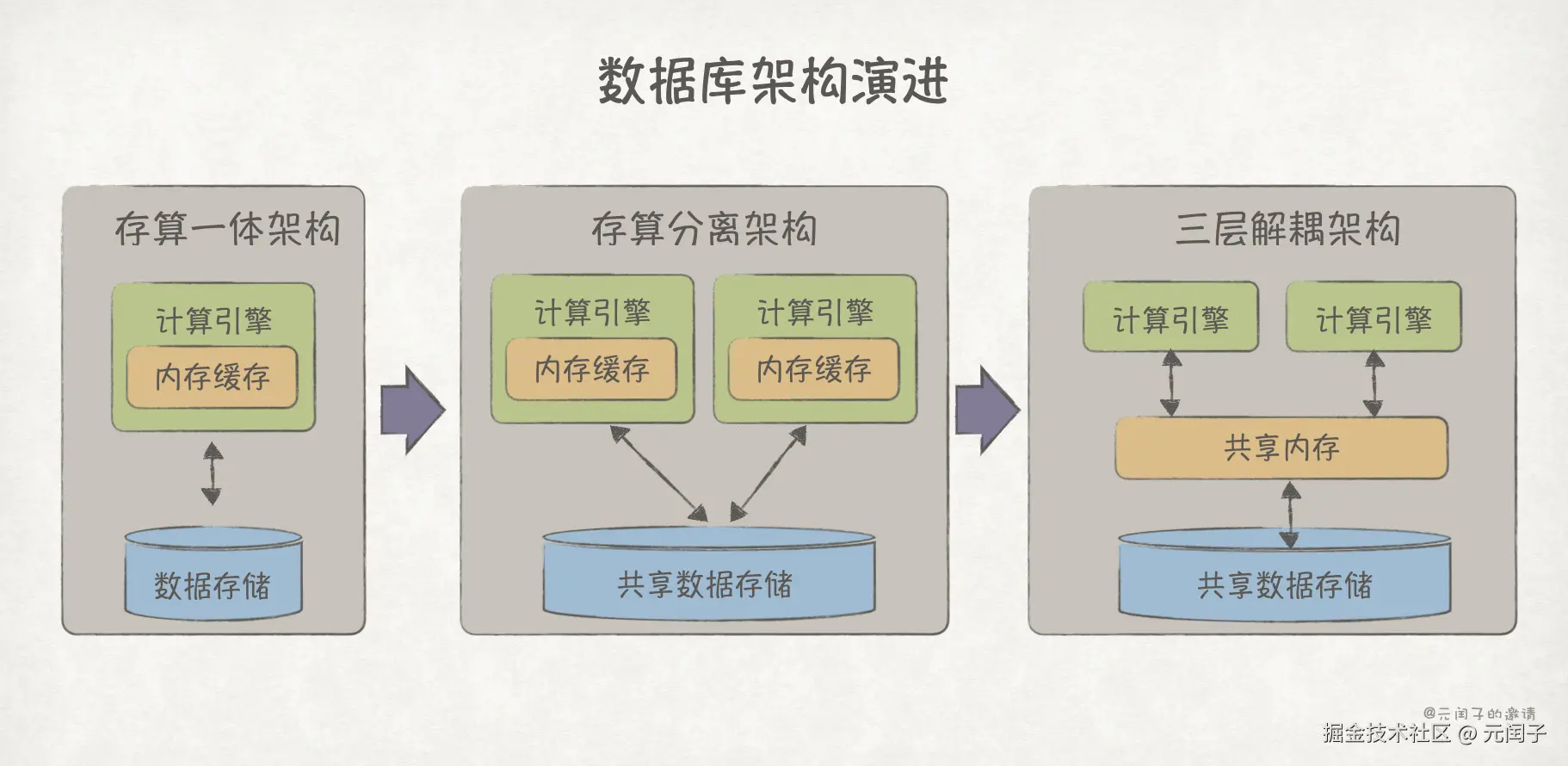
另外,数据库也从最开始的存算一体,到存算分离,再到今年阿里云 PloarDB 的计算、内存、存储三层解耦15,通过分离架构实现极致的资源利用率和可扩展性。
基础设施视角
在最初的冯诺依曼体系架构中,包含控制器和运算器的中央处理器,即 CPU,被设计成能够处理所有业务负载的通用计算芯片。经过多年的优化,CPU 在分支预测、指令乱序执行等流程上都已经过了深度优化,非常善于执行复杂的计算任务。
然而,并非所有的业务都需要复杂的计算,比如图形渲染和矩阵运算,它们都由大量的简单计算任务组成,所需的是强大的并行计算能力,这促使了专用加速芯片 GPU、NPU、TPU 的诞生。类似的,还有专门针对 IO 密集型负载的 DPU 加速芯片。
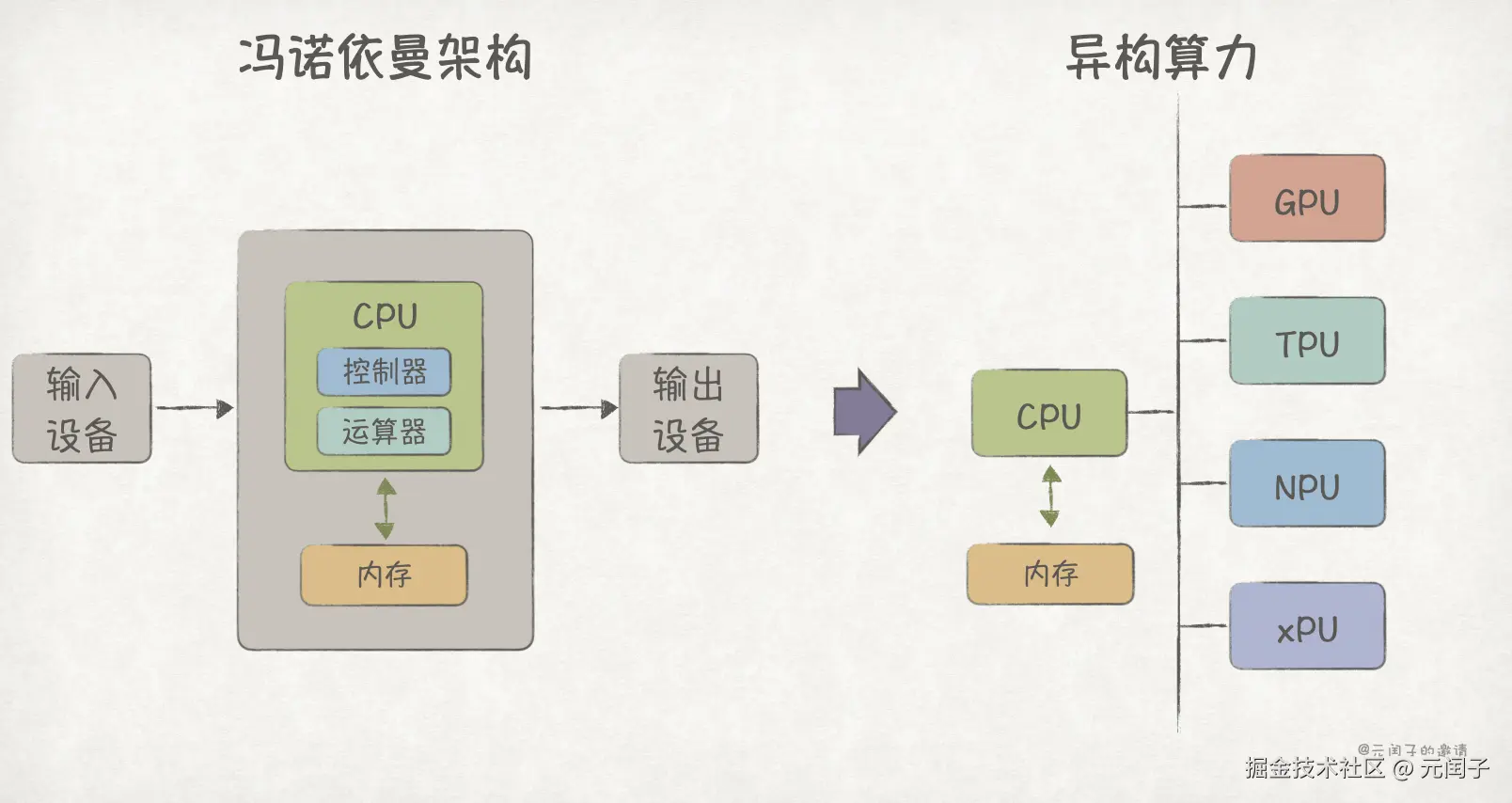
这意味着,基础设施趋于用专门的硬件去应对不同的应用负载,与前面提到的数据引擎类似,走的是分离的路线。
如《为什么CPU不能有更多的核? 》里所提到的,基于功耗、散热等多方面的考虑,单个芯片的核数(算力)不能无限增加,这也同样适用于单服务器。当业务所需算力超过单机算力时,最常见的做法是通过 TCP/IP 网络将各个服务器连接起来,形成一个分布式的系统。
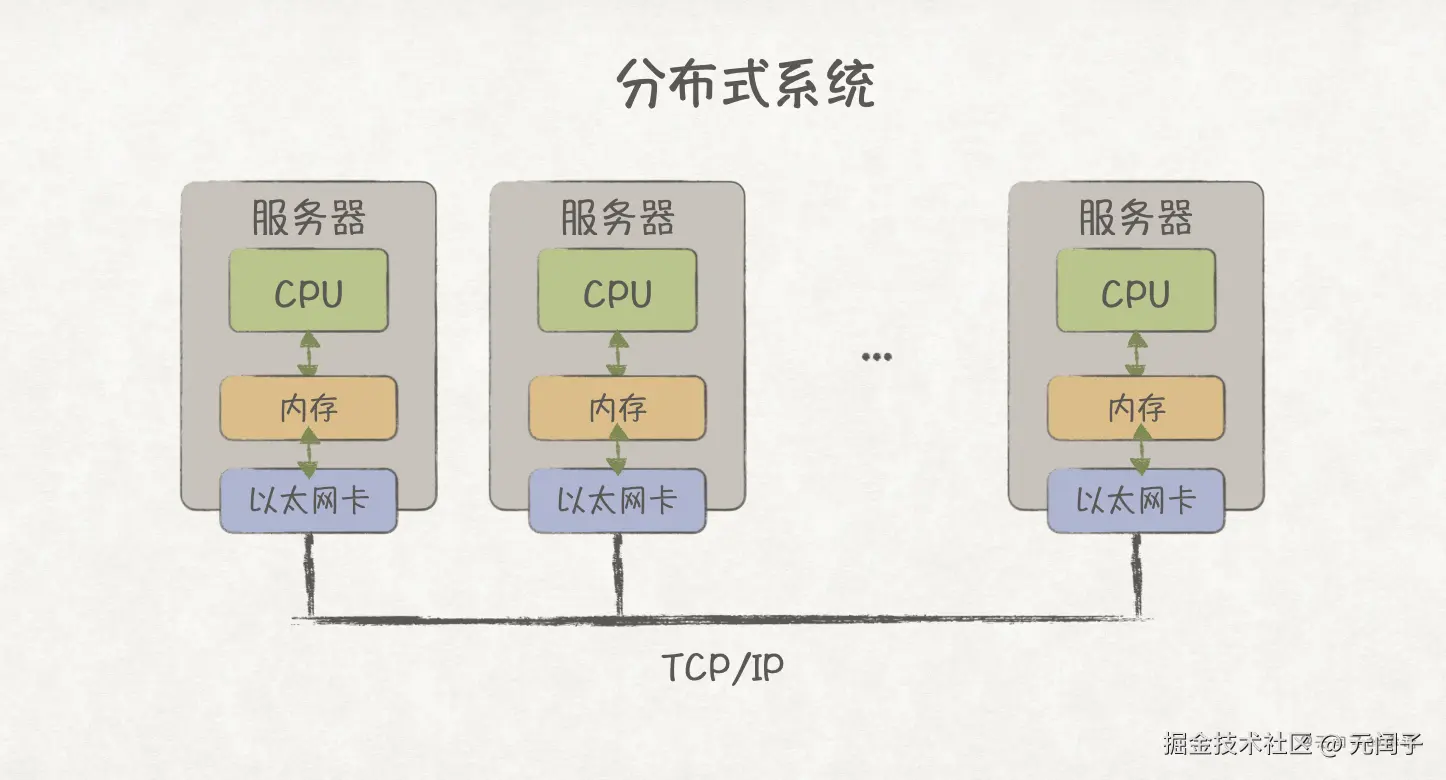
但 TCP/IP 网络传输,就意味着数据需要经过多层协议栈解析,而且网络带宽通常都在 100 GB/s 以下。随着 AI 时代的到来,面对计算密集型的 AI 负载,通信往往会成为主要瓶颈。
于是,类似 NVLink 这种支持 GPU 点对点通信的高速互联协议被推出,到 NVLink 5.0 代际,单 GPU 已可支持 18 个 NVLink 连接,总带宽可达 1.8 TB/s,极大改善了通信瓶颈。
而 CXL 协议(Compute Express Link)则更近一步,它支持远端 Load/Store 内存语义通信,允许程序像访问本地内存一样访问远端节点内存,让真正意义上的超节点成为可能。
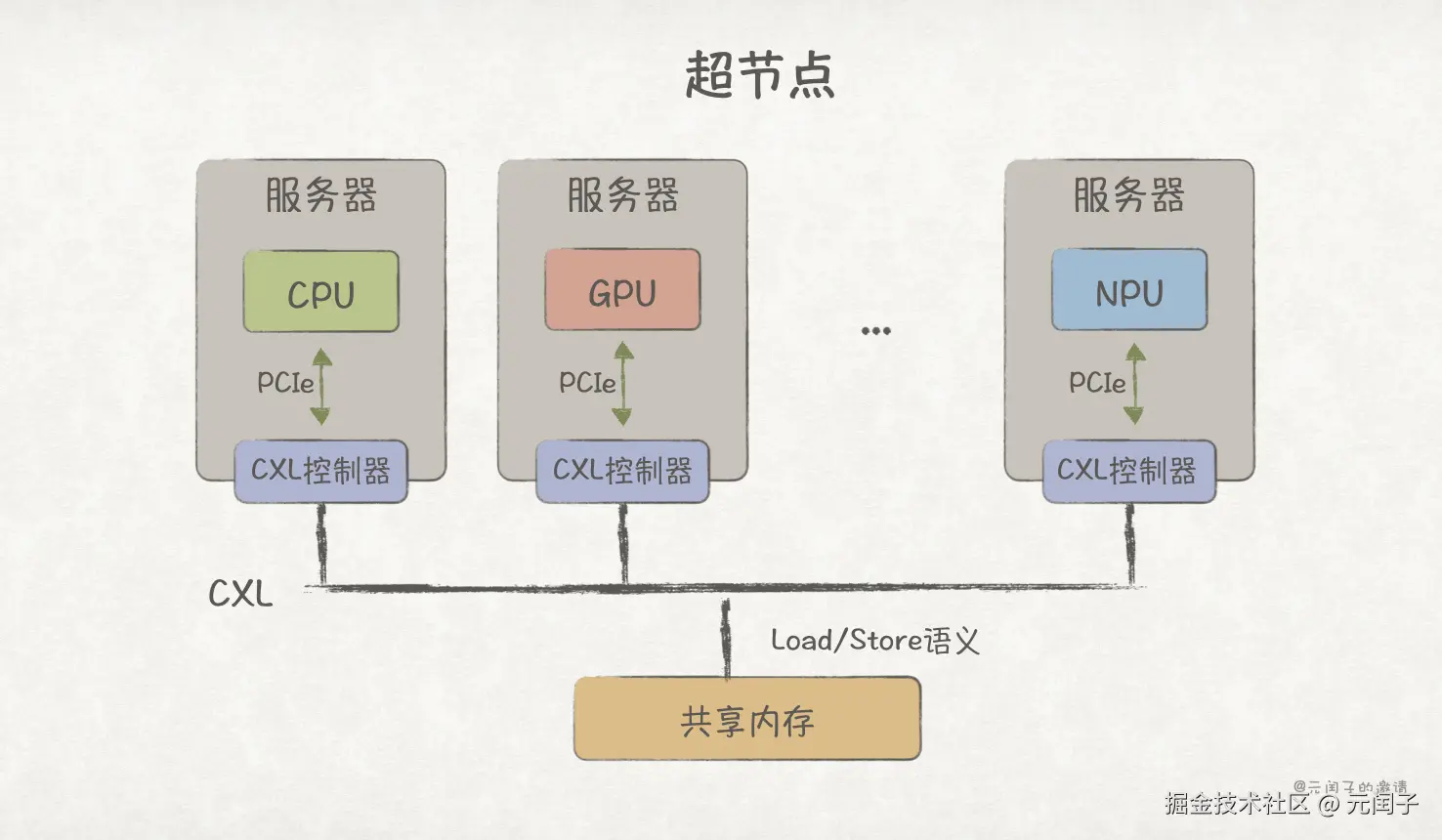
所以,基础设施也趋于让各类异构算力互联更高效,形成一个超节点对外提供服务,是典型的统一路线。
分离还是统一?
如前文分析,从业务、模型、平台、基础设施几个视角上看,整个系统既有分离趋势,也有统一趋势。
那么,这些趋势是否有规律可循呢?
仔细观察可以发现,整体上计算机系统在物理上趋于分离,在逻辑上趋于统一。
不管是微服务的拆分、MoE 模型 Expert 的分离,还是不同的数据引擎、异构算力,都在朝着"专业的人做专业的事"的方向发展。其背后的逻辑源于系统设计本身是一个权衡的过程,天下没有完美的解决方案。所以,在物理实现上,是分离的趋势。
但要想做到整系统的运行效率最高,往往需要把各类资源整合在一起,进行统一的管理和调度,比如资源池化管理、异构算力混合调度等。其背后的逻辑源于必须有全局的视角才有可能做到全局最优。所以,在逻辑功能上,是统一的趋势。
最后,回到最初的问题,计算机系统的发展到底是趋于分离,还是统一?
这不是一个非黑即白的选项,整体上看,物理上分离、逻辑上统一的趋势对大部分系统都成立。
文章配图
可以在 用Keynote画出手绘风格的配图 中找到文章的绘图方法。
参考
1 深入理解 Lambda 架构, 元闰子
2 NVIDIA GB200 NVL72, NVIDIA
3 Serving Large Language Models on Huawei CloudMatrix384, HUAWEI
4 软件架构,一切尽在权衡, 元闰子
5 Why Do Multi-Agent LLM Systems Fail?, UC Berkeley
6 快速了解生成式AI, 元闰子
7 Introducing Claude 4, Anthropic
8 Kimi K2: Open Agentic Intelligence, Moonshot AI
9 A Comprehensive Review of Multimodal Large Language Models: Performance and Challenges Across Different Tasks, 中国西北工业大学等
10 Qwen 3 Model Family Explained: Dense vs MoE Architectures, Topmost Ads
11 Deciphering Data Architectures, James Serra
12 Volcano, CNCF
13 一体化数据库,打造 GenAI 时代数据底, IDC, Oceanbase
14 云原生多模数据库 Lindorm, 阿里云
15 我,PolarDB云原生数据库,5年来实现这些重磅技术创新, 阿里云
(完)